
There are a number of NLP API classes that support SBD. Some are rule-based, whereas others use models that have been trained using common and uncommon text. We will illustrate the use of sentence detection classes using the OpenNLP, Stanford, and LingPipe APIs.
The models can also be trained. The discussion of this approach is illustrated in the Training a Sentence Detector model section of this chapter. Specialized models are needed when working with specialized text such as medical or legal text.
OpenNLP uses models to perform SBD. An instance of the SentenceDetectorME class is created, based on a model file. Sentences are returned by the sentDetect method, and position information is returned by the sentPosDetect method.
A model is loaded from a file using the SentenceModel class. An instance of the SentenceDetectorME class is then created using the model, and the sentDetect method is invoked to perform SDB. The method returns an array of strings, with each element holding a sentence.
This process is demonstrated in the following example. A try-with-resources block is used to open the en-sent.bin file, which contains a model. Then the paragraph string is processed. Next, various IO type exceptions are caught (if necessary). Finally, a for-each statement is used to display the sentences:
try (InputStream is = new FileInputStream(
new File(getModelDir(), "en-sent.bin"))) {
SentenceModel model = new SentenceModel(is);
SentenceDetectorME detector = new SentenceDetectorME(model);
String sentences[] = detector.sentDetect(paragraph);
for (String sentence : sentences) {
System.out.println(sentence);
}
} catch (FileNotFoundException ex) {
// Handle exception
} catch (IOException ex) {
// Handle exception
}On execution, we get the following output:
When determining the end of sentences we need to consider several factors. Sentences may end with exclamation marks! Or possibly questions marks? Within sentences we may find numbers like 3.14159, abbreviations such as found in Mr. Smith, and possibly ellipses either within a sentence …, or at the end of a sentence…
The output worked well for this paragraph. It caught both simple sentences and the more complex sentences. Of course, text that is processed is not always perfect. The following paragraph has extra spaces in some spots and is missing spaces where it needs them. This problem is likely to occur in the analysis of chat sessions:
paragraph = " This sentence starts with spaces and ends with "
+ "spaces . This sentence has no spaces between the next "
+ "one.This is the next one.";When we use this paragraph with the previous example, we get the following output:
This sentence starts with spaces and ends with spaces . This sentence has no spaces between the next one.This is the next one.
The leading spaces of the first sentence were removed, but the ending spaces were not. The third sentence was not detected and was merged with the second sentence.
The getSentenceProbabilities method returns an array of doubles representing the confidence of the sentences detected from the last use of the sentDetect method. Add the following code after the for-each statement that displayed the sentences:
double probablities[] = detector.getSentenceProbabilities();
for (double probablity : probablities) {
System.out.println(probablity);
}By executing with the original paragraph, we get the following output:
0.9841708738988814 0.908052385070974 0.9130082376342675 1.0
The numbers reflects a high level of probabilities for the SDB effort.
The SentenceDetectorME class possesses a sentPosDetect method that returns Span objects for each sentence. Use the same code as found in the previous section, except for two changes: replace the sentDetect method with the sentPosDetect method, and the for-each statement with the method used here:
Span spans[] = sdetector.sentPosDetect(paragraph);
for (Span span : spans) {
System.out.println(span);
}The output that follows uses the original paragraph. The Span objects contain positional information returned from the default execution of the toString method:
[0..74) [75..116) [117..145) [146..317)
The Span class possesses a number of methods. The next code sequence demonstrates the use of the getStart and getEnd methods to clearly show the text represented by those spans:
for (Span span : spans) {
System.out.println(span + "[" + paragraph.substring(
span.getStart(), span.getEnd()) +"]");
}The output shows the sentences identified:
[0..74)[When determining the end of sentences we need to consider several factors.] [75..116)[Sentences may end with exclamation marks!] [117..145)[Or possibly questions marks?] [146..317)[Within sentences we may find numbers like 3.14159, abbreviations such as found in Mr. Smith, and possibly ellipses either within a sentence …, or at the end of a sentence…]
There are a number of other Span methods that can be valuable. These are listed in the following table:
The Stanford NLP library supports several techniques used to perform sentence detection. In this section, we will demonstrate the process using the following classes:
PTBTokenizerDocumentPreprocessorStanfordCoreNLP
Although all of them perform SBD, each uses a different approach to performing the process.
The PTBTokenizer class uses rules to perform SBD and has a variety of tokenization options. The constructor for this class possesses three parameters:
- A
Readerclass that encapsulates the text to be processed - An object that implements the
LexedTokenFactoryinterface - A string holding the tokenization options
These options allow us to specify the text, the tokenizer to be used, and any options that we may need to use for a specific text stream.
In the following code sequence, an instance of the StringReader class is created to encapsulate the text. The CoreLabelTokenFactory class is used with the options left as null for this example:
PTBTokenizer ptb = new PTBTokenizer(new StringReader(paragraph), new CoreLabelTokenFactory(), null);
We will use the WordToSentenceProcessor class to create a List instance of List class to hold the sentences and their tokens. Its process method takes the tokens produced by the PTBTokenizer instance to create the List of list class as shown here:
WordToSentenceProcessor wtsp = new WordToSentenceProcessor(); List<List<CoreLabel>> sents = wtsp.process(ptb.tokenize());
This List instance of list class can be displayed in several ways. In the next sequence, the toString method of the List class displays the list enclosed in brackets, with its elements separated by commas:
for (List<CoreLabel> sent : sents) {
System.out.println(sent);
}The output of this sequence produces the following:
[When, determining, the, end, of, sentences, we, need, to, consider, several, factors, .] [Sentences, may, end, with, exclamation, marks, !] [Or, possibly, questions, marks, ?] [Within, sentences, we, may, find, numbers, like, 3.14159, ,, abbreviations, such, as, found, in, Mr., Smith, ,, and, possibly, ellipses, either, within, a, sentence, ..., ,, or, at, the, end, of, a, sentence, ...]
An alternate approach shown here displays each sentence on a separate line:
for (List<CoreLabel> sent : sents) {
for (CoreLabel element : sent) {
System.out.print(element + " ");
}
System.out.println();
}The output is as follows:
When determining the end of sentences we need to consider several factors . Sentences may end with exclamation marks ! Or possibly questions marks ? Within sentences we may find numbers like 3.14159 , abbreviations such as found in Mr. Smith , and possibly ellipses either within a sentence ... , or at the end of a sentence ...
If we are only interested in the positions of the words and sentences, we can use the endPosition method, as illustrated here:
for (List<CoreLabel> sent : sents) {
for (CoreLabel element : sent) {
System.out.print(element.endPosition() + " ");
}
System.out.println();
}When this is executed, we get the following output. The last number on each line is the index of the sentence boundary:
4 16 20 24 27 37 40 45 48 57 65 73 74 84 88 92 97 109 115 116 119 128 138 144 145 152 162 165 169 174 182 187 195 196 210 215 218 224 227 231 237 238 242 251 260 267 274 276 285 287 288 291 294 298 302 305 307 316 317
The first elements of each sentence are displayed in the following sequence along with its index:
for (List<CoreLabel> sent : sents) {
System.out.println(sent.get(0) + " "
+ sent.get(0).beginPosition());
}The output is as follows:
When 0 Sentences 75 Or 117 Within 146
If we are interested in the last elements of a sentence, we can use the following sequence. The number of elements of a list is used to display the terminating character and its ending position:
for (List<CoreLabel> sent : sents) {
int size = sent.size();
System.out.println(sent.get(size-1) + " "
+ sent.get(size-1).endPosition());
}This will produce the following output:
. 74 ! 116 ? 145 ... 317
There are a number of options available when the constructor of the PTBTokenizer class is invoked. These options are enclosed as the constructor's third parameter. The option string consists of the options separated by commas, as shown here:
"americanize=true,normalizeFractions=true,asciiQuotes=true".
Several of these options are listed in this table:
The following sequence illustrates the use of this option string;
paragraph = "The colour of money is green. Common fraction "
+ "characters such as ½ are converted to the long form 1/2. "
+ "Quotes such as "cat" are converted to their simpler form.";
ptb = new PTBTokenizer(
new StringReader(paragraph), new CoreLabelTokenFactory(),
"americanize=true,normalizeFractions=true,asciiQuotes=true");
wtsp = new WordToSentenceProcessor();
sents = wtsp.process(ptb.tokenize());
for (List<CoreLabel> sent : sents) {
for (CoreLabel element : sent) {
System.out.print(element + " ");
}
System.out.println();
}The color of money is green . Common fraction characters such as 1/2 are converted to the long form 1/2 . Quotes such as " cat " are converted to their simpler form .
The British spelling of the word "colour" was converted to its American equivalent. The fraction ½ was expanded to three characters: 1/2. In the last sentence, the smart quotes were converted to their simpler form.
When an instance of the DocumentPreprocessor class is created, it uses its Reader parameter to produce a list of sentences. It also implements the Iterable interface, which makes it easy to traverse the list.
In the following example, the paragraph is used to create a StringReader object, and this object is used to instantiate the DocumentPreprocessor instance:
Reader reader = new StringReader(paragraph);
DocumentPreprocessor dp = new DocumentPreprocessor(reader);
for (List sentence : dp) {
System.out.println(sentence);
}On execution, we get the following output:
[When, determining, the, end, of, sentences, we, need, to, consider, several, factors, .] [Sentences, may, end, with, exclamation, marks, !] [Or, possibly, questions, marks, ?] [Within, sentences, we, may, find, numbers, like, 3.14159, ,, abbreviations, such, as, found, in, Mr., Smith, ,, and, possibly, ellipses, either, within, a, sentence, ..., ,, or, at, the, end, of, a, sentence, ...]
By default, PTBTokenizer is used to tokenize the input. The setTokenizerFactory method can be used to specify a different tokenizer. There are several other methods that can be useful, as detailed in the following table:
The class can process either plain text or XML documents.
To demonstrate how an XML file can be processed, we will create a simple XML file called XMLText.xml, containing the following data:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl"?>
<document>
<sentences>
<sentence id="1">
<word>When</word>
<word>the</word>
<word>day</word>
<word>is</word>
<word>done</word>
<word>we</word>
<word>can</word>
<word>sleep</word>
<word>.</word>
</sentence>
<sentence id="2">
<word>When</word>
<word>the</word>
<word>morning</word>
<word>comes</word>
<word>we</word>
<word>can</word>
<word>wake</word>
<word>.</word>
</sentence>
<sentence id="3">
<word>After</word>
<word>that</word>
<word>who</word>
<word>knows</word>
<word>.</word>
</sentence>
</sentences>
</document>We will reuse the code from the previous example. However, we will open the XMLText.xml file instead, and use DocumentPreprocessor.DocType.XML as the second argument of the constructor of the DocumentPreprocessor class, as shown next. This will specify that the processor should treat the text as XML text. In addition, we will specify that only those XML elements that are within the <sentence> tag should be processed:
try {
Reader reader = new FileReader("XMLText.xml");
DocumentPreprocessor dp = new DocumentPreprocessor(
reader, DocumentPreprocessor.DocType.XML);
dp.setElementDelimiter("sentence");
for (List sentence : dp) {
System.out.println(sentence);
}
} catch (FileNotFoundException ex) {
// Handle exception
}The output of this example is as follows:
[When, the, day, is, done, we, can, sleep, .] [When, the, morning, comes, we, can, wake, .] [After, that, who, knows, .]
A cleaner output is possible using a ListIterator, as shown here:
for (List sentence : dp) {
ListIterator list = sentence.listIterator();
while (list.hasNext()) {
System.out.print(list.next() + " ");
}
System.out.println();
}Its output is the following:
When the day is done we can sleep . When the morning comes we can wake . After that who knows .
If we had not specified an element delimiter, then each word would have been displayed like this:
[When] [the] [day] [is] [done] ... [who] [knows] [.]
The StanfordCoreNLP class supports sentence detection using the ssplit annotator. In the following example, the tokenize and ssplit annotators are used. A pipeline object is created and the annotate method is applied against the pipeline using the paragraph as its argument:
Properties properties = new Properties();
properties.put("annotators", "tokenize, ssplit");
StanfordCoreNLP pipeline = new StanfordCoreNLP(properties);
Annotation annotation = new Annotation(paragraph);
pipeline.annotate(annotation);The output contains a lot of information. Only the output for the first line is shown here:
Sentence #1 (13 tokens): When determining the end of sentences we need to consider several factors. [Text=When CharacterOffsetBegin=0 CharacterOffsetEnd=4] [Text=determining CharacterOffsetBegin=5 CharacterOffsetEnd=16] [Text=the CharacterOffsetBegin=17 CharacterOffsetEnd=20] [Text=end CharacterOffsetBegin=21 CharacterOffsetEnd=24] [Text=of CharacterOffsetBegin=25 CharacterOffsetEnd=27] [Text=sentences CharacterOffsetBegin=28 CharacterOffsetEnd=37] [Text=we CharacterOffsetBegin=38 CharacterOffsetEnd=40] [Text=need CharacterOffsetBegin=41 CharacterOffsetEnd=45] [Text=to CharacterOffsetBegin=46 CharacterOffsetEnd=48] [Text=consider CharacterOffsetBegin=49 CharacterOffsetEnd=57] [Text=several CharacterOffsetBegin=58 CharacterOffsetEnd=65] [Text=factors CharacterOffsetBegin=66 CharacterOffsetEnd=73] [Text=. CharacterOffsetBegin=73 CharacterOffsetEnd=74]
Alternatively, we can use the xmlPrint method. This will produce the output in XML format, which can often be easier for extracting the information of interest. This method is shown here, and it requires that the IOException be handled:
try {
pipeline.xmlPrint(annotation, System.out);
} catch (IOException ex) {
// Handle exception
}A partial listing of the output is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet href="CoreNLP-to-HTML.xsl" type="text/xsl"?>
<root>
<document>
<sentences>
<sentence id="1">
<tokens>
<token id="1">
<word>When</word>
<CharacterOffsetBegin>0</CharacterOffsetBegin>
<CharacterOffsetEnd>4</CharacterOffsetEnd>
</token>
...
<token id="34">
<word>...</word>
<CharacterOffsetBegin>316</CharacterOffsetBegin>
<CharacterOffsetEnd>317</CharacterOffsetEnd>
</token>
</tokens>
</sentence>
</sentences>
</document>
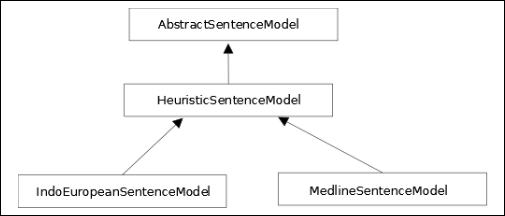
</root>LingPipe uses a hierarchy of classes to support SBD, as shown in the following figure. At the base of this hierarchy is the AbstractSentenceModel class whose primary method is an overloaded boundaryIndices method. This method returns an integer array of a boundary index where each element of the array represents a sentence boundary.
Derived from this class is the HeuristicSentenceModel class. This class uses a series of Possible Stops, Impossible Penultimates, and Impossible Starts token sets. These were discussed earlier in the Understanding SBD rules of LingPipe's HeuristicSentenceModel class section of the chapter.
The IndoEuropeanSentenceModel and MedlineSentenceModel classes are derived from the HeuristicSentenceModel class. They have been trained for English and specialized medical text respectively. We will illustrate both of these classes.
The IndoEuropeanSentenceModel model is used for English text. Its two-argument constructor will specify:
- Whether the final token must be a stop
- Whether parentheses should be balanced
The default constructor does not force the final token to be a stop or expect that parentheses should be balanced. The sentence model needs to be used with a tokenizer. We will use the default constructor of the IndoEuropeanTokenizerFactory class for this purpose, as shown here:
TokenizerFactory TOKENIZER_FACTORY= IndoEuropeanTokenizerFactory.INSTANCE; SentenceModel sentenceModel = new IndoEuropeanSentenceModel();
A tokenizer is created and its tokenize method is invoked to populate two lists:
List<String> tokenList = new ArrayList<>();
List<String> whiteList = new ArrayList<>();
Tokenizer tokenizer= TOKENIZER_FACTORY.tokenizer(
paragraph.toCharArray(),0, paragraph.length());
tokenizer.tokenize(tokenList, whiteList);The boundaryIndices method returns an array of integer boundary indexes. The method requires two String array arguments containing tokens and whitespaces. The tokenize method used two List for these elements. This means we need to convert the List into equivalent arrays, as shown here:
String[] tokens = new String[tokenList.size()]; String[] whites = new String[whiteList.size()]; tokenList.toArray(tokens); whiteList.toArray(whites);
We can then use the boundaryIndices method and display the indexes:
int[] sentenceBoundaries= sentenceModel.boundaryIndices(tokens, whites);
for(int boundary : sentenceBoundaries) {
System.out.println(boundary);
}The output is shown here:
12 19 24
To display the actual sentences, we will use the following sequence. The whitespace indexes are one off from the token:
int start = 0;
for(int boundary : sentenceBoundaries) {
while(start<=boundary) {
System.out.print(tokenList.get(start) + whiteList.get(start+1));
start++;
}
System.out.println();
}The following output is the result:
When determining the end of sentences we need to consider several factors. Sentences may end with exclamation marks! Or possibly questions marks?
Unfortunately, it missed the last sentence. This is due to the last sentence ending in an ellipsis. If we add a period to the end of the sentence, we get the following output:
When determining the end of sentences we need to consider several factors. Sentences may end with exclamation marks! Or possibly questions marks? Within sentences we may find numbers like 3.14159, abbreviations such as found in Mr. Smith, and possibly ellipses either within a sentence …, or at the end of a sentence….
An alternative approach is to use the SentenceChunker class to perform SBD. The constructor of this class requires a TokenizerFactory object and a SentenceModel object, as shown here:
TokenizerFactory tokenizerfactory = IndoEuropeanTokenizerFactory.INSTANCE; SentenceModel sentenceModel = new IndoEuropeanSentenceModel();
The SentenceChunker instance is created using the tokenizer factory and sentence instances:
SentenceChunker sentenceChunker =
new SentenceChunker(tokenizerfactory, sentenceModel);The SentenceChunker class implements the Chunker interface that uses a chunk method. This method returns an object that implements the Chunking interface. This object specifies "chunks" of text with a character sequence (CharSequence).
The chunk method uses a character array and indexes within the array to specify which portions of the text need to be processed. A Chunking object is returned like this:
Chunking chunking = sentenceChunker.chunk(
paragraph.toCharArray(),0, paragraph.length());We will use the Chunking object for two purposes. First, we will use its chunkSet method to return a Set of Chunk objects. Then we will obtain a string holding all the sentences:
Set<Chunk> sentences = chunking.chunkSet(); String slice = chunking.charSequence().toString();
A Chunk object stores character offsets of the sentence boundaries. We will use its start and end methods in conjunction with the slice to display the sentences, as shown next. Each element, sentence, holds the sentence's boundary. We use this information to display each sentence in the slice:
for (Chunk sentence : sentences) {
System.out.println("[" + slice.substring(sentence.start(), sentence.end()) + "]");
}The following is the output. However, it still has problems with sentences ending with an ellipsis, so a period has been added to the end of the last sentence before the text is processed.
[When determining the end of sentences we need to consider several factors.] [Sentences may end with exclamation marks!] [Or possibly questions marks?] [Within sentences we may find numbers like 3.14159, abbreviations such as found in Mr. Smith, and possibly ellipses either within a sentence …, or at the end of a sentence….]
Although the IndoEuropeanSentenceModel class works reasonably well for English text, it may not always work well for specialized text. In the next section, we will examine the use of the MedlineSentenceModel class, which has been trained to work with medical text.
The LingPipe sentence model uses MEDLINE, which is a large collection of biomedical literature. This collection is stored in XML format and is maintained by the United States National Library of Medicine (http://www.nlm.nih.gov/).
LingPipe uses its MedlineSentenceModel class to perform SBD. This model has been trained against the MEDLINE data. It uses simple text and tokenizes it into tokens and whitespace. The MEDLINE model is then used to find the text's sentences.
In the next example, we will use a paragraph from http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3139422/ to demonstrate the use of the model, as declared here:
paragraph = "HepG2 cells were obtained from the American Type Culture "
+ "Collection (Rockville, MD, USA) and were used only until "
+ "passage 30. They were routinely grown at 37°C in Dulbecco's "
+ "modified Eagle's medium (DMEM) containing 10 % fetal bovine "
+ "serum (FBS), 2 mM glutamine, 1 mM sodium pyruvate, and 25 "
+ "mM glucose (Invitrogen, Carlsbad, CA, USA) in a humidified "
+ "atmosphere containing 5% CO2. For precursor and 13C-sugar "
+ "experiments, tissue culture treated polystyrene 35 mm "
+ "dishes (Corning Inc, Lowell, MA, USA) were seeded with 2 "
+ "× 106 cells and grown to confluency in DMEM.";The code that follows is based on the SentenceChunker class, as demonstrated in the previous section. The difference is in the use of the MedlineSentenceModel class:
TokenizerFactory tokenizerfactory = IndoEuropeanTokenizerFactory.INSTANCE;
MedlineSentenceModel sentenceModel = new MedlineSentenceModel();
SentenceChunker sentenceChunker =
new SentenceChunker(tokenizerfactory, sentenceModel);
Chunking chunking = sentenceChunker.chunk(
paragraph.toCharArray(), 0, paragraph.length());
Set<Chunk> sentences = chunking.chunkSet();
String slice = chunking.charSequence().toString();
for (Chunk sentence : sentences) {
System.out.println("["
+ slice.substring(sentence.start(), sentence.end())
+ "]");
}The output is as follows:
[HepG2 cells were obtained from the American Type Culture Collection (Rockville, MD, USA) and were used only until passage 30.] [They were routinely grown at 37°C in Dulbecco's modified Eagle's medium (DMEM) containing 10 % fetal bovine serum (FBS), 2 mM glutamine, 1 mM sodium pyruvate, and 25 mM glucose (Invitrogen, Carlsbad, CA, USA) in a humidified atmosphere containing 5% CO2.] [For precursor and 13C-sugar experiments, tissue culture treated polystyrene 35 mm dishes (Corning Inc, Lowell, MA, USA) were seeded with 2 × 106 cells and grown to confluency in DMEM.]
When executed against medical text, this model will perform better than other models.