
![]()
Databases of the Future
The human brain had a vast memory storage. It made us curious and very creative.... And that brain did something very special. It invented an idea called “the future.”
—David Suzuki
Every revolution has its counterrevolution—that is a sign the revolution is for real.
—C. Wright Mills
This book is the story of how a revolution in database technology saw the “one size fits all” traditional relational SQL database give way to a multitude of special-purpose database technologies. In the past 11 chapters, we have reviewed the major categories of next-database systems and have taken a deep dive into some of the internal architectures of those systems.
Most of the technologies we have reviewed are still evolving rapidly, and few would argue that we’ve reached an end state in the evolution of database systems. Can we extrapolate from the trends that we have reviewed in this book and the technology challenges we’ve observed to speculate on the next steps in database technology? Furthermore, is there any reason to think that any of the revolutionary changes we’ve reviewed here are moving along on the wrong track? Should we start a counterrevolution?
In this chapter I argue that the current state of play—in which one must choose between multiple overlapping compromise architectures—should and will pass away. I believe that we will see an increasing convergence of today’s disparate technologies. The database of the future, in my opinion, will be one that can be configured to support all or most of the workloads that today require unique and separate database technologies.
The Revolution Revisited
As we discussed in Chapter 1, the three major eras of database technology correspond to the three major eras of computer applications: mainframe, client-server, and modern web. It’s not surprising, therefore, that the story of the evolution of modern databases parallels the story of the development of the World Wide Web. The predominant drivers for the latest generation of database systems are the drivers that arose from the demands of Web 2.0, global e-commerce, Big Data, social networks, cloud computing, and—increasingly—the Internet of Things (IoT). These buzzwords represent more than simple marketing claims: they each demand and reflect significant changes in application architectures to which database technologies must respond. Today’s application architectures and database technologies are continuously challenged to meet the needs of applications that demand an unparalleled level of scale, availability, and throughput.
The imperative represented by these challenges is irresistible: for most enterprises, Dig Data, social networks, mobile devices, and cloud computing represent key competitive challenges. The ability to leverage data to create competitive advantage is key to the survival of the modern business organization, as is the ability to deploy applications with global scope and with mobile and social context. It’s hard to imagine a successful modern business that did not have a strategy to exploit data or to engage with users via social networks and mobile channels. For some industries, the IoT represents a similar threat and opportunity: Internet-enabled devices stand to revolutionize manufacturing, health care, transportation, home automation, and many other industries.
The shift in application architectures that has emerged from these demands has been conveniently summarized by the market-research company IDC and others as “the third platform.”
Many of the key database variations we have reviewed in this book are optimized to satisfy one or more of the challenges presented by this third platform:
- Hadoop and Spark exist to provide a platform within which masses of semi-structured and unstructured data can be stored and analyzed.
- Nonrelational operational databases such as Cassandra and MongoDB exist to provide a platform for web applications that can support global scale and continuous availability, and which can rapidly evolve new features. Some, like Cassandra, appeal because of their ability to provide scalability and economies across a potentially global deployment. Others, like MongoDB, appeal because they allow more rapid iteration of application design.
- Graph databases such as Neo4j and Graph Compute Engines allow for the management of network data such as is found in social networks.
However, within each of these domains we see continual demand for the key advantages provided by traditional RDBMS systems. In particular:
- SQL provides an interface for data query that has stood the test of time and that is familiar to millions of human beings and involves thousands of analytic tools.
- The relational model of data represents a theoretically sound foundation for unambiguous and accessible data models. The relational model continues to be the correct representation for most computer datasets, even if the physical implementation takes a different form.
- Transactions, potentially multi-object and ACID, continue to be mandatory in many circumstances for systems that strive to correctly represent all interactions with the system.
Counterrevolutionaries
It would be hard for anyone to argue that some sort of seismic shift in the database landscape has not occurred. Hadoop, Spark, MongoDB, Cassandra, and many other nonrelational systems today form an important and growing part of the enterprise data architecture of many, if not most, Fortune 500 companies. It is, of course, possible to argue that all these new technologies are a mistake, that the relational model and the transactional SQL relational database represent a better solution and that eventually the market will “come to its senses” and return to the relational fold.
While it seems unlikely to me that we would make a complete return to a database architecture that largely matured in the client-server era, it is I think fairly clear that most next-generation databases represent significant compromises. Next-generation databases of today do not represent a “unified field theory” of databases; quite the contrary. We still have a long way to go.
A critic of nonrelational systems might fairly claim that the latest breed of databases suffer from the following weaknesses:
- A return of the navigational model. Many of the new breed of databases have reinstated the situation that existed in pre-relational systems, in which logical and physical representations of data are tightly coupled in an undesirable way. One of the great successes of the relational model was the separation of logical representation from physical implementation.
- Inconsistent to a fault. The inability in most nonrelational systems to perform a multi-object transaction, and the possibility of inconsistency and unpredictability in even single-object transactions, can lead to a variety of undesirable outcomes that were largely solved by the ACID transaction and multi-version consistency control (MVCC) patterns. Phantom reads, lost updates, and nondeterministic behaviors can all occur in systems in which the consistency model is relaxed.
- Unsuited to business intelligence. Systems like HBase, Cassandra, and MongoDB provide more capabilities to the programmer than to the business owner. Data in these systems is relatively isolated from normal business intelligence (BI) practices. The absence of a complete SQL layer that can access these systems isolates them from the broader enterprise.
- Too many compromises. There are a wide variety of specialized database solutions, and in some cases these specialized solutions will be an exact fit for an application’s requirements. But in too many cases the application will have to choose between two or more NQR (not quite right) database architectures.
Have We Come Full Circle?
It’s not unusual for relational advocates to claim that the nonrelational systems are a return to pre-relational architectures that were discarded decades ago. This is inaccurate in many respects, but in particular because pre-relational systems were nondistributed, whereas today’s nonrelational databases generally adopt a distributed database architecture. That alone makes today’s nonrelational systems fundamentally different from the pre-relational systems of the 1960s and ’70s.
However, there is one respect in which many newer nonrelational systems resemble pre-relational databases: they entangle logical and physical representations of data. One of Edgar Codd’s key critiques of pre-relational systems such as IDMS and IMS was that they required the user to be aware of the underlying physical representation of data. The relational model decoupled these logical and physical representations and allowed users to see the data in a logically consistent representation, regardless of the underlying storage model. The normalized relational representation of data avoids any bias toward a particular access pattern or storage layout: it decouples logical representation of data from underlying physical representation.
Many advocates of modern nonrelational systems explicitly reject this decoupling. They argue that by making all access patterns equal, normalization makes them all equally bad. But this assertion is dubious: it ignores the possibility of de-normalization as an optimization applied atop a relational model. It’s clear that the structure presented to the end user does not have to be the same as the structure on disk.
Indeed, the motivation for abandoning the relational model was driven less by these access pattern concerns and more by a desire to align the databases’ representation of data with the object-oriented representation in application code. An additional motivation was to allow for rapidly mutating schemas: to avoid the usually lengthy process involved in making a change to a logical data model and propagating that change through to a production system.
Was Codd wrong in 1970 to propose that the physical and logical representations of data should be separate? Almost certainly not. The ability to have a logical data model that represents an unambiguous and nonredundant view of the data remains desirable. Indeed, most nonrelational modeling courses encourage the user to start with some form of “logical” model.
I argue, therefore, that the need for a high-level logical model of the data is still desirable and that to allow users to interact with the database using that model remains as valid a requirement as it was when the relational model was first proposed. However, modern applications need the ability to propagate at least minor changes to the data model without necessitating an unwieldy database change control process.
An Embarrassment of Choice
Ten years ago, choosing the correct database system for an application was fairly straightforward: choose the relational database vendor with which one had an existing relationship or which offered the best licensing deals. Technical considerations or price might lead to a choice of Oracle over SQL Server, or vice versa, but that the database would be an RDBMS was virtually a given. Today, choosing the best database system is a much more daunting task, often made more difficult by the contradictory claims of various venders and advocates. Most of the time, some form of relational technology will be the best choice. But for applications that may seek to break outside the RDBMS comfort zone and seek competitive advantage from unique features of new database technologies, the choice of database can be decisive.
“Which is the best database to choose?” Often, there is no right answer to the question because each choice implies some form of compromise. An RDBMS may be superior in terms of query access and transactional capability, but fails to deliver the network partition tolerance required if the application grows. Cassandra may deliver the best cross-data-center availability, but may fail to integrate with BI systems. And so on ...
Figure 12-1 illustrates some of the decision points that confront someone trying to decide upon a database today.

Figure 12-1. Decisions involved in choosing the correct database
Can We have it All?
I’ve become convinced that we can “have it all” within a single database offering. For instance, there is no architectural reason why a database system should not be able to offer a tunable consistency model that includes at one end strict multi-record ACID transactions and at the other end an eventual consistency style model. In a similar fashion, I believe we could combine the features of a relational model and the document store, initially by following the existing trend toward allowing JSON data types within relational tables.
The resistance to this sort of convergence will likely be driven as much by market and competitive considerations as by technological obstacles. It may not be in the interests of the RDBMS incumbents nor the nonrelational upstarts to concede that a mixed model should prevail. And supporting such a mixed model may involve technical complexity that will be harder for the smaller and more recent market entrants.
Nevertheless, this is what I believe would be the best outcome for the database industry as a whole. Rather than offering dozens of incompatible technologies that involve significant compromises, it would be better to offer a coherent database architecture that offers as configurable behaviors the features best meet application requirements. Let’s look at each area of convergence and consider what would be required to combine technologies into a single system.
Databases like Cassandra that are built on the Dynamo model already provide a tunable consistency model that allows the administrator or developer to choose a level of consistency or performance trade-off. Dynamo-based systems are well known for providing eventual consistency, but they are equally capable of delivering strict consistency—at least within a single-object transaction. RDBMS systems also provide control over isolation levels—providing levels that guarantee repeatable reads, for instance.
However, systems like Cassandra that are based on Dynamo cannot currently provide multi-object transactions. Meanwhile, RDBMS consistency in existing implementations is influenced by ACID transactional principles, which require that the database always present a consistent view to all users.
As we discussed in Chapter 3, the ultimate motivation for eventual consistency-type systems is the ability to survive network partitions. If a distributed database is split in two by a network partition—the “split brain” scenario—the database can only maintain availability if it sacrifices some level of strict consistency.
Implementing multi-row transactions within an eventually consistent, network partition-tolerant database would undoubtedly be a significant engineering challenge, but it is not obviously impossible. Such a database would allow the developer or the administrator to choose between strictly consistent ACID and eventually consistent transactions that involve multiple objects (as shown in Figure 12-2).
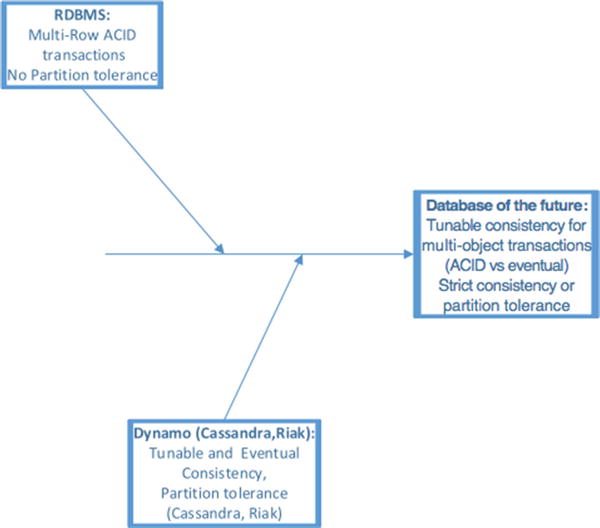
Figure 12-2. A possible convergence of consistency models
Schema
While relational fundamentalists may claim that commercial RDBMS systems have not implemented a pure version of the relational model, the traditional RDBMS has at least established a well-defined discipline on the data modeling process. Data “normalization” eliminates redundancy and ambiguity from the logical representation. By and large, the relational representation of data has proved invaluable in providing non-programmers with a comprehensible view of data and—together with the adoption of SQL as a common language for data access—has offered a predictable and accessible interface to business intelligence and query tools.
Dissent with the relational model arose for at least two reasons:
- Programmers desired a data store that could accept object-oriented data without the overhead and complexity involved in deconstructing and reconstructing from normal form.
- The lifecycle of a relational model represented somewhat of a waterfall process, requiring that the model be comprehensively defined at the beginning of a project and was difficult to change once deployed to production. Modern agile application development practices reject this waterfall approach in favor of an iterative development in which change to design is expected. Furthermore, modern web applications need to iterate new features fast in order to adapt to intense competitive environments. While modern RDBMS systems can perform online schema modifications, the coordination of code and schema change creates risk of application failure and generally requires careful and time-consuming change control procedures.
In short, modern applications require flexible schemas that can be modified if necessary on the fly by changed application code.
However, the need for a comprehensible and unambiguous data model that can be used for business intelligence is even more important in this world of Big Data than it was in the early relational era. Nonrelational databases are unable to easily integrate into an organization’s business intelligence (BI) capability; in the worst case, the data they contain are completely opaque to BI frameworks.
Providing a best-of-both-worlds solution seems within the capabilities of some existing databases. A database that allows data to be represented at a high level in a relatively stable normal form, but which also allows for the storage of dynamically mutating data, only requires that columns in a relational table be able to store arbitrarily complex structures—JSON, for instance—and that these complex structures be supported by efficient query mechanisms integrated into SQL.
As we will see, such hybrid capabilities already exist. Virtually all databases—relational and nonrelational—are introducing support for JSON. For instance, Riak, Cassandra, PostgresSQL, and Oracle all provide specific mechanisms for indexing, storing, and retrieving JSON structures. It will soon be meaningless to describe a database as a “document” database, since all databases will provide strong support for JSON.
I’m sure that relational purists will argue such a hybrid solution is, in fact, the work of the devil in that it compromises the theoretical basis of the relational model. Perhaps so, and a relational implementation that allowed prototyping and rapid iteration of data models while preserving relational purity would be welcome. But for now I believe the short-term direction is set: we’re going to embed JSON in relational tables to balance flexibility with the advantages of the relational model. Figure 12-3 illustrates a vision for the convergence of schema elements in a database of the future.

Figure 12-3. A possible convergence of schema models
Codd’s definition of the relational database did not specify the SQL language, and it is perfectly possible for a formally relational database to use some other language. However over time the advantages of a single cross platform data access language became obvious and the industry united behind SQL.
The term “NoSQL” is unfortunate in that it implies a rejection of the SQL language rather than the more fundamental issues that were at the core of the changes in database technology. However, it is true that in many cases SQL was incompatible or inappropriate for these new systems that often supported record-at-a-time processing using low-level APIs described in Chapter 11.
Today, SQL has regained its status as the lingua franca of the database world, and it seems clear that most databases will allow for SQL queries, whether natively as in Couchbase’s N1QL or via a SQL processing framework such as Apache Drill. Even for databases that cannot natively support the full range of SQL operations, we can see that a reduced SQL syntax enhances usability and programmer efficiency: compare, for instance, the API presented by HBase with the SQL-like interface provided by Apache Cassandra CQL (both are described in Chapter 11).
The emerging challenge to unify databases is not so much to provide SQL access to nonrelational systems as to allow non-SQL access to relational systems. While the SQL language can satisfy a broad variety of data queries, it is not always the most suitable language. In particular, there are data science problems that may call for a lower-level API such as MapReduce or a more complex directed acyclic graph (DAG) algorithm. We’ve also seen how graph traversal operations cannot easily be specified in SQL, and can be more easily expressed in an alternative syntax such as Gremlin or Cypher.
It’s a formal principle of the relational model that one ought not to be able to bypass the set-based query language (e.g., SQL). This is specified in Codd’s 13th rule (nonsubversion). However, if the relational database is going to maintain relevance across all realms, it may be necessary to either relax this rule or provide alternative processing APIs on top of a SQL foundation.
Additionally, when hybrid databases are storing data primarily within embedded JSON structures rather than in relational tables, requiring a SQL syntax to navigate these JSON documents may be unwieldy. An API closer to that native to MongoDB may be more appropriate. Expressing queries as JSON documents pushed to the database via a REST interface (as in existing JSON document databases) might be desirable.
In fact, some of the relational database vendors have already provided much of what is outlined above. We will see later in this chapter how Oracle has provided support for JSON REST queries and the Cypher graph language. Figure 12-4 illustrates the vision for integration of database languages and APIs.

Figure 12-4. A possible convergence path for database languages
The structure of data on disk or other persistent media has an enormous effect on performance and the economics of the database. Chapter 7 discussed the need to be able to tier data in multiple storage layers (memory, SSD, disk, HDFS). We’ve also seen in Chapter 6 how the columnar representation of data can lead to significant improvements for analytical databases. Finally, we saw in Chapter 10 how the B-tree indexing structures that dominated in the traditional RDBMS can be inferior for write-intensive workloads to the log-structured merge tree architectures of Cassandra and HBase.
So, as with the other forks in our technology decision tree, there is no one correct storage layout that suits all workloads. Today, we generally have to pick the database that natively supports the storage layout that best suits our application.
Of course, the underlying storage mechanism for a database is hidden from an application: the access methods to retrieve data must reflect the schematic representation of data, but the structure on disk is generally opaque to the application. Furthermore, we have already seen databases that can maintain multiple storage engines: MySQL has had a pluggable storage engine interface for over 10 years, and MongoDB has recently announced a pluggable storage architecture supporting a handful of alternative storage engines.
We can also see in systems like Hana the ability to choose row-based or columnar storage for specific tables based on anticipated workload requirements.
This pluggable—or at least “choose-able”—storage engine architecture seems to be the right direction for databases of the future. I believe these databases should allow tables or collections to be managed as columnar or row-based, supported by B-trees or log-structured merge trees, resident in memory or stored on disk. In some cases we may even wish to store data in a native graph format to support real-time graph traversal (although in most cases it will be sufficient to layer a graph compute engine over a less restrictive structure). Figure 12-5 illustrates a vision for pluggable storage engines.

Figure 12-5. Convergence options for database storage
A Vision for a Converged Database
By consolidating the convergence visions for individual aspects of database technology, We are in a position to outline the characteristics of an ideal database management system. The key requirement can be summarized as follows:
![]() An ideal database architecture would support multiple data models, languages, processing paradigms, and storage formats within the one system. Application requirements that dictate a specific database feature should be resolved as configuration options or pluggable features within a single database management system, not as choices from disparate database architectures.
An ideal database architecture would support multiple data models, languages, processing paradigms, and storage formats within the one system. Application requirements that dictate a specific database feature should be resolved as configuration options or pluggable features within a single database management system, not as choices from disparate database architectures.
Specifically, an ideal database architecture would:
- Support a tunable consistency model that allows for strict RDBMS-style ACID transactions, Dynamo-style eventual consistency, or any point in between.
- Provide support for an extensible but relational compatible schema by allowing data to be represented broadly by a relational model, but also allowing for application-extensible schemas, possibly by supporting embedded JSON data types.
- Support multiple languages and APIs. SQL appears destined to remain the primary database access language, but should be supplemented by graph languages such as Cypher, document-style queries based on REST, and the ability to express processing in MapReduce or other DAG algorithms.
- Support an underlying pluggable data storage model allowing the physical storage of data to be based on row-oriented or columnar storage is appropriate and on disk as B-trees, log-structured merge trees, or other optimal storage structures.
- Support a range of distributed availability and consistency characteristics. In particular, the application should be able to determine the level of availability and consistency that is supported in the event of a network partition and be able to fine-tune the replication of data across a potentially globally distributed system.
Meanwhile, Back at Oracle HQ ...
Oracle was, of course, the company that first commercialized relational database technology, and as such might be expected to have the most vested interest in maintaining the RDBMS status quo. To some extent this is true: Oracle continues to dominate the RDBMS market, and actively evangelizes SQL and the relational model.
However, behind the scenes, Oracle has arguably come as close as any other vendor to pursuing the vision for the converged database of the future that I outlined earlier. In particular, Oracle has:
- Provided its own engineered system based on Hadoop: the Oracle Big Data Appliance. The Big Data appliance includes the Cloudera distribution of Hadoop (including Spark). It also incorporates significant innovations in performance by pushing predicate filtering down to data nodes, using technology originally created for the Oracle Exadata RDBMS appliance. Oracle also provides connectors that facilitate data movement between the Big Data appliance and Oracle RDBMS and Oracle Big Data SQL, which allows SQL from the Oracle RDBMS to target data held in the Oracle Big Data Appliance.
- Provided very strong support for JSON embedded in the RDBMS. JSON documents may be stored in LOB (see following section) or character columns, and may be retrieved using extensions to SQL. JSON in the database may also be accessed directly by a REST-based JSON query API Simple Oracle Document Access (SODA). This API strongly resembles the MongoDB query API.
- Offers Oracle REST Data Services (ORDS), which also provides a REST-based interface to data in relational tables. This provides a non-SQL based API for retrieving table data using embedded JSON query documents in REST calls that are similar to the JSON-based query language supported by SODA.
- Enhanced its graph compute engine. The new Oracle graph will allow graph analytics using OpenCypher (the graph language originated by Neo4j) to be performed on any data stored in the RDBMS or Big Data Appliance.
- Supports a shared-nothing sharded distributed database, which provides an alternative distributed database model that can support a more linearly scalable OLTP solution compared to the shared-disk RAC clustered database architecture.
Let’s look at some of these offerings in more detail.
Oracle allows JSON documents to be stored in Oracle LOB (Long OBject) or character columns. Oracle provides a check constraint that can be used to ensure the data in those columns is a valid JSON document:
CREATE TABLE ofilms
(
id INTEGER PRIMARY KEY,
json_document BLOB
CONSTRAINT ensure_json CHECK (json_document IS JSON)
)
Oracle supports functions within its SQL dialect that allow for JSON documents to be queried. Specifically:
- JSON_QUERY returns a portion of a JSON document; it uses JSON path expressions that are similar to XPATH for XML.
- JSON_VALUE is similar to JSON_QUERY, but returns a single element from a JSON document.
- JSON_EXISTS determines if a specific element exists in the JSON document.
- JSON_TABLE projects a portion of JSON as a relational table. For instance, JSON_TABLE can be used to project each subelement of a JSON document as a distinct virtual row.
The example that follows uses the “films” JSON document collection that appeared in Chapter 11 to illustrate MongoDB and Couchbase queries. To refresh your memory, these documents look something like this:
{
"Title": "ACE GOLDFINGER",
"Category": "Horror",
"Description": "A Astounding Epistle of a Database Administrator And a Explorer who must Find a Car in Ancient China",
"Length": "48",
"Rating": "G",
"Actors": [
{
"First name": "BOB",
"Last name": "FAWCETT",
"actorId": 19
},
... ...
{
"First name": "CHRIS",
"Last name": "DEPP",
"actorId": 160
}
]
}
Simple dot notation can be used to expand the JSON structures (o.json_document.Title, in the example that follows), while JSON_QUERY can return a complete JSON structure for a selected path within the document. In this example, JSON_QUERY returns the actors nested document.
SQL> SELECT o.json_document.Title,
2 JSON_QUERY (json_document, '$.Actors') actors
3 FROM "ofilms" o
4 WHERE id = 4
5 /
TITLE
------------------------------------------------------------
ACTORS
------------------------------------------------------------
AFFAIR PREJUDICE
[{"First name":"JODIE","Last name":"DEGENERES","actorId":41}
,{"First name":"SCARLETT","Last name":"DAMON","actorId":81} ...
Returning a nested JSON document as a string isn’t helpful in a relational context, so this is where we could use JSON_TABLE to return a single row for each actor. Here is a query that returns the film title and the names of all the actors in the film:
SQL> SELECT f.json_document.Title,a.*
2 FROM "ofilms" f,
3 JSON_TABLE(json_document,'$.Actors[*]'
4 COLUMNS("First" PATH '$."First name"',
5 "Last" PATH '$."Last name"')) a
6 WHERE id=4;
TITLE First Last
-------------------- --------------- ---------------
AFFAIR PREJUDICE JODIE DEGENERES
AFFAIR PREJUDICE SCARLETT DAMON
AFFAIR PREJUDICE KENNETH PESCI
AFFAIR PREJUDICE FAY WINSLET
AFFAIR PREJUDICE OPRAH KILMER
The query returns five rows from the single film document because there are five actors within the actors array in that document. JSON_TABLE is roughly equivalent to the UNNEST clause in N1QL or the FLATTEN clause within Apache Drill (both discussed in Chapter 11).
Accessing JSON via Oracle REST
Jason documents and collections can be created, manipulated, and retrieved entirely without SQL, using the REST-based Simple Oracle Data Access (SODA) protocol.
Although the collections can be created without any SQL-based data definition language statements, under the hood the implementation is as we discussed in the last section—a database table is created containing a LOB that stores the JSON documents.
Regardless of whether the collection was created by the REST API or through SQL, the documents may be interrogated using REST calls. For instance, Figure 12-6 shows a REST command retrieving a document with an ID of 4:

Figure 12-6. Oracle REST JSON query fetching a row by ID
The REST SODA interface can be used to perform CRUD (Create, Read, Update, Delete) operations. Adding a “document” to a “collection” creates a new row in the table.
The interface also supports a query mechanism that can be used to retrieve documents matching arbitrary filter criteria. Figure 12-7 illustrates a simple REST query using this interface (using the Google Chrome “Postman” extension that can be employed to prototype REST calls).

Figure 12-7. Simple SODA REST query
The JSON document filter syntax is extremely similar to that provided by MongoDB. Indeed, the Oracle developers intentionally set out to provide a familiar experience for users of MongoDB and other document databases.
Figure 12-8 illustrates a more complex query in which we search for movies longer than 60 minutes with a G rating, sorted by descending length.

Figure 12-8. Complex Oracle REST query
The Oracle REST data services API provides a REST interface for relational tables as well. The mechanism is virtually identical to the JSON SODA interface we examined earlier.
In Figure 12-9, we see a REST query retrieving data from the Oracle CUSTOMERS table, providing a simple query filter in the HTTP string.

Figure 12-9. Oracle REST interface for table queries
Oracle has long supported an RDF-based graph capability within its Oracle Spatial and Graph option. This option was based on the RDF WC3 standard outlined in Chapter 6. However, while this capability provided some significant graph capabilities, it fell short of the capabilities offered in popular property graph databases such as Neo4J.
As you may recall from Chapter 6, an RDF system is an example of a triple store, which represents relatively simple relationships between nodes. In contrast, a property store represents the relationship between nodes but also allows the model to store significant information (properties) within the nodes and the relationships. While RDF graphs provide strong support for the development of ontologies and support distributed data sources, property graphs are often more attractive for custom application development because they provide a richer data model.
Oracle has recently integrated a property graph compute engine that can perform graph analytics on any data held in the Oracle RDBMS, the Oracle Big Data Hadoop system, or Oracle’s own NoSQL system. The compute engine supports the openCypher graph language. Cypher is the language implemented within Neo4J, the most popular dedicated graph database engine, and openCypher has been made available as an open-source version of that language.
Oracle’s implementation does not represent a native graph database storage engine. As you may recall from Chapter 6, a native graph database must implement index free adjacency, effectively implementing the graph structure in base storage. Rather, Oracle implements a graph compute engine capable of loading data from a variety of formats into memory, where it can be subjected to graph analytics. The advantage of this approach is that graph analytics can be applied to data held in any existing format, provided that format can be navigated as a graph. Many existing relational schemas do in fact implement graph relationships. For example, a typical organization schema will have foreign keys from employees to their managers, which can be represented as a graph.
Oracle sharding is a relatively new feature of the Oracle database, announced in late 2015. Oracle has long provided a distributed database clustering capability. As far back as the early 1990s, Oracle was offering the Oracle Parallel Server—a shared-disk clustered database. This database clustering technology eventually evolved into Oracle Real Application Clusters (RAC), which was widely adopted and which represents the most significant implementation of the shared-disk database clustering model. We discussed shared-disk database clusters in more detail in Chapter 8.
However, the clustered architecture of RAC was more suited to data warehousing workloads than to massively scalable OLTP. Massive scaling of RAC becomes problematic with write-intensive workloads, as the overhead of maintaining a coherent view of data in memory leads to excessive “chatter” across the private database network. For this reason, typical RAC clusters have only a small number of nodes—the vast majority have fewer than 10.
The Oracle sharding option allows an OLTP workload to be deployed across as many as 1,000 separate Oracle instances, using an architecture that is similar to the do-it-yourself sharding of MySQL, which was reviewed in Chapter 3, and also quite similar to the MongoDB sharding architecture that was examined in Chapter 8.
Figure 12-10 shows a representation of the Oracle sharding architecture. The coordinator database (1) contains the catalog that describes how keys are distributed across shards. Each shard is implemented by a distinct Oracle database instance. Queries that include the shard key can be sent directly to the relevant database instance (3); the shard director is aware of the shard mappings and can provide the appropriate connection details to the application (4). Queries that do not specify the shard key or that are aggregating across multiple shards (5) are mediated by the coordinator database which acts as a proxy. The coordinator database sends queries to various shards to retrieve the necessary data (6) and then aggregates or merges the data to return the appropriate result set.

Figure 12-10. Oracle sharding
Oracle sharding supports distribution schemes similar to those supported by Oracle’s existing table partitioning offerings. Data may be partitioned across shards by a hash, shard key ranges, or lists of shard key values. There is also a composite scheme in which data is partitioned primarily by list or range, and then hashed against a second shard key. When hash partitioning is used, Oracle can determine the load balancing automatically by redistributing shard chunks as data volumes change or as nodes are added or removed from the sharded system. Range or list partitioning requires user balancing of shards.
Each shard may be replicated using Oracle replication technologies (DataGuard or Goldengate). Replicas can be used to satisfy read requests, though this may require that the application explicitly request data from a replica rather than from the master.
Tables that don’t conform to the shard key or that are relatively small can be duplicated on each shard rather than being sharded across the entire cluster. For instance, a products table might be duplicated across all shards, while other data is sharded by customer ID.
As with all sharding schemes, Oracle sharding breaks some of the normal guarantees provided by a traditional RDBMS. While joins across shards are supported, there is no guarantee of point-in-time consistency in results. Transactions that span shards are atomic only within a shard—there is no two-phase commit for distributed transactions.
Oracle as a Hybrid Database
It’s surprising, and maybe even a little amusing, to see Oracle adopt a JSON interface that is clearly designed to be familiar to MongoDB users, and to finally adopt a distributed database strategy that admits the superiority of the shared-nothing architecture for certain workloads. But I for one find it encouraging to see the leading RDBMS vendor learn from alternative approaches.
However, Oracle is yet to attempt to address one of the key challenges for an integrated database of the future: balancing consistency and availability in the face of possible network partitions.
Oracle’s RAC clustered database explicitly chooses consistency over availability in the case of a network partition: in a “split brain” scenario, isolated instances in the Oracle RAC cluster will be evicted or voluntarily shut down rather than continue operating in an inconsistent state. Oracle sharding offers a potentially better solution for an online system—theoretically, during a network partition some parts of the sharded database may continue to be available in each partition. However, only a subset—selected shards—will be available to each partition, and there is no mechanism to reconcile inconsistencies. Furthermore, in the sharded model, transactional integrity—even when the entire database is available—is not guaranteed. Transactions or queries that span shards may exhibit inconsistent behavior, for instance.
A mode in which a transactional relational database might maintain availability in the face of a network partition would require some sort of merger between the transactional behavior implemented in ACID RDBMS systems and Dynamo-style eventual consistency.
Oracle is not alone in the RDBMS world in its adoption of JSON or interest in nonrelational paradigms. Whether the Oracle folks are sincerely attempting to move their flagship database product into the future or simply trying to take the wind out of the sails of upstart competitors remains to be seen. But it is clear that significant effort is going into engineering features that shift the Oracle RDBMS away from its traditional RDBMS roots. And if nothing else, some of these features are suggestive of how a converged database system might behave.
There are several other attempts to converge the relational and nonrelational models that are worth mentioning here:
- NuoDB is a SQL-based relational system that uses optimistic asynchronous propagation of transactions to achieve near-ACID consistency in a distributed context. Slight deviations from strict ACID consistency might result from this approach: not all replicas will be updated simultaneously across the cluster. In a manner somewhat similar to that of Dynamo systems, the user can tune the consistency levels required. NuoDB also separates the storage layer from the transactional layer, allowing for a pluggable storage engine architecture.
- Splice Machine layers a relationally compatible SQL layer over an HBase-managed storage system. Although its key objective is to leverage HBase scalability to provide a more economically scalable SQL engine, it does allow for hybrid data access because the data may be retrieved directly from HBase using MapReduce or YARN, as well as via SQL from the relational layer.
- Cassandra has added strong support for JSON in its current release and is also integrating a graph compute engine into its enterprise edition. The Dynamo tunable consistency model, together with the Cassandra lightweight transaction feature, covers a broader range of transactional scenarios than other nonrelational competitors. However, there is no roadmap for full SQL or multi-object ACID transactions.
- Apache Kudu is an attempt to build a nonrelational system that equally supports full-scan and record-based access patterns. The technological approach involves combining in-memory row-based storage and disk-based columnar storage. The stated intent is to bridge the gap between HDFS performance for complete “table” scans and HBase row-level access. Of itself, this doesn’t provide a truly hybrid solution, but coupled with Apache Impala, it could provide a SQL-enabled database that also provides key-value style access and Hadoop compatibility. However, there is no plan as yet for multi-row transactions.
Disruptive Database Technologies
So far, I’ve described a future in which the recent divergence of database technologies is followed by a period of convergence toward some sort of “unified model” of databases.
Extrapolating existing technologies is a useful pastime, and is often the only predictive technique available. However, history teaches us that technologies don’t always continue along an existing trajectory. Disruptive technologies emerge that create discontinuities that cannot be extrapolated and cannot always be fully anticipated.
It’s possible that a disruptive new database technology is imminent, but it’s just as likely that the big changes in database technology that have occurred within the last decade represent as much change as we can immediately absorb.
That said, there are a few computing technology trends that extend beyond database architecture and that may impinge heavily on the databases of the future.
Since the dawn of digital databases, there has been a strong conflict between the economies of speed and the economies of storage. The media that offer the greatest economies for storing large amounts of data (magnetic disk, tape) come with the slowest times and therefore the worst economies for throughput and latency. Conversely, the media that offer the lowest latencies and the highest throughput (memory, SSD) are the most expensive per unit of storage.
As was pointed out in Chapter 7, although the price per terabyte of SSDs is dropping steadily, so is the price per terabyte for magnetic disk. Extrapolation does not suggest that SSDs will be significantly cheaper than magnetic disk for bulk storage anytime soon. And even if SSDs matched magnetic disk prices, the price/performance difference between memory and SSD would still be decisive: memory remains many orders of magnitude faster than SSD, but also many orders of magnitude more expensive per terabyte.
As long as these economic disparities continue, we will be encouraged to adopt database architectures that use different storage technologies to optimize the economies of Big Data and the economies of “fast” data. Systems like Hadoop will continue to optimize cost per terabyte, while systems like HANA will attempt to minimize the cost of providing high throughput or low latency.
However, should a technology arise that simultaneously provides acceptable economies for mass storage and latency, then we might see an almost immediate shift in database architectures. Such a universal memory would provide access speeds equivalent to RAM, together with the durability, persistence, and storage economies of disk.
Most technologists believe that it will be some years before such a disruptive storage technology arises, though given the heavy and continuing investment, it seems likely that we will eventually create a persistent fast and economic storage medium that can meet the needs of all database workloads. When this happens, many of the database architectures we see today will have lost a key part of their rationale for existence. For instance, the difference between Spark and Hadoop would become minimal if persistent storage (a.k.a. disk) was as fast as memory.
There are a number of significant new storage technologies on the horizon, including Memristors and Phase-change memory. However, none of these new technologies seems likely to imminently realize the ambitions of universal memory.
You would have to have been living under a rock for the past few years not to have heard of bitcoin. The bitcoin is an electronic cryptocurrency that can be used like cash in many web transactions. At the time of this writing, there are about 15 million bitcoins in circulation, trading at approximately $US 360 each, for a total value of about $US 5.3 billion.
The bitcoin combines peer-to-peer technology and public key cryptography. The owner of a bitcoin can use a private key to assert ownership and authorize transactions; others can use the public key to validate the transaction. As in other peer-to-peer systems, such as Bittorrent, there is no central server that maintains bitcoin transactions; rather, there is a distributed public ledger called the blockchain.
The implications of cryptocurrencies are way beyond our scope here, but there are definite repercussions for database technologies in the blockchain concept. Blockchain replaces the trusted third party that must normally mediate any transfer of funds. Rather than there being a centralized database that records transactions and authenticates each party, blockchain allows transactions and identities to be validated by consensus with the blockchain network; that is, each transaction is confirmed by public-key-based authentication from multiple nodes before being concluded.
The blockchain underlying the bitcoin is public, but there can be private (or permissioned) blockchains that are “invitation only.” Whether private or public, blockchains arguably represent a new sort of shared distributed database. Like systems based on the Dynamo model, the data in the blockchain is distributed redundantly across a large number of hosts. However, the blockchain represents a complete paradigm shift in how permissions are managed within the database. In an existing database system, the database owner has absolute control over the data held in the database. However, in a blockchain system, ownership is maintained by the creator of the data.
Consider a database that maintains a social network like Facebook: although the application is programmed to allow only you to modify your own posts or personal details, the reality is that the Facebook company actually has total control over your online data. The staff there can— if they wish—remove your posts, censor your posts, or even modify your posts if they really want to. In a blockchain-based database, you would retain total ownership of your posts and it would be impossible for any other entity to modify them.
Applications based on blockchain have the potential to disrupt a wide range of social and economic activities. Transfers of money, property, management of global identity (passports, birth certificates), voting, permits, wills, health data, and a multitude of other transactional data could be regulated in the future by blockchains. The databases that currently maintain records of these types of transactions may become obsolete.
Most database owners will probably want to maintain control of the data in the database, and therefore it’s unlikely that blockchain will completely transform database technology in the short term. However, it does seem likely that database systems will implement blockchain-based authentication and authorization protocols for specific application scenarios. Furthermore, it seems likely that formal database systems built on a blockchain foundation will soon emerge.
The origins of quantum physics date back over 100 years, with the recognition that energy consists of discrete packets, or quanta.
By the 1930s, most of the mindboggling theories of quantum physics had been fully articulated. Individual photons of light appear to pass simultaneously through multiple slits in the famous twin-slit experiment, providing they are not observed. The photons are superimposed across multiple states. Attempts to measure the path of the photons causes them to collapse into a single state. Photons can be entangled, in which case the state of one photon may be inextricably linked with the state of an otherwise disconnected particle—what Albert Einstein called “spooky action at a distance.”
As Niels Bohr famously said, “If quantum mechanics hasn’t profoundly shocked you, you haven’t understood it yet.” The conventional view of quantum physics is that multiple simultaneous probabilities do not resolve until perceived by a conscious observer. This Copenhagen interpretation serves as the basis for the famous Schrödinger’s Cat thought experiment, in which a cat is simultaneously dead and alive when unobserved in an elaborate quantum contraption. Some have conjectured that Schrödinger’s dog actually proposed this experiment.1
The undeniably mindboggling weirdness of various quantum interpretations does have significant implications for real-world technology: most modern electronics are enabled directly or indirectly by quantum phenomena, and this is especially true in computing, where the increasing density of silicon circuitry takes us ever closer to the “realm of the very small” where quantum effects dominate.
Using quantum effects to create a new type of computer was popularized by physicist Richard Feynman back in the 1980s. The essential concept is to use subatomic particle behavior as the building blocks of computing. In essence, the logic gates and silicon-based building blocks of today’s physical computers would be replaced by mechanisms involving superimposition and entanglement at the subatomic level.
Quantum computers promise to provide a mechanism for leapfrogging the limitations of silicon-based technology and raise the possibility of completely revolutionizing cryptography. The promise that quantum computers could break existing private/public key encryption schemes seems increasingly likely, while quantum key transmission already provides a tamper-proof mechanism for transmitting certificates over distances within a few hundreds of kilometers.
If quantum computing realizes its theoretical potential, it would have enormous impact on all areas of computing—databases included. There are also some database-specific quantum computing proposals:
- Quantum transactions: Inspired by the concept of superimposition, it’s proposed that data in a database could be kept in a “quantum” state, effectively representing multiple possible outcomes. The multiple states collapse into an outcome when “observed.” For example, seat allocations in an aircraft could be represented as the sum of all possible seating arrangements, which “collapse” when final seat assignments are made; the collapse could be mediated by various seating preferences: requests to sit together or for aisle or window seats. This approach leverages quantum concepts but does not require a quantum computing infrastructure, though a quantum computer could enable such operations on a potentially massive scale.2
- Quantum search: A quantum computer could potentially provide an acceleration of search performance over a traditional database. A quantum computer could more rapidly execute a full-table scan and find matching rows for a complex non-indexed search term.3 The improvement is unlikely to be decisive when traditional disk access is the limiting factor, but for in-memory databases, it’s possible that quantum database search may become a practical innovation.
- A quantum query language: The fundamental unit of processing in a classical (e.g., non-quantum) computer is the bit, which represents one of two binary states. In a quantum computer, the fundamental unit of processing is the qubit, which represents the superimposition of all possible states of a bit. To persistently store the information from a quantum computer would require a truly quantum-enabled database capable of executing logical operations using qubit logic rather than Boolean bit logic. Operations on such a database would require a new language that could represent quantum operations instead of the relational predicates of SQL. Such a language has been proposed: Quantum Query Language (QQL).4
Promises of practical quantum computing have been made for several decades now, but to date concrete applications have been notably absent. It’s quite possible that true quantum computing will turn out to be unobtainable or will prove to be impractical for mainstream applications. But if quantum computing achieves even some of its ambitions it will change the computing landscape dramatically, and databases will not be immune from the repercussions.
Conclusion
In this book I’ve tried to outline the market and technology forces that “broke” the decades-old dominance of the RDBMS. In Chapter 1, I argued that there was no one-size-fits-all architecture that could meet all the needs of diverse modern applications. I still believe that to be true.
I’d also like to reiterate that I believe the modern RDBMS—essentially a combination of relational model, ACID transactions, and the SQL language—represents an absolute triumph of software engineering. The RDBMS revolutionized computing, database management, and application development. I believe it is apparent that the RDBMS remains the best single choice for the widest variety of application workloads, and that it has and will continue to stand the test of time.
That having been said, it is also clear that the RDBMS architecture that was established in the 1990s does not form a universal solution for the complete variety of applications being built today. Even if it could, it is clear that in the world we live in, developers, application architects, CTOs, and CIOs are increasingly looking to nonrelational alternatives. It behooves us as database professionals to understand the driving forces behind these nonrelational alternatives, to understand their architectures, and to be in a position to advise on, manage, and exploit these systems.
As I have learned more about the technologies underpinning modern next-generation database architectures, I have come to believe that the Cambrian explosion of database diversity we’ve seen in the last 10 years would—or at least should—be followed by a period of convergence. There are too many choices confronting database users, and too many compromises required when selecting the best database for a given application workload. We shouldn’t have to sacrifice multi-row transactions in order to achieve network partition tolerance, nor should we have to throw out the relational baby with the bathwater when we want to allow an application to dynamically evolve schema elements. Thus, I hope for a future in which these choices become a matter of configuration within a single database architecture rather than a Hobson’s choice between multiple, not quite right systems.
Clear signs of convergence are around us: the universal acceptance of JSON into relational systems, the widespread readoption of SQL as the standard language for database access, and the introduction of lightweight transactions into otherwise nontransactional systems.
In this chapter I’ve tried to outline some of the options that an ideal database system should provide in order to reach this Nirvana. We are clearly many years away from being able to deliver such a converged system. But that doesn’t stop a database veteran from dreaming!
I feel cautiously confident that convergence will be the dominant force shaping databases over the next few years. However, there are technologies on the horizon that could force paradigm shifts: quantum computing, blockchain, and universal memory, to mention a few.
Despite the compromises, and the bewildering array of often incompatible or inconsistent technology models, it remains an exciting time to be a database professional. The period of relational dominance allowed us to hone our skills and master a coherent technology stack. Today’s challenge for the database professional is to understand the diversity of technologies that are available, to pick the best and most durable technologies for the job, and to optimize those technologies to the task at hand. Choosing and optimizing the right database enhances the capabilities and economies of the modern applications that—when put to the right purposes—help us build a more prosperous, benevolent, and integrated global community.
Notes