
Linked List Problems
The solutions to the linked list problems that follow can be implemented in any language that supports dynamic memory, but because you rarely implement your own linked lists in languages like Java and C#, these problems make most sense in C.
Stack Implementation
This problem is designed to determine three things:
A stack is a last-in-first-out (LIFO) data structure: Elements are always removed in the reverse order in which they were added, much in the same way that you add or remove a dish from a stack of dishes. The add element and remove element operations are conventionally called push and pop, respectively. Stacks are useful data structures for tasks that are divided into multiple subtasks. Tracking return addresses, parameters, and local variables for subroutines is one example of stack use; tracking tokens when parsing a programming language is another.
One of the ways to implement a stack is by using a dynamic array, an array that changes size as needed when elements are added. (See Chapter 6, “Arrays and Strings,” for a more complete discussion of arrays.) The main advantage of dynamic arrays over linked lists is that arrays offer random access to the array elements — you can immediately access any element in the array if you know its index. However, operations on a stack always work on one end of the data structure (the top of the stack), so the random accessibility of a dynamic array gains you little. In addition, as a dynamic array grows, it must occasionally be resized, which can be a time-consuming operation as elements are copied from the old array to the new array.
Linked lists usually allocate memory dynamically for each element. Depending on the overhead of the memory allocator, these allocations are often more time consuming than the copies required by a dynamic array, so a stack based on a dynamic array is usually faster than one based on a linked list. Implementing a linked list is less complicated than implementing a dynamic array, so in an interview, a linked list is probably the best choice for your solution. Whichever choice you make, be sure to explain the pros and cons of both approaches to your interviewer.
After explaining your choice, you can design the routines and their interfaces. If you take a moment to design your code before writing it, you can avoid mistakes and inconsistencies in implementation. More important, this shows you won’t skip right to coding on a larger project where good planning is essential to success. As always, talk to the interviewer about what you’re doing.
Your stack will need push and pop routines. What will the prototype for these functions be? Each function must be passed the stack it operates on. The push operation will be passed the data it is to push, and pop will return a piece of data from the stack.
The simplest way to pass the stack is to pass a pointer to the stack. Because the stack will be implemented as a linked list, the pointer to the stack will be a pointer to the head of the list. In addition to the pointer to the stack, you could pass the data as a second parameter to push. The pop function could take only the pointer to the stack as an argument and return the value of the data it popped from the stack.
To write the prototypes, you need to know the type of the data that will be stored on the stack. You should declare a struct for a linked list element with the appropriate data type. If the interviewer doesn’t make any suggestion, storing void pointers is a good general-purpose solution:
typedef struct Element {
struct Element *next;
void *data;
} Element;The corresponding prototypes for push and pop follow:
void push( Element *stack, void *data );
void *pop( Element *stack );Now consider what happens in these routines in terms of proper functionality and error handling. Both operations change the first element of the list. The calling routine’s stack pointer must be modified to reflect this change, but any change you make to the pointer that is passed to these functions won’t be propagated back to the calling routine. You can solve this problem by having both routines take a pointer to a pointer to the stack. This way, you can change the calling routine’s pointer so that it continues to point at the first element of the list. Implementing this change results in the following:
void push( Element **stack, void *data );
void *pop( Element **stack );What about error handling? The push operation needs to dynamically allocate memory for a new element. Memory allocation in C is an operation that can fail, so remember to check that the allocation succeeded when you write this routine. (In C++ an exception is thrown when allocation fails, so the error handling is somewhat different.)
You also need some way to indicate to the calling routine whether the push succeeded or failed. In C, it’s generally most convenient to have a routine indicate success or failure by its return value. This way, the routine can be called from the condition of an if statement with error handling in the body. Have push return true for success and false for failure. (Throwing an exception is also an option in C++ and other languages with exception support.)
Can pop fail? It doesn’t have to allocate memory, but what if it’s asked to pop an empty stack? It should indicate that the operation was unsuccessful, but it still has to return data when it is successful. A C function has a single return value, but pop needs to return two values: the data it popped and an error code.
This problem has a number of possible solutions, none of which are entirely satisfactory. One approach is to use the single return value for both purposes. If pop is successful, have it return the data; if it is unsuccessful, return NULL. As long as your data is a pointer type and you never need to store null pointers on the stack, this works. If you have to store null pointers, however, there’s no way to determine whether the null pointer returned by pop represents a legitimate element that you stored or an empty stack. Another option is to return a special value that can’t represent a valid piece of data — a pointer to a reserved memory block, for example, or (for stacks dealing with non-negative numbers only) a negative value. Although restricting the values that can be stored on the stack might be acceptable in some cases, assume that for this problem it is not.
You must return two distinct values. How else can a function return data? The same way the stack parameter is handled: by passing a pointer to a variable. The routine can return data by using the pointer to change the variable’s value, which the caller can access after popping the stack.
There are two possibilities for the interface to pop that use this approach to return two values. You can have pop take a pointer to an error code variable as an argument and return the data, or you can have it take a pointer to a data variable and return an error code. Intuitively, most programmers would expect pop to return data. However, using pop is awkward if the error code is not its return value: Instead of simply calling pop in the condition of an if or while statement, you must explicitly declare a variable for the error code and check its value in a separate statement after you call pop. Furthermore, push would take a data argument and return an error code, whereas pop would take an error code argument and return data. This may offend your sense of symmetry (it does ours).
Neither alternative is clearly correct; there are problems with either approach. In an interview, it wouldn’t matter much which alternative you chose as long as you identified the pros and cons of each and justified your choice. We think error code arguments are particularly irksome, so this discussion continues by assuming you chose to have pop return an error code. This results in the following prototypes:
bool push( Element **stack, void *data );
bool pop( Element **stack, void **data );You also want to write createStack and deleteStack functions, even though neither of these is absolutely necessary in a linked list stack implementation: You could delete the stack by calling pop until the stack is empty and create a stack by passing push a null pointer as the stack argument. However, writing these functions provides a complete, implementation-independent interface to the stack. A stack implemented as a dynamic array would need createStack and deleteStack functions to properly manage the underlying array. By including these functions in your implementation, you create the possibility that someone could change the underlying implementation of the stack without needing to change the programs that use the stack — always a good thing.
With the goals of implementation independence and consistency in mind, it’s a good idea to have these functions return error codes, too. Even though in a linked list implementation neither createStack nor deleteStack can fail, they might fail under a different implementation, such as if createStack couldn’t allocate memory for a dynamic array. If you design the interface with no way for these functions to indicate failure, you severely handicap anyone who might want to change your implementation.
Again, you face the same problem as with pop: createStack must return both the empty stack and an error code. You can’t use a null pointer to indicate failure because a null pointer is the empty stack for a linked list implementation. In keeping with the previous decision, we write an implementation with an error code as the return value. Because createStack can’t return the stack as its value, it must take a pointer to a pointer to the stack. Because all the other functions take a pointer to the stack pointer, it makes sense to have deleteStack take its stack parameter in the same way. This way you don’t need to remember which functions require only a pointer to a stack and which take a pointer to a pointer to a stack — they all work the same way. This reasoning gives you the following prototypes:
bool createStack( Element **stack );
bool deleteStack( Element **stack );When everything is designed properly, the coding is fairly simple. The createStack routine sets the stack pointer to NULL and returns success:
bool createStack( Element **stack ){
*stack = NULL;
return true;
}The push operation allocates the new element, checks for failure, sets the data of the new element, places it at the top of the stack, and adjusts the stack pointer:
bool push( Element **stack, void *data ){
Element *elem = malloc( sizeof(Element) );
if( !elem ) return false;
elem->data = data;
elem->next = *stack;
*stack = elem;
return true;
}The pop operation checks that the stack isn’t empty, fetches the data from the top element, adjusts the stack pointer, and frees the element that is no longer on the stack, as follows:
bool pop( Element **stack, void **data ){
Element *elem;
if( !(elem = *stack) ) return false;
*data = elem->data;
*stack = elem->next;
free( elem );
return true;
}Although deleteStack could call pop repeatedly, it’s more efficient to simply traverse the data structure, freeing as you go. Don’t forget that you need a temporary pointer to hold the address of the next element while you free the current one:
bool deleteStack( Element **stack ){
Element *next;
while( *stack ){
next = (*stack)->next;
free( *stack );
*stack = next;
}
return true;
}Before the discussion of this problem is complete, it is worth noting (and probably worth mentioning to the interviewer) that the interface design would be much more straightforward in an object-oriented language. The createStack and deleteStack operations become the constructor and destructor, respectively. The push and pop routines are bound to the stack object, so they don’t need to have the stack explicitly passed to them, and the need for pointers to pointers evaporates. An exception can be thrown when there’s an attempt to pop an empty stack or a memory allocation fails, which enables you to use the return value of pop for data instead of an error code. A minimal C++ version looks like the following:
class Stack
{
public:
Stack() : head( NULL ) {};
~Stack();
void push( void *data );
void *pop();
protected:
class Element {
public:
Element( Element *n, void *d ): next(n), data( d ) {}
Element *getNext() const { return next; }
void *value() const { return data; }
private:
Element *next;
void *data;
};
Element *head;
};
Stack::~Stack() {
while( head ){
Element *next = head->getNext();
delete head;
head = next;
}
}
void Stack::push( void *data ){
//Allocation error will throw exception
Element *element = new Element(head,data);
head = element;
}
void *Stack::pop() {
Element *popElement = head;
void *data;
/* Assume StackError exception class is defined elsewhere */
if( head == NULL )
throw StackError( E_EMPTY );
data = head->value();
head = head->getNext();
delete popElement;
return data;
}
A more complete C++ implementation should include a copy constructor and assignment operator, because the default versions created by the compiler could lead to multiple deletes of the same Element due to inadvertent sharing of elements between copies of a Stack.
Maintain Linked List Tail Pointer
bool delete( Element *elem );
bool insertAfter( Element *elem, int data );
This problem seems relatively straightforward. Deletion and insertion are common operations on a linked list, and you should be accustomed to using a head pointer for the list. The requirement to maintain a tail pointer is the only unusual aspect of this problem. This requirement doesn’t seem to fundamentally change anything about the list or the way you operate on it, so it doesn’t look as if you need to design any new algorithms. Just be sure to update the head and tail pointers when necessary.
When do you need to update these pointers? Obviously, operations in the middle of a long list do not affect either the head or tail. You need to update the pointers only when you change the list such that a different element appears at the beginning or end. More specifically, when you insert a new element at either end of the list, that element becomes the new beginning or end of the list. When you delete an element at the beginning or end of the list, the next-to-first or next-to-last element becomes the new first or last element.
For each operation you have a general case for operations in the middle of the list and special cases for operations at either end. When you deal with many special cases, it can be easy to miss some of them, especially if some of the special cases have more specific special cases of their own. One technique to identify special cases is to consider what circumstances are likely to lead to special cases being invoked. Then, you can check whether your proposed implementation works in each of these circumstances. If you discover a circumstance that creates a problem, you have discovered a new special case.
The circumstance where you are instructed to operate on the ends of the list has already been discussed. Another error-prone circumstance is a null pointer argument. The only other thing that can change is the list on which you are operating — specifically, its length.
What lengths of lists may be problematic? You can expect somewhat different cases for the beginning, middle, and end of the list. Any list that doesn’t have these three distinct classes of elements could lead to additional special cases. An empty list has no elements, so it obviously has no beginning, middle, or end elements. A one-element list has no middle elements and one element that is both the beginning and end element. A two-element list has distinct beginning and end elements, but no middle element. Any list longer than this has all three classes of elements and is effectively the general case of lists — unlikely to lead to additional special cases. Based on this reasoning, you should explicitly confirm that your implementation works correctly for lists of length 0, 1, and 2.
At this point in the problem, you can begin writing delete. As mentioned earlier, you need a special case for deleting the first element of the list. You can compare the element to be deleted to head to determine whether you need to invoke this case:
bool delete( Element *elem ){
if (elem == head) {
head = elem->next;
free( elem );
return true;
}
...Now write the general middle case. You need an element pointer to keep track of your position in the list. (Call the pointer curPos.) Recall that to delete an element from a linked list, you need a pointer to the preceding element so that you can change its next pointer. The easiest way to find the preceding element is to compare curPos->next to elem, so curPos points to the preceding element when you find elem.
You also need to construct your loop so you don’t miss any elements. If you initialize curPos to head, then curPos->next starts as the second element of the list. Starting at the second item is fine because you treat the first element as a special case, but make your first check before advancing curPos or you’ll miss the second element. If curPos becomes NULL, you have reached the end of the list without finding the element you were supposed to delete, so you should return failure. The middle case yields the following (added code is bolded):
bool delete( Element *elem ){
Element *curPos = head;
if (elem == head) {
head = elem->next;
free( elem );
return true;
}
while( curPos ){
if( curPos->next == elem ){
curPos->next = elem->next;
free( elem );
return true;
}
curPos = curPos->next;
}
return false;
...Next, consider the last element case. The last element’s next pointer is NULL. To remove it from the list, you need to make the next-to-last element’s next pointer NULL and free the last element. If you examine the loop constructed for middle elements, you see that it can delete the last element as well as middle elements. The only difference is that you need to update the tail pointer when you delete the last element. If you set curPos->next to NULL, you know you changed the end of the list and must update the tail pointer. Adding this to complete the function, you get the following:
bool delete( Element *elem ){
Element *curPos = head;
if( elem == head ){
head = elem->next;
free( elem );
}
while( curPos ){
if( curPos->next == elem ){
curPos->next = elem->next;
free( elem );
if( curPos->next == NULL )
tail = curPos;
return true;
}
curPos = curPos->next;
}
return false;
}This solution covers the three discussed special cases. Before you present the interviewer with this solution, you should check behavior for null pointer arguments and the three potentially problematic list length circumstances.
What happens if elem is NULL? The while loop traverses the list until curPos->next is NULL (when curPos is the last element). Then, on the next line, evaluating elem->next dereferences a null pointer. Because it’s never possible to delete NULL from the list, the easiest way to fix this problem is to return false if elem is NULL.
If the list has zero elements, then head and tail are both NULL. Because you’ll check that elem isn’t NULL, elem == head will always be false. Further, because head is NULL, curPos will be NULL, and the body of the while loop won’t be executed. There doesn’t seem to be any problem with zero-element lists. The function simply returns false because nothing can be deleted from an empty list.
Now try a one-element list. In this case, head and tail both point to the one element, which is the only element you can delete. Again, elem == head is true. elem->next is NULL, so you correctly set head to NULL and free the element; however, tail still points to the element you just freed. As you can see, you need another special case to set tail to NULL for one-element lists.
What about two-element lists? Deleting the first element causes head to point to the remaining element, as it should. Similarly, deleting the last element causes tail to be correctly updated. The lack of middle elements doesn’t seem to be a problem. You can add the two additional special cases and then move on to insertAfter:
bool delete( Element *elem ){
Element *curPos = head;
if( !elem )
return false;
if( elem == head ){
head = elem->next;
free( elem );
/* special case for 1 element list */
if( !head )
tail = NULL;
return true;
}
while( curPos ){
if( curPos->next == elem ){
curPos->next = elem->next;
free( elem );
if( curPos->next == NULL )
tail = curPos;
return true;
}
curPos = curPos->next;
}
return false;
}You can apply similar reasoning to writing insertAfter. Because you allocate a new element in this function, you must take care to check that the allocation is successful and that you don’t leak any memory. Many of the special cases encountered in delete are relevant in insertAfter, however, and the code is structurally similar:
bool insertAfter( Element *elem, int data ){
Element *newElem, *curPos = head;
newElem = malloc( sizeof(Element) );
if( !newElem )
return false;
newElem->data = data;
/* Insert at beginning of list */
if( !elem ){
newElem->next = head;
head = newElem;
/* Special case for empty list */
if( !tail )
tail = newElem;
return true;
}
while( curPos ){
if( curPos == elem ){
newElem->next = curPos->next;
curPos->next = newElem;
/* Special case for inserting at end of list */
if( !(newElem->next) )
tail = newElem;
return true;
}
curPos = curPos->next;
}
/* Insert position not found; free element and return failure */
free( newElem );
return false;
}This problem turns out to be an exercise in special cases. It’s not particularly interesting or satisfying to solve, but it’s good practice. Many interview problems have special cases, so you should expect to encounter them frequently. In the real world of programming, unhandled special cases represent bugs that may be difficult to find, reproduce, and fix. Programmers who identify special cases as they are coding are likely to be more productive than those who find special cases through debugging. Intelligent interviewers recognize this and pay attention to whether a candidate identifies special cases as part of the coding process or needs to be prompted to recognize special cases.
Bugs in removeHead
void removeHead( ListElement *head ){
free( head ); // Line 1
head = head->next; // Line 2
}
Bug-finding problems occur with some frequency, so it’s worthwhile to discuss a general strategy that you can apply to this and other problems.
Because you will generally be given only a small amount of code to analyze, your bug-finding strategy will be a little different from real-world programming. You don’t need to worry about interactions with other modules or other parts of the program. Instead, you must do a systematic analysis of every line of the function without the help of a debugger. Consider four common problem areas for any function you are given:
Starting with the first step, verify that data comes into the function properly. In a linked list, you can access every element given only the head. Because you are passed the list head, you have access to all the data you require — no bugs so far.
Now do a line-by-line analysis of the function. The first line frees head — okay so far. Line 2 then assigns a new value to head but uses the old value of head to do this. That’s a problem. You have already freed head, and you are now dereferencing freed memory. You could try reversing the lines, but this would cause the element after head to be freed. You need to free head, but you also need its next value after it has been freed. You can solve this problem by using a temporary variable to store head’s next value. Then you can free head and use the temporary variable to update head. These steps make the function look like the following:
void removeHead( ListElement *head ){
ListElement *temp = head->next; // Line 1
free( head ); // Line 2
head = temp; // Line 3
}Now, move to step 3 of the strategy to make sure the function returns values properly. Though there is no explicit return value, there is an implicit one. This function is supposed to update the caller’s head value. In C, all function parameters are passed by value, so functions get a local copy of each argument, and any changes made to that local copy are not reflected outside the function. Any new value you assign to head on line 3 has no effect — another bug. To correct this, you need a way to change the value of head in the calling code. Variables cannot be passed by reference in C, so the solution is to pass a pointer to the variable you want to change — in this case, a pointer to the head pointer. After the change, the function should look like this:
void removeHead( ListElement **head ){
ListElement *temp = (*head)->next; // Line 1
free( *head ); // Line 2
*head = temp; // Line 3
}Now you can move on to the fourth step and check error conditions. Check a one-element and a zero-element list. In a one-element list, this function works properly. It removes the one element and sets the head to NULL, indicating that the head was removed. Now take a look at the zero-element case. A zero-element list is simply a null pointer. If head is a null pointer, you would dereference a null pointer on line 1. To correct this, check whether head is a null pointer and be sure not to dereference it in this case. This check makes the function look like the following:
void removeHead( ListElement **head ){
ListElement *temp;
if( head && *head ){
temp = (*head)->next;
free( *head );
*head = temp;
}
}You have checked that the body of the function works properly, that the function is called correctly and returns values correctly, and that you have dealt with the error cases. You can declare your debugging effort complete and present this version of removeHead to the interviewer as your solution.
Mth-to-Last Element of a Linked List
Why is this a difficult problem? Finding the mth element from the beginning of a linked list would be an extremely trivial task. Singly linked lists can be traversed only in the forward direction. For this problem you are asked to find a given element based on its position relative to the end of the list. While you traverse the list, however, you don’t know where the end is, and when you find the end, there is no easy way to backtrack the required number of elements.
You may want to tell your interviewer that a singly linked list is a particularly poor choice for a data structure when you frequently need to find the mth-to-last element. If you were to encounter such a problem while implementing a real program, the correct and most efficient solution would probably be to substitute a more suitable data structure (such as a doubly linked list) to replace the singly linked list. Although this comment shows that you understand good design, the interviewer still wants you to solve the problem as it was originally phrased.
How, then, can you get around the problem that there is no way to traverse backward through this data structure? You know that the element you want is m elements from the end of the list. Therefore, if you traverse m elements forward from an element and that places you exactly at the end of the list, you have found the element you were searching for. One approach is to simply test each element in this manner until you find the one you’re searching for. Intuitively, this feels like an inefficient solution because you will traverse over the same elements many times. If you analyze this potential solution more closely, you can see that you would be traversing m elements for most of the elements in the list. If the length of the list is n, the algorithm would be approximately O(mn). You need to find a solution more efficient than O(mn).
What if you store some of the elements (or, more likely, pointers or references to the elements) as you traverse the list? Then, when you reach the end of the list, you can look back m elements in your storage data structure to find the appropriate element. If you use an appropriate temporary storage data structure, this algorithm is O(n) because it requires only one traversal through the list. Yet this approach is far from perfect. As m becomes large, the temporary data structure would become large as well. In the worst-case scenario, this approach might require almost as much storage space as the list itself — not a particularly space-efficient algorithm.
Perhaps working back from the end of the list is not the best approach. Because counting from the beginning of the list is trivial, is there any way to count from the beginning to find the desired element? The desired element is m from the end of the list, and you know the value of m. It must also be l elements from the beginning of the list, although you don’t know l. However, l + m = n, the length of the list. It’s easy to count all the elements in the list. Then you can calculate l = n – m, and traverse l elements from the beginning of the list.
Although this process involves two passes through the list, it’s still O(n). It requires only a few variables’ worth of storage, so this method is a significant improvement over the previous attempt. If you could change the functions that modify the list such that they would increment a count variable for every element added and decrement it for every element removed, you could eliminate the count pass, making this a relatively efficient algorithm. Again, though this point is worth mentioning to the interviewer, he or she is probably looking for a solution that doesn’t modify the data structure or place any restrictions on the methods used to access it.
Assuming you must explicitly count the elements in the current algorithm, you must make almost two complete traversals of the linked list. A large list on a memory-constrained system might exist mostly in paged-out virtual memory (on disk). In such a case, each complete traversal of the list would require a large amount of disk access to swap the relevant portions of the list in and out of memory. Under these conditions, an algorithm that made only one complete traversal of the list might be significantly faster than an algorithm that made two traversals, even though they would both be O(n). Is there a way to find the target element with a single traversal?
The counting-from-the-beginning algorithm obviously demands that you know the length of the list. If you can’t track the length so that you know it ahead of time, you can determine the length only by a full-list traversal. There doesn’t seem to be much hope for getting this algorithm down to a single traversal.
Try reconsidering the previous linear time algorithm, which required only one traversal but was rejected for requiring too much storage. Can you reduce the storage requirements of this approach?
When you reach the end of the list, you are actually interested in only one of the m elements you’ve been tracking — the element that is m elements behind your current position. You are tracking the rest of the m elements merely because the element m behind your current position changes every time your position advances. Keeping a queue m elements long, where you add the current element to the head and remove an element from the end every time you advance your current position, ensures that the last element in the queue is always m elements behind your current position.
In effect, you are using this m element data structure to make it easy to implicitly advance an m-behind pointer in lock step with your current position pointer. However, this data structure is unnecessary — you can explicitly advance the m-behind pointer by following each element’s next pointer just as you do for your current position pointer. This is as easy as (or perhaps easier than) implicitly advancing by shifting through a queue, and it eliminates the need to track all the elements between your current position pointer and your m-behind pointer. This algorithm seems to be the one you’ve been looking for: linear time, a single traversal, and negligible storage requirements. Now you just need to work out the details.
You need to use two pointers: a current position pointer and an m-behind pointer. You must ensure that the two pointers are actually spaced m elements apart; then you can advance them at the same rate. When your current position is the end of the list, m-behind points to the mth-to-last element. How can you get the pointers spaced properly? If you count elements as you traverse the list, you can move the current position pointer to the mth element of the list. If you then start the m-behind pointer at the beginning of the list, they will be spaced m elements apart.
Are there any error conditions you need to watch for? If the list is less than m elements long, then there is no mth-to-last element. In such a case, you would run off the end of the list as you tried to advance the current position pointer to the mth element, possibly dereferencing a null pointer in the process. Therefore, check that you don’t hit the end of the list while doing this initial advance.
With this caveat in mind, you can implement the algorithm. It’s easy to introduce off-by-one errors in any code that spaces any two things m items apart or counts m items from a given point. You may want to refer to the exact definition of “mth to last” given in the problem and try a simple example on paper to make sure you get your counts right, particularly in the initial advancement of the current pointer.
ListElement *findMToLastElement( ListElement *head, int m ){
ListElement *current, *mBehind;
int i;
if (!head)
return NULL;
/* Advance current m elements from beginning,
* checking for the end of the list
*/
current = head;
for( i = 0; i < m; i++ ) {
if( current->next ){
current = current->next;
} else {
return NULL;
}
}
/* Start mBehind at beginning and advance pointers
* together until current hits last element
*/
mBehind = head;
while( current->next ){
current = current->next;
mBehind = mBehind->next;
}
/* mBehind now points to the element we were
* searching for, so return it
*/
return mBehind;
}List Flattening
typedef struct Node {
struct Node *next;
struct Node *prev;
struct Node *child;
int value;
} Node;
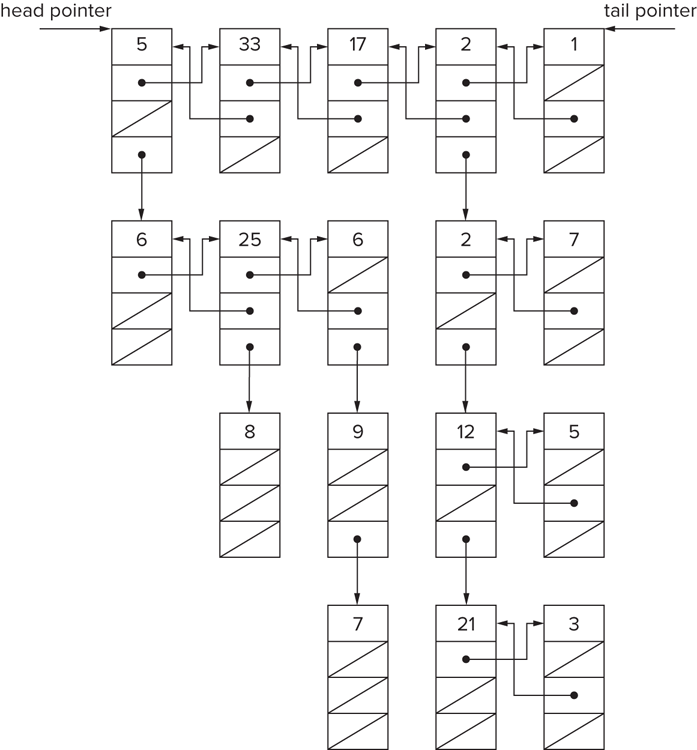
This list-flattening problem gives you plenty of freedom. You have simply been asked to flatten the list. There are many ways to accomplish this task. Each way results in a one-level list with a different node ordering. Start by considering several options for algorithms and the node orders they would yield. Then implement the algorithm that looks easiest and most efficient.
Begin by looking at the data structure. This data structure is a little unusual for a list. It has levels and children — somewhat like a tree. A tree also has levels and children, as you’ll see in the next chapter, but trees don’t have links between nodes on the same level. You might try to use a common tree traversal algorithm and copy each node into a new list as you visit it as a simple way to flatten the structure.
The data structure is not exactly a normal tree, so any traversal algorithm you use must be modified. From the perspective of a tree, each separate child list in the data structure forms a single extended tree node. This may not seem too bad: Where a standard traversal algorithm checks the child pointers of each tree node directly, you just need to do a linked list traversal to check all the child pointers. Every time you check a node, you can copy it to a duplicate list. This duplicate list will be your flattened list.
Before you work out the details of this solution, consider its efficiency. Every node is examined once, so this is an O(n) solution. There is likely to be some overhead for the recursion or data structure required for the traversal. In addition, you make a duplicate copy of each node to create the new list. This copying is inefficient, especially if the structure is large. See if you can identify a more efficient solution that doesn’t require so much copying.
So far, the proposed solution has concentrated on an algorithm, letting the ordering follow. Instead, try focusing on an ordering and then try to deduce an algorithm. You can focus on the data structure’s levels as a source of ordering. It helps to define the parts of a level as child lists. Just as rooms in a hotel are ordered by level, you can order nodes by the level in which they occur. Every node is in a level and appears in an ordering within that level (arranging the child lists from left to right). Therefore, you have a logical ordering just like hotel rooms. You can order by starting with all the first-level nodes, followed by all the second-level nodes, followed by all the third-level nodes, and so on. Applying these rules to the example data structure, you should get the ordering shown in Figure 4-4.

Now try to discover an algorithm that yields this ordering. One property of this ordering is that you never rearrange the order of the nodes in their respective levels, so you could connect all the nodes on each level into a list and then join all the connected levels. However, to find all the nodes on a given level so that you can join them, you would need to do a breadth-first search of that level. Breadth-first searching is inefficient, so you should continue to look for a better solution.
In Figure 4-3, the second level is composed of two child lists. Each child list starts with a different child of a first-level node. You could try to append the child lists one at a time to the end of the first level instead of combining the child lists.
To append the child lists one at a time, traverse the first level from the start, following the next pointers. Every time you encounter a node with a child, append the child (and thus the child list) to the end of the first level and update the tail pointer. Eventually, you append the entire second level to the end of the first level. You can continue traversing the first level and arrive at the start of the old second level. If you continue this process of appending children to the end of the first level, you eventually append every child list to the end and have a flattened list in the required order. More formally, this algorithm is as follows:
Start at the beginning of the first level
While you are not at the end of the first level
If the current node has a child
Append the child to the end of the first level
Update the tail pointer
Advance to next nodeThis algorithm is easy to implement because it’s so simple. In terms of efficiency, every node after the first level is examined twice. Each node is examined once when you update the tail pointer for each child list and once when you examine the node to see if it has a child. The nodes in the first level are examined only once when you examine them for children because you had a first-level tail pointer when you began. Therefore, there are no more than 2n comparisons in this algorithm, and it is an O(n) solution. This is the best time order you can achieve because every node must be examined. Although this solution has the same time order as the tree traversal approach considered earlier, it is more efficient because it requires no recursion or additional memory. (There are other equally efficient solutions to this problem. One such solution involves inserting child lists after their parents, rather than at the end of the list.)
The code for this algorithm is as follows. Note that the function takes a pointer to the tail pointer so that changes to the tail pointer are retained when the function returns:
void flattenList( Node *head, Node **tail ){
Node *curNode = head;
while( curNode ){
/* The current node has a child */
if( curNode->child ){
append( curNode->child, tail );
}
curNode = curNode->next;
}
}
/* Appends the child list to the end of the tail and updates ;
* the tail.
*/
void append( Node *child, Node **tail ){
Node *curNode;
/* Append the child child list to the end */
(*tail)->next = child;
child->prev = *tail;
/* Find the new tail, which is the end of the child list. */
for( curNode = child; curNode->next; curNode = curNode->next )
; /* Body intentionally empty */
/* Update the tail pointer now that curNode is the new tail. */
*tail = curNode;
}List Unflattening
This problem is the reverse of the previous problem, so you already know a lot about this data structure. One important insight is that you created the flattened list by combining all the child lists into one long level. To get back the original list, you must separate the long flattened list back into its original child lists.
Try doing the exact opposite of what you did to create the list. When flattening the list, you traversed down the list from the start and added child lists to the end. To reverse this, you go backward from the tail and break off parts of the first level. You could break off a part when you encounter a node that was the beginning of a child list in the unflattened list. Unfortunately, this is more difficult than it might seem because you can’t easily determine whether a particular node is a child (indicating that it started a child list) in the original data structure. The only way to determine whether a node is a child is to scan through the child pointers of all the previous nodes. All this scanning would be inefficient, so you should examine some additional possibilities to find a better solution.
One way to get around the child node problem is to go through the list from start to end, storing pointers to all the child nodes in a separate data structure. Then you could go backward through the list and separate every child node. Looking up nodes in this way frees you from repeated scans to determine whether a node is a child. This is a good solution, but it still requires an extra data structure. Try looking for a solution without an extra data structure.
It seems you have exhausted all the possibilities for going backward through the list, so try an algorithm that traverses the list from the start to the end. You still can’t immediately determine whether a node is a child. One advantage of going forward, however, is that you can find all the child nodes in the same order that you appended them to the first level. You also know that every child node began a child list in the original list. If you separate each child node from the node before it, you get the unflattened list back.
You can’t simply traverse the list from the start, find each node with a child, and separate the child from its previous node. You would get to the end of your list at the break between the first and second level, leaving the rest of the data structure untraversed. This approach seems promising, though. You can traverse every child list, starting with the first level (which is a child list itself). When you find a child, continue traversing the original child list and also traverse the newly found child list. You can’t traverse both at the same time, however. You could save one of these locations in a data structure and traverse it later. However, rather than design and implement this data structure, you can use recursion. Specifically, every time you find a node with a child, separate the child from its previous node, start traversing the new child list, and then continue traversing the original child list.
This is an efficient algorithm because each node is checked at most twice, resulting in an O(n) running time. Again, an O(n) running time is the best you can do because you must check each node at least once to see if it is a child. In the average case, the number of function calls is small in relation to the number of nodes, so the recursive overhead is not too bad. In the worst case, the number of function calls is no more than the number of nodes. This solution is approximately as efficient as the earlier proposal that required an extra data structure, but somewhat simpler and easier to code. Therefore, this recursive solution would probably be the best choice in an interview. In outline form, the algorithm looks like the following:
Explore path:
While not at the end
If current node has a child
Separate the child from its previous node
Explore path beginning with the child
Go onto the next nodeIt can be implemented in C as:
/* unflattenList wraps the recursive function and updates the tail pointer. */
void unflattenList( Node *start, Node **tail ){
Node *curNode;
exploreAndSeparate( start );
/* Update the tail pointer */
for( curNode = start; curNode->next; curNode = curNode->next )
; /* Body intentionally empty */
*tail = curNode;
}
/* exploreAndSeparate actually does the recursion and separation */
void exploreAndSeparate( Node *childListStart ){
Node *curNode = childListStart;
while( curNode ){
if( curNode->child ){
/* terminates the child list before the child */
curNode->child->prev->next = NULL;
/* starts the child list beginning with the child */
curNode->child->prev = NULL;
exploreAndSeparate( curNode->child );
}
curNode = curNode->next;
}
}Null or Cycle


Start by looking at the pictures to see if you can determine an intuitive way to differentiate a cyclic list from an acyclic list.
The difference between the two lists appears at their ends. In the cyclic list, there is an end node that points back to one of the earlier nodes. In the acyclic list, there is an end node that is null terminated. Thus, if you can find this end node, you can test whether the list is cyclic or acyclic.
In the acyclic list, it is easy to find the end node. You traverse the list until you reach a null terminated node.
In the cyclic list, though, it is more difficult. If you just traverse the list, you go in a circle and won’t know whether you’re in a cyclic list or just a long acyclic list. You need a more sophisticated approach.
Try looking at the end node a bit more. The end node points to a node that has another node pointing at it. This means that there are two pointers pointing at the same node. This node is the only node with two elements pointing at it. You can design an algorithm around this property. You can traverse the list and check every node to determine whether two other nodes are pointing at it. If you find such a node, the list must be cyclic. Otherwise, the list is acyclic, and you will eventually encounter a null pointer.
Unfortunately, it is difficult to check the number of nodes pointing at each element. See if you can find another special property of the end node in a cyclic list. When you traverse the list, the end node’s next node is a node that you have previously encountered. Instead of checking for a node with two pointers pointing at it, you can check whether you have already encountered a node. If you find a previously encountered node, you have a cyclic list. If you encounter a null pointer, you have an acyclic list. This is only part of the algorithm. You still need to figure out how to determine whether you have previously encountered a node.
The easiest way to do this would be to mark each element as you visit it, but you’ve been told you’re not allowed to modify the list. You could keep track of the nodes you’ve encountered by putting them in a separate list. Then you would compare the current node to all the nodes in the already-encountered list. If the current node ever points to a node in the already-encountered list, you have a cycle. Otherwise, you’ll get to the end of the list and see that it’s null terminated and thus acyclic. This would work, but in the worst case the already-encountered list would require as much memory as the original list. See if you can reduce this memory requirement.
What are you storing in the already-encountered list? The already-encountered list’s first node points to the original list’s first node, its second node points to the original list’s second node, its third node points to the original list’s third node, and so on. You’re creating a list that mirrors the original list. This is unnecessary — you can just use the original list.
Try this approach: Because you know your current node in the list and the start of the list, you can compare your current node’s next pointer to all its previous nodes directly. For the ith node, compare its next pointer to see if it points to any of nodes 1 to i – 1. If any are equal, you have a cycle.
What’s the time order of this algorithm? For the first node, 0 previous nodes are examined; for the second node, one previous node is examined; for the third node, two previous nodes are examined, and so on. Thus, the algorithm examines 0 + 1 + 2 + 3 +...+ n nodes. As discussed in Chapter 3, such an algorithm is O(n2).
That’s about as far as you can go with this approach. Although it’s difficult to discover without some sort of hint, there is a better solution involving two pointers. What can you do with two pointers that you couldn’t do with one? You can advance them on top of each other, but then you might as well have one pointer. You could advance them with a fixed interval between them, but this doesn’t seem to gain anything. What happens if you advance the pointers at different speeds?
In the acyclic list, the faster pointer reaches the end. In the cyclic list, they both loop endlessly. The faster pointer eventually catches up with and passes the slower pointer. If the fast pointer is ever behind or equal to the slower pointer, you have a cyclic list. If it encounters a null pointer, you have an acyclic list. You’ll need to start the fast pointer one node ahead of the slow pointer so they’re not equal to begin with. In outline form, this algorithm looks like this:
Start slow pointer at the head of the list
Start fast pointer at second node
Loop infinitely
If the fast pointer reaches a null pointer
Return that the list is null terminated
If the fast pointer moves onto or over the slow pointer
Return that there is a cycle
Advance the slow pointer one node
Advance the fast pointer two nodesYou can now implement this solution:
/* Takes a pointer to the head of a linked list and determines if
* the list ends in a cycle or is NULL terminated
*/
bool determineTermination( Node *head ){
Node *fast, *slow;
slow = head;
fast = head->next;
while( true ){
if( !fast || !fast->next )
return false;
else if( fast == slow || fast->next == slow )
return true;
else {
slow = slow->next;
fast = fast->next->next;
}
}
}Is this algorithm faster than the earlier solution? If this list is acyclic, the faster pointer comes to the end after examining n nodes, while the slower pointer traverses 1⁄2 n nodes. Thus, you examine 3⁄2n nodes, which is an O(n) algorithm.
What about a cyclic list? The slower pointer never goes around any loop more than once. When the slower pointer has examined n nodes, the faster pointer will have examined 2n nodes and have “passed” the slower pointer, regardless of the loop’s size. Therefore, in the worst case you examine 3n nodes, which is still O(n). Regardless of whether the list is cyclic or acyclic, this two-pointer approach is much better than the single-pointer approach to the problem.
Summary
Although they are simple data structures, problems with linked lists often arise in interviews focusing on C or C++ experience as a way to determine whether a candidate understands basic pointer manipulation. Each element in a singly linked list contains a pointer to the next element in the list, whereas each element in a doubly linked list points to both the previous and the next elements. The first element in both list types is referred to as the head, whereas the last element is referred to as the tail. Circular linked lists have no head or tail; instead, the elements are linked together to form a cycle.
List operations are much simpler to perform on doubly linked lists, so most interview problems use singly linked lists. Typical operations include updating the head of the list, traversing the list to find a specific element from the end of the list, and inserting or removing list elements.