
Database Writer
Oracle uses the redo log and lgwr to make transactions durable, so we don’t need to copy changed database buffers from memory to disk the instant we change them; but it’s nice (and in almost all cases necessary) to copy changed buffers to disk at some time. It feels somehow more “natural” and safe if we have a copy of the “real” data on disk, and most systems only have limited memory anyway, so with a DB cache capable of holding N blocks, they’ve got to start copying something to disk if they want to change block N+1.
Once we know that we have to copy blocks to disk, we can start asking interesting questions such as “when do we do it?” and “how do we pick which blocks to copy?” These questions take us straight back to lgwr.
In principle, because of the way that redo works, you could pick any data block off disk at any time, check its SCN (one of the many SCNs you can find on a block is the last change SCN, the SCN at which a change was last made to a block), go to the redo log that holds that SCN, and read forward from that point, finding and applying all the change vectors for that block until you run out of redo log. At that point you will have constructed a logical match for the current in-memory block.
![]() Note It is a little-known feature of Oracle that when a session finds a corrupted data block in the DB cache, it will automatically go through the process I have just described—limited to just the online redo logs—to create a corrected, up-to-date, in-memory copy of the block. It has to pin the buffer exclusively while this is going on, but otherwise the process is transparent. The
Note It is a little-known feature of Oracle that when a session finds a corrupted data block in the DB cache, it will automatically go through the process I have just described—limited to just the online redo logs—to create a corrected, up-to-date, in-memory copy of the block. It has to pin the buffer exclusively while this is going on, but otherwise the process is transparent. The block recover feature of RMAN extended this to allow the DBA to instruct Oracle to read archived redo logs; and 11.2 introduced automatic block media recovery (see hidden parameters like _auto_bmr%) to allow the automatic use of archived logs (a feature I first saw in action when it caused a massive performance problem as three sessions all tried to recover the same index root block by scanning all the archived redo from the last few days). If there is a physical standby available, the code will even start by visiting the standby to see if it can find a recent copy of the block as a starting point for the recovery.
In practice we don’t really want to keep doing this reconstruction; and if we find that we do have to do it, we don’t want to walk through an enormous amount of redo; and we probably don’t have an unlimited amount of disk to play with, anyway, so we won’t want to keep an indefinite volume of redo logs online. Consequently, the strategy dbwr uses is basically one that minimizes the amount of work we have to do if we need to recover data blocks. The core of this strategy is to keep a record of how long ago a block was first changed in memory, and copy buffers out “oldest first.”
Buffer Headers
We’re back, once again, to linked lists and working data sets. So let’s take a look at a dump of the buffer header of a dirty buffer:
BH (11BFA4A4) file#: 3 rdba: 0x00c067cc (3/26572) class: 1 ba: 11B74000
set: 3 blksize: 8192 bsi: 0 set-flg: 0 pwbcnt: 0
dbwrid: 0 obj: 8966 objn: 8966 tsn: 2 afn: 3
hash: [217b55d0,10bf2a00] lru: [15be9774,11bf6748]
lru-flags: hot_buffer
obj-flags: object_ckpt_list
ckptq: [147eaec8,11beab1c] fileq: [147eaed0,11beab24] objq: [1e5ae154,147ed7b0]
st: XCURRENT md: NULL tch: 9
flags: buffer_dirty gotten_in_current_mode block_written_once
redo_since_read
LRBA: [0x294.539f.0] HSCN: [0x0.4864bf4] HSUB: [57]
I discussed the cache buffers lru chain(s) and the cache buffers chains (represented here by the pairs of pointers labeled hash: and lru: on the fourth line of the dump) in Chapter 5. In this chapter we will be looking at the checkpoint queue (ckptq:), file queue (fileq:), and object queue (objq:), of which the checkpoint queue is most significant and the one I will address first.
In this case you can see that flags: shows the buffer is dirty, and it’s on the checkpoint queue and (necessarily) a file queue. Interestingly, obj-flags: is set to object_ckpt_list, which may simply be a shorthand description for being on both the object and checkpoint queues but (for reasons I will mention later) may be giving us a clue that there is yet another set of concealed queues we should know about, a set where each queue links together all the dirty blocks for a given object.
Checkpoint Queues
Let’s just focus on the checkpoint queue first. Each working data set has two checkpoint queues associated with it, which you can infer from the latches exposed in x$kcbwds:
SQL> desc x$kcbwds
Name Null? Type
----------------------------- -------- --------
…
CKPT_LATCH RAW(4)
CKPT_LATCH1 RAW(4)
SET_LATCH RAW(4)
NXT_REPL RAW(4)
PRV_REPL RAW(4)
…
Although these latches are highly visible, appearing in v$latch with the name checkpoint queue latch and matching the addr columns of v$latch_children, it’s not possible to see the end points of the two queues in the structure because there are no nxt_ckpt, prv_ckpt columns to match the nxt_repl, prv_repl columns. When I ran a quick test to generate some dirty blocks and dump all the buffer headers, it was fairly easy to run some PL/SQL to read the trace file and rebuild the linked lists: there were two of them with roughly the same number of buffers per chain and their end-point addresses were fairly close to some of the other pointers listed in x$kcbwds. (A similar analysis of the fileq: pointers showed that there was one file queue for each data file—again with values similar to the other pointers listed in x$kcbwds.)
When a session first makes a buffer dirty, it will get one of the checkpoint queue latch latches (irritatingly the word “latch” really does appear in the latch name) for the working data set that the buffer belongs to and link the buffer to the “recent” end of that checkpoint queue, at the same time setting the LRBA: (low redo block address of the associated redo record in the form log file seq# . log file block#); this means that the buffers are actually linked in order of redo block address—which means they can’t go onto the checkpoint queue if they’re subject to private redo that hasn’t yet been flushed to the log buffer. The latch get is generally in immediate mode (there’s no point in using willing-to-wait mode initially because there are two latches, and one of them is likely to be free) and the buffer is linked while the session holds the latch. My guess is that the session uses a randomizing mechanism to decide which latch to pick first—possibly based on the block address—and then uses a willing-to-wait get on the second latch if both latches fail to succumb to an immediate get.
![]() Note In the redo block address (RBA), the reference to file number is the constantly increasing
Note In the redo block address (RBA), the reference to file number is the constantly increasing seq# from v$log_history, not the group# from v$log, which simply numbers the active redo log files in the instance. This means the RBA is constantly increasing and is a reasonable choice as a sequencing mechanism.
Although this linking process takes place only when the buffer first becomes dirty, there is a special case to consider due to block cloning. When you update a table through a tablescan (and perhaps on other occasions), your session will clone the current block to create a new current copy (statistic switch current to new buffer; see Chapter 5). This means the buffer that is linked into the checkpoint queue is no longer the latest version of the block, so it has to be detached and the new buffer has to be attached instead. The new buffer doesn’t go to the end of the queue, of course, because it has to go to the same place as the previous copy so that the buffers stay in the right order. The session knows where to find that copy because the header of the buffer it has just cloned was pointing to the two buffers on either side of the target that has to be relinked (see Figure 6-5). In this more complex case the session gets the necessary latch in willing-to-wait mode.
![]() Note The
Note The LRBA: on the header won’t change as a clone buffer is exchanged onto the checkpoint queue, but the HSCN: (high SCN) together with the HSUB: (high Sub-SCN, a fine-tuning value introduced in 9i for log buffer parallelism) will be adjusted to the current SCN. For reasons we shall see soon, it’s important that dbwr can tell when the most recent change was made to the buffer. (Oracle also makes use of this value during in-memory recovery of a block, as it tells the code that’s scanning through the redo logs where to stop.)
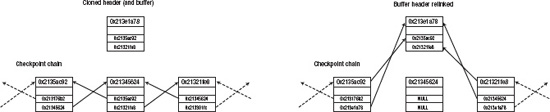
Figure 6-5. Exchanging a cloned buffer (header) in the checkpoint queue
The whole link/unlink mechanism has to be protected by latches because there could be multiple sessions doing the same thing at the same time—but there’s one very special process that’s attaching the checkpoint queues at the same time as the user sessions, and that’s dbwr. Every 3 seconds dbwr wakes up, does any work it’s supposed to, and then sets an alarm for itself before going to sleep again for the next 3 seconds.
Incremental Checkpointing
When dbwr wakes up, it gets each checkpoint queue latch latch in turn (using a willing-to-wait get) to see if there are any buffers in the queue, and then it walks the LRBA: queue from the low end collecting buffers and copying them to disk and detaching them from the checkpoint queue (marking the buffer as clean and clearing the LRBA: at the same time) until it reaches a buffer that is more recent than the target that it was aiming for. Sometimes, of course, dbwr will wake up, check the aged end of each checkpoint queue, find that there are no buffers to be copied, and go straight back to sleep.
The concept of “more recent” is very variable—there are five different parameters to think about as we move through different versions of Oracle, and some of those parameters changed their meaning across versions: fast_start_mttr_target, fast_start_io_target, log_checkpoint_timeout, log_checkpoint_interval, and _target_rba_max_lag_percentage. Then, on top of all these parameters is the self-tuning mechanism that came in with 10g. All these options translate to the same simple intent, though: every time dbwr wakes up it works out a target redo byte address and copies out any buffer with an LRBA: lower than that target. The log_checkpoint_interval is probably the simplest example to understand. It specifies a number of log file blocks, and dbwr simply subtracts that number from the redo block address that lgwr last wrote to (allowing for crossing file boundaries), and then copies out buffers with a lower LRBA: than the result. The other parameters simply use different algorithms to derive their targets.
![]() Note You can appreciate why each working data set has two checkpoint queues when you understand the work done by dbwr. While dbwr is walking along one queue, all the sessions that want to put buffers onto a queue are likely to end up using the other queue thanks to their strategy of using immediate gets on the latches compared with the willing-to-wait gets used by dbwr. (There is a latch named
Note You can appreciate why each working data set has two checkpoint queues when you understand the work done by dbwr. While dbwr is walking along one queue, all the sessions that want to put buffers onto a queue are likely to end up using the other queue thanks to their strategy of using immediate gets on the latches compared with the willing-to-wait gets used by dbwr. (There is a latch named active checkpoint queue latch—might we guess that dbwr updates a public variable to show which queue it is walking so that foreground sessions don’t even try to attach new buffers to it unnecessarily?) Even when dbwr is walking a specific queue, there will be some occasions when a session will have to exchange a buffer on that queue, so dbwr has to keep getting and dropping the checkpoint queue latch latch as it walks the queue.
Inevitably there’s more to copying out data buffers than this. The mechanism I’ve been describing so far is known as incremental checkpointing, and it’s just one of several mechanisms that involve the word “checkpoint.” It is, however, probably the most important because it gives us a guarantee that the data files are a reasonably accurate, fairly recent snapshot of the current state of our data. Moreover, it puts an upper bound on the amount of work that is needed if the instance crashes and we have to use the information in the redo logs to bring the database forward to the moment the crash occurred.
In fact, because of the way that the incremental checkpoint is constantly targeting the LRBA: and moving that target forward as time passes, we know that we can eventually throw away (or rather, overwrite) older online redo logs. Once we’ve got a database running at a steady state, the combination of a fixed number of online redo log files with the data files gives us a guaranteed perfect copy of our data even if the instance itself crashes. Getting the number and sizes of online redo logs right can take a little trial and error, but since you can’t really make your log files too large, it’s only difficult if you’re under pressure to minimize your use of disk space.
If lgwr manages to fill all the available online redo logs too quickly, then it won’t be able to overwrite the first one, which means it won’t be able to write any redo changes to disk, which means your database can’t change—which tends to mean the database stops. Typically this means your redo log files are too small, or you don’t have enough of them to deal with peak levels of processing; sometimes it means you have a coding problem that is generating huge volumes of redundant redo; occasionally it means you need a faster device for your redo logs.
So what else is there to worry about? Two key points: first, I’ve pointed out that lgwr always writes out the changes made to a data block before dbwr writes the data block; second, there are other occasions when dbwr is required to write data blocks before they reach the aged end of the checkpoint queue, and one of those occasions is critical to performance (and a common point of confusion).