
Chapter 11. A Brief Look at Additional RDF Application Environments
The previous chapters have provided a reasonably detailed look at several APIs created in some of the more popular programming languages today: Java, PHP, Python, and Perl. However, as popular as these languages are, they’re not the only ones implementing APIs for processing RDF/XML. There are APIs created in LISP and C, Ruby, Tcl, even .NET-enabled APIs written in C#.
Additionally, some APIs are released as part of a larger framework—APIs connected with a repository or other higher-level functionality. Technically, these frameworks do provide language-based APIs. However, their size and complexity tend to make them a bit much for those looking only for a set of objects to create and/or read an RDF/XML document.
In this chapter, we’ll take a look—briefly, because we want to get into some uses of RDF—at some of the odd-language APIs as well as the more complex frameworks. To start, we’ll look at APIs written in that new kid on the block: C#.
RDF and C#
When Microsoft went to its new .NET architecture, one of the products released with the architecture was the Common Language Runtime (CLR), a programming language platform capable of supporting different programming languages. The first language released was C#, a hybrid between C++ and Java.
Tip
If you’re running Linux, you don’t need .NET to compile C# code; you can also compile the code using the C# compiler provided with Mono, an open source CLR alternative. Download Mono at Ximian’s Mono site, http://www.go-mono.com/.
When I was looking around for application environments that support RDF/XML, I checked for a C# or .NET-based environment, not really expecting to find anything. However, I found more than one product, including an easy-to-install, lightweight C# parser named Drive.
Tip
Drive can be downloaded at http://www.daml.ri.cmu.edu/drive/news.html. According to a news release at the site, the API has been updated to the newest RDF specification.
Drive is a relatively uncomplicated API, providing three major classes:
- Softagents.Drive.RDFEdge
Represents an edge (arc) within an RDF graph. Variables include
m_Sourcenodeandm_Destnode, representing the source and destination node of the arc, respectively.- Softagents.Drive.RDFGraph
Stores and manages the entire graph.
- Softagents.Drive.RDFNode
Represents a node within an RDF graph. Variables include
m_Edges, with all arcs associated with the node. Methods includegetEdges,getIncomingEdges,getOutgoingEdges, and so on.
To work with a graph, first create an instance of RDFGraph, reading in an RDF/XML document. Once
it is read in, you can then query information from the graph, such as
accessing a node with a URI and then querying for the edges related to
that node.
Example 11-1 shows a
small application that pulls the URL for a RDF/XML document from the
command line and then loads this document in a newly created RDFGraph object. Next, the RDFGraph method getNode is called, passing in the URI for the
resource and getting back an RDFNode
object instantiated to that object. The getEdges method is called on the node
returning an ArrayList of RDFEdge objects. The URI and local name
properties for each of the edges are accessed and then printed out to
the console. Finally, at the end, another RDFGraph method, PrintNTriples, is called to print out all of
the N-Triples from the model.
/*****************************************************************************
* PracticalRDF
******************************************************************************/
using System;
using Softagents.Drive;
using System.Collections;
namespace PracticalRDF
{
/// PracticalRDF
///
public class PracticalRDF
{
[STAThread]
static void Main(string[] args)
{
string[] arrNodes;
// check argument count
if(args.Length <1)
{
Console.WriteLine("Usage:Practical <inputfile.rdf>");
return;
}
//read in RDF/XML document
RDFGraph rg = new RDFGraph( );
rg.BuildRDFGraph(args[0]);
// find specific node
RDFNode rNode = rg.GetNode("http://burningbird.net/articles/monsters1.htm");
System.Collections.ArrayList arrEdges = rNode.GetEdges( );
// access edges and print
foreach (RDFEdge rEdge in arrEdges) {
Console.WriteLine(rEdge.m_lpszNameSpace + rEdge.m_lpszEdgeLocalName);
}
// dump all N-Triples
Console.WriteLine("
N Triples
");
rg.PrintNTriples( );
}
}
}After compilation, the application is executed, passing in the name of the RDF/XML document:
PracticalRDF http://burningbird.net/articles/monsters1.rdf
The parser does return warnings about a possible redefinition of a node ID for each of the major resources, but this doesn’t impact on the process:
Warning: Possible redefinition of Node ID=http://burningbird.net/articles/monsters1. htm! Ignoring. Warning: Possible redefinition of Node ID=http://burningbird.net/articles/monsters2. htm! Ignoring. Warning: Possible redefinition of Node ID=http://burningbird.net/articles/monsters3. htm! Ignoring. Warning: Possible redefinition of Node ID=http://burningbird.net/articles/monsters4. htm! Ignoring. Warning: Possible redefinition of Node ID=http://www.yasd.com/dynaearth/monsters1. htm! Ignoring. Warning: Possible redefinition of Node ID=http://www.dynamicearth.com/articles/ monsters1.htm! Ignoring.
All of the predicates directly attached to the top-level node within the document are found and returned:
http://burningbird.net/postcon/elements/1.0/relevancy http://burningbird.net/postcon/elements/1.0/history http://burningbird.net/postcon/elements/1.0/bio http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://burningbird.net/postcon/elements/1.0/related http://burningbird.net/postcon/elements/1.0/related http://burningbird.net/postcon/elements/1.0/related http://burningbird.net/postcon/elements/1.0/presentation
Drive cannot handle query-like processing of the data, using an RDQL language. However, there are methods for adding edges to a node and nodes to a graph if you’re interested in building an RDF graph from scratch or modifying an existing one.
Wilbur — RDF API CLOS
It’s been many years since I used LISP, but I wasn’t surprised to find at least one RDF implementation based on it: Wilbur, written none by none other than the legendary Ora Lassila, coeditor of the original RDF Model & Syntax Specification and the person whose name appears in many RDF/XML tutorials.
Tip
Wilbur is Nokia’s RDF Toolkit for CLOS. Documentation and source can be downloaded from the SourceForge location at http://wilbur-rdf.sourceforge.net/docs/.
Wilbur has parsers capable of working with RDF, DAML (an ontology language discussed in more detail in Chapter 12), and straight XML, with the addition of an RDF API, in addition to an HTTP client and frame system built on RDF and DAML+OIL.
The APIs supported by Wilbur are documented online, but there are no examples or screenshots. There may be examples and additional documentation within Wilbur; however, since I didn’t have support for CLOS, I couldn’t try out the applications or the development tool. However, I wanted to include a reference to it for the sake of comprehensive coverage of language support for RDF.
Overview of Redland—a Multilanguage-Based RDF Framework
Though the majority of RDF/XML APIs are based on Perl, Python, Java, and PHP, several are in other language-based APIs, including ones in C# and CLOS, as discussed in the last section. For instance, if you’re interested in working with Tcl, XOTcl — based on MIT’s OTcl — has RDF/XML-processing capability (http://media.wu-wien.ac.at/). Additionally, Dan Brickley has created an experimental RDF system written in Ruby called RubyRDF (at http://www.w3.org/2001/12/rubyrdf/intro.html). And if you’re interested in a system that supports Tcl as well as Ruby, and Perl, and Python, and Java, and so on, then you’ll want to check out Redland.
One of the older applications supporting RDF and RDF/XML, and one consistently updated to match effort in the RDF specification is Redland—a multilanguage API and data management toolkit. Unlike most of the other APIs discussed in this book, Redland has a core of functionality exposed through the programming language C, functionality that is then wrapped in several other programming languages including Python, Perl, PHP, Java, Ruby, and Tcl. This API capability is then mapped to a scalable architecture supporting data persistence and query.
Because of its use of C, Redland is port and platform dependent; it has been successfully tested in the Linux, BSD, and Mac OS X environments. At the time of this writing, Version 0.9.12 of Redland was released and installed cleanly on my Mac OS X. When writing this section, I tested the C objects, as well as the Python and Perl APIs, the most stable language wrappers in Redland.
Tip
The main Redland web site is at http://www.redland.opensource.ac.uk/. The RDF/XML parser used by Redland, Raptor, can be downloaded and used separately from the framework. Redland is licensed under LGPL and MPL licenses.
Working with the Online Tools
To quickly jump into Redland and its capabilities, there are online demonstrations of several aspects of the framework and its component tools. One online tool is an RSS Validator, which validates any RSS 1.0 (RDF/RSS) file. RSS is described in detail in Chapter 13, but for now, I’ll use the validator to validate an RDF/XML file built from several other combined RSS files. Figure 11-1 shows the results of running the RSS Validator against the file.
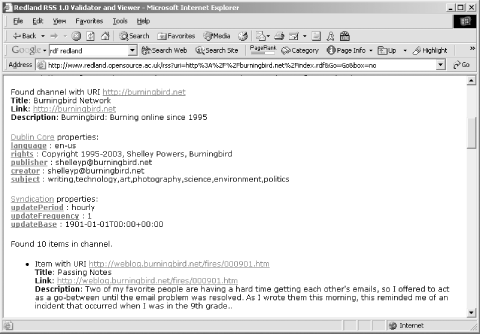
Another validator is an N-Triples Validator, which makes a nice change from RDF/XML validators. There’s also a parser test page, as well as an online database that you can actually manipulate as you test Redland’s capabilities with a persistent store. I created a new database called shelley and loaded in my test RDF/XML file, monsters1.rdf. I could then query the data using Redland’s query triple or by printing out the data and clicking on any one of the triples to access it. The latter is particularly useful because the query that would return the statement is generated and printed out, giving you a model to use for future queries.
As an example of a triple query in Redland, the following
returns all statements that match on the PostCon reason predicate:
?--[http://burningbird.net/postcon/elements/1.0/reason]-->?
The format for the triple pattern is:
[subject]--[predicate]-->[object]
for resource objects and the following for strings:
[subject]--[predicate]-->"object"
Use the question mark to denote that the application is supposed to match on any data within that triple component.
Working with the Redland Framework
The Redland site contains documentation for the core C
API, as well as the primary wrappers: Perl, Python, and Java. The API
Reference covers the C API, and each wrapper has a separate page with
information specific to that wrapper language. For instance, if you
access the Perl page, you’ll find a table of application objects; next
to each object is a link to the documentation page for the core
Redland function (written in C), such as librdf_node, and next to that is a link to
the associated language class.
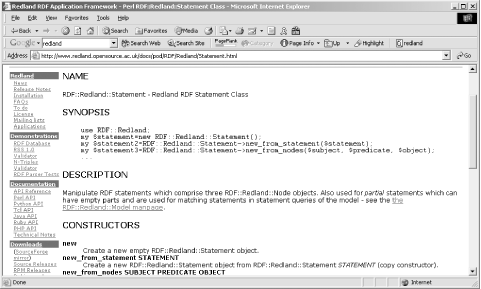
Clicking on the C version of the object opens a page with a listing of all the functions that class supports. Clicking on any of those opens a page that describes how the function works and the parameters it accepts. Clicking on the language wrapper object provides a page of documentation about the object, formatted in a manner similar to other documentation for that language. For instance, Figure 11-2 shows the documentation page for the Perl Statement object, including the traditional Synopsis.
However, the Python documentation was a real eye-opener, following a traditional Python documentation approach (pydoc) as shown in Figure 11-3.
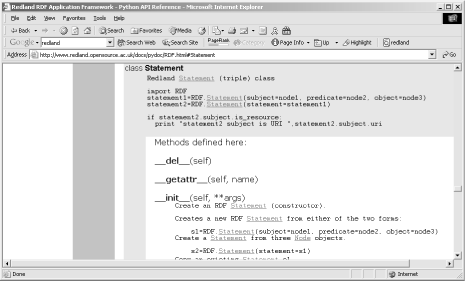
Normally I wouldn’t spend space in a book showing documentation, but I was intrigued by Redland’s use of language-specific documentation style to document different wrappers. In addition to the style, though, the documentation demonstrates how the object is used in an application, which is critical for learning how to use the API correctly.
Redland has persistent database support through the Berkeley DB, if you have access to it, or you can use the memory model. You specify which storage mechanism to use when you create the storage for the RDF model you’re working with. In addition, you can also specify what parser you want to use, choosing from several, including Raptor, the parser that comes with Redland, which you can use independent of Redland. Other parsers you can use are SiRPAC, Repat, RDFStore, and so on.
To use Redland, program your application using the native API or whichever of the wrappers you’re comfortable in, compile it, and run it, in a manner similar to those shown in Chapter 10. The main difference is that the language wrappers are wrappers—behind the scenes, they invoke the functionality through the native API classes. Table 11-1 shows the main Redland classes, focusing on two languages I’m most comfortable with, Perl and Python, in addition to the native API.
Native C API class | Perl class | Python class | Description |
| | | Set of statements (triples) comprising a unique model |
| | | Storage for the model (persistent or memory) |
| | | One complete triple |
| | | RDFnode (resource or literal) |
| | | Parses serialized RDF/XML into either a stream or a model |
| | | Contains stream of RDF statements |
| | | Serializes the model using a specific mime type such as “ntriples” or “rdfxml” |
| | | Supports iteration of nodes from a query |
| | | Generates URIs |
| | Wrapper class to start and stop Redland environment |
There are other classes in each wrapper, but the ones shown in Table 11-1 are the ones of primary interest.
A Quick Demo
I created two small applications, one in Perl, one in Python, to demonstrate the interchangeability of languages within the Redland framework.
The Perl application, shown in Example 11-2, creates a new
Berkeley DB datastore and attaches it to a model. The application then
adds a statement, opens the example RDF/XML document located on the
filesystem, and parses it into the model using the Redland parser
method parse_as_stream. Once
loaded, it serializes the model to disk as a test and then flushes the
storage to disk.
!/usr/bin/perl
#
use RDF::Redland;
# create storage and model
my $storage=new RDF::Redland::Storage("hashes", "practrdf",
"new='yes',hash-type='bdb',dir='/Users/shelleyp'");
die "Failed to create RDF::Redland::Storage
" unless $storage;
my $model=new RDF::Redland::Model($storage, "");
die "Failed to create RDF::Redland::Model for storage
" unless $model;
# add new statement to model
my $statement=RDF::Redland::Statement->new_from_nodes(RDF::Redland::Node->new_from_uri_
string("http://burningbird.net/articles/monsters1.htm"),
RDF::Redland::Node->new_from_uri_
string("http://burningbird.net/postcon/elements/1.0/relatedTo"),
RDF::Redland::Node->new_from_uri_
string("http://burningbird.net/articles/monsters5.htm"));
die "Failed to create RDF::Redland::Statement
" unless $statement;
$model->add_statement($statement);
$statement=undef;
# open file for parsing
# RDF/XML parser using Raptor
my $uri=new RDF::Redland::URI("file:monsters1.rdf");
my $base=new RDF::Redland::URI("http://burningbird.net/articles/");
my $parser=new RDF::Redland::Parser("raptor", "application/rdf+xml");
die "Failed to find parser
" if !$parser;
# parse file
$stream=$parser->parse_as_stream($uri,$base);
my $count=0;
while(!$stream->end) {
$model->add_statement($stream->current);
$count++;
$stream->next;
}
$stream=undef;
# serialize as rdf/xml
my $serializer=new RDF::Redland::Serializer("rdfxml");
die "Failed to find serializer
" if !$serializer;
$serializer->serialize_model_to_file("prac-out.rdf", $base, $model);
$serializer=undef;
warn "
Done
";
# force flush of storage to disk
$storage=undef;
$model=undef;Once the data is stored in the database from the first
application, the second application opens this store and looks for all
statements with dc:subject as
predicate. Once they are found, the application prints these
statements out. When finished, it serializes the entire model to a
stream, and then prints out each statement in the stream, as shown in
Example 11-3.
import RDF
storage=RDF.Storage(storage_name="hashes",
name="practrdf",
options_string="hash-type='bdb',dir='/Users/shelleyp'")
if not storage:
raise "new RDF.Storage failed"
model=RDF.Model(storage)
if not model:
raise "new RDF.model failed"
# find statement
print "Printing all matching statements"
statement=RDF.Statement(subject=None,
predicate=RDF.Node(uri_string="http://purl.org/dc/elements/1.1/subject"),
object=None)
stream=model.find_statements(statement);
# print results
while not stream.end( ):
print "found statement:",stream.current( )
stream.next( );
# print out all statements
print "Printing all statements"
stream=model.serialise( )
while not stream.end( ):
print "Statement:",stream.current( )
stream.next( )When the first application is run, the new database is created. However, the second application just opens the persisted datastore created by the first Perl application.
Warning
Example 11-3 reads the RDF/XML document in from the local filesystem rather than remotely via the URL. In the OS 10.2.4 environment, the examples were tested in; trying to read a file remotely did result in a Bus error.
Redfoot
Redfoot is another multicomponent application. If you reviewed Section 9.3, you saw one of the components — an RDF parser and API written in Python called RDFLib — in use. In addition to RDFLib, Redfoot also provides a lightweight HTTP server in addition to a scriptlike language the creator of Redfoot calls Hypercode.
Tip
Information and the source code for Redfoot can be found at http://redfoot.net. Download RDFLib separately at http://rdflib.net. Check the documentation to review the requirements for Redfoot, first, before installing
Redfoot has an HTTP listener that by default listens in on port 80, so if you have another web server running, you may want to shut it off, first. When running locally, access the RDFLib page through http://localhost.
After Redfoot is running, you can administer Redfoot by setting the document root, managing contexts, or editing a weblog (Redfoot also provides a basic weblogging tool). Document root controls where all persisting information is stored. The framework supports multiple RDF/XML models — the contexts of the tools. Redfoot has several included with the default installation. You can also add additional ones, as I did with the example file at http://burningbird.net/articles/monsters1.rdf. I added the file by specifying its URL within the Add Contexts admin page. From this same admin page, you can also add weblog entries into a weblog; however, the weblog editing features of Redfoot are fairly basic compared to other specialized weblogging tools.
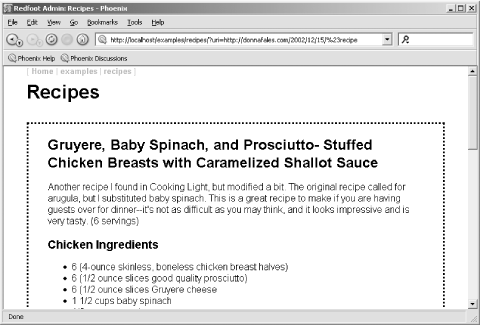
From the main admin page you can access several examples, including an RDF Navigator that seems to allow you to build an RDF model, search on it, and so on. It’s difficult to tell exactly how to use the application, though, because there’s no documentation for it. The Recipes and the FOAF application, though, are intuitively easy to use. Figure 11-4 shows a page from the Recipes application.
As stated earlier, Redfoot uses its own scripting language it calls Hypercode. Hypercode is Python that’s embedded within a CDATA block in an RDF/XML document that contains information about how to initialize the data. For instance, Example 11-4, from the application’s Hello World example, reports back “Hello World” to the browser.
<rdf:Description rdf:about="http://localhost:8080/">
<rdfs:label>Hello World</rdfs:label>
<red:facet>
<red:Facet>
<rdfs:label>Hello World Facet</rdfs:label>
<red:outer rdf:resource="http://redfoot.net/2002/11/09/redsite#outer"/>
<red:code>
<red:Python>
<rdfs:label>Redsite Outer page</rdfs:label>
<red:codestr>
<![CDATA[
response.write("""
<p>Hello World!</p>
""")
]]>
</red:codestr>
</red:Python>
</red:code>
</red:Facet>
</red:facet>
</rdf:Description>
</rdf:RDF>In this example, information about the code is defined using RDF/XML and then implemented within the Python block. Interesting, but again the documentation is quite sparse. Redfoot is an application you’ll want to check out only if you like to explore, feel comfortable with minimum documentation, and have a great fondness for Python.