
Chapter 1. Text Classification
Text classification is one of the most common tasks in NLP and can be used for applications such as tagging customer feedback into categories or routing support tickets according to their language. Chances are that your email’s spam filter is using text classification to protect your inbox from a deluge of unwanted junk!
Another common type of text classification is sentiment analysis, which aims to identify the polarity of a given text. For example, a company like Telsa might analyze Twitter posts like the one in Figure 1-1 to determine if people like their new roofs or not.

Figure 1-1. Analysing Twitter content can yield useful feedback from customers (image courtesy of Aditya Veluri).
Now imagine that you are a data scientist who needs to build a system that can automatically identify emotional states such as “anger” or “joy” that people express towards your company’s product on Twitter. Until 2018, the deep learning approach to this problem typically involved finding a suitable neural architecture for the task and training it from scratch on a dataset of labeled tweets. This approach suffered from three major drawbacks:
-
You needed a lot of labeled data to train accurate models like recurrent or convolutional neural networks.
-
Training these models from scratch was time consuming and expensive.
-
The trained model could not be easily adapted to a new task, e.g. with a different set of labels.
Nowadays, these limitations are largely overcome via transfer learning, where typically a Transformer-based architecture is pretrained on a generic task such as language modeling and then reused for a wide variety of downstream tasks. Although pretraining a Transformer can involve significant data and computing resources, many of these language models are made freely available by large research labs and can be easily downloaded from the Hugging Face Model Hub!
This chapter will guide you through several approaches to emotion detection using a famous Transformer model called BERT, short for Bidirectional Encoder Representations from Transformers.1 This will be our first encounter with the three core libraries from the Hugging Face ecosystem: Datasets, Tokenizers, and Transformers. As shown in Figure 1-2, these libraries will allow us to quickly go from raw text to a fine-tuned model that can be used for inference on new tweets. So in the spirit of Optimus Prime, let’s dive in, “transform and rollout!”

Figure 1-2. How the Datasets, Tokenizers, and Transformers libraries from Hugging Face work together to train Transformer models on raw text.
The Dataset
To build our emotion detector we’ll use a great dataset from an article2 that explored how emotions are represented in English Twitter messages. Unlike most sentiment analysis datasets that involve just “positive” and “negative” polarities, this dataset contains six basic emotions: anger, disgust, fear, joy, sadness, and surprise. Given a tweet, our task will be to train a model that can classify it into one of these emotions!
A First Look at Hugging Face Datasets
We will use the Hugging Face Datasets library to download the data
from the Hugging Face Dataset Hub. This
library is designed to load and process large datasets efficiently,
share them with the community, and simplify interoperatibility between
NumPy, Pandas, PyTorch, and TensorFlow. It also contains many
NLP benchmark datasets and metrics, such as the Stanford Question
Answering Dataset (SQuAD), General Language Understanding Evaluation
(GLUE), and Wikipedia. We can use the list_datasets function to see
what datasets are available in the Hub:
fromdatasetsimportlist_datasetsdatasets=list_datasets()(f"There are {len(datasets)} datasets currently available on the Hub.")(f"The first 10 are: {datasets[:10]}")
There are 607 datasets currently available on the Hub. The first 10 are: ['acronym_identification', 'ade_corpus_v2', 'aeslc', > 'afrikaans_ner_corpus', 'ag_news', 'ai2_arc', 'air_dialogue', > 'ajgt_twitter_ar', 'allegro_reviews', 'allocine']
We see that each dataset is given a name, so let’s inspect
the metadata associated with the emotion dataset:
metadata=list_datasets(with_details=True)[datasets.index("emotion")]# Show dataset description("Description:",metadata.description,"")# Show first 8 lines of the citation string("Citation:","".join(metadata.citation.split("")[:8]))
Description: Emotion is a dataset of English Twitter messages with six basic
> emotions: anger, fear, joy, love, sadness, and surprise. For more detailed
> information please refer to the paper.
Citation: @inproceedings{saravia-etal-2018-carer,
title = "{CARER}: Contextualized Affect Representations for Emotion
> Recognition",
author = "Saravia, Elvis and
Liu, Hsien-Chi Toby and
Huang, Yen-Hao and
Wu, Junlin and
Chen, Yi-Shin",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in
> Natural Language Processing",
This looks like the dataset we’re after, so next we can load
it with the load_dataset function from Datasets:
fromdatasetsimportload_datasetemotions=load_dataset("emotion")
Note
The load_dataset function can also be used to load datasets from disk. For example, to load a CSV file called my_texts.csv you can use load_dataset("csv", data_files="my_texts.csv").
By looking inside our emotions object
emotionsDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})
we see it is similar to a Python dictionary, with each key corresponding to a different split. And just like any dictionary, we can access an individual split as usual
train_ds=emotions["train"]train_ds
Dataset({
features: ['text', 'label'],
num_rows: 16000
})
which returns an instance of the datasets.Dataset class. This object
behaves like an ordinary Python container, so we can query its length
len(train_ds)
16000
or access a single example by its index
train_ds[0]
{'label': 0, 'text': 'i didnt feel humiliated'}
just like we might do for an array or list. Here we see that a single row is represented as a dictionary, where the keys correspond to the column names
train_ds.column_names
['label', 'text']
and the values to the corresponding tweet and emotion. This reflects the
fact that Datasets is based on Apache Arrow, which defines a typed
columnar format that is more memory efficient than native Python. We
can see what data types are being used under the hood by accessing the
features attribute of a Dataset object:
train_ds.features
{'text': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger',
> 'fear', 'surprise'], names_file=None, id=None)}
We can also access several rows with a slice
train_ds[:5]
OrderedDict([('label', [0, 0, 3, 2, 3]),
('text',
['i didnt feel humiliated',
'i can go from feeling so hopeless to so damned hopeful just from
> being around someone who cares and is awake',
'im grabbing a minute to post i feel greedy wrong',
'i am ever feeling nostalgic about the fireplace i will know that
> it is still on the property',
'i am feeling grouchy'])])
or get the full column by name
train_ds["text"][:5]
['i didnt feel humiliated', 'i can go from feeling so hopeless to so damned hopeful just from being around > someone who cares and is awake', 'im grabbing a minute to post i feel greedy wrong', 'i am ever feeling nostalgic about the fireplace i will know that it is still > on the property', 'i am feeling grouchy']
In each case the resulting data structure depends on the type of query; although this may feel strange at first, it’s part of the secret sauce that makes Datasets so flexible!
So now that we’ve seen how to load and inspect data with Datasets let’s make a few sanity checks about the content of our tweets.
From Datasets to DataFrames
Although Datasets provides a lot of low-level functionality to slice
and dice our data, it is often convenient to convert a Dataset object
to a Pandas DataFrame so we can access high-level APIs for data
visualization. To enable the conversion, Datasets provides a
Dataset.set_format function that allow us to change the output
format of the Dataset. This does not change the underlying data
format which is Apache Arrow and you can switch to another format
later if needed:
importpandasaspdemotions.set_format(type="pandas")df=emotions["train"][:]display_df(df.head(),index=None)
| label | text |
|---|---|
| 0 | i didnt feel humiliated |
| 0 | i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake |
| 3 | im grabbing a minute to post i feel greedy wrong |
| 2 | i am ever feeling nostalgic about the fireplace i will know that it is still on the property |
| 3 | i am feeling grouchy |
As we can see, the column headers have been preserved and the first few
rows match our previous views of the data. However, the labels are
represented as integers so let’s use the
ClassLabel.int2str function to create a new column in our DataFrame
with the corresponding label names:
deflabel_int2str(row,split):returnemotions[split].features["label"].int2str(row)df["label_name"]=df["label"].apply(label_int2str,split="train")display_df(df.head(),index=None)
| label | text | label_name |
|---|---|---|
| 0 | i didnt feel humiliated | sadness |
| 0 | i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake | sadness |
| 3 | im grabbing a minute to post i feel greedy wrong | anger |
| 2 | i am ever feeling nostalgic about the fireplace i will know that it is still on the property | love |
| 3 | i am feeling grouchy | anger |
Before diving into building a classifier let’s take a closer look at the dataset. As Andrej Karpathy famously put it, becoming “one with the data”3 is essential to building great models.
Look at the Class Distribution
Whenever you are working on text classification problems, it is a good idea to examine the distribution of examples among each class. For example, a dataset with a skewed class distribution might require a different treatment in terms of the training loss and evaluation metrics than a balanced one.
With Pandas and the visualisation library Matplotlib we can quickly visualize this as follows:
importmatplotlib.pyplotaspltdf["label_name"].value_counts(ascending=True).plot.barh()plt.title("Category Counts");

We can see that the dataset is heavily imbalanced; the joy and
sadness classes appear frequently whereas love and sadness are
about 5-10 times rarer. There are several ways to deal with imbalanced
data such as resampling the minority or majority classes. Alternatively,
we can also weight the loss function to account for the underrepresented
classes. However, to keep things simple in this first practical
application we leave these techniques as an exercise for the reader and
move on to examining the length of our tweets.
How Long Are Our Tweets?
Transformer models have a maximum input sequence length that is referred to as the maximum context size. For most applications with BERT, the maximum context size is 512 tokens, where a token is defined by the choice of tokenizer and can be a word, subword, or character. Let’s make a rough estimate of our tweet lengths per emotion by looking at the distribution of words per tweet:
df["Words Per Tweet"]=df["text"].str.split().apply(len)df.boxplot("Words Per Tweet",by='label_name',grid=False,showfliers=False,color='black',)plt.suptitle("")plt.xlabel("");
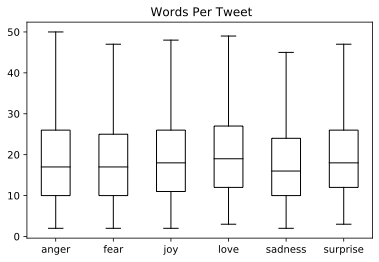
From the plot we see that for each emotion, most tweets are around 15 words long and the longest tweets are well below BERT’s maximum context size of 512 tokens. Texts that are longer than a model’s context window need to be truncated, which can lead to a loss in performance if the truncated text contains crucial information. Let’s now figure out how we can convert these raw texts into a format suitable for Transformers!
From Text to Tokens
Transformer models like BERT cannot receive raw strings as input; instead they assume the text has been tokenized into numerical vectors. Tokenization is the step of breaking down a string into the atomic units used in the model. There are several tokenization strategies one can adopt and the optimal splitting of words in sub-units is usually learned from the corpus. Before looking at the tokenizer used for BERT, let’s motivate it by looking at two extreme cases: character and word tokenizers.
Character Tokenization
The simplest tokenization scheme is to feed each character individually
to the model. In Python, str objects are really arrays under the
hood which allows us to quickly implement character-level tokenization
with just one line of code:
text="Tokenizing text is a core task of NLP."tokenized_text=list(text)(tokenized_text)
['T', 'o', 'k', 'e', 'n', 'i', 'z', 'i', 'n', 'g', ' ', 't', 'e', 'x', 't', ' ', > 'i', 's', ' ', 'a', ' ', 'c', 'o', 'r', 'e', ' ', 't', 'a', 's', 'k', ' ', > 'o', 'f', ' ', 'N', 'L', 'P', '.']
This is a good start but we are not yet done because our model expects each character to be converted to an integer, a process called numericalization. One simple way to do this is by encoding each unique token (which are characters in this case) with a unique integer:
token2idx={}foridx,unique_charinenumerate(set(tokenized_text)):token2idx[unique_char]=idx(token2idx)
{'n': 0, 's': 1, 'k': 2, 'o': 3, 'x': 4, '.': 5, 'N': 6, 'T': 7, 'e': 8, 'g': 9,
> 't': 10, 'r': 11, 'L': 12, 'f': 13, 'a': 14, 'P': 15, 'c': 16, ' ': 17, 'z':
> 18, 'i': 19}
This gives us a mapping from each character in our vocabulary to a
unique integer, so we can now use token2idx to transform the tokenized
text to a list of integers:
input_ids=[token2idx[token]fortokenintokenized_text](input_ids)
[7, 3, 2, 8, 0, 19, 18, 19, 0, 9, 17, 10, 8, 4, 10, 17, 19, 1, 17, 14, 17, 16, > 3, 11, 8, 17, 10, 14, 1, 2, 17, 3, 13, 17, 6, 12, 15, 5]
We are almost done! Each token has been mapped to a unique, numerical
identifier, hence the name input_ids. The last step is to convert
input_ids into a 2d tensor of one-hot vectors which are better suited
for neural networks than the categorical representation of input_ids.
The reason for this is that the elements of input_ids create an
ordinal scale, so adding or subtracting two IDs is a meaningless
operation since the result in a new ID that represents another random
token. On the other hand, the result of the adding two one-hot encodings
can be easily interpreted: the two entries that are “hot” indicate
that the corresponding two tokens co-occur. Each one-hot vector will
have a length the size of the vocabulary and a “1” entry at the
position of each ID, with zeros everywhere else. We can do this directly
in PyTorch by converting input_ids to a torch.Tensor:
importtorchinput_ids=torch.tensor(input_ids)one_hot_encodings=torch.nn.functional.one_hot(input_ids)one_hot_encodings.shape
torch.Size([38, 20])
For each of the 38 input tokens we now have a one-hot vector of
dimension 20 since our vocabularly consists of 20 unique characters. By
examining the first vector we can verify that a 1 appears in the
location indicated by input_ids[0]:
(f"Token: {tokenized_text[0]}")(f"Tensor index: {input_ids[0]}")(f"One-hot vector: {one_hot_encodings[0]}")
Token: T Tensor index: 7 One-hot vector: tensor([0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, > 0])
From our simple example we can see that character-level tokenization ignores any structure in the texts such as words and treats them just as streams of characters. Although this helps deal with misspellings and rare words, the main drawback is that linguistic structures such as words need to be learned, and that process requires significant compute and memory. For this reason, character tokenization is rarely used in practice. Instead, some structure of the text such as words is preserved during the tokenization step. Word tokenization is a straightforward approach to achieve this - let’s have a look at how it works!
Word Tokenization
Instead of splitting the text into characters, we can split it into words and map each word to an integer. By using words from the outset, the model can skip the step of learning words from characters and thereby eliminate complexity from the training process.
One simple class of word tokenizers uses whitespaces to tokenize the
text. We can do this by applying Python’s split function
directly on the raw text:
tokenized_text=text.split()(tokenized_text)
['Tokenizing', 'text', 'is', 'a', 'core', 'task', 'of', 'NLP.']
From here we can take the same steps we took for the character tokenizer
and map each word to a unique identifier. However, we can already see
one potential problem with this tokenization scheme; punctuation is not
accounted for, so NLP. is treated as a single token. Given that words
can include declinations, conjugations, or misspellings, the size of the
vocabulary can easily grow into the millions!
Note
There are variations of word tokenizers that have extra rules for punctuation. One can also apply stemming which normalises the words to their stem (e.g. “great”, “greater”, and “greatest” all become “great”) at the expense of losing some information in the text.
The reason why having a large vocabulary is a problem is that it
requires neural networks with an enormous number of parameters. To
illustrate this, suppose we have 1 million unique words and want to
compress the 1-million dimensional input vectors to 1-thousand
dimensional vectors in the first layer of a neural network. This is a
standard step in most NLP architectures and the resulting weight matrix
of this vector would contain 1 million
Naturally, we want to avoid being so wasteful with our model parameters
since they are expensive to train and larger models are more difficult
to maintain. A common approach is to limit the vocabulary and discard
rare words by considering say the 100,000 most common words in the
corpus. Words that are not part of the vocabulary are classified as
“unknown” and mapped to a shared UNK token. This means that we lose
some potentially important information in the process of word
tokenization since the model has no information about which words were
associated with the UNK tokens.
Wouldn’t it be nice if there was a compromise between character and word tokenization that preserves all input information and some of the input structure? There is! Let’s look at the main ideas behind subword tokenization.
Subword Tokenization
The idea behind subword tokenization is to take the best of both worlds from character and word tokenization. On one hand we want to use characters since they allow the model to deal with rare character combinations and misspellings. On the other hand, we want to keep frequent words and word parts as unique entities.
Warning
Changing the tokenization of a model after pretraining would be catastrophic since the learned word and subword representations would become obsolete! The Transformers library provides functions to make sure the right tokenizer is loaded for the corresponding Transformer.
There are several subword tokenization algorithms such as Byte-Pair-Encoding, WordPiece, Unigram, and SentencePiece. Most of them adopt a similar strategy:
- Simple tokenization
-
The text corpus is split into words, usually according to whitespace and punctuation rules.
- Counting
-
All the words in the corpus are counted and the tally is stored.
- Splitting
-
The words in the tally are split into subwords. Initially these are characters.
- Subword pairs counting
-
Using the tally, the subword pairs are counted.
- Merging
-
Based on a rule, some of the subword pairs are merged in the corpus.
- Stopping
-
The process is stopped when a predefined vocabulary size is reached.
There are several variations of this procedure in the above algorithms and the Tokenizer Summary in the Transformers documentation provides detailed information about each tokenization strategy. The main distinguishing feature of subword tokenization (as well as word tokenization) is that it is learned from the corpus used for pretraining. Let’s have a look at how subword tokenization actually works using the Hugging Face Transformers library!
Using Pretrained Tokenizers
We’ve noted that loading the right pretrained tokenizer for
a given pretrained model is crucial to getting sensible results. The
Transformers library provides a convenient from_pretrained function
that can be used to load both objects, either from the Hugging Face
Model Hub or from a local path.
To build our emotion detector we’ll use a BERT variant
called DistilBERT,4 which is a
downscaled version of the original BERT model. The main advantage of
this model is that it achieves comparable performance to BERT while
being significantly smaller and more efficient. This enables us to train
a model within a few minutes and if you want to train a larger BERT
model you can simply change the model_name of the pretrained model.
The interface of the model and the tokenizer will be the same, which
highlights the flexibility of the Transformers library; we can
experiment with a wide variety of Transformer models by just changing
the name of the pretrained model in the code!
Tip
It is a good idea to start with a smaller model so that you can quickly build a working prototype. Once you’re confident that the pipeline is working end-to-end, you can experiment with larger models for performance gains.
Let’s get started by loading the tokenizer for the DistilBERT model
fromtransformersimportAutoTokenizermodel_name="distilbert-base-uncased"tokenizer=AutoTokenizer.from_pretrained(model_name)
where the AutoTokenizer class ensures we pair the correct tokenizer
and vocabulary with the model architecture.
Note
When you run the from_pretrained function for the first time you will see a progress bar that shows which parameters of the pretrained tokenizer are loaded from the Hugging Face Hub. When you run the code a second time, it will load the tokenizer from cache, usually located at ~./cache/huggingface/.
We can examine a few attributes of the tokenizer such as the vocabulary size:
tokenizer.vocab_size
30522
We can also look at the special tokens used by the tokenizer, which
differ from model to model. For example, BERT uses the [MASK] token
for the primary objective of masked language modeling and the [CLS]
and [SEP] tokens for the secondary pretraining objective of predicting
if two sentences are consecutive:
tokenizer.special_tokens_map
{'unk_token': '[UNK]',
'sep_token': '[SEP]',
'pad_token': '[PAD]',
'cls_token': '[CLS]',
'mask_token': '[MASK]'}
Furthermore, the tokenizer stores the information of the corresponding model’s maximum context sizes:
tokenizer.model_max_length
512
Lets examine how the encoding and decoding of strings works in practice by first encoding a test string:
encoded_str=tokenizer.encode("this is a complicatedtest")encoded_str
[101, 2023, 2003, 1037, 8552, 22199, 102]
We can see that the 4 input words have been mapped to seven integers. When we feed these values to the model, they are mapped into a one-hot vector in a manner analogous to what we saw with character tokenization. We can then translate the numerical tokens back using the decoder:
fortokeninencoded_str:(token,tokenizer.decode([token]))
101 [CLS] 2023 this 2003 is 1037 a 8552 complicated 22199 ##test 102 [SEP]
We can observe two things. First, the [CLS] and [SEP] tokens have
been added automatically to the start and end of the sequence, and
second, the long word complicatedtest has been split into two tokens.
The ## prefix in ##test signifies that the preceding string is not a
whitespace and that it should be merged with the previous token. Now
that we have a basic understanding of the tokenization process we can
use the tokenizer to feed tweets to the model.
Training a Text Classifier
As discussed in Chapter 2, BERT models are pretrained to predict masked words in a sequence of text. However, we can’t use these language models directly for text classification, so instead we need to modify them slightly. To understand what modifications are necessary let’s revisit the BERT architecture depicted in Figure 1-3.
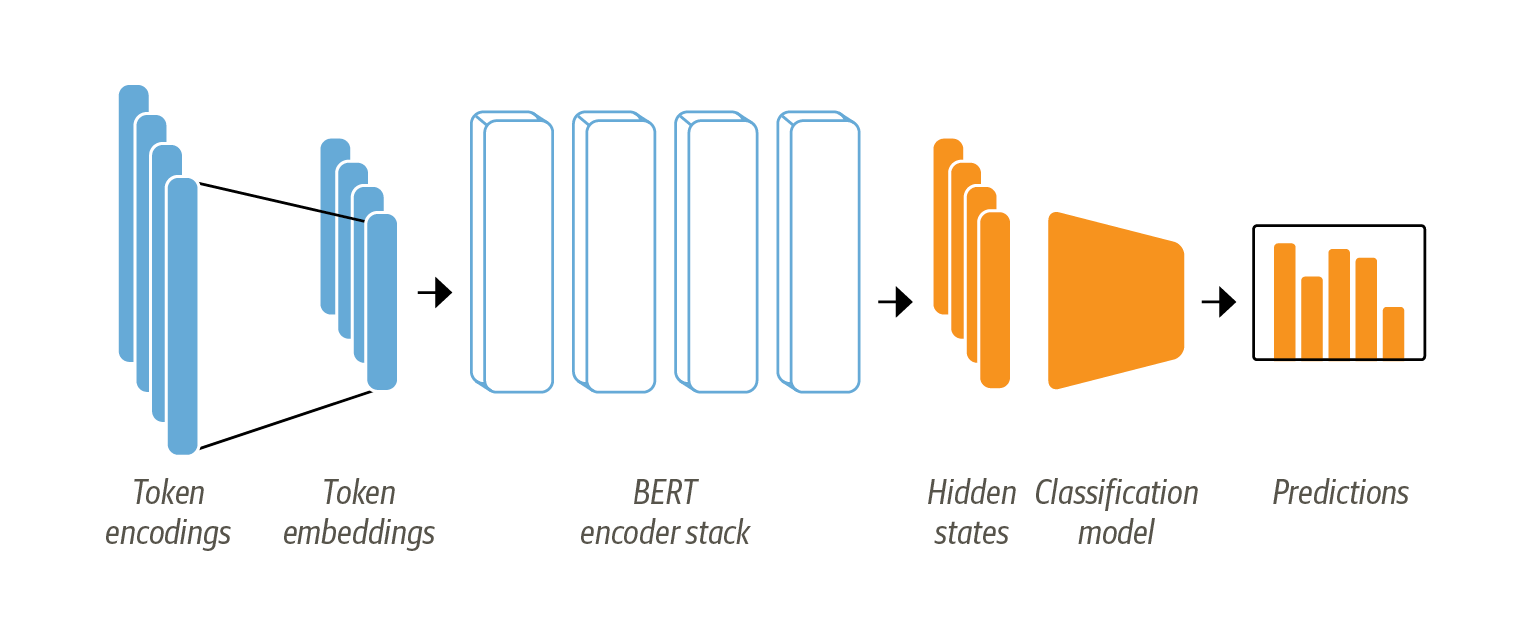
Figure 1-3. The architecture used for sequence classification with BERT. It consists of the model’s pretrained body combined with a custom classification head.
First, the text is tokenized and represented as one-hot vectors whose
dimension is the size of the tokenizer vocabulary, usually consisting of
50k-100k unique tokens. Next, these token encodings are embedded in
lower dimensions and passed through the encoder block layers to yield a
hidden state for each input token. For the pretraining objective of
language modeling, each hidden state is connected to a layer that
predicts the token for the input token, which is only non-trivial if the
input token was masked. For the classification task, we replace the
language modeling layer with a classification layer. BERT sequences
always start with a classification token [CLS], therefore we use the
hidden state for the classification token as input for our
classification layer.
Note
In practice, PyTorch skips the step of creating a one-hot vector because multiplying a matrix with a one-hot vector is the same as extracting a column from the embedding matrix. This can be done directly by getting the column with the token ID from the matrix.
We have two options to train such a model on our Twitter dataset:
- Feature extraction
-
We use the hidden states as features and just train a classifier on them.
- Fine-tuning
-
We train the whole model end-to-end, which also updates the parameters of the pretrained BERT model.
In this section we explore both options for DistilBert and examine their trade-offs.
Transformers as Feature Extractors
To use a Transformer as a feature extractor is fairly simple; as shown in Figure 1-4 we freeze the body’s weights during training and use the hidden states as features for the classifier. The advantage of this approach is that we can quickly train a small or shallow model. Such a model could be a neural classification layer or a method that does not rely on gradients such a Random Forest. This method is especially convenient if GPUs are unavailable since the hidden states can be computed relatively fast on a CPU.
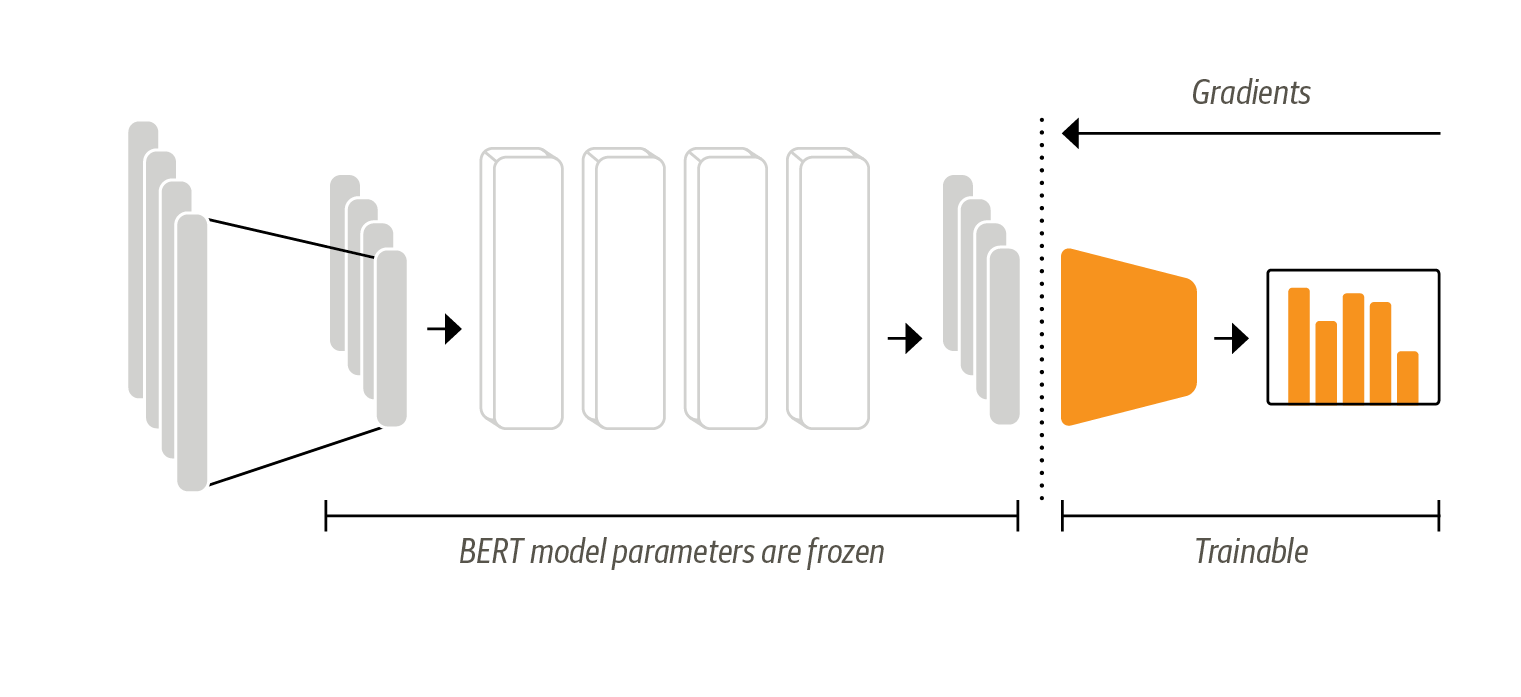
Figure 1-4. In the feature-based approach, the BERT model is frozen and just provides features for a classifier.
The feature-based method relies on the assumption that the hidden states capture all the information necessary for the classification task. However, if some information is not required for the pretraining task, it may not be encoded in the hidden state, even if it would be crucial for the classification task. In this case the classification model has to work with suboptimal data, and it is better to use the fine-tuning approach discussed in the following section.
Using Pretrained Models
Since we want to avoid training a model from scratch we will also use
the from_pretrained function from Transformers to load a pretrained
DistilBERT model:
fromtransformersimportAutoModeldevice=torch.device("cuda"iftorch.cuda.is_available()else"cpu")model=AutoModel.from_pretrained(model_name).to(device)
Here we’ve used PyTorch to check if a GPU is available and
then chained the PyTorch nn.Module.to("cuda") method to the model
loader; without this, we would execute the model on the CPU which can be
considerably slower.
The AutoModel class corresponds to the input encoder that translates
the one-hot vectors to embeddings with positional encodings and feeds
them through the encoder stack to return the hidden states. The language
model head that takes the hidden states and decodes them to the masked
token prediction is excluded since it is only needed for pretraining. If
you want to use that model head you can load the complete model with
AutoModelForMaskedLM.
Extracting the Last Hidden States
To warm up, let’s retrieve the last hidden states for a single string. To do that we first need to tokenize the string
text="this is a test"text_tensor=tokenizer.encode(text,return_tensors="pt").to(device)
where the argument return_tensors="pt" ensures that the encodings are
in the form of PyTorch tensors, and we apply the to(device) function
to ensure the model and the inputs are on the same device. The resulting
tensor has the shape [batch_size, n_tokens]:
text_tensor.shape
torch.Size([1, 6])
We can now pass this tensor to the model to extract the hidden states.
Depending on the model configuration, the output can contain several
objects such as the hidden states, losses, or attentions, that are
arranged in a class that is similar to a namedtuple in Python. In
our example, the model output is a Python dataclass called
BaseModelOutput, and like any class, we can access the attributes by
name. Since the current model returns only one entry which is the last
hidden state, let’s pass the encoded text and examine the
outputs:
output=model(text_tensor)output.last_hidden_state.shape
torch.Size([1, 6, 768])
Looking at the hidden state tensor we see that it has the shape
[batch_size, n_tokens, hidden_dim]. The way BERT works is that a
hidden state is returned for each input, and the model uses these hidden
states to predict masked tokens in the pretraining task. For
classification tasks, it is common practice to use the hidden state
associated with the [CLS] token as the input feature, which is located
at the first position in the second dimension.
Tokenizing the Whole Dataset
Now that we know how to extract the hidden states for a single string, let’s tokenize the whole dataset! To do this, we can write a simple function that will tokenize our examples
deftokenize(batch):returntokenizer(batch["text"],padding=True,truncation=True)
where padding=True will pad the examples with zeroes to the longest
one in a batch, and truncation=True will truncate the examples to the
model’s maximum context size. Previously, we set the output
format of the dataset to "pandas" so that the accessed data is
returned as a DataFrame. We don’t need this output format
anymore so we can now reset it as follows:
emotions.reset_format()
By applying the tokenize function on a small set of texts
tokenize(emotions["train"][:3])
{'input_ids': [[101, 1045, 2134, 2102, 2514, 26608, 102, 0, 0, 0, 0, 0, 0, 0, 0,
> 0, 0, 0, 0, 0, 0, 0, 0], [101, 1045, 2064, 2175, 2013, 3110, 2061, 20625,
> 2000, 2061, 9636, 17772, 2074, 2013, 2108, 2105, 2619, 2040, 14977, 1998,
> 2003, 8300, 102], [101, 10047, 9775, 1037, 3371, 2000, 2695, 1045, 2514,
> 20505, 3308, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1,
> 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1,
> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1,
> 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]}
we see that the result is a dictionary, where each value is a list of
lists generated by the tokenizer. In particular, each sequence in
input_ids starts with 101 and ends with 102, followed by zeroes,
corresponding to the [CLS], [SEP], and [PAD] tokens respectively:
| Special Token | [UNK] | [SEP] | [PAD] | [CLS] | [MASK] |
|---|---|---|---|---|---|
| Special Token ID | 100 | 102 | 0 | 101 | 103 |
Also note that in addition to returning the encoded tweets as
input_ids, the tokenizer also returns list of attention_mask arrays.
This is because we do not want the model to get confused by the
additional padding tokens, so the attention mask allows the model to
ignore the padded parts of the input. See Figure 1-5 for
a visual explanation on how the input IDs and attention masks are
formatted.
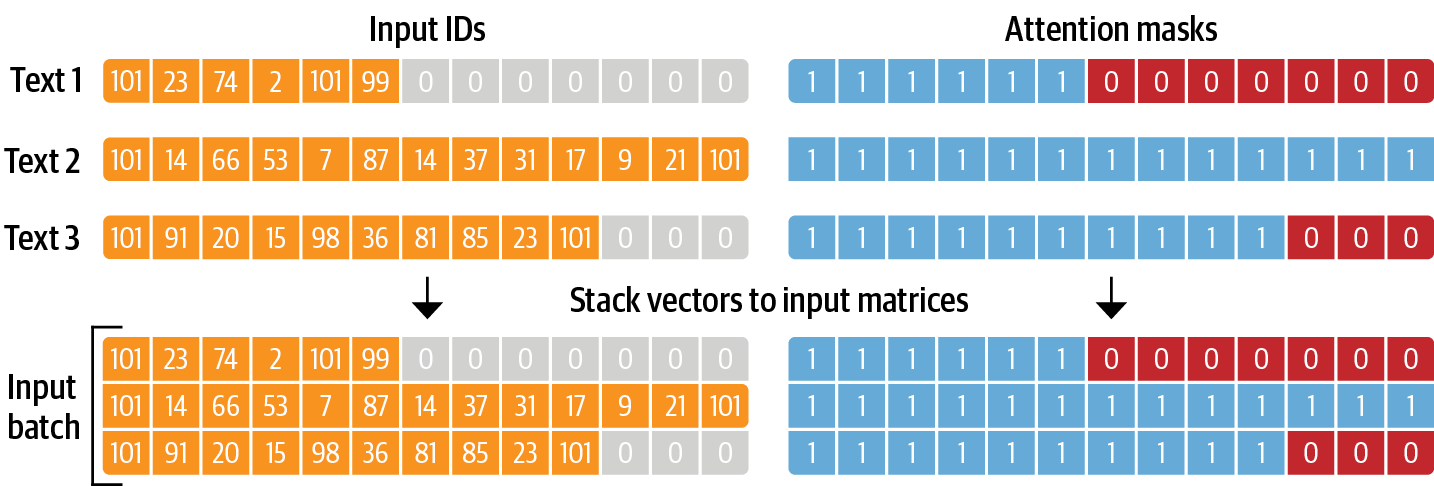
Figure 1-5. For each batch, the input sequences are padded to the maximum sequence length in the batch. The attention mask is used in the model to ignore the padded areas of the input tensors.
Warning
Since the input tensors are only stacked when passing them to the model, it is important that the batch size of the tokenization and training match and that there is no shuffling. Otherwise the input tensors may fail to be stacked because they have different lengths. This happens because they are padded to the maximum length of the tokenization batch which can be different for each batch. When in doubt, set batch_size=None in the tokenization step since this will apply the tokenization globally and all input tensors will have the same length. This will, however, use more memory. We will introduce an alternative to this approach with a collate function which only joins the tensors when they are needed and pads them accordingly.
To apply our tokenize function to the whole emotions corpus,
we’ll use the DatasetDict.map function. This will apply
tokenize across all the splits in the corpus, so our training,
validation and test data will be preprocessed in a single line of code:
emotions_encoded=emotions.map(tokenize,batched=True,batch_size=None)
By default, DatasetDict.map operates individually on every example in
the corpus, so setting batched=True will encode the tweets in batches,
while batch_size=None applies our tokenize function in one single
batch and ensures that the input tensors and attention masks have the
same shape globally. We can see that this operation has added two new
features to the dataset: input_ids and the attention mask.
emotions_encoded["train"].features
{'attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1,
> id=None),
'input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1,
> id=None),
'label': ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger',
> 'fear', 'surprise'], names_file=None, id=None),
'text': Value(dtype='string', id=None)}
From Input IDs to Hidden States
Now that we have converted our tweets to numerical inputs, the next step
is to extract the last hidden states so that we can feed them to a
classifier. If we had a single example we could simply pass the
input_ids and attention_mask to the model as follows
hidden_states = model(input_ids, attention_mask)
but what we really want are the hidden states across the whole dataset.
For this, we can use the DatasetDict.map function again!
Let’s define a forward_pass function that takes a batch of
input IDs and attention masks, feeds them to the model, and adds a new
hidden_state feature to our batch:
importnumpyasnpdefforward_pass(batch):input_ids=torch.tensor(batch["input_ids"]).to(device)attention_mask=torch.tensor(batch["attention_mask"]).to(device)withtorch.no_grad():last_hidden_state=model(input_ids,attention_mask).last_hidden_statelast_hidden_state=last_hidden_state.cpu().numpy()# Use average of unmasked hidden states for classificationlhs_shape=last_hidden_state.shapeboolean_mask=~np.array(batch["attention_mask"]).astype(bool)boolean_mask=np.repeat(boolean_mask,lhs_shape[-1],axis=-1)boolean_mask=boolean_mask.reshape(lhs_shape)masked_mean=np.ma.array(last_hidden_state,mask=boolean_mask).mean(axis=1)batch["hidden_state"]=masked_mean.datareturnbatchemotions_encoded=emotions_encoded.map(forward_pass,batched=True,batch_size=16)
As before, the application of DatasetDict.map has added a new
hidden_state feature to our dataset:
emotions_encoded["train"].features
{'attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1,
> id=None),
'hidden_state': Sequence(feature=Value(dtype='float64', id=None), length=-1,
> id=None),
'input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1,
> id=None),
'label': ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger',
> 'fear', 'surprise'], names_file=None, id=None),
'text': Value(dtype='string', id=None)}
Creating a Feature Matrix
The preprocessed dataset now contains all the information we need to train a clasifier on it. We will use the hidden states as input features and the labels as targets. We can easily create the corresponding arrays in the well known Scikit-Learn format as follows:
importnumpyasnpX_train=np.array(emotions_encoded["train"]["hidden_state"])X_valid=np.array(emotions_encoded["validation"]["hidden_state"])y_train=np.array(emotions_encoded["train"]["label"])y_valid=np.array(emotions_encoded["validation"]["label"])X_train.shape,X_valid.shape
((16000, 768), (2000, 768))
Dimensionality Reduction with UMAP
Before we train a model on the hidden states, it is good practice to
perform a sanity check that they provide a useful representation of the
emotions we want to classify. Since visualising the hidden states in 768
dimensions is tricky to say the least, we’ll use the
powerful UMAP5 algorithm to project the vectors down to 2D. Since UMAP
works best when the features are scaled to lie in the [0,1] interval,
we’ll first apply a MinMaxScaler and then use UMAP to
reduce the hidden states:
fromumapimportUMAPfromsklearn.preprocessingimportMinMaxScalerX_scaled=MinMaxScaler().fit_transform(X_train)mapper=UMAP(n_components=2,metric="cosine").fit(X_scaled)df_emb=pd.DataFrame(mapper.embedding_,columns=['X','Y'])df_emb['label']=y_traindisplay_df(df_emb.head(),index=None)
| X | Y | label |
|---|---|---|
| 6.636130 | 4.465703 | 0 |
| 1.560041 | 4.373974 | 0 |
| 5.782968 | 1.546290 | 3 |
| 2.406569 | 2.855924 | 2 |
| 1.095083 | 6.829075 | 3 |
The result is an array with the same number of training samples, but with only 2 features instead of the 768 we started with! Let us investigate the compressed data a little bit further and plot the density of points for each category separately:
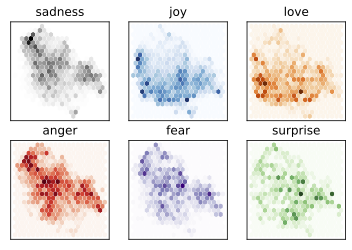
fig,axes=plt.subplots(2,3)axes=axes.flatten()cmaps=["Greys","Blues","Oranges","Reds","Purples","Greens"]fori,(label,cmap)inenumerate(zip(labels,cmaps)):df_emb_sub=df_emb.query(f"label == {i}")axes[i].hexbin(df_emb_sub["X"],df_emb_sub["Y"],cmap=cmap,gridsize=20,linewidths=(0,))axes[i].set_title(label)axes[i].set_xticks([]),axes[i].set_yticks([])
Note
These are only projections onto a lower dimensional space. Just because some categories overlap does not mean that they are not separable in the original space. Conversely, if they are separable in the projected space they will be separable in the original space.
Now there seem to be clearer patterns; the negative feelings such as
sadness, anger and fear all occupy a similar regions with slightly
varying distributions. On the other hand, joy and love are well
separated from the negative emotions and also share a similar space.
Finally, surprise is scattered all over the place. We hoped for some
separation but this in no way guaranteed since the model was not trained
to know the difference between this emotions but learned them implicitly
by predicting missing words.
Training a Simple Classifier
We have seen that the hidden states are somewhat different between the emotions, although for several of them there is not an obvious boundary. Let’s use these hidden states to train a simple logistic regressor with Scikit-Learn! Training such a simple model is fast and does not require a GPU:
fromsklearn.linear_modelimportLogisticRegressionlr_clf=LogisticRegression(n_jobs=-1,penalty="none")lr_clf.fit(X_train,y_train)lr_clf.score(X_valid,y_valid)
0.6405
By looking at the accuracy it might appear that our model is just a bit
better than random, but since we are dealing with an unbalanced
multiclass dataset this is significantly better than random. We can get
a better feeling for whether our model is any good by comparing against
a simple baseline. In Scikit-Learn there is a DummyClassifier that
can be used to build a classifier with simple heuristics such as always
choose the majority class or always draw a random class. In this case
the best performing heuristic is to always choose the most frequent
class:
fromsklearn.dummyimportDummyClassifierdummy_clf=DummyClassifier(strategy="most_frequent")dummy_clf.fit(X_train,y_train)dummy_clf.score(X_valid,y_valid)
0.352
which yields an accuracy of about 35%. So our simple classifier with BERT embeddings is significantly better than our baseline. We can further investigate the performance of the model by looking at the confusion matrix of the classifier, which tells us the relationship between the true and predicted labels:
y_preds=lr_clf.predict(X_valid)plot_confusion_matrix(y_preds,y_valid,labels);

We can see that anger and fear are most often confused with
sadness, which agrees with the observation we made when visualizing
the embeddings. Also love and surprise are frequently mistaken for
joy.
To get an even better picture of the classification performance we can
print Scikit-Learn’s classification report and look at the
precision, recall and
fromsklearn.metricsimportclassification_report(classification_report(y_valid,y_preds,target_names=labels))
precision recall f1-score support
sadness 0.64 0.74 0.69 550
joy 0.73 0.77 0.75 704
love 0.51 0.34 0.41 178
anger 0.54 0.47 0.51 275
fear 0.52 0.55 0.53 212
surprise 0.51 0.32 0.39 81
accuracy 0.64 2000
macro avg 0.58 0.53 0.55 2000
weighted avg 0.63 0.64 0.63 2000
In the next section we will explore the fine-tuning approach which leads to superior classification performance. It is however important to note, that doing this requires much more computational resources, such as GPUs, that might not be available in your company. In cases like this, a feature-based approach can be a good compromise between doing traditional machine learning and deep learning.
Fine-tuning Transformers
Let’s now explore what it takes to fine-tune a Transformer end-to-end. With the fine-tuning approach we do not use the hidden states as fixed features, but instead train them as shown in Figure 1-6. This requires the classification head to be differentiable, which is why this method usually uses a neural network for classification. Since we retrain all the DistilBERT parameters, this approach requires much more compute than the feature extraction approach and typically requires a GPU.
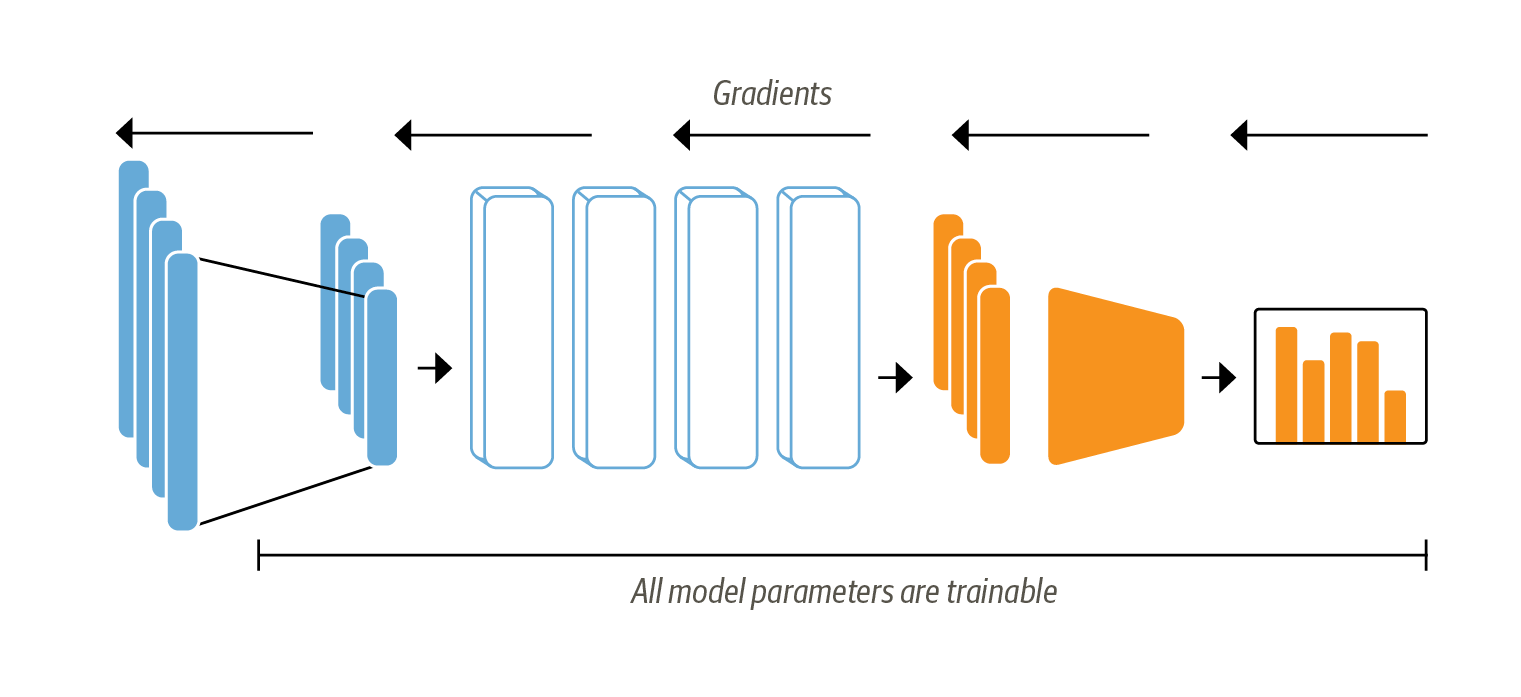
Figure 1-6. When using the fine-tuning approach the whole BERT model is trained along with the classification head.
Since we train the hidden states that serve as inputs to the classification model, we also avoid the problem of working with data that may not be well suited for the classification task. Instead, the initial hidden states adapt during training to decrease the model loss and thus increase its performance. If the necessary compute is available, this method is commonly chosen over the feature-based approach since it usually outperforms it.
We’ll be using the Trainer API from Transformers to
simplify the training loop - let’s look at the ingredients
we need to set one up!
Loading a Pretrained Model
The first thing we need is a pretrained DistilBERT model like the one we
used in the feature-based approach. The only slight modification is that
we use the AutoModelForSequenceClassification model instead of
AutoModel. The difference is that the
AutoModelForSequenceClassification model has a classification head on
top of the model outputs which can be easily trained with the base
model. We just need to specify how many labels the model has to predict
(six in our case), since this dictates the number of outputs the
classification head has:
fromtransformersimportAutoModelForSequenceClassificationnum_labels=6model=(AutoModelForSequenceClassification.from_pretrained(model_name,num_labels=num_labels).to(device))
You will probably see a warning that some parts of the models are randomly initialized. This is normal since the classification head has not yet been trained.
Preprocess the Tweets
In addition to the tokenization we also need to set the format of the
columns to torch.Tensor. This allows us to train the model without
needing to change back and forth between lists, arrays, and tensors.
With Datasets we can use the set_format function to change the data
type of the columns we wish to keep, while dropping all the rest:
emotions_encoded.set_format("torch",columns=["input_ids","attention_mask","label"])
We can see that the samples are now of type torch.Tensor:
emotions_encoded["train"][0]
{'attention_mask': tensor([1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
> 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
'input_ids': tensor([ 101, 1045, 2134, 2102, 2514, 26608, 102, 0,
> 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0]),
'label': tensor(0)}
Define the Performance Metrics
Furthermore, we define some metrics that are monitored during training.
This can be any function that takes a prediction object, that contains
the model predictions as well as the correct labels and returns a
dictionary with scalar metric values. We will monitor the
fromsklearn.metricsimportaccuracy_score,f1_scoredefcompute_metrics(pred):labels=pred.label_idspreds=pred.predictions.argmax(-1)f1=f1_score(labels,preds,average="weighted")acc=accuracy_score(labels,preds)return{"accuracy":acc,"f1":f1}
Training the Model
With the dataset and metrics ready we can now instantiate a Trainer
class. The main ingredient here is the TrainingArguments class to
specify all the parameters of the training run, one of which is the
output directory for the model checkpoints
fromtransformersimportTrainer,TrainingArgumentsbatch_size=64logging_steps=len(emotions_encoded["train"])//batch_sizetraining_args=TrainingArguments(output_dir="results",num_train_epochs=2,learning_rate=2e-5,per_device_train_batch_size=batch_size,per_device_eval_batch_size=batch_size,load_best_model_at_end=True,metric_for_best_model="f1",weight_decay=0.01,evaluation_strategy="epoch",disable_tqdm=False,logging_steps=logging_steps,)
Here we also set the batch size, learning rate, number of epochs, and
also specify to load the best model at the end of the training run. With
this final ingredient, we can instantiate and fine-tune our model with
the Trainer:
fromtransformersimportTrainertrainer=Trainer(model=model,args=training_args,compute_metrics=compute_metrics,train_dataset=emotions_encoded["train"],eval_dataset=emotions_encoded["validation"])trainer.train();
| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|---|---|---|---|---|
| 1 | 0.798664 | 0.305853 | 0.905000 | 0.903347 |
| 2 | 0.244065 | 0.217679 | 0.921000 | 0.921069 |
Looking at the logs we can see that our model has an evaluate method:
results=trainer.evaluate()
results{'eval_loss': 0.2176794707775116,
'eval_accuracy': 0.921,
'eval_f1': 0.9210694523843533,
'epoch': 2.0}
Let’s have a more detailed look at the training metrics by calculating the confusion matrix.
Visualize the Confusion Matrix
To visualise the confusion matrix, we first need to get the predictions
on the validation set. The predict function of the Trainer class
returns several useful objects we can use for evaluation:
preds_output=trainer.predict(emotions_encoded["validation"])
First, it contains the loss and the metrics we specified earlier:
preds_output.metrics
{'eval_loss': 0.13667932152748108,
'eval_accuracy': 0.941,
'eval_f1': 0.9411233837829854}
It also contains the raw predictions for each class. We decode the
predictions greedily with an argmax. This yields the predicted label
and has the same format as the labels returned by the Scikit-Learn
models in the feature-based approach:
y_preds=np.argmax(preds_output.predictions,axis=1)
With the predictions we can plot the confusion matrix again:
plot_confusion_matrix(y_preds,y_valid,labels)

We can see that the predictions are much closer to the ideal diagonal
confusion matrix. The love category is still often confused with joy
which seems natural. Furthermore, surprise and fear are often
confused and surprise is additionally frequently mistaken for joy.
Overall the performance of the model seems very good.
Also, looking at the classification report reveals that the model is also performing much better for minority classes like surprise.
(classification_report(y_valid,y_preds,target_names=labels))
precision recall f1-score support
sadness 0.96 0.96 0.96 550
joy 0.94 0.96 0.95 704
love 0.87 0.87 0.87 178
anger 0.96 0.93 0.94 275
fear 0.92 0.89 0.90 212
surprise 0.87 0.85 0.86 81
accuracy 0.94 2000
macro avg 0.92 0.91 0.91 2000
weighted avg 0.94 0.94 0.94 2000
Making Predictions
We can also use the fine-tuned model to make predictions on new tweets. First, we need to tokenize the text, pass the tensor through the model, and extract the logits:
custom_tweet="i saw a movie today and it was really good."input_tensor=tokenizer.encode(custom_tweet,return_tensors="pt").to("cuda")logits=model(input_tensor).logits
The model predictions are not normalized meaning that they are not a probability distribution but the raw outputs before the softmax layer:
logitstensor([[-0.9604, 3.9607, -0.6687, -1.2190, -1.6104, -1.1041]],
device='cuda:0', grad_fn=<AddmmBackward>)
We can easily make the predictions a probability distribution by applying a softmax function to them. Since we have a batch size of 1, we can get rid of the first dimension and convert the tensor to a NumPy array for processing on the CPU:
softmax=torch.nn.Softmax(dim=1)probs=softmax(logits)[0]probs=probs.cpu().detach().numpy()
We can see that the probabilities are now properly normalized by looking at the sum which adds up to 1.
probsarray([0.0070595 , 0.96823937, 0.0094507 , 0.00545066, 0.00368535,
0.00611448], dtype=float32)
np.sum(probs)
1.0
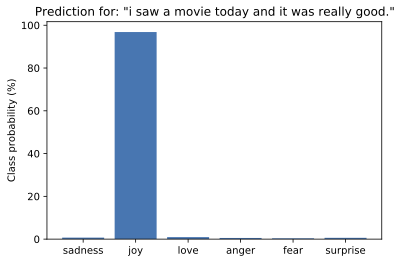
Finally, we can plot the probability for each class in a bar plot.
Clearly, the model estimates that the most likely class is joy, which
appears to be reasonable given the tweet.
plt.bar(labels,100*probs,color='C0')plt.title(f'Prediction for: "{custom_tweet}"')plt.ylabel("Class probability (%)");
Error Analysis
Before moving on we should investigate our model’s prediction a little bit further. A simple, yet powerful tool is to sort the validation samples by the model loss. When passing the label during the forward pass, the loss is automatically calculated and returned. Below is a function that returns the loss along with the predicted label.
fromtorch.nn.functionalimportcross_entropydefforward_pass_with_label(batch):input_ids=torch.tensor(batch["input_ids"],device=device)attention_mask=torch.tensor(batch["attention_mask"],device=device)labels=torch.tensor(batch["label"],device=device)withtorch.no_grad():output=model(input_ids,attention_mask)pred_label=torch.argmax(output.logits,axis=-1)loss=cross_entropy(output.logits,labels,reduction="none")batch["predicted_label"]=pred_label.cpu().numpy()batch["loss"]=loss.cpu().numpy()returnbatch
Using the DatasetDict.map function once more, we apply the function to
get the losses for all the samples:
emotions_encoded.reset_format()emotions_encoded["validation"]=emotions_encoded["validation"].map(forward_pass_with_label,batched=True,batch_size=16)
Finally, we create a DataFrame with the texts, losses, and the
predicted/true labels.
emotions_encoded.set_format("pandas")cols=["text","label","predicted_label","loss"]df_test=emotions_encoded["validation"][:][cols]df_test["label"]=df_test["label"].apply(label_int2str,split="test")df_test["predicted_label"]=(df_test["predicted_label"].apply(label_int2str,split="test"))
We can now easily sort the DataFrame by the losses in either ascending
or descending order. The goal of this exercise is to detect the one of
the following:
- Wrong labels
-
Every process that adds labels to data can be flawed; annotators can make mistakes or disagree, inferring labels from other features can fail. If it was easy to automatically annotate data then we would not need a model to do it. Thus, it is normal that there are some wrongly labeled examples. With this approach we can quickly find and correct them.
- Quirks of the dataset
-
Datasets in the real world are always a bit messy. When working with text it can happen that there are some special characters or strings in the inputs that throw the model off. Inspecting the model’s weakest predictions can help identify such features, and cleaning the data or injecting similar examples can make the model more robust.
Lets first have a look at the data samples with the highest losses:
display_df(df_test.sort_values("loss",ascending=False).head(10),index=None)
| text | label | predicted_label | loss |
|---|---|---|---|
| i as representative of everything thats wrong with corporate america and feel that sending him to washington is a ludicrous idea | surprise | sadness | 7.224881 |
| im lazy my characters fall into categories of smug and or blas people and their foils people who feel inconvenienced by smug and or blas people | joy | fear | 6.525088 |
| i called myself pro life and voted for perry without knowing this information i would feel betrayed but moreover i would feel that i had betrayed god by supporting a man who mandated a barely year old vaccine for little girls putting them in danger to financially support people close to him | joy | sadness | 6.015523 |
| i also remember feeling like all eyes were on me all the time and not in a glamorous way and i hated it | joy | anger | 4.909719 |
| im kind of embarrassed about feeling that way though because my moms training was such a wonderfully defining part of my own life and i loved and still love | love | sadness | 4.789541 |
| i feel badly about reneging on my commitment to bring donuts to the faithful at holy family catholic church in columbus ohio | love | sadness | 4.545475 |
| i guess i feel betrayed because i admired him so much and for someone to do this to his wife and kids just goes beyond the pale | joy | sadness | 4.383130 |
| when i noticed two spiders running on the floor in different directions | anger | fear | 4.341465 |
| id let you kill it now but as a matter of fact im not feeling frightfully well today | joy | fear | 4.177097 |
| i feel like the little dorky nerdy kid sitting in his backyard all by himself listening and watching through fence to the little popular kid having his birthday party with all his cool friends that youve always wished were yours | joy | fear | 4.131397 |
We can clearly see that the model predicted some of the labels wrong. On the other hand it seems that there are quite a few examples with no clear class which might be either mislabelled or require an new class altogether. In particular, joy seems to be mislabelled several times. With this information we can refine the dataset which often can lead to as much or more performance gain as having more data or larger models!
When looking at the samples with the lowest losses, we observe that the
model seems to be most confident when predicting the sadness class.
Deep learning models are exceptionally good at finding and exploiting
shortcuts to get to a prediction. A famous analogy to illustrate this is
the German horse Hans from the early 20th century. Hans was a big
sensation since he was apparently able to do simple arithmetic such as
adding two numbers by tapping the result; a skill which earned him the
nickname Clever Hans. Later studies revealed that Hans was actually
not able to do arithmetic but could read the face of the questioner and
determine based on the facial expression when he reached the correct
result.
Deep learning models tend to find similiar exploits if the features allow it. Imagine we build a sentiment model to analyze customer feedback. Let’s suppose that by accident the number of stars the customer gave are also included in the text. Instead of actually analysing the text, the model can then simply learn to count the stars in the review. When we deploy that model in production and it no longer has access to that information it will perform poorly and therefore we want to avoid such situations. For this reason it is worth investing time by looking at the examples that the model is most confident about so that we can be confident that the model does not exploit certain features of the text.
display_df(df_test.sort_values("loss",ascending=True).head(10),index=None)
| text | label | predicted_label | loss |
|---|---|---|---|
| i feel so ungrateful to be wishing this pregnancy over now | sadness | sadness | 0.015156 |
| im tired of feeling lethargic hating to work out and being broke all the time | sadness | sadness | 0.015319 |
| i do think about certain people i feel a bit disheartened about how things have turned out between them it all seems shallow and really just plain bitchy | sadness | sadness | 0.015641 |
| i feel quite jaded and unenthusiastic about life on most days | sadness | sadness | 0.015725 |
| i have no extra money im worried all of the time and i feel so beyond pathetic | sadness | sadness | 0.015891 |
| i was missing him desperately and feeling idiotic for missing him | sadness | sadness | 0.015897 |
| i always feel guilty and come to one conclusion that stops me emily would be so disappointed in me | sadness | sadness | 0.015981 |
| i feel like an ungrateful asshole | sadness | sadness | 0.016033 |
| im feeling very jaded and uncertain about love and all basically im sick of being the one more in love of falling for someone who doesnt feel as much towards me | sadness | sadness | 0.016037 |
| i started this blog with pure intentions i must confess to starting to feel a little disheartened lately by the knowledge that there doesnt seem to be anybody reading it | sadness | sadness | 0.016082 |
We now know that the joy is sometimes mislabelled and that the model is most confident about giving the label sadness. With this information we can make targeted improvements to our dataset and also keep an eye on the class the model seems to be very confident about. The last step before serving the trained model is to save it for later usage. The Transformer library allows to do this in a few steps which we show in the next section.
Saving the Model
Finally, we want to save the model so we can reuse it in another session or later if we want to put it in production. We can save the model together with the right tokenizer in the same folder:
trainer.save_model("models/distilbert-emotion")tokenizer.save_pretrained("models/distilbert-emotion")
('models/distilbert-emotion/tokenizer_config.json',
'models/distilbert-emotion/special_tokens_map.json',
'models/distilbert-emotion/vocab.txt',
'models/distilbert-emotion/added_tokens.json')
The NLP community benefits greatly from sharing pretrained and fine-tuned models, and everybody can share their models with others via the Hugging Face Model Hub. Through the Hub, all community-generated models can be downloaded just like we downloaded the DistilBert model.
To share your model, you can use the Transformers CLI. First, you will need to create an account on huggingface.co and then login on your machine:
transformers-cli login Username: YOUR_USERNAME Password: YOUR_PASSWORD Login successful Your token: S0m3Sup3rS3cr3tT0k3n Your token has been saved to ~/.huggingface/token
Once you are logged in with your Model Hub credentials, the next step is to create a Git repository for storing your model, tokenizer, and any other configuration files:
transformers-cli repo create distilbert-emotion
This creates a repository on the Model Hub which can be cloned and versioned like any other Git repository. The only subtlety is that the Model Hub uses Git Large File Storage for model versioning, so make sure you install that before cloning the repository:
git lfs install git clone https://huggingface.co/username/your-model-name
Once you have cloned the repository, the final step is to copy all the files from models/distilbert-emotion and then add, commit, and push them to the Model Hub:
cp -r models/distilbert-emotion/ distilbert-emotioncddistilbert-emotion git add .&&git commit -m"Add fine-tuned DistilBERT model for emotion detection"
The model will then be accessible on the Hub at YOUR_USERNAME/distilbert-emotion so anyone can use it by simply running the following two lines of code:
tokenizer=AutoTokenizer.from_pretrained("YOUR_USERNAME/distilbert-emotion")model=AutoModel.from_pretrained("YOUR_USERNAME/distilbert-emotion")
Now we have saved our first model for later. This is not the end of the journey but just the first iteration. Building performant models requires many iterations and thorough analysis and in the next section we list a few points to get further performance gains.
Further Improvements
There are a number of things we could try to improve the feature-based model we trained this chapter. For example, since the hidden states are just features for the model, we could include additional features or manipulate the existing ones. The following steps could yield further improvement and would be good exercises:
-
Address the class imbalance by up- or down-sampling the minority or majority classes respectively. Alternatively, the imbalance could also be adressed in the classification model by weighting the classes.
-
Add more embeddings from different models. There are many BERT-like models that have a hidden state or output we could use such as ALBERT, GPT-2 or ELMo. You could concatenate the tweet embedding from each model to create one large input feature.
-
Apply traditional feature engineering. Besides using the embeddings from Transformer models, we could also add features such as the length of the tweet or whether certain emojis or hashtags are present.
Although the performance of the fine-tuned model already looks promising
there are still a few things you can try to improve it: - We used
default values for the hyperparameters such as learning rate, weight
decay, and warmup steps, which work well for standard classification
tasks. However the model could still be improved with tuning them and
see Chapter 3 where we use Optuna to
systematically tune the hyperparameters. - Distilled models are great
for their performance with limited computational resources. For some
applications (e.g. batch-based deployments), efficiency may not be the
main concern, so you can try to improve the performance by using the
full model. To squeeze out every last bit of performance you can also
try ensembling several models. - We discovered that some labels might be
wrong which is sometimes referred to as label noise. Going back to the
dataset and cleaning up the labels is an essential step when developing
NLP applications. - If label noise is a concern you can also think about
applying label smoothing.6 Smoothing out the
target labels ensures that the model does not get overconfident and
draws clearer decision boundaries. Label smoothing is already built-in
the Trainer and can be controlled via the label_smoothing_factor
argument.
Conclusion
Congratulations, you now know how to train a Transformer model to classify the emotions in tweets! We have seen two complimentary approaches useing features and fine-tuning and investigated their strengths and weaknesses. Improving either model is an open-ended endeavour and we listed several avenues to further improve the model and the dataset.
However, this is just the first step towards building a real-world application with Transformers so where to from here? Here’s a list of challenges you’re likely to experience along the way that we cover in this book:
-
My boss wants my model in production yesterday! - In the next chapter we’ll show you how to package our model as a web application that you can deploy and share with your colleagues.
-
My users want faster predictions! - We’ve already seen in this chapter that DistilBERT is one approach to this problem and in later chapters we’ll dive deep into how distillation actually works, along with other tricks to speed up your Transformer models.
-
Can your model also do X? - As we’ve alluded to in this chapter, Transformers are extremely versatile and for the rest of the book we will be exploring a range of tasks like question-answering and named entity recognition, all using the same basic architecture.
-
None of my text is in English! - It turns out that Transformers also come in a multilingual variety, and we’ll use them to tackle tasks in several languages at once.
-
I don’t have any labels! - Transfer learning allows you to fine-tune on few labels and we’ll show you how they can even be used to efficiently annotate unlabeled data.
In the next chapter we’ll look at how Transformers can be used to retrieve information from large corpora and find answers to specific questions.
1 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, J. Devlin et al. (2018)
2 CARER: Contextualized Affect Representations for Emotion Recognition, E. Saravia et al. (2018)
3 http://karpathy.github.io/2019/04/25/recipe/
4 DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, V. Sanh et al. (2019)
5 UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction, L. McInnes, J. Healy, and J. Melville (2018)
6 See e.g. Does Label Smoothing Mitigate Label Noise?, M. Lukasik et al. (2020).