In this chapter, we are going to cover various methods and techniques to preprocess the text data along with exploratory data analysis.
We are going to discuss the following
recipes under text preprocessing and exploratory data analysis.
Recipe 1. Lowercasing
Recipe 2. Punctuation removal
Recipe 3. Stop words removal
Recipe 4. Text standardization
Recipe 5. Spelling correction
Recipe 6. Tokenization
Recipe 7. Stemming
Recipe 8. Lemmatization
Recipe 9. Exploratory data analysis
Recipe 10. End-to-end processing pipeline
Before directly jumping into the recipes, let us first understand the need for preprocessing the text data. As we all know, around 90% of the world’s data is unstructured and may be present in the form of an image, text, audio, and video. Text can come in a variety of forms from a list of individual words, to sentences to multiple paragraphs with special characters (like tweets and other punctuations). It also may be present in the form of web, HTML, documents, etc. And this data is never clean and consists of a lot of noise. It needs to be treated and then perform a few of the preprocessing functions to make sure we have the right input data for the feature engineering and model building. Suppose if we don’t preprocess the data, any algorithms that are built on top of such data will not add any value for the business. This reminds me of a very popular phrase in the Data Science world “Garbage in – Garbage out.”
Preprocessing involves transforming raw text data into an understandable format. Real-world data is very often incomplete, inconsistent, and filled with a lot of noise and is likely to contain many errors. Preprocessing is a proven method of resolving such issues. Data preprocessing prepares raw text data for further processing.
Recipe 2-1. Converting Text Data to Lowercase
In this recipe, we are going to discuss how to lowercase the text data in order to have all the data in a uniform format and to make sure “NLP” and “nlp” are treated as the same.
Problem
How to lowercase the text data?
Solution
The simplest way to do this is by using the default lower() function in Python.
The lower() method
converts all uppercase characters in a string into lowercase characters and returns them.
How It Works
Let’s follow the steps in this section to lowercase a given text or document. Here, we are going to use Python.
Step 1-1 Read/create the text data
Let’s create a list of strings and assign it to a variable.
text=['This is introduction to NLP','It is likely to be useful, to people ','Machine learning is the new electrcity','There would be less hype around AI and more action going forward','python is the best tool!','R is good langauage','I like this book','I want more books like this']
#convert list to data frame
import pandas as pd
df = pd.DataFrame({'tweet':text})
print(df)
#output
tweet
0 This is introduction to NLP
1 It is likely to be useful, to people
2 Machine learning is the new electrcity
3 There would be less hype around AI and more ac...
4 python is the best tool!
5 R is good langauage
6 I like this book
7 I want more books like this
Step 1-2 Execute lower() function on the text data
When there is just the string, apply the
lower() function directly as shown below:
x = 'Testing'
x2 = x.lower()
print(x2)
When you want to perform lowercasing on a data frame, use the apply a function as shown below:
df['tweet'] = df['tweet'].apply(lambda x: " ".join(x.lower() for x in x.split()))
df['tweet']
#output
0 this is introduction to nlp
1 it is likely to be useful, to people
2 machine learning is the new electrcity
3 there would be less hype around ai and more ac...
4 python is the best tool!
5 r is good langauage
6 i like this book
7 i want more books like this
That’s all. We have converted
the whole tweet column into lowercase. Let’s see what else we can do in the next recipes.
Recipe 2-2. Removing Punctuation
In this recipe, we are going to discuss how to remove punctuation from the text data. This step is very important as punctuation doesn’t add any extra information or value. Hence removal of all such instances will help reduce the size of the data and increase computational efficiency.
Problem
You want to remove punctuation from the text data.
Solution
The simplest way to do this is by using the regex and replace() function in Python.
How It Works
Let’s follow the steps in this section to remove punctuation from the text data.
Step 2-1 Read/create the text data
Let’s create a list of strings and assign it to a variable.
text=['This is introduction to NLP','It is likely to be useful, to people ','Machine learning is the new electrcity','There would be less hype around AI and more action going forward','python is the best tool!','R is good langauage','I like this book','I want more books like this']
#convert list to dataframe
import pandas as pd
df = pd.DataFrame({'tweet':text})
print(df)
#output
tweet
0 This is introduction to NLP
1 It is likely to be useful, to people
2 Machine learning is the new electrcity
3 There would be less hype around AI and more ac...
4 python is the best tool!
5 R is good langauage
6 I like this book
7 I want more books like this
Step 2-2 Execute below function on the text data
Using the regex and
replace() function, we can remove the punctuation as shown below:
s = "I. like. This book!"
s1 = re.sub(r'[^ws]',",s)
s1
#output
'I like This book'
Or:
df['tweet'] = df['tweet'].str.replace('[^ws]',")
df['tweet']
#output
0 this is introduction to nlp
1 it is likely to be useful to people
2 machine learning is the new electrcity
3 there would be less hype around ai and more ac...
4 python is the best tool
5 r is good langauage
6 i like this book
7 i want more books like this
Or:
s = "I. like. This book!"
for c in string.punctuation:
s= s.replace(c,"")
s
#output
'I like This book'
Recipe 2-3. Removing Stop Words
In this recipe, we are going to discuss how to remove stop words. Stop words are very common words that carry no meaning or less meaning compared to other keywords. If we remove the words that are less commonly used, we can focus on the important keywords instead. Say, for example, in the context of a search engine, if your search query is “How to develop chatbot using python,” if the search engine tries to find web pages that contained the terms “how,” “to,” “develop,” “chatbot,” “using,” “python,” the search engine is going to find a lot more pages that contain the terms “how” and “to” than pages that contain information about developing chatbot because the terms “how” and “to” are so commonly used in the English language. So, if we remove such terms, the search engine can actually focus on retrieving pages that contain the keywords: “develop,” “chatbot,” “python” – which would more closely bring up pages that are of real interest. Similarly we can remove more common words and rare words as well.
Problem
You want to remove stop words.
Solution
The simplest way to do this by using the NLTK library, or you can build your own stop words file.
How It Works
Let’s follow the steps in this section to remove stop words from the text data.
Step 3-1 Read/create the text data
Let’s create a list of strings and assign it to a variable.
text=['This is introduction to NLP','It is likely to be useful, to people ','Machine learning is the new electrcity','There would be less hype around AI and more action going forward','python is the best tool!','R is good langauage','I like this book','I want more books like this']
#convert list to data frame
import pandas as pd
df = pd.DataFrame({'tweet':text})
print(df)
#output
tweet
0 This is introduction to NLP
1 It is likely to be useful, to people
2 Machine learning is the new electrcity
3 There would be less hype around AI and more ac...
4 python is the best tool!
5 R is good langauage
6 I like this book
7 I want more books like this
Step 3-2 Execute below commands on the text data
Using the NLTK library, we can remove the punctuation as shown below.
#install and import libraries
!pip install nltk
import nltk
nltk.download()
from nltk.corpus import stopwords
stop = stopwords.words('english')
df['tweet'] = df['tweet'].apply(lambda x: " ".join(x for x in x.split() if x not in stop))
df['tweet']
0 introduction nlp
1 likely useful people
2 machine learning new electrcity
3 would less hype around ai action going forward
4 python best tool
5 r good langauage
6 like book
7 want books like
There are no stop words
now. Everything has been removed in this step.
Recipe 2-4. Standardizing Text
In this recipe, we are going to discuss how to standardize the text. But before that, let’s understand what is text standardization and why we need to do it. Most of the text data is in the form of either customer reviews, blogs, or tweets, where there is a high chance of people using short words and abbreviations to represent the same meaning. This may help the downstream process to easily understand and resolve the semantics of the text.
Problem
You want to standardize text.
Solution
We can write our own custom dictionary to look for short words and abbreviations.
How It Works
Let’s follow the steps in this section to perform text standardization.
Step 4-1 Create a custom lookup dictionary
The dictionary will be for text standardization based on your data.
lookup_dict = {'nlp':'natural language processing', 'ur':'your', "wbu" : "what about you"}
Step 4-2 Create a custom function for text standardization
Here is the code:
def text_std(input_text):
words = input_text.split()
new_words = []
for word in words:
word = re.sub(r'[^ws]',",word)
if word.lower() in lookup_dict:
word = lookup_dict[word.lower()]
new_words.append(word)
new_text = " ".join(new_words)
return new_text
Step 4-3 Run the text_std function
We also need to check the output:
text_std("I like nlp it's ur choice")
#output
'natural language processing your'
Here, nlp has standardised to 'natural language processing' and ur to 'your'.
Recipe 2-5. Correcting Spelling
In this recipe, we are going to discuss how to do spelling correction. But before that, let’s understand why this spelling correction is important. Most of the text data is in the form of either customer reviews, blogs, or tweets, where there is a high chance of people using short words and making typo errors. This will help us in reducing multiple copies of words, which represents the same meaning. For example, “proccessing” and “processing” will be treated as different words even if they are used in the same sense.
Note that abbreviations should be handled before this step, or else the corrector would fail at times. Say, for example, “ur” (actually means “your”) would be corrected to “or.”
Problem
You want to do spelling correction.
Solution
The simplest way to do this by using the TextBlob library
.
How It Works
Let’s follow the steps in this section to do spelling correction.
Step 5-1 Read/create the text data
Let’s create a list of strings and assign it to a variable.
text=['Introduction to NLP','It is likely to be useful, to people ','Machine learning is the new electrcity', 'R is good langauage','I like this book','I want more books like this']
#convert list to dataframe
import pandas as pd
df = pd.DataFrame({'tweet':text})
print(df)
#output
tweet
0 Introduction to NLP
1 It is likely to be useful, to people
2 Machine learning is the new electrcity
3 R is good langauage
4 I like this book
5 I want more books like this
Step 5-2 Execute below code on the text data
Using TextBlob, we can do spelling correction as shown below:
#Install textblob library
!pip install textblob
#import libraries and use 'correct' function
from textblob import TextBlob
df['tweet'].apply(lambda x: str(TextBlob(x).correct()))
#output
0 Introduction to NLP
1 It is likely to be useful, to people
2 Machine learning is the new electricity
3 R is good language
4 I like this book
5 I want more books like this
If you clearly observe this, it corrected the spelling of
electricity and language.
#You can also use autocorrect library as shown below
from autocorrect import spell
print(spell(u'mussage'))
print(spell(u'sirvice'))
#output
'message'
'service'
Recipe 2-6. Tokenizing Text
In this recipe, we would look at the ways to tokenize. Tokenization refers to splitting text into minimal meaningful units. There is a sentence tokenizer and word tokenizer. We will see a word tokenizer in this recipe, which is a mandatory step in text preprocessing for any kind of analysis. There are many libraries to perform tokenization like NLTK, SpaCy, and TextBlob. Here are a few ways to achieve it.
Problem
You want to do tokenization.
Solution
The simplest way to do this is by using the TextBlob library.
How It Works
Let’s follow the steps in this section to perform tokenization.
Step 6-1 Read/create the text data
Let’s create a list of strings and assign it to a variable.
text=['This is introduction to NLP','It is likely to be useful, to people ','Machine learning is the new electrcity','There would be less hype around AI and more action going forward','python is the best tool!','R is good langauage','I like this book','I want more books like this']
#convert list to dataframe
import pandas as pd
df = pd.DataFrame({'tweet':text})
print(df)
#output
tweet
0 This is introduction to NLP
1 It is likely to be useful, to people
2 Machine learning is the new electrcity
3 There would be less hype around AI and more ac...
4 python is the best tool!
5 R is good langauage
6 I like this book
7 I want more books like this
Step 6-2 Execute below code on the text data
The result of tokenization is a list of tokens:
#Using textblob
from textblob import TextBlob
TextBlob(df['tweet'][3]).words
#output
WordList(['would', 'less', 'hype', 'around', 'ai', 'action', 'going', 'forward'])
#create data
mystring = "My favorite animal is cat"
nltk.word_tokenize(mystring)
#output
['My', 'favorite', 'animal', 'is', 'cat']
#using split function from python
mystring.split()
#output
['My', 'favorite', 'animal', 'is', 'cat']
Recipe 2-7. Stemming
In this recipe, we will discuss stemming. Stemming is a process of extracting a root word. For example, “fish,” “fishes,” and “fishing” are stemmed into fish.
Problem
You want to do stemming.
Solution
The simplest way to do this by using NLTK or a TextBlob library.
How It Works
Let’s follow the steps in this section to perform stemming.
Step 7-1 Read the text data
Let’s create a list of strings and assign it to a variable.
text=['I like fishing','I eat fish','There are many fishes in pound']
#convert list to dataframe
import pandas as pd
df = pd.DataFrame({'tweet':text})
print(df)
#output
tweet
0 I like fishing
1 I eat fish
2 There are many fishes in pound
Step 7-2 Stemming the text
Execute the below code on the text data:
#Import library
from nltk.stem import PorterStemmer
df['tweet'][:5].apply(lambda x: " ".join([st.stem(word) for word in x.split()]))
#output
0 I like fish
1 I eat fish
2 there are mani fish in pound
If you observe this, you will notice that fish, fishing, and fishes have been stemmed to fish.
Recipe 2-8. Lemmatizing
In this recipe, we will discuss lemmatization. Lemmatization is a process of extracting a root word by considering the vocabulary. For example, “good,” “better,” or “best” is lemmatized into good.
The part of speech of a word is determined in lemmatization. It will return the dictionary form of a word, which must be a valid word while stemming just extracts the root word.
Lemmatization can get better results.
The stemmed form of leafs is leaf.
The stemmed form of leaves is leav.
The lemmatized form of leafs is leaf.
The lemmatized form of leaves is leaf.
Problem
You want to perform lemmatization.
Solution
The simplest way to do this is by using NLTK or the TextBlob library.
How It Works
Let’s follow the steps in this section to perform lemmatization.
Step 8-1 Read the text data
Let’s create a list of strings and assign it to a variable.
text=['I like fishing','I eat fish','There are many fishes in pound', 'leaves and leaf']
#convert list to dataframe
import pandas as pd
df = pd.DataFrame({'tweet':text})
print(df)
tweet
0 I like fishing
1 I eat fish
2 There are multiple fishes in pound
3 leaves and leaf
Step 8-2 Lemmatizing the data
Execute the below code on the text data:
#Import library
from textblob import Word
#Code for lemmatize
df['tweet'] = df['tweet'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
#output
0 I like fishing
1 I eat fish
2 There are multiple fish in pound
3 leaf and leaf
You can observe that fish and fishes are lemmatized to fish and, as explained, leaves and leaf are lemmatized to leaf.
Recipe 2-9. Exploring Text Data
So far, we are comfortable with data collection and text preprocessing. Let us perform some exploratory data analysis.
Problem
You want to explore and understand the text data.
Solution
The simplest way to do this by using NLTK or the TextBlob library.
How It Works
Let’s follow the steps in this process.
Step 9-1 Read the text data
Execute the below code to download the dataset, if you haven’t already done so:
nltk.download().
#Importing data
import nltk
from nltk.corpus import webtext
nltk.download('webtext')
wt_sentences = webtext.sents('firefox.txt')
wt_words = webtext.words('firefox.txt')
Step 9-2 Import necessary libraries
Import Library for computing frequency:
from nltk.probability import FreqDist
from nltk.corpus import stopwords
import string
Step 9-3 Check number of words in the data
Count the number of words:
Step 9-4 Compute the frequency of all words in the reviews
Generating frequency for all the words:
frequency_dist = nltk.FreqDist(wt_words)
frequency_dist
#showing only top few results
FreqDist({'slowing': 1,
'warnings': 6,
'rule': 1,
'Top': 2,
'XBL': 12,
'installation': 44,
'Networking': 1,
'inccorrect': 1,
'killed': 3,
']"': 1,
'LOCKS': 1,
'limited': 2,
'cookies': 57,
'method': 12,
'arbitrary': 2,
'b': 3,
'titlebar': 6,
sorted_frequency_dist =sorted(frequency_dist,key=frequency_dist.__getitem__, reverse=True)
sorted_frequency_dist
['.',
'in',
'to',
'"',
'the',
"'",
'not',
'-',
'when',
'on',
'a',
'is',
't',
'and',
'of',
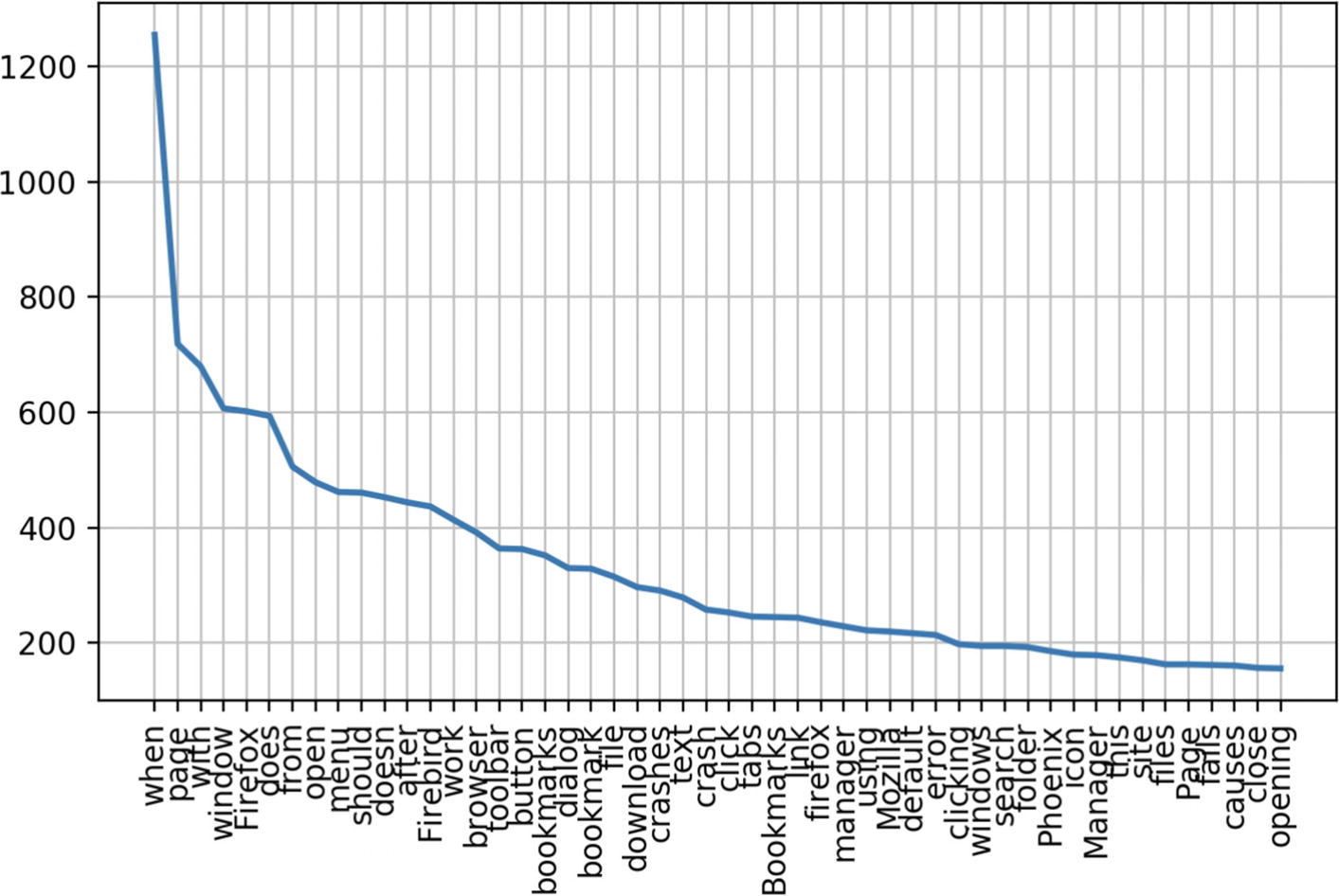
Step 9-5 Consider words with length greater than 3 and plot
Let’s take the words only if their frequency is greater than 3.
large_words = dict([(k,v) for k,v in frequency_dist.items() if len(k)>3])
frequency_dist = nltk.FreqDist(large_words)
frequency_dist.plot(50,cumulative=False)
Step 9-6 Build Wordcloud
Wordcloud is the pictorial representation of the most frequently repeated words representing the size of the word.
#install library
!pip install wordcloud
from wordcloud import WordCloud
wcloud = WordCloud().generate_from_frequencies(frequency_dist)
import matplotlib.pyplot as plt
plt.imshow(wcloud, interpolation="bilinear")
plt.axis("off")
(-0.5, 399.5, 199.5, -0.5)
plt.show()
Readers, give this a try: Remove the stop words
and then build the word cloud. The output would look something like that below.
Recipe 2-10. Building a Text Preprocessing Pipeline
So far, we have completed most of the text manipulation and processing techniques and methods. In this recipe, let’s do something interesting.
Problem
You want to build an end-to-end text preprocessing pipeline. Whenever you want to do preprocessing for any NLP application, you can directly plug in data to this pipeline function and get the required clean text data as the output.
Solution
The simplest way to do this by creating the custom function with all the techniques learned so far.
How It Works
This works by putting all the possible processing techniques into a wrapper function and passing the data through it.
Step 10-1 Read/create the text data
Let’s create a list of strings and assign it to a variable. Maybe a tweet sample:
tweet_sample= "How to take control of your #debt https://personal.vanguard.com/us/insights/saving-investing/debt-management.#Best advice for #family #financial #success (@PrepareToWin)"
You can also use your Twitter data extracted in Chapter .
Step 10-2 Process the text
Execute the below function to process the tweet:
import re
import nltk
from textblob import TextBlob
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from textblob import Word
from nltk.util import ngrams
import re
from wordcloud import WordCloud, STOPWORDS
from nltk.tokenize import word_tokenize
tweet = row
#Lower case
tweet.lower()
#Removes unicode strings like "u002c" and "x96"
tweet = re.sub(r'(\u[0-9A-Fa-f]+)',r", tweet)
tweet = re.sub(r'[^x00-x7f]',r",tweet)
#convert any url to URL
tweet = re.sub('((www.[^s]+)|(https?://[^s]+))','URL',tweet)
#Convert any @Username to "AT_USER"
tweet = re.sub('@[^s]+','AT_USER',tweet)
#Remove additional white spaces
tweet = re.sub('[s]+', ' ', tweet)
tweet = re.sub('[
]+', ' ', tweet)
#Remove not alphanumeric symbols white spaces
tweet = re.sub(r'[^w]', ' ', tweet)
#Removes hastag in front of a word """
tweet = re.sub(r'#([^s]+)', r'1', tweet)
#Replace #word with word
tweet = re.sub(r'#([^s]+)', r'1', tweet)
#Remove :( or :)
tweet = tweet.replace(':)',")
tweet = tweet.replace(':(',")
#remove numbers
tweet = ".join([i for i in tweet if not i.isdigit()])
#remove multiple exclamation
tweet = re.sub(r"(!)1+", ' ', tweet)
#remove multiple question marks
tweet = re.sub(r"(?)1+", ' ', tweet)
#remove multistop
tweet = re.sub(r"(.)1+", ' ', tweet)
#lemma
from textblob import Word
tweet =" ".join([Word(word).lemmatize() for word in tweet.split()])
#stemmer
#st = PorterStemmer()
#tweet=" ".join([st.stem(word) for word in tweet.split()])
#Removes emoticons from text
tweet = re.sub(':)|;)|:-)|(-:|:-D|=D|:P|xD|X-p|^^|:-*|^.^|^-^|^\_^|,-)|)-:|:'(|:(|:-(|:S|T.T|.\_.|:<|:-S|:-<|*-*|:O|=O|=-O|O.o|XO|O\_O|:-@|=/|:/|X-(|>.<|>=(|D:', ", tweet)
#trim
tweet = tweet.strip(''"')
#call the function with your data
processRow(tweet_sample)
#output
'How to take control of your debt URL Best advice for family financial success AT_USER'