
5
An Interactive Attention Network with Stacked Ensemble Machine Learning Models for Recommendations
Ahlem DRIF1, SaadEddine SELMANI1 and Hocine CHERIFI2
1Computer Sciences Department, Ferhat Abbas University Setif 1, Algeria
2LIB, University of Burgundy Franche-Comté, Dijon, France
Recommender systems are broadly used to suggest goods (e.g. products, news services) that best match user needs and preferences. The main challenge comes from modeling the dependence between the various entities incorporating multifaceted information, such as user preferences, item attributes and users’ mutual influence, resulting in more complex features. To deal with this issue, we design a recommender system incorporating a collaborative filtering (CF) module and a stacking recommender module. We introduce an interactive attention mechanism to model the mutual influence relationship between aspect users and items. It allows the mapping of the original data to higher order feature interactions. In addition, the stacked recommender, composed of a set of regression models and a meta-learner, optimizes the weak learners’ performance with a strong learner. The developed stacking recommender considers the content for recommendation to create a profile model for each user. Experiments on real-world datasets demonstrate that the proposed algorithm can achieve more accurate predictions and higher recommendation efficiency.
5.1. Introduction
Recommender systems have become an integral part of e-commerce sites and other platforms, such as social networking and movie/music rendering websites. They have a massive impact on the revenue earned by these businesses and also benefit users by reducing the cognitive load of searching and sifting through an excessive amount of data. Research around recommender systems falls into three main categories: collaborative filtering (CF) approaches, content-based approaches and hybrid approaches that combine the two techniques. CF recommender systems imput the unspecified ratings because observed ratings are often highly correlated across various users and items. Content-based recommender systems use the descriptive attributes of items that are labeled with ratings as training data to create a user-specific classification or regression modeling. Hybrid recommenders provide many opportunities. Indeed, various aspects originating from different systems are combined to achieve the best of both worlds. Many researchers deploy deep learning algorithms into recommendation systems to increase accuracy and solve the cold start problem. Furthermore, deep learning has shown its effectiveness in capturing the nonlinearity of user-item interconnections. He et al. (2017) propose a neural architecture with the potential to learn better representations, extract features and generate users-item interaction history. In the works (Musto et al. 2016; Tan et al. 2016; Okura et al. 2017), the authors develop recommender systems based on recurrent neural networks (RNNs) to model the temporal dynamics and sequential evolution of content information. Tang et al. (2018) propose a sequential recommendation with convolutional neural networks (CNNs). Sequential patterns are learned as local features of images using convolutional filters. In addition, autoencoders prove their effectiveness in representing user-item interactions for easy and accurate collaborative filtering. Liang et al. (2018) propose variational autoencoders for collaborative filtering (MultiVAE).
The authors define a generative model with a multinomial likelihood representation. They use Bayesian inference for parameter estimation. Drif et al. (2020) propose an ensemble variational autoencoder framework for recommendations (EnsVAE). This architecture allows the transformation of the sub-recommenders’ predicted utility matrix into interest probabilities based on a variational autoencoder.
Various entities drive the recommendation process, including item features, user preferences and user-item history interactions. In general, item profiles may be available in the form of descriptions of products. Similarly, users may have created profiles explicitly describing their interests. Numerous works propose modeling the context-dependence between these different entities. However, there is less work exploring users’ mutual influence on the item. In this chapter, we introduce a novel framework that models higher order user-item features, as well as interactions between users and items in latent spaces to tackle these limitations. Our main contributions are summarized as follows:
- – The proposed Interactive Personalized Recommender (IPRec) learns the weight of interactions between user actions and various features, such as user-item profile information and side information; the pieces of side information are the attributes. For example, users might be associated with a demographic, such as their name, address, age, gender or profession. An item, such as a movie, might have side information associated with it, such as the title, actors, directors and so on. Attributes are not only associated with the user and item dimensions, but also with the contextual dimensions. Providing additional side information improves rating prediction accuracy. The two components developed are (1) an interactive neural attention network-based collaborative filtering recommender; and (2) a stacked content-based recommender. Integrating these components optimizes the recommendation task. Approximating the results of this mixture model can be attempted using a weighted average of the predictions of the two different models.
- – The interactive neural attention network-based collaborative filtering recommender exploits the encoding ability of the interactive attention between users and items. It learns the most relevant weights representing users’ mutual influence on the item. Therefore, it boosts the accuracy of recommender systems by indicating which higher order feature interactions are informative for the prediction.
- – The stacked content-based recommender is composed of a stack of machine learning (ML) models. Combining the predictive power of its constituents leads to improved predictive accuracy. This recommender creates a profile model for each user and extracts valuable features from the item-based side information.
- – The empirical evaluation demonstrates that the proposed framework of “IPRec” significantly outperforms state-of-the-art baselines on several real-world datasets.
The remainder of the chapter is organized as follows. Related literature is described in section 5.2. Section 5.3 presents the proposed architecture. Experimental settings are presented in Section 5.4. Experimental results are reported and discussed in section 5.5. Section 5.6 summarizes the conclusions.
5.2. Related work
5.2.1. Attention network mechanism in recommender systems
Although several deep learning models provide a satisfactory solution to recommendation systems, they are less effective when new items do not accumulate enough data. The attention mechanism (Vaswani et al. 2017) has attracted interest from researchers as a solution to this cold start problem in recommendation systems. The attention mechanism enables the model to impose different weights on inputs, depending on the context. Tay et al. (2018) propose a multi-pointer learning scheme that learns to combine multiple views of user-item interactions based on the pointer networks. They apply a co-attention mechanism to select the most informative review from the review bank of each user and item, respectively. Liu et al. (2021) have developed a sequential neural recommendation to model users’ long- and short-term preferences through aspect-level reviews. The model embeds user-related and item-related reviews into a continuous low-dimensional dense vector space using aspect-aware convolution and self-attention. Ying et al. (2018) introduce a memory attention-aware recommender system based on a memory component and an attentional mechanism to learn deep adaptive user representations.
Kang et al. (2018) propose a self-attention-based sequential model that allows long-term semantics to be captured, but makes its predictions based on relatively few actions. At each time step, the model seeks to identify which items are relevant from a user’s action history and use them to predict the next item. Zhou et al. (2018) developed a Deep Interest Network (DIN) by designing a local activation unit to adaptively learn the representation of user interests from historical behaviors concerning a particular ad. The algorithm learns to aggregate the sequence of users’ history to form a user embedding. User embedding is regarded as the weighted sum of item embeddings, and an attention network obtains the weight of each item embedding. In Yakhchi et al. (2020), the authors propose a Deep Attention-based Sequential (DAS) model. It deals with the representation of false dependencies between items when modeling a user’s long-term preferences by attention mechanism.
The recommender engine learns to aggregate the users’ history sequence to compute the attention weighted sum of item embeddings in previous work. By contrast, the proposed framework does not only learn the interaction between user interests and item embeddings, but it also adds a new component to learn the mutual influence generated by the contributions of items that carry collaborative signals on user decisions, helping to account for complex user-item interactions.
5.2.2. Stacked machine learning for optimization
Ensemble machine learning algorithms enhance the predictions of simple and understandable models. They require a more sophisticated technique to prepare the model and more computational resources to train the model. They are wrappers for a set of smaller, concrete pre-trained models. The wrapper then follows a well-defined strategy to aggregate their predictions into a final one. Several ensemble approaches have been proposed, such as voting classifiers, bagging and pasting, boosting and stacking (Pavlyshenko et al. 2018). Stacking is a rather simple idea that can leverage one of the most powerful ensemble models possible. Instead of using a trivial aggregation function such as “mode” and “mean”, stacking uses a meta-learner model that learns the mapping from lower predictions to the label. A stacked generalization ensemble can use the set of predictions as a context and conditionally decide to weigh the input predictions differently, potentially resulting in better performance (Wolpert et al. 1992).
Numerous approaches combining multiple classifiers based on meta-learning have been proposed. Reid and Grudic (2009) apply regularization to linear stack generalization at the combiner level to avoid the over-fitting problem and improve performance. Jurek et al. (2014) propose a meta-learning-based approach incorporating an unsupervised learning method at the meta-level. All of the base classifiers initially classify each instance from the validation set (Jurek et al. 2014). Outputs of the classification process are considered later as new attributes. The K-Means clustering technique divides all instances from the validation set into clusters according to the new attributes. The collection of clusters is considered as a final meta-model, where each cluster represented one class. Deng et al. (2012b) propose a kernel deep convex networks (K-DCN) architecture composed of a variable number of modules stacked together to form the deep architecture. The deep stacking network (DSN) enabling parallel training on very large-scale datasets is proposed in Deng et al. (2012a).
For recommendation, Otunba et al. (2019) stack an ensemble of a generalized matrix factorization (GMF) and multi-layer perceptron (MLP) that propagates the prediction from constituent models through other constituent models to final output. Bao et al. (2009) combine predictions from multiple recommendation engines to generate a single prediction. They first define each component recommendation engine as a level-1 predictor. Then they learn a level-2 predictor, using a meta-learning algorithm, with predictions of the component engines as meta-features. The level-2 predictor can be either a linear function or a nonlinear function based on the meta-learning algorithm employed. They define a new meta-feature which represents properties of the input users/items as additional meta-features. It allows the combination of component recommendation engines at runtime based on user/item characteristics. In Da et al. (2016), the authors develop three ensemble approaches based on multimodal interactions. Different types of users feedback processed individually by traditional recommendation algorithms are combined in order to optimize the modeling of users’ profiles. Unlike previous works with stacked recommenders, the stacking content-based recommender considers the content for recommendation to create a profile model for each user. Its main advantage is the ability of the embedding representation to integrate the side information in the hybrid architecture.
5.3. Interactive personalized recommender
The proposed framework is a mixture of a collaborative interactive attention network recommender and a deep-stacked recommendation component. It gives more capacity to model the interaction characteristic. We build a joint user and item interactive attention maps to predict a distribution over the items. The main idea behind this attention network model is to learn the most relevant weights that represent the users’ mutual influence on the item. Figure 5.1 illustrates the mutual interactions between users and items. For example, both user 1 and user 3 rate the same item. User 2 and user 3 rate item 4. Therefore, we deduce that item 4 can be interesting for user 1. This is a kind of a first-order interaction. In the same way, we can observe the interaction between user 1 and user 2 regarding item 6. Moreover, we deduce a mutual influence that can be defined as entities dependencies of more than one order interaction level. For example, user 3 is influenced by the interest of user 2 (a similar user to user 1) generating an interest toward item 6. This component aims at modeling the context-dependence between the different entities by integrating the user-item interaction and the users’ mutual influence on items.
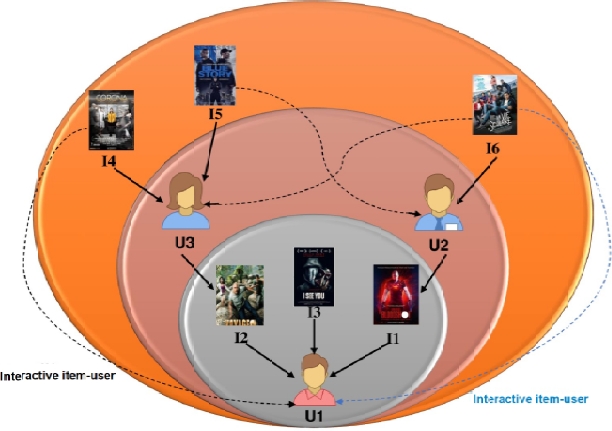
Figure 5.1. The Interactive Personalized Recommender framework models the mutual influence between the different entities
5.3.1. Notation
A robust way to formulate a recommendation task is to approach it as a prediction problem. Thus, the interactions between users and items are represented in the form of a utility matrix R. For each user u ∈ U, the recommender system attempts to predict all of the unspecified ratings ȓu. Let U = u1, u2, ..., un and I = i1, i2, ..., im be the sets of users and items, respectively, where n is the number of users, and m is the number of items. The matrix factorization algorithm decomposes a matrix M(n×m) into two matrices P E IRN×K and Q E IRM×K. A user’s interaction on an item is modeled as the inner product (interaction function) of their latent vectors. Let ui be the ground truth rating assigned by the user u on the item i. The utility matrix is defined as:
where K denotes the dimension of the latent space. Latent factor models are a state-of-the-art methodology for model-based collaborative filtering. Matrix factorization techniques are a class of widely successful latent factor models that attempt to characterize items and users using vectors of factors inferred from item rating patterns. High correspondence between item and user factors leads to a recommendation. The matrix factorization performs remarkably well on dyadic data prediction tasks. However, it fails to capture the heterogeneous nature of objects and their interactions, as well as failing to model the context in which a rating is given. In fact, latent factor models are inherently linear, which limits their modeling capacity for recommendation. Recently, a growing body of work adding crafted nonlinear features into the linear latent factor models has been introduced, powered by neural networks. In this chapter, we use the GloVe embedding with 50 dimensions in order to represent the latent space.
A training set T is consisted of N tuples. Each tuple (u, i, ȓui) denotes a rating by user u for item i. For a given predicted rating matrix, the normalization is done on a user-basis. For each user ∈ U, the minimal rating min = min (rs(ui)) and the maximal rating max = max (rs (ui)) are extracted. Then, the min/max scaling function is applied to ![]() as follows:
as follows:
The normalization step can be performed before, during or after the generation of the rating matrix. Moreover, one can easily adjust neural-based recommenders for this purpose. Sigmoid is used as the activation function for the output layer, ultimately skipping the use of the Min/Max scaler. In the remainder of this chapter, we use the notations given in Table 5.1.
Table 5.1. Notations
Symbol | Definitions and descriptions |
r ui | The rating value of item i by user u |
P∈ IRN×K | The latent factors for user u |
Q∈ IRM×K | The latent factors for item i |
g1(), g2() | The LSTM models applied to users and items, respectively |
eu | The user embedding layer |
ei | The item embedding layer |
a*u | Attention network of user u |
a*i | Attention network of item i |
au | The final attention weights of user u |
ai | The final attention weights of item i |
℘ | Each possible combination of the prediction set |
C | The number of observed ratings |
⊕ | The concatenation operator |
rij | A scalar referring to the rating of an item i as specified by user u |
W , b | The weight and bias in the interactive attention neural network. |
5.3.2. The interactive attention network recommender
The first component of the proposed framework is an interactive attention network recommender. Its role is to discover latent features that exhibit mutual influence between users and items. The attention mechanism has proved to be effective in various machine learning tasks such as image/video captioning (Rital et al. 2002, 2005; Xu et al. 2015) and machine translation (Bahdanau et al. 2014). It allows different parts to contribute when compressing them to a single representation. The attention mechanism is a process that mimics the actions of the human brain to selectively concentrate on a few relevant things, while ignoring others in deep neural networks. The attention mechanism emerged naturally from problems that deal with time-varying data. The core idea is that we can look at all of the different words at the same time and learn to pay attention to the correct ones depending on the task at hand.
The attention mechanism, which is simply a notion of memory, gained from attending at multiple inputs through time, emerged from problems that deal with time-varying data.
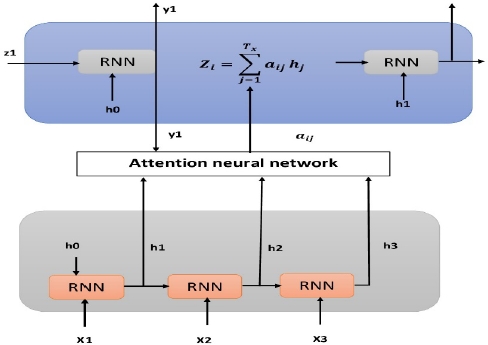
Figure 5.2. The Interactive Personalized Recommender framework models the mutual influence between the different entities
The attention network is based on the encoder and decoder which are stacked RNN layers. The encoder processes the input and produces one compact representation, called z, from all of the input time steps. It can be regarded as a compressed format of the input. The attention ensures a direct connection with each timestamp, in which the context vector z should have access to all parts of the input sequence instead of just the last one (see Figure 5.2). Thus, applying a co-attention mechanism in the context of collaborative filtering recommendation allows the discrimination of the items that are interesting for users, even those with no previous interaction, through higher attention weights.
The attention network-CF approach is inspired by the paper by Chen et al. (2017). Previous works put more emphasis on only learning the complex relationship between the target users (or items) and their neighbors by attention network. Here, we aim to exploit the encoding ability of the interactive attention between the users and the items to learn the most relevant weights that represent the users’ mutual influence on the item. The underlying idea is that some correlation between users and items with particular characteristics can reveal the possibility that an item is interesting for similar users (see Figure 5.3).
First, the list of users U and the list of items I are fed into two different embedding layers: eu and ei, respectively. It makes it possible to capture some useful latent properties of users pu and items qi. Each of these embedding layers is chained with a long short-term memory (LSTM) layer. The LSTM (Sherstinsky et al. 2020) is a variety of RNNs that can learn long sequences with long time lags. The advantage of this architecture is that LSTM units are recurrent modules, which enable long-range learning. Each LSTM state has two inputs, the current feature vector and the output vector of the previous state, ht-1, and one output vector ht. The LSTM based representation learning can be denoted as follows:
The learned representation can be denoted as H and H, respectively. The respective dimensions of H and H are d × n and d × m (d-dimensional vectors of LSTM).

Figure 5.3. The interactive attention network recommender
The attention mechanism is used to project the users and items embedding inputs into a common representation space. The proposed neural attention framework can model the high-order nonlinear relationship between users and items and mutual influence. Indeed, interactive attention on both the users and items is applied. The final rating prediction is based on all the interactive users and items features. This mechanism is explored as follows: joint user and item interactive attention maps are built and combined recursively to predict a distribution over the items. First, a matrix L ∈ IRn×m as L = tanh ![]() is computed, where Wpq is a d × d matrix of learnable parameters. The feature interaction attention map is given by:
is computed, where Wpq is a d × d matrix of learnable parameters. The feature interaction attention map is given by:
Therefore, the interactive attention models the mutual interactions between the user latent factors and item latent factors by applying a tangent function (tanh). Subsequently, an attention distribution is calculated as a probability distribution over the embedding space. The attention weights are generated through the softmax function:
The function f is a multi-layer neural network (MLP). Besides, the attention vectors of high-order interaction features can be generated by a weighted sum using the derived attention weights or a sigmoid function, given by βp and β. These latent spaces of users and items are then concatenated as follows:
In order to form the predicted score Rui, the concatenation spaces are fed into a dense layer with a sigmoid activation function as follows:
During the training phase, a grid-search method is used to learn the model parameters and set the cost function as defined below:
The model predicts interest probabilities for each possible combination of the prediction set ℘, as shown in Algorithm 1.
5.3.3. The stacked content-based filtering recommender
The content-based recommender system injects item attributes as a deciding factor for recommendations. The stacked recommender generates a user profile for each user in the form of a learned model. First, the recommender extracts “tags” from item descriptions or reviews and uses them to calculate each item’s embedding vector with the help of Stanford’s pre-trained GloVe vectors (Pennington et al. 2014). Afterward, the recommender employs the stacking ensemble learning technique to learn the profile for each user, as shown in Figure 5.4.
Let L = {L1, L2, ..., Ll} be different regression models, and xtrain be the training dataset. U and emb are independent variables. The base regression models’ hyperparameters are ∀l ∈ L θl. The number and the type of regression algorithms are tunable.
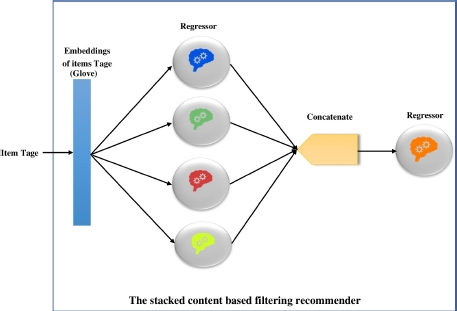
Figure 5.4. The stacked content-based filtering recommender
Each l ∈ L is trained separately with the same training dataset. Each model provides predictions for the outcomes (R), which are then cast into a meta-learner (blender). In other words, the L predictions of each regressor become features for the blender. The latter can be any model, such as linear regression, SVR or Decision Tree,...etc., as expressed in [5.11].
where the weight vector w is learned by a meta-learner.
A blender model can then be defined and tuned with its hyperparameters 0blende. It is then trained on the outputs of the stack L. It learns the mapping between the outcome of the stacked predictors and the final ground-truth ratings. The expression of the final prediction is as follows:
In order to train the two recommenders needed for the task at hand, one applies an aggregation function to merge their outputs into a single utility matrix. The IPRec framework uses the simple unweighted average aggregation function followed by encoder layers. The final predicted utility matrix ui is as follows.
5.4. Experimental settings
This section briefly reviews the datasets, evaluation measures and alternative techniques used in the experiments.
5.4.1. The datasets
MovieLens dataset: It presents real, timestamped 5-star ratings, as given by users of the MovieLens Website on different films. Furthermore, GroupLens supplied movies with their genomic tags to describe them in a machine-friendly manner. The dataset has several versions, depicted by the total number of ratings packaged in the files (Harper et al. 2015). They are:
- – MovieLens 25M: this huge dataset offers 25 million ratings, applied to 62,000 movies by 162,000 users. It was released in December 2019.
- – MovieLens 20M: the predecessor of the previous version offers 20 million ratings given by 138,000 users over 27,000 movies. It was first released in April 2015 and last updated in October 2016. Its support has been discontinued ever since.
- – MovieLens 10M: it is a rather old dataset, dated February 2009. It provides 10 million ratings applied to 10,000 movies by 72,000 users. An Interactive Attention Network 137
- – MovieLens 1M: this is the most popular MovieLens Dataset version. It is widely used for research and benchmarking recommender systems. It contains 1 million ratings from 6,000 users over 4,000 movies. Its exact specifications are in Table 5.2.
- – MovieLens Small: a small subset of the latest MovieLens Dataset version (currently MovieLens 25M), which usually contains 100,000 ratings applied to 9,000 movies over 600 users. It is generally used for educational purposes only, such as learning recommender systems.
Table 5.2. MovieLens 1M specifications
|
# of Users |
6,040 |
|
# of Movies |
3,883 |
|
# of Ratings |
1,000,209 |
|
Sparsity %o |
95.5% |
|
Item Description |
Genomic Tags |
|
User Description |
Demographics |
5.4.2. Evaluation metrics
Two influential metrics are adopted to evaluate the predictive accuracy of the recommendation framework: the mean average precision and the normalized discounted cumulative gain.
The mean average precision (MAP) is a popular metric in measuring the accuracy of information retrieval, and object detection systems (Lasfar et al. 2000; Labatut et al. 2012). For a set of queries Q, MAP calculates the mean of the average precision scores for each query q∈ Q, The result is always a value between 0 and 1, where the higher the score, the better the accuracy.
where:
- – TP: True Positives: positive items that are detected by the system as positive;
- – FP: False Positives: negative items that are detected by the system as positive;
- – Pr: the precision value considering only q-first items.
In recommender systems, we usually trim the results to return the top-k elements, where 1 <k<=q. The number of elements k depends on use: a system may show the top three trending items or the best 10 items that match the taste of the current user, etc. Therefore, a more flexible variant of MAP, referred to by MAP @, is used. The latter performs the same calculation procedure but over the smaller set of top-k elements:
The rank in which recommendations are shown has an impact on the performance of a recommender system. The normalized discounted cumulative gain (NDCG) is a ranking quality evaluation metric that is also used in information retrieval systems (Demirkesen et al. 2008; Balakrishnan et al. 2012). NDCG measures the normalized usefulness of items based on their positions in the resulting list by calculating the ratio between discounted cumulative gain (DCG) of the recommended items over the DCG of their ideal ranking. The result ∈ [0 –1] indicates the gain of the recommender. Hence, the higher this value, the better.
where:
- – DCG: the discounted cumulative gain of the predicted item set ranked by the recommender system;
- – i DCG: the discounted cumulative gain of the ideal ranking of predicted items; An Interactive Attention Network 139
- – Pos(q): the position of q, as predicted by the recommender system;
- – iPos(q): the ideal position of q.
NDCG@k is used to evaluate the ranking quality of the top-k recommended items.
5.4.3. Baselines
The personalized recommender system is compared with the following recommender systems:
- – Interactive attention network recommender: it is a novel collaborative filtering recommender system. This state-of-the-art technique is based on the co-attention mechanism. It takes its power from discriminating the importance of different feature interactions between all of the entities (user-user, item-item and users-item).
- – The stacked content-based filtering recommender: this content-based recommender system is proposed in Drif et al. (2020). The stacked ensemble exploits the strengths of embedding representation and the stacking ensemble learning for modeling the content. Here, we adopt a Random forest (Chollet et al. 2021) model as a meta-learner because it improves the predictive accuracy by fitting several decision tree classifiers on various sub-samples of the dataset.
- – Neural Collaborative Filtering (NCF) (He et al. 2017): this recommender system applies the MLP to learn the user-item interaction function.
- – Variational Autoencoders for Collaborative Filtering (MultiVAE) (Liang et al. 2018): this technique models the collaborative information in a multinomial distribution to sample prediction for items on the long tail.
- – EnsVAE:Ensemble Variational Autoencoders for Recommendations (Drif et al. 2020): the EnsVAE-compliant recommender system provides simple guidelines to build hybrids for a plethora of use cases. It is adjusted to output interest probabilities by learning the distribution of each item’s ratings and attempts to provide various novel items pertinent to users.
5.5. Experiments and discussion
5.5.1. Hyperparameter analysis
This section depicts the hyperparameters analysis step performed separately on each recommender. The proposed implementation method is based on Keras (Chollet et al. 2021). In addition, the latter runs over Tensorflow (Abadi et al. 2016), which ensures the ability to reproduce the same results by replicating the same developing and evaluating environment. The machine used throughout the whole development and evaluation phases is a MacBook Pro (16 GB 1600 MHz DDR3, GPU 2.2GHz 6-core Intel Core i7).
The stacked content-based recommender is composed of a set of regression models and a meta-learner. The idea behind stacking is to enhance weak learners with a strong learner. Therefore, a small group of weak learners that exhibit different errors would perform the same as a large set of powerful learners with similar errors (Géron et al. 2019). Consequently, we perform the analysis on stacks 1–5 and focus on the learning algorithms used by each learner, alongside the meta-learner’s hyperparameters.
The first step is to find the combination of regression models that compose the best stack. A grid search is performed over six algorithms: polynomial-kernel support vector machines (SVMpoly) (Singh et al. 2016), RBF-kernel support vector machines (SVMrbf), decision trees (DT), automatic relevance detection regression (ARD), the simple linear regression (LR) and the Random Forest. Table 5.3 reports the results of the top 5 stacks for k= 10, 30 and 50.
Table 5.3. The best scoring stacked content-based filtering recommenders
|
Mean Average Precision |
Normalized DCG | |||||
|
Stack |
MAP@10 |
MAP@30 |
MAP@50 |
NDCG@10 |
NDCG@30 |
NDCG@50 |
|
Stack 1 |
0.75 |
0.72 |
0.7 |
0.62 |
0.71 |
0.74 |
|
Stack 2 |
0.79 |
0.75 |
0.73 |
0.65 |
0.72 |
0.76 |
|
Stack 3 |
0.80 |
0.77 |
0.76 |
0.66 |
0.73 |
0.76 |
|
Stack 4 |
0.82 |
0.78 |
0.77 |
0.66 |
0.75 |
0.77 |
|
Stack 5 |
0.8 |
0.78 |
0.76 |
0.65 |
0.73 |
0.76 |
Stack 4 exhibits the higher score compared to the other stacks. The structure of each stack is as follows:
- – Stack 1: DT – LR – SVMrbf | ARD
- – Stack 2: LR – DT – ARD | SVMpoly
- – Stack 3: DT – LR – SVRpoly | ARD
- – Stack 4: LR – SVRpoly – ARD | Random Forest
- – Stack 5: LR – SVRpoly – Random Forest| ARD
The second step is to fine-tune the stack’s learners and the meta-learners hyperparameters. Here, we present the results of fine-tuning the Stack base Random Forest meta-learner. A grid search algorithm over Random Forest hyperparameters, namely: nestimators (the number of trees in the forest), maxdepth (the maximum number of levels in each decision tree), maxfeatures (the maximum number of features considered for splitting a node), min sample Leaf (min number of data points allowed in a leaf node), min sample Split (the minimum number of data points placed in a node before the node is split), is performed. The evaluation metric used is the normalized discounted cumulative gain (NDCG) at k = 10. Figure 5.5 shows the changes in NDCG scores while tweaking these hyperparameters.
The final meta-learner hyperparameters for the stacked recommender are as follows: nestimators = 300, maxdepth = 40,
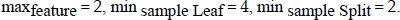
We developed an interactive attention network recommender that learns the interaction between the users and items and the mutual influence between the items and user interaction. The predicted utility matrix is generated based on the learned embeddings. Figure 5.6 illustrates the hyperparameters analysis.
For each hyperparameter, a range of values is explored to find the best set of hyperparameters. They are: the dimensions of the embedding a ∈ [30, 100], the number of dense layers after 0 ∈ [2, 20], the number of neurons per dense layer r ∈ [30, 150], the activation function used in the dense layers <Y ∈ { selu, elu, relu} and the optimizer Jc ∈ { sgd, adam, adagrad}. Results show that the best performance is achieved for the following settings: a = 50, 0 = 03, r = 100, <Y = elu, Jc = Adam.
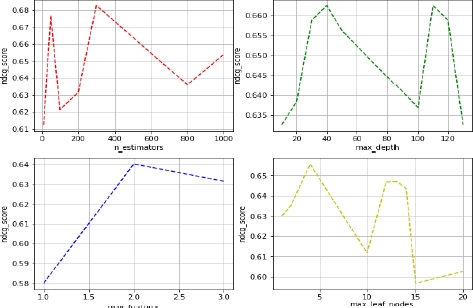
Figure 5.5. Hyperparameter searching for the stack-based random forest
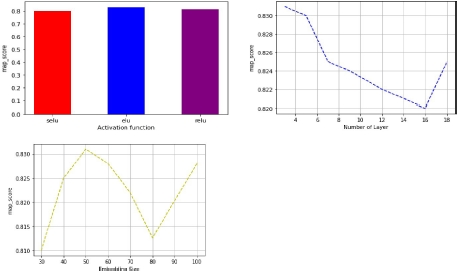
Figure 5.6. Hyperparameters analysis for interactive attention network recommender
5.5.2. Performance comparison with the baselines
To provide a better insight into the interactive attention network recommender results, we visualize a sample of the interactive co-attention weights for 10 items and four users. Figure 5.7 shows that this recommender constructs a user-item co-attention map for the final rating prediction. It identifies the most relevant weights that represent users’ mutual influence on the item. This is due to its ability to capture complementary information from each user contribution and combine them to predict the utility matrix. Indeed, the co-attention module emphasizes the dependencies between the different entities.
Table 5.4 presents the recommendation performance of all methods on MovieLens. The proposed framework outperforms all baselines according to the mean average precision. The most likely reason is that the IPRec can model the higher order feature interactions. Figure 5.8 represents the MAP@k performance versus k-top items. IPRec generates a personalized recommendation, as the MAP measure represents the fraction of relevant items in the top k recommendations averaged over all of the users.
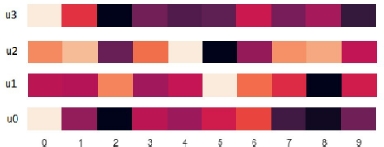
Figure 5.7. Visualization of the interactive co-attention weights for 10 items and four users, dark colors refer to low attention weights
To put it differently, IPRec can recall the relevant items for the user better than the other models. It acquires the user-item interaction and creates a user personalized task recommendation justifying its high recorded scores. In addition, both the interactive attention recommender and EnsVAE recommender produce competitive empirical results. For example, the IPRec, EnsVAE and Inter-active attention recommenders achieve MAP@10=0.89, MAP@10=0.87 and MAP@10=0.86, respectively, which are higher than the baselines. The MultiVAE models the collaborative information in the form of a multinomial distribution to sample the likelihood of presenting certain items to certain users. However, it scores weak MAP values because it does not model a rich semantic representation of data. The neural collaborative filtering (NCF) method gives a good score with k=10, MAP@10=0.74 due to the modeling of the interaction between user and item features.
Table 5.4. Recommendation accuracy scores (%) of compared methods conducted on MovieLens 1M dataset. We generate Top 10, 30 and 50 items for each user. The best performance of MAP@k and NDCG@k are highlighted with a bold font
|
Mean Average Precision |
|
Normalized DCG | ||||
|
Recommender Systems |
MAP@10 |
MAP@30 |
MAP@50 |
NDCG@10 |
NDCG@30 |
NDCG@50 |
|
Interactive attention recommender |
0.86 |
0.84 |
0.83 |
0.72 |
0.78 |
0.8 |
|
Stacked |
0.82 |
0.78 |
0.77 |
0.67 |
0.74 |
0.77 |
|
recommender | ||||||
|
IPRec |
0.89 |
0.87 |
0.86 |
0.55 |
0.65 |
0.69 |
|
EnsVAE |
0.87 |
0.84 |
0.82 |
0.7 |
0.75 |
0.77 |
|
MultiVAE |
0.62 |
0.58 |
0.54 |
0.57 |
0.62 |
0.65 |
|
NCF |
0.74 |
0.68 |
0.65 |
0.68 |
0.73 |
0.76 |
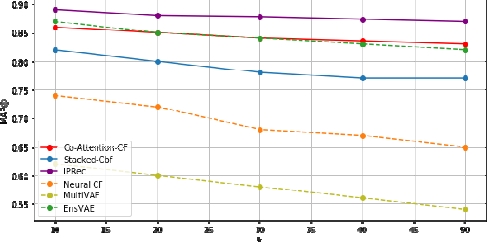
Figure 5.8. Results of the comparison on MovieLens dataset. Evaluation of the performance of top-K recommended lists, in terms of MAP. The ranking position K ranges from 1 to 50
As shown in Figure 5.9, we observe that the interactive attention recommender (Co-attention-CF) records a high NDCG score on the MovieLens dataset. In other words, the rank of an item in its top-k recommendation list is close to the one observed in the ground-truth list. Applying the attention mechanism enhances the modeling of user-item interaction. Indeed, the more positive the users toward an item, the more likely it is recommended by users with similar preferences. Note that the EnsVAE recommender and the stacked recommender still exhibit good NDCG scores. The stacked recommender is effective in obtaining the user’s overall interest built by the stack’s learners. It captures the side-information to create a profile model for each user, while optimizing the stack’s learners’ objective function.
The IPRec scores are lower compared to the above models. Due to the average aggregation of the two recommenders, it reduces the rating probabilities of some items. Given that NDCG is a ranking metric, this reduction may cause items to be misplaced on the query, reducing the NDCG score. Nevertheless, the high MAP values indicate that the top-k items are still relevant to the user, although ranked differently. In general, many opportunities exist for the hybridization of recommender systems. The ultimate goal is to use all of the knowledge available in different data sources and the algorithmic power of these various recommender systems to make robust inferences. The content-based recommender tends to integrate the various data sources more tightly (side information). In addition, the collaborative recommender is more effective when a lot of data is available. Here, we combine the scores of the two recommender systems into a single unified score by computing the weighted aggregates (average aggregation) of the scores from individual ensemble components. Using different combinations of features for building the entire recommendation system is challenging because we consider two aspects: tailoring the recommender system and improving performance. Therefore, it is a complex task to find a tradeoff between these two aspects. The main advantage of the proposed approach is that we simulate the different configurations in some recommender systems where user behavior is tightly related to the content information available in the items. Leveraging a combination of recommendation techniques boosts the recommendation system performance. Hence, the IPRec framework outperforms other baselines with a significant margin in terms of the mean average precision.
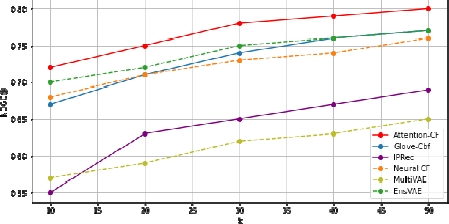
Figure 5.9. Results of the comparison on MovieLens dataset. Evaluation of the performance of top-K recommended lists, in terms of NDCG. The ranking position K ranges from 1 to 50
5.6. Conclusion
In this chapter, we have proposed and investigated a hybrid recommender system where the recommended content is accurate and personalized for each user. The IPRec model incorporates two models: the first exploits the collaborative interactions between users and items in latent spaces, and infers the mutual interactions as a result of a co-attention mechanism; the second model consists of a stacked ensemble recommender that combines several base estimator predictions with a given machine learning algorithm, in order to maximize the predictive performance. The empirical study on real-world datasets proves that IPRec significantly outperforms state-of-the-art methods in recommendation performance. In future work, we plan to extend this novel framework to other recommendation tasks that provide contextual data.
5.7. References
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., Kudlur, M., Levenberg, J., Monga, R., Moore, S., Murray, D., Steiner, B., Tucker, P., Vasudevan, V., Warden, P., Wicke, M., Yu, Y., Zheng, X. (2016). Tensorflow: A system for large-scale machine learning. Proceedings of the 12th Symposium on Operating Systems Design and Implementation, 265–283.
Bahdanau, D., Cho, K., Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. ACM International Conference on Web Search and Data Mining, arXiv preprint: 1409.0473.
Balakrishnan, S. and Chopra, S. (2012). Collaborative ranking. Proceedings of the 5th ACM International Conference on Web Search and Data Mining, 143–152.
Bao, X., Bergman, L., Thompson, R. (2009). Stacking recommendation engines with additional meta-features. Proceedings of the 3rd ACM Conference on Recommender Systems, 109–116.
Chen, J., Zhang, H., He, X., Nie, L., Liu, W., Chua, T.S. (2017). Attentive collaborative filtering: Multimedia recommendation with item and component-level attention. Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, 335–344.
Chollet, F. (2021). Keras: The Python Deep Learning Library. Astrophysics Source Code Library, ascl: 1806.022.
Da Costa, A.F. and Manzato, M.G. (2016). Exploiting multimodal interactions in recommender systems with ensemble algorithms. Information Systems, 56, 120–132.
Demirkesen, C. and Cherifi, H. (2008). A comparison of multiclass SVM methods for real world natural scenes. Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, 752–763.
Deng, L., Yu, D., Platt, J. (2012a). Scalable stacking and learning for building deep architectures. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2133–2136.
Deng, L., Tur, G., He, X., Hakkani-Tur, D. (2012b). Use of kernel deep convex networks and end-to-end learning for spoken language understanding. Proceedings of the IEEE Spoken Language Technology Workshop (SLT), 210–215.
Drif, A., Zerrad, H.E., Cherifi, H. (2020). EnsVAE: Ensemble Variational Autoencoders for Recommendations. IEEE Access, 8, 188335–188351.
Géron, A. (2019). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. O’Reilly Media, Sebastopol.
Harper, F.M. and Konstan, J.A. (2015). The MovieLens datasets: History and context. ACM Transactions on Interactive Intelligent Systems (TIIS), 5(4), 1–19.
He, X., Liao, L., Zhang, H., Nie, L., Hu, X., Chua, T.S. (2017). Neural collaborative filtering. Proceedings of the 26th International Conference on World Wide Web, 173–182.
Jurek, A., Bi, Y., Wu, S., Nugent, C. (2014). A survey of commonly used ensemble-based classification techniques. The Knowledge Engineering Review, 29(5), 551–581.
Kang, W.C. and McAuley, J. (2018). Self-attentive sequential recommendation. Proceedings of the IEEE International Conference on Data Mining (ICDM), 197–206.
Labatut, V. and Cherifi, H. (2012). Accuracy measures for the comparison of classifiers. arXiv preprint: 1207.3790.
Lasfar, A., Mouline, S., Aboutajdine, D., Cherifi, H. (2000). Content-based retrieval in fractal coded image databases. Proceedings of the 15th International Conference on Pattern Recognition. ICPR-2000, 1, 1031–1034.
Liang, D., Krishnan, R.G., Hoffman, M.D., Jebara, T. (2018). Variational autoencoders for collaborative filtering. Proceedings of the World Wide Web Conference, 689–698.
Liu, Y., Wang, Y., Zhang, J. (2012). New machine learning algorithm: Random forest. Proceedings of the International on Information Computing and Applications, 246–252.
Liu, Y., Zhang, Y., Zhang, X. (2021). An end-to-end review-based aspect-level neural model for sequential recommendation. Discrete Dynamics in Nature and Society, 2021, 6693730, Hindawi, London.
Musto, C., Greco, C., Suglia, A., Semeraro, G. (2016). Ask me any rating: A content-based recommender system based on recurrent neural networks. Proceedings of the 7th Italian Information Retrieval Workshop, 1–4.
Okura, S., Tagami, Y., Ono, S., Tajima, A. (2017). Embedding-based news recommendation for millions of users. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1933–1942.
Otunba, R., Rufai, R.A., Lin, J. (2019). Deep stacked ensemble recommender. Proceedings of the 31st International Conference on Scientific and Statistical Database Management, 197–201.
Pavlyshenko, B. (2018). Using stacking approaches for machine learning models. Proceedings of the 2nd International Conference on Data Stream Mining & Processing (DSMP), 255–258.
Pennington, J., Socher, R., Manning, C.D. (2014). Glove: Global vectors for word representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532–1543.
Reid, S. and Grudic, G. (2009). Regularized linear models in stacked generalization. International Workshop on Multiple Classifier Systems, 112–121.
Rital, S., Bretto, A., Cherifi, H., Aboutajdine, D. (2002). A combinatorial edge detection algorithm on noisy images. Proceedings of the International Symposium on VIPromCom Video/Image Processing and Multimedia Communications, 351–355.
Rital, S., Cherifi, H., Miguet, S. (2005). Weighted adaptive neighborhood hypergraph partitioning for image segmentation. Proceedings of the International Conference on Pattern Recognition and Image Analysis, 522–531.
Robertson, S. (2009). Evaluation in information retrieval. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 81–92.
Sherstinsky, A. (2020). Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Physica D: Nonlinear Phenomena, 404, 132306.
Tan, J., Wan, X., Xiao, J. (2016). A neural network approach to quote recommendation in writings. Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, 65–74.
Tang, J. and Wang, K. (2018). Personalized top-N sequential recommendation via convolutional sequence embedding. Proceedings of the 11th ACM International Conference on Web Search and Data Mining, 565–573.
Tay, Y., Luu, A.T., Hui, S.C. (2018). Multi-pointer co-attention networks for recommendation. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2309–2318.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaise, L., Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 5998–6008, arXiv: 1706.03762.
Wolpert, D.H. (1992). Stacked generalization. Neural Networks, 5(2), 241–259.
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y. (2015). Show, attend and tell: Neural image caption generation with visual attention. Proceedings of the International Conference on Machine Learning, 2048–2057.
Yakhchi, S., Beheshti, A., Ghafari, S.M., Orgun, M.A., Liu, G. (2020). Towards a deep attention-based sequential recommender system. IEEE Access, 8, 178073–178084.
Ying, H., Zhuang, F., Zhang, F., Liu, Y., Xu, G., Xie, X., Xiong, H., Wu, J. (2018). Sequential recommender system based on hierarchical attention network. Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, July, 3926–3932.
Zhou, G., Zhu, X., Song, C., Fan, Y., Zhu, H., Ma, X., Yan, Y., Jin, J., Li, H., Gai, K. (2018). Deep interest network for click-through rate prediction. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 1059–1068.
Zhou, G., Zhu, X., Song, C., Fan, Y., Zhu, H., Ma, X., Yan, Y., Jin, J., Li, H., Gai, K. (2018). Deep interest network for click-through rate prediction. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 1059–1068.
- For a color version of all the figures in this chapter, see: www.iste.co.uk/chelouah/optimization.zip