
CHAPTER 3
QUANTITATIVE TEXT SUMMARIES
There are a number of text mining techniques, many of which require counts of text patterns as their starting point. The last chapter introduces regular expressions, a methodology to describe patterns, and this chapter shows how to count the matches.
As noted in section 2.6, literary texts consist of tokens, most of which are words. One useful task is counting up the number of times each distinct token appears, that is, finding the frequency of types. For example, sentence 3.1 has five tokens but only four types because the word the appears twice, while the rest appear only once.
(3.1) The cat ate the bird.
Although counting four types at once is not hard, it requires deeper knowledge of Perl to count thousands of patterns simultaneously. We begin this chapter by learning enough Perl to do this.
3.2 SCALARS, INTERPOLATION, AND CONTEXT IN PERL
We have already encountered scalar variables, which start with a dollar sign and store exactly one value. Several examples are given in code sample 3.1, which also contrasts the usage of single and double quotes for strings. First, notice that $a and $b have the same value because it does not matter which type of quote marks are used to specify a specific string. However, $g and $h are different because when $a is in double quotes, it is replaced by its value, but this is not true with single quotes. This is another example of interpolation (see the discussion near code sample 2.2).
Code Sample 3.1 Ten examples of scalar variables. Each has only one value, either a number or a string.
$a = ‘Text’; |
$b = "Text"; |
$c 7; |
$d = 7.00; |
$e = "7"; |
$f = ""; |
$g = “$a”; |
$h = "$a"; |
$i = $e + 5; |
$j = "twenty" . $c; |
print "$a, $b, $c, $d, $e, $f, $g, $h, $i, $j"; |
Output 3.1 Output of code sample 3.1.
Text, Text, 7, 7, 7, , $a, Text, 12, twenty7 |
Second, $c, $d, $e all print out the value 7. Ifthe two zeros after the decimal point are desired (for instance, if $d represents a dollar amount), there is a formatted print statement, printf, to do this. For an example, see problem 2.6.
Third, the string "7" acts like a number when it is added to 5 to compute $i. That is, Perl converts the string "7" to the number 7, and then adds these together to get 12. In general, Perl tries to determine what context is appropriate for any operation, and addition implies a numerical context. For a programmer used to declaring all variables before using them, this allows some unusual programming techniques. Here is another example using the period, which stands for string concatenation. When computing $j, Perl pastes the string twenty with $c, expecting the latter is a string. However, $c is a number, but it is in a string context, hence Perl converts it into one, and the final result is twenty7. Perl recognizes other contexts, for example, strings and numbers can be used as logical truth values as discussed in section 2.7.2 (see table 2.8). In the next section we discuss scalar and array contexts.
Finally, we have already seen in section 2.3.3 that when using split to break text into words, it is natural to store the results in an array because prior knowledge of the number of words is not needed. Arrays are useful in other ways, and the next section begins our study of them.
3.3 ARRAYS AND CONTEXT IN PERL
Arrays can be defined by putting values inside parentheses, which is called a list. This explicitly shows its values, for example, ("The", "Black", "Cat"). Looking at code sample 3.2, an array can have both numbers and strings as entries. Finally, note that the two print statements produce exactly the same text: both give the array entries in the same order.
Code Sample 3.2 Example of initializing an array. Note that both numbers and strings can be used in one array.
@array = ("the", 220, "of", 149); |
print "$array [0] $array [1] $array [−2] $array [−1] "; |
print "@array "; |
Array numbering starts at 0, so that $array [1] is the second value in the list. Negative values start at the end of the array, so $array [−1] is the last entry, and $array [−2] is the next to last entry, and so forth. All scalars in Perl start with the dollar sign, so the entries of @array all start with a dollar sign, for example, $array [0].
An array is also interpolated in a string if double quotes are used, and the default is to separate its entries with a space. However, the separator is the value of the Perl variable $". For instance, the following code prints out the entries of @array with commas.
$" = ‘,’; print "@array";
It is valid syntax to use print @array; but then the entries are printed without any separator at all. So the following two commands print 1234567, which does not allow a person to determine what the entries of this array are. Consequently, interpolation of an array by putting it into double quotes is usually what a programmer wants.
@array = (1, 2, 34, 56, 7); print @array;
Just as there are string and number contexts, there are also scalar and array contexts. This allows various shortcuts, but it can lead to unexpected results for the unwary. For example, code sample 3.3 shows examples of assigning arrays to scalars and vice versa. Try to guess what each print statement produces before reading on.
Code Sample 3.3 An example of scalar and array contexts.
$scalarl = ("Damning", "with", "faint", "praise"); |
@array1 = ("Damning", "with", "faint", "praise"); |
$scalar2 = @array1; |
@array2 = $scalarl; |
print "$scalarl, $scalar2, @array1, @array2"; |
The two scalar values are hard to guess unless one is familiar with Perl. First, $scalar is assigned the last element of a list of values. But if an array is assigned to a scalar, then the scalar context is in force. In this case, Perl assigns the length of the array to the scalar. Hence, $scalarl has the string "praise", but $scalar2 has the number 4. Thinking that $scalarl and $scalar2 both have the same value is reasonable, but it is not what Perl does. When trying to find errors in a program, knowing these sort of details prevents frustration.
Setting an array equal to a scalar forces the latter into an array context. The result, however, is not surprising. The array that is created has only one element, which is equal to the scalar. Hence @array2 has just the value of $scalarl.
When defining an array using a list of values, these can include variables, or even other arrays. Entries of an array are accessed by using an index in square brackets, and portions of an array are accessed by giving ranges of values. One shortcut for consecutive indices is the range operator, which is formed by two periods in a row. For example, (1. .5) produces an array with the numbers 1 through 5. This also works for strings: (‘a’. . ‘e’) produces an array with the letters a through e. If one array has indices in it, say @indices, then @array [@indices] consists of exactly the elements of @array with the indices of @indices. Examples are given in code sample 3.4.
Code Sample 3.4 Examples of making new arrays from parts of an existing array.
@array1 = ("Tip", "of", "the", "iceberg"); |
@array2 = ("Time", "is", "of", "the", "essence"); |
$scalar = "not"; |
@indices = (0. .2); |
@array3 = @array1 [@indices]; |
@array4 = @array1[0,1,2]; |
@array5 = @array1[0..2]; |
@array6 = @array1 [(0. .2)]; |
@array7 = (@array1, @array2); |
@array8 = (@array2[0..1], $scalar, @array2[2..4]); |
print "@array3 @array4 @array5 @array6 @array7 @array8 "; |
This produces output 3.2. Note that @array3, @array4, @array5, @array6 are exactly the same. In addition, Perl flattens arrays, that is, constructing an array by including arrays (as done for @array7) still produces a one-dimensional array. Note that the print statement has arrays separated by newline characters, which makes the output easier to read.
Output 3.2 Output of code sample 3.4.
Tip of the |
Tip of the |
Tip of the |
Tip of the |
Tip of the iceberg Time is of the essence |
Time is not of the essence |
Keeping in mind that Perl is context driven, try to guess what code sample 3.5 prints out before reading further.
Perl does not treat an array like a vector, so the results are not what a mathematician expects. Since $xl is a scalar, @vector1 is in scalar context, which means its value (in this context) is the length of the array, which is 6. Therefore Perl multiplies 6 by 2 to get 12. Of course, $x2, $x3 and $x4 are also scalars, so all the arrays on the right-hand side are converted to lengths. Hence, $x2 equals 11, and $x3 is set to 30. Finally, $x4 forces the right hand side into scalar context, and the period, which is the string concatenation operator, interprets the lengths of the arrays as strings. The result is the concatenation of “6” and “5”, which produces “65”.
Code Sample 3.5 Examples of scalar context.
@vector1 = (1, 1, 2, 3, 5, 8); |
@vector2 = (1, 3, 4, 7, 11); |
$xl = @vector1 * 2; |
$x2 = @vector1 + @vector2; |
$x3 = @vector1 * @vector2; |
$x4 = @vector1 . @vector2; |
print "$xl, $x2, $x3, $x4"; |
Lists can be used to create new arrays, and there is one rule to keep in mind: assignment takes place from left to right. This is illustrated in the examples of code sample 3.6.
Code Sample 3.6 Examples of assigning arrays to lists and scalars.
@array = (‘a’.. ‘g’); |
($first) = @array; |
print "$first
"; |
($first, $second, @crest) = @array; |
print "$first, $second, @rest
"; |
($first, $second) = ($second, $first); |
print "$first, $second
"; |
$first = @array; |
print "$first "; |
The first line in output 3.3 is the first element of @array, which is an example of assignment going from left to right. With this rule in mind, the output of the second print statement is no surprise. These assignments are done as if in parallel, so the third print statement reveals that the values previously in $first and $second have been switched. Finally, ($first) is an array, while $first is a scalar. Consequently, the last print statement shows that the length of the array is stored in $first, which differs from the first print statement.
Output 3.3 Output of code sample 3.6.
a |
a, b, c d e f g |
b, a |
7 |
Before moving to the next section, a word of caution. Perl allows the programmer to use the same name for both a scalar and an array. That is, it is valid to use both $name and @name, and these are treated as unrelated variables. However, doing this is confusing, so it is not recommended.
3.4 WORD LENGTHS IN POE’S “THE TELL-TALE HEART”
Instead of learning more Perl syntax in this section, we analyze the word lengths of a text. To do this, we split the text into words, find their lengths, and tally these. Since arrays use numerical indices and these lengths are numbers, using an array to store the tallies is straightforward.
The goal of section 2.4 is to write a program that extracts words from “The Tell-Tale Heart” [94]. This culminates in program 2.6, which is the starting point for the counting task at hand. A length of a string is easily obtained by the function length. So consider code sample 3.7, which is described below.
Code Sample 3.7 A program to tally the lengths of words in “A Tell-Tale Heart.”

The overall structure is simple. The first while loop goes through the “The Tell-Tale Heart” line by line, removes the punctuation marks, and breaks each line into words. The heart of the first while loop is the regular expression. Its parentheses store each word in $1. The length function computes the length of each word, which becomes the index of the array called @count, and $count [length($1)] is incremented by 1. The entries of this array are set to the empty string by default, but this is converted to 0 when addition is attempted, which is a case of a numeric context.
The second while loop prints out the number of times each word length appears. The variable $#count gives the largest index of @count, which is the upper limit of the variable $i. Finally, the print statement produces the final tallies, as shown in output 3.4. Note that the first line does not give a value for the number of words of length 0. This happens because $count [0] is never incremented, so that its value remains the empty string. Not printing a number, however, is not as clear as printing out a zero. There is an easy solution to this: before printing out the value of $count [$i], add zero to it. This does not change any of the numerical values, and it converts the empty string to zero, as desired.
Output 3.4 Output of code sample 3.7.
There are words of length 0 |
There are 168 words of length 1 |
There are 335 words of length 2 |
There are 544 words of length 3 |
There are 408 words of length 4 |
There are 231 words of length 5 |
There are 167 words of length 6 |
There are 137 words of length 7 |
There are 69 words of length 8 |
There are 45 words of length 9 |
There are 23 words of length 10 |
There are 9 words of length 11 |
There are 6 words of length 12 |
There are 1 words of length 13 |
There are 3 words of length 14 |
In fact, besides adding zero to $count [$i], there are other ways to improve this code. First, counting something is a common task in programming, so there is a shorter way to do this than using +=1. The operator ++ placed before a variable does the same thing. Similarly, the operator -- placed before a variable decreases it by 1. These operators can also be placed after a variable, but they work slightly differently when this is done. Consult Day 3 of Lemay’s Perl in 21 Days [71] for an explanation of this technical point.
Second, this program only works for the short story “The Tell-Tale Heart.” As discussed in section 2.5.1, inputting information from the command line is easy. Instead of placing the filename in the open statement, the Perl variable $ARGV [0] can be used instead. If the name of the program were word_lengths.p1, then the command line looks like the following. Note that the quotes are required because this filename has blanks in it.
perl word_lengths.pl "The Tell-Tale Heart.txt"
Third, although the second while loop works fine, it isreplaceable by a for loop, which is more compact. The while statement is used when the number of iterations is not known prior to running the code, but a for statement is often used when it is known. In this case, the number of iterations is unknown beforehand because it depends on the length of the longest word in the text, but it is stored in the Perl variable $#count, so a for loop makes sense.
The for loop requires an initial value for a variable, a logical test of an ending condition, and a way to change the value of this variable. For example, consider the following line of code.
for ($i = 0 $i <= $#count; ++$i) { # commands }
This for loop is equivalent to the while loop in code sample 3.7. The while loop initializes $i before the loop and changes $i inside the loop, but the for loop does all this in one place. Making these four changes in code sample 3.7 produces program 3.1. This revised version is more general and prints out 0 if there is no instances for a specific word length.
Program 3.1 A refined version of code sample 3.7.

Finally, the print statement is a function that can have multiple arguments, all of which are printed. In program 3.1 these are separated by commas.
The output of program 3.1 is exactly the same as output 3.4 except for one item. The first line has a zero, not an empty string. With this application finished, the next section discusses functions that use arrays for either input or output.
In section 2.3.3 the functions split and join are introduced. The former breaks a string into the pieces that are between the matches of a regex, which form an array. The join function reverses this process: it takes an array and glues its entries to form a string. For a simple example, see code sample 2.7. Both of these commands involve arrays, and this section introduces more such functions.
3.5.1 Adding and Removing Entries from Arrays
An array is a one-dimensional list of entries indexed by nonnegative integers. It is possible to modify an array by adding or removing entries from either the right or left end of it. Perl has functions to do each combination of these modifications, which we now consider.
First, an array can be lengthened by appending an entry on the right. For example, code sample 3.8 adds the word Cat after the last entry of @title, so that the print statements produces The Black Cat.
Code Sample 3.8 The function push adds the word Cat to the end of @title.
@title = ("The", "Black"); |
push(@title, "Cat"); |
print "@title"; |
Note that push modifies its array argument, @title. Also notice that declaring arrays beforehand is not required. When elements are added to an array, Perl knows it must be lengthened. Finally, the first argument of push must be an array: using a list instead produces an error.
The function push can create an array from scratch. For example, suppose an array of square numbers (called squares) is desired. Recalling that a square equals an integer multiplied by itself, we can use push inside a for loop to create it, and this is done in code sample 3.9. The results are shown in output 3.5. Since the for loop makes $i go from 1 through 10, @squares contains the first 10 squares from lowest to highest.
Code Sample 3.9 This program creates an array containing the first 10 squares by using push.
@squares = 0; |
for ($i = 1; $i <= 10; ++$i) { |
push(@squares, $i**2) |
print "@squares" |
Output 3.5 Output of code sample 3.9.
1 4 9 16 25 36 49 64 81 100 |
Second, the left end of an array can be added to by using unshift. For example, the following commands change @title to ("The", "Black", "Cat").
title = ("Black", "Cat"); unshift(@title, "The");
As with push, unshift can be used to create arrays. For example, code sample 3.10 replaces push in code sample 3.9 by unshift. This change still produces the first 10 square numbers, but in reverse order because the numbers are now added on the left, which is shown in output 3.6.
Third, instead of adding to an array, removal of entries is possible. To remove the last (rightmost) element of an array. use pop (@array). To remove the first (leftmost) element, use shift (@array).
As a final example of these four functions, consider the operation of taking the last element of an array and making it the first. This can be done by using pop followed by unshift. Similarly, taking the first element and making it the last can be done by using shift followed by push. These types of operations are sometimes called rotations or cyclic permutations. See code sample 3.11 for an example of rotating an array. The first line of output 3.7 shows that the last three letters of the alphabet have been moved to the beginning, and the second line shows that the first three letters have been moved to the end. In both cases, three letters have been rotated, though in opposite directions.
Code Sample 3.10 This program creates an array with the first 10 squares in reverse order by using unshift.
@squares = (); |
for ($i = 1; $i <= 10; ++$i) { |
unshift(@squares, $i**2); |
print "@squares"; |
Output 3.6 Output of code sample 3.10
100 81 64 49 36 25 16 9 4 1 |
Code Sample 3.11 Example of using pop and unshift as well as push and shift to rotate the alphabet by three letters.
# Rotating the alphabet by three letters |
@letters = (‘A’. .‘Z’); |
for ($i = 1; $i <= 3; ++$i) { |
unshift(@letters, pop(@letters)); |
} |
print @letters, " "; |
# Rotating the alphabet in the opposite direction |
@letters = (‘A’. .‘Z’); |
for ($i = 1; $i <= 3; ++$i) { |
push(@letters, shift(@letters)); |
} |
print @letters; |
Output 3.7 Output of code sample 3.11.
XYZABCDEFGHIJKLMNOPQRSTUVW |
DEFGHIJKLMNOPQRSTUVWXYZABC |
In this section, functions that manipulate arrays one entry at a time are discussed. Sometimes subsets of an array are desired, and Perl has a function called grep that can select entries that match a given regular expression. Chapter 2 shows the utility of regexes, so this function is powerful, as seen in the next section.
3.5.2 Selecting Subsets of an Array
The syntax for grep is given below. It selects entries of a matrix that match a regex and is based on a utility of the same name.
grep(/$regex/, @array);
Recalling code sample 2.28, which uses a regex to check for double letters in a word, we create code sample 3.12. It also uses the qr// construction, which is demonstrated in code sample 2.31. For this task the regex can be placed in grep directly, but using qr// can speed up the code (the regex is precompiled), and this technique allows the programmer to build up complex patterns. Finally, note that $regex must be inside forward slashes, as shown in this code. When run, only the word letters is printed out.
Code Sample 3.12 Example of using grep to select a subset of an array.
@words = qw(A test for double letters); |
$regex = qr/(w)1/ |
@double = grep(/$regex/, @words); |
print "@double"; |
The next section discusses how to sort an array. Perl has built-in functions to sort strings in alphabetical order and numbers in numerical order, but the function sort is able to use programmer-defined orders, too.
3.5.3 Sorting an Array
Not surprisingly, the Perl function sort does sorting. However, this function does have some surprising results, one of which is shown by code sample 3.13.
Code Sample 3.13 Two examples of sorting the entries of an array.
$data = "Four score and seven years ago"; |
@words = split(/ /, $data); # Break the phrase into words |
@sorted_words = sort(@words); # Sort the words |
print "@sorted_words "; |
@numbers = (1, 8, 11, 18, 88, 111, 118, 181, 188); |
@sorted_numbers = sort(@numbers); # Sort the numbers |
print "@sorted_numbers"; |
It seems obvious what the output should be for these two arrays when they are sorted. Unfortunately, the results in output 3.8 are unexpected.
Both arrays have been sorted using the order given by the American Standard Code for Information Interchange (ASCII) standard, where the numbers 0 through 9 precede the uppercase letters A through Z, which precede the lowercase letters a through z. These three ranges of characters are not contiguous in ASCII, but the others that come between are not present in these arrays, so they do not matter here. Hence Four precedes ago because the former word is capitalized, which precedes lowercase.
Output 3.8 Output of code sample 3.13.
Four ago and score seven years |
1 11 111 118 18 181 188 8 88 |
Moreover, dictionary order is used both for the words and the numbers. For example, even though both start with the same three letters, bee precedes beech. This is equivalent to adding spaces at the end of the shorter word and declaring that a space precedes all the alphanumeric characters (which is true for ASCII). Hence 1 comes before 11, which comes before 111. And 118 precedes 18 since both start with 1, but for the second character, 1 precedes 8.
Since numbers are usually sorted by numerical value, the default used by sort is typically not appropriate with them. It turns out, fortunately, that it is easy to make sort use other orders.
The general form of sort is as follows.
sort { code } @array;
Here code must use the arguments $a and $b, and it must return a numerical value. A positive value means $a comes after $b, and a negative value means $a comes before $b. Finally, 0 means that $a and $b are equivalent. This function is often <=> or cmp, which is discussed below, but it is possible to use an explicit block of code or a user-defined function. Creating the latter requires the use of subroutines, which is discussed in section 5.3.2.1. In this section, we focus on the first two methods and only give a short example of the third method in code sample 3.20.
The default of sort is cmp, which uses the dictionary order. It returns one of three values: −1, 0, and 1, and these have the effect described in the previous paragraph. Hence code sample 3.14 reproduces output 3.8.
Code Sample 3.14 This example is equivalent to the default use of sort in code sample 3.13.
$data = "Four score and seven years ago"; |
@words = split(/ /, $data); |
@sortes_words = sort { $a cmp $b } @words; |
print "@sorted_words"; |
Even with cmp, it is still the case that the word Four is put first because its first letter is in uppercase. But this is easy to fix by applying the function 1c to $a and $b, so that all strings are changed into lowercase when compared. One can also use uc, which transforms text into uppercase, because the key is to have all text in the same case. Changing code sample 3.14 this way produces code sample 3.15.
Output 3.9 now shows the desired results. Note that @sorted_words contains the sorted words, but that the entries of @words are unchanged. Unlike pop or shift, sort does not modify its argument.
Switching $a and $b sorts in reverse order, so $a and $b are not interchangeable. The function reverse reverses the order of an array, so if reverse alphabetical order is desired, then either of the two methods in code sample 3.16 works.
Code Sample 3.15 This modification of code sample 3.14 produces the results one expects in output 3.9.
$data = "Four score and seven years ago"; |
@words = split(/ /, $data); |
@sorted_words = sort { lc($a) cmp lc($b) } @words; |
print "@sorted_words"; |
Output 3.9 Output of code sample 3.15.
ago and Four score seven years |
Code Sample 3.16 Two ways to obtain reverse alphabetical order.
$data = "Four score and seven years ago"; |
words = split(/ /, $data); |
# Reverse alphabetical order, method 1 |
@reverse_sorted_words1 = sort { lc($b) cmp lc($a) } @words; |
# Reverse alphabetical order, method 2 |
@reverse_sorted_words2 = reverse sort {lc($a) cmp lc($b)} @words; |
print "@reverse_sorted_words1 @reverse_sorted_words2"; |
Remember that code sample 3.13 did not sort the numbers into numerical order. The numerical analog of cmp is <=>, which is sometimes called the spaceship operator because of its appearance. Like its analog, it returns one of three values: −1, 0, and 1, which correspond to less than, equal to, and greater than, respectively. Code sample 3.17, which uses the spaceship operator, now sorts the numbers as expected: @sorted_numbers is identical to @numbers.
Code Sample 3.17 Example of a numerical sort.
@numbers = (1, 8, 11, 18, 88, 111, 118, 181, 188); |
@sorted_numbers = sort{ $a <=> $b } @numbers; |
print "@sorted_numbers"; |
We end this section with two types of sorts, each one of interest to anyone who enjoys word games. The first sorts an array of words in alphabetical order, but considering the letters from right to left. The second is a double sort: first sort by word length, and within the words of a fixed length, then sort by the usual alphabetical order. Although the output of the code shown below is not that informative, there are extensive word lists on the Web (for example, see Grady Ward’s Moby Word Lists [123]), and if these two sorts are applied to such a list, that output is interesting.
To accomplish right to left alphabetical word order, we use the function reverse, which is used above to reverse the entries in an array. In scalar context, this function reverses the characters in a string. If applied to a number, the number is acted upon as if it were a string. Code sample 3.18 shows how to perform this sort.
Code Sample 3.18 Example of a right to left alphabetical word sort.
@words = qw(This is a list of words using qw); |
@sorted_words = sort {lc(reverse($a)) cmp lc(reverse($b))} @words; |
print "@sorted_words"; |
Note that lc is used so that case differences are ignored. Because writing a list of words, each with double quotes, is tedious, Perl has the operator qw that informs it that strings are involved. To remember this, think of the initial letters of quote word. Output 3.10 gives the results, which make sense if the ends of the words are considered.
Output 3.10 Output of code sample 3.18.
a of using words is This list qw |
For the second example, we sort words first by using length, then by alphabetical order for all the words of a given length. Code sample 3.19 shows an example of this using the following logic. First, compare the lengths of $a and $b using the function length and the comparison operator <=>. If these lengths are the same, then compare the strings using lc and cmp.
Code Sample 3.19 Example of sorting strings first by length then by alphabetical order.
@words = qw(This is a list of words using qw); |
@sorted_words = |
sort { $value = (length($a) <=> length($b)); |
if ($value == 0) { return lc($a) cmp lc($b); |
} else { return $value }; } |
@words; |
print "@sorted_words"; |
Output 3.11 Output of code sample 3.19.
a is of qw list This using words |
Although itworks, code sample 3.19 is becoming hard to read. This sorting code can be defined as a separate function, which is done in code sample 3.20. The technique is almost the same as making a user-defined function, except that the arguments are the special Perl variables $a and $b. Notice that the function name lengthSort is put between sort and the name of the array, and curly brackets are not needed. Finally, the output of this code sample is the same as output 3.11.
Code Sample 3.20 Rewriting code sample 3.19 using a subroutine for sorting.
@words = qw(This is a list of words using qw); |
@sorted_words = sort byLength @words; |
print "@sorted words"; |
sub byLength { |
$value = (length($a) <=> length($b)); |
if ($value == 0) { |
return lc($a) cmp lc($b); |
} else { |
return $value; |
} |
{ |
Arrays are excellent tools for storing a sequence of values. For example, when splitting a sentence into words, the order is important. However, suppose the goal is the following: for a specific text, determine what set of words are in it and then count the frequency of each of these. To use an array, each numerical index must represent a unique word, and the problem becomes how to keep track of which index represents which word.
Fortunately, there is a better way. Instead of indexing with the numbers 0, 1, 2, ..., it is more convenient to use the words themselves for indices. This idea is exactly what a hash does.
Just as arrays start with their own unique symbol (an @), hashes must begin with the percent sign, that is, %. Recall that the entries of @array are accessed by $array [0], $array [1], $array [2],.... Similarly, the entries of %hash are accessed by $hash{"the"} $hash{"and"}, and so forth. The strings that have associated values are the keys. See table 3.1 for a summary of these points.
Table 3.1 Comparison of arrays and hashes in Perl.
Arrays |
Hashes |
@name |
%name |
$name [0] |
$name{"stringl"} |
$name [1] |
$name{"string2"} |
Indices are numbers |
Indices are strings |
Uses square brackets |
Uses curly brackets |
Ordered |
No inherit order |
Like arrays, lists can be used to define a hash. Moreover, it is easy to convert a hash to an array, as well as the reverse. Examples of hashes and hash conversions to arrays are given in code sample 3.21. Unlike arrays, hashes cannot be interpolated in double quotes because they are unordered.
Note that %hashl through %hash4 are identical. Although a hash can be defined using a list with all commas, its entries naturally come in key-value pairs, so Perl provides the => operator, which is equivalent to a comma, but it is easier to read. Perl also expects that the keys are strings, so quotes (either single or double) are optional as long as there are no embedded blanks. Since pairs of entries are the norm for a hash, a list usually has an even number of entries. However, %hash5 has an odd length, which means the key 9 has no value paired to it in the list. Whenever this happens, Perl assigns the empty string as the value.
Code Sample 3.21 Examples of defining hashes and converting them into arrays.
%hashl = ("the", 220, "of", 149); |
%hash2 = ("the" => 220, "of" => 149); |
%hash3 = (the, 220, of, 149); |
%hash4 = (the => 220, of => 149); |
%hash5 (1. .9); |
@array1 = %hashl; |
@array2 = %hash2; |
@array3 = %hash3; |
@array4 = %hash4; |
@array5 = %hash5; |
$" = ","; |
print "@array1 @array2 @array3 @array4 @array5 "; |
Output 3.12 Output of code sample 3.21.
the , 220 , of , 149 |
the , 220 , of , 149 |
the , 220 , of , 149 |
the , 220 , of , 149 |
1,2,3,4,7,8,9, ,5,6 |
The first four lines of output 3.12 contain no surprises. The arrays are identical to the hashes assigned to them. However, the fifth line shows that the hash has changed the order of some of the key-value pairs. In particular, key 5 has been moved to the last position. Hashes are ordered so that storage and retrieval of values are optimized.
As is the case with arrays, there are Perl functions that manipulate hashes. The most important of these are discussed in the next section.
3.6.1 Using a Hash
Hashes have no particular order, so functions such as push and pop do not make sense, and using them with a hash produces a compilation error. However, hashes do have keys and values, which are returned as arrays by the functions keys and values, respectively. The former is particularly useful for looping through a hash. We consider this next.
Consider code sample 3.22. The variable $sentence is a string, and the punctuation is removed by using the s/// operator. Then split extracts the individual words, which are put into the array @words. The foreach loop goes through this array one at a time, which are keys for the hash, %counts. Initially, each key has the empty string for its value, but the increment operator ++ forces this empty string into number context, where it acts like 0, so it works even for the first appearance of a word. Note that lc is used to put all th letters into lowercase, so that capitalization is ignored. For example, the words The and the are counted as the same.
Code Sample 3.22 This code counts the frequency of each word in the sentence by using a hash.
$sentence = "The cat that saw the black cat is a calico."; |
$sentence = s/ [.,?! ;;'"(){} []]//g; # Remove punctuation |
@words = split(/ /,$sentence); |
foreach $word (@words) { |
++$counts{lc ($word) }; |
} |
foreach $word (keys %counts) { |
print "$word, $counts{$word} "; |
} |
The second foreach loop prints out the frequencies of each word by looping over the array produced by keys. Remember that the order of these keys typically looks random to a human, as is the case in output 3.13. However, these keys can be sorted.
Output 3.13 Output of code sample 3.22.
the, 2 |
a, 1 |
that, 1 |
is, 1 |
cat, 2 |
saw, 1 |
black, 1 |
calico, 1 |
Alphabetical order is commonly used to list the keys of a hash. Since this is the default order of sort, it is easy to do: just put this function in front of keys in code sample 3.22, which produces code sample 3.23. This prints output 3.14.
Code Sample 3.23 Example of sorting the keys of the hash %counts, which is created in code sample 3.22.
foreach $word (sort keys %counts) { |
print "$word, $counts{$word} "; |
} |
Suppose that the least frequent words in $sentence are of interest. In this case, listing the values of the hash in numerical order is desired, which is done by the following trick. The value of key $a is $counts{$a}, and an analogous statement is true for $b. Hence, we apply the spaceship operator to $counts{$a} and $counts{$b}, which is done in code sample 3.24, which produces output 3.15.
Output 3.14 Output of code sample 3.23.
a, 1 |
black, 1 |
calico, 1 |
cat, 2 |
is, 1 |
saw, 1 |
that, 1 |
the, 2 |
Code Sample 3.24 The sort function puts the values of %counts (from code sample 3.22) into numerical order.
foreach $word (sort {$counts{$a} <=> $counts{$b}} keys %counts) { |
print "$word, $counts{$word} "; |
} |
Output 3.15 Output of code sample 3.24.
a, 1 |
that, 1 |
is, 1 |
saw, 1 |
black, 1 |
calico, 1 |
the, 2 |
cat, 2 |
Although the values are in order, for a fixed value, the keys are not in alphabetical order. This is fixed by byValues in code sample 3.25, which is an extension of byLength in code sample 3.20. By using this user-defined function, this sort statement is much easier to read. Finally, the results of using this order is given in output 3.16.
We end this section with a quick mention of one additional Perl hash function. The function exists checks to see whether or not a key has a value in a hash. Here is an example of its use.
if ( exists($counts{$key}) ) { # commands }
Up to this point, much of this chapter discusses how to use arrays and hashes in Perl. Now it is time to apply this knowledge. The next section discusses two longer examples where we implement our new programming skills to analyze text.
Code Sample 3.25 The subroutine byValues first orders the values of %counts (from code sample 3.22) numerically and then by alphabetical order.
foreach $word (sort byValues keys %counts) { |
print "$word, $counts{$word} "; |
} |
sub byValues { |
$value = $counts{$a} <=> $counts{$b}; |
if ($value == 0) { |
return $a cmp $b; |
} else { |
return $value; |
} |
} |
Output 3.16 Output of code sample 3.25.
a, 1 |
black, 1 |
calico, 1 |
is, 1 |
saw, 1 |
that, 1 |
cat, 2 |
the, 2 |
This section discusses two applications, which are easy to program in Perl thanks to hashes. The first illustrates an important property of most texts, one that has consequences later in this book. The second develops some tools that are useful for certain types of word games. We have worked hard learning Perl, and now it is time to reap the benefits.
Before starting these applications, we generalize the concordance code, program 2.7, which is hard-coded to read in Charles Dickens’s A Christmas Carol [39] and to find the word the. Section 2.5.1 discusses the command line, which is also used in program 3.1. The version here, program 3.2, uses the command line to read in a file name, a regex, and a text radius (to determine the size of the text extracts). This program proves useful below.
As for the code itself, note that the first two lines are comments, which tell the user about the code. The regex from the command line is put into parentheses when assigned to the variable $target, which causes the match to be stored in $1. If the parentheses are included on the command line, however, the code still works.
3.7.1 Zipf’s Law for A Christmas Carol
This section determines which words are in Dickens’s A Christmas Carol and how often each of these appears. That is, we determine all the word frequencies. This sounds like a straightforward task, but punctuation is trickier than one might expect. As discussed in sections 2.4.2 and 2.4.3, hyphens and apostrophes cause problems. Using program 3.2, we can find all instances of potentially problematic punctuation. These cases enable us to decide how to handle the punctuation so that the words in the novel change as little as possible.
Program 3.2 A concordance program that finds matches for a regular expression. The file name, regex, and text extract radius are given as command line arguments.
# USAGE > perl regex_concordance.pl FileName.txt Regex Radius |
# This program is case insensitive. |
open (FILE, "$ARGV[O]") or die("$ARGV[0] not found"); |
$1 = ""; # Paragraph mode for first while loop |
# Initialize variables |
$target = "($ARGV[l])"; # Parentheses needed for $1 in 2nd while |
$radius = $ARGV[2]; |
$width = 2*$radius; |
while (<FILE>) { |
chomp; |
s/ / /g; # Replace newlines by spaces |
while ( $_ = ~/$target/gi ) { |
$match = $1; |
$pos = pos($_); |
$start = $pos $radius length($match); |
if ($start < 0) { |
$extract = substr($_, 0, $width+$start+length($match)); |
$extract = (" " x -$start) . $extract; |
$len = length($extract); |
} else { |
$extract = substr($_, $start, $width+length($match)); |
} |
print "$extract "; |
} |
} |
First, we check for dashes in the novel and whether or not there are spaces between the dashes and the adjacent words. The following command produces output 3.17.
perl regex_concordance.pl A_Christmas_Carol.txt --30
Notice the name of the file containing the novel has no blanks in it. If it did, double quotes must be placed around this name (single quotes do not work).
The complete output has 82 lines, and the first 10 are shown here. Certainly A Christmas Carol does use dashes, and these are generally placed in between words without spaces, so the few spaces that do appear are typos. Substituting a space for each dash removes them, and this is easily done by s/--/ /g;.
Output 3.17 Output from program 3.2, which prints out extracts containing dashes. Only the first 10 lines shown.

Next we check for single hyphens, which should only appear in hyphenated words. The regex w-w detects them since it specifies a hyphen between two alphanumeric characters. This gives the following command, which produces 226 examples, the first 10 of which are given in output 3.18. Note that the regex is in double quotes, which are optional here, but are required if the regex has spaces or quotes.
perl regex_concordance.pl A_Christmas_Carol.txt "w-w" 30
Output 3.18 Output from program 3.2, which prints out extracts containing hyphenated words. Only the first 10 lines shown.
ld Marley was as dead as a door-nail. |
particularly dead about a door-nail. I might have been incline ned, myself, to regard a coffin-nail as the deadest piece of ir at Marley was as dead as a door-nail. |
re would be in any other middle-aged gentleman rashly turning o |
Oh! But he was a tight-fisted hand at the grind-stone, tight-fisted hand at the grind-stone, Scrooge! a squeezing, wr generous fire; secret, and self—contained, and solitary as an o; he iced his office in the dog—days; and didn’t thaw it one de crooge sat busy in his counting-house. It was cold, bleak, biti |
Since this text has just over 200 hyphenated words, we need to decide what to do with them. The 3 simplest choices are: leave them as is; split them into separate words; or combine them into one word. In this case, Dickens is an acknowledged great writer, so let us leave his text as is.
Third, and trickiest, are the apostrophes. This text uses double quotes for direct quotations. Apostrophes are used for quotes within quotations as well as for possessive nouns. The latter produces one ambiguity due to possessives of plural nouns ending in s, for example, seven years’. Another possible ambiguity is a contraction with an apostrophe at either the beginning or the end of a word. To check how common the latter is, the regex w’W checks for an alphanumeric character, an apostrophe, and then a nonaiphanumeric character. Running the following command creates output 3.19, which gives all 13 cases.
perl regex_concordance .pl A_Christmas_Carol .txt "w’W" 30
Output 3.19 Output from program 3.2, which matches words ending with ‘.
oes about with ‘Merry Christmas’ uddy as they passed. Poulterers’ passed. Poulterers’ and grocers’ last mention of his seven years’ ave become a mere United States’ azing away to their dear hearts’ f it went wrong. The poulterers’ 1 half open, and the fruiterers’ rapes, made, in the shopkeepers’ |
The Grocers’ |
The Grocers’! oh, the Grocers’ ing their dinners to the bakers’ |
"Are spirits’ |
on his lips, should be boiled and grocers’ trades became a s trades became a splendid joke: dead partner that afternoon. A security if there were no days content. There was nothing ver shops were still half open, an were radiant in their glory. T benevolence to dangle from con ! oh, the Grocers’! nearly clos! nearly closed, with perhaps t shops. The sight of these poor lives so short?" asked Scrooge |
The only example other than a possessive noun is the first line, which is a quote within a quote that ends in the letter s. In particular, none of these are a contraction with an apostrophe at the end of the word. So if no single quotes after the final letter of a word are removed, only one error arises. If one error is unacceptable, then add a line of code to handle this exception.
Finally, there is the possibility of a contraction starting with an apostrophe, which does happen in this text. Using the regex W’w, we find all cases of this. This results in 24 matches, the first 10 of which are given in output 3.20.
Output 3.20 Output from program 3.2, which matches words starting with’. Only the first 10 lines shown.
d Scrooge’s name was good upon books and having every item in very idiot who goes about with |
"Couldn’t I take fter sailing round the island.in, accompanied by his fellow— shutters--one, two, three--had laces--four, five, six--barred ve, six--barred ‘em and pinned rybody had retired but the two |
‘Change, for anything he chose t ‘em through a round dozen of mon ‘Merry Christmas’ on his lips, s ‘em all at once, and have it ove ‘Poor Robin Crusoe, where have y ’prentice. |
‘em up in their places--four, fi ‘em and pinned ‘em--seven, eight ‘em--seven, eight, nine--and cam ‘prentices, they did the same to |
The only contractions that appear are ‘Change (short for the Exchange, a financial institution), ‘em (them), and ‘prentices (apprentices). Again we can check for these three cases, or we can always remove an initial single quote, and this produces only one ambiguity: it is not possible to distinguish between ‘Change and the word change (which does appear in this text). For more on contractions, see problem 3.1.
Turning the above discussion into Perl code, we get program 3.3. There are several points to note. First, there are two open statements. The first opens the text file containing A Christmas Carol. The second opens a file for the output, which is indicated by the greater sign at the start of the filename (see section 2.5.2 for more on this). Since this program produces many lines of output (one for each distinct word), this is easier to handle if it is in a file. To write to this, the print statement must have the filehandle immediately after it as shown in the last foreach loop.
Program 3.3 This program counts the frequency of each word in A Christmas Carol. The output is sorted by decreasing frequencies.

Second comes the while loop. It starts with chomp, which removes the final newline character from the default variable, $_. Then $_ = lc; converts the default variable to lowercase. The next three lines are substitutions that remove all of the punctuation except for the single quote. Next, the line of text is split into words.
Third, the foreach loop inside the while loop decides whether or not to remove apostrophes. If it is inside the word itself, it is not removed. If it is at the end of the word, it is removed only if the word is Christmas, which is an odd rule, but one discovered by looking at output 3.19. If the single quote is at the start of the string, it is removed unless it is one of the following: ‘change, ‘em, or ‘prentices.
Fourth, since $word has no punctuation (except apostrophes), we use the hash %dictionary to increment the count associated with $word. Once the while loop is done, the last foreach loop prints out the results to the file Word_Counts.csv. The order of the sort is determined by byDescendingValues, which sorts by values, from largest to smallest. Code sample 3.26 gives the subroutine for this function, and the first 10 lines it produces are given in output 3.21. Note that the suffix of this file, . csv, stands for comma-separated variables. Many types of programs know how to read such a file, and they are a popular way to store data.
Code Sample 3.26 This subroutine sorts the values of %dictionary (computed by program 3.3) from largest to smallest.

Output 3.21 First 10 lines of output from program 3.3, which uses code sample 3.26.
the, 1563 |
and, 1052 |
a, 696 |
to, 658 |
of, 652 |
in, 518 |
it, 513 |
he, 485 |
was, 427 |
his, 420 |
Finally, the file used for A Christmas Carol has chapter titles. These have been included in program 3.3. If a programmer wants to leave these out, this requires modifying this code.
Now we can state and illustrate Zipf’s law. First, the words in the text are listed from most to least frequent. Then assign ranks for each word by numbering them 1, 2, 3, .... For example, from output 3.21 we see that the is most common (appearing 1563 times), so it has rank 1. Since the sequence continues and, a, to, these words have ranks 2, 3, 4. respectively. If there are ties, then arrange these alphabetically, and rank them in that order, For example, but and not both appear 177 times, so give the former rank 24, and the latter rank 25. As the counts get smaller, the number of ties goes up. For instance, there are 2514 out of 4398 words that appear exactly once (just over 57%). Such words are called hapaxlegomena.
The total number of words mA Christmas Carol is determined by adding all the numbers produced by program 3.3, which is 28,514. We can also count the number of distinct words, or types. This is the number of lines of output, which equals 4398.
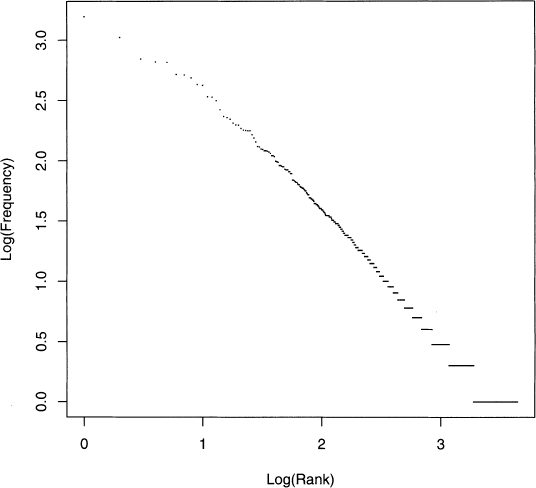
Once the ranks are given, each word has two values associated with it: its frequency and its rank. Zipf’s law says that plotting the logarithm of the frequency against the logarithm of the rank produces an approximately straight line. Figure 3.1 shows such a plot, which is approximately straight. More importantly, since the horizontal lines in the lower right corner represent numerous ties, the conclusion is clear: the lower the frequency, the larger the number of ties, on average.
Figure 3.1 Log(Frequency) vs. Log(Rank) for the words in Dickens’s A Christmas Carol.
3.7.2 Perl for Word Games
Now we take a break for some fun. There are various types of word lists on the Web, and for word games we want one that includes inflected words. That is, nouns include both singular and plural forms; verbs include all the conjugated forms; adjectives include the comparative and superlative forms, and so forth. We use Grady Ward’s CROSSWD.TXT from the Moby Word Lists [123]. This has more than 110,000 words total, including inflected forms.
In this section we consider three types of word games. First, in a crossword puzzle the length of a word is known. In addition, a few letters and their locations in the word can be known. Using CROSSWD.TXT, we find all words that match these two constraints. Second, given a group of letters, we find out if it is possible to rearrange them so that they form a word. For example, the letters eorsstu can form seven words: estrous, oestrus, ousters, sourest, souters, stoures, and tussore. Third, given a group of letters, what are all the possible words that can be formed from all or some of these letters? For example, using all or some of the letters in textmining, what words can be formed? There are many possibilities, some obvious like text and mining, and others that are harder to discover, like emitting and tinge.
3.7.2.1 An Aid to Crossword Puzzles Finding words to fit in a crossword puzzle is easy to do. Suppose the goal is to find a seven-letter word with a j in the third position and an n in the sixth. All the other letters must match w, so the following regex works because CROSSWD.TXT has exactly one word per line, so the initial caret and ending dollar sign guarantee that the matches are exactly seven letters long.
/^w{2}jw{2}nw$/
Program 3.4 is straightforward to create. For flexibility, it uses acommand line argument to supply the regex, which is constructed by the qr// operator. The if statement prints out each word that matches this regex.
If we run the following command, we get output 3.22, assuming that program 3.4 is stored under the filename crossword.p1.
perl crossword. p1 "^w{2}jw{2}nw$"
The usefulness of this program depends on the number of matches found. The extreme case is using something like the regex /^w{7}$/, which returns all 21,727 seven-letter words, which is not much help in solving a crossword clue.
3.7.2.2 Word Anagrams Here we create an anagram dictionary, which is a listing of words indexed by the letters of each word sorted in alphabetical order. For example, the word abracadabra has the index string aaaaabbcdrr. By making this index string a key, we can create a hash that stores the entire anagram dictionary. Unfortunately, sort does not have a string context, but the following approach works.
The function split (//) turns a string into an array, which sort can order. Finally, the function join turns the array back into a string. Its first argument is the text to place between array entries, and if the empty string is used, then the entries of the array are concatenated together. So using these three functions can create the index string discussed above.
Program 3.4 Finding words fitting crossword-puzzle-type constraints.

Output 3.22 All matches from running program 3.4 as described in the text.
adjoins |
adjoint |
enjoins |
rejoins |
sejeant |
There is one last issue. Some keys work for more than one word. This requires checking to see if any value has been assigned to the current key. If so, then the program appends the new word to the old list using a comma as a separator. If not, then the current word becomes the value for this key. Using these ideas results in program 3.5. The first 10 lines produced by this program are given in output 3.23. Finally, note that this same technique is applicable to all sorts of strings, not just words. See problem 3.9 for an example.
3.7.2.3 Finding Words in a Set of Letters The final task is harder because it requires considering not just a group of letters, but also all subgroups. Unfortunately, the number of nonempty subsets of n letters is 2n – 1, which grows quickly. For instance, eight letters has 255 subsets. Fortunately, there is a trick to avoid considering all these explicitly.
Suppose we want to find all the words that can be formed from some or all of the letters in the word algorithm. Sorting the letters of this word produces aghilmort. Now loop through all the keys of the anagram dictionary created by program 3.5. For each key, sort its letters, then create a regex from these by placing . * at the beginning, between each pair of letters, and at the end. For example, for the key pull, we sort to get llpu, and then create the regex /. *l. *l. *p. *u. */. The only way that aghilmort can match this regex is that all the letters of pull are contained in the letters of algorithm. In this case, this is not true, so pull cannot be formed.
It is true that they are many keys, but computers are fast. Taking the logic of the last paragraph, and reusing the anagram dictionary code of program 3.5, we get program 3.6. In this code, $index contains the sorted letters of the string entered on the command line. The foreach loop sorts each key of %dictionary, creates a regex from these sorted letters as described above, then checks if $index matches. This technique is another example of interpolation, and it demonstrates how powerful it can be.
Program 3.5 Creates an anagram dictionary.

Output 3.23 First 10 lines from running program 3.5
aa, aa |
aaaaabbcdrr, abracadabra |
aaaabcceeloprsttu, postbaccalaureate |
aaaabcceelrstu, baccalaureates |
aaaabcceelrtu, baccalaureate |
aaaabdilmorss, ambassadorial |
aaaabenn, anabaena |
aaaabenns, anabaenas |
aaaaccdiiklllsy, lackadaisically |
aaaaccdiiklls, lackadaisical |
Finally, 10 lines of program 3.6 are given in output 3.24. Lines with more than one entry contain anagrams. For example, algorithm is an anagram of logarithm. Although the order of these words seems random, they are in alphabetical order of their keys.
In this section we have seen the power of hashes. In the next, we consider more complex data structures, which are essential later in this book.
For a single text, hashes and arrays are sufficient. However, if a collection of texts are of interest, it is unwieldy to use numerous data structures, each with its own name. Fortunately, Perl supports complex data structures like arrays of arrays. But to understand how these work, we must learn about references, the topic of the next section.
Program 3.6 This program finds all words formed from subsets of a group of letters.

Output 3.24 First 10 lines from running program 3.6 with algorithm as the input.
hag |
laigh |
algorithm, logarithm |
alright |
alight |
aright |
ogham |
garth |
ghat |
glioma |
3.8.1 References and Pointers
So far, we have assigned values to variables. For example, the command below assigns the string the to the scalar $word.
$word = "the";
However, it is possible to assign not the value, but the memory location of the value, which is called a reference. For example, the command below now stores the location of the in the variable $wordref.
$wordref = "the";
The backslash in front of the string indicates that a reference to that string is desired. Backslashes in front of arrays and hashes also produce references. Printing out $wordref on my computer produced SCALAR(0x184ba64), where the value in the parentheses is a memory location written out as a base 16 number (as indicated by the first two characters, 0x).
The actual memory location is not directly useful to a programmer, so a method to retrieve the value is needed, which is called dereferencing. A scalar reference is dereferenced by putting it inside the curly brackets of ${}. An example of this is given in code sample 3.27.
Code Sample 3.27 Example of referencing and dereferencing scalars.
$word = "the"; |
$wordref 1 = "the"; |
$wordref2 = $word; |
print "$wordref 1, $wordref2 "; |
print "${$wordrefl}, ${$wordref2} "; |
print "$$wordref 1, $$wordref2 "; |
Running this code sample produces output 3.25. The print statements show that $wordref 1 and $wordref2 have memory locations, and that ${$wordrefl} and ${$wordref2} do access the values. In addition, these can be abbreviated to $$wordref1 and $$wordref2.
Output 3.25 Results of code sample 3.27.
SCALAR(0x1832824), SCALAR(0x18327f4) |
the, the |
the, the |
Analogous examples can be created for both arrays and hashes. Code sample 3.28 shows an example for the array @sentence. Note that there are two ways to make an array reference. First, put the backslash operator in front of an array name. Second, use square brackets instead of parentheses for a list, which is also called an anonymous array. Note that putting a backslash in front of a list does not create an array reference.
Looking at output 3.26, putting the array reference inside @{} does work. That is, @{$sentenceref1} is an array, so, for example, @{$sentenceref1}->[0] or @{$sentenceref1} [0] accesses the first element of the array. However, this notation is a bit cumbersome, so two equivalent forms exist in Perl: $sentenceref1-> [0] and $$sentenceref1 [0]. References are also called pointers, and so a pointing arrow is an appropriate symbol. Notice that when $sentenceref1-> [−1] is set to a different word, the original array, @sentence is itself changed. Hence changing a reference changes what it points to.
Finally, code sample 3.29 shows a hash example of referencing and dereferencing. As with arrays, there are two ways to specify a hash reference: using the backslash or using curly brackets, and the latter is called an anonymous hash. Again using either the arrow or the double dollar notations work with hash references, similar to arrays. The results of this code sample are given in output 3.27.
Code Sample 3.28 Example of referencing and dereferencing an array.
@sentence = qw(This is a sentence.); |
$sentenceref1 = @sentence; |
$sentenceref2 = ["This", "is","a","sentence."]; |
print "$sentenceref1, $sentenceref2 "; |
print "@{$sentenceref1} "; |
print "@{$sentenceref2} "; |
print "@{$sentenceref1}-> [0] "; |
print "@{$sentenceref1} [0] "; |
print "$sentenceref1-> [0] "; |
print "$$sentenceref1 [0] "; |
print "$sentenceref1-> [–1] "; |
$sentencerefl->[–1] = "banana"; |
print "@sentence "; |
Output 3.26 Results of code sample 3.28.
Arrays |
ARRAY(0x1832974), ARRAY(0x2356f0) |
This is a sentence. |
This is a sentence. |
This |
This |
This |
This |
sentence. |
This is a banana |
If you are new to programming, creating a reference to a memory location, and then dereferencing it to access its value may seem crazy. After all, why not just work with the value itself? It turns out that references are useful in more than one way, but we consider just one important application here.
Before stating this application, the need for it comes from one unfortunate fact about Perl: it only handles one-dimensional data structures. However, complex data structures like multidimensional arrays are possible in Perl, so how is this one-dimensional limitation overcome? Consider this concrete example: suppose a one-dimensional array $array2d contained references to other arrays. Then $array2d [0] is a reference to another array, as is $array2d [1], $array2d [2], and so forth. By dereferencing $array2d [0], we are able to access this new array, and the same is true for $array2d [1], $array2d [2],.... The result is a data structure that has two indices. In fact, it is more general than a traditional two-dimensional, rectangular array.
Code Sample 3.29 Example of referencing and dereferencing a hash.
%counts = (the => 1563, and => 1052, a => 696); |
$countsref 1 = \%counts; |
$countsref2 = {the => 1563, and => 1052, a => 696}; |
print "$countsref1, $countsref2 "; |
print "$countsrefl—>{and} "; |
print "$countsref2—>{the} "; |
print "$$countsref2{the} "; |
Output 3.27 Results of code sample 3.29.
HASH(0x1832d04), HASH(0x1832ca4) |
1052 |
1563 |
1563 |
But before moving on, the following facts are useful to memorize. First, the backslash in front of a scalar variable, an array, or a hash creates a reference to these respective data structures, and this reference is a scalar in all cases (its scalar value is the memory location). Second, the dereferencing operators, ${}, @{}, %{} all start with the symbol that begins the respective names of the data structures. Third, anonymous arrays use square brackets, and array indices are put into square brackets. Similarly, anonymous hashes use curly brackets, and hash indices are put into curly brackets. In the next section we create an array of arrays, and see how it works in detail.
3.8.2 Arrays of Arrays and Beyond
The construction of an array of arrays discussed in the last section is straightforward. A one-dimensional array can be constructed by putting the entries inside parentheses. Array references can be created by listing entries inside square brackets, which are called anonymous arrays. So if we create a list of anonymous arrays, then that is an array of arrays. A simple example is done in code sample 3.30.
Code Sample 3.30 Example of an array of arrays using a list of anonymous arrays.
@data = ([1, 2, 3], [‘a’, ‘b’, ‘c’, ‘d’], [3.3, 2.06]); |
print "$data[0] "; |
print "{$data[0] } "; |
print "$data[l] -> [0] "; |
print "$data[2] [1] "; |
The results from this code sample is given in output 3.28. The first line shows that $data [0] is indeed a reference to an array. By putting $data [0] into @{} this is dereferenced. Note that the following three expressions are equivalent, and all access an entry of an array of arrays. However, do not use double dollar signs in this situation.
@{$data [2] }–> [1]
$data [2] -> [1]
$data[2] [1]
Knowing that two sets of square brackets imply the existence of the arrow between them, the last form is the easiest to use. However, it is prudent to remember that @data is not a two-dimensional array, but instead an array of references that happen to point to more arrays.
Output 3.28 Results of code sample 3.30.
ARRAY (Oxl8bl2ac) |
1,2,3 |
a |
2.06 |
To get a complete listing of the elements of @data, one can use several techniques, two of which are shown in code sample 3.31. To understand the first method, remember that $#data gives the last index of @data, so the for loop iterates over the number of anonymous arrays in @data. The join function makes a string out of each dereferenced array using commas as separators. Finally, note that since @data has scalar entries that are references, the references must start with a dollar sign. Hence in join, the dereferencing operator @{} must contain the scalar variable $data [$i]. The second method iterates over the number of anonymous arrays, just like the first method. And the second for loop iterates over the length of each anonymous array since $#{} gives the value of the last index for the referenced array within the curly brackets. Output 3.29 shows the results.
Hashes of hashes are similar to arrays of arrays. In code sample 3.32, we see that arrows can be used, but similar to arrays of arrays, they are implied when two curly brackets are side by side. For printing out of all the values, notice that the first foreach loop iterates over the keys of %data, which is a hash of references. In the second foreach loop, $data{$i} is a reference, so it must start with a dollar sign, and it is dereferenced by %{}, which allows the use of keys. Finally, note that the order of the values printed by the two foreach loops in output 3.30 is not the order used in the definition of %data. Remember that Perl stores hashes using its own ordering.
Finally, arrays and hashes can be mixed together. An example of an array of hashes is seen in code sample 3.33, which produces output 3.31. Note that dropping the arrows is possible between square brackets and curly brackets, similar to the two cases above. Note that the for loop iterates through the array of hash references, and the foreach loop iterates through the keys of each hash.
Hashes of arrays are very similar to arrays of hashes. Moreover, it is possible to have more than two levels of references, for example, arrays of hashes of hashes, or even varying number of levels, for instance, @array where $array [0] refers to a hash, $array [1] refers to an array of arrays, $array [2] refers to a scalar, and so forth. For this book, two levels suffice, but the above examples suggest how a programmer might proceed. For example, it is not surprising that $data{$i} [$j] [$k] accesses a value of a hash of arrays of arrays.
Code Sample 3.31 Two examples of printing out an array of arrays using for loops.

Output 3.29 Results of code sample 3.31.
Method #1 |
1, 2, 3 |
a, b, c, d |
3.3, 2.06 |
Method #2 |
1, 2, 3, |
a, b, c, d, |
3.3, 2.06, |
There is more to know about references, but the material above suffices for the tasks in this book. Now we apply the tools discussed in this section to text. In the next section, we learn how to compare the words in two texts by using an array of hashes.
3.8.3 Application: Comparing the Words in Two Poe Stories
In this section we compare the vocabulary of Edgar Allan Poe’s “Mesmeric Revelation” and “The Facts in the Case of M. Valdemar.” With only two texts, two hashes can be used, but our goal is to use the techniques of the last section so that the code is generalizable to many texts, which is used in chapter 5.
We assume that the two stories are in one file, and the beginning of each story is marked by its title put between two XML tags as follows.
<TITLE> MESMERIC REVELATIONS </TITLE>
Code Sample 3.32 Examples of a hash of hashes and how to print out all its values.

Output 3.30 Results of code sample 3.32.
2 |
1 |
Listing |
length, c, 1 |
length, a, 1 |
length, b, 1 |
order, c, 3 |
order, a, 1 |
order, b, 2 |
XML (eXtensible Markup Language) is related to HTML (HyperText Markup Language), which are the tags used in creating Web pages. XML and HTML are the most famous instances of SGML (Standard Generalized Markup Language). The need for XML in this case is modest: only title tags are used. Conveniently, we only need to know that XML tags come in matched pairs, as is shown above.
These title tags inform the program when one story ends and another one begins. The words of all the stories are stored in an array of hashes, one hash for each story. Notice that it is not necessary to know the number of stories in advance since hashes can be added as needed. Once Perl code exists to analyze one story, looping through all the stories is easy to do.
To create the array of hashes, a counter (just a variable that counts something up) is incremented each time a title tag is detected (by a regex, of course). This counter is also the current array index of the array of hashes. We already have segmented a text into words, so the first part of the program is familiar. Our first new task is to count the number of words shared by each pair of stories, which includes a story with itself (this equals the number of words in that story). Program 3.7 contains this code, which is described below.
After opening the input file and assigning it to the filehandle IN, the counter $nstory is initialized to −1. This counter is incremented in the while loop each time a title tag pair is matched, and it is also the index to the array @name.
Code Sample 3.33 Example of an array of hashes and how to print out all its values.
@data = ({a => 1, b => 2, c => 3}, {a => “first”, b => "second"}); |
print "$data[0] "; |
print "$data[0] ->{a} "; |
print "$data[0] {a} "; |
print "$data[l] {b} "; |
print " Listing "; |
for ($i = 0; $i <= $#data; ++$i) { |
foreach $j (keys %{$data[$i]} ) { |
print "$i, $j, $data[$i]{$j} "; |
} |
} |
Output 3.31 Results of code sample 3.33.
HASH(0x1858d08) |
1 |
1 |
second |
Listing |
0, c, 3 |
0, a, 1 |
0, b, 2 |
1, a, first |
1, b, second |
The if statement switches between two tasks. If a <TITLE> </TITLE> pair is detected, then the counter $nstory is incremented, and the story title is saved in the array name. Otherwise, the line of text is processed: it is transformed into lowercase, dashes are removed, multiple spaces are reduced to one space, and then all punctuation except for the apostrophe is removed. It turns out that these two stories both use dashes, but one uses a single hyphen, the other a double hyphen. In addition, the only apostrophes used in both are either contractions or possessives. That is, none are single quotes used within quotations.
With the punctuation removed, since the default regex for split is one space, the words on each line are assigned to the array @words. The foreach loop goes through these one by one, and then two hashes are incremented. The first is the array of hashes, @dict. Note that ++$dict [$nstory] {$w} increments the count of $w in the story indexed by $nstory in @dict. Even though the text file used here has only two stories, this code works for any number as long as each one starts with XML title tags. The second hash, %combined, keeps track of word counts for all the stories combined, which is used in the next step.
When the while loop is finished, the raw data is in place. The two for loops after it keep track of each pair of stories, and then the foreach loop iterates through all the words in both stories (which are in the hash %combined). The if statement finally determines whether each word is a key for both hash references $dict [$i] and $dict [$j] by applying the function exists.
Program 3.7 This program reads stories in from a file that has titles inside XML tags. Shared word counts are computed for each pair of stories, including a story with itself.

Finally, the last for loop prints out the counts between each pair of stories, and output 3.32 shows the results. The order of the stories is printed out, and the counts form a two-by-two table, which reveals that “Mesmeric Revelation” has 1004 types (distinct words), and “The Facts in the Case of M. Valdemar” has 1095. Finally, these two stories have 363 types in common.
Output 3.32 The results of program 3.7.
MESMERIC REVELATION detected. |
THE FACTS IN THE CASE OF M. VALDEMAR detected. |
1004,363 |
363,1095 |
Program 3.7 is easily modified to count the number of words in the first story but not the second. Code sample 3.34 shows the nested for loops that do this. It gives the answer 641, which is confirmed by output 3.32, since of the 1004 types in the first story, 363 are shared by the second, which leaves 1004 – 363 = 641 types unique to the first.
Code Sample 3.34 If these for loops replace the analogous for loops in program 3.7, the resulting code computes the number of distinct words in the first story that are not in the second.

Thinking in terms of sets, program 3.7 computes the size of the intersection of the keys of two hashes, and code sample 3.34 computes the size of the complement of a hash. Finally, the keys of the hash %combined is the union of the keys of the hashes for each story. Recall that sets do not allow repeated elements, which is also true of hash keys. So these act like sets. For a discussion of working with sets in Perl see chapter 6 of Mastering Algorithms with Perl by Orwant et al. [84].
Section 2.8 lists some introductory books on Perl and on regular expressions. This section lists some more advanced books on Perl programming as well as a few that apply Perl to text-mining-related topics.
Larry Wall created Perl, and he co-authored Progamming Perl with Tom Christiansen and Jon Onwant [120]. A companion volume to this book is the Perl Cookbook by Tom Christiansen and Nathan Torkington [28]. A third that covers the details of Perl is Professional Perl Programming by Peter Wainwright and six other authors [119].
If you want to learn about algorithms, try Mastering Algorithms with Perl by Jon Orwant, Jarkko Hietaniemi, and John Macdonald [84]. It covers many of the important tasks of computer science. Also, chapter 9 covers strings, and it gives the details on how regular expressions are actually implemented in Perl.
The book Data Munging with Perl by David Cross [36] focuses on how to use Perl to manipulate data, including text data. It is a good introduction to more advanced ideas such as parsing. One great source of text is the Web, which begs to be analyzed. A book that uses Perl to do just this is Spidering Hacks by Kevin Hemenway and Tara Calishain [53].
Genetics has discovered another type of text: the genome. This has an alphabet of four letters (A, C, G, T), and the language is poorly understood at present. However, looking for patterns in DNA is text pattern matching, so it is not surprising that Perl has been used to analyze it. For an introduction on this topic, try one of these three books: Perl for Exploring DNA by Mark LeBlanc and Betsey Dexter Dyer [70]; Beginning Perl for Bioinformatics by James Tisdall [116]; and Mastering Perl for Bioinformatics by James Tisdall [117].
There are many more areas of Perl that are useful to text mining but are not used in this book. Here are four example topics, each with a book that covers it. First, many Perl modules (bundled code that defines new functions; see section 9.2) are object oriented. Hence, this kind of programming is supported by Perl, and this can be learned from Object Oriented Perl by Damian Conway [33]. Second, a programmer can use Perl for graphics using the add-on package Perl/Tk. For more on this topic, see Mastering Perl/Tk by Steve Lidie and Nancy Walsh [72]. Third, text mining is related to data mining, which uses databases. There is a Perl DBI (Data Base Interface), which is covered in Programming the Perl DBI by Alligator Descartes and Tim Bunce [38]. Finally, text is everywhere on the Web, and the Perl module LWP can download Web pages into a running program. For more on this see Perl & LWP by Sean Burke [20]. Remember if you fall in love with Perl, these topics are just the beginning. A book search on the term Perl reveals many more.
Chapter 2 introduces regular expressions and how to use them. This chapter introduces some data structures and how to implement these in Perl. Both of these together are an introduction to a subset of Perl that can do basic analyses of texts. The core of these analyses are text pattern matching (with regexes) and counting up matches in the text (which are kept track of by arrays and hashes). Working through these two chapters has taught you enough Perl to understand the programming after this point. If you started this book with no knowledge of Perl and little knowledge of programming, these two chapters required much thought and effort, and congratulations on getting this far.
At this point in this book, there is a transition. Prior to this, analyses of texts have been mixed with extensive discussions on how to use Perl. After this point, the focus is on analyzing texts with more complicated techniques, and Perl is more of a tool, not the focus of the discussion. However, if new features are used, these are pointed out and explained. But in general, the focus in the upcoming chapters is on text mining techniques, with Perl playing a supporting role.
3.1 Find all the words containing interior apostrophes in Dickens’s A Christmas Carol. Hence, on each side of the apostrophe there is an alphanumeric character. There are quite a few of these, some familiar to today’s reader (like it’s or I’ll), and some unfamiliar (like thank’ee or sha’n’t). For each of these, find its frequency in the novel.
3.2 A lipogram is a text that is written without one or more letters of the alphabet. This is usually done with common letters because, for example, not using q is not much of a challenge. In English, many lipograms do not use the letter e, the most common letter. An impressive example is A Void, a translation into English from French by Gilbert Adair of Georges Perec’s La Disparition. Both the original and the translation do not have the letter e.
Several people have written about the lipogram. See chapter 13 of Tony Augarde‘s The Oxford Guide to Word Games [5] for a history of lipograms. For a more detailed history, see the paper “History of the Lipogram” by Georges Perec [86], who is the same author noted in the above paragraph for writing a lipogrammic novel. Also see sections 11 and 12 of Ross Eckler’s Making the Alphabet Dance [41]. For an example of a phonetic lipogram (the text is missing a particular sound), see pages 12–14 of Ross Eckler’s Word Recreations [40].
The goal of this problem is to create a lipogram dictionary, that is, a list of words not containing some set of letters. This is not hard to do using a word list such as Grady Ward’s CROSSWD .TXT from the Moby Word Lists [123]. Have Perl read in this file and test each word against the appropriate regex. For example, code sample 3.35 disallows the letter e. Modify this code sample to answer the questions below.
Code Sample 3.35 Assuming that WORDS is a filehandle to a word list, this prints out the words not containing the letter e. For problem 3.2.
$regex = qr/^[^e]+$/i; |
while (<WORDS>) { |
if ( $_ = ~$regex ) { |
print; |
} |
} |
a) How many words do not have any of the letters a, e, i, o, and u?
b) How many words do not have any of the letters a, e, i, o, u, and y? Surprisingly, an exhaustive word list does have such words. For example there is crwth, which is borrowed from Welsh.
c) How many words require only the middle row of the keyboard? That is, how many words are composed of letters strictly from the following list: a, s, d, f, g, h,j, k, and l?
d) Compose a dictionary of words using only the vowel u. For discussion of this property, see section 12 of Ross Eckler’s Making the Alphabet Dance [41].
e) Find words that have exactly the five vowels, each appearing once, for example, facetious. For examples of such words for every permutation of the vowels, see section 12 of Ross Eckler’s Making the Alphabet Dance [41].
3.3 Section 3.7.2.2 discusses word anagrams, which are two (or more) words using the same group of letters, but with different orders. For example, algorithm is an anagram of logarithm since the former is a permutation of the latter.
Instead of allowing all permutations, one challenge is finding word anagrams limited to only certain types of permutations, examples of which are given below. Examples can be found by using a word list, for example, Grady Ward’s CROSSWD .TXT from the Moby Word Lists [123].
a) The easiest permutation to check is reversing the letters because there is already a Perl function to do this, reverse. Find all the words that are also words when read backwards.
Hint: One way to do this is to create a hash, say %list, where its keys are the words in the word list. Then loop through the keys checking to see if the reversal of the word is also a key, as done in code sample 3.36. Note that this also finds palindromes, that is, words that are the same backwards as forwards, for example, deified.
Code Sample 3.36 A loop to find words that are still words when reversed. For problem 3.3.a.
foreach $x (sort %list) { |
if ( exists($list{reverse($x)}) ) { |
print "$x " |
} |
} |
b) Another simple permutation is taking the last letter and putting it first (sometimes called a rotation). Find words for which this rotation is also a word. For example, rotating trumpets produces strumpet, or rotating elects produces select.
Hint: Use the function rotate in code sample 3.37 instead of reverse in code sample 3.36.
Code Sample 3.37 A function to move the last letter of a word to the front for problem 3.3.b.
sub rotate { |
my $word = $_[0]; |
my @1etters = split(//, $word); |
unshift(@1etters, pop(@1etters)); |
return join(’’, @1etters); |
} |
c) Create a function that is a rotation in the opposite sense of rotate in code sample 3.37. Then find all words that are still words under this new rotation. For example, rotating swear in this way produces wears. Question: how does this list compare with the list from problem 3.3.b?
3.4 Using a word list, for example, Grady Ward’s CROSSWD .TXT from the Moby Word Lists [123], find all the words where every letter appears exactly twice using a regex. For example, this is true of the word hotshots.
This property is called an isogram. For more information on these, see section 29 and figure 29c of Ross Eckler’s Making the Alphabet Dance [41].
First hint: Sort the letters of each word into alphabetical order, then try to create a regex that matches pairs of letters. Note that /^ ((w)1)+$/ seems promising, but does not work.
Second hint: define a pair of letters regex using qr// as shown below.
$pattern = qr/(w)1/;
Then use the regex /^$pattern+$/. This regex allows false positives (describe them), Is there a simple way to correct this?
3.5 One way to associate a numeric value to a word is as follows. Let A = 1, B = 2, C = 3, ..., and Z = 26, then for a given word, sum up its letter values, for example, cat produces 3 + 1 + 20, or 24. This method is sometimes used in word puzzles, for example, see section 59 of Ross Eckler’s Making the Alphabet Dance [41]. Here the goal is to write a function that takes a word and returns its number.
Code sample 3.38 shows one way to do this for all the numerical values at once using hash of hashes. To figure out how the code works, refer back to section 3.8.2. The function ord changes an ASCII character into a number, which makes it easy to convert a to 1, 1 to 2, and so forth. The function map applies a function defined with $_ as its argument to every entry in an array. For more information on this command, try looking it up online al http://perldoc.perl.org/[3]. Finally, note that using an array of hashes is another approach to this task.
Code Sample 3.38 Assuming that WORDS is a filehandle to word list, this code finds all words having the same numerical value using the procedure given in problem 3.5.
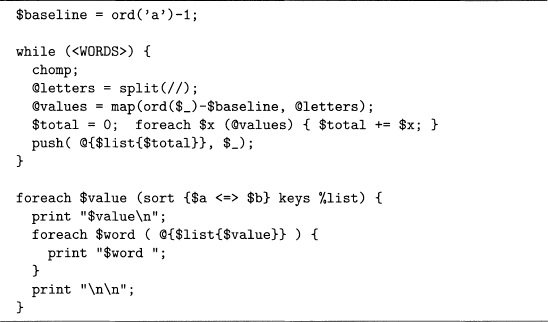
a) Perhaps this problem can be a start of a new type of pseudoscience. For your name, find out its value, then examine the words that share this value to discover possible clues to your personality (or love life, or career paths, ...). For example. the name Roger has the value 63, which is shared by acetone, catnip, and quiche Not surprisingly, these words describe me quite well.
b) Another numerology angle arises by concatenating the letter values together to form a string. For example, Roger becomes 18157518. It can happen that some numbers are associated with more than one word. For example, abode and lode both have the number 121545. For this problem write a Perl program that finds all such words. See the article Concatenating Letter Ranks [13] for more information.
3.6 Transaddition is the following process: take a word, add a letter such that all the letters can be rearranged to form a new word. For example, adding the letter t to learn produces antler (or learnt or rental). A transdeletion is the removal of a letter so that what remains can be rearranged into a word, for example, removing l from learn produces earn (or near). For an extensive discussion on these two ideas, see sections 41 and 49 of Ross Eckler’s Making the Alphabet Dance [41].
Code sample 3.39 shows how to take a word and find what words can be found by adding a letter and then rearranging all of them. Starting with this code, try changing it so that it can find transdeletions instead. Assume that WORDS is the filehandle for a word list.
Code Sample 3.39 Code to find all transadditions of a given word. For problem 3.6.

3.7 Lewis Carroll created the game called Doublets, where the goal is to transform one word into another (of the same length) by changing one letter at a time, and such that each intermediate step is itself a word. For example, red can be transformed into hot as follows: red, rod, rot, hot.
One approach to this is to create a word network that shows all the one-letter-change linkages. The programming task of creating and storing such a network in a (complex) data structure is challenging because the network can be quite large (depending on the number of letters), and it is possible to have loops in the network (the network is not a tree in the graph-theoretic sense).
This problem presents an easier task: given one word, find all other words that are only a one-letter change from the given word. For example, the words deashed, leached, and leashes are all exactly one letter different from leashed.
Here is one approach. Create a hash from a word list (using, for example, Grady Ward’s CROSSWD .TXT from the Moby Word Lists [123]). Then take the given word, replace the first letter by each letter of the alphabet. Check each of these potential words against the hash. Then do this for the second letter, and the third, and so forth. See code sample 3.40 to get started.
Code Sample 3.40 Hint on how to find all words that are one letter different from a specified word. For problem 3.7.
# $len = length of the word in $ARGV[0] |
# The keys of °hlist are from a word list |
for ($i = 0; $i < $len; ++$i) { |
foreach $letter ( ‘a’ .. ‘z’ ) { |
$word = $ARGV[0]; |
substr($word, $i, 1) = $letter; |
if ( exists($list{$word}) and $word ne $ARGV[0]) { |
print "$word "; |
} |
} |
} |
Finally, for more information on Doublets, see chapter 22 of Tony Augarde’s The Oxford Guide to Word Games [5]. Moreover, sections 42 through 44 of Ross Eckler’s Making the Alphabet Dance [41] give examples of word networks.
3.8 With HTML, it is possible to encode a variety of information by modifying the font in various ways. This problem considers one such example. Section 3.6.1 shows how to compute word frequencies. Given these frequencies, the task here is to convert them into font sizes, which are then used to write an HTML page.
Code sample 3.41 assumes that the hash %size contains font sizes in points for each word in Poe’s “The Black Cat.” The HTML is printed to the file BlackCat . html.
These font sizes are based on word counts using all of Poe’s short stories, and $size{$word} was set to the function below.
int(1 .5*log($freq)+12.5)
In this case, the frequencies went from 1 to 24,401, so the this function reduces this wide range of counts to a range appropriate for font sizes. Output 3.33 has the beginning of the HTML that is produced by this code.
For a text of your own choosing, create a word frequency list, and then modify the frequencies to create font sizes.
3.9 Section 3.7.2.2 shows how to find distinct words that have the same letters, but in different orders, which are called anagrams. The same idea is applicable to numerals. For example, are there many square numbers with anagrams that are also square numbers? Examples are the squares 16,384 (equals 1282), 31,684 (1782), 36,481 (1912), 38,416 (1962), and 43,681 (2092), and all five of these five-digit numbers use the same digits. This is called an anasquare.
Code Sample 3.41 Code to vary font size in an HTML document. For problem 3.8.

Output 3.33 A few lines from code sample 3.41.
<html> |
<body> |
<marquee> |
<span style="font–size :24pt">FOR</span> |
<span style="font–size :27pt">the</span> |
<span style="font–size :2lpt">most</span> |
<span style="font–size :l9pt">wild,</span> |
<span style="font–size :2lpt">yet</span> |
<span style="font–size :2lpt">most</span> |
<span style="font–size :l2pt">homely</span> |
<span style="font–size :l6pt">narrative</span> |
<span style="font–size :24pt">which</span> |
Although word anagrams are not that common, this is not true for anasquares. See “Anasquares: Square anagrams of squares” [14] for a discussion of this.
3.10 As noted in problem 2.9.b, at present, there are plenty of DNA sequences available to the public at the National Center for Biotechnology Information (NCBI) at its Web page: http://www.ncbi.nlm.nih.gov/[81].
Since DNA is text (though its words and grammar are mostly unknown), it makes sense to use Perl and regexes to analyze DNA, which is exactly the point made in Perl for Exp1oring DNA by Mark LeBlanc and Betsey Dexter Dyer [70]. Note that these authors also enjoy word games, and they introduce the idea of text patterns in DNA by analyzing letter patterns in English words. Even without a background in biology, the book is quite readable, and I recommend it.
For this problem, get a copy of LeBlanc and Dyer’s book and see how they use Perl for DNA pattern finding. With the data of the NCBI, perhaps you can discover something notable.