
Chapter 8: Defining Automation Tools and Processes
One of the major advantages of cloud environments is the fact that we can automate almost anything. We don't want too many manual tasks in our cloud environment. We also want to automate as much as we can in the management of the infrastructure. How do we automate cross-cloud, what processes do we need to have in place, and who's going to be responsible for managing the automation templates?
This chapter will introduce the core principle of automation in abstracting environments in layers. We will look at the automation tools that are integrated with the platforms of the major providers: Azure, AWS, and Google Cloud. Next, we will study how we can design an automation process, starting with storing our source code in a single repository, and then we will apply version control to that code. We will also briefly discuss the main pitfalls when defining automation.
In this chapter, we're going to cover the following main topics:
- Understanding cross-cloud infrastructure automation
- Creating automation processes using a code repository and workflows
- Using automation tools
- Designing automation for multi-cloud
Cross-cloud infrastructure automation
Before we can start thinking about automation itself, we need to virtualize all of our components in IT. Automation simply doesn't work if we have to drag physical devices into a data center – unless we have robots or drones to do that. So, it starts with virtualization, and this is exactly why companies such as VMware still play such an important role in the cloud arena. Their software-defined data center (SDDC) concept is basically the blueprint for building clouds. We have to virtualize the full stack: compute, storage, and networks.
Only virtualized entities can be stored in a repository, and from there programmatically provisioned on-demand. However, we want this to be truly multi-cloud, hence the interoperability of these virtualized components is key in automation.
Virtualization is the starting point, but we want it to be truly agnostic and cross-platform. Then we'll find that a lot of systems are still very dependent on settings in the underlying physical infrastructure, even in the public clouds of the hyperscalers, the major cloud providers: Azure, AWS, and Google Cloud. Let's take virtual machines as an example: we can tell the physical host that it can share its processor (CPU) and memory among multiple virtual machines by using a hypervisor, but all of these virtual machines still will need their own guest operating system.
One way to overcome this issue is by using containers. As we saw in Chapter 4, Service Design for Multi-Cloud, containers don't have their own operating system; they use the operating system of the physical host. Yet containers do require a platform that can host and orchestrate these containers. This is where Kubernetes typically comes in. The main platforms all have Kubernetes services (AKS, EKS, PKS, and GKE), but also, for the use of containers, we need to build and configure infrastructure. The use of containers doesn't mean that we can skip infrastructure build.
In essence, it comes down to abstracting layers. We have to make sure that the application layer is not depending on the infrastructure layer: it needs to be completely unaware of the infrastructure it's hosted on. Let's first look at a logical view of these layers:
- Access layer: The access layer comprises the network and interfaces. We need networking to get connections from the outside into the environments that are hosted on the cloud platforms and connections within the platforms so that applications can communicate with each other or with, for example, databases. The access layer also contains the interconnects to the services layer; this can be a real portal or any command interface that we can use to order and configure services in the services layer.
- Application layer: This layer holds the application code and the configuration code of the application. It's completely separated from all the other layers.
- Services layer: This is the layer where Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS) are positioned. IaaS contains services for servers or storage. PaaS is for managed services, such as AWS Elastic Beanstalk or RedHat OpenShift. SaaS contains full-stack business services, such as office automation – for example, Office365.
- Resources layer: This is the layer where the building blocks are for the services in the services layer. In this layer, we have a physical pool of resources for the CPU, disks, network interface cards (NICs), and so on. These are all the resources that are needed to build a server and make it accessible over a network connection. This layer also contains a pool of logical resources, such as operating systems and runtime scripts.
The following diagram shows the concept of abstracting the data center in order to virtualize it and providing a logical view in deploying environments on a cloud platform:

Figure 8.1 – Logical model of abstracting layers in an environment
You can imagine how deploying IT environments used to be a very intensive, costly process that took a lot of effort and time before we found a way to get our infrastructure defined as code. Besides defining the architecture, we really needed to do a proper sizing of the physical machines that we would need in our data center. A mistake in the sizing or ordering the wrong machines could lead to a situation where the capacity would either not be enough or be too much. After ordering the machines, we would need to install them in the data center, and only then could we actually start deploying our workloads – a process that could easily take up two months of the total throughput time.
Now, we have the technology to virtualize the entire data center, and even better: we use existing data centers that Azure, AWS, and Google Cloud provide. They have already figured out a lot of the building blocks that we can use from the resource, services, and access layer to compose our environments. These building blocks are code. Putting the building blocks together is the only thing left to do. Cloud automation is exactly about the steps of putting it all together. If we have found a way to put building blocks from the different layers together and we know that we want to repeat this process frequently, then it makes sense to automate the steps that form this process. It will save us time and thus costs; but also, with automation, the risk of errors will be lower than with manual intervention.
In the next section, we will dive into the process of automation and how we can use catalogs and libraries for the automation process.
Automation processes using a code repository and workflows
In Chapter 4, Service Design for Multi-Cloud, we briefly discussed the continuous integration (CI)/continuous delivery (CD) pipeline. In this section, we will explore this further since the CI/CD pipeline is a crucial part of our automation. A high-level diagram of the pipeline is shown here:
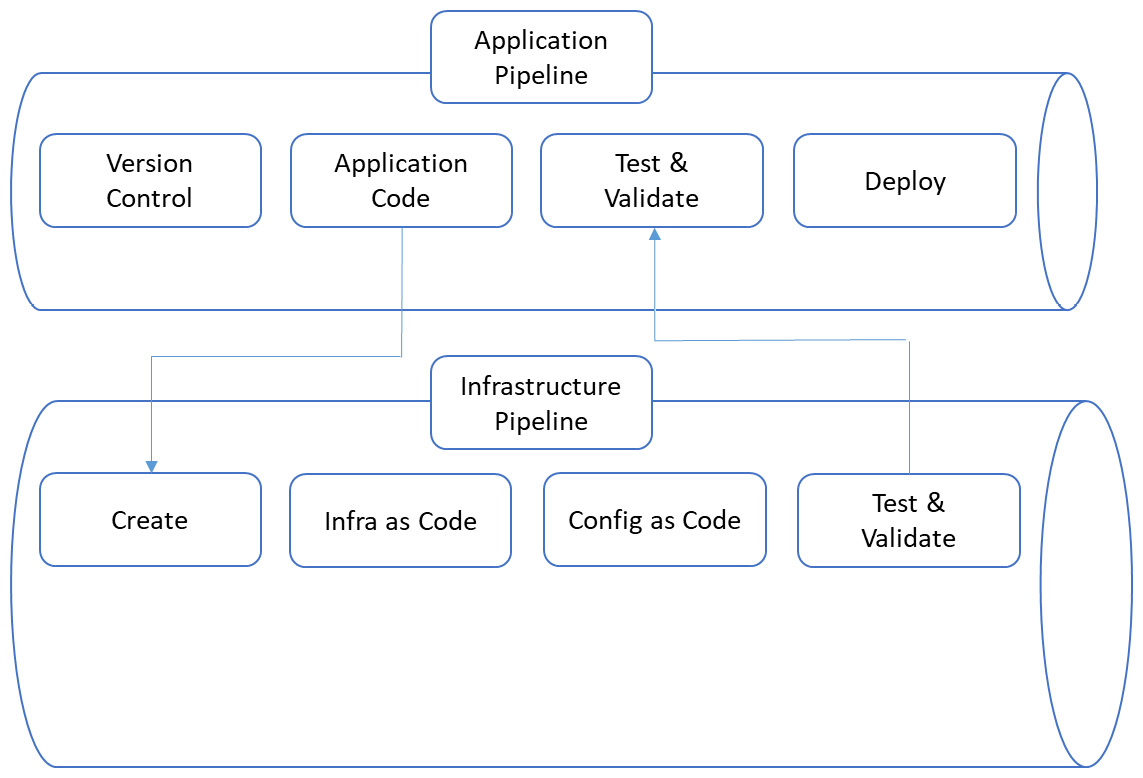
Figure 8.2 – High-level overview of the CI/CD concept
The pipeline begins with version control and the actual application code. To start version control, we will need source code. This source code is typically stored in a source code repository. An example of an independent repository is Git, such as GitHub, BitBucket, or GitLab. However, each cloud has its own, and an enterprise can even host their own repository on-premises. The automation pipeline configuration starts with a request to change the code – or to fork the code. By forking, we are creating a new branch where we can develop the code further. This forked code can then be submitted back to the master branch when it's validated and tested.
In any case, the request will trigger a process in the CI pipe that will prepare the code for the next stage. This is the build phase, where the code is packaged into components that can be deployed into our environment. This package will contain not only the application code but also the packages for the required resources where the code is to be deployed. Resources can be a virtual machine, a storage block, or a container. Finally, before we get to deployment, all of these packages need to be tested and validated against the desired state and policies, after which the whole deployment process finishes.
Common processes to automate infrastructure in cloud environments are as follows:
- Auto-provisioning of virtual machines
- Deploying Desired State Configuration (DSC) to infrastructure components
- Deploying backup schedules
- Automation of workflows for scaling and failover scenarios (for example, disaster recovery)
The most important automation task is to create infrastructure as code (IaC) and store that in the repository. With automation tools, we can fork items from the repository. This is the reason why abstraction in layers is crucial. Every item or component is defined in code: virtual machines, storage blocks, network parameters, and containers. Depending on the application code and the packages that have been defined to run this application code, the automation tool will know how it should assemble components and next deploy them into our environment. If an application requires, for instance, a number of containers, the tool can create these containers and also configure them to land on a Kubernetes node, connect storage, configure load balancing, and apply the network policies. This entire workflow can be set as a process within the automation.
But there's more that automation tooling can do and can bring benefits besides the automated deployment of environments. Automation can also be used to manage environments. We can use automation to perform tasks such as scaling or trigger remediation actions when the performance of an application is degrading. This is why automation tooling needs to be integrated with monitoring. If this monitoring detects that an environment is experiencing peak load or the performance decreases, it can trigger the automation to execute predefined actions: for example, add extra virtual machines, increase storage capacity, and add load balancing. On the other hand, if environments or components are detected to be idle, automation can be triggered to remove these components if they are not needed anymore, and with that, save costs.
Be aware that provisioning, managing, and removing components is tied into a process – a workflow that needs to be defined carefully. Just removing a virtual machine, for instance, can cause failures if that machine has connections to other components in the environment. Automation needs to be aware of these connections and other interactions.
The very same applies if we auto-deploy new workloads to our environment: with what other components should these workloads interface? Automation is not something that you just turn on and then wait for the magic to happen. We will need to define and design the workflows in the automation tool. The following diagram shows an example of a workflow to automate the deployment of a virtual machine:
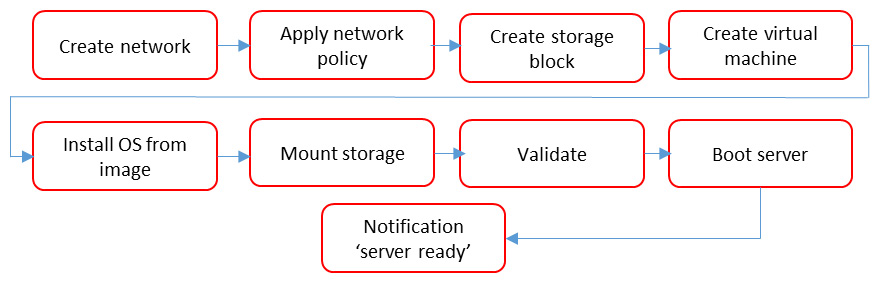
Figure 8.3 – Conceptual workflow for the deployment of a virtual machine
In the next section, we will explore various automation tools and how we should get started with automation.
Exploring automation tools
There's a whole world to discover when it comes to cloud automation; there are a lot of tools available on the market. The cloud platforms themselves offer native tooling. We'll look at these first.
Azure Automation
Azure Automation offers a variety of solutions to automate repetitive tasks in infrastructure that is deployed in Azure. Using DSC can help in keeping the infrastructure up to standard, consistent, and compliant. It may be good to recap DSC first since it's an important aspect of cloud automation.
We're automating for two main reasons: to drive operational costs down and to prevent human error by having administrators doing too many manual and repetitive tasks. DSC is one way to start with automation. If we run a server farm, we might get to a point where we discover that over time, the settings on these servers have changed and actually differ from each other. If there's a good reason to allow these differences, then this is not necessarily an issue and should be documented with an updated DSC.
In larger server farms, it can be a cumbersome, time-consuming task checking and manually updating servers. We want that process to be automated with a tool that monitors whether servers still have the right settings and policies applied, and if that's not the case, automatically remediate these settings and policies. Servers that are newly deployed will also automatically get these settings and policies. This is the benefit of standardization that a DSC provides.
Azure Automation is the tool to manage DSC: it handles configuration and update management. But the most interesting part of Azure Automation is the process automation. Azure uses runbook automation for this. This means that you can create runbooks graphically, in PowerShell or using Python. Runbooks let you deploy and manage workloads in Azure, but also on systems that you host on-premises or in other clouds, such as AWS. You can even integrate runbooks with webhooks into the monitoring systems. This can be ITSM platforms, such as ServiceNow. And, of course, Azure Automation integrates perfectly with Azure DevOps, where we can define complete DevOps projects, including CI/CD pipelines.
The key concept in runbooks is the worker that executes a specified job that we create. Workers can be shared among different resources in Azure, but they can only be assigned to one job at the time. From a trigger in CI/CD, or monitoring, the job gets started and a worker is assigned to that job. Next, it fulfills the actual runbook – for instance, applying a policy to a virtual machine.
Remember that everything in the cloud is basically an identity: in this case, the identity is a worker that is assigned to a job. That worker will need access to resources where it needs to execute the job. This means that we have to make sure that workers have the right permissions and are authenticated against Active Directory. Otherwise, the job will fail.
Tip
More information on Azure Automation and runbooks can be found at https://docs.microsoft.com/en-us/azure/automation/.
AWS OpsWorks
As with a lot of tools within AWS, OpsWorks integrates with third-party tooling. The functionality of OpsWorks is comparable to DSC with PowerShell and Azure Automation, but OpsWorks integrates with either Chef Automate or Puppet Enterprise. There's also a native service for OpsWorks that is called OpsWorks Stacks.
Stacks works with layers. A layer can be a group of virtual machines, deployed from the Elastic Compute Cloud (EC2) service in AWS. That layer will deploy the web servers or the database servers. Next, Stacks can deploy the application layer on the infrastructure. Although Stacks is a native service, it does use Chef as its underlying technology. In fact, it uses Chef's recipes to automate the deployment of layers, as well as install the applications and scripts. It also applies autoscaling, if demanded, and installs monitoring on the stacks.
OpsWorks with Chef Automate goes a step further. This service requires Chef servers in your environment that hold cookbooks. It doesn't only deploy a server stack, but it also applies configuration policies, implements access controls based on Lightweight Directory Access Protocol (LDAP) or Security Assertion Markup Language (SAML), and configures the integrations. You can define workflows for full deployments – also for containerized environments, compliance, and security checks using industry-led security frameworks, such as the one by the Center of Internet Security (CIS).
Again, Chef also works with layers. The main parts of these layers are attributes and resources. Attributes contain details on the systems that we want to install: the nodes. Chef evaluates the current state of the node and the desired state. To reach the desired state, it uses resources describing the desired state in the packages, templates, and services that it retrieves from AWS. Under the hood, Chef works with JSON and Ruby, so when working with Chef, it's advisable to have an understanding of these script languages.
Chef provides the full cloud-native menu to create an application landscape using cookbooks. It does require knowledge on how to define these cookbooks. As mentioned, we will explore this in much more detail in Chapter 18, Design Process for Test, Integration, Deployment, and Release Using CI/CD. The best part is the fact that you can use cookbooks that have been developed and tested by a community already and that can be downloaded from GitHub.
One other toolset that we can use is OpsWorks for Puppet Enterprise. In this case, we will deploy Puppet master servers that control the infrastructure in AWS. Puppet works with modules that contain the desired state for infrastructure components in AWS. With Puppet, you can, as with Chef, deploy, configure, and manage systems, whether they are in AWS using EC2 or on-premises. It will deploy the systems, install operating systems, configure databases, and enroll desired state policies, all from workflows that you can define yourself in the development kit or use from Puppet Forge, where a large community contributes to the Puppet modules.
Puppet Enterprise will be discussed in Chapter 18, Design Process for Test, Integration, Deployment, and Release Using CI/CD, in more detail too.
Tip
More information on AWS OpsWorks can be found at https://docs.aws.amazon.com/opsworks/latest/userguide/welcome.html.
Automation in Google Cloud Platform
By now, it should be clear that by abstracting environments into separate identifiable layers, it's possible to automate deployments and management of our environments. We can deploy complete application stacks and configure them with the policies that we have defined, ensuring that all these stacks are consistent and compliant. Management is also made a lot more efficient since we do have the stack as a whole, but, for instance, update parts of the stack without having to touch other components. Since it is all code, we only need to manage the code and not the underlying physical hardware, such as servers, switches, routers, computer racks, and cables. All those physical parts are taken care of by the cloud provider.
In Google Cloud Platform (GCP) (https://cloud.google.com/solutions/devops/devops-tech-deployment-automation), we have exactly the same concept as we have seen in Azure and AWS. GCP automates deployments in packages and scripts. Very simply explained, packages contain the what, while scripts contain the how. Packages hold the artifacts that have to be deployed, whereas scripts define how the packages are deployed. With scripts, the target environment in GCP is prepared by defining the project (similar to an AWS VPC or Azure vNet) where the systems will be hosted, followed by the actual deployment of the packages, and finally, test scripts are executed to make sure that the systems can be accessed and that they function as designed.
Exploring other automation tools
We discussed the native tooling that is integrated with Azure, AWS, and GCP. We also mentioned that there many more tools available on the market. Chef, Puppet, Terraform, Spinnaker – originally created at Netflix – and Ansible are just a couple of them. Keep in mind that all of these tools have strong assets, but might not always be the right tool for the goals that you have set. The saying goes that if a hammer is the only tool you have at your disposal, then every problem looks like a nail. Better said: the tool should fit your needs. It's important to review the toolset on a frequent basis. That's a team effort: allow developers and solution builders in the cloud to evaluate toolsets and have them recommend improvements.
Just look at the periodic table of DevOps tools at https://xebialabs.com/periodic-table-of-devops-tools/, which is created and maintained by Xebia Labs. It changes regularly for a good reason.
Architecting automation for multi-cloud
Automation seems like the holy grail in the cloud, but there are some major pitfalls that we should avoid. The three main reasons why automation projects in the cloud fail are as follows:
- Making automation too complex: As with anything in the cloud, you should have a plan before you start. We have to think about the layers: which components in which layer are we deploying and are these repetitive actions? Think of the easiest way to perform these actions so that they are really simple to repeat. For example, spinning up a virtual machine is very likely such a task. What would you do to create a virtual machine? You determine where the machine should land, create the machine, and next install the operating system. These are three basic steps that we can automate.
- Trying to automate everything: For instance, consider the usage of PaaS solutions. A lot of cloud-native applications use PaaS that can be triggered by just one command. The trigger to that command is something we can include in the automation script, but not the service itself. You could, perhaps, but you shouldn't: it would be too complicated. This pitfall is tightly related to the first one: making automation too complex.
- Disregarding dependencies: Automation doesn't make sense if the process fails with the first component that isn't available in the automation script. What do we mean with that? The automation script makes calls to components in the cloud environment. That's where orchestration comes in. With automation, we make calls to a number of specific services offered by cloud providers, but these calls have to be made in a particular order.
For example, if we deploy a database from an automation script, we should first provision and confirm that the database server is up and running with an operating system before we deploy the database and, at last, the actual data itself. A good practice in automation is that services can be automated independently so that they don't crash if another component is not available. If an automation script that deploys a database doesn't find a virtual machine to instantiate, it should simply hold and wait for the server to come online, and not proceed to the installation of the database. This phenomenon is called lock-step.
So, how do we start? The answer to that question is with version control. We can't start automating if we don't have a repository where we have our code stored in a logical way. That starts with the source code, but all the iterations to all the different components – files – to the code need to be filed in a repository that is shared and accessible to everyone who's working with it. This not only ensures that the code can be reused and improved upon in every iteration but also that it can be traced who changed the code and how it has changed. In the case of system failure, we can trace the changes back in the versions that we have at the time of failure.
For version control, we can use Git, but there are more tools available, such as Subversion. The thing that really matters is that we have to bring all the code under version control. From the following list, you will definitively recognize the different abstracted layers:
- Application code.
- Runtime scripts.
- Deployment scripts for any building block in the environment. These can be image building scripts, as well as Chef recipes or Puppet modules.
- Buildpacks for containers.
- Scripts for the packaging and provisioning of components, such as databases, and in the case of containerization, Kubernetes nodes and pods.
- Configuration files for the desired state, such as AWS CloudFormation files, Azure DSC, and Terraform files.
- Configuration files for the core and boundary, such as firewall configuration settings and DNS parameter files.
From the source code and version control, we will design the automation process. If we have done a proper job in layering and versioning, then we can work from three categories to start designing the automation:
- Application code
- System configuration
- Application configuration
From the application, we define what resources we need in the systems layer. Then, we create the flow to configure the systems to the desired state so that they are ready to run the application code. Let's take a simple web application as an example, containing a web server, application server, and a database for which we're using a PaaS service. How would we automate the deployment of this stack? In the following diagram, a more detailed workflow for this is presented, adjacent to the workflow in Figure 8.3:
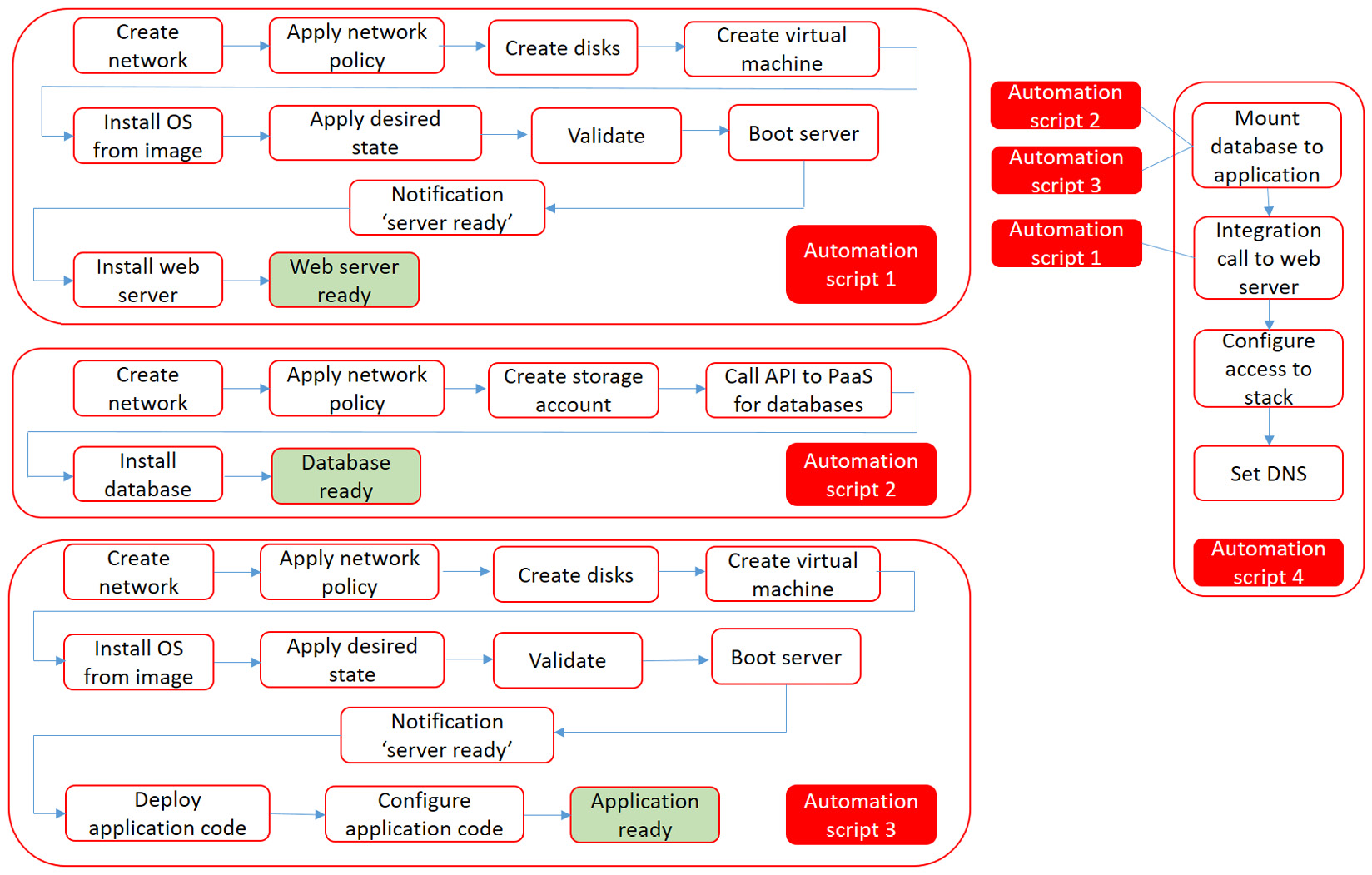
Figure 8.4 – Script design for automating an application with a database on PaaS and a web server
In Chapter 1, Introduction to Multi-Cloud, we introduced the 12-factor app. The 12-factor app is truly automated. The first of the 12 factors is the code base: the single repository where we will have all the code stored. The second factor is about making sure that components have very clear – explicit – descriptions of dependencies. The third factor is about configuration: configuration is strictly separated from the application code itself. There we have our layers once more.
Summary
In this chapter, we have discussed the basic principles of automation. We have learned how to abstract our environment in different layers: applications, systems, and configurations. We have studied tools that enable automation in Azure, AWS, and GCP, as well as found that there are many more tools that we can use to automate deployment and management of systems in multi-cloud environments. We have learned how to start designing the automation process and that version control is crucial in automation.
Now, if we have deployed our systems, we want to keep a close eye on them. That's what the next chapter is all about: monitoring and management.
Questions
- In what layer would CPUs be if we abstract the data center into layers?
- AWS OpsWorks has two options to integrate with configuration management. Can you name them?
- True or false: version control is crucial in automation.
Further reading
As well as the links that we have mentioned in this chapter, check out the following books for more information on the topics that we have covered:
- VMware Cross-Cloud Architecture by Ajit Pratap Kundan, Packt Publishing
- Blog post by Tim Warner on DSC (https://4sysops.com/archives/powershell-desired-state-configuration-dsc-part-1-introduction/)
- The principles of the 12-factor app: https://12factor.net/