
A SQLJ program contains Java/JDBC code, SQLJ declaration statements, and SQLJ executable statements, as illustrated by Figure 11.1.
This chapter covers SQLJ declarations, SQLJ executable statements, interoperability between SQLJ and JDBC, and, finally, Expressions in SQLJ.
This category contains import statements, connection contexts declaration, execution contexts declarations, and iterators declarations.
import java.sql.SQLException; import sqlj.runtime.ref.DefaultContext; import oracle.sqlj.runtime.*; ...
A connection context is not tied to a schema but is associated with a well-scoped set of tables, views, and stored procedures that have the same names and data types—called exemplar schema—and that are validated duringtranslation time. Using the same connection context with the occurences of the “exemplar schema” through different databases (e.g., development databases versus deployment databases) preserves the validity of the translation-time checking. It is up to the developer to maintain a valid connection context versus exemplar schema association.
The sqlj.runtime.ConnectionContext interface specifies the following public methods:
getConnection():Returns the underlying JDBC connection object associated with this context instance.getExecutionContext():Returns the default execution context used by this connection context (execution context will be covered later).close(boolean closeConnection):Releases the connection context and all associated resources, including the underlying JDBC connection, unless the Boolean constantKEEP_CONNECTIONis furnished in parameter and the connection is left open (default isCLOSE_CONNECTION; in this case, the JDBC connection is closed).
A SQLJ application can create a new connection context class by just declaring it as follows (the translator takes care of implementing the class):
#sql context <Context Name> [<implements_clause>] [<with_clause>];
Here is an example of a context declaration and the implementation class generated by the translator under the covers (the implementation class is transparent to the SQLJ developer):
#sql context myConCxt;
// and here is the generated class
class myConCxt implements sqlj.runtime.ConnectionContext
extends ...
{
public myConCxt(String url, Properties info, boolean autocommit)
throws SQLException {...}
public myConCxt(String url, boolean autocommit)
throws SQLException {...}
public myConCxt(String url, String user, String password,
boolean autocommit) throws SQLException {...}
public myConCxt(Connection conn) throws SQLException {...}
public myConCxt(ConnectionContext other) throws SQLException {...}
public static myConCxt getDefaultContext() {...}
public static void setDefaultContext(myConCxt ctx) {...}
}Here is how the application creates instances of the previously declared context:
myConCtx Ctx1 = new myConCtx
(Oracle.getConnection(myClass.class, "connect.properties"));
myConCtx Ctx2 = new myConCtx
("jdbc:oracle:thin:@localhost:1521/service", "foo","bar",
false);The SQLJ runtime furnishes a special sqlj.runtime.ref.DefaultContext class that applications can use just to create instances of default connection context as follows:
DefaultContext defConCtx = new DefaultContext
("jdbc:oracle:thin:@localhost:1521/service", "scott",
"tiger", false);The Oracle SQLJ runtime furnishes the oracle.sqlj.runtime.Oracle class to simplify DefaultContext class management, as follows:
Upon the invocation of the
Oracle.connect()method, a default connection context is initialized (if not already) along with an underlying JDBC connection (setting auto-commit tofalse); it takes the following signatures:Oracle.connect(myClass.class, "connect.properties"); Oracle.connect(getClass, "connect.properties"); Oracle.connect("URL"); Oracle.connect("jdbc:oracle:thin@host:port:sid", "user", "passwd"); Oracle.connect("URL", flag); // auto-commit true|falseThe
Oracle.getConnection()creates and returns an instance ofDefaultContextobject (auto-commitis set tofalse, by default).The
Oracle.close()closes only the default connection context.
SQLJ allows managing connections at the statement level. In order to issue executable statements against the database, a connection context is required; however:
When not specified, all executable statements will use the default connection context.
#sql { SQL operation }; // a short form for the // following #sql [DefaultContext.getDefaultContext()] { SQL operation };Alternatively, an executable statement can explicitly specify the connection context, as follows:
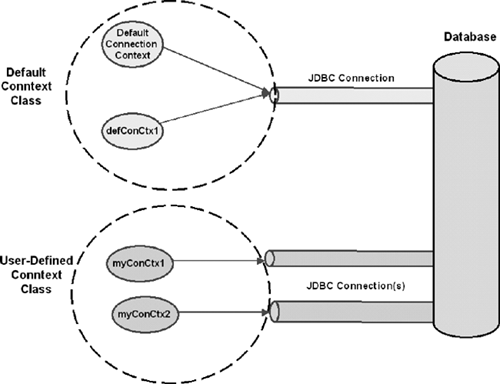
#sql [conctx] {SQL Operation};As Figure 11.2 illustrates, each instance of a connection context class is tied to a JDBC connection; however:
Different instances of a connection context class (
DefaultContextclass or user-defined context class) may share the same JDBC connection, as follows:myCtx myConCtx1 = new myCtx(DefaultContext.getDefaultContext().getConnection( )); myCtx myConCtx2 = new myCtx(DefaultContext.getDefaultContext().getConnection( ));Different instances of a connection context class (
DefaultContector user-defined context) may use different JDBC connections, as follows:DefaultContext defConCtx1 = Oracle.getConnection ("jdbc:oracle:thin:@localhost1:1521/service1", "scott", "tiger"); DefaultContext defConCtx2 = Oracle.getConnection ("jdbc:oracle:thin:@localhost1:1521/myservice2", "foo", "bar");
The default connection context can be overridden using the sqlj.runtime.ref.DefaultContext.setDefaultContext method to set a different connection context as the default:
DefaultContext.setDefaultContext(defConCtx1);
// The following execution statememts will use myCtx1
#sql { SQL operation };
...
DefaultContext.setDefaultContext(defConCtx2);
// The following execution statements will use myCtx2
#sql { SQL operation };
#sql { SQL operation };
...
// Save the current default context
DefaultContext savedCtx = DefaultContext.getDefaultContext();
// Assign new context as default
DefaultContext.setDefaultContext( new DefaultContext(
("jdbc:oracle:thin:@localhost:1521/service", "scott",
"tiger", false)
));
// use the newly assigned default context
#sql {SQL peration};You may use your own custom connection context interface instead of the standard ConnectionContext interface using the IMPLEMENTS clause during the declaration step:
#sql public context myInterfCtx implements myCtxInterface;
where myCtxInterface contains your interface definition, which may be a more restrictive version (i.e., hide some functions) of ConnectionContext, and then instantiate it as follows:
myInterfCtx myConCtx1 =
new myInterfCtx(("jdbc:oracle:thin:@localhost:1521/
myservice", <user>, <pass>, <autocommit>);DataSource is the standard/recommended mechanism for establishing a JDBC connection. Similarly, SQLJ supports the datasource mechanism in two ways: associate a connection context with a JDBC datasource, and use SQLJ-specific datasources.
Associating a SQLJ connection context with a JDBC datasource in the connection context declaration. Additional constructors are generated within the connection context class when it is declared with a
dataSourceproperty; consequently, theDriverManager-based constructors are not generated. The SQLJ runtime looks up the datasource object in JNDI contexts; you need anInitialContextprovider. Also, thejavax.sql.*andjavax.naming.*packages must be available in your environment (CLASSPATH).The following declaration associates a context with a data-source and generates additional constructors (listed as bullet items) in the generated class (i.e.,
DSCtx):#sql context DSCtx with (dataSource="jdbc/myDSource");
DSCtx():Looks up the datasource forjdbc/myDSource, and then calls thegetConnection()method on the datasource to obtain a connection.DSCtx(String user, String password):Looks up the datasource forjdbc/myDSource,and then calls thegetConnection(user,password)method on the datasource to obtain a connection.DSCtx(ConnectionContext ctx):Delegates toctxto obtain a connection.When the default SQLJ context is not set, the SQLJ runtime will use the default data source—bound to the
jdbc/defaultDataSource—to establish the connection.
Listing 11.1, is based on the JDBC JNDI example
DataSrceJNDI.javain Chapter 7; you need to install the file system–based JNDI as explained in Chapter 7 (your CLASSPATH must containfscontest.jarandproviderutil.jar). The file system–based JNDI machinery does not do justice to SQLJ simplicity; the code would be much simpler in a middle-tier environment, where containers have their own namespace and initial context provider; see #2, which follows.Example 11.1. myDataSource.sqlj
import java.sql.*; import javax.sql.*; import oracle.jdbc.*; import oracle.jdbc.pool.OracleDataSource; import javax.naming.*; import javax.naming.spi.*; import java.util.*; import java.io.*; import sqlj.runtime.*; import sqlj.runtime.ref.DefaultContext; import oracle.sqlj.runtime.*; public class myDataSource { public static void main(String[] args) throws java.sql.SQLException, NamingException, java.io.IOException { try { // Initialize the Context Context ctx = null; Hashtable env = new Hashtable (5); env.put (Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.fscontext.RefFSContextFactory"); env.put (Context.PROVIDER_URL, "file:" + args[0]); ctx = new InitialContext(env); // Create a JDBC OracleDataSource instance explicitly OracleDataSource ods = new OracleDataSource(); // Get URL from datasource.properties InputStream is = null; is = ClassLoader.getSystemResourceAsStream("datasource.properties"); Properties p = new Properties(); p.load(is); is.close(); String url = p.getProperty("url"); String user = p.getProperty("user"); String passw = p.getProperty("passw"); System.out.println ("Config file: url = " + url + " User = " + user + " Password = " + passw); ods.setURL(url); ods.setUser(user); ods.setPassword(passw); // Bind the SQLJ default data source to the JNDI name // jdbc/defaultDataSource System.out.println ("Binding the logical name: jdbc/ defaultDataSource"); ctx.bind ("jdbc/defaultDataSource", ods); // The SQLJ runtime will use the default JDBC connection // to connect Connection conn = ods.getConnection(); DefaultContext.setDefaultContext(new DefaultContext(conn)); int i; #sql { select empno into :i from emp where ename = 'SCOTT' }; System.out.println("SCOTT's emp# is : "+i); ods.close(); Oracle.close(); } catch (NamingException ne) { ne.printStackTrace(); } } } $ sqlj myDataSource.sqlj $ java -Doracle.net.tns_admin=$TNS_ADMIN myDataSource ~/jndi Config file: url = jdbc:oracle:thin:@inst1 User = scott Password = tiger Binding the logical name: jdbc/defaultDataSource SCOTT's emp# is : 7788 $SQLJ-specific datasources extend a JDBC datasource and return SQLJ connection context instances. The Oracle SQLJ supports SQLJ-specific datasources in the
runtime12eelibrary for use with middle-tier containers (these are not available withruntime12.jar).SQLJ datasources are based on the corresponding JDBC data-source interface or class. With Oracle JDBC 10g drivers, use the
OracleSqljDataSourceandOracleSqljConnectionPool-DataSourceclasses available inoracle.sqlj.runtimeandoracle.sqlj.runtime.clientpackages.The
oracle.sqlj.runtimepackage includes theOracleSqljDataSource class, which extendsoracle.jdbc.pool.OracleDataSourceand implementsConnectionContextFactory.The
oracle.sqlj.runtime.clientpackage includes theOracleSqljXADataSource class,which extendsoracle.jdbc.xa.client.OracleXADataSourceand implementsConnectionContextFactory.
The sqlj.runtime.ConnectionContextFactory interface acts as a base interface for SQLJ datasource and specifies getDefaultContext() and getContext() methods:
getDefaultContext() returns a sqlj.runtime.ref.DefaultContext instance for the SQLJ default context (with signatures that enable you to specify auto-commit setting, user, and password for the underlying JDBC connection):
DefaultContext getDefaultContext()DefaultContext getDefaultContext(boolean autoCommit)DefaultContext getDefaultContext(String user, String password)DefaultContext getDefaultContext(String user, String password, boolean autoCommit)
getContext() returns a sqlj.runtime.ConnectionContext instance of the user-declared connection context class (with signatures that enable you to specify auto-commit setting, user, and password for the underlying JDBC connection):
When a parameter is not specified, it is obtained from the underlying datasource that generates the connection (Note: auto-commit defaults to false when not set to true for the underlying datasource).
The oracle.sqlj.runtime.client package contains the OracleSqljXADataSource class.
Here is a code fragment using SQLJ datasources:
//Initialize the data source
SqljXADataSource sqljDS = new OracleSqljXADataSource();
sqljDS.setUser("scott");
sqljDS.setPassword("tiger");
sqljDS.setServerName("myserver");
sqljDS.setDatabaseName("ORCL");
sqljDS.setDataSourceName("jdbc/OracleSqljXADS");
//Bind the data source to JNDI
Context ctx = new InitialContext();
ctx.bind("jdbc/OracleSqljXADS");
int i;
#sql [ctx] { select empno into :i from emp where ename =
'SCOTT' };
System.out.println("SCOTT's emp# is : "+i);For Oracle SQLJ code, statement caching of the underlying connection is enabled through methods on the connection context interface and classes.
The following static methods in the sqlj.runtime.ref.DefaultCon-text class and user-defined context classes set the default statement cache size for all connection contexts classes and their instances:
setDefaultStmtCacheSize(int)int getDefaultStmtCacheSize()
The following instance methods in the sqlj.runtime.ref.DefaultContext class and user-defined context classes set the cache size for the current connection context instance; this setting overrides the default setting.
setStmtCacheSize(int)int getStmtCacheSize()
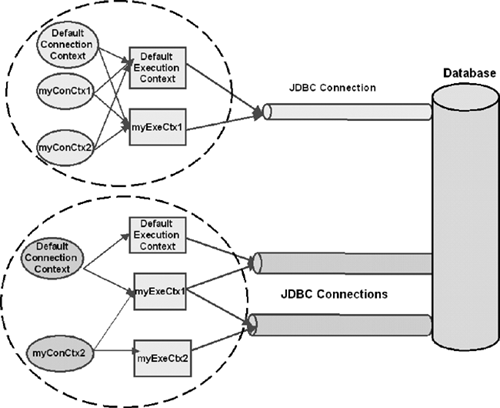
Similar to connection context, an instance of the execution context class (i.e., sqlj.runtime.ExecutionContext) must be associated with each executable SQLJ statement, either implictly (using the default execution context instance associated with every connection context) or explictly. The applications create new instances by invoking the constructor of the class (i.e., new ExecutionContext()).
The association of an execution context with an executable statement is specified in the following ways:
#sql [<execution context>] {<SQLJ clause>}#sql [<connection context>, <execution context>] {<SQLJ clause>}
The following code fragment creates a new execution context and assigns it to the SQLJ statement:
Example
=======
import sqlj.runtime.ExecutionContext;
...
ExecutionContext ec = new ExecutionContext();
#sql [ec] { SQLJ clause};The execution context associated with a context can be retrieved using the getExecutionContext() method of the ConnectionContext interface. Consequently, you can retrieve the static default execution context of each connection context class using the DefaultContext.getDefaultContext.getExecutionContext() method:
Example #1
==========
import sqlj.runtime.ExecutionContext;
...
exCtx =
DefaultContext.getDefaultContext().getExecutionContext();
#sql [exCtx] { SQLJ clause};
Example #2
==========
#sql static context Contx;
...
Contx myCtx = new
Contx(DefaultContext.getDefaultContext().getConnection());
#sql [ myctx.getDefaultContext(),
myctx.getExecutionContext() ] {SQLJ clause};
...
#sql [ myctx.getExecutionContext()] { SQLJ Clause};As Figure 11.3 illustrates, each instance of execution context class must be assigned a connection context; if not explicitly done, it is attached to the default context.
Describing the status and result of the most recent SQL operations:
SQLWarning getWarnings(): Returns ajava.sql.SQLWarningUse
getWarnings()of the execution context to get the first warning, thengetNextWarning()method of eachSQLWarningobject to get the next warning.Example #1 SQLException sqle = contxt.getExecutionContext().getWarnings(); Example #2 SQLWarning sqlwarn = iter1.getWarnings(); while (true) { if (sqlwarn == null) { System.out.println ("No more Warning"); break; } else { System.out.println ("Warning: " + sqlwarn.getMessage()); } sqlwarn = sqlwarn.getNextWarning(); }int getUpdateCount(): Returns the number of rows updated by the last SQL operation that used this execution context instance.Example System.out.println("Update cnt: " + conCtx.getExecutionContext().getUpdateCount());Managing the semantic of subsequent SQL operations:
int getMaxFieldSize(): Returns the maximum amount of data (in bytes) that would be returned from a subsequent SQL operation forBINARY, VARBINARY, LONGVARBINARY, CHAR, VARCHAR, or LONGVARCHARcolumns (default value is 0, i.e., no limit).
Example:
System.out.println ("MaxFieldSize: " +
conCtx.getExecutionContext().getMaxFieldSize());setMaxFieldSize(int): sets the maximum field-size.
int getMaxRows(): Returns the maximum number of rows that can be contained in SQLJ iterators or JDBC result sets created using this execution context instance (default is 0, i.e., no limit).
setMaxRows(int): Sets the maximum rows.
int getQueryTimeout(): Returns the timeout interval, in seconds, for any SQL operation that uses this execution context instance. A SQL exception is thrown if a SQL operation exceeds this limit (default is 0, i.e., no timeout limit).
setQueryTimeout(int): Sets the query timeout limit.
int getFetchSize(): Retrieves the current fetch size (previously set using setFetchSize()), for iterator objects generated from this ExecutionContext object.
setFetchSize(int): Sets the number of rows that should be fetched when more rows are needed from iterators.
int getFetchDirection(): Retrieves the default fetch direction for scrollable iterator objects that are generated from this ExecutionContext object (default is sqlj.runtime.ResultSetIterator.FETCH_FORWARD).
setFetchDirection(int): Sets the direction in which rows of scrollable iterator objects are processed (default is sqlj.runtime.ResultSetIterator.FETCH_FORWARD).
Notes:
getNextResultSet(int): is not implemented in Oracle SQLJ.
ResultSets in Oracle SQLJ are always bound as explicit arguments.
Terminating the SQL operations currently executing:
cancel(): To be used in a multithreading environment, from one thread to cancel a SQL operation currently executing in another thread.Enabling/disabling update batching:
int[] executeBatch(): Executes the pending statement batch and returns an array ofintupdate counts.int getBatchLimit(): Returns the current batch limit (defaultUNLIMITED_BATCH). If set, then a pending batch is implicitly executed once it contains that number of statements.int[] getBatchUpdateCounts(): Returns an array ofintupdate counts for the last batch executed.boolean isBatching(): Returns a Boolean value indicating whether update batching is enabled. ThegetUpdateCount()method indicates whether a batch has been newly created, added to, or executed.setBatching(boolean): Boolean value to enable update batching (disabled by default).setBatchLimit(int): Takes a positive, nonzerointvalue as input to set the current batch limit. Special values areUNLIMITED_BATCHandAUTO_BATCH(lets the SQLJ runtime dynamically determine a batch limit).Example:
sqlj.runtime.ExecutionContext exectx = sqlj.runtime.ref.DefaultContext.getDefaultContext().get ExecutionContext(); exectx.setBatching(true); exectx.setBatchLimit(6);
Managing JDBC 3.0 savepoint operations (i.e., set a savepoint, roll back to a savepoint, and release a savepoint):
Object oracleSetSavepoint(ConnectionContextImpl, String): Registers a savepoint and returns it as anObjectinstance. It takes an instance of thesqlj.runtime.ref.ConnectionContextImplclass and a string that specifies the savepoint name. The Oracle SQLJ save-point is an instance of theoracle.jdbc.OracleSavepointclass, which extends thejava.sql.Savepointinterface. Also, the OracleObjectdoes not require JDK 1.4, unlike the standardjava.sql.Savepointinterface.void oracleRollbackToSavepoint (ConnectionContextImpl, Object): Rolls back changes to the specified savepoint. It takes the connection context as an instance ofConnectionContextImpland the savepoint as anObjectinstance.void oracleReleaseSavepoint(ConnectionContextImpl, Object):Releases the specified savepoint.Closing the execution context:
close(): To be used if (1) Oracle-specific code generation, and (2) using explicitly createdExecutionContext,and (3) not using an explicit execution context withCOMMIT/ROLLBACK, and (4) not callingexecuteBatch()on theExecutionContextinstance.Execution Context eCtx = new ExecutionContext(); ... try { ... #sql [eCtx] { SQL operation }; ... } finally { eCtx.close(); }
Multithreading in SQLJ depends on the multithreading support in the underlying JDBC driver. In Oracle JDBC, methods are synchronized on the connection (i.e., the driver sends a command to the server on behalf of a thread and then waits for its completion before the connection/socket can be used by another thread. Simultaneous multithreading is possible when threads are not sharing the same connection—in other words, it is not recommended!
Iterators are similar to JDBC result sets in that these are used for retrieving multiple rows upon a query execution; for queries that return a single row, use the SELECT clause (see executable statements below). However, unlike result sets, iterators can be weakly typed (i.e., instances of sqlj.runt-ime.ResultSetIterator or sqlj.runtime.ScrollableResultSetIterator classes furnished by the runtime) or strongly typed (i.e., instances of user-declared classes).
Weakly typed iterators are interoperable/compatible with JDBC result sets (hence, familiar to JDBC aficionados); however, they do not benefit from the SQLJ semantics and type checking (see strongly typed iterators next).
ResultSet Iterators are instances of the sqlj.runtime.ResultSetIterator class, which implements the ResultSetIterator interface; this interface specifies the following methods:
close():Closes the iterator.ResultSet getResultSet():Extracts the underlying JDBC result set from the iterator.boolean isClosed():Determines if the iterator has been closed.boolean next():Moves to the next row of the iterator; it returnstrueif there remains a valid next row.boolean endFetch():Returns true if the last fetch failed, false otherwise.int getFetchSize():Retrieves the current fetch size for this iterator object.setFetchSize(int rows):Sets the default fetch size (in parameter) for result sets generated from this iterator object.
ResultSet iterators are mainly used in Oracle SQLJ as host expressions, cursors in FETCH statements, and for accessing the JDBC ResultSet, as follows:
sqlj.runtime.ResultSetIterator RSetIter;
ResultSet JdbcRs;
#sql RSetIter = { SELECT ename FROM emp };
JdbcRs = RSetIter.getResultSet();
while (JdbcRs.next()) {
System.out.println("ename: " + JdbcRs.getString(1));
}
RSetIter.close();Scrollable iterators are another flavor of weakly typed iterators.
Like many things in SQLJ, strongly typed iterators enforce semantics checking of the queries; however, the minor downside is that these are not interoperable with JDBC. In order to define a strongly typed iterator, you must declare: its class, the names of the columns, and/or the Java types of the columns. Declaring both the name and the Java type of each column defines a “named iterator,” while declaring just the column types defines a “positional iterator.”
Named iterators are instances of user-declared classes; the SQLJ translator generates the corresponding classes implementing the ResultSetIterator and sqlj.runtime.NamedIterator interfaces. The beauty of named iterators, in contrast to JDBC getxxx()/getXXX(), reside, in the fact that the column names serve as getters or accessors for the retrieval of the value in the columns; in addition, the order of appearance of the column names in the SELECT statement and the iterator declaration does not matter.
The following code fragments illustrate named iterator declaration and usage:
//Fragment #1
#sql iterator namedIter1 (int empno, String ename, Double
sal, float comm);
namedIter1 nIter1
#sql nIter1 = { SELECT ename, empno, sal, comm FROM
employees};
...
while (nIter1.next()) {
...
}
nIter1.close();
//Fragment #2
#sql iterator namedIter2 (int empno, String ename);
#sql context Context;
namedIter2 nIter2;
Context ctx;
...
#sql [ctx] nIter2 = { select ename, empno from employees } ;
while (nIter2.next()) {
...
};
nIter1.close();Positional iterators are instances of user-declared classes; at translation time, the SQLJ translator generates classes that implement the ResultSetIterator and sqlj.runtime.PositionedIterator interfaces. With positional iterators, the column names are not specified, only the types are. The data is retrieved using FETCH INTO, in the same order as the columns appear in the SELECT statement; however, the data types of the table columns must match the types of the iterator columns.
The PositionedIterator interface specifies the endFetch() method for determining if the last row has been reached.
The following code fragments define positional iterators:
// Fragment#3
#sql iterator posIter2 (int, String);
#sql context Context;
posIter2 pIter2;
Context ctx;
String ename;
int empno;
#sql [ctx] pIter2 = { select ename, empno from emp where empno = 7788}
;
while (true) {
#sql [ctx] FETCH :pIter2 INTO :ename, :empno};
if (pIter2.endFetch()) break;
System.out.println("ename = " + ename + ", emp# = " + empno);
}
pIter2.close();
//Fragment #4
#sql iterator posIter1 (int, String, Double, float);
posIter1 pIter1
#sql pIter1 = { SELECT ename, empno, sal, comm FROM employees};
...
while (pIter1.next()) {
// retrieve and process the row
};
pIter1.close();
//Fragment #5
#sql iterator posIter2 (int, String);
#sql context Context;
posIter2 pIter2;
Context ctx;
...
#sql [ctx] pIter2 = { select ename, empno from employees } ;
while (pIter2.next()) {
// retrieve and process the row
};
pIter1.close();The ISO SQLJ supports the scrollable iterators that are similar/compatible with JDBC Scrollable ResultSet. The sqlj.runtime.Scrollable furnishes the following features:
Hints about the fetch direction to scrollable iterators:
setFetchDirection(int): The direction in which rows are processed; takes one of the followingsqlj.runtime.ResultSetIteratorconstants:FETCH_FORWARD, FETCH_REVERSE, orFETCH_UNKNOWN (default is FETCH_FORWARD)int getFetchDirection(): Retrieves the current fetch direction.
Methods that provide information about the position of the iterator in the underlying result set:
boolean isBeforeFirst():Trueif the iterator is before the first row in the result set.if (sri.isBeforeFirst())System.out.println("Is before first.");boolean isFirst():Trueif the iterator is on the first row of the result set.if (sri.isFirst()) System.out.print(”Is first.”);boolean isLast():Trueif the iterator is on the last row of the result set.if (sri.isBeforeFirst())System.out.println("Is before first.");boolean isAfterLast():Trueif the iterator is after the last row in the result set.if (sri.isAfterLast()) System.out.println("Is after last.");
The IMPLEMENTS SCROLLABLE clause is required for declaring scrollable iterators (i.e., implements sqlj.runtime.Scrollable):
public interface ScrollableResultSetIterator
extends ResultSetIterator
implements Scrollable
{...}Instances of sqlj.runtime.ScrollableResultSetIterator class, which extends ResultSetIterator and Scrollable interfaces, can be used with FETCH CURRENT syntax to process result set iterators with SQLJ.
#sql { FETCH CURRENT FROM :sri INTO :i, :name };The scrollable named iterators use the following navigation methods in the Scrollable interface: next(), previous(), first(), last(), absolute(), relative(), beforeFirst(), and afterLast().
Example:
#sql public static iterator ScrollNamIter
implements sqlj.runtime.Scrollable
(int empno, String ename);
ScrollNamIter sni;
#sql sni = { select empno, ename from emp };
int no;
String name;
//
#sql { FETCH :sni INTO :no, :name };
//
#sql { FETCH NEXT FROM :sni INTO :no, :name };
//
#sql { FETCH PRIOR FROM :sni INTO :no, :name };
//
#sql { FETCH FIRST FROM :sni INTO :no, :name };
//
#sql { FETCH LAST FROM :sni INTO :no, :name };
//
#sql { FETCH ABSOLUTE :(6) FROM :sni INTO :no, :name };
//
#sql { FETCH RELATIVE :(-3) FROM :sni INTO :no, :name };
//
#sql { FETCH CURRENT FROM :sni INTO :no, :name };
Oracle.close();The following code fragment is similar to the previous one and illustrates the use of navigation methods with scrollable positional iterator:
#sql public static iterator ScrollPosIter
implements sqlj.runtime.Scrollable
(int, String);
ScrollPosIter spi;
#sql spi = { select empno, ename from emp };
int no;
String name;
#sql { FETCH :spi INTO :no, :name };
#sql { FETCH NEXT FROM :spi INTO :no, :name };
#sql { FETCH PRIOR FROM :spi INTO :no, :name };
#sql { FETCH FIRST FROM :spi INTO :no, :name };
#sql { FETCH LAST FROM :spi INTO :no, :name };
#sql { FETCH ABSOLUTE :(6) FROM :spi INTO :no, :name };
#sql { FETCH RELATIVE :(-3) FROM :spi INTO :no, :name };
#sql { FETCH CURRENT FROM :spi INTO :no, :name };
Oracle.close();Sometimes you may want to add new functionality relative to processing query results. SQLJ lets you extend the base iterator classes, as follows:
Declare your iterator class:
#sql public static iterator <baseClassIter> (...);
Extend the base class with new methods, as follows; notice that you must furnish a public constructor that takes an instance of
sqlj.runtime.RTResultSetas input:/* * This is a skeleton of Iterator SubClassing */ import java.sql.SQLException; import sqlj.runtime.profile.RTResultSet; import oracle.sqlj.runtime.Oracle; public class mySubClassIter { // Declare the base iterator class #sql public static iterator baseClassIter(...); // Declare a subclass Iterator class, which // extends the base Iterator class public static class subClassIter extends baseClassIter { /* * Provide a sqlj.runtime.RTResultSet for the constructor */ public subClassIter(RTResultSet rtrset) throws SQLException { super(rtrset); } /* ** Add your custom (public and private) methods here */ public String method2() throws SQLException { ... while (super.next()) ... super.close(); } // Use the finalizer of the base class protected void finalize() throws Throwable { super.finalize(); } // Use the close method of the base class public void close() throws SQLException { super.close(); } } SubclassIterDemo() throws SQLException { Oracle.connect(getClass(), "connect.properties"); } void runit() throws SQLException { subClassIter subECtx; ... // Use it #sql subECtx = { SQLJ clause }; } }
Similar to JDBC Scrollable ResultSets covered in Chapter 8, iterators may also be sensitive or insensitive to changes in the underlying data. Sensitivity is specified using the WITH clause during the iterator declaration, as follows:
#sql public static iterator SensRSetIter implements
sqlj.runtime.Scrollable
with (sensitivity=SENSITIVE)
(String ename, int empno);When sensitivity is not specified, it defaults to INSENSITIVE in the Oracle SQLJ implementation. However, you can use the ISO SQLJ ASENSITIVE, instead of INSENSITIVE.
#sql iterator AsNIter1 with (sensitivity=ASENSITIVE) (int s); #sql iterator IsNIter2 with (sensitivity=INSENSITIVE) (String t); #sql iterator AsNIter3 with (sensitivity=sqlj.runtime.ResultSetIterator.ASENSITIVE) (int s); #sql iterator IsNIter4 with (sensitivity=sqlj.runtime.ResultSetIterator.INSENSITIVE) (String t);
We have seen the IMPLEMENTS SCROLLABLE clause in declaring scrollable iterators. The IMPLEMENTS clause can also be used during context and iterator declarations to implement user-defined interfaces and positioned update/delete iterators.
User-defined interfaces let you customize the generated classes from which instances of iterators are created. Assume you want to restrict access to sensitive columns of a named iterator, such as date of birth, salary, Social Security number, and so on. By default, a named iterator class generates a getter method for every column involved in the SELECT clause. In order to achieve your goal, you just create an interface, which defines getters only for columns you want to expose. The following interface will generate a CustNamedIter class with only ename and empno accessors:
interface CustNamedIterInterf extends NamedIterator
{
public String ename () throws SQLException;
public int empno () throws SQLException;
}
#sql iterator cni implements CustNamedIterInterf (String emame, int
empno, data dob);Similarly, you may want to restrict the columns returned by a positional iterator through a user-defined interface:
interface CustPosIterInterf extends PositionedIterator
{
public String getString () throws SQLException;
public int getInt () throws SQLException;
}
#sql iterator cpi implements CustPosIterInterf (String, int,
date);The following instruction declares a connection context class that implements an interface named MyConnCtxtIntfc:
#sql public context MyContext implements mypackage.MyConnCtxtIntfc;
The current row of a result set can be updated or deleted using a positioned update (i.e., UPDATE ... WHERE CURRENT OF ...) or a positioned delete (i.e., DELETE ... WHERE CURRENT OF ... ) statement that references the cursor name.
In Oracle Database 10g Release 2 (10.2), SQLJ supports positioned update and positioned delete operations; any type of iterator (a named, positional, or scrollable), which implements the sqlj.runtime.ForUpdate interface, can be used as a parameter to the WHERE CURRENT OF clause.
import sqlj.runtime.ForUpdate;
#sql iterator PUpdateIter implements ForUpdate
(int EMPNO, String ENAME);
PUpdateIter pit;
#sql { UPDATE emp WHERE CURRENT OF :pit SET SAL = SAL * 1.2 }
;
#sql { DELETE FROM emp WHERE CURRENT OF :c };However, the following restrictions apply on the iterators in question:
The query used to populate the iterator should not operate on multiple tables.
A PL/SQL procedure returning a
REF CURSORcannot be used with the iterator.The iterator cannot interoperate with a JDBC ResultSet; in other words, the iterator cannot be populated with data from a result set as follows:
#sql iter = {cast :rs}
#sql <modifiers< context context_classname with (var1=value1,..., varN=valueN);
Use the WITH clause to set values for fields in SQLJ-generated classes during connection context declaration that can be used later in host expressions.
#sql static context Ctx with (ENAME="SMITH");
#sql { SELECT sal INTO :sal FROM emp WHERE ename =
:(Ctx.ENAME) };Similarly, during iterator declaration, you can use the WITH clause to set values for the fields in the SQLJ-generated classes:
#sql static iterator Iter with (SAL=3402) (String ename, BigDecimal sal);
A predefined set of standard SQLJ constants can be defined in the WITH clause; however, the Oracle SQLJ implementation does not currently support all of these. Here is a description of supported versus unsupported constants.
The Oracle SQLJ supports the following standard constants in connection context declarations:
typeMap: AStringliteral defining the name of a type-map properties resourceThe Oracle SQLJ also supports the use of
typeMapin iterator declarations, as follows:#sql iterator MyIterator with (typeMap="MyTypeMap") (Person pers, Address addr);In Oracle-specific code, the iterator and connection context declarations must use the same type maps.
dataSource: AStringliteral defining the name under which a data-source is looked up in theInitialContext(covered previously)It also supports the following standard constants in iterator declarations:
sensitivity:SENSITIVE/ASENSITIVE/INSENSITIVE, to define the sensitivity of a scrollable iterator (covered previously)returnability:true/false, to define whether an iterator can be returned from a Java stored procedure or function
#sql iterator Iter2 with (returnability=false) (String s);
The Oracle SQLJ does not support the following standard constants in connection context declarations:
path: The name of a path (Stringliteral) to be prepended for resolving Java stored procedures and functionstransformGroup: The name of a SQL transformation group (Stringliteral) that can be applied to SQL typesNor does it support the following standard constants, involving cursor states, in iterator declarations:
holdability:Boolean, determines SQL cursor holdability; the cursor can then be continued in the next transaction of the same SQL session.updateColumns: A comma-delimited list (aStringliteral) of column names. Awithclause that specifiesupdateColumnsmust also have animplementsclause for thesqlj.runtime.ForUpdateinterface. The Oracle SQLJ implementation enforces this, even thoughupdateColumnsis currently unsupported. See the following syntax:#sql iterator iter1 implements sqlj.runtime.ForUpdate with (updateColumns="ename, empno") (int empno, String ename);
SQLJ executable statements are the most illustrative part of SQLJ simplicity (i.e., embedding SQL in Java). Executable statements must observe the following rules:
Contain an optional SQLJ space where connection and execution contexts are explicitly specified
Contain valid Java block statements wherever permitted
Embed a SQL operation enclosed in curly braces:
{...}; this is also called the SQL spaceBe terminated by a semicolon (;)
Executable statements can be grouped into two categories: Statement clauses and Assignment clauses.
The generic syntax of a statement clause is as follows:
#sql [optional SQLJ space] { Statement clause };Statement clauses comprise SELECT INTO clause, FETCH clause, COMMIT clause, ROLLBACK clause, SAVEPOINT clause, SET TRANSACTION clause, Procedure clause, SQL clause, and PL/SQL clause.
The SELECT clause includes valid query operations, which return exactly a single row into OUT Java host expressions (returning zero or several rows will throw an exception).
As you can see, the host expressions (covered in Chapter 12) are declared as :OUT parameters:
#sql { SELECT column_name1, column_name2
INTO :OUT host_exp1, :OUT host_exp2
FROM table WHERE condition };However, it is a general practice to omit the :OUT qualifier because this is implied (using IN, IN/OUT qualifier for a SELECT INTO will throw an exception).
#sql { SELECT column_name1, column_name2
INTO host_exp1, host_exp2
FROM table WHERE condition };Examples:
int no;
int pay;
#sql { SELECT empno, sal INTO :no, :pay
FROM emp WHERE ename = 'SMITH' } ;
int count;
#sql { SELECT COUNT(*) INTO :count FROM EMP };The FETCH clause designates the operations of fetching data from a positional iterator (iterators are covered later).
#sql positer = { SELECT empno, sal FROM EMP
WHERE ENAME = 'SMITH' OR EMPNO = 7788 ORDER
BY EMPNO
};
while (true) {
#sql { FETCH :positer INTO :empno, :sal };
if (positer.endFetch()) break;
System.out.println("empno = " + empno + ", sal = " + sal);
}
positer.close();The JDBC semantics for manual COMMIT/ROLLBACK (i.e., for DML when auto-commit is disabled) apply here.
#sql { COMMIT };
#sql { ROLLBACK};Note that COMMIT and ROLLBACK operations do not impact open result sets and iterators (unless the iterator sensitivity is set to SENSITIVE).
The SAVEPOINT clause designates the ISO SQLJ SAVEPOINT syntax and the Oracle SQLJ SAVEPOINT syntax.
The ISO SQLJ SAVEPOINT syntax takes string literals. As seen previously, execution context store savepoint and furnish methods, which parallel the following methods:
#sql { SAVEPOINT savepoint1 };
#sql { ROLLBACK TO savepoint1 };
#sql { RELEASE SAVEPOINT savepoint1 };The Oracle SAVEPOINT syntax differs from the ISO SAVEPOINT in three ways: it takes string variables instead of string literals; it uses SET SAVE-POINT instead of SAVEPOINT; and it uses RELEASE instead of RELEASE SAVEPOINT.
#sql { SET SAVEPOINT :savepoint };
#sql { ROLLBACK TO :savepoint };
#sql { RELEASE :savepoint };The SET TRANSACTION clause allows setting the access mode and/or the isolation level. Like JDBC, the SET TRANSACTION instruction must be the first statement preceding any DML statements.
Syntax:
#sql { SET TRANSACTION <access_mode>, <ISOLATION LEVEL
isolation_level> };
#sql [context] { SET TRANSACTION <access_mode>,
<ISOLATION LEVEL isolation_level> };When the connection context is not specified, the setting applies to the default context.
The access mode can take two values:
READ ONLYorREAD WRITE.READ ONLY:SELECTis allowed, but DML (i.e.,INSERT, UPDATE, DELETE,andSELECT FOR UPDATE) are not.READ WRITE(default):SELECTand DML are allowed.
The SQLJ transaction isolation levels are semantically identical to the JDBC transaction isolation levels covered in Chapter 9 (see following examples).
Examples:
#sql { SET TRANSACTION READ WRITE };
#sql { SET TRANSACTION READ ONLY};
#sql { SET TRANSACTION ISOLATION LEVEL SERIALIZABLE };
#sql [Ctxt] { SET TRANSACTION ISOLATION LEVEL SERIALIZABLE };
#sql { SET TRANSACTION READ WRITE, ISOLATION LEVEL
SERIALIZABLE };
#sql { SET TRANSACTION ISOLATION LEVEL READ COMMITTED READ
ONLY};
#sql { SET TRANSACTION ISOLATION LEVEL READ COMMITTED, READ
WRITE };
#sql {SET TRANSACTION READ ONLY,ISOLATION LEVEL READ
UNCOMMITTED};
#sql {SET TRANSACTION READ WRITE,ISOLATION LEVEL READ
UNCOMMITTED};The procedure clause is used for calling a stored procedure (PL/SQL, Java, or SQLJ). You can think of it as JDBC CallableStatement/OracleCallableStatement made simple, and here is the syntax:
#sql { CALL PROC(<PARAM_LIST>) };Assume we have a basic (and stupid) Java stored procedure that returns the database date (I told you it’s stupid!) as out parameter.
Here is the SQLJ code fragment:
java.sql.Date x;
#sql { CALL basicproc(:out x) };
System.out.println(" The Database Current date is " +
x.toString());The complete code and script is shown in Listing 11.2.
basicProc.sql
=============
create or replace and resolve java source named basicproc as
import java.sql.Date;
public class basicProc {
public static void foo(Date d[]) {
d[0] = new java.sql.Date(System.currentTimeMillis());;
}
}
/
create or replace procedure basicproc(d OUT DATE) as language java
name 'basicProc.foo(java.sql.Date[])';
/
connect.properties
==================
# Users should uncomment one of the following URLs or add their own.
# (If using Thin, edit as appropriate.)
#sqlj.url=jdbc:oracle:thin:@localhost:1521:inst1
sqlj.url=jdbc:oracle:thin:@inst1
#sqlj.url=jdbc:oracle:oci8:@
#sqlj.url=jdbc:oracle:oci7:@
# User name and password here (edit to use different user/password)
sqlj.user=scott
sqlj.password=tigerimport sqlj.runtime.ref.*;
import oracle.sqlj.runtime.*;
import java.sql.*;
public class basicProc
{
public static void main(String[] args)
{
try
{
Oracle.connect(basicProc.class, "connect.properties");
java.sql.Date x;
#sql { CALL basicproc(:out x) };
System.out.println("The Database Current date is " +
x.toString());
}
catch (java.sql.SQLException sqlex)
{
sqlex.printStackTrace();
System.out.println(sqlex);
}
}
}
$ sqlj basicProc.sqlj
$ java -Doracle.net.tns_admin=$TNS_ADMIN basicProc
The Database Current date is 2006-01-04
$The SQL clause refers to embedding valid DML statements (i.e., UPDATE, INSERT, and DELETE). Combine this with the SELECT clause, and you can get a feel for the simplicity, in its whole simplicity: no Statement/OracleStatement or PreparedStatement/OraclePreparedStatement or the like.
#sql { INSERT INTO TAB1 VALUES (PMTS','Kenneth',12,'Parker',NULL) };
#sql { INSERT INTO TAB2 SELECT * FROM TAB1 } ;
// A more comprehensive code fragment
#sql public static context ConCtx;
...
ctx = new ConCtx(getConnect());
...
int count = 0;
#sql [ctx] { SELECT count(*) into :count FROM Tab1 };
// Add 100 more rows
for (int i = 0; i < 100; i++) {
#sql [ctx] { INSERT INTO Tab1 values(:(i+count)) };
#sql { UPDATE EMP SET ENAME = 'Joe Bloe' WHERE EMPNO = 7788 };
#sql [ctx] { UPDATE EMP SET SAL=4500.0 WHERE EMPNO = 7788 } ;The PL/SQL clause consists of using anonymous PL/SQL blocks such as BEGIN...END, or DECLARE ... BEGIN ... END, within SQLJ statements.
// Example #1
char name ;
#sql { BEGIN SELECT ename INTO :out name FROM emp
WHERE ename='KING'; END; };
System.out.printlm("Name: " + name);
// Example #2
String pay;
#sql { BEGIN EXECUTE IMMEDIATE
:("update emp set sal=3500 where ename='KING'"); END;
};
#sql { SELECT sal into :pay FROM emp WHERE ename='KING' };
// Example #3
a = 0;
b = 0;
c = 0;
#sql
{
BEGIN
:OUT a := 45345;
:OUT b := 676;
:OUT c := 9999;
END;
};
System.out.println("a = " + a + ", b = " + b + ", c = "
+ c + "." );This is a very powerful technique. If you are familiar with PL/SQL, you can use this technique as a smooth transition to database programming with Java; JDBC might be a little bit intimidating. If you are unfamiliar, you can still use this same technique as a wrapper to anonymous PL/SQL block, provided you know what this block is doing.
Assignment clauses comprise: Query clause, Function clause, and Iterator conversion clause.
The query clause consists of selecting data into a SQLJ iterator, covered in section 11.2.1.
#sql iter = { SQLJ clause };
#sql [conctx, exectx] iter = { SQLJ clause };A function clause is used for calling a stored function. The standard syntax is shown as follows:
#sql result = { VALUES (<Function> (<paramlist>))};The Oracle-SQLJ also supports the following alternative syntax:
#sql result = { VALUES <Function> (<paramlist>)};Assume a stored function, which is a modified version of the basic Java stored procedure (just for the sake of calling a function from SQLJ):
SQL> create or replace and resolve java source named basicfunc as
2 import java.sql.Date;
3 public class basicFunc {
4
5 public static String foo(Date d) {
6 return d.toString();
7 }
8 }
9 /
Java created.
SQL>
SQL> create or replace function basicfunc(d DATE) return VARCHAR2 as
language java
2 name 'basicFunc.foo(java.sql.Date) return java.lang.String';
3 /
Function created.In SQL*Plus you invoke the function as follows:
SQL> select basicfunc(sysdate) from dual; BASICFUNC(SYSDATE) ----------------------------------------- 2006-01-04 SQL>
Here is the equivalent SQLJ code fragment:
java.sql.Date x = new
java.sql.Date(System.currentTimeMillis());
#sql datstr = { VALUES basicfunc(:x) };
System.out.println(" The Curent date is " + datstr);The complete code and script are shown in Listing 11.3.
connect.properties =========== # Users should uncomment one of the following URLs or add their own. # (If using Thin, edit as appropriate.) #sqlj.url=jdbc:oracle:thin:@localhost:1521:inst1 sqlj.url=jdbc:oracle:thin:@inst1 #sqlj.url=jdbc:oracle:oci8:@ #sqlj.url=jdbc:oracle:oci7:@ # User name and password here (edit to use different user/password) sqlj.user=scott sqlj.password=tiger
Example 11.3. basicFunc.sqlj
==============================
import sqlj.runtime.ref.*;
import oracle.sqlj.runtime.*;
import java.sql.*;
public class basicFunc
{
public static void main(String[] args)
{
try
{
Oracle.connect(basicFunc.class, "connect.properties");
String datstr;
java.sql.Date x = new java.sql.Date(System.currentTimeMillis());
#sql datstr = { VALUES basicfunc(:IN x) };
System.out.println("The System Curent date is " + datstr);
}
catch (java.sql.SQLException sqlex)
{
sqlex.printStackTrace();
System.out.println(sqlex);
}
}
}
$ sqlj basicFunc.sqlj
$ java -Doracle.net.tns_admin=$TNS_ADMIN basicFunc
The System Curent date is 2006-01-04
$The iterator conversion clause consists of converting a JDBC result set into an iterator using the CAST operator:
#sql iter = { CAST :rset };Ths simple statement performs the following operations:
Binds the JDBC result set object (i.e.,
rset) into the SQLJ executable statementConverts the result set
Populates the SQLJ iterator (i.e.,
iter) with the result set dataThis is yet another illustration of SQLJ conciseness.
Even though the SQLJ specification only supports static SQL statements, the Oracle implementation allows dynamic SQL expressions that are only fully defined at runtime, avoiding the obligation to switch to JDBC for dynamic SQL operations. The dynamic expressions replace parts of the SQL expression, which is fully materialized only at runtime.
The dynamic expressions are called meta bind expressions. These are Java Strings, or String-valued Java expressions, optionally appended with a constant or static SQL expression, which is used during translation for syntax and semantics checking.
:{ Java_bind_expression }or:
:{ Java_bind_expression :: SQL_replacement_code }Meta bind expressions may be used as substitutes for the following:[1]
Table name:
int x = 10; int y = x + 10; int z = y + 10; String table = "new_Dept"; #sql { INSERT INTO :{table :: dept} VALUES (:x, :y, :z) };At translation time, using the static replacement code, it will become:
INSERT INTO dept VALUES (10, 20, 30);
At runtime it will be evaluated as:
INSERT INTO new_Dept VALUES (10, 20, 30);
All or part of a
WHEREclause condition:String table = "new_Emp"; String query = "ename LIKE 'S%' AND sal>1000"; #sql myIter = { SELECT * FROM :{table :: emp2} WHERE :{query :: ename='SCOTT'} };At translation time, using the static replacement code, it becomes:
SELECT * FROM emp2 WHERE ename='SCOTT';
At runtime, it becomes:
SELECT * FROM new_Emp WHERE ename LIKE 'S%' AND sal>1000;
Column name in a
SELECTstatement (without the column alias, if specified):double raise = 1.12; String col = "comm"; String whereQuery = "WHERE "+col+" IS NOT null"; for (int i=0; i>5; i++) { #sql { UPDATE :{"emp"+i :: emp} SET :{col :: sal} = :{col :: sal} * :raise :{whereQuery ::} }; }At translation time, using the static replacement code, it becomes:
UPDATE emp SET sal = sal * 1.12;
At runtime it becomes (with the
forloop):UPDATE emp0 SET comm = comm * 1.12 WHERE comm IS NOT null; UPDATE emp1 SET comm = comm * 1.12 WHERE comm IS NOT null; UPDATE emp2 SET comm = comm * 1.12 WHERE comm IS NOT null; UPDATE emp3 SET comm = comm * 1.12 WHERE comm IS NOT null; UPDATE emp4 SET comm = comm * 1.12 WHERE comm IS NOT null;
Role, schema, catalog, or package name in a data definition language (DDL) or DML statement
SQL literal value or SQL expression
However, in order for the SQLJ translator to figure out the nature of the SQL operation and perform syntactic analysis of the SQLJ statement, the following restrictions apply:
A meta bind expression cannot be the first noncomment of the SQLJ clause.
A meta bind expression cannot contain the
INTOtoken of a SQLJSELECT INTOstatement and cannot expand to become theINTO-list of aSELECT INTOstatement.A meta bind expression cannot appear in
CALL,VALUES,SET,COMMIT,ROLLBACK,FETCH INTO, orCAST.
In the previous descriptions, we’ve embedded the meta bind expressions directly into the SQL clause that is submitted to the SQL Translator; this is the usual way. You may also use anonymous PL/SQL block and JDBC for implementing dynamic SQL.
Anonymous PL/SQL block:
// #sql { begin execute immediate 'insert into ' || :table_name || '(ename, empno, sal) values( :1, :2, :3)' using :ename, :empno, :sal; end; };Dynamic SQL in JDBC:
String stmt = "select count(*) from " + table; PreparedStatement ps = DefaultContext.getDefaultContext().getConnection().prepareSta tement(stmt); ResultSet rs = ps.executeQuery(); rs.next(); count = rs.getInt(1); rs.close(); ps.close();
SQLJ lets you exploit Java expressions in SQLJ statements; this section details host expressions, context expressions, and result expressions. Here is the generic syntax:
#sql [connctxt_exp, execctxt_exp]result_exp = { SQL with host expression };
In SQLJ, host variables are Java variables prefixed by a colon (i.e., “:”) and optionally coupled with the usage mode (i.e., :IN, :OUT, :INOUT, the default mode is OUT).
Examples:
//
int hvar;
#sql { SELECT 3 INTO :hvar FROM dual };
//
BigDecimal bdvar = new BigDecimal(8);
#sql bdvar = { VALUES(Fn(:IN bdvar, :OUT bdvar, :INOUT bdvar)
};Note
A simple host variable can appear multiple times in the same SQLJ statement provided these are all input variables, or at least one of these occurrences is an output variable in a stored procedure/function call, SET statement, or INTO-list. By default, Oracle SQLJ creates a unique name for each reference of the variable; however, the -bind-by-identifier flag when set to true allows SQLJ to evaluate all occurences of the same host variable to the same value.
//
int raise = 250;
#sql { UPDATE EMP SET SAL = SAL + :raise WHERE ENAME = 'KING' };
//
class BaseClass
{
static class Inner
{
static BigDecimal bdvar = null;
}
public void run() {}
static public int i = 1;
}
public class SubClass extends BaseClass
{
int j = 2;
public void run()
{
BigDecimal bdvar = null;
try {
#sql { select sal into :bdvar from emp where ENAME='KING' };
#sql { select sal into :(Inner.bdvar) from emp where ENAME='KING' };
System.out.println("sal is : " + Inner.bdvar);
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("bdvar is " + bdvar);
}
private int l = 0;
}More general and more versatile than host variables, SQLJ host expressions let you use any valid Java expressions, including simple Java host variables, simple Java class field values, simple Java array elements, complex Java arithmetic expressions, Java method calls with return values, Java conditional expressions (a ? b : c), Java logical expressions, and Java bitwise expressions. Host expressions can be used in lieu of host variables, within the curly braces of a SQLJ executable statement (i.e., within the SQL space) either as OUT parameter (the default), or IN parameter, or INOUT parameter.
Host expressions are specified by enclosing them within ":("and and ")"; optionally coupled with the mode: ":IN(" or ":OUT(" or ":INOUT(".
Examples (code fragments):
BigDecimal hvar;
static final double d = 0.0;
int instanceMeth(int a, int b){return 1;}
static int staticMeth(int a, int b) {return 2;}
// arithmetic expressions (assume variable i, j, and k)
#sql { set :hvar = :(1/i) };
#sql { select :(0) from dual };
#sql { select :(i+j*k) from dual into :(m) };
#sql { select :(x[1].j[0] += -33 ) from dual };
#sql { select :(-2.71f) from dual into :(y) };
#sql { SELECT :(j+=i) into :k from dual};
#sql { select :(j + i ) from dual into :(i) };
//
public static final int FOO = 111 * 4 + 666 / 2;
#sql { select :(111 * 4 + 666 / 2) from dual into :FOO};
//
#sql {set :hvar = :(1/(true?0:3)) }; // conditional
expression
#sql {set :hvar = :(staticMeth(1, 2)) }; // ref to static
method
#sql {set :hvar = :(instanceMeth(1, 2)) }; // ref to instance
method
#sql { select :(fib(n-1)) + :(fib(n-2)) into :res from dual };
int salary = -32;
#sql { SELECT SAL into :salary from emp where EMPNO = 7788 };
System.out.println("Salary = " + salary );Unlike host expressions, which are used in the SQL space (i.e., within the curly braces), connection context expressions, execution context expressions, and result expressions are used in the SQLJ space, meaning outside the curly braces.
A context expression is a valid Java expression, including local variables, declared parameters, class fields, and array elements, that defines the name of a connection context instance or an execution context instance.
#sql [context_array[thread]] result = {
VALUES(foo(:bar,:baz)) };Code fragment:
#sql context myCtx;
#sql iterator myCurs (Double sal, int ename, String ename);
// array of connection context
myCtx [] ctx – new myCtx[2];
ctx[0] = new Ctx(getConnect());
// get an instance of iterator
myCurs [] c = new myCurs[ 2 ];
#sql [ctx[0]] c[0] = { SELECT SAL, EMPNO, ENAME FROM EMP
WHERE EMPNO = 7788 };A result expression is any legal Java expression, including local variables, declared parameters, class fields, and array elements, that can receive query results or function return (i.e., appears on the left side of an equals sign).
#sql [context] result_array[i] = { VALUES(foo(:bar,:baz)) };Code fragment:
#sql context myCtx;
#sql iterator myCurs (Double sal, int ename, String ename);
myCtx ctx = new Ctx(getConnect());
// array of iterator instances
myCurs [] c = new myCurs[ 2 ];
#sql [ctx] c[0] = { SELECT SAL, EMPNO, ENAME FROM EMP WHERE
EMPNO = 7788 };Unlike PL/SQL, where host espressions are all evaluated together in the order of their appearance before any statements within the block are executed, host expressions in SQLJ are evaluated by Java from left to right, once and only once, before being sent to SQL. Upon execution, the OUT and INOUT host expressions are assigned values in order from left to right, and then result expressions are assigned values last.
For standard ISO-SQLJ code, the following rules apply:
Connection context expressions are evaluated immediately, before any other Java expressions.
Execution context expressions are evaluated after connection context expressions, but before result expressions.
Result expressions are evaluated after context expressions, but before host expressions.
Chapter 10 introduced SQLJ as JDBC made simpler; however, because these API come from different standard bodies (JCP versus ISO), SQLJ does not support every JDBC features and vice versa. The good news is that you can mix the two APIs within the same application. This section briefly covers interoperability in terms of connection (i.e., how to use JDBC connection in SQLJ, how to use SQLJ connection context with JDBC) and also in terms of data retrieval (i.e., converting JDBC Result Set into SQLJ iterators and converting SQLJ iterators into JDBC ResultSet).
Listing 11.4 illustrates using JDBC connection as SQLJ connection context and converting JDBC Result Set into SQLJ Named Iterator.
Note
You should access the iterator only; avoid retrieving data from the result set, either before or after the conversion. Upon completion, close the iterator, not the result set.
import sqlj.runtime.ref.DefaultContext;
import java.sql.*;
import oracle.sqlj.runtime.*;
import oracle.jdbc.pool.OracleDataSource;
public class Jdbc2Sqlj
{
#sql static public iterator NameIter (double sal, int empno);
public static void main(String[] args) throws java.sql.SQLException
{
try {
// Create an OracleDataSource
OracleDataSource ods = new OracleDataSource();
// Set the URL, using TNS Alias with JDBC-Thin
String url = "jdbc:oracle:thin:scott/tiger@inst1";
ods.setURL(url);
Connection conn = ods.getConnection(); // Retrieve a connection
conn.setAutoCommit(false); // Disable Auto Commit
DefaultContext.setDefaultContext(new DefaultContext(conn));
PreparedStatement s =
DefaultContext.getDefaultContext().getConnection().prepareCall
("UPDATE EMP SET SAL = 4350 WHERE EMPNO = 7788");
s.executeUpdate();
s.close();
s =
DefaultContext.getDefaultContext().getConnection().prepareCall
("SELECT SAL, EMPNO FROM EMP WHERE EMPNO = 7788");
ResultSet rs = s.executeQuery();
NameIter niter;
#sql niter = { CAST :rs };
while (niter.next()) {
System.out.println("SAL = " + niter.sal() + ", EMPNO = " +
niter.empno());
}
s.close();
niter.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
$sqlj Jdbc2Sqlj.sqlj
$java -Doracle.net.tns_admin=$TNS_ADMIN Jdbc2Sqlj
SAL = 4350.0, EMPNO = 7788
$As we have seen when discussing JDBC, the Oracle JDBC brings extraordinary connection services in RAC/Grid environments, including implicit connection caching, fast connection fail-over, and runtime connection load balancing. SQLJ can benefit from all of these by just delegating connection concerns to JDBC. Listing 11.5 illustrates this point:
Example 11.5. myInterop.sqlj
import sqlj.runtime.ref.DefaultContext;
import java.sql.*;
import oracle.sqlj.runtime.*;
import oracle.jdbc.pool.OracleDataSource;
public class myInterop
{
public static void main(String[] args) throws java.sql.SQLException
{
try {
// Create an OracleDataSource
OracleDataSource ods = new OracleDataSource();
// Set the URL, using TNS Alias with JDBC-Thin
String url = "jdbc:oracle:thin:scott/tiger@inst1";
ods.setURL(url);
Connection conn = ods.getConnection(); // Retrieve a connection
conn.setAutoCommit(false); // Disable Auto Commit
// Create/Set SQLJ context from JDBC connection
// From here let's speak SQLJ
DefaultContext.setDefaultContext(new DefaultContext(conn));
System.out.println("Create a dummy function.");
#sql { CREATE OR REPLACE FUNCTION R(dummy integer) RETURN INTEGER AS
i INTEGER;
BEGIN
SELECT SAL INTO i FROM EMP WHERE ENAME = 'SMITH';
RETURN i;
END; };
int start_sal;
#sql start_sal = { VALUE R(100) };
System.out.println("Starting pay: " + start_sal );
int raise = 300;
#sql { UPDATE EMP SET SAL = SAL + :raise WHERE ENAME = 'SMITH' };
System.out.println(" Giving Raise to SMITH ");
int end_sal;
#sql end_sal = { VALUE R(100) };
System.out.println("Ending pay: " + end_sal +
" - Raise amt is "+ (end_sal-start_sal));
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
$ sqlj myInterop.sqlj
$ java -Doracle.net.tns_admin=$TNS_ADMIN myInterop
Create a dummy function.
Starting pay: 800
Giving Raise to SMITH
Ending pay: 1100 - Raise amt is 300
$ Remember that ResultSet Iterators are more suitable for conversion into JDBC Result Set. Listing 11.6 illustrates using SQLJ connection context with JDBC and converting SQLJ iterator into JDBC Result Set:
import sqlj.runtime.ref.DefaultContext;
import java.sql.SQLException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import oracle.sqlj.runtime.*;
public class Sqlj2Jdbc
{
public static void main(String[] args) throws java.sql.SQLException
{
try {
java.sql.ResultSet rs;
sqlj.runtime.ResultSetIterator sri;
Oracle.connect(Sqlj2Jdbc.class, "connect.properties");
#sql sri = { SELECT ename, empno FROM EMP };
rs = sri.getResultSet();
while (rs.next())
{
System.out.println (" *** Emp Name: " + rs.getString(1) + I
" -- Emp #: " + rs.getInt(2));
};
sri.close();
Oracle.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
$ sqlj Sqlj2Jdbc.sqlj
$ java -Doracle.net.tns_admin=$TNS_ADMIN Sqlj2Jdbc
*** Emp Name: SMITH -- Emp #: 7369
*** Emp Name: ALLEN -- Emp #: 7499
*** Emp Name: WARD -- Emp #: 7521
*** Emp Name: JONES -- Emp #: 7566
*** Emp Name: MARTIN -- Emp #: 7654
*** Emp Name: BLAKE -- Emp #: 7698
*** Emp Name: CLARK -- Emp #: 7782
*** Emp Name: SCOTT -- Emp #: 7788
*** Emp Name: KING -- Emp #: 7839
*** Emp Name: TURNER -- Emp #: 7844
*** Emp Name: ADAMS -- Emp #: 7876
*** Emp Name: JAMES -- Emp #: 7900
*** Emp Name: FORD -- Emp #: 7902
*** Emp Name: MILLER -- Emp #: 7934
$The same technique can be used for converting Named and Positional iterators into JDBC Result Sets.
Now that we have seen the essential elements of a SQLJ program, let’s tackle the last part of this abridged SQLJ coverage: SQL data access and manipulation using SQLJ, in the next chapter.