
10.1. Clustering
Replacing a single server with a cluster of servers is often a good technique for scaling applications to support greater number of clients. Clustering multiple servers implies that multiple instances act in unison, serving external clients as a single logical entity. Functionality is typically replicated across the clustered servers, and members of a cluster often share state information.
Clustering efforts could involve either vertical clustering or horizontal clustering. In vertical clustering, multiple instances of a software server are installed on the same piece of hardware. In contrast to this, in horizontal clustering multiple instances of a software server are installed on different pieces of hardware.
Vertical clustering helps optimize hardware's CPU and memory usage. It does not provide fallback options on a hardware failure though. Horizontal clustering, on the other hand, provides a failover option among servers, in addition to providing scaling capabilities.
Besides software clustering, one also has the choice of hardware clustering, in which case a load balancer acts as the front end for calls to the clustered hardware infrastructure. Typically, a load balancer optimizes the way requests from clients are distributed among the clustered members. Once a load balancer associates a client to a cluster member, it sends all subsequent requests from that client to the same cluster member.
Software and hardware clustering can be combined. In this section, though, I will focus on software clustering.
You can cluster a set of BlazeDS instances to enhance the scalability and availability of your application. Clustered instances of BlazeDS share data and messages across instances. Therefore, message producers connected to a clustered server instance can send messages to message consumers connected to a different server within the same cluster. Besides sharing state information and routing information through the clustered servers, clustering provides for channel failover support.
Flex applications connect to a BlazeDS destination via a Channel. For example, a Flex application could connect to a RemoteObject, using an instance of mx.messaging.channels.AMFChannel. In clustered scenarios, channel failover is possible. That is, if a Flex application fails to connect to a destination via a channel to a server, connection via alternative channels and connection to alternative servers, in the cluster, is tried. Channel failover is supported for remote procedure call– and message–based services.
10.1.1. Channel Failover
When a Flex client tries to connect for the first time to a server in a cluster, it receives a set of endpoint URI(s) for possible channels that it can connect to. This returned set of channels is saved locally in the Channel.failoverURIs property in the client. The client refers to this property when it relies on channel failover to connect to a cluster of servers. The order followed for failover is illustrated in a flow diagram in Figure 10-1.
In order to support failover, all servers in a cluster should define the same set of channels for a destination and specify the same security policy.
Failover is also impacted by retry configurations and the timeout property. Flex-side RPC and message service components allow developers to configure a few such properties. Following is a list of failover-related client-side properties:
reconnectAttempts—A Producer component property that defines the number of times the producer should attempt to reconnect on connection failure. The default value is 0, which implies no retries. For indefinite retries, set the value to −1.
reconnectInterval—A Producer property that defines the interval between reconnect attempts. Setting the property value to 0 disables the retries. The default value is 5000 milliseconds, or 5 seconds.
resubscribeAtttempts—A Consumer property that defines the number of times the consumer should attempt to resubscribe on connection failure. The default value is 5. For indefinite retries, set the value to −1.
resubscribeInterval—A Consumer property that defines the interval between resubscribe attempts. Setting the property value to 0 disables the retries. The default value is 5000 milliseconds, or 5 seconds.
requestTimeout—A property of a RemoteObject, a WebService, an HTTPService, a Producer, and a Consumer that defines the time interval beyond which a request for which no response is received is timed out. An acknowledgment, a successful result, or a fault could be a response to a request.
connectTimeout—A property of a Channel that defines when a hung connection should be timed out.
Figure 10.1. Figure 10-1
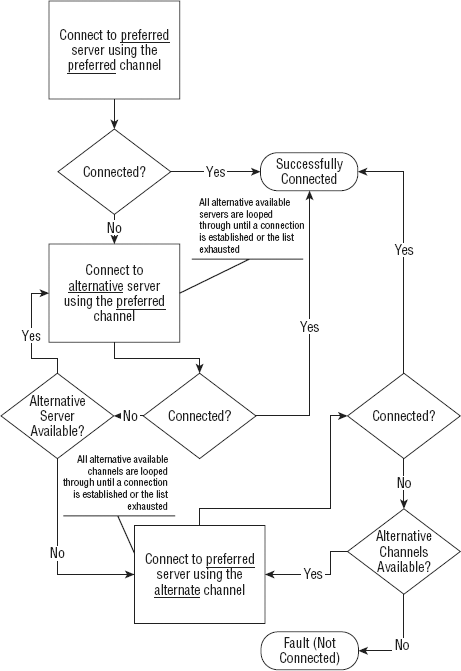
Each of these properties impacts the way that a fault event is finally dispatched after connection attempts are made across all servers and all channels in a cluster.
While I have explicitly mentioned that BlazeDS servers can be clustered, I have explained little about how they can be clustered and what makes the data and messages replicate successfully across the cluster. Next, I will attempt to explain the infrastructure that supports clustering BlazeDS servers.
10.1.2. Clustering Powered by JGroups
JGroups (www.jgroups.org) is an open source toolkit for reliable multicast communication. JGroups allows the creation of groups spread across the network, where members of a group can send messages to each other using TCP, UDP, and JMS. Messages can be sent point-to-point and point-to-multipoint. The toolkit supports detection and notification as members join, leave, or crash.
BlazeDS leverages JGroups to propagate data and message across a cluster. You need to configure JGroups to enable BlazeDS clustering.
When you download the turnkey distribution of BlazeDS, you will find a resources folder in that distribution. Within the resources folder you will find a folder named clustering. All the JGroups-related packages and configuration files are in the clustering folder.
To use JGroups, first copy jgroups.jar to the WEB-INF/lib folder of your BlazeDS-powered Flex application. Then, copy jgroups-tcp.xml and jgroups-udp.xml to the WEB-INF/flex folder. Finally configure JGroups to use it with BlazeDS.
Use TCP multicast over UDP multicast with JGroups for reliability. You can configure JGroups for BlazeDS to use TCP multicast by making entries in jgroups-tcp.xml as follows:
<TCP bind_addr="<IP Address or Host Name>" start_port="7800" loopback="false"/>
<TCPPING timeout="3000"
initial_hosts="cluster_server1.com[7800],
cluster_server2.com[7800],cluster_server3.com[7800]"
port_range="1"
num_initial_members="3"/>
<FD_SOCK/>
<FD timeout="6000" max_tries="4"/>
<VERIFY_SUSPECT timeout="1500" down_thread="false" up_thread="false"/>
<MERGE2 max_interval="10000" min_interval="2000"/>
<pbcast.NAKACK gc_lag="100" retransmit_timeout="600,1200,2400,4800"/>
<pbcast.STABLE stability_
delay="1000" desired_avg_gossip="20000" down_thread="false"
max_bytes="0" up_thread="false"/>
<pbcast.GMS
print_local_addr="true" join_timeout="5000" join_retry_timeout="2000" shun="true"/>The TCP bind_addr holds the IP address or the hostname of the server on which this configuration file is deployed. The start_port is the port on which one can make a connection to the JGroups member. The TCPPING property points to all the other members in the group. Specifically, the initial_hosts property holds the IP address or the domain name of the other cluster members. Much of the rest of it is present in the default jgroups-tcp.xml file available with the distribution.
To use this JGroups configuration with a BlazeDS cluster, make the following entry in services-config.xml:
<?xml version="1.0"?>
<services-config>
...
<clusters>
<cluster id="blazeds-cluster" properties="jgroups-tcp.xml" default="true"/>
</clusters>
...
</services-config>Then refer to this cluster within a destination configuration as follows:
<destination id="aDestination">
...
<properties>
<network>
<cluster ref="blazeds-cluster"/>
</network>
</properties>
...
</destination>The cluster "blazeds-cluster" has a property named "default" whose value equals "true" and this cluster is the default cluster. Therefore, even if you only specified <cluster/> within the network property of a destination in the example illustrated, the "blazeds-cluster" would still be used.
If the destination that uses a cluster is a messaging destination, then you also have the option to configure server-to-server messaging, which sends subscribe and unsubscribe messages to all servers in the cluster. but sends data messages only to the active cluster members. To configure server-to-server messaging in a messaging destination, add the following:
<destination id="aTopic">
<properties>
...
<server>
<cluster-message-routing>server-to-server</cluster-message-routing>
</server>
</properties>
...
</destination>That completes most of the clustering configuration. By now you are, hopefully, convinced that BlazeDS clustering is beneficial and easy to implement.
While clustering provides connection scalability advantages, sometimes the performance bottlenecks are the result of long-running data interchanges over the connections. Such cases occur when data packets exchanged are very large and bulky or the connection bandwidth is too small, or both. In the next section, you will learn to compress the data and the send it across the wire. Compressed data increases resource utilization efficiency and enhances scalability.