
Let's suppose, you have some plain text files, and you want to know what is said in them. You don't want to read them, so you decide to count the times that words appear in the text, and see the most frequent ones to get an idea of what the files are about.
Note
Before starting, you'll need at least one text file to play with. The text file used in this tutorial is named smcng10.txt and is available for you to download from the Packt website.
Let's work:
- Create a new transformation.
- By using a Text file input step, read your file. The trick here is to put as a separator a sign you are not expecting in the file, for example
|. By doing so, the entire line would be recognized as a single field. Configure the Fields tab by defining a single string field namedline. - From the Transform category of step, drag to the canvas a Split field to rows step, and create a hop from Text file input step to this new step.
- Configure the step like this:
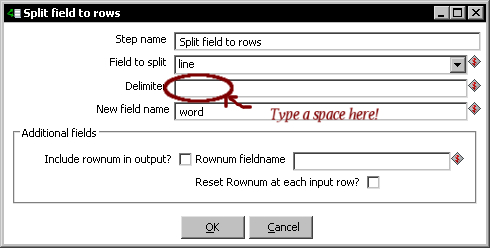
- With this last step selected, do a preview. Your preview window should look like this:
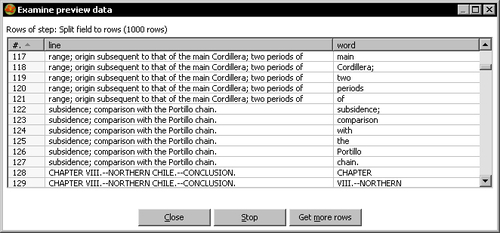
- Close the preview window.
- Expand the Flow category of steps, and drag a Filter rows step to the work area.
- Create a hop from the last step to the Filter rows step.
- Edit the Filter rows step by double-clicking it.
- Click the
<field>textbox to the left of the=sign. The list of fields appears. Selectword. - Click the
=sign. A list of operations appears. SelectIS NOT NULL. - The window looks like the following:
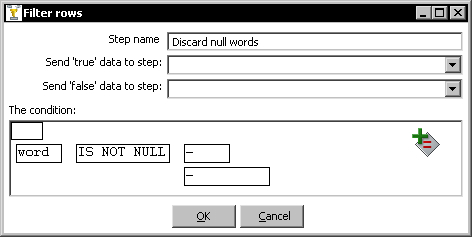
- Click OK.
- From the Transform category of steps drag a Sort rows step to the canvas, and create a hop from the Filter rows step to this new step.
- Sort the rows by
word. - From the Statistics category, drag a Group by step, and create a hop from the Sort rows step to this step.
- Configure the grids in the Group by configuration window like shown:
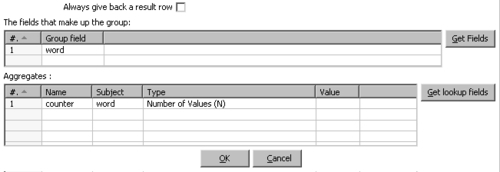
- Add a Calculator step, create a hop from the last step to this, and calculate the new field
len_wordrepresenting the length of the words. For that, use the calculator functionReturn the length of a string Aand selectwordfrom the drop-down menu for Field A. - Expand the Flow category and drag another Filter rows step to the canvas.
- Create a hop from the Calculator step to this step and edit it.
- Click
<field>and selectcounter. - Click the
=sign, and select>. - Click
<value>. A small window appears. - In the Value textbox of the little window,
enter 2. - Click OK.
- Position the mouse cursor over the icon in the upper-right corner of the window. When the text Add condition shows up, click on the icon.
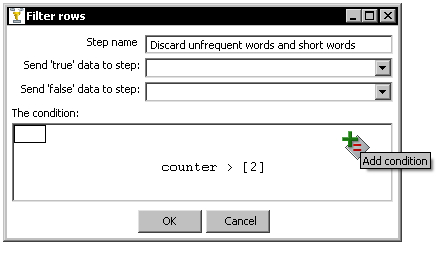
- A new blank condition is shown below the one you created.
- Click on null = [] and create the condition
len_word>3, in the same way you created the conditioncounter>2. - Click OK.
- The final condition looks like this:

- Add one more Filter rows step to the transformation and create a hop from the last step to this new step.
- On the left side of the condition, select
word. - As comparator select IN LIST.
- At the end of the condition, inside the textbox value, type the following:
a;an;and;the;that;this;there;these. - Click the upper-left square above the condition and the word NOT will appear.
- The condition looks like the following:
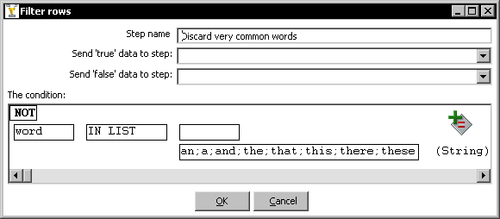
- Add a Sort rows step, create a hop from the previous step to this step, and sort the rows in the descending order of
counter. - Add a Dummy step at the end of the transformation, create a hop from the last step to the Dummy step.
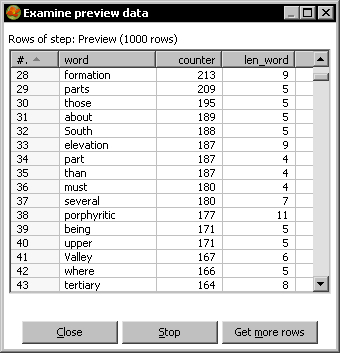
- With the Dummy step selected, preview the transformation. The following is what you should see now:
You read a regular plain file and arranged the words that appear in the file in some particular fashion.
The first thing you did was to read the plain file and split the lines so that every word became a new row in the dataset. Consider, for example, the following line:
subsidence; comparison with the Portillo chain.
The splitting of this line resulted in the following rows being generated:
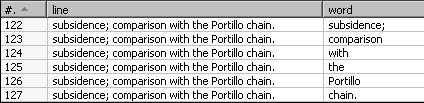
Thus, a new field named word became the basis for your transformation.
First of all, you discarded rows with null words. You did it by using a filter with the condition word IS NOT NULL. Then, you counted the words by using the Group by step you learned in the previous tutorial. Once you counted the words, you discarded those rows where the word was too short (length less than 4) or too common (comparing to a list you typed).
Once you applied all those filters, you sorted the rows in the descending order of the number of times the word appeared in the file so that you could see the most frequent words.
Scrolling down a little the preview window to skip some prepositions, pronouns, and other very common words that have nothing to do with a specific subject, you found words such as shells, strata, formation, South, elevation, porphyritic, Valley, tertiary, calcareous, plain, North, rocks, and so on. If you had to guess, you would say that this was a book or article about geology, and you would be right. The text taken for this exercise was Geological Observations on South America by Charles Darwin.
The Filter rows step allows you to filter rows based on conditions and comparisons.
The step checks the condition for every row. Then it applies a filter letting pass only the rows for which the condition is true. The other rows are lost.
In the counting words exercise, you used the Filter rows step several times so you already have an idea of how it works. Let's review it.
In the Filter rows setting window you have to enter a condition. The following table summarizes the different kinds of conditions you may enter:
|
Condition |
Description |
Example |
|---|---|---|
|
A single field followed by |
Checks whether the value of a field in the stream is null |
|
|
A field, a comparator, and a constant |
Compares a field in the stream against a constant value. |
|
|
Two fields separated by a comparator |
Compares two fields in the stream |
|
You can combine conditions as shown here:
counter > 2 AND len_word>3
You can also create subconditions such as:
( counter > 2 AND len_word>3 ) OR (word in list geology; sun)
In this last example, the condition lets the word geology pass even if it appears only once. It also lets the word sun pass, despite its length.
When editing conditions, you always have a contextual menu which allows you to add and delete sub-conditions, change the order of existent conditions, and more.
Maybe you wonder what the Send 'true' data to step: and Send 'false' data to step: textboxes are for. Be patient, you will learn how to use them in Chapter 4.
Now it is your turn to try filtering rows. Modify the counting_words transformation in the following way:
- Alter the Filter rows steps. By using a Formula step create a flag (a Boolean field) that evaluates the different conditions (
counter>2, and so on). Then use only one Filter rows step that filters the rows for which the flag is true. Test it and verify that the results are the same as before the change. - Add a sub-condition to avoid excluding some words, just like the one in the example:
(word in list geology; sun). Change the list of words and test the filter to see that the results are as expected.
If you take a look at the results in the tutorial, you may notice that some words appear more than once in the final list because of special signs such as . , ) or", or because of lower or upper case letters. For example, look how many times the word rock appears: rock (99 occurrences) - rock,(51 occurrences) rock. (11 occurrences) rock." (1 occurrence) - rock: (6 occurrences) - rock; - (2 occurrences). You can fix this and make the word rock appear only once: Before grouping the words, remove all extra signs and convert all words to lower case or upper case, so they are grouped as expected.
Try one or more of the following steps: Formula, Calculator, Replace in string.