
Suppose you have an online system for your customers to order products. On a daily basis, the system creates a file with the orders information. Now you will check if you have stock for the ordered products and make a list of the products you'll have to buy.
- Create a new transformation.
- From the Input category of steps, drag a Get data from XML step to the canvas.
- Use it to read the
orders.xmlfile. In the Content tab, fill the Loop XPath option with the/orders/orderstring. In the Fields tab get the fields. - Do a preview. You will see the following:
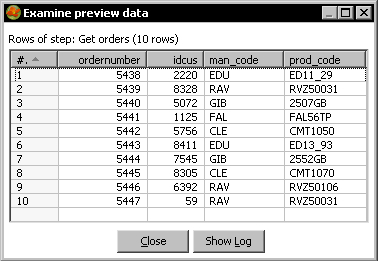
- Add a Sort rows step and use it to sort the data by
man_code, prod_code. - Add a Group by step and double-click it.
- Use the upper grid for grouping by
man_codeandprod_code. - Use the lower grid for adding a field with the number of orders in each group. As Name write
quantity, as Subjectordernumber, and as Type write Number of Values (N). Expand the Lookup category of steps. - Drag a Database lookup step to the canvas and create a hop from the Group by step toward this step.
- Double-click the Database lookup step.
- As Connection, select
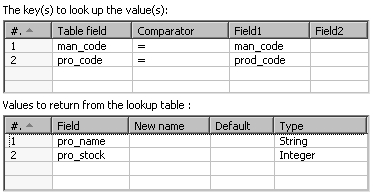
jsand in Lookup table, browse the database and selectproductsor just type its name. - Fill the grids as follows:
- Click on OK.
- Add a filter step to pass only the rows where
pro_stock<quantity. - Add a Text file output step to send the manufacturer code, the product code, the product name, and the ordered quantity to a file named
products_to_buy.txt. - Run the transformation.
- The file should have the following content:
man_code;prod_code;pro_name;quantity EDU;ED13_93;Times Square;1 RAV;RVZ50031;Disney World Map;2 RAV;RVZ50106;Star Wars Clone Wars;1
You processed a file with orders. You grouped and counted the ordered products by product code. Then with the Database lookup step, you looked up the product table for the record belonging to the ordered product. You added to your stream, the name and stock for the products. After that, you kept only the rows for which the stock was lower than the units your customers ordered. With the rows that passed, you created a list of products to buy.
The Database lookup step allows you to look up values in a database table. In the upper grid of the setting window, you specify the keys to look up. In the example you look for a record that has the same product code and manufacturer code as the codes coming in the stream.
In the lower grid you put the name of the table columns you want back. Those fields are added to the output stream. In this case, you added the name and the stock of the product.
The step returns only one row even if it doesn't find a matching record or if it finds more than one. When the step doesn't find a record with the given conditions, it returns null for all the added fields, unless you specify a default value for those new fields.
Note that this behavior is quite similar to the Stream lookup step's behavior. You search for a match and, if a record is found, the step returns you the specified fields. If not, the new fields are filled with default values. Besides the fact that the data is searched in a database, the new thing here is that you specify the comparator to be used: =, <, >, and so on. The Stream lookup step looks only for equal values. As all the products in the file existed in your database, the step found a record for every row, adding to your stream two fields: the name and the stock for the product. You can check it by doing a preview on the Database lookup step. After the Database lookup setup, you used a Filter rows step to discard the rows where the stock was lower than the required quantity of products. You can avoid adding this step by refining the lookup configuration. In the upper grid you could add the condition pro_stock<quantity and check the Do not pass the row if the lookup fails checkbox; you now get a different result. The step will look not only for the product, but also for the condition pro_stock<quantity. If it doesn't find a record that matches, that is, the lookup fails, the check Do not pass the row if the lookup fails does its work—filters the row. Doing these changes, you don't have to use the extra Filter rows step, nor add the pro_stock field to the stream unless you need it for another use.
As a final remark—if the lookup returns more than one row, only the first is returned. You have the option to abort the whole transformation if this happens—simply check the Fail on multiple results? checkbox.
Tip
Making a performance difference when looking up data in a database
Database lookups are costly and can severely impact transformation performance. However, performance can be significantly improved by using the cache feature of the Database lookup step. To enable the cache feature, just check the Enable cache? option.
This is how it works: Think of the cache as a buffer of high-speed memory that temporarily holds frequently requested data. By enabling the cache option, Kettle will look first in the cache and then in the database.
If the table where you look up has few records, you could preload the cache with all the data in the lookup table. You do it by checking the Load all data from table option. This will give you the best performance.
On the contrary, if the number of rows in the lookup table is too large to fit entirely into memory, instead of caching the whole table you can tell Kettle the maximum number of rows to hold in cache. You do it by specifying the number in the Cache size in rows textbox. The bigger this number, the faster the lookup process.
Note
Be careful when setting the cache options. If you have a large table or don't have much memory, you risk running out of memory.
Create a new transformation and do the following. Taking as source the orders file, create a list of the customers who ordered products. Include their name, last name, and full address. Order the data by country name.
Modify the original transformation. As the file may have been manipulated, it may contain invalid data. Apply the following treatment:
- Verify that there is a customer with the given number. If the customer doesn't exist, discard the row. Use the Do not pass the row if the lookup fails checkbox.
- In the rows that passed, verify that there is a product with the given manufacturer and product codes. If the data is valid, check the stock and proceed. If not, make a list so that the cases can be handled later by the customer care department.