
Kudu is an Apache-licensed open source columnar storage engine built for the Apache Hadoop platform. It supports fast sequential and random reads and writes, enabling real-time stream processing and analytic workloads. i It integrates with Impala, allowing you to insert, delete, update, upsert, and retrieve data using SQL. Kudu also integrates with Spark (and MapReduce) for fast and scalable data processing and analytics. Like other projects in the Apache Hadoop ecosystem, Kudu runs on commodity hardware and was designed to be highly scalable and highly available.
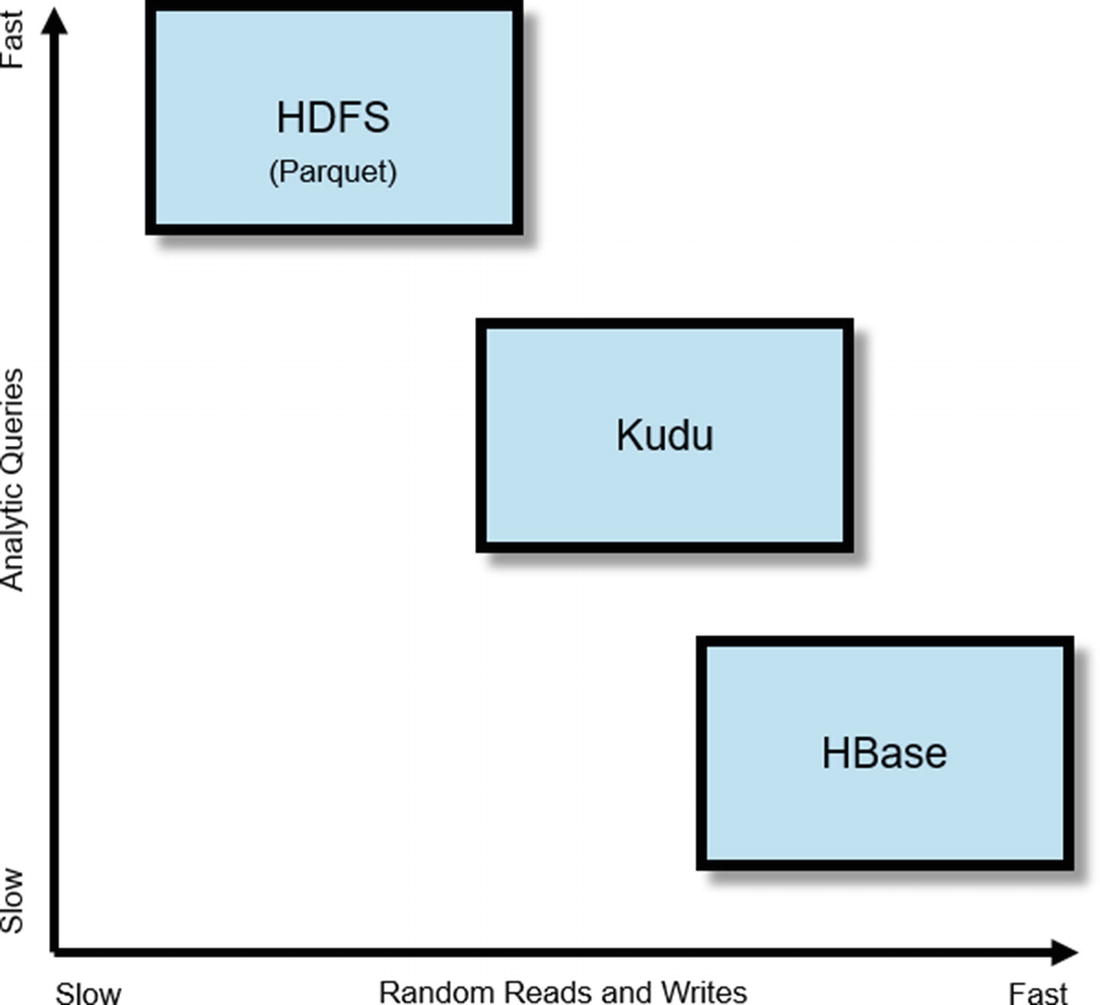
High-level performance comparison of HDFS, Kudu, and HBase
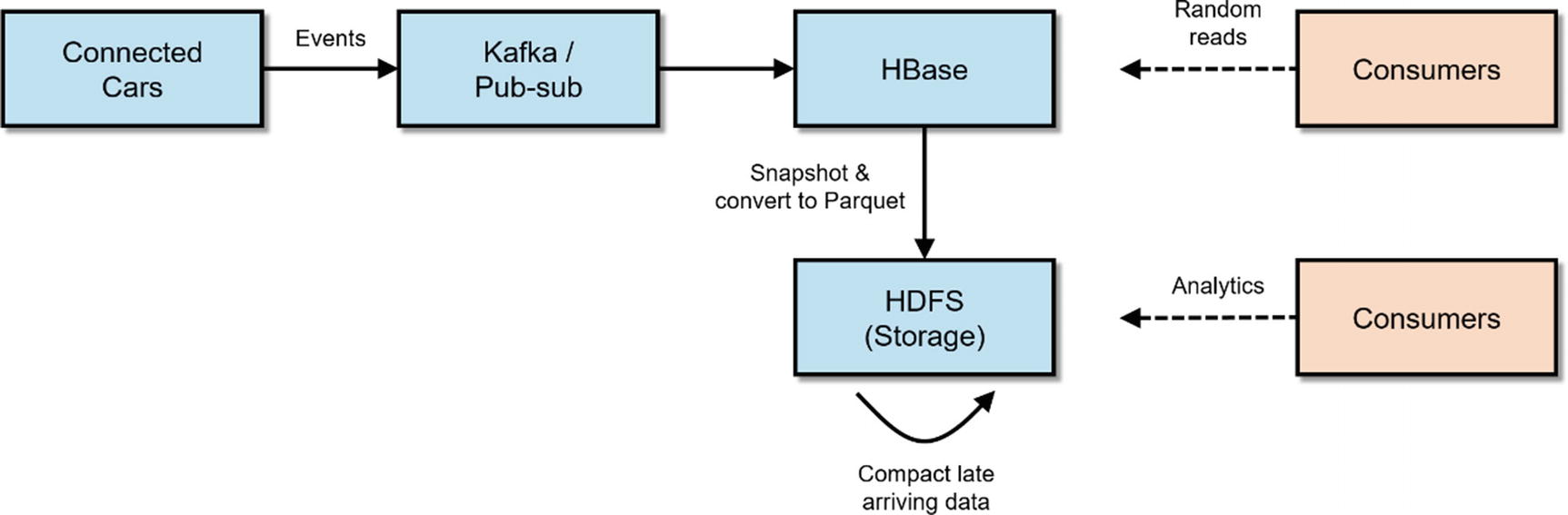
Lambda Architecture

Modern data ingest pipeline using Kudu
Kudu Is for Structured Data
Kudu was designed to store structured data similar to relational databases. In fact, Kudu (when used with Impala) is often used for relational data management and analytics. Kudu rivals commercial data warehouse platforms in terms of capabilities, performance, and scalability. We’ll discuss Impala and Kudu integration later in the chapter and more thoroughly in Chapter 4.
Use Cases
Before we begin, let’s talk about what Kudu is not. Kudu is not meant to replace HBase or HDFS. HBase is a schema-less NoSQL-style data store that makes it suitable for sparse data or applications that requires variable schema. HBase was designed for OLTP-type workloads that requires random reads and writes. For more information on HBase, see the HBase online documentation.
HDFS was designed to store all types of data: structured, semi-structured, and unstructured. If you need to store data in a highly scalable file system, HDFS is a great option. As mentioned earlier, HDFS (using Parquet) is still faster in some cases than Kudu when it comes to running analytic workloads. For more on HDFS, see the HDFS online documentation.
As discussed earlier, Kudu excels at storing structured data. It doesn’t have an SQL interface, therefore you need to pair Kudu with Impala. Data that you would normally think of storing in a relational or time series database can most likely be stored in Kudu as well. Below are some use cases where Kudu can be utilized. iv
Relational Data Management and Analytics
Kudu (when used with Impala) exhibits most of the characteristics of a relational database. It stores data in rows and columns and organizes them in databases and tables. Impala provides a highly scalable MPP SQL engine and allows you to interact with Kudu tables using ANSI SQL commands just as you would with a relational database. Relational database use cases can be classified into two main categories, online transactional processing (OLTP) and decision support systems (DSS) or as commonly referred to in modern nomenclature, data warehousing. Kudu was not designed for OLTP, but it can be used for data warehousing and other enterprise data warehouse (EDW) modernization use cases.
Data Warehousing
Kudu can be used for dimensional modeling – the basis of modern data warehousing and online analytic processing (OLAP). Kudu lacks foreign key constraints, auto-increment columns, and other features that you would normally find in a traditional data warehouse platform; however these limitations do not preclude you from organizing your data in facts and dimensions tables. Impala can be accessed using your favorite BI and OLAP tools via ODBC/JDBC. I discuss data warehousing using Impala and Kudu in Chapter 8.
ETL Offloading
ETL offloading is one of the many EDW optimization use cases that you can use Kudu for. Critical reports are unavailable to the entire organization due to ETL processes running far beyond its processing window and pass into the business hours. By offloading time-consuming ETL processing to an inexpensive Kudu cluster, ETL jobs can finish before business hours, making critical reports and analytics available to business users when they need it. I discuss ETL offloading using Impala and Kudu in Chapter 8.
Analytics Offloading and Active Archiving
Impala is an extremely fast and scalable MPP SQL engine. You can reduce the load on your enterprise data warehouse by redirecting some of your ad hoc queries and reports to Impala and Kudu. Instead of spending millions of dollars upgrading your data warehouse, analytics offloading and active archiving is the smarter and more cost-effective way to optimize your EDW environment. I discuss analytics offloading and active archiving using Impala and Kudu in Chapter 8.
Data Consolidation
It’s not unusual for large organizations to have hundreds or thousands of legacy databases scattered across its enterprise, paying millions of dollars in licensing, administration and infrastructure cost. By consolidating these databases into a single Kudu cluster and using Impala to provide SQL access, you can significantly reduce cost while improving performance and scalability. I discuss data consolidation using Impala and Kudu in Chapter 8.
Internet of Things (IoT) and Time Series
Kudu is perfect for IoT and time series applications where real-time data ingestion, visualization, and complex event processing of sensor data is critical. Several large companies and government agencies such as Xiaomi, JD.com, v and Australia Department of Defense vi are successfully using Kudu for IoT use cases. I discuss IoT, real-time data ingestion, and complex event processing using Impala, Kudu, and StreamSets in Chapter 7. I discuss real-time data visualization with Zoomdata in Chapter 9.
Feature Store for Machine Learning Platforms
Data science teams usually create a centralized feature store where they can publish and share highly selected sets of authoritative features with other teams for creating machine learning models. Creating and maintaining feature stores using immutable data formats such as ORC and Parquet is time consuming, cumbersome, and requires too much unnecessary hard work, especially for large data sets. Using Kudu as a fast and highly scalable mutable feature store, data scientists and engineers can easily update and add features using familiar SQL statements. The ability to update feature stores in seconds or minutes is critical in an Agile environment where data scientists are constantly iterating in building, testing, and improving the accuracy of their predictive models. In Chapter 6, we use Kudu as a feature store for building a predictive machine learning model using Spark MLlib.
Note
Kudu allows up to a maximum of 300 columns per table. HBase is a more appropriate storage engine if you need to store more than 300 features. HBase tables can contain thousands or millions of columns. The downside in using HBase is that it is not as efficient in handling full table scans compared to Kudu. There is discussion within the Apache Kudu community to address the 300-column limitation in future versions of Kudu.
Strictly speaking, you can bypass Kudu’s 300-column limit by setting an unsafe flag. For example, if you need the ability to create a Kudu table with 1000 columns, you can start the Kudu master with the following flags: --unlock-unsafe-flags --max-num-columns=1000. This has not been thoroughly tested by the Kudu development team and is therefore not recommended for production use.
Key Concepts
Kudu introduces a few concepts that describe different parts of its architecture.
Table A table is where data is stored in Kudu. Every Kudu table has a primary key and is divided into segments called tablets.
Tablet A tablet, or partition, is a segment of a table.
Tablet Server A tablet server stores and serves tablets to clients.
Master A master keeps track of all cluster metadata and coordinates metadata operations.
Catalog Table Central storage for all of cluster metadata. The catalog table stores information about the location of tables and tablets, their current state, and number of replicas. The catalog table is stored in the master.
Architecture
Similar to the design of other Hadoop components such as HDFS and HBase (and their Google counterparts, BigTable and GFS), Kudu has a master-slave architecture. As shown in Figure 2-4, Kudu comprises one or more Master servers responsible for cluster coordination and metadata management. Kudu also has one or more tablet servers, storing data and serving them to client applications. vii For a tablet, there can only be one acting master, the leader, at any given time. If the leader becomes unavailable, another master is elected to become the new leader. Similar to the master, one tablet server acts as a leader, and the rest are followers. All write request go to the leader, while read requests go to the leader or replicas. Data stored in Kudu is replicated using the Raft Consensus Algorithm, guaranteeing the availability of data will survive the loss of some of the replica as long as the majority of the total number of replicas is still available. Whenever possible, Kudu replicates logical operations instead of actual physical data, limiting the amount of data movement across the cluster.
Note
The Raft Consensus Algorithm is described in detail in “The Raft Paper”: In Search of an Understandable Consensus Algorithm (Extended Version) by Diego Ongaro and John Ousterhout. viii Diego Ongaro’s PhD dissertation, “Consensus: Bridging Theory and Practice,” published by Stanford University in 2014, expands on the content of the paper in more detail. ix
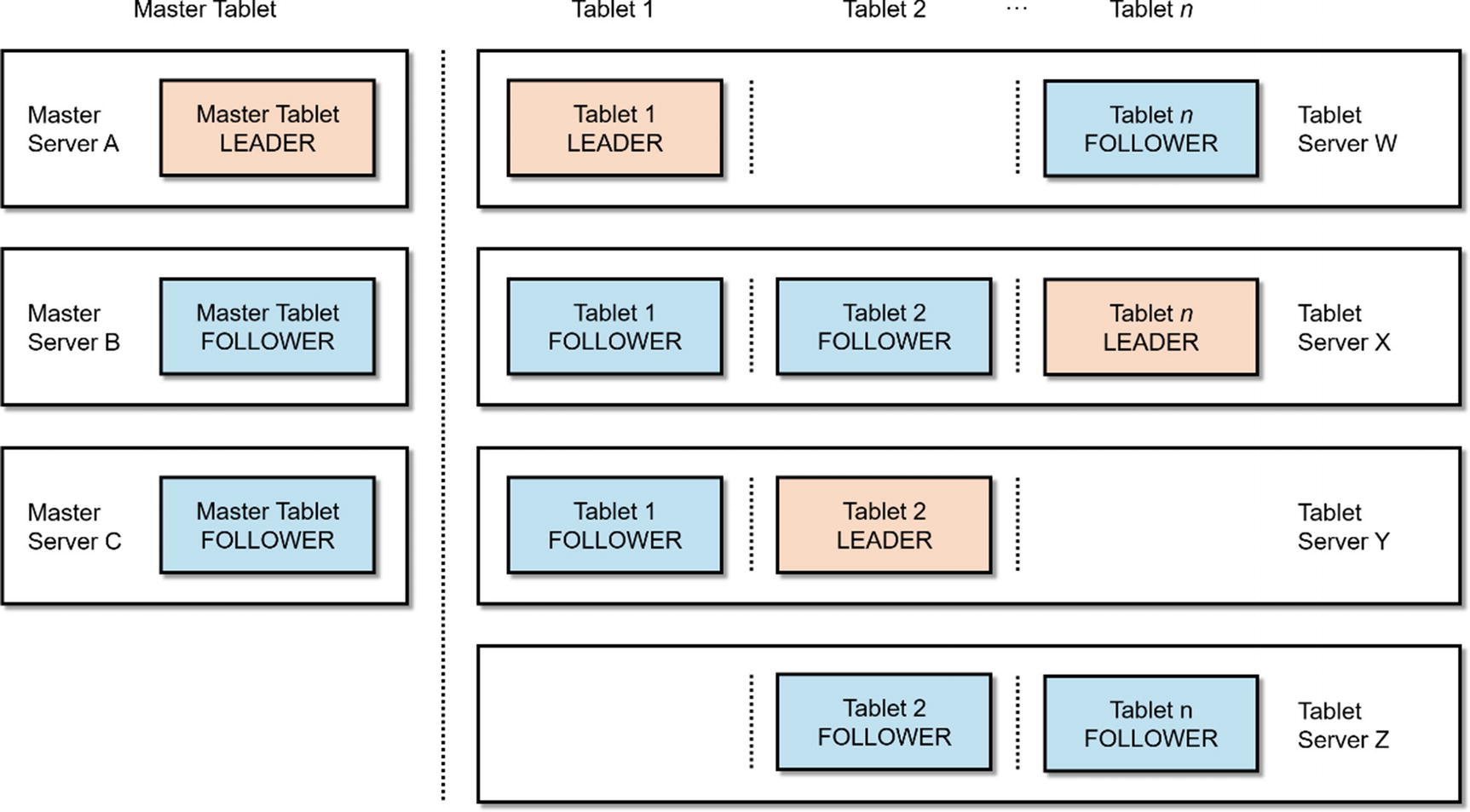
Kudu Architecture
Multi-Version Concurrency Control (MVCC)
Most modern databases use some form of concurrency control to ensure read consistency instead of traditional locking mechanisms. Oracle has a multi-version consistency model since version 6.0. x Oracle uses data maintained in the rollback segments to provide read consistency. The rollback segments contain the previous data that have been modified by uncommitted or recently committed transactions. xi MemSQL and SAP HANA manages concurrency using MVCC as well. Originally, SQL Server only supported a pessimistic concurrency model, using locking to enforce concurrency. As a result, readers block writers and writers block readers. The likelihood of blocking problems and lock contention increase as the number of concurrent users and operations rise, leading to performance and scalability issues. Things became so bad in SQL Server-land that developers and DBAs were forced to use the NOLOCK hint in their queries or set the READ UNCOMITTED isolation level, tolerating dirty reads in exchange for a minor performance boost. Starting in SQL Server 2005, Microsoft introduced its own version of multi-version concurrency control known as row-level versioning. xii SQL Server doesn’t have the equivalent of rollback segments so it uses tempdb to store previously committed data. Teradata does not have multi-version consistency model and relies on transactions and locks to enforce concurrency control. xiii
Similar to Oracle, MemSQL, and SAP HANA, Kudu uses multi-version concurrency control to ensure read consistency. xiv Readers don’t block writers and writers don’t block readers. Kudu’s optimistic concurrency model means that operations are not required to acquire locks during large full table scans, considerably improving query performance and scalability.
Impala and Kudu
Impala is the default MPP SQL engine for Kudu. Impala allows you to interact with Kudu using SQL. If you have experience with traditional relational databases where the SQL and storage engines are tightly integrated, you might find it unusual that Kudu and Impala are decoupled from each other. Impala was designed to work with other storage engines such as HDFS, HBase, and S3, not just Kudu. There’s also work underway to integrate other SQL engines such as Apache Drill (DRILL-4241) and Hive (HIVE-12971) with Kudu. Decoupling storage, SQL, and processing engines are common practices in the open source community.
The Impala-Kudu integration works great but there is still work to be done. While it matches or exceeds traditional data warehouse platforms in terms of performance and scalability, Impala-Kudu lacks some of the enterprise features found in most traditional data warehouse platforms. We discuss some of these limitations later in the chapter.
Primary Key
Every Kudu table needs to have a primary key. Kudu’s primary key is implemented as a clustered index. With a clustered index, the rows are stored physically in the tablet in the same order as the index. Also note that Kudu doesn’t have an auto-increment feature so you will have to include a unique primary key value when inserting rows to a Kudu table. If you don’t have a primary key value, you can use Impala’s built-in uuid() function or another method to generate a unique value.
Data Types
List of Data Types, with Available and Default Encoding
Data Type | Encoding | Default |
|---|---|---|
boolean | plain, run length | run length |
8-bit signed integer | plain, bitshuffle, run length | bitshuffle |
16-bit signed integer | plain, bitshuffle, run length | bitshuffle |
32-bit signed integer | plain, bitshuffle, run length | bitshuffle |
64-bit signed integer | plain, bitshuffle, run length | bitshuffle |
unixtime_micros (64-bit microseconds since the Unix epoch) | plain, bitshuffle, run length | bitshuffle |
single-precision (32-bit) IEEE-754 floating-point number | plain, bitshuffle | bitshuffle |
double-precision (64-bit) IEEE-754 floating-point number | plain, bitshuffle | bitshuffle |
UTF-8 encoded string (up to 64KB uncompressed) | plain, prefix, dictionary | dictionary |
binary (up to 64KB uncompressed) | plain, prefix, dictionary | dictionary |
You may notice that Kudu currently does not support the decimal data type. This is a key limitation in Kudu. The float and double data types only store a very close approximation of the value instead of the exact value as defined in the IEEE 754 specification. xv Because of this behaviour, float and double are not appropriate for storing financial data. At the time of writing, support for decimal data type is still under development (Apache Kudu 1.5 / CDH 5.13). Decimal support is coming in Kudu 1.7. Check KUDU-721 for more details. There are various workarounds available. You can store financial data as string then use Impala to cast the value to decimal every time you need to read the data. Since Parquet supports decimals, another workaround would be to use Parquet for your fact tables and Kudu for dimension tables.
As shown in Table 2-1, Kudu columns can use different encoding types depending on the type of column. Supported encoding types includes Plain, Bitshuffle, Run Length, Dictionary, and Prefix. By default, Kudu columns are uncompressed. Kudu supports column compression using Snappy, zlib, or LZ4 compression codecs. Consult Kudu’s documentation for more details on Kudu encoding and compression support.
Note
In earlier versions of Kudu, date and time are represented as a BIGINT. You can use the TIMESTAMP data type in Kudu tables starting in Impala 2.9/CDH 5.12. However, there are several things to keep in mind. Kudu represents date and time columns using 64-bit values, while Impala represents date and time as 96-bit values. Nanosecond values generated by Impala are rounded when stored in Kudu. When reading and writing TIMESTAMP columns, there is an overhead converting between Kudu’s 64-bit representation and Impala’s 96-bit representation. There are two workarounds: use the Kudu client API or Spark to insert data, or continue using BIGINT to represent date and time. xvi
Partitioning
Table partitioning is a common way to enhance performance, availability, and manageability of Kudu tables. Partitioning allows tables to be subdivided into smaller segments, or tablets. Partitioning enables Kudu to take advantage of partition pruning by allowing access to tables at a finer level of granularity. Table partitioning is required for all Kudu tables and is completely transparent to applications. Kudu supports Hash, Range, and Composite Hash-Range and Hash-Hash partitioning. Below are a few examples of partitioning in Kudu.
Hash Partitioning
There are times when it is desirable to evenly distribute data randomly across partitions to avoid IO bottlenecks. With hash partitioning , data is placed in a partition based on a hashing function applied to the partitioning key. Not that you are not allowed to add partitions on hash partitioned tables. You will have to rebuild the entire hash partitioned table if you wish to add more partitions .
Range Partitioning
Range partitioning stores data in partitions based on predefined ranges of values of the partitioning key for each partition. Range partitioning enhances the manageability of the partitions by allowing new partitions to be added to the table. It also improves performance of read operations via partition pruning. One downside: range partitioning can cause hot spots if you insert data in partition key order.
Hash-Range Partitioning
Hash-Range partitioning combines the benefits while minimizing the limitations of hash and range partitioning. Using hash partitioning ensures write IO is spread evenly across tablet servers, while using range partitions ensure new tablets can be added to accommodate future growth.
I discuss table partitioning in more detail in Chapter 4.
Spark and Kudu
Spark is the ideal data processing and ingestion tool for Kudu. Spark SQL and the DataFrame API makes it easy to interact with Kudu. I discuss Spark and Kudu integration in more detail in Chapter 6.
You use Spark with Kudu using the DataFrame API. You can use the --packages option in spark-shell or spark-submit to include kudu-spark dependency. You can also manually download the jar file from central.maven.org and include it in your --jars option. Use the kudu-spark2_2.11 artifact if you are using Spark 2 with Scala 2.11. For example:
Kudu Context
You use a Kudu context in order to execute DML statements against a Kudu table. xvii For example, if we need to insert data into a Kudu table:
Insert the DataFrame into Kudu table. I assume the table already exists.
Confirm that the data was successfully inserted.
I discuss Spark and Kudu integration in more detail in Chapter 6.
Note
Starting in Kudu 1.6, Spark performs better by taking advantage of scan locality. Spark will scan the closest tablet replica instead of scanning the leader, which could be in a different tablet server.
Spark Streaming and Kudu
In our example shown in Listing 2-1, we will use Flafka (Flume and Kafka) and Spark Streaming to read data from a Flume spooldir source, store it in Kafka, and processing and writing the data to Kudu with Spark Streaming.
A new stream processing engine built on Spark SQL was included in Spark 2.0 called Structured Streaming. Starting with Spark 2.2.0, the experimental tag from Structured Streaming has been removed. However, Cloudera still does not support Structured Streaming as of this writing (CDH 5.13). Chapter 7 describes Flafka and Spark Streaming in more detail.
Spark Streaming and Kudu
Listing 2-2 shows the flume configuration file, with Kafka used as a flume channel.
Flume configuration file
After compiling the package, submit the application to the cluster to execute it.
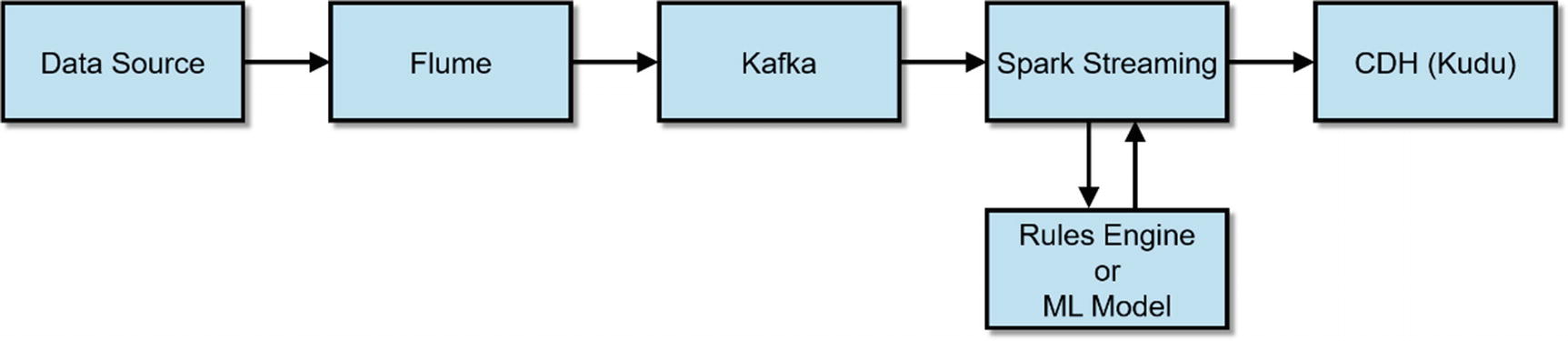
A Flafka pipeline with Spark Streaming and Kudu
Kudu C++, Java, and Python Client APIs
Kudu provides NoSQL-style Java, C++, and Python client APIs. Applications that require the best performance from Kudu should use the client APIs. In fact, some of the data ingestion tools discussed in Chapter 7, such as StreamSets, CDAP, and Talend utilize the client APIs to ingest data into Kudu. DML changes via the API are available for querying in Impala immediately without the need to execute INVALIDATE METADATA.
Kudu Java Client API
Listing 2-3 provides an example using the Java client API.
Sample Java code using the Kudu client API
Maven Artifacts
You will need the following in your pom.xml file.
Kudu Python Client API
The Python client API provides an easy way to interact with Kudu. The Python API is still in experimental stage and might change at any time. See Listing 2-4 for an example.
Sample Python code using the Kudu client API
Kudu C++ Client API
Kudu also provides a C++ client API. See Listing 2-5 for an example.
Sample C++ code using the Kudu client API
More examples xviii can be found on Kudu’s official website xix and github repository. xx The sample code available online was contributed by the Kudu development team and served as reference for this chapter.
Backup and Recovery
Kudu doesn’t have a backup and recovery utility. However, there are a few ways to back up (and recover) Kudu tables using Impala, Spark, and third-party tools such as StreamSets and Talend.
Note
HDFS snapshots cannot be used to back up Kudu tables since Kudu data does not reside in HDFS. xxi
Backup via CTAS
The simplest way to back up a Kudu table is to use CREATE TABLE AS (CTAS) . You’re basically just creating another copy of the Kudu table in HDFS, preferably in Parquet format (or other compressed format), so you can copy the file to a remote location such as another cluster or S3.
You can create the table first so you can customize table options if needed, and then use INSERT INTO to insert data from the Kudu table.
Note
The CREATE TABLE LIKE syntax is not supported on Kudu tables. If you try to use the syntax to create a table, you will receive an error message similar to the following: “ERROR: AnalysisException: Cloning a Kudu table using CREATE TABLE LIKE is not supported.”
Check the files with the HDFS command.
Copy the Parquet Files to Another Cluster or S3
You can now copy the Parquet files to another cluster using distcp.
You can also copy the files to S3.
To maintain consistency, note that I used the -pb option to guarantee that the special block size of the Parquet data files is preserved. xxii
Note
Cloudera has a cluster replication feature called Cloudera Enterprise Backup and Disaster Recovery (BDR) . BDR provides an easy-to-use graphical user interface that lets you schedule replication from one cluster to another. BDR does not work with Kudu, but you can replicate the destination Parquet files residing in HDFS. xxiii
Export Results via impala-shell to Local Directory, NFS, or SAN Volume
Impala-shell can generate delimited files that you can then compress and copy to a remote server or NFS/SAN volume. Note that this method is not appropriate for large tables.
Export Results Using the Kudu Client API
The Kudu client API can be used to export data as well. See Listing 2-6 for an example.
Sample Java code using the Kudu client API to export data
Compile the java code and run it from the command line. Redirect the results to a file. This method is appropriate for small data sets.
Export Results with Spark
You can also back up data using Spark. This is more appropriate for large tables since you can control parallelism, the number of executors, executor cores, and executor memory.
Start by creating a Data Frame.
Save the data in CSV format.
Or you can save it as Parquet.
Using coalesce to limit the amount of files generated when writing to HDFS may cause performance issues. I discuss coalesce in more details in Chapter 5.
Replication with Spark and Kudu Data Source API
We can use Spark to copy data from one Kudu cluster to another.
Start the spark-shell.
Connect to the Kudu master and check the data in the users table. We’re going to sync this Kudu table with another Kudu table in another cluster.
Let’s go ahead and insert the data to a table in another Kudu cluster. The destination table needs to be present in the other Kudu cluster.
Verify the data in the destination table.
The rows were successfully replicated.
Real-Time Replication with StreamSets
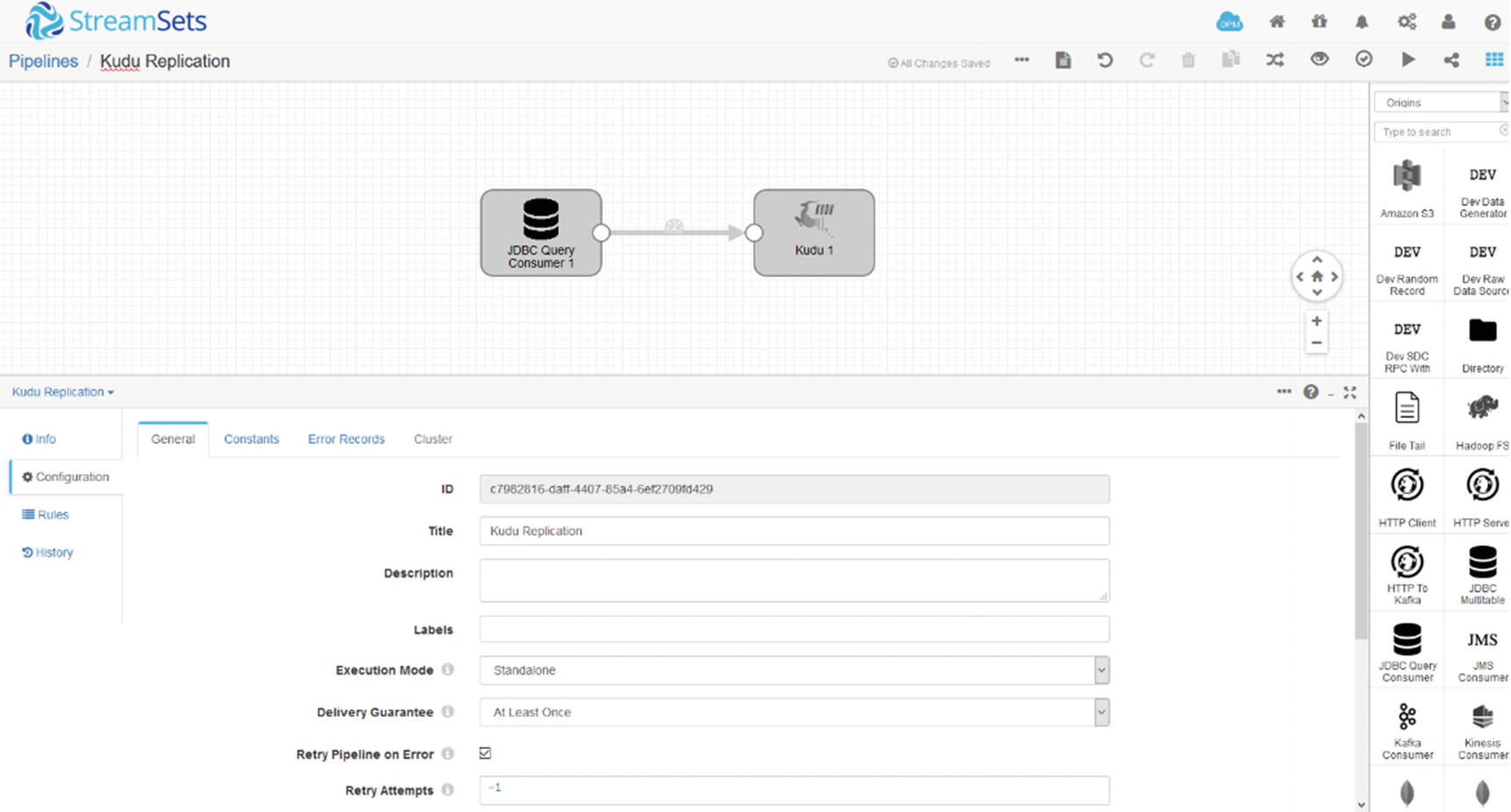
StreamSets and Kudu
The JDBC Multitable Consumer origin reads multiple tables in the same database. The JDBC Multitable Consumer origin is appropriate for database replication. StreamSets includes a Kudu destination; alternatively the JDBC Producer is a (slower) option and can be used to replicate data to other relational databases. Chapter 7 covers StreamSets in more detail.
Replicating Data Using ETL Tools Such as Talend, Pentaho, and CDAP
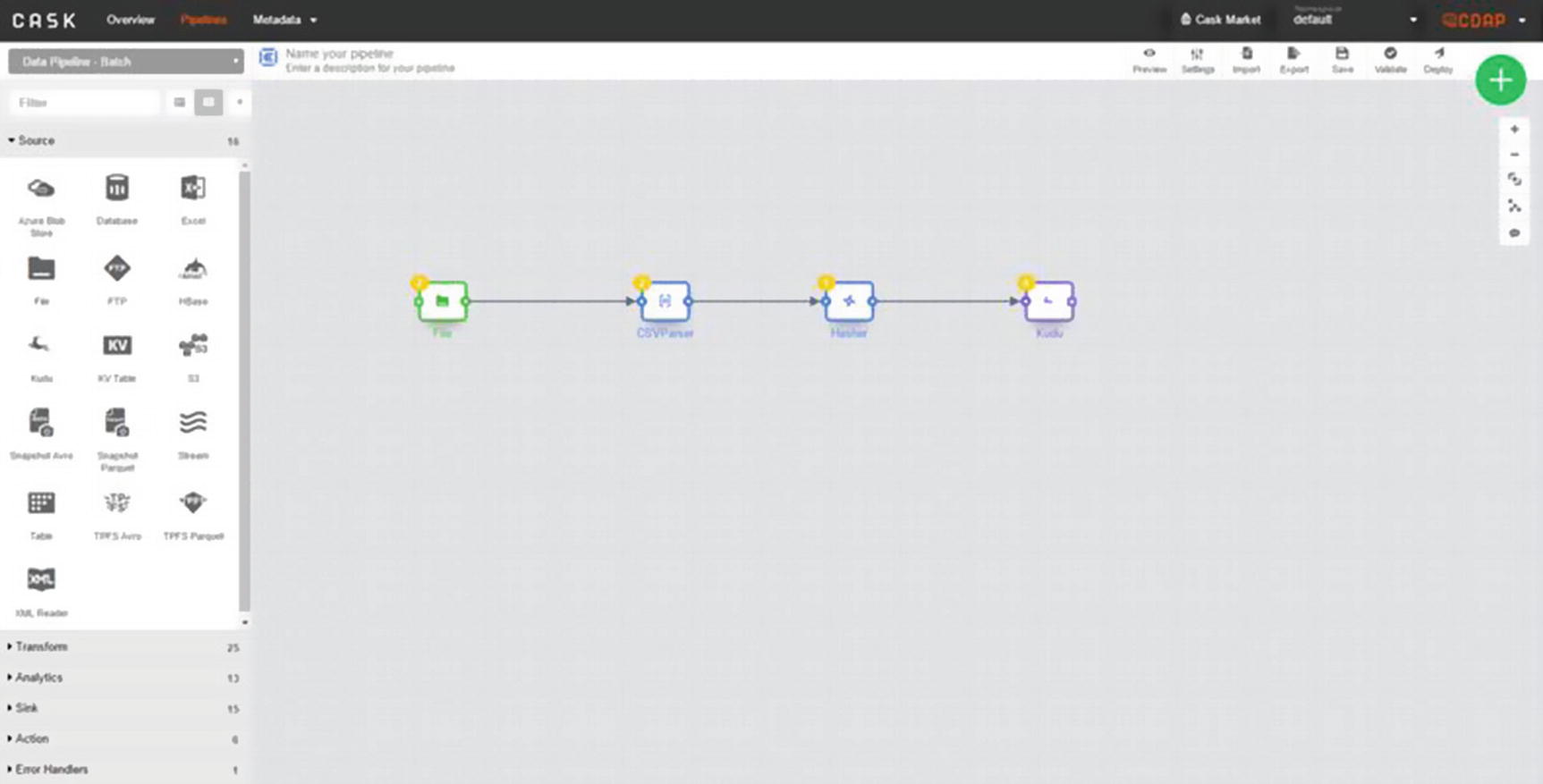
ETL with CDAP and Kudu
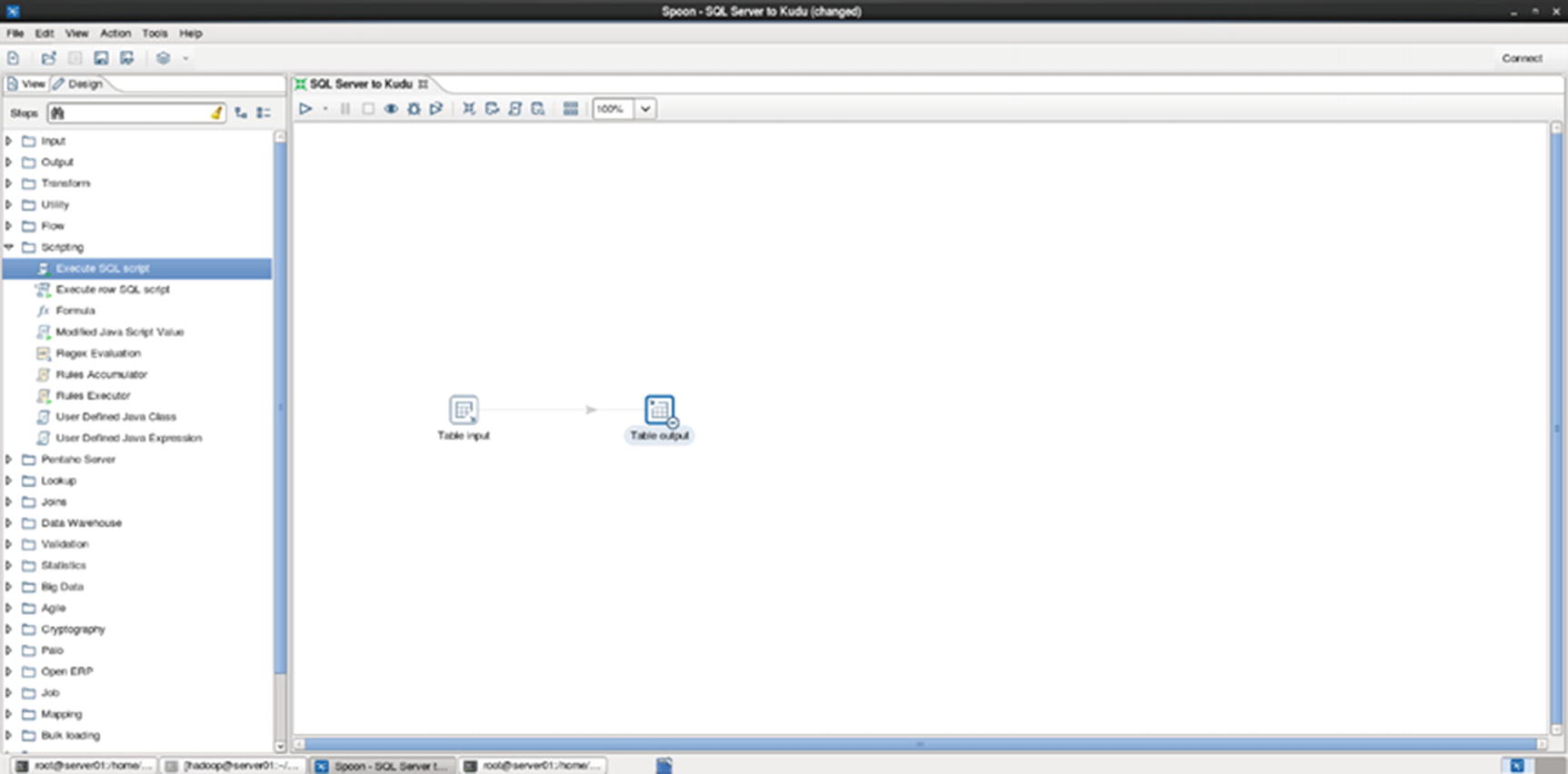
ETL with Pentaho and Kudu
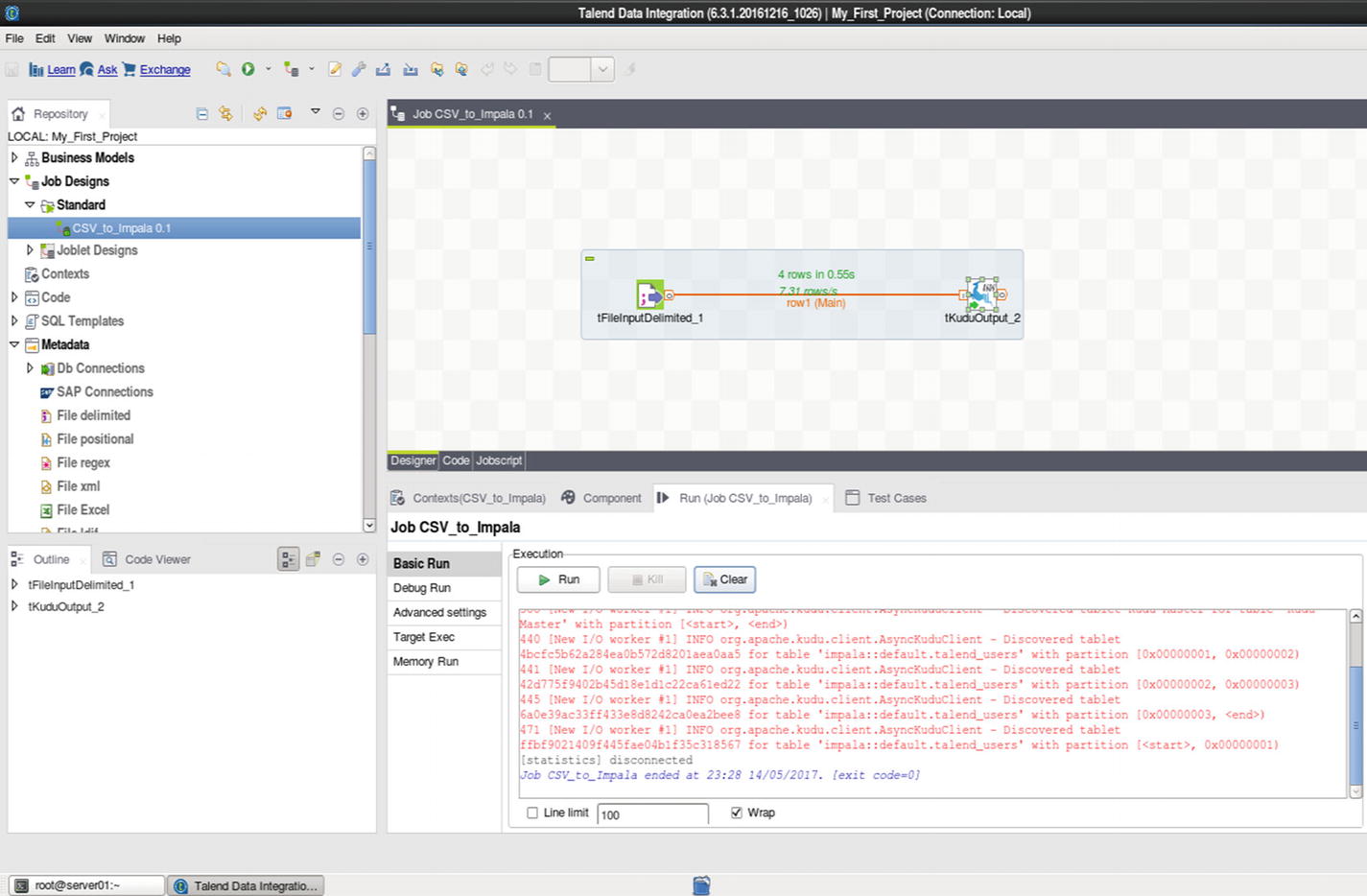
ETL with Talend and Kudu
Note
Talend Kudu components are provided by a third-party company, One point Ltd. These components are free and downloadable from the Talend Exchange at – https://exchange.talend.com/ . The Kudu Output and Input components need to be installed before you can use Talend with Kudu.
Python and Impala
Using Python is not the fastest or most scalable way to back up large Kudu tables, but it should be adequate for small- to medium-sized data sets. Below is a list of the most common ways to access Kudu tables from Python.
Impyla
Cloudera built a Python package known as Impyla. xxiv Impyla simply communicates with Impala using standard ODBC/JDBC. One of the nice features of Impyla is its ability to easily convert query results into pandas DataFrame (not to be confused with Spark DataFrames). Here’s an example.
pyodbc
pyodbc is a popular open source Python package that you can use to access databases via ODBC/JDBC. xxv Here’s an example on how to use pyodbc. To learn more about pyodbc, visit its github page at github.com/mkleehammer/pyodbc.
SQLAlchemy
SQLAlchemy is an SQL toolkit for Python that features an object-relational mapper (ORM). To learn more about SQLAlchemy, visit its website at sqlalchemy.org. Here’s an example on how to use SQLAlchemy to connect to Impala.
High Availability Options
Aside from Kudu , having a default tablet replica factor of 3 (which can be increased to 5 or 7), there are no built-in high availability tools or features available for Kudu. Fortunately, you can use built-in components in Cloudera Enterprise and third-party tools such as StreamSets to provide high availability capabilities to Kudu. High availability can protect you from complete site failure by having two or more Kudu clusters. The clusters can be in geographically distributed data centers or cloud providers. xxvi Just be aware that the amount of data that is being replicated could impact performance and cost. An added benefit of having an active-active environment is being able to use both clusters for different use cases. For example, a second cluster can be used for ad hoc queries, building machine learning models, and other data science workloads, while the first cluster is used for real-time analytics or use cases with well-defined SLAs. Let’s explore a few high availability options for Kudu.
Active-Active Dual Ingest with Kafka and Spark Streaming
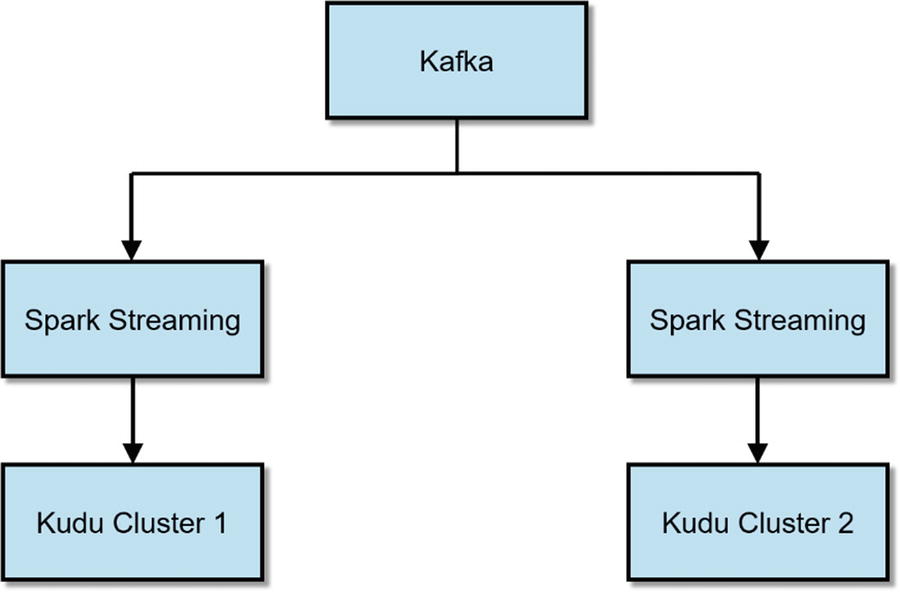
Active-Active Dual Ingest with Kafka and Spark Streaming
Active-Active Kafka Replication with MirrorMaker
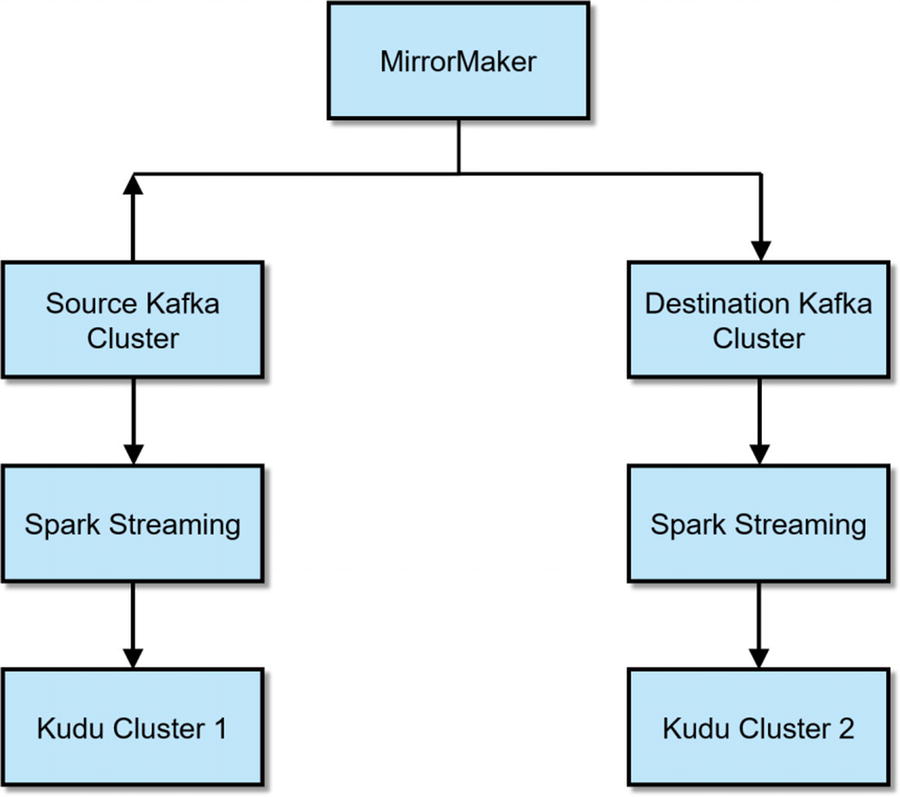
Active-Active Kafka Replication with MirrorMaker
Active-Active Dual Ingest with Kafka and StreamSets
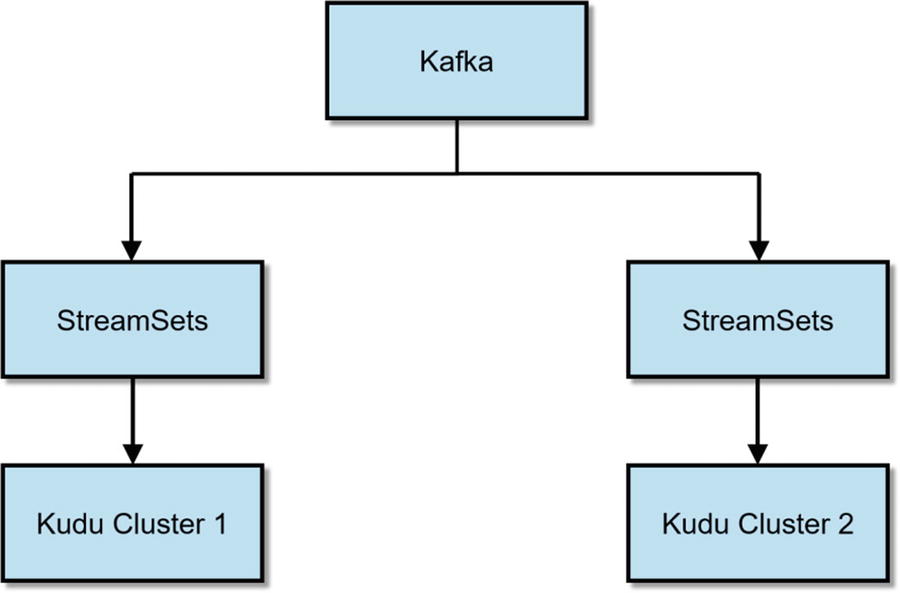
Active-Active Dual Ingest with Kafka and StreamSets
Active-Active Dual Ingest with StreamSets
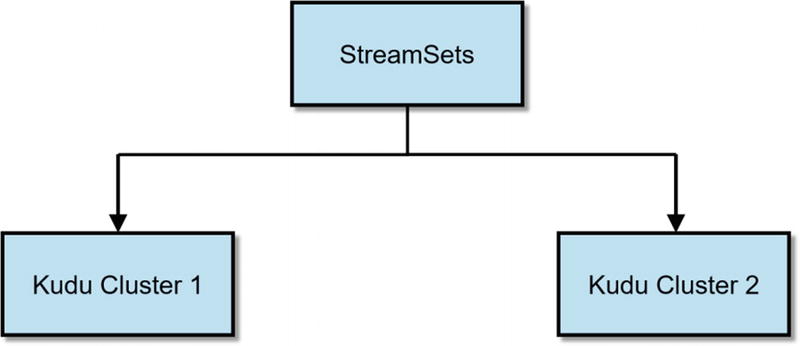
Active-Active Dual Ingest with Kafka and StreamSets
Administration and Monitoring
Just like other data management platforms, Kudu provides tools to aid in system administration and monitoring.
Cloudera Manager Kudu Service
Cloudera Manager is Cloudera’s cluster management tool, providing a single pane of glass for administering and managing Cloudera Enterprise clusters. With Cloudera Manager, you can perform common administration tasks such as starting and stopping the Kudu service, updating configuration, monitoring performance, and checking logs.
Kudu Master Web UI
Kudu Masters provide a web interface (available on port 8051) that provides information about the cluster. It displays information about tablet servers, heartbeat, hostnames, tables, and schemas. You can also view details on available logs, memory usage, and resource consumption.
Kudu Tablet Server Web UI
Each table server also provides a web interface (available on port 8050) that provides information about the tablet servers cluster. It displays more detailed information about each tablet hosted on the tablet servers, debugging and state information, resource consumption, and available logs.
Kudu Metrics
Kudu provides several metrics that you can use to monitor and troubleshoot your cluster. You can get a list of available Kudu metrics by executing $ kudu-tserver --dump_metrics_json or kudu-master --dump_metrics_json. Once you know the metric you want to check, you can collect the actual value via HTTP by visiting /metrics end-point. These metrics are also collected and aggregated by Cloudera Manager. For example:
Kudu Command-Line Tools
In addition to Cloudera Manager and the web user interfaces accessible provided by the master and tablet servers, Kudu includes command-line tools for common system administration tasks.
Validate Cluster Health
ksck: Checks that the cluster metadata is consistent and that the masters and tablet servers are running. Ksck checks all tables and tablets by default, but you can specify a list of tables to check using the tables flag, or a list of tablet servers using the tablets flag. Use the checksum_scan and checksum_snapshot to check for inconsistencies in your data.
Usage:
File System
check: Check a Kudu filesystem for inconsistencies
Usage:
list: Show list of tablet replicas in the local filesystem
Usage:
data_size: Summarize the data size/space usage of the given local replica(s).
Usage:
Master
status: Get the status of a Kudu Master
Usage:
timestamp: Get the current timestamp of a Kudu Master
Usage:
list: List masters in a Kudu cluster
Usage:
Measure the Performance of a Kudu Cluster
loadgen: Run load generation with optional scan afterward
loadgen inserts auto-generated random data into an existing or auto-created table as fast as the cluster can execute it. Loadgen can also check whether the actual count of inserted rows matches the original row count.
Usage:
Table
delete: Delete a table
Usage:
list: List all tables
Usage:
Tablets
leader_step_down: Force the tablet’s leader replica to step down
Usage:
add_replica: Add a new replica to a tablet’s Raft configuration
Usage:
move_replica: Move a tablet replica from one tablet server to another
The replica move tool effectively moves a replica from one tablet server to another by adding a replica to the new server and then removing it from the old one.
Usage:
Tablet Server
status: Get the status of a Kudu Tablet Server
Usage:
timestamp: Get the current timestamp of a Kudu Tablet Server
Usage:
list: List tablet servers in a Kudu cluster
Usage:
Consult Kudu’s online command-line reference guide xxvii for a complete list and description of Kudu’s command-line tools.
Known Issues and Limitations
Kudu does not support DECIMAL, CHAR, VARCHAR, DATE, and complex types like ARRAY, MAP, and STRUCT.
Kudu tables can have a maximum of 300 columns.
Kudu does not have secondary indexes.
Kudu does not have foreign keys.
Multi-row and multi-table transactions are not supported.
Kudu does not have a built-in backup and recovery and high availability feature.
Kudu does not support row, column, and table-level role-based access control.
Kudu recommends 100 as a maximum number of tablet servers.
Kudu recommends 3 as a maximum number of masters.
Kudu recommends 8TB as the maximum amount of stored data, post-replication and post-compression, per tablet server.
Kudu recommended 2000 as a maximum number of tablets per tablet server, post-replication.
Kudu recommends 60 as a maximum number of tablets per table for each tablet server, post-replication, at table-creation time.
Kudu does not support rack-awareness, multiple data centers, and rolling restarts.
For a more complete and up-to-date list of Kudu’s limitations, consult Cloudera’s online documentation. xxviii
Security
Kudu supports Kerberos for strong authentication. Communication between Kudu clients and servers is encrypted with TLS. Kudu does not support table, row, or column-level access control. Instead it uses a white-list style access control list to implement coarse-grained authorization. Two levels of access include Superuser and User. Unauthenticated users will be unable to access the Kudu cluster. xxix
There’s still a lot of work to be done from a security standpoint. For the meantime, additional suggestions to tighten up security include restricting direct access to the Kudu tables and implementing role-based access control via the business intelligence tool’s semantic layer. Implementing databases views to mimic row and column-level role-based access control is another option. Configuring IP access lists to restrict access from certain IP addresses to the port used by the master for RPC (the default port is 7051) can also be explored.
Consult Cloudera’s online documentation for a more up-to-date development on Kudu security.
Summary
Although Hadoop is known for its ability to handle structured, unstructured, and semi-structured data, structured relational data remains the focus of most companies’ data management and analytic strategies and will continue to be in the foreseeable future. xxx In fact, a majority of the big data use cases involves replicating workloads from relational databases. Kudu is the perfect storage engine for structured data. Throughout the book, we will focus on Kudu and how it integrates with other projects in the Hadoop ecosystem and third-party applications to enable useful business use cases.
References
- i.
Globenewswire; “Cloudera Announces General Availability of Apache Kudu with Release of Cloudera Enterprise 5.10,” Cloudera, 2017, https://globenewswire.com/news-release/2017/01/31/912363/0/en/Cloudera-Announces-General-Availability-of-Apache-Kudu-with-Release-of-Cloudera-Enterprise-5-10.html
- ii.
Todd Lipcon; “A brave new world in mutable big data: Relational storage,” O’Reilly, 2017, https://conferences.oreilly.com/strata/strata-ny/public/schedule/speaker/75982
- iii.
Jimmy Xiang; “Apache HBase Write Path,” Cloudera, 2012, https://blog.cloudera.com/blog/2012/06/hbase-write-path/
- iv.
Apache Software Foundation; “Introducing Apache Kudu,” ASF, 2017, https://kudu.apache.org/docs/#kudu_use_cases
- v.
Apache Software Foundation; “The Apache Software Foundation Announces Apache® Kudu™ v1.0,” ASF, 2017, https://blogs.apache.org/foundation/entry/the_apache_software_foundation_announces100
- vi.
Pat Patterson; “Innovation with @ApacheKafka, #StreamSets, @ApacheKudu & @Cloudera at the Australian @DeptDefence - spotted on the Kudu Slack channel,” Twitter, 2017, https://twitter.com/metadaddy/status/843842328242634754
- vii.
Todd Lipcon; “Kudu: Storage for Fast Analytics on Fast Data,” Cloudera, 2015, https://kudu.apache.org/kudu.pdf
- viii.
Diego Ongaro and John Ousterhout; “In Search of an Understandable Consensus Algorithm
(Extended Version),” Stanford University, 2014, https://raft.github.io/raft.pdf
- ix.
Diego Ongaro; “Consensus: Bridging Theory and Practice,” Stanford University, 2014, https://github.com/ongardie/dissertation#readme
- x.
Neil Chandler; “Oracle’s Locking Model – Multi Version Concurrency Control,” Neil Chandler, 2013, https://chandlerdba.com/2013/12/01/oracles-locking-model-multi-version-concurrency-control/
- xi.
Oracle; “Multiversion Concurrency Control,” Oracle, 2018, https://docs.oracle.com/cd/B19306_01/server.102/b14220/consist.htm#i17881
- xii.
Microsoft; “Database Concurrency and Row Level Versioning in SQL Server 2005,” Microsoft, 2018, https://technet.microsoft.com/en-us/library/cc917674.aspx
- xiii.
Teradata; “About Concurrency Control,” Teradata, 2018, https://info.teradata.com/HTMLPubs/DB_TTU_16_00/index.html#page/General_Reference%2FB035-1091-160K%2Fvju1472241438286.html%23
- xiv.
David Alves and James Kinley; “Apache Kudu Read & Write Paths,” Cloudera, 2017, https://blog.cloudera.com/blog/2017/04/apache-kudu-read-write-paths/
- xv.
Microsoft; “Using decimal, float, and real Data,” Microsoft, 2018, https://technet.microsoft.com/en-us/library/ms187912(v=sql.105).aspx
- xvi.
Apache Impala; “TIMESTAMP Data Type,” Apache Impala, 2017, https://impala.apache.org/docs/build/html/topics/impala_timestamp.html
- xvii.
Cloudera; “Example Impala Commands With Kudu,” Cloudera, 2017, https://kudu.apache.org/docs/developing.html#_kudu_integration_with_spark
- xviii.
William Berkeley, “scantoken_noncoveringrange.cc,” Cloudera, 2017, https://gist.github.com/wdberkeley/50e2e47548a0daa3d3bff68e388da37a
- xix.
Apache Kudu, “Developing Applications With Apache Kudu,” Apache Kudu, 2017, http://kudu.apache.org/docs/developing.html
- xx.
Apache Kudu; “Kudu C++ client sample,” Apache Kudu, 2018, https://github.com/cloudera/kudu/tree/master/src/kudu/client/samples
- xxi.
Apache Kudu; “Apache Kudu FAQ,” Apache Kudu, 2018, https://kudu.apache.org/faq.html
- xxii.
Cloudera; “Using the Parquet File Format with Impala Tables”, Cloudera, 2018, https://www.cloudera.com/documentation/enterprise/latest/topics/impala_parquet.html
- xxiii.
Cloudera; “How To Back Up and Restore HDFS Data Using Cloudera Enterprise BDR,” Cloudera, 2018, https://www.cloudera.com/documentation/enterprise/latest/topics/cm_bdr_howto_hdfs.html
- xxiv.
Cloudera; “A New Python Client for Impala”, Cloudera, 2018, http://blog.cloudera.com/blog/2014/04/a-new-python-client-for-impala/
- xxv.
Cloudera; “Importing Data into Cloudera Data Science Workbench,” Cloudera, 2018, https://www.cloudera.com/documentation/data-science-workbench/latest/topics/cdsw_import_data.html#impala_impyla
- xxvi.
Cloudera; “Implementing Active/Active Multi-Cluster Deployments with Cloudera Enterprise,” Cloudera, 2018, https://www.cloudera.com/content/dam/www/marketing/resources/whitepapers/implementing-active-deployments-with-cloudera-enterprise-whitepaper.pdf.landing.html
- xxvii.
Cloudera; “Apache Kudu Command Line Tools Reference,” Cloudera, 2018, https://kudu.apache.org/docs/command_line_tools_reference.html
- xxviii.
Cloudera; “Impala Integration Limitations,” Cloudera, 2018, https://www.cloudera.com/documentation/kudu/latest/topics/kudu_known_issues.html#impala_kudu_limitations
- xxix.
Cloudera; “Apache Kudu Security,” Cloudera, 2018, https://www.cloudera.com/documentation/kudu/latest/topics/kudu_security.html
- xxx.
Cloudera; “Dell Survey: Structured Data Remains Focal Point Despite Rapidly Changing Information Management Landscape,” Cloudera, 2018, http://www.dell.com/learn/us/en/uscorp1/press-releases/2015-04-15-dell-survey