
Now you will split your transformation into two smaller transformation so that each meets a specific task. Here are the instructions.
- Open the transformation in the previous tutorial. Select all steps related to the preparation of data, that is, all steps from the Text file input step upto the Formula step.
- Copy the steps and paste them in a new transformation.
- Expand the Job category of steps.
- Select a Copy rows to result step, drag it to the canvas, and create a hop from the last step to this new one. Your transformation looks like this:

- Save the transformation in the
transformationsfolder with the nametop_scores_flow_preparing.ktr. - Go back to the original transformation and select the rest of the steps, that is, the Mapping and the Text file output steps.
- Copy the steps and paste them in a new transformation.
- From the Job category of steps select a Get rows from result step, drag it to the canvas, and create a hop from this step to each of the Mapping steps. Your transformation looks like this:
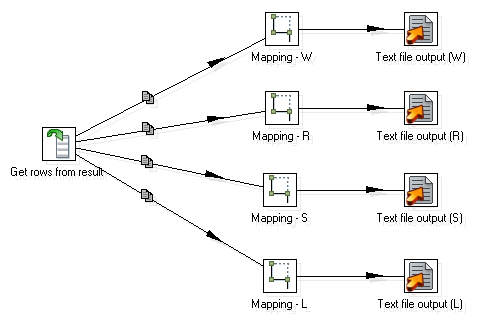
- Save the transformation in the
transformationsfolder with the nametop_scores_flow_processing.ktr. - In the
top_scores_flow_preparingtransformation , right-click the step Copy rows to result and select Show output fields. - The grid with the output dataset shows up.
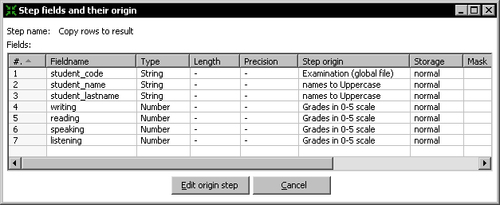
- Select all rows. Press Ctrl+C to copy the rows.
- In the
top_scores_flow_processingtransformation, double-click the step Get rows from result. - Press Ctrl+V to paste the values. You have the following result:
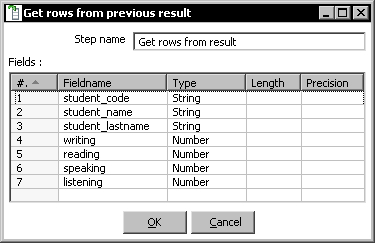
- Save the transformation.
- Create a new Job.
- Add a START and two transformation entries to the canvas and link them one after the other.
- Double-click the first transformation. Put
${Internal.Job.Filename.Directory}/transformations/top_scores_flow_preparing.ktras the name of the transformation. - Double-click the second transformation. Put
${Internal.Job.Filename.Directory}/transformations/top_scores_flow_processing.ktras the name of the transformation. - Your job looks like the following:

- Save the job. Press F9 to open the Job properties window and click on Launch. Again, the four files should have been generated, with the very same information.
You split the main transformation in two—one for the preparation of data and the other for the generation of the files. Then you embedded the transformations into a job that executed them one after the other. By using the Copy rows to result step, you sent the flow of data outside the transformation, and using Get rows from result step, you picked that data to continue with the flow. The final result was the same as before the change.
Note
Notice that you split the last version of the transformation—the one with the subtransformations inside. You could have split the original. The result would have been exactly the same.
The copy/get rows mechanism allows you to transfer data between two transformations, creating a process flow. The following drawing shows you how it works:

The Copy rows to result step transfers your rows of data to the outside of the transformation. You can then pick that data by using a Get rows from result step. In the preceding image, Transformation A copies the rows and, Transformation B, which executes right after Transformation A, gets the rows. If you create a single transformation with all steps from Transformation A followed by all steps from Transformation B, you would get the same result.
Note
The copy of the dataset is made in memory. It's useful when you have small datasets. For bigger datasets, you should prefer saving the data in a temporary file or database table in the first transformation, and then create the dataset from the file or table in the second transformation.
The Serialize to file /De-serialize from file steps are very useful for this, as the data and the metadata are saved together.
There is no limit to the number of transformations that can be chained using this mechanism. Look at the following image:
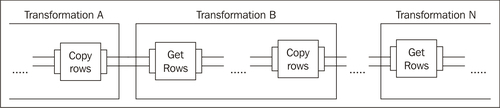
As you can see, you may have a transformation that copies the rows, followed by another that gets the rows and copies again, followed by a third transformation that gets the rows, and so on.
Modify the last exercise in the following way:
- Include just the students who had an average score above 70.
- Generate just the top five scores for every skill.
- Create each file in a different transformation. The transformations execute one after the other.