
Chapter 1. Introduction
Computers used to be much simpler. That’s not to say they were easy to use or write code for, but conceptually there was a lot less to work with. PCs in the 1980s typically had a single 8-bit CPU core, and not a whole lot of memory. You typically could only run a single program at one time. What we think of these days as operating systems would not even be running at the same time as the program the user was interacting with.
Eventually, people wanted to run more than one program at once, and multitasking was born. This allowed operating systems to run several programs at the same time by switching execution between them. Programs could decide when it would be an appropriate time to let another program run by yielding execution to the operating system. This approach is called cooperative multitasking.
In a cooperative multitasking environment, when a program fails to yield execution for any reason, no other program can continue executing. This interruption to other programs is not desirable, so eventually operating systems moved toward preemptive multitasking. In this model, the operating system would determine which program would run on the CPU at which time, using its own notion of scheduling, rather than relying on the programs themselves to be the sole deciders of when to switch execution. To this day, almost every operating system uses this approach, even on multi-core systems, because we generally have more programs running that we have CPU cores.
Running multiple tasks at once is extremely useful for both programmers and users. Before threads, a single program (that is, a single process) could not have multiple tasks running at the same time. Instead, programmers wishing to perform tasks concurrently would either have to split up the task into smaller chunks and schedule them inside the process, or run separate tasks in separate processes and have them communicate with each other.
Even today, in some high-level languages the appropriate way to run multiple tasks at once is to run additional processes. In some languages, like Ruby and Python, there’s a global interpreter lock (GIL), meaning only one thread can be executing at a given time. While this makes memory management far more practical, it makes multithreaded programming not as attractive to programmers, and instead multiple processes are employed.
Until fairly recently, JavaScript was a language where the only multitasking mechanisms available were splitting tasks up and scheduling their pieces for later execution, and in the case of Node.js, running additional processes. We’d typically break code up into asynchronous units using callbacks or Promises. A typical chunk of code written in this manner might look something like Example 1-1, breaking up the operations by callbacks or await.
Example 1-1. A typical chunk of asynchronous code, using two different patterns.
readFile(filename,(data)=>{doSomethingWithData(data,(modifiedData)=>{writeFile(modifiedData,()=>{console.log('done');});});});// orconstdata=awaitreadFile(filename);constmodifiedData=awaitdoSomethingWithData(data);awaitwriteFile(filename);console.log('done');
Today, in all major JavaScript environments, we have access to threads, and unlike Ruby and Python, we don’t have a GIL making them effectively useless for performing CPU-intensive tasks. Instead, other trade-offs are made, like not sharing JavaScript objects across threads (at least not directly). Still, threads are useful to JavaScript developers for cordoning off CPU-intensive tasks. In the browser, there are also special-purpose threads that have feature sets available to them that are different from the main thread. The details of how we can do this are the topics of later chapters, but to give you an idea, spawning a new thread and handling a message in a browser can be as simple as Example 1-2.
Example 1-2. Spawning a browser thread.
constworker=newWorker('worker.js');worker.postMessage('Hello, world');// worker.jsself.onmessage=(msg)=>console.log(msg.data);
The purpose of this book is to explore and explain JavaScript threads as a programming concept and tool. You’ll learn how to use them, and more importantly, when to use them. Not every problem needs to be solved with threads. Not even every CPU-intensive problem needs to be solved with threads. It’s the job of software developers to evaluate problems and tools to determine the most appropriate solutions. The aim here is to give you another tool, and enough knowledge around it to know when to use it and how.
What Are Threads?
In all modern operating systems, all units of execution outside the kernel are organized into processes and threads. Developers can use processes and threads, and communication between them, to add concurrency to a project. On systems with multiple CPU cores, this also means adding parallelism.
When you execute a program, such as Node.js or a code editor, you’re initiating a process. This means that code is loaded into a memory space unique to that process, and no other memory space can be addressed by the program without either asking the kernel for more memory, or for a different memory space to be mapped in. Without adding threads or additional processes, only one instruction is executed at a time, in the appropriate order as prescribed by the program code. If you’re unfamiliar, you can think of instructions as a single unit of code, like a line of code. (In fact, an instruction generally corresponds to one line in your processor’s assembly code!)
A program may spawn additional processes, which have their own memory space. These processes do not share memory (unless it’s mapped in via additional system calls), and have their own instruction pointers, meaning each one can be executing a different instruction at the same time. If the processes are being executed on the same core, the processor may switch back and forth between processes, temporarily stopping execution for that one process while another one executes.
A process may also spawn threads, rather than full-blown processes. A thread is just like a process, except that it shares memory space with the process that it belongs to. A process can have many threads, and each one has its own instruction pointer. All the same properties about execution of processes apply to threads as well. Because they share a memory space, it’s easy to share program code and other values between threads. This makes them more valuable than processes for adding concurrency to programs, but at the cost of some complexity in programming, which we’ll cover later on in this book.
A typical way to take advantage of threads is to offload CPU-intensive work, like mathematical operations, to an additional thread or pool of threads while the main thread is free to interact externally with the user or other programs by checking for new interactions inside an infinite loop. Many classic web server programs, such as Apache, use a system like this in order to handle large loads of HTTP requests. This might end up looking something like Figure 1-1. In this model, HTTP request data is passed to a worker thread for processing, and then when the response is ready, it’s handed back to the main thread to be returned back to the user agent.
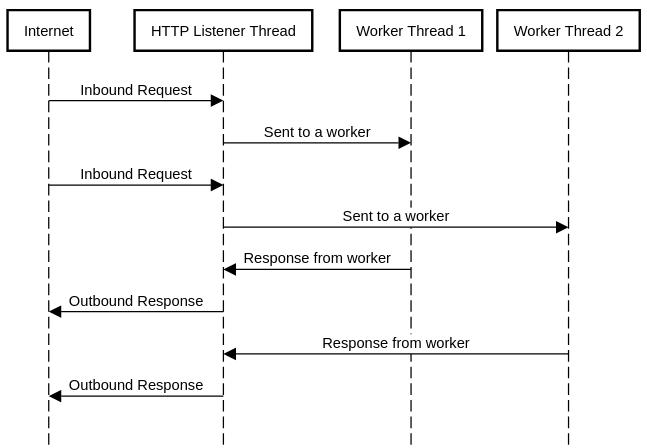
Figure 1-1. Worker threads as they might be used in an HTTP server.
In order for threads to be useful, they need to be able to coordinate with each other. This means they have to be able to do things like wait for things to happen on other threads, and get data from them. As discussed, we have a shared memory space between threads, and with some other basic primitives, systems for passing messages between threads can be constructed. In many cases, these sorts of constructs are available at the language or platform level.
Concurrency vs. Parallelism
It’s important to distinguish between concurrency and parallelism, since they’ll come up fairly often when programming in a multithreaded manner. These are very related terms, and can mean very similar things depending on the circumstances. Let’s start with some definitions.
- Concurrency
-
Tasks are run in overlapping time.
- Parallelism
-
Tasks are run at exactly the same time.
While it may seem like these mean the same thing, consider that tasks may be broken up into smaller parts and then interleaved. In this case, concurrency can be achieved without parallelism, since the time-frames that the tasks run in can be overlapped. For tasks to be running with parallelism, they must be running at exactly the same time. Generally, this means they must be running on separate CPU cores at exactly the same time.
Consider Figure 1-2. In it, we have two tasks running being run in parallel and concurrently. In the concurrent case, only one task is being executed at a given time, but throughout the entire period, execution switched between the two tasks. This means they’re running in overlapping time, so it fits the definition of concurrency. In the parallel case, both tasks are executing simultaneously, so they’re running in parallel. Since they’re also running in an overlapping time period, they’re also running concurrently. Parallelism is a subset of concurrency.
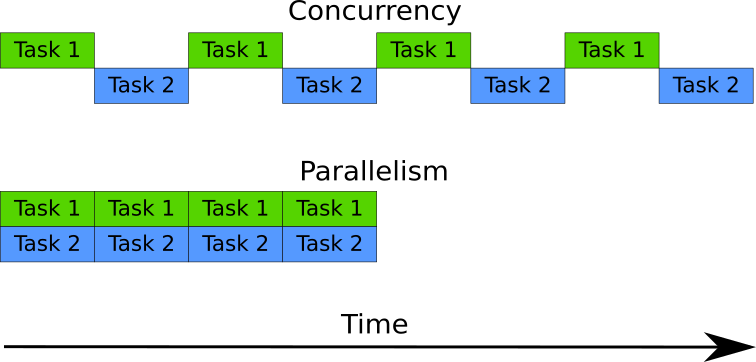
Figure 1-2. Concurrency v.s. Parallelism.
Threads do not automatically provide parallelism. The system hardware must allow for this by having multiple CPU cores, and the operating system scheduler must decide to run the threads on separate CPU cores. On single-core systems, or systems with more threads running than CPU cores, multiple threads may be run on a single CPU concurrently by switching between them at appropriate times. Also, in languages with a GIL like Ruby and Python, threads are explicitly prevented from offering parallelism because only one instruction can be executed at a time throughout the entire runtime.
It’s important to also think about this in terms of timing, since threads are typically added to a program to increase performance. If your system is only allowing for concurrency, due to only having a single CPU core available, or being already loaded with other tasks, then there may not be any perceived benefit to using extra threads. In fact, the overhead of synchronization and context-switching between the threads may end up making the program perform even worse. Always measure the performance of your application under the conditions it’s expected to run in. That way you can verify whether a multithreaded programming model will actually be beneficial to you.
Single-Threaded JavaScript
Historically, the platforms that JavaScript ran on did not provide any thread support, so the language was thought of as single-threaded. Whenever you hear someone say that JavaScript is single-threaded, they’re referring to this historical background and the programming style that it naturally lent itself to. It’s true though, that despite the title of this book, the language itself does not have any built-in functionality to create threads. This shouldn’t be that much of a surprise, because it also doesn’t have any built-in functionality to interact with the network, devices, file system, or make any system calls. Indeed, even such basics as setTimeout() aren’t actually JavaScript features. Instead environments the VM is embedded in, such as Node.js or browsers, provide these via environment-specific APIs.
Instead of threads as a concurrency primitive, most JavaScript code is written in an event-oriented manner operating on a single execution thread. As various events like user interactions or I/O happen, they trigger the execution of functions previously set to run upon these events. These functions are typically called callbacks and are at the core of how asynchronous programming is done in Node.js and the browser. Even in promises or the async/await syntax, callbacks are the underlying primitive. It’s important to recognize that callbacks are not running in parallel, or alongside any other code. When code in a callback is running, that’s the only code that’s currently running. Put another way, only one call stack is active at any given time.
It’s often easy to think of operations happening in parallel, when in fact they’re happening concurrently. For example, imagine you want to open three files containing numbers, named 1.txt, 2.txt, and 3.txt, and then add up the results and print them. In Node.js, you might do something like Example 1-3.
Example 1-3. Reading from files concurrently in Node.js.
importfsfrom'fs/promises';asyncfunctiongetNum(filename){returnparseInt(awaitfs.readFile(filename,'utf8'),10);}try{constnumberPromises=[1,2,3].map(i=>getNum(`${i}.txt`));constnumbers=awaitPromise.all(numberPromises);console.log(numbers[0]+numbers[1]+numbers[2]);}catch(err){console.error('Something went wrong:');console.error(err);}
To run this code, save it in a file called reader.js. Make sure you have text files named 1.txt, 2.txt, and 3.txt, each containing integers, and then run the program with node reader.js.
Since we’re using Promise.all(), we’re waiting for all three files to be read and parsed. If you squint a bit, it may even look similar to the pthread_join() from the C example later in this chapter. However, just because the promises are being created together and waited upon together doesn’t mean that the code resolving them runs at the same time, it just means their timeframes are overlapping. There’s still only one instruction pointer, and only one instruction is being executed at a time.
In the absence of threads, there’s only one JavaScript environment to work with. This means one instance of the VM, one instruction pointer, and one instance of the garbage collector. By one instruction pointer, we mean that the JavaScript interpreter is only executing one instruction at any given time. That doesn’t mean we’re restricted to one global object though. In both the browser and Node.js, we have Realms at our disposal.
Realms can be thought of as instances of the JavaScript environment as provided to JavaScript code. This means that each Realm gets its own global object, and all of the associate properties of the global object, such as built-in classes like Date and other objects like Math. The global object is referred to as global in Node.js and window in browsers, but in modern versions of both, you can refer to the global object as globalThis.
In browsers, each frame in a web page has a Realm for all of the JavaScript within it. Since each frame has its own copy of Object and other primitives within it, you’ll notice that they have their own inheritance trees, and instanceof might not work as you expect it to when operating on objects from different Realms. This is demonstrated in Example 1-4.
Example 1-4. Objects from a different from in a browser.
constiframe=document.createElement('iframe');document.body.appendChild(iframe);constFrameObject=iframe.contentWindow.Object;console.log(Object===FrameObject);console.log(newObject()instanceofFrameObject);console.log(FrameObject.name);
The global object inside the
iframeis accessible with thecontentWindowproperty.
This returns false, so the
Objectinside the frame is not the same as in the main frame.
instanceofevaluates tofalse, as expected since they’re not the sameObject.
Despite all this, the constructors have the same
nameproperty.
In Node.js, Realms can be constructed with the vm.createContext() function, as shown in Example 1-5. In Node.js parlance, Realms are called Contexts. All the same rules and properties applying to browser frames also apply to Contexts, but in Contexts, you don’t have access to any global properties or anything else that might be in scope in your Node.js files. If you want to use these features, they need to be manually passed in to the Context.
Example 1-5. Objects from a new Context in Node.js.
constvm=require('vm');constContextObject=vm.runInNewContext('Object');console.log(Object===ContextObject);console.log(newObject()instanceofContextObject);console.log(ContextObject.name);
We can get objects from a new context using
runInNewContext.This returns false, so as with browser iframes,
Objectinside the context is not the same as in the main context.Similarly,
instanceofevaluates tofalse.Once again, the constructors have the same
nameproperty.
In any of these Realm cases, it’s important to note that we still only have instruction pointer, and code from only one Realm is running at a time, because we’re still only talking about single-threaded execution.
Threads in C: Get Rich with Happycoin
Threads are obviously not unique to JavaScript. They’re a long-standing concept at the operating system level, independent of languages. Let’s explore how a threaded program might look in C. C is an obvious choice here, since the C interface for threads is what underlies most thread implementations in higher-level languages, even if there may seem to be different semantics.
Let’s start with an example. Imagine a proof-of-work algorithm for a simple and impractical cryptocurrency called Happycoin, as follows:
-
Generate a random unsigned 64-bit integer.
-
Determine whether or not the integer is happy.
-
If it’s not happy, it’s not a Happycoin.
-
If it’s not divisible by 10,000, it’s not a Happycoin.
-
Otherwise, it’s a Happycoin.
A number is happy if it eventually goes to 1 when replacing it with the sum of the squares of its digits, and looping until either the 1 happens, or a previously-seen number arises. Wikipedia defines it clearly, and also points out that if any previously seen numbers arise, then 4 will arise, and vice versa. You may notice that our algorithm is needlessly too expensive, because we could check for divisibility before checking for happiness. This is intentional, because we’re trying to demonstrate a heavy workload.
Let’s build a simple C program that runs the proof-of-work algorithm 10,000,000 times, printing any Happycoins found, and a count of them.
Note
The cc in the compilation steps here can be replaced with gcc or clang, depending on which is available to you. On most systems, cc is an alias for either gcc or clang, so that’s what we’ll use here.
Windows users may have to do some extra work here to get this going in Visual Studio, and the threads example won’t work out-of-the-box on Windows since it uses POSIX threads rather than Windows threads, which are different. To simplify trying this on Windows, the recommendation is to use Windows Subsystem for Linux so that you have a POSIX-compatible environment to work with.
With Only the Main Thread
Create a file called happycoin.c, in a directory called ch1-c-threads/. We’ll build up this file over the course of this section. To start off, add the code as shown in Example 1-7.
Example 1-7. ch1-c-threads/happycoin.c
#include <inttypes.h>#include <stdbool.h>#include <stdio.h>#include <stdlib.h>#include <time.h>uint64_trandom64(uint32_t*seed){uint64_tresult;uint8_t*result8=(uint8_t*)&result;for(size_ti=0;i<sizeof(result);i++){result8[i]=rand_r(seed);}returnresult;}
This line uses pointers, which may be unfamiliar to you if you’re coming from a mostly-JavaScript background. The short version of what’s going on here is that
result8is an array of 8 8-bit unsigned integers, backed by the same memory asresult, which is a single 64-bit unsigned integer.
We’ve added a bunch of includes which give us handy things like types, I/O functions, and the time and random number functions we’ll be needing. Since the algorithm requires the generation of a random 64-bit unsigned integer (i.e. a uint64_t), we need eight random bytes, which random64() gives us by calling rand_r() until we have enough bytes. Since rand_r() also requires a reference to a seed, we’ll pass that into random64() as well.
Now let’s add our happy number calculation as shown in Example 1-8.
Example 1-8. ch1-c-threads/happycoin.c
uint64_tsum_digits_squared(uint64_tnum){uint64_ttotal=0;while(num>0){uint64_tnum_mod_base=num%10;total+=num_mod_base*num_mod_base;num=num/10;}returntotal;}boolis_happy(uint64_tnum){while(num!=1&&num!=4){num=sum_digits_squared(num);}returnnum==1;}boolis_happycoin(uint64_tnum){returnis_happy(num)&&num%10000==0;}
To get the sum of the squares of the digits in sum_digits_squared, we’re using the mod operator, %, to get each digit from right to left, squaring it, then adding it to our running total. We then use this function in is_happy in a loop, stopping when the number is 1 or 4. We stop at 1, since that indicates the number is happy. We also stop at 4, because that’s indicative of an infinite loop where we never end up at 1. Finally, in is_happycoin(), we do the work of checking whether a number is happy and also divisible by 10,000.
Let’s wrap this all up in our main() function as shown in Example 1-9.
Example 1-9. ch1-c-threads/happycoin.c
intmain(){uint32_tseed=time(NULL);intcount=0;for(inti=1;i<10000000;i++){uint64_trandom_num=random64(&seed);if(is_happycoin(random_num)){printf("%"PRIu64" ",random_num);count++;}}printf("count %d",count);return0;}
First, we need a seed for the random number generator. The current time is as suitable a seed as any, so we’ll use that via time(). Then, we’ll loop 10,000,000 times, first getting a random number from random64(), then checking if it’s a Happycoin. If it is, we’ll increment the count, and print the number out. The weird PRIu64 syntax in the printf() call is necessary for properly printing out 64-bit unsigned integers. When the loop completes, we print out the count and exit the program.
To compile and run this program use the following commands in your ch1-c-threads directory.
$ cc -o happycoin happycoin.c $ ./happycoin
You’ll get a list of Happycoins found on one line, and the count of them on the next line. For a given run of the program, it might look something like this:
11023541197304510000 ... 167 entries redacted for brevity ... 770541398378840000 count 169
It takes a non-trivial amount of time to run this program; about 2 seconds on a run-of-the-mill computer. This is a case where threads can be useful to speed things up, because many iterations of the same largely mathematical operation are being run.
Let’s go ahead and convert this example to a multithreaded program.
With Four Worker Threads
We’ll set up four threads that will each run a quarter of the iterations of the loop that generates a random number and tests if it’s a Happycoin.
In POSIX C, threads are managed with the pthread_* family of functions. The pthread_create() function is use to create a thread. A function is passed in that will be executed on that thread. Program flow continues on the main thread. The program can wait for a thread’s completion by calling pthread_join() on it. You can pass arguments to the function being run on the thread via pthread_create() and get return values from pthread_join().
In our program, we’ll isolate the generation of Happycoins in a function called get_happycoins() and that’s what will run in our threads. We’ll create the 4 threads, and then immediately wait for the completion of them. Whenever we get the results back from a thread, we’ll output them, and store the count so we can print the total at the end. To help in passing the results back, we’ll created a simple struct called happy_result.
Make a copy of your existing happycoin.c and name it happycoin-threads.c. Then in the new file, insert the code in Example 1-10 under the last #include currently in the file.
Example 1-10. ch1-c-threads/happycoin-threads.c
#include <pthread.h>structhappy_result{size_tcount;uint64_t*nums;};
The first line includes pthread.h, which gives us access to the various thread functionality we’ll need. Then struct happy_result is defined, which we’ll use as the return value for our thread function get_happycoins() later on. It stores an array of found happycoins, represented here by a pointer, and the count of them.
Now, go ahead and delete the whole main() function, since we’re about to replace it. First, lets add our get_happycoins() function in Example 1-11, which is the code that will run on our worker threads.
Example 1-11. ch1-c-threads/happycoin-threads.c
void*get_happycoins(void*arg){intattempts=*(int*)arg;intlimit=attempts/10000;uint32_tseed=time(NULL);uint64_t*nums=malloc(limit*sizeof(uint64_t));structhappy_result*result=malloc(sizeof(structhappy_result));result->nums=nums;result->count=0;for(inti=1;i<attempts;i++){if(result->count==limit){break;}uint64_trandom_num=random64(&seed);if(is_happycoin(random_num)){result->nums[result->count++]=random_num;}}return(void*)result;}
This weird pointer casting thing basically says “treat this arbitrary pointer as a pointer to an
int, and then get me the value of thatint“.
You’ll notice that this function takes in a single void * and returns a single void *. That’s the function signature expected by pthread_create(), so we don’t have a choice here. This means we have to cast our arguments to what we want them to be. We’ll be passing in the number of attempts, so we’ll cast the argument to an int. Then, we’ll set the seed as we did in the previous example, but this time it’s happening in our thread function, so we get a different seed per thread.
After allocating enough space for our array and struct happy_result, we go ahead into the same loop that we did in main() in the single-threaded example, only this time we’re putting the results into the struct instead of printing them. Once the loop is done, we return the struct as a pointer, which we cast as void * to satisfy the function signature. This is how information is passed back to the main thread, which will make sense of it.
This demonstrates one of the key properties of threads that we don’t get from processes, which is the shared memory space. If, for example, we were using processes instead of threads, and some interprocess communication (IPC) mechanism to transfer results back, we wouldn’t be able to simply pass a memory address back to the main process, since the main process wouldn’t have access to memory of the worker process. Thanks to virtual memory, the memory address might refer to something else entirely in the main process. Instead of passing a pointer, we’d have to pass the entire value back over the IPC channel, which can introduce performance overhead. Since we’re using threads instead of processes, we can just use the pointer, so that the main thread can use it just the same.
Shared memory isn’t without its trade-offs though. In our case, there’s no need for the worker thread to make any use of the memory it has now passed to the main thread. This isn’t always the case with threads. In a great multitude of cases, it’s necessary to properly manage how threads access shared memory via synchronization, otherwise some unpredictable results may occur. We’ll go into how this works in JavaScript in detail in Chapter 4 and Chapter 5.
Now, let’s wrap this up with the main() function in Example 1-12.
Example 1-12. ch1-c-threads/happycoin-threads.c
#define THREAD_COUNT 4intmain(){pthread_tthread[THREAD_COUNT];intattempts=10000000/THREAD_COUNT;intcount=0;for(inti=0;i<THREAD_COUNT;i++){pthread_create(&thread[i],NULL,get_happycoins,&attempts);}for(intj=0;j<THREAD_COUNT;j++){structhappy_result*result;pthread_join(thread[j],(void**)&result);count+=result->count;for(intk=0;k<result->count;k++){printf("%"PRIu64" ",result->nums[k]);}}printf("count %d",count);return0;}
First, we’ll declare our four threads as an array on the stack. Then, we divide our desired number of attempts (10,000,000) by the number of threads. This is what will be passed to get_happycoins() as an argument, which we see inside the first loop, which creates each of the threads with pthread_create(), passing in the number of attempts per thread as an argument. In the next loop, we wait for each of the threads to finish their execution with pthread_join(). Then we can print the results and the total from all the threads, just like we would in the single-threaded example.
Note
This program leaks memory. One hard part of multithreaded programming in C and some other languages is that it can be very easy to lose track of where and when memory is allocated and where and when it should be freed. See if you can modify the code here to ensure the program exits with all heap-allocated memory freed.
With the changes complete, you can compile and run this program with the following commands in your ch1-c-threads directory.
$ cc -pthread -o happycoin-threads happycoin-threads.c $ ./happycoin-threads
The output should look something like this:
2466431682927540000 ... 154 entries redacted for brevity ... 15764177621931310000 count 156
You’ll notice output similar to the single-threaded example.1 You’ll also notice that it’s a bit faster. On a run-of-the-mill computer it finishes in about 0.8 seconds. This isn’t quite four times as fast, since there’s some initial overhead in the main thread, and also the cost of printing of results. We could print the results as soon as they’re ready on the thread that’s doing the work, but if we do that, the results may clobber each other in the output, since nothing stops two threads from printing to the output stream at the same time. By sending the results to the main thread, we can coordinate the printing of results there so that nothing gets clobbered.
This illustrates the primary advantage and one drawback of threaded code. On one hand, it’s useful for splitting up computationally expensive tasks so that they can be run in parallel. On the other hand, we need to ensure that some events are properly synchronized so that weird errors don’t occur. When adding threads to your code in any language, it’s worth making sure that the use is appropriate. Also, as with any exercise in attempting to make faster programs, always be measuring. You don’t want to have the complexity of threaded code in your application if it doesn’t turn out to give you any actual benefit.
Any programming language supporting threads is going to provide some mechanisms for creating and destroying threads, passing messages in between, and interacting with data that’s shared between the threads. This may not look the same in every language, because as languages and their paradigms are different, so are their programmatic models of parallel programming. Now that we’ve explored what threaded programs look like in a low-level language like C, let’s dive in to JavaScript. Things will look a little different, but as you’ll see, the principles remain the same.
1 The fact that the total count from the multithreaded example is different from the single-threaded example is irrelevant, since the count is dependent on how many random numbers happened to be Happycoins. The result will be completely different between two different runs.