
![]()
Column Databases
I wish I could find a witty quote about column databases
—Guy Harrison, Next Generation Databases
Those of us raised in Western cultures have been conditioned to think of data as arranged in rows. The way data is presented in ledgers, tables, spreadsheets, and even in the left to right, top to bottom organization of European languages has programmed us to visualize data in row format. It’s not surprising, therefore, that the first digital files were created with each record represented as a row. But no matter how convenient and familiar this format may be, it is not always the best way to organize data physically.
When the first digital files were created, the data for each record was kept together in a way we think of as “row formatted.” The first databases that attempted to implement the relational model were created during a period in which OLTP processing—essentially, record at a time processing—was the most important type of database workload. This sort of workload is primarily record oriented, and the row-oriented physical structure of early digital files provided good performance.
However, as we progressed beyond OLTP processing into the realm of data warehousing and analytic workloads, row-oriented physical organization became less ideal. In a data warehouse you rarely want to process all the columns of a single row, but you often want to process the values of a single column across all rows. Column-oriented databases address this requirement by storing columns physically together on disk.
At the time that Edgar Codd published his seminal paper on the relational database model, database workloads were dominated by record-based processing: so-called CRUD operations (Create, Read, Update, Delete) were the most time-critical ones, while report programs typically iterated through entire tables and were run in a background batch mode where query response time was not a critical issue. However, during the late 1980s and 1990s, an increasing number of relational databases were tasked with supporting analytic and decision support applications that often demanded interactive response times. These systems became known as data warehouses, and increasingly were operated parallel to the OLTP system that had generated the original data. The acronym OLAP (Online Analytic Processing) was coined by Edgar Codd to differentiate these workloads from those of OLTP systems.
Separating OLTP and OLAP workloads was important for maintaining service-level response times for the OLTP systems: sudden IO intensive aggregate queries would generally cause an unacceptable response-time degradation in the OLTP system. But equally important, the OLAP system demanded a different schema from the OLTP system.
Star schemas were developed to create data warehouses in which aggregate queries could execute quickly and which would provide a predictable schema for Business Intelligence (BI) tools. In a star schema, central large fact tables are associated with numerous smaller dimension tables. When the dimension tables implement a more complex set of foreign key relationships, then the schema is referred to as a snowflake schema.
Figure 6-1 shows an example of a simplified star schema.

Figure 6-1. Star schema
![]() Note although star schemas are typically found in relational databases, they do not represent a fully normalized relational model of data. Both the dimension tables and the fact tables usually contain redundant information, or information depended only partly on the primary key. In some respects, widespread adoption of the star schema was a step away from full compliance with Codd’s relational model.
Note although star schemas are typically found in relational databases, they do not represent a fully normalized relational model of data. Both the dimension tables and the fact tables usually contain redundant information, or information depended only partly on the primary key. In some respects, widespread adoption of the star schema was a step away from full compliance with Codd’s relational model.
Almost all data warehouses adopted some variation on the star schema paradigm, and almost all relational databases adopted indexing and SQL optimization schemes to accelerate queries against star schemas. These optimizations allowed relational data warehouses to serve as the foundation for management dashboards and popular BI products. However, despite these optimizations, star schema processing in data warehouses remained severely CPU and IO intensive. As data volumes grew and user demands for interactive response times continued, there was increasing discontent with traditional data warehousing performance.
The Columnar Alternative
The idea that it might be better to store data in columnar format dates back to the 1970s, although commercial columnar databases did not appear until the mid-1990s.
The essence of the columnar concept is that data for columns is grouped together on disk. Figure 6-2 compares columnar and row-oriented storage for some simple data: in a columnar database, values for a specific column become co-located in the same disk blocks, while in the row-oriented model, all columns for each row are co-located.

Figure 6-2. Comparison of columnar and row-oriented storage
There are two big advantages to the columnar architecture. First, in a columnar architecture, queries that seek to aggregate the values of specific columns are optimized, because all of the values to be aggregated exist within the same disk blocks. Figure 6-3 illustrates this phenomenon for our sample database; retrieving the sum of salaries from the row store must scan five blocks, while a single block access suffices in the column store.

Figure 6-3. Aggregate operations in columnar stores require fewer IOs
The exact IO and CPU optimizations delivered by a column architecture vary depending on workload, indexing, and schema design. In general, queries that work across multiple rows are significantly accelerated in a columnar database.
The second key advantage for the columnar architecture is compression. Compression algorithms work primarily by removing redundancy within data values. Data that is highly repetitious—especially if those repetitions are localized—achieve higher compression ratios than data with low repetition. Although the total amount of repetition is the same across the entire database, regardless of row or column orientation, compression schemes usually try to work on localized subsets of the data; the CPU overhead of compression is far lower if it can work on isolated blocks of data. Since in a columnar database the columns are stored together on disk, achieving a higher compression ratio is far less computationally expensive.
Furthermore, in many cases a columnar database will store column data in a sorted order. In this case, very high compression ratios can be achieved simply by representing each column value as a “delta” from the preceding column value. The result is extremely high compression ratios achieved with very low computational overhead.
The key disadvantage of the columnar architecture—and the reason it is a poor choice for OLTP databases—is the overhead it imposes on single row operations. In a columnar database, retrieving a single row involves assembling the row from each of the column stores for that table. Read overhead can be partly reduced by caching and multicolumn projections (storing multiple columns together on disk). However, when it comes to DML operations—particularly inserts—there is virtually no way to avoid having to modify all the columns for each row.
Figure 6-4 illustrates the insert overhead for a column store on our simple example database. The row store need only perform a single IO to insert a new value, while the column store must update as many disk blocks as there are columns.
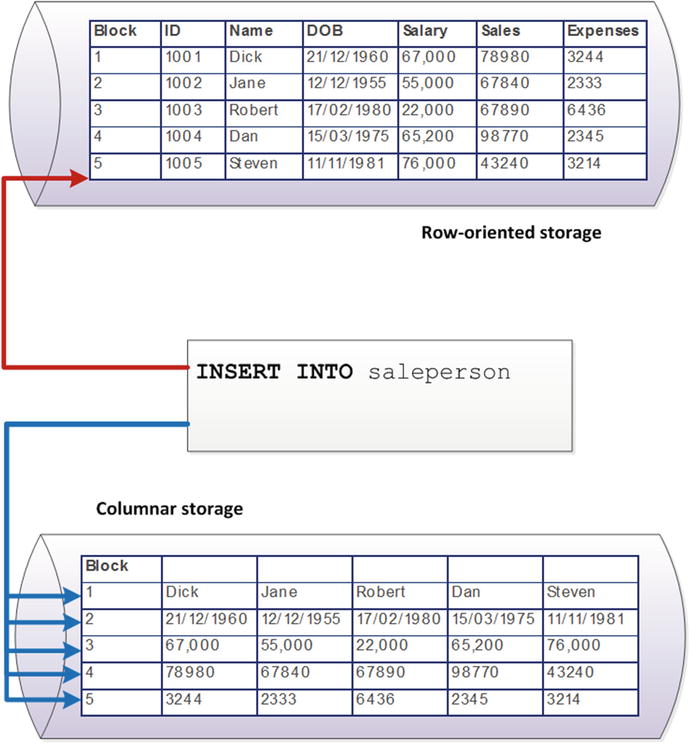
Figure 6-4. Insert overhead for a column store
In real-world row stores (e.g., traditional RDBMS), inserts require more than a single IO because of indexing overhead, and real-world column stores implement mitigating schemes to avoid the severe overhead during single-row modifications. However, the fundamental principle—that column stores perform poorly during single-row modifications—is valid.
Sybase IQ, C-Store, and Vertica
In the mid-1990s, Sybase—one of the top four relational database vendors of the day— acquired Expressway. Expressway had developed what was arguably the first significant commercial column-oriented database. Expressway technology became the basis of Sybase IQ (“Intelligent Query”), which became Sybase’s flagship data warehousing platform. However, although Sybase IQ gained significant traction during the succeeding decade, and despite its leading-edge technology, Sybase IQ failed to dominate the data warehousing market. Industry recognition of the significance of columnar technology remained low.
In 2005, relational pioneer and Ingres inventor Mike Stonebraker and colleagues published a paper outlining a formal database system that they called C-store.1 C-store shared many characteristics with existing columnar systems, as well as having some significant innovations to improve write performance. Stonebraker’s paper included TPC-H benchmark results that demonstrated the C-Store architecture was able to outperform existing row-based DBMS for data warehousing workloads.
Stonebraker formed a companyVertica—to build a commercial implementation of C-Store. Vertica was acquired by HP in 2011.
Timing is everything, and while Sybase IQ had delivered a successful commercial columnar database almost a decade earlier, C-Store and Vertica arrived just as cracks were emerging in the “one size fits all” relational edifice. C-Store and Vertica became emblematic of a new wave of systems that—while not rejecting the relational model or SQL—departed significantly from the traditional RDBMS architecture. Vertica became the poster child for a “NewSQL” database.
Subsequent to the release of the C-Store model, several other significant column-based systems entered the market, including InfoBright, VectorWise, and MonetDB. Columnar technology also became an important element within many significant commercial relational databases, including Oracle Exadata, Microsoft SQL Server, and SAP HANA. (We’ll look at Oracle’s implementation later in this chapter and at HANA in the next chapter.)
Column Database Architectures
As we noted earlier, insert and update overhead for single rows is a key weakness of a columnar architecture. Many data warehouses were bulk-loaded in daily batch jobs—a classic overnight ETL scenario. However, it became increasingly important for data warehouses to provide real-time “up-to-the-minute” information, which implied that the data warehouse should be able to accept a constant trickle feed of changes. The simplistic columnar architecture outlined above would be unable to cope with this constant stream of row-level modifications.
To address this issue, columnar databases generally implement some form of write-optimized delta store (we’ll call this the delta store for short). This area of the database is optimized for frequent writes. You can think simplistically of the data in the delta store as being in a row format, although in practice the internal format might still be columnar or a row/column hybrid. Regardless of the internal format of the data, the delta store is generally memory resident, the data is generally uncompressed, and the store can accept high-frequency data modifications.
Data in the delta store is periodically merged with the main columnar-oriented store. In Vertica, this process is referred to as the Tuple Mover and in Sybase IQ as the RLV (Row Level Versioned) Store Merge. The merge will occur periodically, or whenever the amount of data in the delta store exceeds a threshold. Prior to the merge, queries might have needed to access both the delta store and the column store in order to return complete and accurate results.
Figure 6-5 shows a generic columnar database architecture. The database contains a primary column store that contains highly compressed columnar data backed by disk storage. A smaller write-optimized delta store contains data that is minimally compressed, memory resident, and possibly row oriented.

Figure 6-5. Write optimization in column store databases
Large-scale bulk sequential loads—such as nightly ETL jobs—will generally be directed to the column store (1). Incremental inserts and updates will be directed to the write-optimized store (2). Queries may need to read from both stores in order to get complete and consistent results (3). Periodically, or as required, a process will shift data from the write-optimized store to the column store (4).
In the simplistic description of a columnar database earlier, we showed each column stored together. For queries that access only a single column, storing each column in its own region on disk may be sufficient, but in practice complex queries need to read combinations of column data. It therefore sometimes makes sense to store combinations of columns together on disk.
To achieve this, columnar databases such as Vertica store tables physically as a series of projections, which contain combinations of columns that are frequently accessed together.
For instance, in Figure 6-6 we see a single logical table with three projections. In Vertica, each table has a default superprojection that includes all the columns in the table (1). Additional projections are created to support specific queries. In this case, a projection is created to support sales aggregated by customer (2) and another projection created for sales aggregated by region and product (3).

Figure 6-6. Columnar database table with three projections
In Vertica, projections may be sorted on one or more columns. This decreases processing time for sort and aggregate operations, and also increases compression efficiency. Vertica also supports pre-join projections that materialize columns from multiple tables based on a join criterion. Pre-join projections serve a similar function to materialized views that are created to support specific join operations in traditional relational systems.
Projections may be created manually by the database administrator, on the fly by the query optimizer in response to a specific SQL, or in bulk based on historical workloads. Creating the correct set of projections is of critical importance to columnar store performance—roughly equivalent to the importance of correct indexing in a row store.
Sybase IQ refers to its query optimization structures as “indexes”; however, these indexes bear more resemblance to Vertica projections than to B-Tree indexes in Oracle or SQL Server. Indeed, the Sybase IQ default index—which is automatically created on all columns during table creation—is called the fast projection index. Sybase also supports other indexing options based on traditional bitmap and B-Tree indexing schemes.
Columnar Technology in Other Databases
Variations on the columnar paradigm have been implemented within both traditional relational systems and other “NewSQL” systems. For instance the in-memory database SAP HANA provides support for column or row orientation on a table-by-table basis. The Oracle 12c “Database in Memory” also implements a column store. We’ll touch on these architectures in Chapter 7.
Oracle’s Enhanced Hybrid Columnar Compression (EHCC) is an interesting attempt to achieve a best-of-both-worlds combination of row and column storage technologies. In EHCC— currently only available in Oracle’s Exadata system—rows of data are contained within compression units of about 1 MB, with columns stored together within smaller 8K blocks. Because the columns are stored together within blocks, high levels of compression can be achieved. Because rows are guaranteed to be within a 1 MB compression unit, the overhead for performing row-level modifications is reduced. Figure 6-7 illustrates the concept. Rows are contained within 1MB compression units, but each 8K block contains data for a specific column that is highly compressed.

Figure 6-7. Oracle’s hybrid columnar compression scheme
Column-oriented storage is common in modern nonrelational systems as well. Apache Parquet is a column-oriented storage mechanism for Hadoop files that allows Hadoop systems to take advantage of columnar performance advantages and compression. Apache Kudu uses both row and column storage formats to bridge the perceived performance gap between HDFS row-based processing and Hadoop file scans.
Conclusion
It’s easy to think of columnar architecture as a physical tweak to storage that has only a minor impact on the overall design of database systems. However, the columnar storage paradigm is incredibly influential in the evolution of both existing relational systems that aspire to perform data warehousing roles and “new SQL” systems such as Vertica.
Understanding columnar architecture is also important when examining the new breed of in-memory databases; as we will see in the next chapter, many of these adopt a columnar architecture internally in order to optimize and compress memory-resident data for analytical purposes.
Note
- C-Store: A Column-oriented DBMS, Proceedings of the 31st VLDB Conference, Trondheim, Norway, 2005; http://db.lcs.mit.edu/projects/cstore/vldb.pdf