
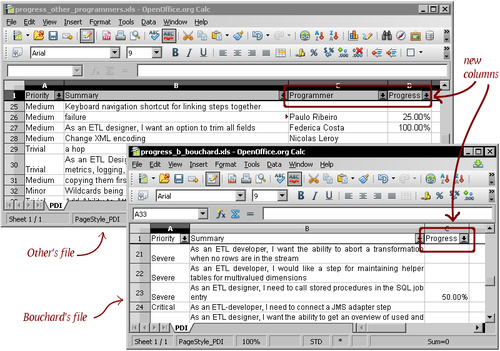
Suppose that you delivered the Excel files you generated in the Assigning tasks by filtering priorities tutorial earlier in the chapter. You gave the b_bouchard.xls to Benjamin Bouchard, the senior programmer. You also gave the other Excel file to a project leader who is going to assign the tasks to different programmers. Now they are giving you back the worksheets, with a new column indicating the progress of the development. In the case of the shared file, there is also a column with the name of the programmer who is working on every issue. Your task is now to unify those sheets.
Here is what the Excel files look like:
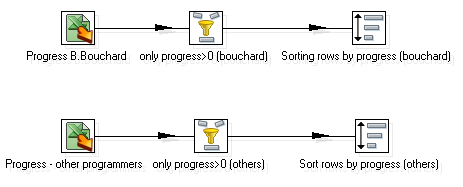
- Create a new transformation.
- Drag an Excel Input step to the canvas and read one of the files.
- Add a Filter row step to keep only the rows where the progress is not null, that is, the rows belonging to tasks whose development has been started.
- After the filter, add a Sort rows step, and configure it to order the fields by
Progress, in descending order. - Add another Excel Input step, read the other file, and filter and sort the rows just like you did before. Your transformation should look like this:
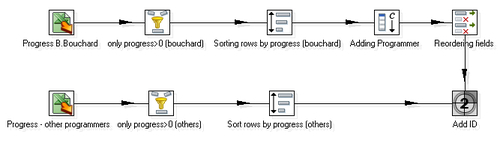
- From the Transform category of steps, select the Add Constants step and drag it onto the canvas.
- Link the step to the stream that reads the B. Bouchard's file; edit the step and add a new field named
Programmer, with typestringand value Benjamin Bouchard. - After this step, add a Select values step and reorder the fields so that they remain in a specific order
Priority, Summary, Programmer, Progress—to resemble the other stream. - Now, from the Transform category add an Add sequence step, name the new field
ID, and link the step with the Select values step. - Create a hop from the Sort rows step of the other stream to the Add sequence step. Your transformation should look like the one shown next:
- Select the Add sequence step and do a preview. You will see this:
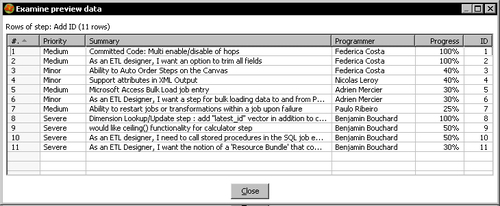
You read two similar Excel files and merged them into one single dataset.
First of all, you read, filtered, and sorted the files as usual. Then you altered the stream belonging to B. Bouchard, so it looked similar to the other. You added the field Programmer, and reordered the fields.
After that, you used an Add sequence step to create a single dataset containing the rows of both streams, with the rows numbered.
You can create a union of two or more streams anywhere in your transformation. To create a union of two or more data streams, you can use any step. The step unifies the data, takes the incoming streams in any order, and then it completes its task in the same way as if the data came from a single stream.
In the example, you used an Add sequence step as the step to join two streams. The step gathered the rows from the two streams, and then proceeded to numerate the rows with the sequence name ID.
This is only one example of how you can mix streams together. As said, any step can be used to unify two streams. Whichever the step, the most important thing you have to have in mind is that you cannot mix rows that have a different layout. The rows have to have the same lengths, the same data types, and the same fields in the same order.
Fortunately, there is a trap detector that provides warnings at design time if a step is receiving mixed layouts.
You can try this out. Delete the Select values step. Create a hop from the Add constants step to the Add sequence step. A warning message appears as shown next:
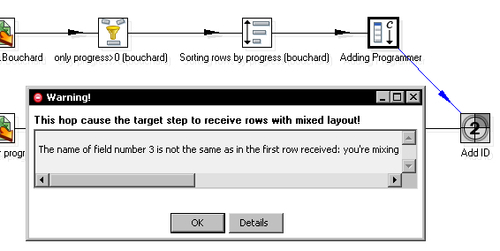
In this case, the third field of the first stream, Programmer (String), does not have the same name or the same type as the third field of the second stream, Progress (Number).
Note
Note that PDI warns you but it doesn't prevent you from mixing row layouts when creating the transformation.
If you want Kettle to prevent you from running transformations with mixed row layouts, you can check the option Enable safe mode in the window that shows up when you dispatch the transformation. Have in mind that doing this will cause a performance drop.
When you use an arbitrary step to unify, the rows remain in the same order as they were in their original stream, but the streams are joined in any order. Take a look at the example's preview. The rows of the Bouchard's stream as well as the rows of the other stream remained sorted within its original group. However, whether the Bouchard's stream appeared before or after the rows of the other stream was just a matter of chance. You didn't decide the order of the streams; PDI decided it for you. If you care about the order in which the union is made, there are some steps that can help you. Here are the options you have:
|
If you want to ... |
You can do this ... |
|---|---|
|
Append two or more streams, and don't care about the order |
Use any step. The selected step will take all the incoming streams in any order, and then will proceed with its specific task. |
|
Append two streams in a given order |
Use the Append streams step from the Flow category. It helps to decide which stream goes first. |
|
Merge two streams ordered by one or more fields |
Use a Sorted Merge step from the Joins category. This step allows you to decide on which field(s) to order the incoming rows before sending them to the destination step(s). The input streams must be sorted on that field(s). |
|
Merge two streams keeping the newest when there are duplicates |
Use a Merge Rows (diff) step from the Joins category. You tell PDI the key fields, that is, the fields that say that a row is the same in both streams. You also give PDI the fields to compare when the row is found in both streams. PDI tries to match rows of both streams, based on the key fields. Then it creates a field that will act as a flag, and fills it as follows:
|
Let's try one of these options.