
![]()
Customizing Git
So far, we’ve covered the basics of how Git works and how to use it, and we’ve introduced a number of tools that Git provides to help you use it easily and efficiently. In this chapter, we’ll see how you can make Git operate in a more customized fashion, by introducing several important configuration settings and the hooks system. With these tools, it’s easy to get Git to work exactly the way you, your company, or your group needs it to.
Git Configuration
As you briefly saw in Chapter 1, you can specify Git configuration settings with the git config command. One of the first things you did was set up your name and e-mail address:
$ git config --global user.name "John Doe"
$ git config --global user.email [email protected]
Now you’ll learn a few of the more interesting options that you can set in this manner to customize your Git usage.
First, a quick review: Git uses a series of configuration files to determine non-default behavior that you may want. The first place Git looks for these values is in an /etc/gitconfig file, which contains values for every user on the system and all their repositories. If you pass the option --system to git config, it reads and writes from this file specifically.
The next place Git looks is the ~/.gitconfig (or ~/.config/git/config) file, which is specific to each user. You can make Git read and write to this file by passing the --global option.
Finally, Git looks for configuration values in the configuration file in the Git directory (.git/config) of whatever repository you’re currently using. These values are specific to that single repository.
Each of these “levels” (system, global, local) overwrites values in the previous level, so values in .git/config trump those in /etc/gitconfig, for instance.
![]() Note Git’s configuration files are plain-text, so you can also set these values by manually editing the file and inserting the correct syntax. It’s generally easier to run the git config command, though.
Note Git’s configuration files are plain-text, so you can also set these values by manually editing the file and inserting the correct syntax. It’s generally easier to run the git config command, though.
Basic Client Configuration
The configuration options recognized by Git fall into two categories: client-side and server-side. The majority of the options are client-side—configuring your personal working preferences. Many, many configuration options are supported, but a large fraction of them are only useful in certain edge cases. We’ll only be covering the most common and most useful here. If you want to see a list of all the options your version of Git recognizes, you can run
$ man git-config
This command lists all the available options in quite a bit of detail. You can also find this reference material at http://git-scm.com/docs/git-config.html.
core.editor
By default, Git uses whatever you’ve set as your default text editor ($VISUAL or $EDITOR) or else falls back to the vi editor to create and edit your commit and tag messages. To change that default to something else, you can use the core.editor setting:
$ git config --global core.editor emacs
Now, no matter what is set as your default shell editor, Git will fire up Emacs to edit messages.
commit.template
If you set this to the path of a file on your system, Git will use that file as the default message when you commit. For instance, suppose you create a template file at ~/.gitmessage.txt that looks like this:
subject line
what happened
[ticket: X]
To tell Git to use it as the default message that appears in your editor when you run git commit, set the commit.template configuration value:
$ git config --global commit.template ~/.gitmessage.txt
$ git commit
Then, your editor will open to something like this for your placeholder commit message when you commit:
subject line
what happened
[ticket: X]
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: lib/test.rb
#
~
~
".git/COMMIT_EDITMSG" 14L, 297C
If your team has a commit-message policy, then putting a template for that policy on your system and configuring Git to use it by default can help increase the chance of that policy being followed regularly.
core.pager
This setting determines which pager is used when Git pages output such as log and diff. You can set it to more or to your favorite pager (by default, it’s less), or you can turn it off by setting it to a blank string:
$ git config --global core.pager ''
If you run that, Git will page the entire output of all commands, no matter how long they are.
user.signingkey
If you’re making signed annotated tags, setting your GPG signing key as a configuration setting makes things easier. Set your key ID like so:
$ git config --global user.signingkey <gpg-key-id>
Now, you can sign tags without having to specify your key every time with the git tag command:
$ git tag -s <tag-name>
core.excludesfile
You can put patterns in your project’s .gitignore file to have Git not see them as untracked files or try to stage them when you run git add on them.
But sometimes you want to ignore certain files for all repositories that you work with. If your computer is running Mac OS X, you’re probably familiar with .DS_Store files. If your preferred editor is Emacs or Vim, you know about files that end with a ~.
This setting lets you write a kind of global .gitignore file. If you create a ~/.gitignore_global file with these contents:
*~
.DS_Store
...and you run git config --global core.excludesfile ~/.gitignore_global, Git will never again bother you about those files.
help.autocorrect
If you mistype a command, it shows you something like this:
$ git chekcout master
git: 'chekcout' is not a git command. See 'git --help'.
Did you mean this?
checkout
Git helpfully tries to figure out what you meant, but it still refuses to do it. If you set help.autocorrect to 1, Git will actually run this command for you:
$ git chekcout master
WARNING: You called a Git command named 'chekcout', which does not exist.
Continuing under the assumption that you meant 'checkout'
in 0.1 seconds automatically...
Note that “0.1 seconds” business. help.autocorrect is actually an integer which represents tenths of a second. So if you set it to 50, Git will give you 5 seconds to change your mind before executing the autocorrected command.
Colors in Git
Git fully supports colored terminal output, which greatly aids in visually parsing command output quickly and easily. A number of options can help you set the coloring to your preference.
color.ui
Git automatically colors most of its output, but there’s a master switch if you don’t like this behavior. To turn off all Git’s colored terminal output, do this:
$ git config --global color.ui false
The default setting is auto, which colors output when it’s going straight to a terminal, but omits the color-control codes when the output is redirected to a pipe or a file.
You can also set it to always to ignore the difference between terminals and pipes. You’ll rarely want this; in most scenarios, if you want color codes in your redirected output, you can instead pass a --color flag to the Git command to force it to use color codes. The default setting is almost always what you’ll want.
color.*
If you want to be more specific about which commands are colored and how, Git provides verb-specific coloring settings. Each of these can be set to true, false, or always:
color.branch
color.diff
color.interactive
color.status
In addition, each of these has subsettings you can use to set specific colors for parts of the output, if you want to override each color. For example, to set the meta information in your diff output to blue foreground, black background, and bold text, you can run
$ git config --global color.diff.meta "blue black bold"
You can set the color to any of the following values: normal, black, red, green, yellow, blue, magenta, cyan, or white. If you want an attribute like bold in the previous example, you can choose from bold, dim, ul (underline), blink, and reverse (swap foreground and background).
External Merge and Diff Tools
Although Git has an internal implementation of diff, which is what we’ve been showing in this book, you can set up an external tool instead. You can also set up a graphical merge-conflict-resolution tool instead of having to resolve conflicts manually. We’ll demonstrate setting up the Perforce Visual Merge Tool (P4Merge) to do your diffs and merge resolutions, because it’s a nice graphical tool and it’s free.
If you want to try this out, P4Merge works on all major platforms, so you should be able to do so. I’ll use path names in the examples that work on Mac and Linux systems; for Windows, you’ll have to change /usr/local/bin to an executable path in your environment.
To begin, download P4Merge from http://www.perforce.com/downloads/Perforce/. Next, you’ll set up external wrapper scripts to run your commands. I’ll use the Mac path for the executable; in other systems, it will be where your p4merge binary is installed. Set up a merge wrapper script named extMerge that calls your binary with all the arguments provided:
$ cat /usr/local/bin/extMerge
#!/bin/sh
/Applications/p4merge.app/Contents/MacOS/p4merge $*
The diff wrapper checks to make sure seven arguments are provided and passes two of them to your merge script. By default, Git passes the following arguments to the diff program:
path old-file old-hex old-mode new-file new-hex new-mode
Because you only want the old-file and new-file arguments, you use the wrapper script to pass the ones you need.
$ cat /usr/local/bin/extDiff
#!/bin/sh
[$# -eq 7 ] && /usr/local/bin/extMerge "$2" "$5"
You also need to make sure these tools are executable:
$ sudo chmod +x /usr/local/bin/extMerge
$ sudo chmod +x /usr/local/bin/extDiff
Now you can set up your config file to use your custom merge resolution and diff tools. This takes a number of custom settings: merge.tool to tell Git what strategy to use, mergetool.*.cmd to specify how to run the command, mergetool.trustExitCode to tell Git if the exit code of that program indicates a successful merge resolution or not, and diff.external to tell Git what command to run for diffs. So, you can either run four config commands
$ git config --global merge.tool extMerge
$ git config --global mergetool.extMerge.cmd
'extMerge "$BASE" "$LOCAL" "$REMOTE" "$MERGED"'
$ git config --global mergetool.trustExitCode false
$ git config --global diff.external extDiff
or you can edit your ~/.gitconfig file to add these lines:
[merge]
tool = extMerge
[mergetool "extMerge"]
cmd = extMerge "$BASE" "$LOCAL" "$REMOTE" "$MERGED"
trustExitCode = false
[diff]
external = extDiff
After all this is set, if you run diff commands such as this:
$ git diff 32d1776b1^ 32d1776b1
Instead of getting the diff output on the command line, Git fires up P4Merge, which looks something like this:
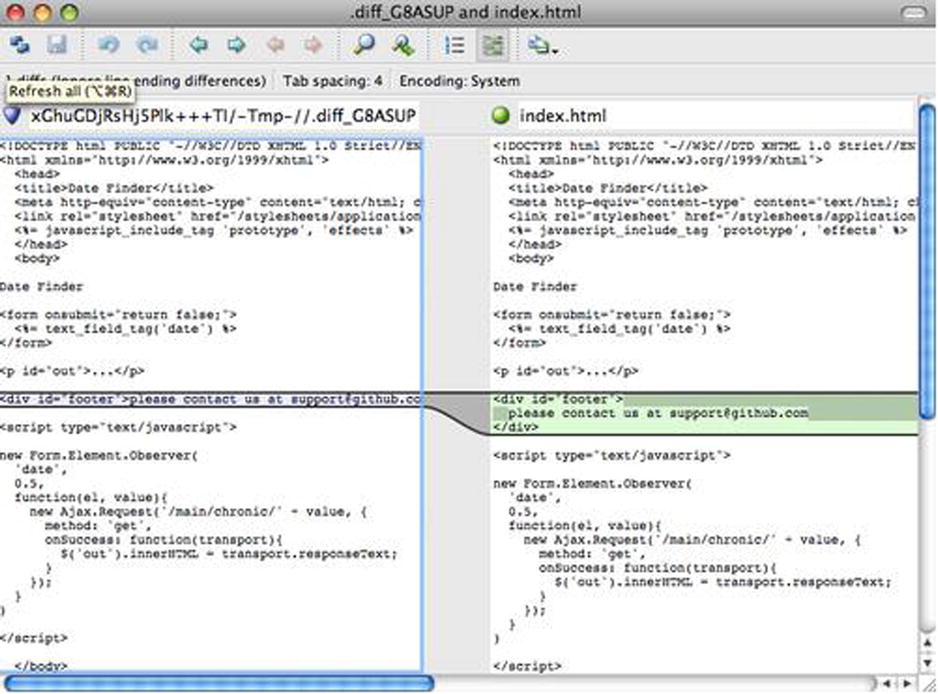
Figure 8-1. P4Merge
If you try to merge two branches and subsequently have merge conflicts, you can run the command git mergetool; it starts P4Merge to let you resolve the conflicts through that GUI tool.
The nice thing about this wrapper setup is that you can change your diff and merge tools easily. For example, to change your extDiff and extMerge tools to run the KDiff3 tool instead, all you have to do is edit your extMerge file:
$ cat /usr/local/bin/extMerge
#!/bin/sh
/Applications/kdiff3.app/Contents/MacOS/kdiff3 $*
Now, Git will use the KDiff3 tool for diff viewing and merge conflict resolution.
Git comes preset to use a number of other merge-resolution tools without your having to set up the cmd configuration. To see a list of the tools it supports, try this:
$ git mergetool --tool-help
'git mergetool --tool=<tool>' may be set to one of the following:
emerge
gvimdiff
gvimdiff2
opendiff
p4merge
vimdiff
vimdiff2
The following tools are valid, but not currently available:
araxis
bc3
codecompare
deltawalker
diffmerge
diffuse
ecmerge
kdiff3
meld
tkdiff
tortoisemerge
xxdiff
Some of the tools listed above only work in a windowed environment. If run in a terminal-only session, they will fail.
If you’re not interested in using KDiff3 for diff but rather want to use it just for merge resolution, and the kdiff3 command is in your path, then you can run
$ git config --global merge.tool kdiff3
If you run this instead of setting up the extMerge and extDiff files, Git will use KDiff3 for merge resolution and the normal Git diff tool for diffs.
Formatting and Whitespace
Formatting and whitespace issues are some of the more frustrating and subtle problems that many developers encounter when collaborating, especially cross-platform. It’s very easy for patches or other collaborated work to introduce subtle whitespace changes because editors silently introduce them, and if your files ever touch a Windows system, their line endings might be replaced. Git has a few configuration options to help with these issues.
core.autocrlf
If you’re programming on Windows and working with people who are not (or vice versa), you’ll probably run into line-ending issues at some point. This is because Windows uses both a carriage-return character and a linefeed character for newlines in its files, whereas Mac and Linux systems use only the linefeed character. This is a subtle but incredibly annoying fact of cross-platform work; many editors on Windows silently replace existing LF-style line endings with CRLF, or insert both line-ending characters when the user hits the enter key.
Git can handle this by auto-converting CRLF line endings into LF when you add a file to the index, and vice versa when it checks out code onto your filesystem. You can turn on this functionality with the core.autocrlf setting. If you’re on a Windows machine, set it to true—this converts LF endings into CRLF when you check out code:
$ git config --global core.autocrlf true
If you’re on a Linux or Mac system that uses LF line endings, then you don’t want Git to automatically convert them when you check out files; however, if a file with CRLF endings accidentally gets introduced, then you may want Git to fix it. You can tell Git to convert CRLF to LF on commit but not the other way around by setting core.autocrlf to input:
$ git config --global core.autocrlf input
This setup should leave you with CRLF endings in Windows checkouts, but LF endings on Mac and Linux systems and in the repository.
If you’re a Windows programmer doing a Windows-only project, then you can turn off this functionality, recording the carriage returns in the repository by setting the config value to false:
$ git config --global core.autocrlf false
core.whitespace
Git comes preset to detect and fix some whitespace issues. It can look for six primary whitespace issues—three are enabled by default and can be turned off, and three are disabled by default but can be activated.
The ones that are turned on by default are blank-at-eol, which looks for spaces at the end of a line; blank-at-eof, which notices blank lines at the end of a file; and space-before-tab, which looks for spaces before tabs at the beginning of a line.
The three that are disabled by default but can be turned on are indent-with-non-tab, which looks for lines that begin with spaces instead of tabs (and is controlled by the tabwidth option); tab-in-indent, which watches for tabs in the indentation portion of a line; and cr-at-eol, which tells Git that carriage returns at the end of lines are OK.
You can tell Git which of these you want enabled by setting core.whitespace to the values you want on or off, separated by commas. You can disable settings by either leaving them out of the setting string or prepending a - in front of the value. For example, if you want all but cr-at-eol to be set, you can do this:
$ git config --global core.whitespace
trailing-space,space-before-tab,indent-with-non-tab
Git will detect these issues when you run a git diff command and try to color them so you can possibly fix them before you commit. It will also use these values to help you when you apply patches with git apply. When you’re applying patches, you can ask Git to warn you if it’s applying patches with the specified whitespace issues:
$ git apply --whitespace=warn <patch>
Or you can have Git try to automatically fix the issue before applying the patch:
$ git apply --whitespace=fix <patch>
These options apply to the git rebase command as well. If you’ve committed whitespace issues but haven’t yet pushed upstream, you can run git rebase --whitespace=fix to have Git automatically fix whitespace issues as it’s rewriting the patches.
Server Configuration
Not nearly as many configuration options are available for the server side of Git, but there are a few interesting ones you may want to take note of.
receive.fsckObjects
Git is capable of making sure every object received during a push still matches its SHA-1 checksum and points to valid objects. However, it doesn’t do this by default; it’s a fairly expensive operation, and might slow down the operation, especially on large repositories or pushes. If you want Git to check object consistency on every push, you can force it to do so by setting receive.fsckObjects to true:
$ git config --system receive.fsckObjects true
Now, Git will check the integrity of your repository before each push is accepted to make sure faulty (or malicious) clients aren’t introducing corrupt data.
receive.denyNonFastForwards
If you rebase commits that you’ve already pushed and then try to push again, or otherwise try to push a commit to a remote branch that doesn’t contain the commit that the remote branch currently points to, you’ll be denied. This is generally good policy; but in the case of the rebase, you may determine that you know what you’re doing and can force-update the remote branch with a -f flag to your push command.
To tell Git to refuse force-pushes, set receive.denyNonFastForwards:
$ git config --system receive.denyNonFastForwards true
The other way you can do this is via server-side receive hooks, which we’ll cover in a bit. That approach lets you do more complex things like deny non-fast-forwards to a certain subset of users.
receive.denyDeletes
One of the workarounds to the denyNonFastForwards policy is for the user to delete the branch and then push it back up with the new reference. To avoid this, set receive.denyDeletes to true:
$ git config --system receive.denyDeletes true
This denies any deletion of branches or tags – no user can do it. To remove remote branches, you must remove the ref files from the server manually. There are also more interesting ways to do this on a per-user basis via ACLs, as you’ll learn later.
Git Attributes
Some of these settings can also be specified for a path, so that Git applies those settings only for a subdirectory or subset of files. These path-specific settings are called Git attributes and are set either in a .gitattributes file in one of your directories (normally the root of your project) or in the .git/info/attributes file if you don’t want the attributes file committed with your project.
Using attributes, you can do things like specify separate merge strategies for individual files or directories in your project, tell Git how to diff non-text files, or have Git filter content before you check it into or out of Git. In this section, you’ll learn about some of the attributes you can set on your paths in your Git project and see a few examples of using this feature in practice.
Binary Files
One cool trick for which you can use Git attributes is telling Git which files are binary (in cases it otherwise may not be able to figure out) and giving Git special instructions about how to handle those files. For instance, some text files may be machine generated and not diffable, whereas some binary files can be diffed. You’ll see how to tell Git which is which.
Identifying Binary Files
Some files look like text files but for all intents and purposes are to be treated as binary data. For instance, Xcode projects on the Mac contain a file that ends in .pbxproj, which is basically a JSON (plain-text Javascript data format) dataset written out to disk by the IDE, which records your build settings, and so on. Although it’s technically a text file (because it’s all UTF-8), you don’t want to treat it as such because it’s really a lightweight database—you can’t merge the contents if two people change it, and diffs generally aren’t helpful. The file is meant to be consumed by a machine. In essence, you want to treat it like a binary file.
To tell Git to treat all .pbxproj files as binary data, add the following line to your .gitattributes file:
*.pbxproj binary
Now, Git won’t try to convert or fix CRLF issues; nor will it try to compute or print a diff for changes in this file when you run git show or git diff on your project.
Diffing Binary Files
You can also use the Git attributes functionality to effectively diff binary files. You do this by telling Git how to convert your binary data to a text format that can be compared via the normal diff.
Because this is a pretty cool and not widely known feature, we’ll go over a few examples. First, you’ll use this technique to solve one of the most annoying problems known to humanity: version-controlling Microsoft Word documents. Everyone knows that Word is the most horrific editor around, but oddly, everyone still uses it. If you want to version-control Word documents, you can stick them in a Git repository and commit every once in a while; but what good does that do? If you run git diff normally, you only see something like this:
$ git diff
diff --git a/chapter1.docx b/chapter1.docx
index 88839c4..4afcb7c 100644
Binary files a/chapter1.docx and b/chapter1.docx differ
You can’t directly compare two versions unless you check them out and scan them manually, right? It turns out you can do this fairly well using Git attributes. Put the following line in your .gitattributes file:
*.docx diff=word
This tells Git that any file that matches this pattern (.docx) should use the “word” filter when you try to view a diff that contains changes. What is the “word” filter? You have to set it up. Here you’ll configure Git to use the docx2txt program to convert Word documents into readable text files, which it will then diff properly.
First, you’ll need to install docx2txt; you can download it from http://docx2txt.sourceforge.net. Follow the instructions in the INSTALL file to put it somewhere your shell can find it. Next, you’ll write a wrapper script to convert output to the format Git expects. Create a file that’s somewhere in your path called docx2txt, and add these contents:
#!/bin/bash
docx2txt.pl $1 -
Don’t forget to chmod a+x that file. Finally, you can configure Git to use this script:
$ git config diff.word.textconv docx2txt
Now Git knows that if it tries to do a diff between two snapshots, and any of the files end in .docx, it should run those files through the “word” filter, which is defined as the docx2txt program. This effectively makes nice text-based versions of your Word files before attempting to diff them.
Here’s an example: Chapter 1 of this book was converted to Word format and committed in a Git repository. Then a new paragraph was added. Here’s what git diff shows:
$ git diff
diff --git a/chapter1.docx b/chapter1.docx
index 0b013ca..ba25db5 100644
--- a/chapter1.docx
+++ b/chapter1.docx
@@ -2,6 +2,7 @@
This chapter will be about getting started with Git. We will begin at the beginning by explaining some background on version control tools, then move on to how to get Git running on your system and finally how to get it setup to start working with. At the end of this chapter you should understand why Git is around, why you should use it and you should be all setup to do so.
1.1. About Version Control
What is “version control”, and why should you care? Version control is a system that records changes to a file or set of files over time so that you can recall specific versions later. For the examples in this book you will use software source code as the files being version controlled, though in reality you can do this with nearly any type of file on a computer.
+Testing: 1, 2, 3.
If you are a graphic or web designer and want to keep every version of an image or layout (which you would most certainly want to), a Version Control System (VCS) is a very wise thing to use. It allows you to revert files back to a previous state, revert the entire project back to a previous state, compare changes over time, see who last modified something that might be causing a problem, who introduced an issue and when, and more. Using a VCS also generally means that if you screw things up or lose files, you can easily recover. In addition, you get all this for very little overhead.
1.1.1. Local Version Control Systems
Many people's version-control method of choice is to copy files into another directory (perhaps a time-stamped directory, if they're clever). This approach is very common because it is so simple, but it is also incredibly error prone. It is easy to forget which directory you're in and accidentally write to the wrong file or copy over files you don't mean to.
Git successfully and succinctly tells me that I added the string “Testing: 1, 2, 3.”, which is correct. It’s not perfect—formatting changes wouldn’t show up here—but it certainly works.
Another interesting problem you can solve this way involves diffing image files. One way to do this is to run JPEG files through a filter that extracts their EXIF information—metadata that is recorded with most image formats. If you download and install the exiftool program, you can use it to convert your images into text about the metadata, so at least the diff will show you a textual representation of any changes that happened:
$ echo '*.png diff=exif' >> .gitattributes
$ git config diff.exif.textconv exiftool
If you replace an image in your project and run git diff, you see something like this:
diff --git a/image.png b/image.png
index 88839c4..4afcb7c 100644
--- a/image.png
+++ b/image.png
@@ -1,12 +1,12 @@
ExifTool Version Number : 7.74
-File Size : 70 kB
-File Modification Date/Time : 2009:04:21 07:02:45-07:00
+File Size : 94 kB
+File Modification Date/Time : 2009:04:21 07:02:43-07:00
File Type : PNG
MIME Type : image/png
-Image Width : 1058
-Image Height : 889
+Image Width : 1056
+Image Height : 827
Bit Depth : 8
Color Type : RGB with Alpha
You can easily see that the file size and image dimensions have both changed.
Keyword Expansion
SVN- or CVS-style keyword expansion is often requested by developers used to those systems. The main problem with this in Git is that you can’t modify a file with information about the commit after you’ve committed, because Git checksums the file first. However, you can inject text into a file when it’s checked out and remove it again before it’s added to a commit. Git attributes offers you two ways to do this.
First, you can inject the SHA-1 checksum of a blob into an $Id$ field in the file automatically. If you set this attribute on a file or set of files, then the next time you check out that branch, Git will replace that field with the SHA-1 of the blob. It’s important to notice that it isn’t the SHA of the commit, but of the blob itself:
$ echo '*.txt ident' >> .gitattributes
$ echo '$Id$' > test.txt
The next time you check out this file, Git injects the SHA of the blob:
$ rm text.txt
$ git checkout -- text.txt
$ cat test.txt
$Id: 42812b7653c7b88933f8a9d6cad0ca16714b9bb3 $
However, that result is of limited use. If you’ve used keyword substitution in CVS or Subversion, you can include a datestamp—the SHA isn’t all that helpful, because it’s fairly random and you can’t tell if one SHA is older or newer than another just by looking at them.
It turns out that you can write your own filters for doing substitutions in files on commit/checkout. These are called “clean” and “smudge” filters. In the .gitattributes file, you can set a filter for particular paths and then set up scripts that will process files just before they’re checked out (the smudge filter is run on checkout) and just before they’re staged (the clean filter is run when files are staged). These filters can be set to do all sorts of fun things.
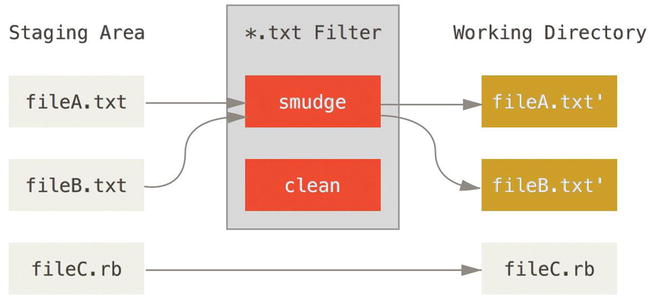
Figure 8-2. The “smudge” filter is run on checkout
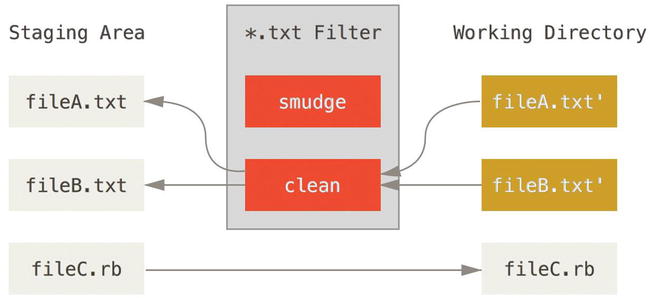
Figure 8-3. The “clean” filter is run when files are staged
The original commit message for this feature gives a simple example of running all your C source code through the indent program before committing. You can set it up by setting the filter attribute in your .gitattributes file to filter *.c files with the indent filter:
*.c filter=indent
Then, tell Git what the indent filter does on smudge and clean:
$ git config --global filter.indent.clean indent
$ git config --global filter.indent.smudge cat
In this case, when you commit files that match *.c, Git will run them through the indent program before it stages them and then run them through the cat program before it checks them back out onto disk. The cat program does essentially nothing: it spits out the same data that it comes in. This combination effectively filters all C source code files through indent before committing.
Another interesting example gets $Date$ keyword expansion, RCS style. To do this properly, you need a small script that takes a filename, figures out the last commit date for this project, and inserts the date into the file. Here is a small Ruby script that does that:
#! /usr/bin/env ruby
data = STDIN.read
last_date = `git log --pretty=format:"%ad" -1`
puts data.gsub('$Date$', '$Date: ' + last_date.to_s + '$')
All the script does is get the latest commit date from the git log command, stick that into any $Date$ strings it sees in stdin, and print the results – it should be simple to do in whatever language you’re most comfortable in. You can name this file expand_date and put it in your path. Now, you need to set up a filter in Git (call it dater) and tell it to use your expand_date filter to smudge the files on checkout. You’ll use a Perl expression to clean that up on commit:
$ git config filter.dater.smudge expand_date
$ git config filter.dater.clean 'perl -pe "s/\$Date[^\$]*\$/\$Date\$/"'
This Perl snippet strips out anything it sees in a $Date$ string, to get back to where you started. Now that your filter is ready, you can test it by setting up a file with your $Date$ keyword and then setting up a Git attribute for that file that engages the new filter:
$ echo '# $Date$' > date_test.txt
$ echo 'date*.txt filter=dater' >> .gitattributes
If you commit those changes and check out the file again, you see the keyword properly substituted:
$ git add date_test.txt .gitattributes
$ git commit -m "Testing date expansion in Git"
$ rm date_test.txt
$ git checkout date_test.txt
$ cat date_test.txt
# $Date: Tue Apr 21 07:26:52 2009 -0700$
You can see how powerful this technique can be for customized applications. You have to be careful, though, because the .gitattributes file is committed and passed around with the project, but the driver (in this case, dater) isn’t, so it won’t work everywhere. When you design these filters, they should be able to fail gracefully and have the project still work properly.
Exporting Your Repository
Git attribute data also allows you to do some interesting things when exporting an archive of your project.
export-ignore
You can tell Git not to export certain files or directories when generating an archive. If there is a subdirectory or file that you don’t want to include in your archive file but that you do want checked into your project, you can determine those files via the export-ignore attribute.
For example, say you have some test files in a test/ subdirectory, and it doesn’t make sense to include them in the tarball export of your project. You can add the following line to your Git attributes file:
test/ export-ignore
Now, when you run git archive to create a tarball of your project, that directory won’t be included in the archive.
export-subst
Another thing you can do for your archives is some simple keyword substitution. Git lets you put the string $Format:$ in any file with any of the --pretty=format formatting shortcodes, many of which you saw in Chapter 2. For instance, if you want to include a file named LAST_COMMIT in your project, and the last commit date was automatically injected into it when git archive ran, you can set up the file like this:
$ echo 'Last commit date: $Format:%cd$' > LAST_COMMIT
$ echo "LAST_COMMIT export-subst" >> .gitattributes
$ git add LAST_COMMIT .gitattributes
$ git commit -am 'adding LAST_COMMIT file for archives'
When you run git archive, the contents of that file when people open the archive file will look like this:
$ cat LAST_COMMIT
Last commit date: $Format:Tue Apr 21 08:38:48 2009 -0700$
Merge Strategies
You can also use Git attributes to tell Git to use different merge strategies for specific files in your project. One very useful option is to tell Git to not try to merge specific files when they have conflicts, but rather to use your side of the merge over someone else’s.
This is helpful if a branch in your project has diverged or is specialized, but you want to be able to merge changes back in from it, and you want to ignore certain files. Say you have a database settings file called database.xml that is different in two branches, and you want to merge in your other branch without messing up the database file. You can set up an attribute like this:
database.xml merge=ours
If you merge in the other branch, instead of having merge conflicts with the database.xml file, you see something like this:
$ git merge topic
Auto-merging database.xml
Merge made by recursive.
In this case, database.xml stays at whatever version you originally had.
Git Hooks
Like many other Version Control Systems, Git has a way to fire off custom scripts when certain important actions occur. There are two groups of these hooks: client-side and server-side. Client-side hooks are triggered by operations such as committing and merging, while server-side hooks run on network operations such as receiving pushed commits. You can use these hooks for all sorts of reasons.
Installing a Hook
The hooks are all stored in the hooks subdirectory of the Git directory. In most projects, that’s .git/hooks. When you initialize a new repository with git init, Git populates the hooks directory with a bunch of example scripts, many of which are useful by themselves; but they also document the input values of each script. All the examples are written as shell scripts, with some Perl thrown in, but any properly named executable scripts will work fine—you can write them in Ruby or Python or what have you. If you want to use the bundled hook scripts, you’ll have to rename them; their filenames all end with sample.
To enable a hook script, put a file in the hooks subdirectory of your Git directory that is named appropriately and is executable. From that point forward, it should be called. I’ll cover most of the major hook filenames here.
Client-Side Hooks
There are a lot of client-side hooks. This section splits them into committing-workflow hooks, e-mail-workflow scripts, and everything else.
![]() Note It’s important to note that client-side hooks are not copied when you clone a repository. If your intent with these scripts is to enforce a policy, you’ll probably want to do that on the server side.
Note It’s important to note that client-side hooks are not copied when you clone a repository. If your intent with these scripts is to enforce a policy, you’ll probably want to do that on the server side.
Committing-Workflow Hooks
The first four hooks have to do with the committing process.
The pre-commit hook is run first, before you even type in a commit message. It’s used to inspect the snapshot that’s about to be committed, to see if you’ve forgotten something, to make sure tests run, or to examine whatever you need to inspect in the code. Exiting non-zero from this hook aborts the commit, although you can bypass it with git commit --no-verify. You can do things like check for code style (run lint or something equivalent), check for trailing whitespace (the default hook does exactly this), or check for appropriate documentation on new methods.
The prepare-commit-msg hook is run before the commit message editor is fired up but after the default message is created. It lets you edit the default message before the commit author sees it. This hook takes a few parameters: the path to the file that holds the commit message so far, the type of commit, and the commit SHA-1 if this is an amended commit. This hook generally isn’t useful for normal commits; rather, it’s good for commits where the default message is auto-generated, such as templated commit messages, merge commits, squashed commits, and amended commits. You may use it in conjunction with a commit template to programmatically insert information.
The commit-msg hook takes one parameter, which again is the path to a temporary file that contains the commit message written by the developer. If this script exits non-zero, Git aborts the commit process, so you can use it to validate your project state or commit message before allowing a commit to go through. In the last section of this chapter, I’ll demonstrate using this hook to check that your commit message is conformant to a required pattern.
After the entire commit process is completed, the post-commit hook runs. It doesn’t take any parameters, but you can easily get the last commit by running git log -1 HEAD. Generally, this script is used for notification or something similar.
E-mail Workflow Hooks
You can set up three client-side hooks for an e-mail-based workflow. They’re all invoked by the git am command, so if you aren’t using that command in your workflow, you can safely skip to the next section. If you’re taking patches over e-mail prepared by git format-patch, then some of these may be helpful to you.
The first hook that is run is applypatch-msg. It takes a single argument: the name of the temporary file that contains the proposed commit message. Git aborts the patch if this script exits non-zero. You can use this to make sure a commit message is properly formatted, or to normalize the message by having the script edit it in place.
The next hook to run when applying patches via git am is pre-applypatch. Somewhat confusingly, it is run after the patch is applied but before a commit is made, so you can use it to inspect the snapshot before making the commit. You can run tests or otherwise inspect the working tree with this script. If something is missing or the tests don’t pass, exiting non-zero aborts the git am script without committing the patch.
The last hook to run during a git am operation is post-applypatch, which runs after the commit is made. You can use it to notify a group or the author of the patch you pulled in that you’ve done so. You can’t stop the patching process with this script.
Other Client Hooks
The pre-rebase hook runs before you rebase anything and can halt the process by exiting non-zero. You can use this hook to disallow rebasing any commits that have already been pushed. The example pre-rebase hook that Git installs does this, although it makes some assumptions that may not match with your workflow.
The post-rewrite hook is run by commands that replace commits, such as git commit --amend and git rebase (though not by git filter-branch). Its single argument is which command triggered the rewrite, and it receives a list of rewrites on stdin. This hook has many of the same uses as the post-checkout and post-merge hooks.
After you run a successful git checkout, the post-checkout hook runs; you can use it to set up your working directory properly for your project environment. This may mean moving in large binary files that you don’t want source controlled, auto-generating documentation, or something along those lines.
The post-merge hook runs after a successful merge command. You can use it to restore data in the working tree that Git can’t track, such as permissions data. This hook can likewise validate the presence of files external to Git control that you may want copied in when the working tree changes.
The pre-push hook runs during git push, after the remote refs have been updated but before any objects have been transferred. It receives the name and location of the remote as parameters, and a list of to-be-updated refs through stdin. You can use it to validate a set of ref updates before a push occurs (a non-zero exit code will abort the push).
Git occasionally does garbage collection as part of its normal operation, by invoking git gc --auto. The pre-auto-gc hook is invoked just before the garbage collection takes place, and can be used to notify you that this is happening, or to abort the collection if now isn’t a good time.
Server-Side Hooks
In addition to the client-side hooks, you can use a couple of important server-side hooks as a system administrator to enforce nearly any kind of policy for your project. These scripts run before and after pushes to the server. The pre hooks can exit non-zero at any time to reject the push as well as print an error message back to the client; you can set up a push policy that’s as complex as you wish.
pre-receive
The first script to run when handling a push from a client is pre-receive. It takes a list of references that are being pushed from stdin; if it exits non-zero, none of them are accepted. You can use this hook to do things like make sure none of the updated references are non-fast-forwards, or to do access control for all the refs and files they’re modifying with the push.
update
The update script is very similar to the pre-receive script, except that it’s run once for each branch the pusher is trying to update. If the pusher is trying to push to multiple branches, pre-receive runs only once, whereas update runs once per branch they’re pushing to. Instead of reading from stdin, this script takes three arguments: the name of the reference (branch), the SHA-1 that reference pointed to before the push, and the SHA-1 the user is trying to push. If the update script exits non-zero, only that reference is rejected; other references can still be updated.
post-receive
The post-receive hook runs after the entire process is completed and can be used to update other services or notify users. It takes the same stdin data as the pre-receive hook. Examples include e-mailing a list, notifying a continuous integration server, or updating a ticket-tracking system—you can even parse the commit messages to see if any tickets need to be opened, modified, or closed. This script can’t stop the push process, but the client doesn’t disconnect until it has completed, so be careful if you try to do anything that may take a long time.
An Example Git-Enforced Policy
In this section, you’ll use what you’ve learned to establish a Git workflow that checks for a custom commit message format, and allows only certain users to modify certain subdirectories in a project. You’ll build client scripts that help the developer know if their push will be rejected and server scripts that actually enforce the policies.
The scripts we’ll show are written in Ruby; partly because of our intellectual inertia, but also because Ruby is easy to read, even if you can’t necessarily write it. However, any language will work—all the sample hook scripts distributed with Git are in either Perl or Bash, so you can also see plenty of examples of hooks in those languages by looking at the samples.
Server-Side Hook
All the server-side work will go into the update file in your hooks directory. The update hook runs once per branch being pushed and takes three arguments:
- The name of the reference being pushed to
- The old revision where that branch was
- The new revision being pushed
You also have access to the user doing the pushing if the push is being run over SSH. If you’ve allowed everyone to connect with a single user (like “git”) via public-key authentication, you may have to give that user a shell wrapper that determines which user is connecting based on the public key, and set an environment variable accordingly. Here we’ll assume the connecting user is in the $USER environment variable, so your update script begins by gathering all the information you need:
#!/usr/bin/env ruby
$refname = ARGV[0]
$oldrev = ARGV[1]
$newrev = ARGV[2]
$user = ENV['USER']
puts "Enforcing Policies..."
puts "(#{$refname}) (#{$oldrev[0,6]}) (#{$newrev[0,6]})"
Yes, those are global variables. Don’t judge—it’s easier to demonstrate this way.
Enforcing a Specific Commit-Message Format
Your first challenge is to enforce that each commit message adheres to a particular format. Just to have a target, assume that each message has to include a string that looks like “ref: 1234” because you want each commit to link to a work item in your ticketing system. You must look at each commit being pushed up, see if that string is in the commit message, and, if the string is absent from any of the commits, exit non-zero so the push is rejected.
You can get a list of the SHA-1 values of all the commits that are being pushed by taking the $newrev and $oldrev values and passing them to a Git plumbing command called git rev-list. This is basically the git log command, but by default it prints out only the SHA-1 values and no other information.
So, to get a list of all the commit SHAs introduced between one commit SHA and another, you can run something like this:
$ git rev-list 538c33..d14fc7
d14fc7c847ab946ec39590d87783c69b031bdfb7
9f585da4401b0a3999e84113824d15245c13f0be
234071a1be950e2a8d078e6141f5cd20c1e61ad3
dfa04c9ef3d5197182f13fb5b9b1fb7717d2222a
17716ec0f1ff5c77eff40b7fe912f9f6cfd0e475
You can take that output, loop through each of those commit SHAs, grab the message for it, and test that message against a regular expression that looks for a pattern.
You have to figure out how to get the commit message from each of these commits to test. To get the raw commit data, you can use another plumbing command called git cat-file. We’ll go over all these plumbing commands in detail later; but for now, here’s what that command gives you:
$ git cat-file commit ca82a6
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
author Scott Chacon <[email protected]> 1205815931 -0700
committer Scott Chacon <[email protected]> 1240030591 -0700
changed the version number
A simple way to get the commit message from a commit when you have the SHA-1 value is to go to the first blank line and take everything after that. You can do so with the sed command on Unix systems:
$ git cat-file commit ca82a6 | sed '1,/^$/d'
changed the version number
You can use that incantation to grab the commit message from each commit that is trying to be pushed and exit if you see anything that doesn’t match. To exit the script and reject the push, exit non-zero. The whole method looks like this:
$regex = /[ref: (d+)]/
# enforced custom commit message format
def check_message_format
missed_revs = `git rev-list #{$oldrev}..#{$newrev}`.split(" ")
missed_revs.each do |rev|
message = `git cat-file commit #{rev} | sed '1,/^$/d'`
if !$regex.match(message)
puts "[POLICY] Your message is not formatted correctly"
exit 1
end
end
end
check_message_format
Putting that in your update script will reject updates that contain commits that have messages that don’t adhere to your rule.
Enforcing a User-Based ACL System
Suppose you want to add a mechanism that uses an access control list (ACL) that specifies which users are allowed to push changes to which parts of your projects. Some people have full access, and others can only push changes to certain subdirectories or specific files. To enforce this, you’ll write those rules to a file named acl that lives in your bare Git repository on the server. You’ll have the update hook look at those rules, see what files are being introduced for all the commits being pushed, and determine whether the user doing the push has access to update all those files.
The first thing you’ll do is write your ACL. Here you’ll use a format very much like the CVS ACL mechanism: it uses a series of lines, where the first field is avail or unavail, the next field is a comma-delimited list of the users to which the rule applies, and the last field is the path to which the rule applies (blank meaning open access). All of these fields are delimited by a pipe (|) character.
In this case, you have a couple of administrators, some documentation writers with access to the doc directory, and one developer who only has access to the lib and tests directories, and your ACL file looks like this:
avail|nickh,pjhyett,defunkt,tpw
avail|usinclair,cdickens,ebronte|doc
avail|schacon|lib
avail|schacon|tests
You begin by reading this data into a structure that you can use. In this case, to keep the example simple, you’ll only enforce the avail directives. Here is a method that gives you an associative array where the key is the user name and the value is an array of paths to which the user has write access:
def get_acl_access_data(acl_file)
# read in ACL data
acl_file = File.read(acl_file).split(" ").reject { |line| line == '' }
access = {}
acl_file.each do |line|
avail, users, path = line.split('|')
next unless avail == 'avail'
users.split(',').each do |user|
access[user] ||= []
access[user] << path
end
end
access
end
On the ACL file you looked at earlier, this get_acl_access_data method returns a data structure that looks like this:
{"defunkt"=>[nil],
"tpw"=>[nil],
"nickh"=>[nil],
"pjhyett"=>[nil],
"schacon"=>["lib", "tests"],
"cdickens"=>["doc"],
"usinclair"=>["doc"],
"ebronte"=>["doc"]}
Now that you have the permissions sorted out, you need to determine what paths the commits being pushed have modified, so you can make sure the user who’s pushing has access to all of them.
You can pretty easily see what files have been modified in a single commit with the --name-only option to the git log command (mentioned briefly in Chapter 2):
$ git log -1 --name-only --pretty=format:'' 9f585d
README
lib/test.rb
If you use the ACL structure returned from the get_acl_access_data method and check it against the listed files in each of the commits, you can determine whether the user has access to push all their commits:
# only allows certain users to modify certain subdirectories in a project
def check_directory_perms
access = get_acl_access_data('acl')
# see if anyone is trying to push something they can't
new_commits = `git rev-list #{$oldrev}..#{$newrev}`.split(" ")
new_commits.each do |rev|
files_modified = `git log -1 --name-only --pretty=format:'' #{rev}`.split(" ")
files_modified.each do |path|
next if path.size == 0
has_file_access = false
access[$user].each do |access_path|
if !access_path # user has access to everything
|| (path.start_with? access_path) # access to this path
has_file_access = true
end
end
if !has_file_access
puts "[POLICY] You do not have access to push to #{path}"
exit 1
end
end
end
end
check_directory_perms
You get a list of new commits being pushed to your server with git rev-list. Then, for each of those commits, you find which files are modified and make sure the user who’s pushing has access to all the paths being modified.
Now your users can’t push any commits with badly formed messages or with modified files outside of their designated paths.
Testing It Out
If you run chmod u+x .git/hooks/ update, which is the file you into which you should have put all this code, and then try to push a commit with a non-compliant message, you get something like this:
$ git push -f origin master
Counting objects: 5, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 323 bytes, done.
Total 3 (delta 1), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
Enforcing Policies...
(refs/heads/master) (8338c5) (c5b616)
[POLICY] Your message is not formatted correctly
error: hooks/update exited with error code 1
error: hook declined to update refs/heads/master
To git@gitserver:project.git
! [remote rejected] master -> master (hook declined)
error: failed to push some refs to 'git@gitserver:project.git'
There are a couple of interesting things here. First, you see this where the hook starts running.
Enforcing Policies...
(refs/heads/master) (fb8c72) (c56860)
Remember that you printed that out at the very beginning of your update script. Anything your script echoes to stdout will be transferred to the client.
The next thing you’ll notice is the error message.
[POLICY] Your message is not formatted correctly
error: hooks/update exited with error code 1
error: hook declined to update refs/heads/master
The first line was printed out by you, the other two were Git telling you that the update script exited non-zero and that is what is declining your push. Lastly, you have this:
To git@gitserver:project.git
! [remote rejected] master -> master (hook declined)
error: failed to push some refs to 'git@gitserver:project.git'
You’ll see a remote rejected message for each reference that your hook declined, and it tells you that it was declined specifically because of a hook failure.
Furthermore, if someone tries to edit a file they don’t have access to and push a commit containing it, they will see something similar. For instance, if a documentation author tries to push a commit modifying something in the lib directory, they see
[POLICY] You do not have access to push to lib/test.rb
From now on, as long as that update script is there and executable, your repository will never have a commit message without your pattern in it, and your users will be sandboxed.
Client-Side Hooks
The downside to this approach is the whining that will inevitably result when your users’ commit pushes are rejected. Having their carefully crafted work rejected at the last minute can be extremely frustrating and confusing; and furthermore, they will have to edit their history to correct it, which isn’t always for the faint of heart.
The answer to this dilemma is to provide some client-side hooks that users can run to notify them when they’re doing something that the server is likely to reject. That way, they can correct any problems before committing and before those issues become more difficult to fix. Because hooks aren’t transferred with a clone of a project, you must distribute these scripts some other way and then have your users copy them to their .git/hooks directory and make them executable. You can distribute these hooks within the project or in a separate project, but Git won’t set them up automatically.
To begin, you should check your commit message just before each commit is recorded, so you know the server won’t reject your changes due to badly formatted commit messages. To do this, you can add the commit-msg hook. If you have it read the message from the file passed as the first argument and compare that to the pattern, you can force Git to abort the commit if there is no match:
#!/usr/bin/env ruby
message_file = ARGV[0]
message = File.read(message_file)
$regex = /[ref: (d+)]/
if !$regex.match(message)
puts "[POLICY] Your message is not formatted correctly"
exit 1
end
If that script is in place (in .git/hooks/commit-msg) and executable, and you commit with a message that isn’t properly formatted, you see this:
$ git commit -am 'test'
[POLICY] Your message is not formatted correctly
No commit was completed in that instance. However, if your message contains the proper pattern, Git allows you to commit:
$ git commit -am 'test [ref: 132]'
[master e05c914] test [ref: 132]
1 file changed, 1 insertions(+), 0 deletions(-)
Next, you want to make sure you aren’t modifying files that are outside your ACL scope. If your project’s .git directory contains a copy of the ACL file you used previously, then the following pre-commit script will enforce those constraints for you:
#!/usr/bin/env ruby
$user = ENV['USER']
# [ insert acl_access_data method from above]
# only allows certain users to modify certain subdirectories in a project
def check_directory_perms
access = get_acl_access_data('.git/acl')
files_modified = `git diff-index --cached --name-only HEAD`.split(" ")
files_modified.each do |path|
next if path.size == 0
has_file_access = false
access[$user].each do |access_path|
if !access_path || (path.index(access_path) == 0)
has_file_access = true
end
if !has_file_access
puts "[POLICY] You do not have access to push to #{path}"
exit 1
end
end
end
check_directory_perms
This is roughly the same script as the server-side part, but with two important differences. First, the ACL file is in a different place, because this script runs from your working directory, not from your .git directory. You have to change the path to the ACL file from this
access = get_acl_access_data('acl')
to this:
access = get_acl_access_data('.git/acl')
The other important difference is the way you get a listing of the files that have been changed. Because the server-side method looks at the log of commits, and, at this point, the commit hasn’t been recorded yet, you must get your file listing from the staging area instead. Instead of
files_modified = `git log -1 --name-only --pretty=format:'' #{ref}`
you have to use
files_modified = `git diff-index --cached --name-only HEAD`
But those are the only two differences—otherwise, the script works the same way. One caveat is that it expects you to be running locally as the same user you push as to the remote machine. If that is different, you must set the $user variable manually.
One other thing we can do here is make sure the user doesn’t push non-fast-forwarded references. To get a reference that isn’t a fast-forward, you either have to rebase past a commit you’ve already pushed up or try pushing a different local branch up to the same remote branch.
Presumably, the server is already configured with receive.denyDeletes and receive.denyNonFastForwards to enforce this policy, so the only accidental thing you can try to catch is rebasing commits that have already been pushed.
Here is an example pre-rebase script that checks for that. It gets a list of all the commits you’re about to rewrite and checks whether they exist in any of your remote references. If it sees one that is reachable from one of your remote references, it aborts the rebase.
#!/usr/bin/env ruby
base_branch = ARGV[0]
if ARGV[1]
topic_branch = ARGV[1]
else
topic_branch = "HEAD"
end
target_shas = `git rev-list #{base_branch}..#{topic_branch}`.split(" ")
remote_refs = `git branch -r`.split(" ").map { |r| r.strip }
target_shas.each do |sha|
remote_refs.each do |remote_ref|
shas_pushed = `git rev-list ^#{sha}^@ refs/remotes/#{remote_ref}`
if shas_pushed.split(" ").include?(sha)
puts "[POLICY] Commit #{sha} has already been pushed to #{remote_ref}"
exit 1
end
end
end
This script uses a syntax that wasn’t covered in the "Revision Selection" section of Chapter 6. You get a list of commits that have already been pushed up by running this:
`git rev-list ^#{sha}^@ refs/remotes/#{remote_ref}`
.
The SHA^@ syntax resolves to all the parents of that commit. You’re looking for any commit that is reachable from the last commit on the remote and that isn’t reachable from any parent of any of the SHAs you’re trying to push up—meaning it’s a fast-forward.
The main drawback to this approach is that it can be very slow and is often unnecessary – if you don’t try to force the push with -f, the server will warn you and not accept the push. However, it’s an interesting exercise and can in theory help you avoid a rebase that you might later have to go back and fix.
Summary
We’ve covered most of the major ways that you can customize your Git client and server to best fit your workflow and projects. You’ve learned about all sorts of configuration settings, file-based attributes, and event hooks, and you’ve built an example policy-enforcing server. You should now be able to make Git fit nearly any workflow you can dream up.