
HTTP is a TCP/IP-based system; therefore, an administrator trying to extract the last drop of performance will not only optimize the web server, but also look at the TCP network stack. TCP has various network congestion avoidance defaults, which can be tweaked to yield better bandwidth utilization. Moreover, TCP connections consume server resources, such as ports and memory. These are fixed resources and are only reused when released by previous TCP connections. System administrators can configure parameters for the optimal reuse of these fixed resources.
In this chapter, we will cover the following topics:
- TCP buffers
- TCP states
- Raising server limits
- Setting up the server
The chapter will discuss various commands to tweak TCP parameters on the Debian platform. These commands may vary on other platforms, so please check the related reference documentation.
The TCP protocol uses the socket interface to communicate. Its performance does not depend only on network transfer rate, but rather on the product of the transfer rate and the roundtrip time. This is known as the bandwidth delay product (BDP). The BDP measures the amount of data that fills the TCP pipe.
Internally, the OS kernel attaches certain (received and sent) buffers to each of the opened sockets. Each of these buffers must be large enough to hold the TCP data along with an OS-specific overhead. The BDP signifies the buffer space required by the sender and the receiver to obtain maximum throughput on TCP. The send and receive buffers describe a congestion window for a socket communication, which determines how many packets can be sent over the wire in one go. The buffers can be configured to push more network packets over high-speed networks.
The buffer size is limited by the operating system, which imposes an upper bound on the maximum amount of memory available for use by a TCP connection, inclusive of everything. These limits are too small for today's high-speed networks.
The ping command can be used to derive the BDP for a network. It gives the roundtrip time, which is multiplied by the network capacity to define the buffer size. Here's the command:
buffer size = network capacity * round trip time
For example, if the ping time is 30 milliseconds and the network consists of 1G Ethernet, then the buffers should be as follows:
.03 sec * (1024 Megabits)*(1/8)= 3.84 MegaBytes
The memory consumed by TCP can be found by listing the net.ipv4.tcp_mem key using the sysctl command:
$ sysctl net.ipv4.tcp_mem net.ipv4.tcp_mem = 188319 251092 376638
The output lists three values, namely, minimum, initial, and maximum buffer size.
Tip
There is no need to manually tune the values of tcp_mem. Since version 2.6.17, the Linux kernel comes bundled with an auto-tuning feature that configures the buffer values dynamically within the specified range. List net.ipv4.tcp_moderate_rcvbuf to check for auto-tuning:
$ sysct lnet.ipv4.tcp_moderate_rcvbuf net.ipv4.tcp_moderate_rcvbuf = 1
The value 1 indicates that tuning is enabled.
In addition to the total TCP buffer, we can also list the receive and send buffers using the following keys:
net.ipv4.tcp_rmemThis lists the memory for the TCP receive buffers
net.ipv4.tcp_wmemThis lists the memory for the TCP send buffers
The keys output three values, namely, minimum, initial, and maximum, for the respective buffers.
The initial size determines the amount of memory allocated at the start, when the socket is created. This should be kept low; otherwise, under heavy traffic conditions, each socket will start allocating large initial memory, which can cause the system to run out of memory, thus yielding poor performance. The Linux kernel's auto-tuning will dynamically adjust the buffers during usage for optimal performance and memory utilization.
The maximum size for the receive and send buffers can be determined using the net.core.rmem_max and net.core.wmem_max properties. The default values for these properties are quite low—around 200 Kb. Here's an example:
$ sysctl net.ipv4.tcp_moderate_rcvbuf net.core.rmem_max = 212992 $ sysctl net.ipv4.tcp_moderate_rcvbuf net.core.wmem_max = 212992
Using the preceding set of kernel properties, TCP defines what are known as the "receiver window size" and the "sender window size", respectively. Now, if the receiver window is small, then the sender cannot send more data, thus leading to suboptimal performance. Even while sending data, if the "send window" is small, then the server will send smaller data than what the receiver can hold.
Modify these values to something like 16 MB as the maximum window size. Also, modify the maximum values of net.ipv4.tcp_rmem and net.ipv4.tcp_wmem to the corresponding values. The values can be updated by setting the correct set of keys and values in the sysctl command:
$ sudo sysctl -w net.core.rmem_max=16777216 net.core.rmem_max = 16777216 $ sudo sysctl -w net.ipv4.tcp_rmem='4096 87380 16777216' net.ipv4.tcp_rmem = 4096 87380 16777216 $ sudo sysctl -w net.core.wmem_max=16777216 net.core.wmem_max = 16777216 $ sudo sysctl -w net.ipv4.tcp_wmem='4096 16384 16777216' net.ipv4.tcp_wmem = 4096 16384 16777216
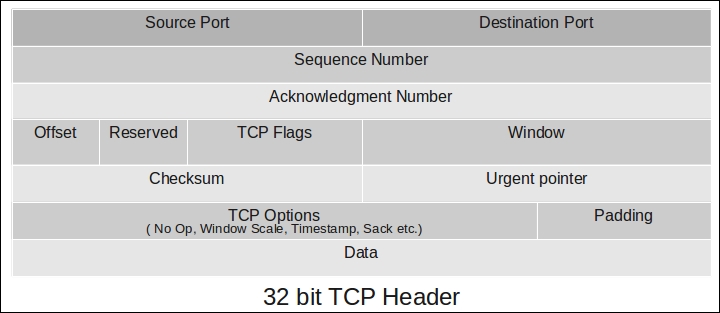
The TCP header contains a
window field, which determines the receiver buffer size. The default size of this window is 16 bits, which means it can represent data of a few Kb.
TCP defines a window-scaling option, which can extend the 16-bit TCP window field (part of the TCP header) to 32 bits, essentially allowing larger data packets. The option specifies the count of bits by which the header needs to be shifted. This shifting allows larger values to be sent using the window field. The following diagram shows this:
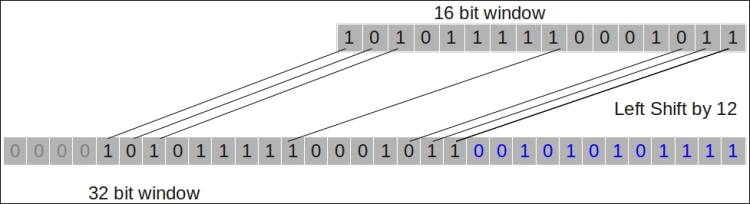
The buffer allocated at the receiving end is dynamically altered by the value in this window field. Window scaling is part of the TCP handshake and is enabled by default. This feature of TCP can be toggled using net.ipv4.tcp_window_scaling.
Along with TCP window scaling, the TCP header also defines a timestamp (net.ipv4.tcp_timestamps) used to sync packets and a sack (net.ipv4.tcp_sack) used to selectively identify packets lost during transmission.
TCP enables all the features mentioned earlier by default. They should not be disabled as turning them off will hurt performance rather than make any gains.
TCP uses control algorithms to avoid congestion. There are various implementations for these algorithms. The Linux kernel packs the htcp, cubic, and reno implements. These can be found using the net.ipv4.tcp_available_congestion_control key as follows:
$ sysctl net.ipv4.tcp_available_congestion_control net.ipv4.tcp_available_congestion_control = cubic reno
The reno implementation has been the classical model of congestion control. It suffers from various issues, for example, it is slow to start. Thus, it is not suitable for high bandwidth networks. Cubic has replaced reno as the default implementation for various OS kernels.
You can verify the congestion control algorithm used by TCP by listing the net.ipv4.tcp_congestion_control key:
$ sysctl net.ipv4.tcp_congestion_control net.ipv4.tcp_congestion_control = cubic