
Let's modify the transformation that calculates the top scores to avoid unnecessary duplication of steps:
- Under the
transformationfolder, create a new folder namedsubtransformations. - Create a new transformation and save it in that new folder with the name
scores.ktr. - Expand the Mapping category of steps. Select a Mapping input specification step and drag it to the work area.
- Double-click the step and fill it like this:
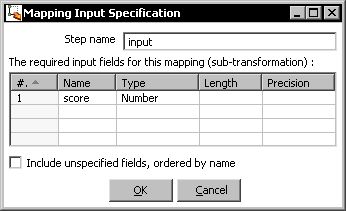
- Add a Sort rows step and use it to sort the
scorefield in descending order. - Add a JavaScript step and type the following code to filter the top 10 rows:
trans_Status = CONTINUE_TRANSFORMATION; if (getProcessCount('r')>10) trans_Status = SKIP_TRANSFORMATION; - Add an Add sequence step to add a sequence field named
seq. - Finally, add a Mapping output specification step. You will find it in the Mapping category of steps. Your transformation looks like this:

- Save the transformation.
- Open the transformation
top_scores.ktrand save it astop_scores_with_subtransformations.ktr. - Modify the writing stream. Delete all steps except the Text file output step—the Sort rows, JavaScript, Add sequence, and the Select rows steps.
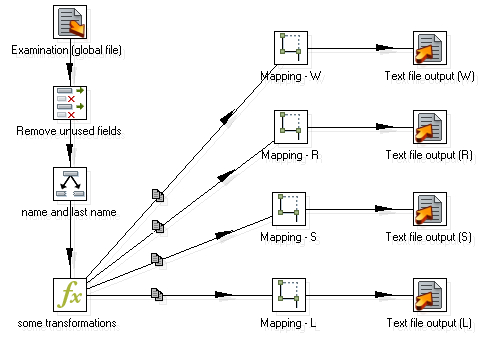
- Drag a Mapping (sub-transformation) step to the canvas and put it in the place where all the deleted steps were. You should have this:

- Double-click the Mapping step.
- In the Mapping transformation frame, select the option named Use a file for the mapping transformation. In the textbox below it, type
${Internal.Transformation.Filename.Directory}/subtransformations/scores.ktr. Select the Input tab, check the Is this the main data path? option, and fill the grid as shown:
- Select the Output tab and fill the grid as shown:

- Click on OK.
- Repeat the steps 11 to 16 for the other streams—reading, speaking, and listening. The only difference is what you put in the Input tab of the Mapping steps—instead of
writing, you should putreading, speaking, andlistening. - The final transformation looks as follows:
- Save the transformation.
- Press F9 to run the transformation.
- Select Minimal logging and click on Launch. The Logging window looks like the following:
- The output files should have been generated and should look exactly the same as before. This time let's check the
reading_top10.txtfile (the names and values may vary depending on the examination files that you appended to the global file):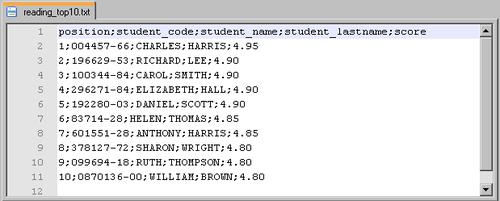
You took the bunch of steps that calculate the top scores and moved it to a subtransformation. Then, in the main transformation, you simply called the subtransformation four times, each time using a different field.
It's worth saying that the Text file output step could also have been moved to the subtransformation. However, instead of simplifying the work, it would have complicated it. This is because the names of the files are different in each case and, in order to build that name, it would have been necessary to add some extra logic.
Subtransformations are, as the named suggests, transformations inside transformations.
Note
The PDI proper name for a subtransformation is mapping. However, as the word mapping is also used with other meanings in PDI, we will use the old, more intuitive name subtransformation.
In the tutorial, you created a subtransformation to isolate a task that you needed to apply four times. This is a common reason for creating a subtransformation—to isolate a functionality that is likely to be needed more than once. Then you called the subtransformations by using a single step.
Let's see how subtransformations work. A subtransformation is like a regular transformation, but it has input and output steps, connecting it to the transformations that use it.
The Mapping input specification step defines the entry point to the subtransformation. You specify here just the fields needed by the subtransformation. The Mapping output specification step simply defines where the flow ends.
Note
The presence of Mapping input specification and Mapping output specification steps is the only fact that makes a subtransformation different from a regular transformation.
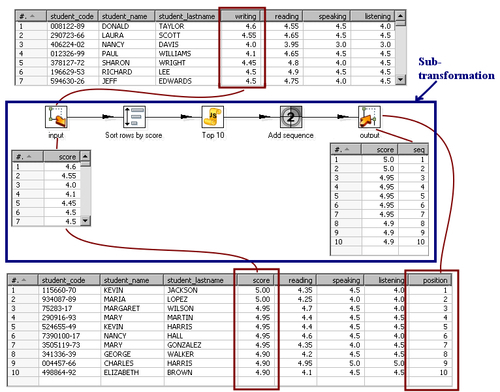
In the sample subtransformation you created in the tutorial, you defined a single field named score. You sorted the rows by that field, filtered the top 10 rows, and added a sequence to identify the rank—a number from 1 to 10.
You call or execute a subtransformation by using a Mapping (sub-transformation) step. In order to execute the subtransformation successfully, you have to establish a relationship between your fields and the fields defined in the subtransformation.
Let's first see how to define the relationship between your data and the input specification. For the sample subtransformation, you have to define which of your fields is to be used as the input field score defined in the input specification. You can do it in an Input tab in the Mapping step dialog window. In the first Mapping step, you told the subtransformation to use the field writing as its score field.
If you look at the output fields coming out of the Mapping step, you will no longer see the writing field but a field named score. It is the same field writing that was renamed as score. If you don't want your fields to be renamed, simply check the Ask these values to be renamed back on output? option found in the Input tab. That will cause the field to be renamed back to its original name—writing in this example.
Let's now see how to define the relationship between your data and the output specification. If the subtransformation creates new fields, you may want to add them to your main dataset. To add to your dataset, a field created in the subtransformation, you use an Output tab of the Mapping step dialog window. In the tutorial, you were interested in adding the sequence. So, you configured the Output tab, telling the subtransformation to retrieve the field named seq in the subtransformation but renamed as position. This causes a new field named position to be added to your stream.
If you want the subtransformation to simply transform the incoming stream without adding new fields, or if you are not interested in the fields added in the subtransformation, you don't have to create an Output tab.
The following screenshot summarizes what was explained just now. The upper and lower grids show the datasets before and after the streams have flown through the subtransformation.
The subtransformation in the tutorial allowed you to reuse a bunch of steps that were present in several places, avoiding doing the same task several times. Another common situation where you may use subtransformations is the one where you have a transformation with too many steps. If you can identify a subset of steps that accomplish a specific purpose, you may move those steps to a subtransformation. Doing so, your transformation will become cleaner and easier to understand.
Modify the subtransformation in the following way:
Add a new field named below_first. The field should have the difference between the score in the current row and the maximum score. For example, if the maximum score is 5 and the current score is 4.85, the value for the field should be 0.15.
Modify the main transformation by adding the new field to all output files.
Combine the following Hero exercises from Chapter 3:
- Counting words, discarding those that are commonly used
- Counting words more precisely
Create a subtransformation that receives a String value and cleans it. Remove extra signs that may appear as part of the string such as . , ) or". Then convert the string to lower case.
Also create a flag that tells whether the string is a valid word. Remember that the word is valid if its length is at least 3 and if it is not in a given list of common words.
Retrieve the modified word and the flag.
Modify the main transformation by using the subtransformation. After the subtransformation step, filter the words by looking at the flag.
With the implementation of a subtransformation, you simplify much of the transformation. But you still have some reworking to do. In the main transformation, you basically do two things. First you read the source data from a file and prepare it for further processing. And then, after the preparation of the data, you generate the files with the top scores. To have a clearer vision of these two tasks, you can split the transformation in two, creating a job as a process flow. Let's see how to do that.