
![]()
Transaction Processing
After you use Oracle Database for a while, you might have certain expectations of how it behaves. When you enter a query, you expect a consistent result set to be returned. If you enter a SQL statement to update several hundred records and the update of one of those rows fails, you expect the entire update to fail and all rows to be returned to their prior state. If your update succeeds and you commit your work to the database, you expect your changes to become visible to other users and remain in the database, at least until the data are updated again by someone else. You expect that when you are reading data, you never block a session from writing, and you also expect the reverse to be true. These are fundamental truths about how Oracle Database operates, and after you’ve become comfortable working with Oracle, you tend to take these truths for granted.
However, when you begin to write code for applications, you need to be keenly aware of how Oracle provides the consistency and concurrency you’ve learned to rely on. Relational databases are intended to process transactions, and in my opinion, Oracle Database is exceptional at keeping transaction data consistent, accurate, and available. However, you must design and implement transactions correctly if the protections you receive automatically at the statement level are to be extended to your transactions. How you design and code a transaction impacts the integrity and consistency of the application data, and if you do not define the transaction boundaries clearly, your application may behave in some unexpected ways. Transaction design also influences how well the system performs when multiple users are retrieving and altering the information within it. Scalability can be severely limited when transactions are designed poorly.
Although there are only a few transaction control statements, understanding how a transaction is processed requires an understanding of some of the more complex concepts and architectural components in Oracle Database. In the next few sections, I briefly cover a few transaction basics, the ACID properties (aka atomicity, consistency, isolation, and durability), ISO/ANSI SQL transaction isolation levels, and multiversion read consistency. For a more thorough treatment of these topics, please read the Oracle Concepts Manual (http://www.oracle.com/technetwork/indexes/documentation/index.html) and then follow up with Tom Kyte’s Expert Oracle Database Architecture Oracle Database 9i, 10g and 11g Programming Techniques and Solutions (Apress 2010), Chapters 6, 7, and 8. The goal for this chapter is to acquire a basic understanding of how to design a sound transaction and how to ensure that Oracle processes your transactions exactly as you intend them to be processed.
What Is a Transaction?
Let’s start by making sure we’re all on the same page when it comes to the word transaction. The definition of a transaction is a single, logical unit of work. It is comprised of a specific set of SQL statements that must succeed or fail as a whole. Every transaction has a distinct beginning, with the first executable SQL statement, and a distinct ending, when the work of the transaction is either committed or rolled back. Transactions that have started but have not yet committed or rolled back their work are active transactions, and all changes within an active transaction are considered pending until they are committed. If the transaction fails or is rolled back, then those pending changes never existed in the database at all.
The most common example of a transaction is a banking transfer. For example, a customer wants to transfer $500 from a checking account to a savings account, which requires a two-step process: a $500 debit from checking and a $500 credit to savings. Both updates must complete successfully to guarantee the accuracy of the data. If both updates cannot be completed, then both updates must roll back. Transactions are an all-or-nothing proposition, because a partial transaction may corrupt the data’s integrity. Consider the bank transfer. If the funds are removed from the checking account but the credit to the savings account fails, the data are no longer consistent and the bank’s financial reporting is inaccurate. The bank also has a very unhappy customer on its hands because the customer’s $500 has mysteriously disappeared.
It is also necessary to ensure that both updates are committed to the database as a single unit. Committing after each statement increases the possibility of one statement succeeding and the other statement failing; it also results in a point in time when the data are inconsistent. From the moment the first commit succeeds until the second commit completes, the bank records do not represent reality. If a bank manager happens to execute a report summarizing all account balances during that space of time between the two commits, the total in the deposited accounts would be short by $500. In this case, the customer is fine because the $500 does eventually end up in her savings account. Instead, there is a very frustrated accountant working late into the night to balance the books. By allowing the statements to process independently, the integrity of the data provided to the users becomes questionable.
A transaction should not include any extraneous work. Using the banking example again, it would be wrong to add the customer’s order for new checks in the transfer transaction. Adding unrelated work violates the definition of a transaction. There is no logical reason why a check order should depend on the success of a transfer. Nor should the transfer depend on the check order. Maybe if a customer is opening a new account it would be appropriate to include the check order with the transaction. The bank doesn’t want to issue checks on a nonexistent account. But then again, is the customer required to get checks for the account? Probably not. The most important element of coding a sound transaction is setting the transaction boundaries accurately around a logical unit of work and ensuring that all operations within the transaction are processed as a whole. To know where those boundaries should be, you need to understand the application requirements and the business process.
A transaction can be comprised of multiple DML statements, but it can contain only one DDL statement. This is because every DDL statement creates an implicit commit, which also commits any previously uncommitted work. Be very cautious when including DDL statements in a transaction. Because a transaction must encompass a complete logical unit of work, you must be certain that a DDL statement is either issued prior to the DML statements as a separate transaction or issued after all DML statements have processed successfully. If a DDL statement occurs in the middle of a transaction, then your “logical unit of work” ends up divided into two not-so-logical partial updates.
ACID Properties of a Transaction
Transaction processing is a defining characteristic of a data management system; it’s what makes a database different from a file system. There are four required properties for all database transactions: atomicity, consistency, isolation, and durability. These four properties are known as ACID properties. The ACID properties have been used to define the key characteristics of database transactions across all brands of database systems since Jim Gray first wrote about them in 1976, and clearly he defined those characteristics very well because no one has done it better in the 37 years since then. Every transactional database must comply with ACID, but how they choose to implement their compliance has created some of the more interesting differences in database software products.
All Oracle transactions comply with the ACID properties, which are described in the Oracle Concepts Manual (http://www.oracle.com/technetwork/indexes/documentation/index.html) as follows:
- Atomicity: All tasks of a transaction are performed or none of them are. There are no partial transactions.
- Consistency: The transaction takes the database from one consistent state to another consistent state.
- Isolation: The effect of a transaction is not visible to other transactions until the transaction is committed.
- Durability: Changes made by committed transactions are permanent.
Think for a moment about the fundamental behaviors of the individual SQL statements you issue to the Oracle Database and compare them with the ACID properties just listed. These properties represent the behaviors you expect at the statement level, because Oracle provides atomicity, consistency, isolation, and durability for SQL statements automatically without you having to expend any additional effort. Essentially, when you design a transaction to be processed by the database, your goal is to communicate the entire set of changes as a single operation. As long as you use transaction control statements to convey the contents of an individual transaction correctly, and set your transactions to the appropriate isolation level when the default behavior is not what you need, Oracle Database provides the atomicity, consistency, isolation, and durability required to protect your data.
Transaction Isolation Levels
And now for a little more depth on one particular ACID property: isolation. The definition of isolation in the Oracle Concepts Manual referenced earlier states that the effects of your transaction cannot be visible until you have committed your changes. This also means that your changes should not influence the behavior of other active transactions in the database.
In the banking transaction, I discussed the importance of protecting (isolating) the financial report from your changes until the entire transaction is complete. If you commit the credit to checking before you commit the debit to savings, the total bank funds are overstated (briefly) by $500, which violates the isolation property, because any users or transactions can see that the checking account balance has been reduced before the funds were added to the savings account.
However, there are two sides to the requirement for transaction isolation. In addition to isolating other transactions from your updates, you need to be aware of how isolated your transaction needs to be from updates made by other transactions. To some extent, the way to deal with this issue depends on those business requirements, but it also depends on how sensitive your transaction is to changes made by other users, and how likely the data are to change while your transaction is processing. To appreciate the need for isolation, you need to understand how isolation, or the lack thereof, impacts transactions on a multiuser database.
The ANSI/ISO SQL standard defines four distinct levels of transaction isolation: read uncommitted, read committed, repeatable read, and serializable. Within these four levels, the standard defines three phenomena that are either permitted or not permitted at a specific isolation level: dirty reads, nonrepeatable reads, and phantom reads. Each of the three phenomena is a specific type of inconsistency that can occur in data that are read by one transaction while another transaction is processing updates. As the isolation level increases, there is a greater degree of separation between transactions, which results in increasingly consistent data.
The ANSI/ISO SQL standard does not tell you how a database should achieve these isolation levels, nor does it define which kinds of reads should or should not be permitted. The standard simply defines the impact one transaction may have on another at a given level of isolation. Table 14-1 lists the four isolation levels and notes whether a given phenomenon is permitted.
Table 14-1. ANSI Isolation Levels
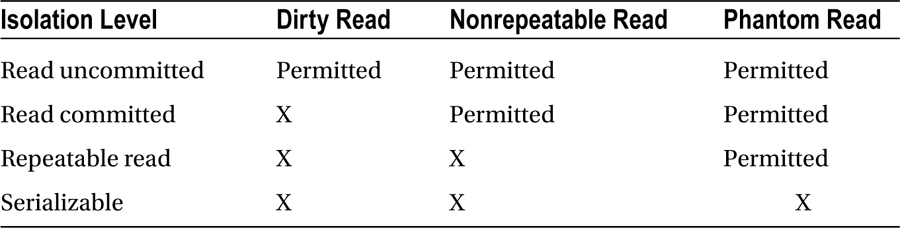
The definitions of each phenomenon are as follows:
- Dirty read: Reading uncommitted data is called a dirty read, and it’s a very appropriate name. Dirty reads have not been committed, which means that data have not yet been verified against any constraints set in the database. Uncommitted data may never be committed, and if this happens, the data were never really part of the database at all. Result sets built from dirty reads should be considered highly suspect because they can represent a view of the information that never actually existed.
- Nonrepeatable read: A nonrepeatable read occurs when a transaction executes a query a second time and receives a different result because of committed updates by another transaction. In this case, the updates by the other transaction have been verified and made durable, so the data are valid; they’ve just been altered since the last time your transaction read it.
- Phantom read: If a query is executed a second time within a transaction, and additional records matching the filter criteria are returned, it is considered a phantom read. Phantom reads result when another transaction has inserted more data and committed its work.
By default, transactions in Oracle are permitted to read the committed work of other users immediately after the commit. This means that it is possible to get nonrepeatable and phantom reads unless you specifically set the isolation level for your transaction to either read only or serializable. The important question is “Will either phenomenon prevent my transaction from applying its changes correctly and taking the database from one consistent state to the next?” If your transaction does not issue the same query more than once in a single transaction or it does not need the underlying data to remain consistent for the duration of your transaction, then the answer is no and the transaction can be processed safely at the default read-committed isolation level.
Only a serializable transaction removes completely the possibility of all three phenomena while still allowing for updates, thus providing the most consistent view of the data even as they are changing. However, serializable transactions can reduce the level of concurrency in the database because there is a greater risk of transactions failing as a result of conflicts with other updates. If you require repeatable reads and you need to update data in the transaction, setting your transaction to execute in serializable mode is your only option. If your transaction requires repeatable reads but it does not update data, then you can set your transaction to read-only mode, which guarantees repeatable reads until your transaction completes or until the system exceeds its undo retention period. I talk about how to accomplish serializable and repeatable read transactions shortly.
Oracle does not support the read-uncommitted isolation level, nor is it possible to alter the database to do so. Reading uncommitted data is permitted in other databases to prevent writers from blocking readers and to prevent readers from blocking writers. Oracle prevents such blocks from occurring with multiversion read consistency, which provides each transaction with its own read-consistent view of the data. Thanks to multiversion read consistency, dirty reads are something Oracle users and developers never need to worry about.
Multiversion Read Consistency
As mentioned earlier, the ACID properties do not determine how the database should provide data consistency for transactions, nor do the ANSI/ISO SQL transaction isolation levels define how to achieve transaction isolation or even specify the levels of isolation a database product must provide. Each individual vendor determines how to comply with ACID and the levels of isolation it supports. If you develop applications that operate on multiple database platforms, it is crucial for you to understand the different implementations provided by each vendor and how those differences can impact the results of a given transaction.
Fortunately, you only have to worry about one approach in this chapter. Oracle provides data consistency and concurrency with the multiversion read consistency model. This can be a fairly complex concept to grasp, although it’s transparent to users. Oracle is able to display simultaneously multiple versions of the data, based on the specific point in time a transaction requested the information and on the transaction’s isolation level. The database accomplishes this amazing feat by retaining the before-and-after condition of altered data blocks so that the database can recreate a consistent view of the data for multiple sessions at a single point in time. If a transaction is running in the default read-committed mode, then a “consistent view of the data” means the results are based on the committed data as of when a query or update was initiated. When a transaction executes in serializable mode, the read-consistent view is based on the committed data as of when the transaction began. There is a limit to how far Oracle can reach into the past to create this consistent view of the data, and that limit depends on the allocation of undo space configured for the database. If Oracle cannot reach back far enough into the past to support a given statement, that statement fails with a “snapshot too old” error.
Undo blocks retain the before condition of the data whereas the redo information is stored in the online redo logs in the SGA. The redo logs contain both the change to the data block and the change to the undo block. The same structures that provide the means to roll back your changes also provide read-consistent views of the data to multiple users and multiple transactions. Because a transaction should always encompass a complete logical unit of work, the undo storage and retention level should be configured to support transactions at the required level of concurrency. If you are considering dividing your logical unit of work to prevent “snapshot too old” errors, you need to revisit your code or talk with your DBA. Or maybe do both.
The database buffers of the SGA are updated with changes for a committed transaction, but the changes are not necessarily written immediately to the data files. Oracle uses the system change number (SCN) to keep a sequential record of changes occurring throughout the instance and to connect changes to a particular point in time. Should the database fail, all pending transactions are rolled back so that when the database is restarted, the data are at a consistent state once again, reflecting only the committed work as of the time of failure. You get the exact same result if the DBA issues a command to flash the database back to a specific SCN. The database returns to the point in time marked by the SCN, and any transactions committed after that no longer exist in the database. This is necessary to prevent partial transactions from being stored in the database.
So how does multiversion read consistency impact individual transactions? If transaction B requests data that have been altered by transaction A, but transaction A has not committed its changes, Oracle reads the before condition of the data and returns that view to transaction B. If transaction C begins after transaction A commits its changes, the results returned to transaction C include the changes committed by transaction A, which means that transaction C receives a different result than transaction B, but the results are consistent with the point in time when each session requested the information.
Transaction Control Statements
There are only five transaction control statements: commit, savepoint, rollback, set transaction, and set constraints. There are relatively few variants of these statements, so learning the syntax and the options for controlling your transactions is not too difficult. The challenge of coding a transaction is understanding how and when to use the appropriate combination of statements to ensure your transaction complies with ACID and that it is processed by the database exactly as you expect.
Commit
Commit, or the SQL standard-compliant version commit work, ends your transaction by making your changes durable and visible to other users. With the commit write extensions now available, you have the option to change the default behavior of a commit. Changes can be committed asynchronously with the write nowait extension, and you can also choose to allow Oracle to write commits in batches. The default behavior processes a commit as commit write wait immediate, which is how commits were processed in earlier versions of Oracle. This is still the correct behavior for the majority of applications.
So when might you choose not to wait for Oracle to confirm your work has been written? By choosing an asynchronous commit, you are allowing the database to confirm that your changes have been received before those changes are made durable. If the database fails before the commit is written, your transaction is gone yet your application and your users expect it to be there. Although this behavior may be acceptable for applications that process highly transitive data, for most of us, ensuring the data have indeed been committed is essential. A nowait commit should be considered carefully before being implemented. You need to be certain that your application can function when committed transactions seem to disappear.
Savepoint
Savepoints allow you to mark specific points within your transaction and roll back your transaction to the specified savepoint. You then have the option to continue your transaction rather than starting a brand new one. Savepoints are sequential, so if you have five savepoints and you roll back to the second savepoint, all changes made for savepoints 3 through 5 are rolled back.
Rollback
Rollback is the other option for ending a transaction. If you choose to roll back, your changes are reversed and the data return to their previously consistent state. As noted earlier, you have the option to roll back to a specific savepoint, but rolling back to a savepoint does not end a transaction. Instead, the transaction remains active until either a complete rollback or a commit is issued.
Set Transaction
The set transaction command provides multiple options to alter default transaction behavior. Set transaction read only provides repeatable reads, but you cannot alter data. You also use the set transaction command to specify serializable isolation. Set transaction can be used to choose a specific rollback segment for a transaction, but this is no longer recommended by Oracle. In fact, if you are using automatic undo management, this command is ignored. You can also use set transaction to name your transaction, but the dbms.application_info package is a better option for labeling your transactions because it provides additional functionality.
Set Constraints
Constraints can be deferred during a transaction with the set constraint or set constraints commands. The default behavior is to check the constraints after each statement, but in some transactions it may be that the constraints are not met until all the updates within the transaction are complete. In these cases, you can defer constraint verification as long as the constraints are created as deferrable. This command can defer a single constraint or it can defer all constraints.
As far as the SQL language goes, transaction control statements may be some of the simplest and clearest language options you have. Commit, rollback, and rollback to savepoint will be the transaction control commands you use most often. You may need to set the isolation level with set transaction occasionally, whereas deferring constraints is likely to be a rare occurrence. If you want more information about the transaction control statements, referring to the SQL statement documentation is likely to give you enough information to execute the commands; but, before you use one of the less common commands, be sure to research and test it extensively so you know absolutely what effect the nondefault behavior will have on your data.
Grouping Operations into Transactions
By now, you should be well aware that understanding business requirements is central to designing a good transaction. However, what is considered a logical unit of work in one company may be very different at another. For example, when an order is placed, is the customer’s credit card charged immediately or is the card charged when the order ships? If payment is required to place the order, then the procuring the funds should be part of the order transaction. If payments are processed when the product is shipped, then payment may be authorized with the order, but processed just before shipment. Neither option is more correct than the other, it just depends on how the business has decided to manage its orders. If a company sells a very limited product, then expecting payment at the time of order is perfectly reasonable because the company makes that rare item unavailable to other customers. If the product is common, then customers generally don’t expect to pay until the product ships, and choosing to process payments earlier may cost the company some business.
In addition to understanding the requirements of the business, there are some general rules for designing a sound transaction:
- Process each logical unit of work as an independent transaction. Do not include extraneous work.
- Ensure the data are consistent when your transaction begins and that they remain consistent when the transaction is complete.
- Get the resources you need to process your transaction and then release the resources for other transactions. Hold shared resources for as long as you need them, but no longer. By the same token, do not commit during your transaction just to release locks you still need. Adding commits breaks up the logical unit of work and does not benefit the database.
- Consider other transactions likely to be processing at the same time. Do they need to be isolated from your transaction? Does your transaction need to be isolated from other updates?
- Use savepoints to mark specific SQL statements that may be appropriate for midtransaction rollbacks.
- Transactions should always be committed or rolled back explicitly. Do not rely on the default behavior of the database or a development tool to commit or roll back. Default behavior can change.
- After you’ve designed a solid transaction, consider wrapping it in a procedure or package. As long as a procedure does not contain any commits or rollbacks within it, it is provided with the same default atomicity level Oracle provides to all statements. This means that the protections afforded automatically to statements also apply to your procedure and, therefore, to your transaction.
- Exception handling can have a significant impact on a transaction’s integrity. Exceptions should be handled with relevant application errors, and any unhandled exceptions should always raise the database error. Using the WHEN OTHERS clause to bypass an error condition is a serious flaw in your code.
- Consider using the dbms_application_info package to label your transactions to help identify specific sections of code quickly and accurately when troubleshooting errors or tuning performance. I talk more about dbms_application_info and instrumentation in the next chapter.
The Order Entry Schema
Before I move on to talking about active transactions, let’s talk about the sample schema we’ll be using for our transaction examples. The order entry (OE) schema contains a product set that is available for orders, and it is associated with the human resources schema you may already be familiar with. In this case, some of the employees are sales representatives who take orders on behalf of customers. Listing 14-1 shows the names of the tables in the default OE schema.
Listing 14-1. OE Schema Tables
TABLE_NAME
------------------------------
CATEGORIES
CUSTOMERS
INVENTORIES
ORDERS
ORDER_ITEMS
PRODUCT_DESCRIPTIONS
PRODUCT_INFORMATION
WAREHOUSES
The OE schema may be missing a few critical components; there are no warehouses in the warehouses table and there is no inventory in the inventories table, so you are out of stock on everything and you have no place to store the stock if you did have any. It’s hard to create orders without any inventory, so we need to add data to the existing tables first.
Start by adding a warehouse to the company’s Southlake, Texas, location where there should be plenty of real estate, and then add lots of inventory to be sold. I used the dbms_random procedure to generate more than 700,000 items, so if you choose to follow along, your actual inventory may vary. But, you should end up with enough products in stock to experiment with a few transactions, and you can always add more. As you create your orders, notice the product_information table contains some very old computing equipment. If it helps, consider the equipment vintage and pretend you’re selling collectibles.
The orders table contains an order_status column, but the status is represented by a numeric value. Create a lookup table for the order status values and, because the existing orders use a range of one through ten, your order_status table needs to contain ten records. Although this is not a PL/SQL book, I created a few functions and a procedure to provide some necessary functionality without having to show a lot of extra code that might detract from the primary purpose of the example. There are functions to get the list price from the product_information table, one to get a count of the number of line items added to an order, and another one to calculate the order total using the sum of the line items. The contents of the functions are not important to your transactions, but the code to create them is included in the download available at the Apress web site, along with the rest of the schema updates.
We also need to create a billing schema and a credit authorization procedure. The procedure accepts a customer ID number and order total, and then returns a randomly generated number to simulate the process of ensuring payment for the products. In the real world, billing likely represents an entire accounting system and possibly a distributed transaction, but for our purposes, we simply need to represent the customers’ promise to pay for the items they wish to order. Remember, the most important rule for any transaction is that it should contain a complete logical unit of work. The credit authorization represents the exchange of funds for the product. We’re not in business to give our products away, and customers aren’t going to send us cash unless they receive something in return. It’s this exchange that represents a transaction. Listing 14-2 shows the rest of the OE schema changes.
Listing 14-2. OE Schema Changes
-- create 'billing' user to own a credit authorization procedure
conn / as sysdba
create user billing identified by &passwd ;
grant create session to billing ;
grant create procedure to billing ;
--- add warehouses and inventory using a random number to populate inventory quantities
connect oe
insert into warehouses values (1, 'Finished Goods', 1400) ;
insert into inventories
select product_id, 1, round(dbms_random.value(2, 5000),0)
from product_information;
commit;
--- check total quantity on hand
select sum(quantity_on_hand) from inventories;
--- create a sequence for the order id
create sequence order_id start with 5000;
--- create a table for order status
create table oe.order_status
(
order_status number(2, 0) not null,
order_status_name varchar2(12) not null,
constraint order_status_pk order_status)
);
--- add values for order status 1 through 10 to match existing sample data
insert into order_status (order_status, order_status_name) values (0, 'Pending'),
insert into order_status (order_status, order_status_name) values (1, 'New'),
insert into order_status (order_status, order_status_name) values (2, 'Cancelled'),
insert into order_status (order_status, order_status_name) values (3, 'Authorized'),
insert into order_status (order_status, order_status_name) values (4, 'Processing'),
insert into order_status (order_status, order_status_name) values (5, 'Shipped'),
insert into order_status (order_status, order_status_name) values (6, 'Delivered'),
insert into order_status (order_status, order_status_name) values (7, 'Returned'),
insert into order_status (order_status, order_status_name) values (8, 'Damaged'),
insert into order_status (order_status, order_status_name) values (9, 'Exchanged'),
insert into order_status (order_status, order_status_name) values (10, 'Rejected'),
--- create a function to get the list prices of order items
@get_listprice.fnc
--- create a function to get the order total
@get_ordertotal.fnc
--- create a function to get the order count
@get_orderitemcount.fnc
--- create order detail views
@order_detail_views.sql
--- Create credit_request procedure
connect billing
@credit_request.sql
Now that you know what we’re selling and we have a customers table to tell us who we might be selling it to, let’s take a look at an order transaction. Your longstanding customer Maximilian Henner of Davenport, Iowa, has contacted sales manager John Russell and placed an order for five 12GB hard drives, five 32GB RAM sticks, and 19 boxes of business cards containing 1000 cards per box. Mr. Henner has a credit authorization of $50,000, although our customers table does not tell us how much he may already owe for prior purchases. This information is stored in our imaginary billing system. John enters Mr. Henner’s order in the order entry screen of our sales system and creates order number 2459 for customer 141. The order is a direct order entered into the system by our employee, ID number 145. When our sales manager sends a copy of this order to his customer, the order should look something like this:
Order no.: 2459
Customer: Maximilian Henner
2102 E Kimberly Rd
Davenport, IA 52807
Sold by: John Russell

Mr. Henner wants to purchase multiple quantities of three different products, so we need to add three items to the order_item table. Each item needs a product ID, a quantity, and a list price. There is a discount percentage that is applied to the entire order, and it is used to calculate the discounted price. The discounted priced is multiplied by the item quantity to produce the line item total.
As we add the items to the order, we also must reduce the on-hand inventory for these items so that another sales person does not commit to delivering a product that is no longer available. Next, we need to calculate the order total as a sum of the line items and then call the credit authorization procedure to verify that Mr. Henner has the required amount available in his credit line. After we have the authorization, we set the order total to equal the amount charged, and the transaction is complete. All these steps are required for the order to exist and, therefore, these steps comprise our logical unit of work for an order.
Before we enter the order, check the inventory for the products the customer has requested, as shown in Listing 14-3.
Listing 14-3. Verify Available Inventory
SQL> select product_id, quantity_on_hand
from inventories
where product_id in (2255, 2274, 2537)
order by product_id ;
PRODUCT_ID QUANTITY_ON_HAND
---------- ----------------
2255 672
2274 749
2537 2759
When we look at the statements as they are received by the database to create this order, reduce the inventory, and obtain a credit authorization, they might look something like the transaction shown in Listing 14-4.
Listing 14-4. Order Transaction in a Procedure
SQL> begin
savepoint create_order;
insert into orders
(order_id, order_date, order_mode,
order_status, customer_id, sales_rep_id)
values
(2459, sysdate, 'direct', 1, 141, 145) ;
--- Add first ordered item and reduce inventory
savepoint detail_item1;
insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(2459, 1, 2255, 775, 658.75, 5) ;
update inventories set quantity_on_hand = quantity_on_hand - 5
where product_id = 2255 and warehouse_id = 1 ;
--- Add second ordered item and reduce inventory
savepoint detail_item2;
insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(2459, 2, 2274, 161, 136.85, 5) ;
update inventories set quantity_on_hand = quantity_on_hand - 5
where product_id = 2274 and warehouse_id = 1 ;
--- Add third ordered item and reduce inventory
savepoint detail_item3;
insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(2459, 3, 2537, 200, 170, 19) ;
update inventories set quantity_on_hand = quantity_on_hand - 19
where product_id = 2537 and warehouse_id = 1 ;
--- Request credit authorization
savepoint credit_auth;
begin billing.credit_request(141,7208); end;
savepoint order_total;
--- Update order total
savepoint order_total;
update orders set order_total = 7208 where order_id = 2459;
exception
when others then RAISE;
end;
/
Customer ID = 141
Amount = 7208
Authorization = 3452
PL/SQL procedure successfully completed.
We see the output from the credit authorization and get a confirmation that our procedure completed. We have not yet ended our transaction because we haven’t issued a commit or a rollback. First, query the data to confirm our updates, including the update to reduce the on-hand inventory. The confirmation queries are shown in Listing 14-5.
Listing 14-5. Confirm Transaction Updates
SQL> select order_id, customer, mobile, status, order_total, order_date
from order_detail_header
where order_id = 2459 ;
ORDER_ID CUSTOMER MOBILE STATUS ORDER_TOTAL ORDER_DATE
---------- ----------------- --------------- ------- ------------ -----------
2459 Maximilian Henner +1 319 123 4282 New 7,208.00 04 Jul 2010
1 row selected.
SQL> select line_item_id ITEM, product_name, unit_price,
discount_price, quantity qty, line_item_total
from order_detail_line_items
where order_id = 2459
order by line_item_id ;
ITEM PRODUCT_NAME UNIT_PRICE DISCOUNT_PRICE QTY LINE_ITEM_TOTAL
----- ------------------------ ---------- -------------- --- ---------------
1 HD 12GB @7200 /SE 775.00 658.75 5 3,293.75
2 RAM - 32 MB 161.00 136.85 5 684.25
3 Business Cards Box - 1000 200.00 170.00 19 3,230.00
3 rows selected.
SQL> select product_id, quantity_on_hand
from inventories
where product_id in (2255, 2274, 2537)
order by product_id ;
PRODUCT_ID QUANTITY_ON_HAND
---------- ----------------
2255 667
2274 744
2537 2740
All required operations within our transaction have been confirmed. The order is created, three products are added, the inventory is reduced, and our order total is updated to reflect the sum of the individual line items. Our transaction is complete, and we can commit the changes. Instead, however, we’re going to roll them back and use this transaction again.
![]() Note The most important rule for transaction processing is to ensure the transaction is ACID compliant. The transaction in Listing 14-4 has been wrapped in a procedure with an exception clause to illustrate the atomicity principal. The remainder of the examples are shown as independently entered SQL statements and, in some cases, only a portion of the transaction is shown to keep the examples to a reasonable length. If there is one message you take away from this chapter, it is the importance of ensuring that the entire transaction succeeds as a whole or fails as a whole.
Note The most important rule for transaction processing is to ensure the transaction is ACID compliant. The transaction in Listing 14-4 has been wrapped in a procedure with an exception clause to illustrate the atomicity principal. The remainder of the examples are shown as independently entered SQL statements and, in some cases, only a portion of the transaction is shown to keep the examples to a reasonable length. If there is one message you take away from this chapter, it is the importance of ensuring that the entire transaction succeeds as a whole or fails as a whole.
The Active Transaction
As soon as we issue the first SQL statement that alters data, the database recognizes an active transaction and creates a transaction ID. The transaction ID remains the same whether we have one DML statement in our transaction or 20, and the transaction ID exists only as long as our transaction is active and our changes are still pending. In the order example from the previous section, the transaction ID is responsible for tracking only one transaction: the new order for Mr. Henner. After we roll back the entire transaction, our transaction ends and the transaction ID is gone. We see the same result if we commit our work.
The SCN, on the other hand, continues to increment regardless of where we are in our transaction process. The SCN identifies a specific point in time for the database, and it can be used to return the database to a prior point in time while still ensuring the data are consistent. Committed transactions remain committed (durability), and any pending transactions are rolled back (atomicity).
If we check the transaction ID and SCN while executing the individual statements that comprised the order procedure shown earlier, we see something like the results in Listing 14-6.
Listing 14-6. Order Transaction with Transaction ID and SCN Shown
SQL> insert into orders
(order_id, order_date, order_mode,
order_status, customer_id, sales_rep_id)
values
(2459, sysdate, 'direct', 1, 141, 145) ;
1 row created.
SQL> select current_scn from v$database;
CURRENT_SCN
-----------
83002007
SQL> select xid, status from v$transaction ;
XID STATUS
---------------- ----------------
0A001800CE8D0000 ACTIVE
.......
SQL> --- Update order total
SQL> update orders set order_total = 7208 where order_id = 2459;
1 row updated.
SQL> select order_id, customer, mobile, status, order_total, order_date
from order_detail_header
where order_id = 2459;
ORDER_ID CUSTOMER MOBILE STATUS ORDER_TOTAL ORDER_DATE
---------- ------------------------- --------------- ------------ -------------- -----------
2459 Maximilian Henner +1 319 123 4282 New 7,208.00 04 Jul 2010
SQL> select line_item_id, product_name, unit_price,
discount_price, quantity, line_item_total
from order_detail_line_items
where order_id = 2459
order by line_item_id ;
ITEM PRODUCT_NAME UNIT_PRICE DISCOUNT_PRICE QUANTITY LINE_ITEM_TOTAL
---- ---------------------------------- ---------- -------------- ---------- ---------------
1 HD 12GB @7200 /SE 775.00 658.75 5 3,293.75
2 RAM - 32 MB 161.00 136.85 5 684.25
3 Business Cards Box - 1000 200.00 170.00 19 3,230.00
SQL> select current_scn from v$database;
CURRENT_SCN
-----------
83002012
SQL> select xid, status from v$transaction ;
XID STATUS
---------------- ----------------
0A001800CE8D0000 ACTIVE
SQL> rollback;
Rollback complete.
SQL> select current_scn from v$database;
CURRENT_SCN
-----------
83002015
SQL> select xid, status from v$transaction ;
no rows selected
If the database flashed back to SCN 83002012, none of the operations in our order exist. Because any changes we made were pending at that point in time, the only way Oracle can guarantee data consistency is to roll back all noncommitted work. Whether we committed the transaction or rolled it back is immaterial. The updates were not committed at SCN 830020012, and pending changes are always reversed.
In the initial order transaction, we included savepoints but did not make use of them. Instead, we executed our transaction, confirmed the order information with two queries, and then rolled back the entire transaction. In the example shown in Listing 14-7, we roll back to savepoint item_detail1, which is recorded prior to adding any product to the order. Let’s take a look at our data after returning to a savepoint.
Listing 14-7. Returning to a Savepoint
SQL> savepoint create_order;
Savepoint created.
SQL> insert into orders
(order_id, order_date, order_mode,
order_status, customer_id, sales_rep_id)
values
(2459, sysdate, 'direct', 1, 141, 145) ;
1 row created.
SQL> --- Add first ordered item and reduce inventory
SQL> savepoint detail_item1;
Savepoint created.
SQL> insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(2459, 1, 2255, 775, 658.75, 5) ;
1 row created.
SQL> update inventories set quantity_on_hand = quantity_on_hand - 5
where product_id = 2255 and warehouse_id = 1 ;
1 row updated.
SQL> --- Add second ordered item and reduce inventory
SQL> savepoint detail_item2;
Savepoint created.
SQL> insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(2459, 2, 2274, 161, 136.85, 5) ;
1 row created.
SQL> update inventories set quantity_on_hand = quantity_on_hand - 5
where product_id = 2274 and warehouse_id = 1 ;
1 row updated.
SQL> --- Add third ordered item and reduce inventory
SQL> savepoint detail_item3;
Savepoint created.
SQL> insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(2459, 3, 2537, 200, 170, 19) ;
1 row created.
SQL> update inventories set quantity_on_hand = quantity_on_hand - 19
where product_id = 2537 and warehouse_id = 1 ;
1 row updated.
SQL> --- Request credit authorization
SQL> savepoint credit_auth;
Savepoint created.
SQL> exec billing.credit_request(141,7208) ;
Customer ID = 141
Amount = 7208
Authorization = 1789
PL/SQL procedure successfully completed.
SQL> savepoint order_total;
Savepoint created.
SQL> --- Update order total
SQL> savepoint order_total;
Savepoint created.
SQL> update orders set order_total = 7208 where order_id = 2459;
1 row updated.
SQL> select order_id, customer, mobile, status, order_total, order_date
from order_detail_header
where order_id = 2459;
ORDER_ID CUSTOMER MOBILE STATUS ORDER_TOTAL ORDER_DATE
---------- ------------------------- --------------- ------------ -------------- -----------
2459 Maximilian Henner +1 319 123 4282 New 7,208.00 04 Jul 2010
SQL> select line_item_id, product_name, unit_price, discount_price,
quantity, line_item_total
from order_detail_line_items
where order_id = 2459
order by line_item_id ;
ITEM PRODUCT_NAME UNIT_PRICE DISCOUNT_PRICE QUANTITY LINE_ITEM_TOTAL
---- ------------------------- ---------- -------------- ---------- ---------------
1 HD 12GB @7200 /SE 775.00 658.75 5 3,293.75
2 RAM - 32 MB 161.00 136.85 5 684.25
3 Business Cards Box - 1000 200.00 170.00 19 3,230.00
SQL> rollback to savepoint detail_item1;
Rollback complete.
When we reexecute the queries to check the order data, notice in Listing 14-8 that all changes occurring after the savepoint are reversed, yet the order itself still exists. Our sales rep has the option of continuing with Mr. Henner’s order by adding new line items or rolling it back completely to end the transaction.
Listing 14-8. Verifying Data after Rollback to a Savepoint
SQL> select order_id, customer, mobile, status, order_total, order_date
from order_detail_header
where order_id = 2459;
ORDER_ID CUSTOMER MOBILE STATUS ORDER_TOTAL ORDER_DATE
---------- ------------------------- --------------- ------------ -------------- -----------
2459 Maximilian Henner +1 319 123 4282 New 04 Jun 2010
SQL> select line_item_id, product_name, unit_price, discount_price,
quantity, line_item_total
from order_detail_line_items
where order_id = 2459
order by line_item_id ;
no rows selected
SQL> select product_id, quantity_on_hand
from inventories
where product_id in (2255, 2274, 2537)
order by product_id ;
PRODUCT_ID QUANTITY_ON_HAND
---------- ----------------
2255 672
2274 749
2537 2759
Notice how in the first set of query selects both the order and the three products are added to the order_items table. After we roll back to the item_detail1 savepoint, there are no products associated with the order, the inventory has returned to its previous level, and—although the order header still exists—the order total field is now null.
Serializing Transactions
When a transaction is executed in serializable mode, Oracle’s multiversion read consistency model provides a view of the data as they existed at the start of the transaction. No matter how many other transactions may be processing updates at the same time, a serializable transaction only sees its own changes. This creates the illusion of a single-user database because changes committed by other users after the start of the transaction remain invisible. Serializable transactions are used when a transaction needs to update data and requires repeatable reads. Listings 14-9 and 14-10 demonstrate when a serialized transaction or repeatable read may be required.
Executing transactions in serializable mode does not mean that updates are processed sequentially. If a serializable transaction attempts to update a record that has been changed since the transaction began, the update is not permitted and Oracle returns error “ORA-08177: can’t serialize access for this transaction.”
At this point, the transaction could be rolled back and repeated. For a serializable transaction to be successful, there needs to be a strong possibility that no one else will update the same data while the transaction executes. We can increase the odds of success by completing any changes that may conflict with other updates early in our transaction, and by keeping the serialized transaction as short and as fast as possible.
This makes the need for serializable updates somewhat contrary to their use. If the data are unlikely to be updated by another user, then why do we need serializable isolation? Yet, if the data are changeable enough to require serializable isolation, this may be difficult to achieve.
For the next example, we open two sessions. Session A initiates a serializable transaction and adds an additional product to an existing order. After the item is added and before the order total is updated, we pause the transaction to make a change to the same order in another session. In session B, we update the status of the order to Processing and commit our changes. Then, we return to session A to update the order. This results in an ORA-08177 error, as shown in Listing 14-9.
Listing 14-9. Serialized Transaction and ORA-08177
Session A: Serialized transaction to add an additional item
SQL> set transaction isolation level serializable;
Transaction set.
SQL> variable o number
SQL> execute :o := &order_id
Enter value for order_id: 5006
PL/SQL procedure successfully completed.
SQL> variable d number
SQL> execute :d := &discount
Enter value for discount: .1
PL/SQL procedure successfully completed.
SQL> --- Add new ordered item and reduce on-hand inventory
SQL> variable i number
SQL> execute :i := &first_item
Enter value for first_item: 1791
PL/SQL procedure successfully completed.
SQL> variable q number
SQL> execute :q := &item_quantity
Enter value for item_quantity: 15
PL/SQL procedure successfully completed.
SQL> variable p number
SQL> execute :p := get_ListPrice(:i)
PL/SQL procedure successfully completed.
SQL> insert into order_items
(order_id, line_item_id, product_id, unit_price, discount_price, quantity)
values
(:o, 1, :i, :p, :p-(:p*:d), :q) ;
1 row created.
SQL> update inventories set quantity_on_hand = quantity_on_hand - :q
where product_id = :i and warehouse_id = 1 ;
1 row updated.
SQL> pause Pause ...
Pause ...
Session B: Order Status Update
SQL> variable o number
SQL> execute :o := &order_id
Enter value for order_id: 5006
PL/SQL procedure successfully completed.
SQL> variable s number
SQL> execute :s := &status
Enter value for status: 4
PL/SQL procedure successfully completed.
SQL> update orders
set order_status = :s
where order_id = :o ;
1 row updated.
SQL> select order_id, customer, mobile, status, order_total, order_date
from order_detail_header
where order_id = :o;
ORDER_ID CUSTOMER MOBILE STATUS ORDER_TOTAL ORDER_DATE
---------- ------------------------- --------------- ------------ -------------- -----------
5006 Harry Mean Taylor +1 416 012 4147 Processing 108.00 04 Jul 2010
SQL> select line_item_id, product_name, unit_price, discount_price,
quantity, line_item_total
from order_detail_line_item
where order_id = :o
order by line_item_id ;
ITEM PRODUCT_NAME UNIT_PRICE DISCOUNT_PRICE QUANTITY LINE_ITEM_TOTAL
---- ------------------------- ---------- -------------- ---------- ---------------
1 Cable RS232 10/AM 6 5.40 20 108.00
SQL> commit;
Session A: Return to the serializable transaction
SQL> --- Get New Order Total
SQL> variable t number
SQL> execute :t := get_OrderTotal(:o)
PL/SQL procedure successfully completed.
SQL> --- Update order total
SQL> update orders set order_total = :t where order_id = :o ;
update orders set order_total = :t where order_id = :o
*
ERROR at line 1:
ORA-08177: can't serialize access for this transaction
Because session B already committed changes to order 5006, session A is not permitted to update the order total. This is necessary to prevent a lost update. Session A cannot see the order status has changed; its serialized view of the data still considers the order to be New. If session A replaced the record in the order table with its version of the data, changes made by session B would be overwritten by the previous version of the data even though they were committed changes. In this case, the order total would have to be updated earlier during session A’s transaction for this transaction to be successful. However, because the order total is a sum of the individual line items, that number is unknown until the new line item is added. This is also a case when serializable isolation might really be required. If two sessions are attempting to add line items to the same order at the same time, the calculated order total might end up inaccurate.
![]() Note I switched from hard coded data values to user variables in the transactions, which makes it easier to execute the order transactions repeatedly for testing and to view the results at each step. The code to process orders with prompts, variables, and functions is available on the Apress web site.
Note I switched from hard coded data values to user variables in the transactions, which makes it easier to execute the order transactions repeatedly for testing and to view the results at each step. The code to process orders with prompts, variables, and functions is available on the Apress web site.
Isolating Transactions
Using the same pair of transactions, let’s take a quick look at what can happen when we don’t isolate a transaction properly. In this case, session A commits the additional items to order 5007 before pausing, which means the product is added to the order and is made durable; but, the order total does not include the additional product. Listing 14-10 shows how permitting other sessions to see partial transactions can jeopardize data integrity.
Listing 14-10. Inappropriate Commits and Transaction Isolation Levels
Session A: Serializable transaction to add an additional item
SQL> set transaction isolation level serializable;
Transaction set.
SQL> variable o number
SQL> execute :o := &order_id
Enter value for order_id: 5007
PL/SQL procedure successfully completed.
SQL> variable d number
SQL> execute :d := &discount
Enter value for discount: .2
PL/SQL procedure successfully completed.
SQL> --- Add new ordered item and reduce on-hand inventory
SQL> variable i number
SQL> execute :i := &first_item
Enter value for first_item: 3127
PL/SQL procedure successfully completed.
SQL> variable q number
SQL> execute :q := &item_quantity
Enter value for item_quantity: 5
PL/SQL procedure successfully completed.
SQL> variable p number
SQL> execute :p := get_ListPrice(:i)
PL/SQL procedure successfully completed.
SQL> insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(:o, 1, :i, :p, :p-(:p*:d), :q) ;
1 row created.
SQL> update inventories set quantity_on_hand = quantity_on_hand - :q
where product_id = :i and warehouse_id = 1 ;
1 row updated.
SQL> commit;
Commit complete.
SQL> pause Pause ...
Pause ...
Session B: Order Status Update
SQL> variable o number
SQL> execute :o := &order_id
Enter value for order_id: 5007
PL/SQL procedure successfully completed.
SQL> variable s number
SQL> execute :s := &status
Enter value for status: 4
PL/SQL procedure successfully completed.
SQL> update orders
set order_status = :s
where order_id = :o ;
1 row updated.
SQL> select order_id, customer, mobile, status, order_total, order_date
from order_detail_header
where order_id = :o;
ORDER_ID CUSTOMER MOBILE STATUS ORDER_TOTAL ORDER_DATE
---------- ------------------------- --------------- ------------ -------------- -----------
5007 Alice Oates +41 4 012 3563 Processing 16,432.00 04 Jul 2010
SQL> select line_item_id, product_name, unit_price, discount_price,
quantity, line_item_total
from order_detail_line_item
where order_id = :o
order by line_item_id ;
ITEM PRODUCT_NAME UNIT_PRICE DISCOUNT_PRICE QUANTITY LINE_ITEM_TOTAL
---- ---------------------------------- ---------- -------------- ---------- ---------------
1 Monitor 21/HR/M 889.00 711.20 5 3,556.00
2 Laptop 128/12/56/v90/110 3,219.00 2,575.20 5 12,876.00
3 LaserPro 600/6/BW 498.00 398.40 5 1,992.00
SQL> commit;
Notice in the previous output that the LaserPro 600 printer is added to the order, but the order total does not reflect the additional $1992. The status update transaction is able to view changes made by the partial transaction. Because session A issued a commit, its serializable transaction ends. Either session is now able to record its view of the orders table, and the statement that is recorded last gets to determine the data in the order header. If session A completes first, session B alters the order status to Processing, but the order total remains wrong. If session B completes first, session A sets the correct order total, but the order is returned to an order status of New. Either option results in a lost update, which demonstrates why it’s so critical to ensure that a transaction completes a single, logical unit of work. Because of session A’s partial transaction, data consistency has been jeopardized.
What if session B is running a report instead of updating the order’s status? Session A eventually results in a consistent update, but session B may end up reporting inaccurate data. This is a slightly less serious infraction because the data in the database are accurate. However, end users make decisions based on reports, and the impact of a poorly placed commit affects decisions to be made. The best solution to this issue is twofold. First, the code executed in session A should be corrected to removed the ill-placed commit and to ensure the entire transaction commits or fails as a single unit. Second, if data are changing quickly and the reports are not bound by date or time ranges, setting the report transaction to ensure a repeatable read may also be advisable.
Within our main transaction, we have the option of calling an autonomous transaction, which is an independent transaction that can be called from within another transaction. The autonomous transaction is able to commit or roll back its changes without impacting the calling, or main, transaction. Autonomous transactions are very useful if you have information you need to store, regardless of the final resolution of the main transaction. Error logging is possibly the best example of a good use of autonomous transactions, and in some cases auditing is an appropriate use as well, although overusing autonomous transactions is not a good idea. For most of us, there are better tools available in the database for auditing, and any attempts to circumvent normal database or transaction behavior is likely to create problems eventually.
So when would you want to use an autonomous transaction? I can think of a few examples in our ordering system, and—in both cases—the goal is to retain information to prevent lost sales opportunities. For example, we might want to record the customer ID and a timestamp in an order_log table in case the order fails. If the transaction is successful, the entry in order_log notes the order was created successfully. This allows us to provide our sales team with a report on any attempted orders that were not completed.
If you’ve done much shopping online, you may have received one of those e-mail reminders that you have left items in your shopping cart. Maybe you were shopping but something came up and you navigated away from the site, or perhaps you decided you didn’t really need to purchase those items after all. Either way, the vendor knows you were interested enough in the items to think about buying them, and they don’t want to miss an opportunity to sell products to an interested customer. I’ve been browsing Amazon lately for diving equipment, in part because I’m still learning about the gear and in part to do a little price comparison with my local dive shop. Within a day or two, Amazon sent me an e-mail to let me know about a special sale on one of the products I was browsing. I find this a little disconcerting, especially when I haven’t even logged in while browsing, but I have to admit it can be awfully tempting when you receive the news that the shiny, expensive piece of equipment you really want now costs 20 percent less than before.
Another possibility for an autonomous transaction is to record customer information when new customers place their first order. Creating a new customer can be considered a separate logical unit of work, so we aren’t breaking any of the transaction design rules by committing the customer information outside the order. If the order is interrupted for any reason, it is advantageous to retain the contact data so someone can follow up with the customer to make sure the order is placed correctly.
In Listing 14-11, we create an order_log table with four fields: customer_id, order_id, order_date, and order_status. Next, we create an autonomous transaction in a procedure. The record_new_order procedure logs the customer ID, the order ID, and the current date, committing the information immediately. We add a call to the procedure in the order transaction as soon as the order ID and customer ID are known.
Listing 14-11. Creating the Autonomous Order Logging Transaction
SQL> @autonomous_transaction
SQL> create table order_log
(
customer_id number not null,
order_id number not null,
order_date date not null,
order_outcome varchar2(10),
constraint order_log_pk primary key (customer_id, order_id, order_date)
);
Table created.
SQL> create or replace procedure record_new_order (p_customer_id IN NUMBER,
p_order_id IN NUMBER)
as
pragma autonomous_transaction;
begin
insert into order_log
(customer_id, order_id, order_date)
values
(p_customer_id, p_order_id, sysdate);
commit;
end;
/
Procedure created.
Listing 14-12 shows the execution of a new order transaction containing the autonomous transaction to log the customer information. The main transaction is rolled back, yet when we query the order_log table, the customer information is stored. This is because the write to the order_log table is an autonomous transaction and does not depend on the successful completion of the calling transaction.
Listing 14-12. Executing an Order Transaction with the Order Logging Autonomous Transaction
SQL> @order_transaction
SQL> WHENEVER SQLERROR EXIT SQL.SQLCODE ROLLBACK;
SQL> variable o number
SQL> execute :o := order_id.nextval
PL/SQL procedure successfully completed.
SQL> variable c number
SQL> execute :c := &customer_id
Enter value for customer_id: 264
PL/SQL procedure successfully completed.
SQL> execute oe.record_new_order(:c,:o);
PL/SQL procedure successfully completed.
SQL> variable s number
SQL> execute :s := &salesperson_id
Enter value for salesperson_id: 145
PL/SQL procedure successfully completed.
SQL> variable d number
SQL> execute :d := &discount
Enter value for discount: .1
PL/SQL procedure successfully completed.
SQL> savepoint create_order;
Savepoint created.
SQL> insert into orders
(order_id, order_date, order_mode, order_status, customer_id, sales_rep_id)
values
(:o, sysdate, 'direct', 1, :c, :s) ;
1 row created.
SQL> --- Add first ordered item and reduce on-hand inventory
SQL> savepoint detail_item1;
Savepoint created.
SQL> variable i number
SQL> execute :i := &first_item
Enter value for first_item: 2335
PL/SQL procedure successfully completed.
SQL> variable q number
SQL> execute :q := &item_quantity
Enter value for item_quantity: 1
PL/SQL procedure successfully completed.
SQL> variable p number
SQL> execute :p := get_ListPrice(:i)
PL/SQL procedure successfully completed.
SQL> insert into order_items
(order_id, line_item_id, product_id,
unit_price, discount_price, quantity)
values
(:o, 1, :i, :p, :p-(:p*:d), :q) ;
1 row created.
SQL> update inventories set quantity_on_hand = quantity_on_hand - :q
where product_id = :i and warehouse_id = 1 ;
1 row updated.
SQL> --- Get Order Total
SQL> variable t number
SQL> execute :t := get_OrderTotal(:o)
PL/SQL procedure successfully completed.
SQL> -- Request credit authorization
SQL> savepoint credit_auth;
Savepoint created.
SQL> execute billing.credit_request(:c,:t);
Customer ID = 264
Amount = 90
Authorization = 99
PL/SQL procedure successfully completed.
SQL> --- Update order total
SQL> savepoint order_total;
Savepoint created.
SQL> update orders set order_total = :t where order_id = :o ;
1 row updated.
SQL> select order_id, customer, mobile, status, order_total, order_date
from order_detail_header
where order_id = :o ;
ORDER_ID CUSTOMER MOBILE STATUS ORDER_TOTAL ORDER_DATE
---------- ------------------------- --------------- ------------ -------------- -----------
5020 George Adjani +1 215 123 4702 New 90.00 05 Jul 2010
SQL> select line_item_id ITEM, product_name, unit_price, discount_price, quantity, line_item_total
from order_detail_line_items
where order_id = :o
order by line_item_id ;
ITEM PRODUCT_NAME UNIT_PRICE DISCOUNT_PRICE QUANTITY LINE_ITEM_TOTAL
----- ------------------------ ---------- -------------- ---------- ---------------
1 Mobile phone 100.00 90.00 1 90.00
SQL> rollback;
Rollback complete.
SQL> select * from order_log;
CUSTOMER_ID ORDER_ID ORDER_DATE ORDER_STATUS
----------- -------- ------------------- ------------
264 5020 2010-07-05 00:45:56
The order log retains a committed record of the attempted order. As for the order status, there are several ways we can handle this. We can create another procedure that sets the order status in the order_log table when the order is committed by the application. If the order status is not populated in order_log, we then know the order has not been committed. We could also schedule a process to compare the order_log table with the orders table. If no record is found in the orders table, we then update the order_log table to note the order failed.
When using autonomous transactions, be certain that you are not dividing a transaction or circumvent normal database behavior. Think carefully about the effect you create when you allow the autonomous transaction to commit while rolling back the main transaction. The work in the autonomous transaction should clearly be its own logical unit of work.
Summary
Transactions are the heart of a database. We create databases to store information and, if that information is going to be useful, the data must be protected and they must remain consistent. If we jeopardize the integrity of the data, we have devalued the system significantly. Data integrity is an all-or-nothing proposition; either we have it or we don’t. Although I’ve heard people use percentage values to describe a database’s level of accuracy, this seems to be a downward spiral into increasing uncertainty. When we know part of the data are wrong, how do we know any of the data are accurate? And how do we know which part of the data we can trust?
If our data are to remain trustworthy, we need to ensure that each transaction complies with the ACID properties. Transactions must be atomic, containing one logical unit of work that succeeds or fails as a whole. Transactions must be consistent; they need to ensure the data are consistent when they begin, and that the data remain consistent when the transaction ends. Transactions should occur in isolation; uncommitted changes should not be visible to users or other transactions, and some transactions require higher levels of isolation than others. Transactions must be durable; when the changes have been committed to the database and the database has responded that the changes exist, users should be able to count on the fact that there is a record of their changes.
Fortunately, Oracle makes it fairly easy for us to build ACID-compliant transactions as long as we define the boundaries of our transaction carefully and accurately. Oracle does not require us to specify that we are starting a new transaction; instead, the database knows which kinds of statements begin a transaction, and it creates a transaction ID to track the operations within it. Always commit or roll back your transactions specifically, because failing to do so can make those transaction boundaries a little fuzzy. Relying on the default behavior of software tools is risky because the behavior may change in a future release.
Building sound transactions requires both technical skills and functional knowledge, and having both of those is a rare and valuable commodity in the information technology (IT) industry. This book provides a solid foundation for the development of your technical skills—and you can develop these skills further by following up with the reference material mentioned earlier—but, learning to apply these skills requires practice. Start by downloading the changes I made to the OE schema and build a few transactions of your own. Deliberately introduce some bad choices just to see what happens. (But don’t leave that code lying around; it can be dangerous!) Experimenting with isolation levels can be particularly interesting. Practice building a few more complex transactions, and make sure the transaction fails if any part of it fails. Then, add some custom exception handling and savepoints so that you don’t have to lose the entire transaction if you need to revert part of it. When you’ve got something you’re proud of, wrap it up in a procedure and be sure to share what you’ve learned with someone else.