
Chapter 11: Defining Principles for Resource Provisioning and Consumption
Cost control starts with guidelines and principles on when and what type of resources may be deployed and by whom. The way resources are deployed in different cloud platforms is different and needs alignment when an enterprise has adopted a multi-cloud strategy. In this chapter, we will discover that resource planning should be a part of our architecture. We need to define what type of resources we are planning to provision and how we can deploy them using the different methods that Azure, AWS, and Google Cloud Platform (GCP) provide.
We will also learn how we can set budgets in our environment and how cost alerts can be set when budget thresholds are met. We will have a look at the tools that the public clouds provide in terms of cost control and management.
In this chapter, we're going to cover the following main topics:
- Avoiding Amex Armageddon with unlimited budgets
- The provisioning and consumption of resources in public cloud platforms
- The provisioning and consumption of resources in on-premises systems
- Setting guidelines and principles for provisioning and consumption
- Controlling resource consumption using cost alerts
Avoiding Amex Armageddon with unlimited budgets
The term Amex Armageddon will not be familiar to you. It's a term I use when I see companies starting off in the public cloud. Very often, companies, even big ones, begin deploying resources in the public cloud without a plan. Someone simply opens an account, gets a subscription, fills in some credit card details, and starts. Often, the resources go unmonitored and don't adhere to the organization mandates, more commonly known as shadow IT. That's alright if you're a developer who wants to try out things on a Saturday afternoon, but it's certainly not OK if you're working for a company. It's the reason why Azure, AWS, and GCP have developed Cloud Adoption Frameworks (CAFs).
If you're moving a company to a public cloud, you're basically building a data center in Azure, AWS, GCP, or any other cloud. The only difference is that this data center is completely software-defined. But as with a physical data center, the virtual data center in a public cloud costs money. If you're working without a plan, it will cost you more money than necessary and probably also more than keeping applications in the physical data center. That's what I call Amex Armageddon.
We can avoid this by having a plan—in most cases, by following CAFs that provide guidelines to set up a business in the public cloud, which is covered in Chapter 1, Introduction to Multi-Cloud, Chapter 2, Business Acceleration Using a Multi-Cloud Strategy, and Chapter 3, Getting Connected – Designing Connectivity. Part of the plan is also to select the type of resources that you will have to provision in the cloud environment. Will you only use Virtual Machines (VMs) or are you planning to use other services as well? If you're only deploying VMs, what type of applications are you planning to host?
If you're only hosting a website, then there's no need to have an option to deploy big machines with lots of memory. But if you're planning to host an in-memory Enterprise Resource Planning (ERP) system, such as SAP HANA, then you will very likely need big machines with as much as 32 GB or more of memory. The point is that it makes sense to have a plan, worked out in an architecture.
In this chapter, we will first look at the different types of resources in the public cloud and how we can provision them while keeping track of costs. One method to do that is by setting budgets and defining, per the architecture, what resources we will be deploying in our cloud environment.
The provisioning and consumption of resources in public cloud platforms
Before we dive into cost control in the provisioning of resources, we need to understand how resource provisioning works in the public cloud. There are lots of different ways to do this, but for this chapter, we will stick with the native provisioning tools that Azure, AWS, and GCP provide.
There are basically two types of provisioning:
- Self-provisioning
- Dynamic
Typically, we start with self-provisioning through the portal or web interface of a cloud provider. The customer chooses the resources that are needed in the portal. After confirmation that these resources may be deployed in the cloud environment, the resources are spun up and made available for usage by the provider.
The resources are billed by hour or minute unless there is a contract for reserved instances. Reserved instances are contracted for a longer period—1, 3, or 5 years. The customer is guaranteed availability, capacity, and usage of the pre-purchased reserved instances. The benefit of reserved instances can be that cloud providers offer discounts on these resources. Over a longer period, this may be very cost-efficient. It's a good way to set budget control: a company will know exactly what the costs will be for that period. However, it's less flexible than a pay-as-you-go model and, even more important, it requires up-front payments or investments.
Dynamic provisioning is more of an automated process. An example is a web server that experiences a spike in load. When we allow automatic scale-out or scale-up of this web server, the cloud provider will automatically deploy more resources to that web server or pool. These extra resources will also be billed on a pay-as-you-go rate.
Now, let's take a look at how these resources are deployed.
Deploying resources in Azure using ARM
Azure works with Azure Resource Manager (ARM). This is a service that handles requests from users and makes sure that the requests are fulfilled. That request is sent to ARM. Next, ARM executes all the actions to actually deploy the VM. What it does is assign memory, the processor, and disks to a VM and makes it available to the user. ARM can do this with all types of resources in Azure: VMs, storage accounts, web apps, databases, virtual network resource groups, subscriptions, management groups, and tags.
ARM can be directly accessed from the portal. However, most developers will be working with PowerShell or the Command-Line Interface (CLI). In that case, the request goes to a SDK, a software development kit. SDKs are libraries with scripts and code templates that can be called through a command in PowerShell or the CLI. From the SDK, the resources are deployed in ARM. The following diagram shows the high-level conceptualization for ARM:
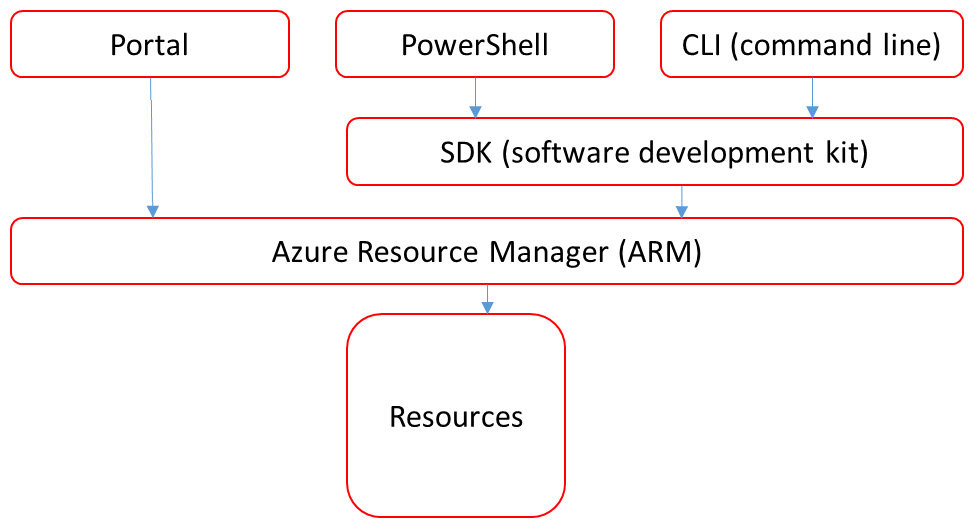
Figure 11.1 – High-level concept for ARM
In the next section, we will learn how we can deploy resources in AWS.
Deploying resources in AWS using OpsWorks
AWS has AWS OpsWorks Stacks for the deployment of resources. It works with a cookbook repository—a term that AWS borrowed from Chef. That makes sense since under the hood, Stacks works with Chef. We've had a deeper look at Stacks in Chapter 8, Defining Automation Tools and Processes.
The stack itself is the core component for any deployment in AWS; it's the construct that holds the different resources, such as EC2, VMs, and Amazon RDS (short for Relational Database Services) database instances. OpsWorks makes sure that these resources are grouped together in a logical way and deployed as that logical group—we call this the cookbook or recipe.
It's important to remember that Stacks work in layers. The first layer is the Elastic Load Balancing (ELB) layer, which holds the load balancer. The next layer hosts the VMs, the actual servers that are deployed from EC2. The third layer is the database layer. If the stack is deployed, you can add the application from a different repository. OpsWorks can do this automatically as soon as the servers and databases are deployed, or it can be done manually.
The following diagram shows the conceptualization of an OpsWorks stack:

Figure 11.2 – High-level overview of an OpsWorks stack in AWS
The last cloud that we will discuss is GCP. In the next section, we will look at Google's Deployment Manager.
Deploying resources in GCP using Deployment Manager
In GCP, the native programmatic deployment mechanism is Deployment Manager. We can create resources and group them logically together in a deployment. For instance, we can create VMs and a database and have them as one code file in a deployment. However, it does take some programming skills to work with Deployment Manager. To start, you will need to have the gcloud command-line tool installed. Next, create or select a GCP project. Lastly, resources are defined in a deployment coded in YAML. When the deployment is ready, we can actually deploy it to our project in GCP using gcloud deployment –manager.
As said, it does take some programming skills. Deployment Manager works with YAML files in which we specify the resource:
- Machine type: A set of predefined VM resources from the GCP gallery
- Image family: The operating system
- Zone: The zone in GCP where the resource will be deployed
- Root persistent disk: Specifies the boot sequence of the resource
- IP address
This information is stored in a vm.yaml file that is deployed by Deployment Manager.
Benefits of cloud provisioning
The major benefit of cloud provisioning is that an organization doesn't need to make large investments in on-premises infrastructure. In the public cloud, it can deploy and scale resources whenever needed and pay for these resources as long the organization uses it. If it doesn't use the resources, it will not receive an invoice—unless a company has contracted reserved instances.
Another advantage of cloud provisioning is the agility and speed of deployment. Developers can easily deploy resources, within a few minutes. But that's a budget risk at the same time. With on-premises investments, a company knows exactly what the costs will be over a certain period: the investment itself and depreciation are a given. The cloud works differently, but an organization needs to be able to forecast the costs and control them.
A way to do this is by tagging resources. Tags allow a company to organize the resources in its cloud environment in a logical way, so they can easily be identified. By grouping resources using tags, it's also easy to see what costs are related to these resources and to which department or company division these costs should be transferred to. Defining and using tags will be explained in the next chapter, Chapter 12, Defining Naming Convention and Asset Tagging Standards.
We have discussed the various methods to deploy resources in the major clouds: Azure, AWS, and GCP. But in multi-cloud, we might also have on-premises environments. In the next section, we will elaborate on these on-premises resources.
The provisioning and consumption of resources in on-premises propositions
We are talking about multi-cloud in this book. In Chapter 1, Introduction to Multi-Cloud, we defined that the cloud could involve public clouds such as Azure, AWS, and GCP, but also private clouds. In most cases, private clouds are still on-premises environments that take a significant investment. Companies use private clouds for different reasons, the most important one being compliancy—data and systems that aren't allowed to be moved to a public cloud.
The challenge with private clouds is that companies have to make major up-front investments to get hardware that enables the setup of a private cloud. They don't want to overspend by way of too much hardware, but they also don't want to be confronted with capacity limits on their hardware. Forecasting and capacity management are really crucial in terms of cost control on private clouds, even more so than in public clouds.
One of the advantages of deploying resources to public clouds is that a lot of stuff is taken care of by the cloud provider. If we deploy a VM in Azure or AWS through portals or other interfaces, the platforms guide you through the complete setup, and most of the activities are automated from the start. In private environments, this works differently; we have to account for networking and connecting storage.
How do we get the most out of our private clouds and how do we control costs when we provision workloads to these environments? If the whole private cloud is paid by one single entity and costs are not allocated to divisions or groups within the company, then there's no driver to keep track of costs, perhaps. However, most companies do allocate costs to different divisions.
Virtualization of the whole environment does help. That's where VMware comes in as the most important enterprise player in the field. They realized that in order to control a fully private environment, including networks and storage, you would need to virtualize it so that it would be easy to define who consumes what in the private cloud, making cost allocation possible. So, VMware doesn't just virtualize compute resources with vSphere, but also storage with vSAN and networks with NSX.
So, VMware introduced Cloud Foundation for the configuration of compute, storage, networks, security, and management. It's a deployment and management console for full deployments of private clouds running VMware, as well as for public clouds. To enable this, it uses Hyperconverged Infrastructure (HCI). HCI is hardware that comprises compute, storage, and networking devices in one single stack or machine.
There are more on-premises propositions that we might want to consider; Azure Stack, AWS Outposts, and Google Anthos are examples. These on-premises systems are managed through the consoles of the related public platforms. Take notice of the fact that Google Anthos is really a container-hosting platform, using Google Kubernetes Engine. Azure Stack and AWS Outposts are really extensions of the respective public cloud platforms and offer hybrid, on-premises infrastructure with the services that you can get from the Azure and AWS public clouds.
Setting guidelines and principles for provisioning and consumption
This chapter is about keeping control of costs while provisioning resources to cloud environments. Let's start with saying that the sky is the limit in these clouds, but unfortunately, most companies do have limits to their budgets. So, we will need to set principles and guidelines and what divisions or developers are allowed to consume in the cloud environments, to avoid budgets being overrun.
To be able to set these guidelines and principles, we need to understand what these public clouds have to offer. Let's have a look at Azure first.
Using the Azure pricing calculator
It's easy to get an overview of what a VM would cost us in Azure: the pricing overview on https://azure.microsoft.com/en-us/pricing/calculator/ is a very handy tool for this.
If we open the page, we can look at the Virtual Machines tab, as shown in the following screenshot:
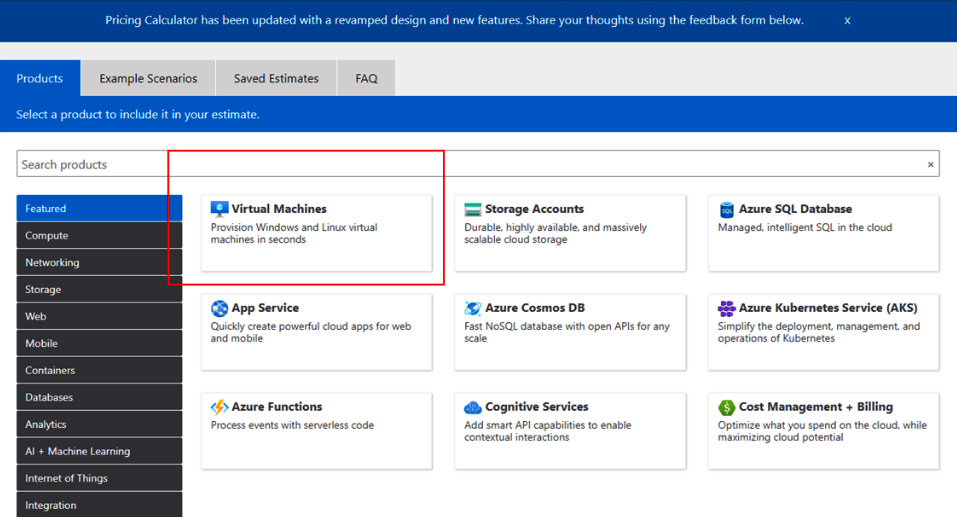
Figure 11.3 – The Virtual Machines tab in the Azure pricing calculator
The portal will display all the possible choices that are offered in terms of VMs, as shown in the following screenshot:
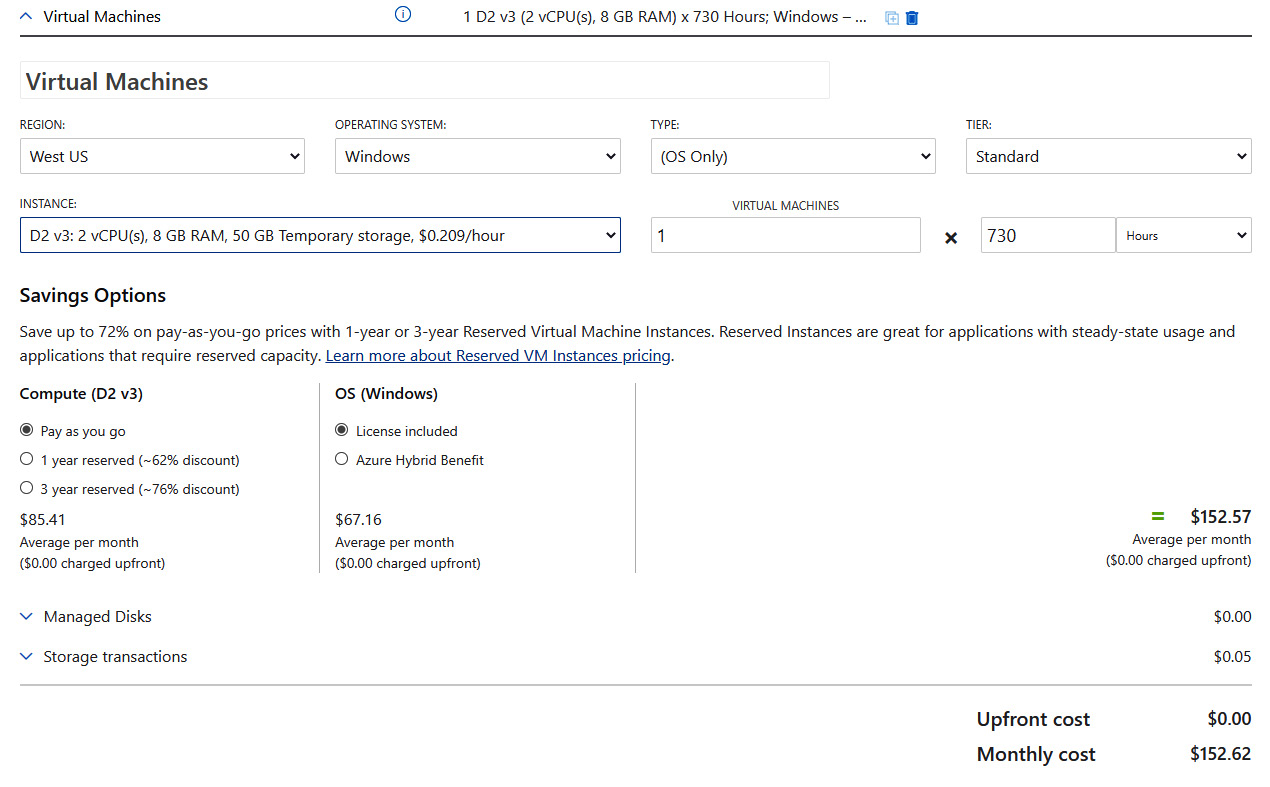
Figure 11.4 – Tab details for VMs in the Azure pricing calculator
In the screenshot, the D2 v3 VM has been selected. This is a standard VM with two virtual CPUs and 8 GB of memory. It also comes with 50 GB of ephemeral storage. We can also see that it will be deployed in the West US Azure region, running Windows as the operating system. We purchase it for 1 month, or 730 hours, but under the condition of Pay as you go—so we will only be charged for the time that this VM is really up and running. For the full month, this VM will cost us US$152.62.
We could also buy the machine as a reserved instance, for 1 or 3 years. In that case, the VM cost would be reduced by 62% for 1 year and 76% with a 3-year commitment. The reason Azure does this is that reserved instances mean guaranteed revenue for a longer period of time.
The D2 v3 is a general-purpose machine, but the drop-down list contains well over 130 different types of VMs, grouped in various series. The D-series are for common use. The drop-down list starts with the A-series, which are basic VMs mainly meant for development and testing. To run a heavy workload such as an SAP HANA in-memory database, an E-series VM would be more appropriate. The E64s v4 has 64 vCPUs and 500 GB of memory, which would cost around US$5,000/month. It makes sense to have this type of VM as a reserved instance.
Using the AWS calculator
The same exercise can be done in AWS, using the calculator on https://calculator.aws/#/. By clicking Create an estimate, the following page is shown. Next, select Amazon EC2 as the service for creating VMs:

Figure 11.5 – Tab for EC2 VMs in the AWS pricing calculator
By clicking on that tab, a similar screen is displayed as in Azure. There is, however, one major difference. In Azure, the VM machine type is also taken into account
It can be done in AWS, too; the requirements of the machine can be specified by indicating how many vCPUs and how much memory a machine should have. AWS will next decide what type of VM fits the requirements. The following example shows the requirements for a machine with two vCPUs and 8 GB of memory. AWS has defined t3a.large—t3a being a specific instance size—as a suitable machine:
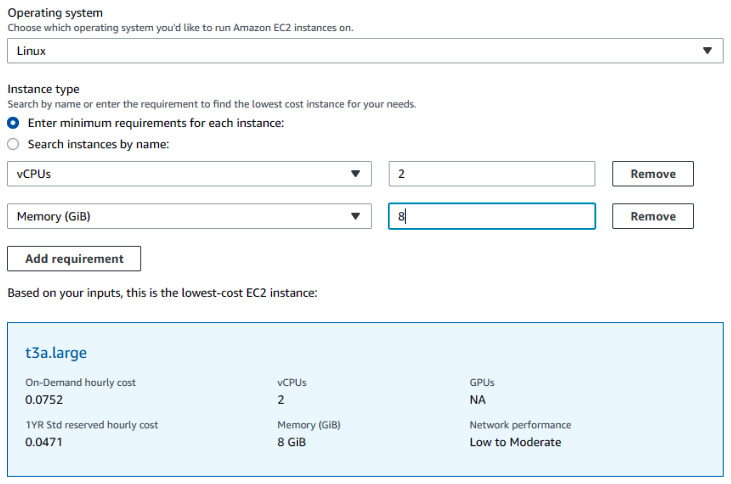
Figure 11.6 – Defining specifications for a VM in the AWS pricing calculator
The next decision to make is regarding the cloud strategy. AWS offers on-demand and reserved instances for 1 and 3 years, with the possibility of no, partial, or full up-front payments. With a relatively small VM such as our example, payment wouldn't become an issue, but also, AWS offers some huge instances of up to 64 vCPUs and up to 1 TB of memory, which would cost some serious money.
That's the reason for having guidelines and principles for provisioning. We don't want a developer being able just to click a very heavy machine with high costs, without knowing it or having validated a business case for using this machine; especially since the VM is only one of the components: storage and networking also need to be taken into consideration. Costs could easily rise to high levels.
It starts with the business and the use case. What will be the purpose of the environment? The purpose is defined by the business case. For example: if the business needs a tool to study maps geographic information systems, then software that views and works with maps would be needed. To host the maps and enable processing, the use case will define the need for machines with strong graphical power. Systems with Graphics Processing Units (GPUs) will fit best. In Azure, that would be the N-series; these machines have GPUs and are designed for that task. The equivalent in AWS is the G- and P-series, and in GCP, we can add NVIDIA Tesla GPUs to Compute Engine instances.
Using the GCP instance pricing
GCP doesn't really differentiate from Azure and AWS. GCP has a full catalog of predefined instances that can deployed to a GCP project. The E2 instances are the standard machines, while the M-series is specially designed for heavy workloads with in-memory features, running up to and over 1 TB of memory. Details on the GCP catalog can be found on https://cloud.google.com/compute/vm-instance-pricing. And obviously, GCP has a calculator too. In the following screenshot, we've ordered a standard E2 instance with a free Linux operating system:
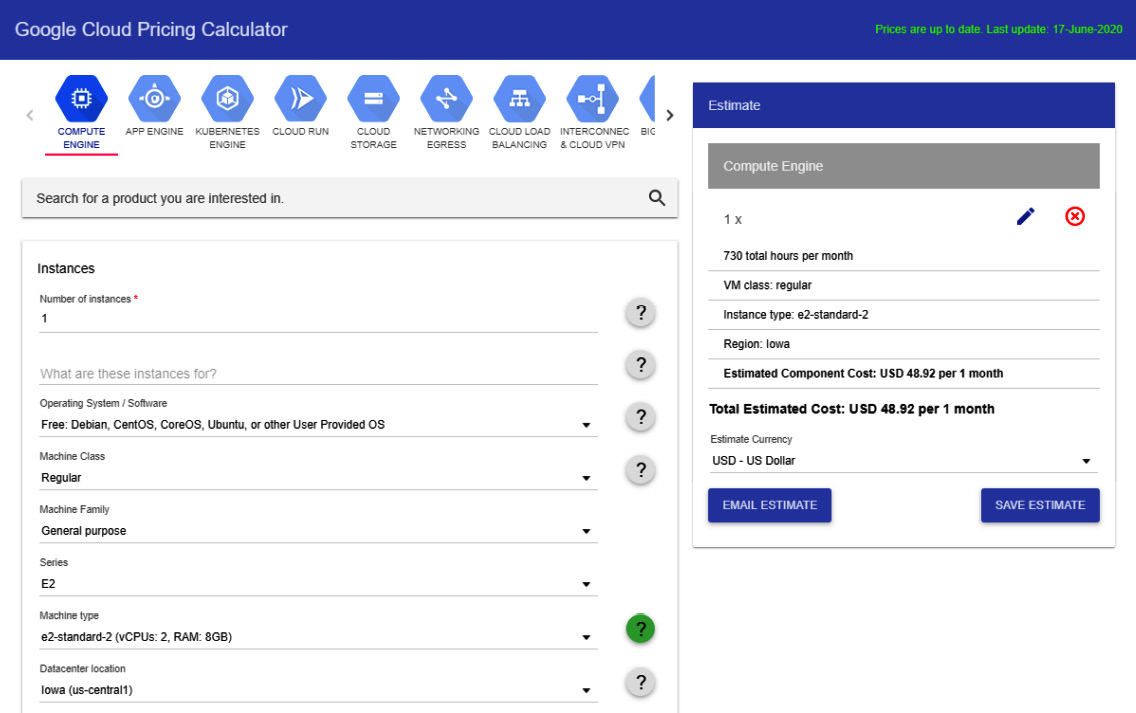
Figure 11.7 – Defining specifications for a VM in the GCP pricing calculator
The pricing calculator for GCP can be accessed at https://cloud.google.com/products/calculator.
So far, we have looked at the major cloud platforms and how to purchase and provision VMs to the cloud environments. The next question is: how do we define what is really needed and how do we make sure that we're only provisioning the things that we need, in order to stay in control of costs. That's what the next section is about.
Design example for resource planning
In the architecture, we can define a principle for the type of VMs that are allowed for deployment. The following example is taken from a design document and contains the guidelines for the usage of VMs in an Azure production environment. In this case, the business case only foresees the use of development VMs and standard production VMs in Azure. Without the need for very heavy workloads, a maximum of 16 vCPUs is sufficient:

How do we make sure that only these types are actually deployed? The answer is through policies such as the following:
- In the case of Azure, the use of the ARM policy to restrict access to resources that aren't to be deployed in the environment or to limit the sizes of VMs that can be provisioned. This is besides the fact that in all cases, usage of naming and tagging should be enforced, as we will explore in the next chapter.
In order to enforce that only certain types of resources can be deployed in Azure, we can create a JSON file that lists the exact specifications of the VMs that have been allowed for provisioning. That file is attached to a policy that next can be applied to a specific Azure subscription or even a resource group. The policy itself is relatively easy: it simply states that if someone issues a request to provision a VM that doesn't match the specifications of the machines that are allowed, then the request gets denied and the VM will not be provisioned.
- In AWS, we can use CodeDeploy. CodeDeploy specifies a workflow to deploy applications to AWS that utilize EX2 VMs. Provisioning the instances is part of the workflow in CodeDeploy. By specifying a deployment group, the type of instances can be provisioned.
Tags can also be applied to these instances. To define the instances, we can work with CloudFormation and regular expressions. An expression contains a parameter, and in this case, this should be a parameter that specifies a certain instance type, InstanceTypeParameter. Parameters can be defined in JSON or YAML. AWS allows 60 parameters in one CloudFormation template.
- In Google, instance templates are created to define and enforce the use of specific VM types. To deploy multiple instances, we can add instance templates to a Managed Instance Group (MIG), but the instance template can also be used for individual instances.
In this section, we talked about VMs as the main type of resource in our cloud environments. One thing we haven't touched on so far is the provisioning of containers. All clouds will offer possibilities to run containers on VMs. The container will hold the application and the libraries, packed in a Docker image.
Next, we will create a VM with a container-optimized operating system. This is a requirement since we will need Docker runtime on our VM to start the container. However, this is not very efficient. If we want to run multiple containers on a VM, we need a container runtime environment, typically Kubernetes. All of the platforms provide Kubernetes runtime services that enable the deployment of containers.
Controlling resource consumption using cost alerts
In the previous sections, we discussed how we can provision resources—VMs—to our cloud environments and learned why it's important that we have control over what resources teams or developers can deploy, mainly because we have to stay in control of costs. The cloud is agile and flexible, but it doesn't come for free.
How do we keep track of costs? All cloud providers have dashboards that show exactly how much resource consumption will cost. That's a reactive approach, which can be fine. But if we want to force teams and developers to stay within budgets, we can set credit caps on subscriptions and have alerts raised as soon the cap is reached. The different ways to set caps in Azure, AWS, and GCP are listed in the following overview:
- In Azure, we can set budgets and alerts. Both services are part of the Cost Management module in Azure. We can set budgets for specific services for a certain amount of time. Azure evaluates costs against the set budgets every 4 hours. We can also allow Azure to send email notifications as soon as budget limits are met.
For this, we use cost alerts. Like budgets, these alerts can be defined through the Azure portal or with the Azure Consumption API. The latter enables programmatic access to retrieve data on consumption and generated costs. Since the API is available in various formats, such as Python and Node.js, it can integrate with service management tooling.
- AWS also offers the possibility to set budgets and generate cost alerts. Budgets are set in the AWS Budgets dashboard, which is accessed through the AWS console. We can create budgets for almost any timeframe and link them to a large variety of AWS services. Budget alerts are sent through email or by using Amazon's Simple Notification Service (SNS).
To set cost or billing alerts, we can use the native monitoring service of AWS: CloudWatch. It calculates the costs several times per day, against the worldwide valid charges. In order to get alerts, we need to specify a threshold to the charged amount. As soon as this threshold is hit, the alarm will be triggered.
- And, of course, in GCP, we can set budgets and cost alerts too. Google offers Cloud Billing budgets. As in AWS, we set a threshold. Exceeding the threshold will trigger alerts, sending an email to every contact that has a billing role in GCP. That probably needs some explanation: a user in GCP can have a billing role, next to any other role that they have as an admin. In the Google console, it's specified in roles/billing.admin or roles/billing.user. Next to these users, we can customize the recipients of these alerts. For instance, we can add project managers so that they receive cost alerts for their projects directly from Cloud Billing.
Deploying resources to clouds means that we generate costs. An enterprise needs to be able to keep track of those costs. In this section, we provided tips and tools to enable cost management.
Summary
In this chapter, we discussed various ways of how we can provision workloads to the different cloud platforms: Azure, AWS, and Google Cloud. It's recommended to decide what type of resources we plan to deploy before we actually start building our environment. We've seen that cloud providers offer a wide variety of resources—from simple, low-cost development VMs to heavy workloads with lots of memory—for use, such as in-memory databases. In order to stay in control of costs, it's wise to define what we really need and enforce it by policies that only allow those resources to be deployed. That's what is referred to as resource planning and should be part of the multi-cloud architecture.
We have also learned how we can set budgets and cost alerts in the cloud platforms. All major cloud providers allow us to set budgets on time and type of resources consumed. Next, we can set triggers as soon as budget thresholds are met and get notified by email when this happens.
It's important to remember to apply a naming convention and tagging to keep track of resources. In the next chapter, we will explore the naming and tagging best practices in the cloud platforms.
Questions
- If we plan to provision resources to an environment in Azure, what management layer makes sure that these resources are actually deployed?
- A popular trend in on-premises private clouds is hardware that comprises compute, storage, and networking in one single stack. What do we call this type of hardware?
- In all clouds, we can specify what type of resources we want to deploy, using policies or templates. What specific solution would you recommend in AWS?
- Rate the following statement true or false: In order to receive cost alerts from GCP, you need to have the billing role.
Further reading
- VMware Cross-Cloud Architecture by Ajit Pratap Kundan, Packt Publishing
- An article by Larry Dignan, ZDNet: https://www.zdnet.com/article/cloud-cost-control-becoming-a-leading-issue-for-businesses/
- Documentation on how to use ARM: https://docs.microsoft.com/en-us/azure/azure-resource-manager/management/overview
- Documentation about working with OpsWorks in AWS: https://docs.aws.amazon.com/opsworks/latest/userguide/welcome_classic.html
- Documentation about working with Deployment Manager in GCP: https://cloud.google.com/deployment-manager/docs/
- Documentation on cost control and billing in Azure: https://docs.microsoft.com/nl-nl/azure/cost-management-billing/costs/cost-mgt-alerts-monitor-usage-spending
- Documentation on cost control and billing in AWS: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/monitor_estimated_charges_with_cloudwatch.html, documentation on cost and budget control in AWS
- Documentation on cost control and budgets in GCP: https://cloud.google.com/billing/docs/how-to/budgets, documentation on cost and budget control in GCP