
Chapter 12. On Analyzing Text
This chapter is about the general problem of analyzing security data consisting of text. Text analysis, particularly log and packet payload analysis, is a consistent unstructured task for security analysts. This chapter provides tools, techniques, and a basic workflow for dealing with the problem of semistructured text analysis.
I use the term semistructured to refer to data such as DNS records and logs. This contrasts with unstructured text (text for human consumption, like this book) in that there are well-defined rules for creating the text. With semistructured text, some enterprising developer wrote a series of logical statements and templates for generating every conceivable result. However, in comparison to fully structured data, those logical statements and templates are often opaque to the security analyst.
This chapter is divided into three main sections. The first section discusses text encoding and its impact on security data. The second section discusses basic skills that an analyst should expect to have for processing this data—this is primarily represented as a set of Unix utilities and the corresponding mechanisms in Python. The third section discusses techniques for analyzing and comparing text; these are standard text processing techniques, largely focused on the problem of finding similarity. This section also discusses security-specific text encoding problems: in particular, obfuscation and homoglyphs.
Text Encoding
Encoding refers to the rules that tell a computer that it should display the value 65 with the image A, and that the value 0x43E is displayed as о. Current systems rely heavily on the Unicode encoding standard, usually encoded as UTF-8, but in order to maintain backward compatibility, an enormous legacy infrastructure exists on top of this.
Text encoding requires managing a vast number of corner cases and
legacy processing. The plethora of standards leads to ambiguity, and
attackers thrive on ambiguity. Information passing between two hosts
will be encoded multiple times, often implicitly. For example, HTTP
supports implicit compression (usually with gzip or deflate); if your
inline packet inspector isn’t aware of that, then the attacker just
has to kick in the right compression algorithm and continue onward.
This is effectively an arms race, with the attacker looking for more obscure
obfuscators and the defender looking for more defenses.1
Unicode is a character set—it is an index that associates each character with a single numerical value (a code point). An encoding is a mechanism for representing these numbers in a standardized binary form. A character is not an image; instead, it’s the idea behind a family of images, the way a mathematical point is the idea behind the dot you draw on a blackboard. The equivalent of that blackboard dot is a glyph; glyphs are what you see on screen. A glyph is the representation of a character that is indexed by a code point.
The reason for the distinction between character and glyph is because different encoding schemes may handle the same representations very differently. Encoding schemes don’t simply have to handle images—they contain control characters, possibly even sounds (the BEL character in ASCII is an example). In addition, the same glyph may be represented by radically different encodings; for example, a character such as ä may, depending on the encoding scheme, be represented by a code point for “a with umlaut,” by an “a” followed by an umlaut, or by an “a”, followed by a non-deleting backspace and an umlaut.
Finally, and this is a critical legacy issue, the distinction between a code point and its encoding is not necessarily as clear outside of the Unicode world. Unicode does not make an assumption about how code points are represented—that’s a task for encoding schemes such as UTF-8 or UTF-16. Conversely, Windows code pages, macOS code pages, and the ISO standards make assumptions about numeric representation.2
History and legacy are important issues here. The encoding world’s history is breakable into two epochs: before Unicode and after Unicode. In the pre-Unicode world, encoding standards developed within individual countries and proprietary platforms. This meant that communicating between hosts using different coding standards involved navigating multiple incompatible drivers and arcane character sets, sometimes chosen for intentional incompatibility.3 Major computer companies also maintained their own standards—Apple and Microsoft have their own code page tables with distinct indices for different character sets. Incompatibilities were often so bad that software was forked just to handle a specific encoding scheme, because the assumptions of an ASCII-dominated world would cause buffer overflows when dealing with 16-bit code points. The Unicode standard was designed to deal with all of these problems. Unicode does for characters what IPv6 does for addresses—provide so many slots that everything from Amharic (U+1200) to Engsvanyali (U+E1004) is consistently represented.
Unicode supplanted, but did not replace, these legacy standards.5 Today, for compatibility reasons Japanese systems and web pages will recognize JIS, Russian ones will recognize KOI8, and so on. To some extent, the world is divided into encoding standards—there are tools that Chinese-language users rely on that users who work with the Roman script will never know about, and there is malware specifically for those tools. Table 12-1 tries to unify this Babel into a coherent whole by providing a list of major character sets, their code pages, and legacy encoding schemes.
| Character set | Unicode code page | Legacy encodings | Notes |
|---|---|---|---|
Roman |
U+0000 |
ASCII, ISO-8859-XX, ISO-Latin-1, Mac OS Roman |
ASCII isn’t able to handle accent characters, so languages like French and Spanish had to move to other standards. |
Chinese |
U+4E00 |
GuoBiao, EUC-CN, Big5 |
The Unicode page is the CJK (Chinese-Japanese-Korean) set. GuoBiao is PRC, Big5 is Taiwan and HK. |
Japanese |
U+3040 |
JIS, EUC-JP |
The code page is specifically for kana, while JIS standards include kana and kanji. |
Cyrillic |
U+0400 |
KOI8-X, Windows-1251, ISO-8859-5 |
This includes Russian, Ukrainian, and Tajik. |
Korean |
U+AC00, U+1100 |
EUC-KR, KS X 1001 |
U+AC00 is the syllabary, U+1100 is the individual jamo. North Korea has its own standard. a |
Arabic |
U+0600 |
U+0600 is the base set, but Arabic is scattered about the standard. |
|
a KPS 9566-97. | |||
Unicode, UTF, and ASCII
As noted previously, Unicode isn’t an encoding scheme, it is a standard for relating code points to characters. The Unicode standard specifies up to 1,114,112 code points, each of which is stored in one of 16 65,536-point code planes. We care primarily about plane zero, which contains all the characters in the sets listed in Table 12-1.
Encoding, which is to say the process of actually representing the characters, is managed primarily via UTF-8 (Unicode Text Format, RFC 3629). UTF-8 is a variable-length encoding scheme specifically designed to handle a number of problems involved in transmission and in its predecessor standard, UTF-16. This means that Unicode encoding has a number of header and delimiter conventions that limit the efficiency of the system. The value 129, for instance, is going to stretch across 2 bytes. The following example shows this in action, as well as the germane Python commands:
# This is done in Python 2.7; the Python 3 version merges the uni*
# functions for ease of use.
>>> s=unichr(4E09)
# unichr is the Unicode equivalent of chr; note that I enter the
# hexadecimal index. All it cares about is the index value.
>>> print(s)
三
>>> print(unichr(19977))
三
# print is important, direct text dump is going to give me the
# abstract Unicode encoding that Python uses. Note the u and u
# characters. The u before the string indicates it's Unicode,
# the u indicates it's an unsigned sixteen bit--Python effectively
# uses UTF-16 internally for representation.
>>> s
u'u4e09'
# Now, let's convert from utf-16 to utf-8.
>>> s.encode('utf-8')
'xe4xb8x89'
# Note that this is 3 bytes; a utf-8 representation includes
# overhead to describe the data provided. Let's compare it
# with vanilla ASCII.
>>> s=u'a'
>>> print s
a
>>> s
a
# Note that we're in ASCIIland and it's treated as a default.
>>> s.encode('utf-8')
'a'
>>> ord(s)
97
Note that in the example, as soon as I went to the a character, the encoding function and everything else dropped all of the hexadecimal and integer encoding. UTF-8 is backward compatible with ASCII (American Standard Code for Information Interchange), the 7-bit6 character encoding standard.
Encoding for Attackers
Having discussed the general role of encoding, now let’s talk about the role of encoding for an attacker. For attackers, encoding is a tool for evasion, slipping information past filters intended to stop them, delaying defenders from figuring out that something is amiss. To that end, the attackers can rely on a number of different techniques to manipulate encoding, abetted by the implicit dependencies encoding strategies have.
Base64 encoding
Base encoding7 is an encoding technique originally developed for email that currently serves as a workhorse for data transfer, including malware.
The goal of base64 encoding is to provide a mechanism for encoding arbitrary binary values using commonly recognized characters. To do so, it maps binary values to values between 0 and 63, assigns each code point a common, easily recognizable character, and then encodes the values using that character. The base64 encoding standard involves 64 code points representing the characters A–Z, a–z, and 0–9, and two characters that differ by standard—we’ll say + and / for now.
Figure 12-1 shows the basic process of base64 encoding. Note that the process includes a padding convention; when working with bytes, base64 encoding neatly transfers 3 bytes into 4 characters. If your string isn’t a multiple of three, you’ll need to zero-pad up to three and then add equals signs at the end of the encoded string to indicate this.

Figure 12-1. Base64 encoding in action
Base64 encoding is cheap and omnipresent; Python includes a standard
library in the form of base64, and JavaScript has btoa and atob
functions to handle it. This makes it a pretty easy and quick way to
hide text directly.
In addition to base64, HTML natively supports a completely different encoding, called numeric character references (NCRs). Numeric character references encode values using the format &#DDDD;, where DDDD is the index of the corresponding code point in Unicode. NCRs can use decimal (e.g., 三) or hex (e.g., �x4E09;).
The fastest way to identify base64 is to look for characters that base64 doesn’t cover, but which you expect to see: commas, spaces, periods, and apostrophes. Long sequences of text without those will be unusual. NCRs are recognizable by the use of ampersands.
Informal encoding/obfuscation
Introduce rules, and people are going to find ways around them. Informal encoding schemes pop up because people are looking for quick-and-dirty ways to evade a detection or filtering technique, then they become ossified and just part of a culture. There are no real rules here, just some rubrics I’ve seen over time that are worth at least noting.
The most common immediate tricks are simple reversals and appending. For example, it’s been an old trick for years to rename .zip files with a .piz extension to trick filters into passing them. Similarly, I regularly see users just append numbers to strings.
Given enough time, substitutions can become more formal. The most common example of this is leetspeak and its cousins; whenever I see 1337 show up somewhere, I raise an eyebrow. It’s not that leetspeak (properly 1337sp3ak, more properly l33tsp34k, even more properly 1337sp34|<) is an attack technique, but it’s one of those forehead-slapping flags that I’ve run into too many times not to pay attention to. There aren’t hard and fast rules for leetspeak, but there are common behaviors. 3, 4, 7, and 1 are used for e, a, t, and l; z is usually substituted for s. 0 is used to indicate 0, ah, and u noises (as in hax0rz, pr0n, and n00bs).
Compression
An easy and robust mechanism for evading detection is to simply compress the files, maybe throwing in a garbage datafile with each instance to change the resulting compressed payload. This is not a new problem, and many deep packet inspection tools these days will include a half dozen common unpackers specifically to deal with it.
That said, the beauty of compression (for attackers) is that people are constantly building new compressors. It’s easy for an attacker to go find a new archive format, harder for defenders to recognize that archived data is in a new format and figure out what the decompressor is. Table 12-2 is a list of common archiving formats.
| Name | Extension | Notes |
|---|---|---|
ZIP |
.zip |
By far the most prevalent compression scheme, from PKZIP |
GZIP |
.gz |
The GNU version of ZIP |
TAR |
.tar |
TApe aRchive, not a compression scheme but a multifile archiving utility |
TAR-GZIP |
.tgz |
TAR with GZIP, ubiquitous on Unix systems |
CAB |
.cab |
A Microsoft archiving format including compression and certificates |
ARC |
.arc |
ARChive format, antique but occasionally seen |
UPX |
.upx |
Ultimate Packer for eXecutables; a PE compressor |
7ZIP |
.7z |
An efficient but slow compression algorithm |
RAR |
.rar |
Common on Windows systems (winRAR) |
LZO |
.lzo |
Compact and fast |
Of particular note when looking at compression algorithms are executable compressors such as UPX, Themida, and ASPack. These systems pack the datafile and the decompressor into a single executable package. Executable compressors are attractive because they’re easily portable—the attacker can bring the whole shebang across the network rather than having to transfer a decompressor separately.
Encryption
Checking the entropy of a sample is a relatively quick-and-dirty way to identify that traffic is encrypted. Properly encrypted data should have a high entropy; there is a potential false positive in that the data may be compressed, but this should be identifiable by looking for the corresponding headers indicating the type of compression.
Basic Skills
In this section, I will review a basic set of skills for processing and manipulating text. In the field, analysts will usually work with a combination of command-line Unix tools and functions within a scripting language. Consequently, this section largely consists of examples within both environments. Both Unix and Python have an enormous number of text processing tools, and the references at the end of the chapter will provide additional reading material.
This section is skill-based rather than tool-based. That is, each subsection covers a specific problem and ways to handle it in Unix or Python.
Finding a String
The go-to tool for finding a particular string is grep (the generalized regular expression processor). When using grep, remember that its default input is regular expressions—consequently, when entering IP addresses, you can run into overmatches. For example:
$ grep 10.16 http_example.txt | grep '10:16' 10.147.201.99 - - [17/Sep/2016:10:16:14 -0400] "HEAD / HTTP/1.1" 200 221 "-" "-" 10.147.201.99 - - [17/Sep/2016:10:16:16 -0400] "GET / HTTP/1.1" 200 2357 "-" "-" $ grep 10.16 http_example.txt | grep -v '10:16' | head -1 10.16.94.206 - - [18/Sep/2016:05:57:16 -0400] "GET /helpnew/faq/faq_simple_zh_CN.jsp HTTP/1.1" 404 437 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36"
Since the . character is a wildcard in regular expressions, grep looks for both the address and the time signature. Ensure that you match a literal dot using the . construct:
$ grep '10.16' http_example.txt | head -1
10.16.94.206 - - [18/Sep/2016:05:57:16 -0400]
"GET /helpnew/faq/faq_simple_zh_CN.jsp HTTP/1.1" 404 437 "-"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36"
Python strings support two searching methods: find and index. Of the two, I prefer find over index purely because index raises an exception when it fails to find a string. I’m intentionally avoiding discussing the re library for now; I’ll discuss regular expressions a bit more later.
Manipulating Delimiters
The tr tool provides a number of handy utilities for splitting delimiters. Without other switches, tr will do an ordered substitution of the contents of one list with another list. Here’s an example of how this works:
$ echo 'dog cat god' | tr 'dog' 'bat' bat cat tab
As the example shows, tr transposes the individual characters, not the entire string. To do this in Python, you need to use a string’s .translate method. This method takes a translation table, which is best generated using the maketrans function from the string library. Here’s an example:
>>> from string import maketrans
>>> 'dog cat god'.translate(maketrans('dog','bat'))
'bat cat tab'
tr includes a number of other handy routines, the most important one being -s. The squeeze operation will reduce multiple copies of a specified character down to one, particularly important when working with spaces. For example:
$ echo 'a||b|c' | tr -s '|' a|b|c
The most Pythonic way to do this is to split the series into a list, filter out empty elements, and then join the list using the original delimiter. For example:
>>> '|'.join(filter(bool, 'a||b|c'.split('|')))
'a|b|c'
Splitting Along Delimiters
cut is capable of splitting files along delimiters, characters, bytes, or other values as needed. To use delimiters, specify a -d argument and then a -f for the fields:
$ echo 'a|b|c' | cut -d '|' -f 3,1 a|c
Note that -f doesn’t pay attention to the ordering—you get the fields in the order they appear in the file. Also note that the -d argument takes a single character.
In Python, the .split method converts strings to lists, after which you can manipulate them as normal. Given how Python slicing works, it’s generally preferable to use the itemgetter function after that to get ordered elements:
>>> from operator import itemgetter
>>> itemgetter(2,1,5)('a|b|c|d|e|f'.split('|'))
('c', 'b', 'f')
In passing, NumPy arrays provide an arbitrary selection operator via double brackets ([[).
Regular Expressions
Regular expressions are the most powerful tool directly available for
text analysis. In this section, I will provide a very brief overview
of their use, as well as some rules for ensuring that they don’t get
out of hand. In general, my largest caution about using regular
expressions is that they are very expensive—regular expressions are
effectively an interpreted programming language for matching text, and
there are often much more effective and faster mechanisms for achieving
the same results, such as tr.
A regular expression is a sequence of characters specifying how to match another sequence of characters. In its simplest form, a regular expression is just a string. Here is an example of regular expression matching in Python:
>>> import re
>>> re.search('foo','foobar')
<_sre.SRE_Match object at 0x100431cc8>
>>> re.search('foo','waffles')
Python regular expressions are implemented by the re library. As
this example shows, a successful regular expression search will return
a match object; a failure of the search function will return None.
The re library contains three key functions: search, match, and
findall. search searches through the target string and terminates
on the first match; match succeeds only on an exact match. Both
search and match return match objects on success, or None on failure.
findall will search for every instance of a regular expression and return a list of successful matches:
>>> re.match('foo','foobar')
<_sre.SRE_Match object at 0x100431cc8>
>>> re.match('foo','barfoo')
# Note the failure; this is because of the positioning of foo - the characters
# bar precede it.
>>> re.search('foo','foobar')
<_sre.SRE_Match object at 0x1004318b8>
>>> re.search('foo','barfoo')
<_sre.SRE_Match object at 0x100431cc8>
# Search works because it isn't an exact match
>>> re.findall('foo','foofoo')
['foo', 'foo']
Regular expressions provide a rich language for wildcarding. The most
basic wildcards involve the use of the ., ?, +, and * characters.
. specifies a match for a single character, while the other three
specify the order of the match. ? indicates zero or one
instances, + one or more, and * zero or more:
>>> re.findall('foo.+','foo foon foobar')
['foo foon foobar']
>>> re.findall('foo.?','foo foon foobar')
['foo ', 'foon', 'foob']
>>> re.findall('foo.','foo foon foobar')
['foo foon foobar']
>>> re.findall('foo*','foo foon foobar')
['foo', 'foo', 'foo']
>>> re.findall('foo.*','foo foon foobar')
['foo ', 'foon', 'foob']
Instead of simply matching on one or more characters, regular expressions can be grouped into parentheses. The order characters can then be applied to the whole expression:
>>> re.findall('f(o)+','foo foooooo')
['o', 'o']
>>> re.findall('f(o)+','foo')
['o']
When you use a group, the matches will only return the characters in the group. This is handy for extracting specific terms. For example:
>>> re.findall('To: (.+)','To: Bob Smith <[email protected]>')
['Bob Smith <[email protected]>']
>>> re.findall('To: (.+) <','To: Bob Smith <[email protected]>')
['Bob Smith']
>>> re.findall('To: (.+) <(.*)>','To: Bob Smith <[email protected]>')
[('Bob Smith', '[email protected]')]
Groups can also express a number of options, via a bar, and a specific number of instances by putting the range in curly braces:
>>> re.findall('T(a|b)','To Ta Tb To Tb Ta')
['a', 'b', 'b', 'a']
>>> re.findall('T(a){2,4}','To Ta Taa Taaa')
['a', 'a']
Square brackets are used to match a range of characters:
>>> re.findall('f[abc]','fo fa fb fo fc')
['fa', 'fb', 'fc']
Finally, a couple of special notes. The ^ and $ symbols are used to match the beginning and end of a string:
>>> re.findall('^f[o]+','foo fooo')
['foo']
>>> re.findall('f[o]+','foo fooo')
['foo', 'fooo']
>>> re.findall('f[o]+$','foo fooo fo')
['fo']
You can match any of the control characters (e.g., {, +, etc.) by
slapping a in front of them:
>>> re.findall('a+.','ab a+b')
['a+b']
That was a very basic introduction to regular expressions, but I’ll also make some practical observations.
First, if you’re using regular expression matching with a new tool,
check to see how much regular expression parsing the tool does. At the
minimum, regular expressions tend to be broken into a basic syntax, an
extended syntax (ERE), and PCRE (Perl Compatible Regular Expression)
syntax. The default grep tool, for example, doesn’t recognize
extended syntax, so the first command here produces no output:
$ echo 'foo' | grep 'fo.?' $ echo 'foo' | egrep 'fo.?' foo
Most modern environments will use ERE, and everything I’ve discussed
in this chapter should work if the parser recognizes ERE. PCRE, yet
more powerful, usually requires additional libraries, and there is a
standard PCRE tool (pcregrep) for parsing those expressions. If you
expect to be doing a lot of Unicode work, I suggest going straight to
PCRE.
Second, keep notes. Outside of one-off parsing, you’re most likely going to use regular expressions to repeatedly parse and normalize logfiles as part of the analysis infrastructure. The logfile format changes, regular expressions fail, and you’re left trying to figure out what that string of line noise actually means. A useful aid to this documentation process is to use capture groups, to ensure that you can track what you’re watching for.
Third, use regular expressions for what they’re good for, and keep them
simple. Matching string. is an expensive way to match string. As
a rule of thumb, if I’m not doing something at least as complex as a conditional
(e.g., (a|b)) or a sequence count (e.g., a{2,3}), I’m looking
for a simpler approach. Regular expressions are expensive—many
common tasks, such as squeezing spaces, are three to four times slower using REs.
Finally, if you’re working in Python, make sure you’re compiling, and know
the difference between match and search and findall. Since
match requires that you express the full string, it tends to
necessitate a considerable amount more complexity and performance than
search does.
Techniques for Text Analysis
In this section, I will discuss numerical techniques applying the tools and approaches discussed earlier in this chapter. The following techniques are a grab back of mechanisms for processing data, and are often used in combination with each other.
N-Gram Analysis
An n-gram is a sequence of n or more tokens. For example, when parsing characters in a text string, an n-gram will be n or more individual characters in sequence, such as turning “waffles” into the trigrams “waf”, “aff”, “ffl”, “fle”, and “les”. The same principle can be used for words in a sentence (“I have”, “have pwnd”, “pwnd your”, “your system”) or any other token.
The key feature of n-gram decomposition is the use of this sliding window. n-gram decompositions produce a lot of strings from a single source, and the process of analyzing the n-grams is computationally expensive. However, n-gram analysis is, in my experience, a very good “I don’t know what’s in this data yet” technique when you’re looking at previously unknown piles of text. With many of the following distance techniques, you may use them interchangeably with the original strings or with n-grams.
Jaccard Distance
Of the three comparison metrics I will discuss in this section, the Jaccard distance is the cheapest to implement, but also the least powerful. Given two strings, A and B, the Jaccard distance is calculated as the ratio of the intersection of A and B over the union of A and B. Jaccard distance is trivial to calculate using Python’s set operators, as shown here:
def jaccard(a,b):
"""
Given two strings a and b, calculate the Jaccard distance
between them as characters
"""
set_a = set(a)
set_b = set(b)
return float(len((set_a.intersection(set_b))))/float(len(set_a.union(set_b)))
Jaccard distance is quick to implement, and it’s easy to implement a very fast version of the set when you know all the potential tokens. It’s also normalized: a value of 0 indicates no characters in common, and 1 indicates that all characters are in common. That said, it’s not a very powerful distance metric—it doesn’t account for duplicated characters, string ordering, or the presence of substrings, so the strings “foo” and “ofoffffoooo” are considered as identical as “foo” and “foo”.
Hamming Distance
The Hamming distance between two strings of identical length is the total number of individual characters within those strings that differ. This is shown in Python in the following example:
def hamming(a,b):
"""
Given two strings of identical length, calculate the Hamming
distance between them.
"""
if len(a) == len(b):
return sum(map(lambda x:1 if x[0] == x[1] else 0, zip(a,b)))
else:
raise Exception, "Strings of different length"
Hamming distance is a powerful similarity metric. It’s fast to calculate, but it’s also restricted by string size, and the lack of normalization means that the values are a little vague. In addition, when you calculate a Hamming distance, you have to be very clear about what your definition of a different token is. For example, if you decide to use individual bits as a distance metric, you will find that UTF-16 encodings and UTF-8 encodings of the same strings will have different values due to the encoding overheads!
Levenshtein Distance
The Levenshtein distance between two strings is described as the minimum number of single character operations (insertions, deletions, or character substitutions) required to change one string to another string. For example, the strings “hax0r” and “hacker” have a Levenshtein distance of 3 (add a c before the x, change x to k, change 0 to e).
Levenshtein distance is one of those classic “let’s learn dynamic
programming” examples, and is a bit more complex than I want to dive
into in this chapter. The levenshtein function in
text_examples.py provides an example of how to implement this
distance metric.
Levenshtein distance is sensitive to substrings and placement in ways that Hamming distance isn’t. For example, the strings “hacks” and “shack” have a Hamming distance of 5 but a Levenshtein distance of 2 (add an s at the beginning, drop an s from the end). However, it’s a considerably more computationally expensive algorithm to implement than Hamming distance, and you may end up paying a performance cost for identifying phenomena that are discernible using a cheaper algorithm.
Entropy and Compressibility
The entropy (properly, Shannon entropy) of a signal is the probability that a particular character will appear in a sample of that signal. This is mathematically formulated as:

That is, the sum over all the observed symbols of their probabilities by their information content (the log of their entropy).
The entropy as formulated here describes the number of bits required to describe all of the characters observed in a string. So, the entropy of the string “abcd” would be 2 (there are four unique symbols), and the entropy of the string “abcedfgh” would be 3 (8 unique symbols). Signals that are high-entropy are noisy—they look like the data is randomly generated, as the probability of seeing any particular token is largely even. Low-entropy signals are biased toward repeated patterns; as a rule of thumb, low-entropy data is structured, has repeated symbols, and is compressible.
Natural language is low-entropy, and most logfiles are low-entropy; compressed data is high-entropy (compression is about finding entropy and exploiting it), and encrypted data is high-entropy (because the goal is to look like noise). Figure 12-3 shows this phenomenon in more depth; this figure shows the results, respectively, of compressing and encrypting data (in this case, 10,000-character samples of the complete works of Shakespeare). As the example illustrates, the entropy of natural-language text hovers at around 5 bits/character, while that of compressed and encrypted data is approximately 8 bits/character.
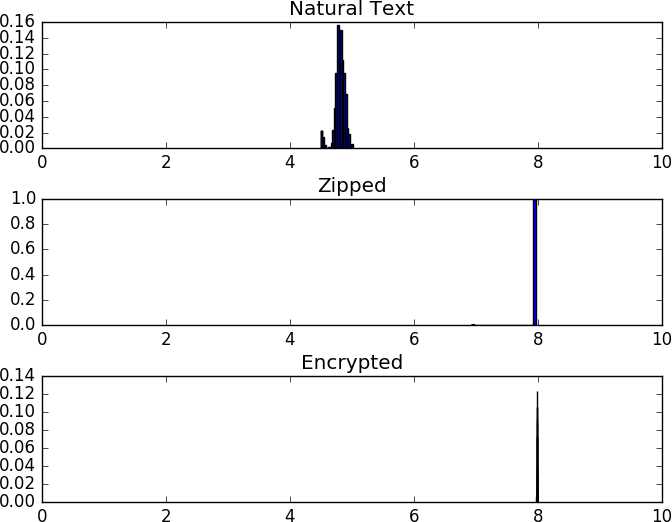
Figure 12-3. A comparison of entropy for different systems
Selectively sampling and approximating entropy is a good quick-and-dirty technique to check for compression or encryption on a dataset.
Homoglyphs
In http_example.txt, there’s a line that reads:
10.193.9.88 - - [19/Sep/2016:19:36:11 -0400] "POST /wp-loаder.php HTTP/1.1" 404 380 "-" "Mozilla/5.0 (Windows NT 6.0; rv:16.0) Gecko/20130722 Firefox/16.0"
Let’s look for it:
$ cat http_example.txt | grep loader $ cat http_example.txt | grep 10.193.9.88 10.193.9.88 - - [19/Sep/2016:19:36:11 -0400] "POST /wp-loаder.php HTTP/1.1" 404 380 "-" "Mozilla/5.0 (Windows NT 6.0; rv:16.0) Gecko/20130722 Firefox/16.0"
What sorcery is this? The a in the logfile is actually the Unicode character 0x430, or the Cyrillic lowercase a. Thus, the first request returns no results. This is an example of a homoglyph—two code points with identical-appearing glyphs. Homoglyph attacks rely on this similarity; to the human eye the characters look identical, but they are encoded differently and an analyst grepping for the former will not find the latter.
Homoglyphs are a particular problem when dealing with the DNS. Internationalized domain names (IDNs) include mechanisms to ease the process of creating multi-code-page domain names, resulting in demonstrated attacks. Unfortunately, there’s no fast and easy way to determine whether something is a homoglyph—they are literally fooling sight. Generally, the best rule of thumb is to try to work within a specific code page (such as in the US, catching anything with a character code above 127). Alternatively, there are tables of known homoglyphs (see the next section for more information) that can provide you with lists of characters to watch out for.
Further Reading
-
C. Weir, “Using Probabilistic Techniques to Aid in Password Cracking Attacks,” PhD Dissertation, Dept. of Computer Science, Florida State University, Tallahassee, FL, 2010.
-
A. Das et al., “The Tangled Web of Password Reuse,” Proceedings of the 2014 Network and Distributed Security (NDSS) Symposium, San Diego, CA, 2014.
-
W. Alcorn, C. Frichot, and M. Orru, The Browser Hacker’s Handbook (Indianapolis, IN: John Wiley & Sons, 2014).
-
D. Sarkar, Text Analytics with Python (Berkeley, CA: Apress, 2016).
1 The attacker will always win this race.
2 That said, UTF-8 = ASCII = ISO-Latin-1 if the value is below 128.
3 IBM, eternally content to make everyone march to its drummer, used a number of slightly different encoding schemes called EBCDIC while everyone else went toward ASCII.
4 Okay, so it’s private space; it’s the thought that counts.
5 You can trace the process of supplanting at https://w3techs.com/technologies/history_overview/character_encoding/ms/y.
6 Note that ASCII is a 7-bit representation. The high bit is always 0. 7 bits it shall be, and the number of bits shall be 7; if you don’t believe me transfer a binary in text mode and wonder why.
7 RFC 3548 summarizes, but don’t treat it like gospel; everybody tweaks.