
Using Joins to Combine Tables
When designing a database, it often makes sense to divide data between two or more tables. For example, if we are maintaining a database of patient records, we would probably want at least four tables: one for the patient’s personal information (such as name and date of birth), a second to keep track of appointments, a third for information about the doctors who are treating the patient, and a fourth for information about the hospitals or clinics those doctors work at.
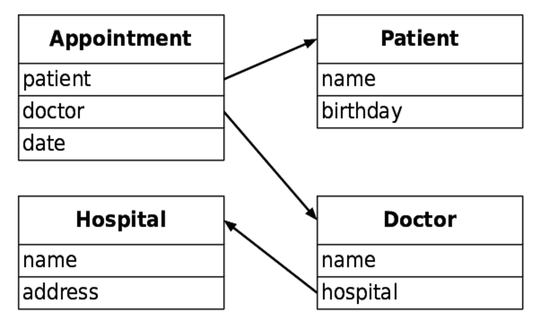
We could store all of this in one table, but then a lot of information would be needlessly duplicated as shown in the image.

If we divide information between tables, though, we need some way to pull that information back together. For example, if we want to know the hospitals at which a patient has had appointments, we need to combine data from all four tables to find out the following:
- Which appointments the patient has had
- Which doctor each appointment was with
- Which hospital/clinic that doctor works at
The right way to do this in a relational database is to use a join. As the name suggests, a join combines information from two or more tables to create a new set of records, each of which can contain some or all of the information in the tables involved.
To begin, let’s add another table that contains the names of countries, the regions that they are in, and their populations:
| | >>> cur.execute('''CREATE TABLE PopByCountry(Region TEXT, Country TEXT, |
| | Population INTEGER)''') |
Then let’s insert data into the new table:
| | >>> cur.execute('''INSERT INTO PopByCountry VALUES("Eastern Asia", "China", |
| | 1285238)''') |
Inserting data one row at a time like this requires a lot of typing. It is simpler to make a list of tuples to be inserted and write a loop that inserts the values from these tuples one by one using the placeholder notation from Creating and Populating:
| | >>> countries = [("Eastern Asia", "DPR Korea", 24056), ("Eastern Asia", |
| | "Hong Kong (China)", 8764), ("Eastern Asia", "Mongolia", 3407), ("Eastern |
| | Asia", "Republic of Korea", 41491), ("Eastern Asia", "Taiwan", 1433), |
| | ("North America", "Bahamas", 368), ("North America", "Canada", 40876), |
| | ("North America", "Greenland", 43), ("North America", "Mexico", 126875), |
| | ("North America", "United States", 493038)] |
| | >>> for c in countries: |
| | ... cur.execute('INSERT INTO PopByCountry VALUES (?, ?, ?)', (c[0], c[1], c[2])) |
| | ... |
| | >>> con.commit() |
Now that we have two tables in our database, we can use joins to combine the information they contain. Several types of joins exist; you’ll learn about inner joins and self-joins.
We’ll begin with inner joins, which involve the following. (Note that the numbers in this list correspond to circled numbers in the following diagram.)
- Constructing the cross product of the tables
- Discarding rows that do not meet the selection criteria
- Selecting columns from the remaining rows

First, all combinations of all rows in the tables are combined, which makes the cross product. Second, the selection criteria specified by WHERE are applied, and rows that don’t match are removed. Finally, the selected columns are kept, and all others are discarded.
In an earlier query, we retrieved the names of regions with projected populations greater than one million. Using an inner join, we can get the names of the countries that are in those regions. The query and its result look like this:
| | >>> cur.execute(''' |
| | SELECT PopByRegion.Region, PopByCountry.Country |
| | FROM PopByRegion INNER JOIN PopByCountry |
| | WHERE (PopByRegion.Region = PopByCountry.Region) |
| | AND (PopByRegion.Population > 1000000) |
| | ''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('Eastern Asia', 'China'), ('Eastern Asia', 'DPR Korea'), |
| | ('Eastern Asia', 'Hong Kong (China)'), ('Eastern Asia', 'Mongolia'), |
| | ('Eastern Asia', 'Republic of Korea'), ('Eastern Asia', 'Taiwan')] |
To understand what this query is doing, we can analyze it in terms of the three steps outlined earlier:
-
Combine every row of PopByRegion with every row of PopByCountry. PopByRegion has 2 columns and 12 rows, while PopByCountry has 3 columns and 11 rows, so this produces a temporary table with 5 columns and 132 rows:
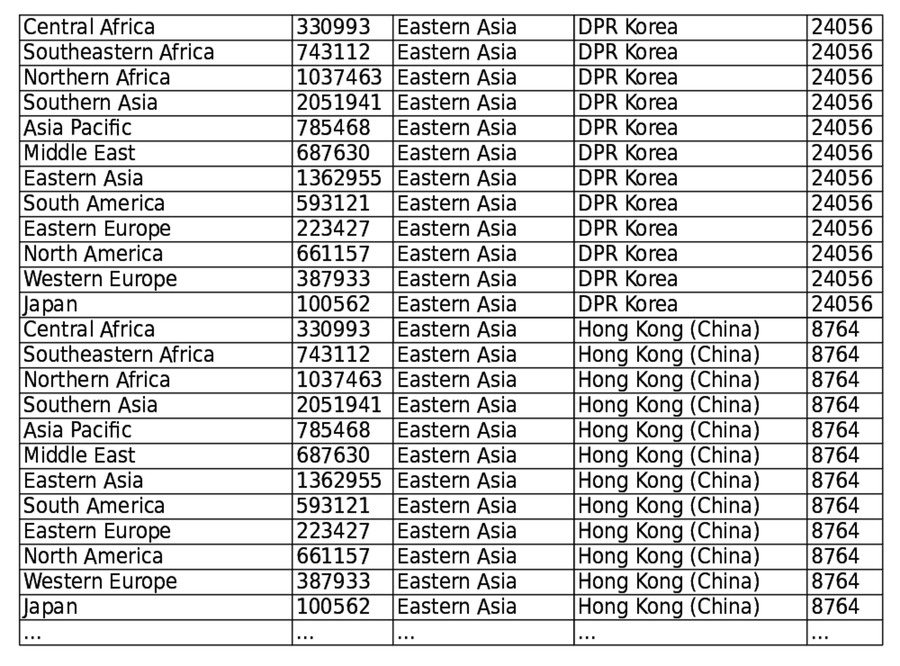
-
Discard rows that do not meet the selection criteria. The join’s WHERE clause specifies two of these: the region taken from PopByRegion must be the same as the region taken from PopByCountry, and the region’s population must be greater than one million. The first criterion ensures that we don’t look at records that combine countries in North America with regional populations in East Asia; the second filters out information about countries in regions whose populations are less than our threshold.
-
Finally, select the region and country names from the rows that have survived.
Removing Duplicates
To find the regions where one country accounts for more than 10 percent of the region’s overall population, we would also need to join the two tables.
| | >>> cur.execute(''' |
| | SELECT PopByRegion.Region |
| | FROM PopByRegion INNER JOIN PopByCountry |
| | WHERE (PopByRegion.Region = PopByCountry.Region) |
| | AND ((PopByCountry.Population * 1.0) / PopByRegion.Population > 0.10)''') |
| | <sqlite3.Cursor object at 0x102e3e490> |
| | >>> cur.fetchall() |
| | [('Eastern Asia',), ('North America',), ('North America',)] |
We use multiplication and division in our WHERE condition to calculate the percentage of the region’s population by country as a floating-point number. The resulting list contains duplicates, since more than one North American country accounts for more than 10 percent of the region’s population. To remove the duplicates, we add the keyword DISTINCT to the query:
| | >>> cur.execute(''' |
| | SELECT DISTINCT PopByRegion.Region |
| | FROM PopByRegion INNER JOIN PopByCountry |
| | WHERE (PopByRegion.Region = PopByCountry.Region) |
| | AND ((PopByCountry.Population * 1.0) / PopByRegion.Population > 0.10)''') |
| | >>> cur.fetchall() |
| | [('Eastern Asia',), ('North America',)] |
Now in the results, ’North America’ appears only once.