
Recursion Problems
Recursive algorithms offer elegant solutions to problems that would be awkward to code nonrecursively. Interviewers like these kinds of problems because many people find recursive thinking difficult.
Binary Search
In a binary search, you compare the central element in your sorted search space (an array, in this case) with the item you’re looking for. There are three possibilities. If the central element is less than what you’re searching for, you eliminate the first half of the search space. If it’s more than the search value, you eliminate the second half of the search space. In the third case, the central element is equal to the search item, and you stop the search. Otherwise, you repeat the process on the remaining portion of the search space. If it’s not already familiar to you from computer science courses, this algorithm may remind you of the optimum strategy in the children’s number-guessing game in which one child guesses numbers in a given range and a second responds “higher” or “lower” to each incorrect guess.
Because a binary search can be described in terms of binary searches on successively smaller portions of the search space, it lends itself to a recursive implementation. Your method needs to be passed the array it is searching, the limits within which it should search, and the element for which it is searching. You can subtract the lower limit from the upper limit to find the size of the search space, divide this size by two, and add it to the lower limit to find the index of the central element. Next, compare this element to the search element. If they’re equal, return the index. Otherwise, if the search element is smaller, the new upper limit becomes the central index – 1; if the search element is larger, the new lower limit is the central index + 1. Recurse until you match the element you’re searching for.
Before you code, consider what error conditions you need to handle. One way to think about this is to consider what assumptions you’re making about the data you are given and then consider how these assumptions might be violated. One assumption, explicitly stated in the problem, is that only a sorted array can be searched. If the upper limit is ever less than the lower limit, it indicates that the list is unsorted, and you should throw an exception. (Another way to handle this case would be to call a sort routine and then restart the search, but that’s more than you need to do in an interview.)
Another assumption implicit in a search may be a little less obvious: The element you’re searching for is assumed to exist in the array. If you don’t terminate the recursion until you find the element, you’ll recurse infinitely when the element is missing from the array. You can avoid this by throwing an exception if the upper and lower limits are equal and the element at that location is not the element you’re searching for. Finally, you assume that the lower limit is less than or equal to the upper limit. For simplicity, you can just throw an exception in this case; although in a real program, you’d probably want to define this as an illegal call and use an assertion to check it.
Your recursive function will be easier to use if you write a wrapper that sets the initial values for the limits to the full extent of the array. Now you can translate these algorithms and error checks into Java code:
int binarySearch(int[] array, int target) throws BSException {
return binarySearch(array, target, 0, array.length-1);
}
int binarySearch( int[] array, int target, int lower,
int upper ) throws BSException {
int center, range;
range = upper - lower;
if( range < 0 ){
throw new BSException("Limits reversed");
} else if( range == 0 && array[lower] != target ){
throw new BSException("Element not in array");
}
if( array[lower] > array[upper] ){
throw new BSException("Array not sorted");
}
center = ((range)/2) + lower;
if( target == array[center] ){
return center;
} else if( target < array[center] ){
return binarySearch( array, target, lower, center - 1 );
} else {
return binarySearch( array, target, center + 1, upper );
}
}
Although the preceding function completes the given task, it is not as efficient as it could be. As discussed at the beginning of this chapter, recursive implementations are generally less efficient than equivalent iterative implementations.
If you analyze the recursion in the previous solution, you can see that each recursive call serves only to change the search limits. There’s no reason why you can’t change the limits on each iteration of a loop and avoid the overhead of recursion. (When compiled with tail call elimination, the preceding recursive implementation would likely produce machine code indistinguishable from an iterative implementation.) The method that follows is a more efficient, iterative analog of the recursive binary search:
int iterBinarySearch( int[] array, int target) throws BSException {
int lower = 0, upper = array.length – 1;
int center, range;
if( lower > upper ){
throw new BSException("Limits reversed");
}
while( true ){
range = upper - lower;
if( range == 0 && array[lower] != target ){
throw new BSException("Element not in array");
}
if( array[lower] > array[upper] ){
throw new BSException("Array not sorted");
}
center = ((range)/2) + lower;
if( target == array[center] ){
return center;
} else if( target < array[center] ){
upper = center - 1;
} else {
lower = center + 1;
}
}
}
A binary search is O(log(n)) because half of the search space is eliminated (in a sense, searched) on each iteration. This is more efficient than a simple search through all the elements, which would be O(n). However, to perform a binary search, the array must be sorted, an operation that is usually O(n log(n)).
Permutations of a String
Manually permuting a string is a relatively intuitive process, but describing an algorithm for the process can be difficult. In a sense, the problem here is like being asked to describe how you tie your shoes: You know the answer, but you probably still have to go through the process a few times to figure out what steps you’re taking.
Try applying that method to this problem: Manually permute a short string and try to reverse-engineer an algorithm out of the process. Take the string “abcd” as an example. Because you’re trying to construct an algorithm from an intuitive process, you want to go through the permutations in a systematic order. Exactly which systematic order you use isn’t terribly important — different orders are likely to lead to different algorithms, but as long as you’re systematic about the process, you should be able to construct an algorithm. You want to choose a simple order that makes it easy to identify any permutations that you might accidentally skip.
You might consider listing all the permutations in alphabetical order. This means the first group of permutations will all start with “a”. Within this group, you first have the permutations with a second letter of “b”, then “c”, and finally “d”. Continue in a like fashion for the other first letters.
Before you continue, make sure you didn’t miss any permutations. Four possible letters can be placed in the first position. For each of these four possibilities, there are three remaining possible letters for the second position. Thus, there are 4 × 3 = 12 different possibilities for the first two letters of the permutations. After you select the first two letters, two different letters remain available for the third position, and the last remaining letter is put in the fourth position. If you multiply 4 × 3 × 2 × 1 you have a total of 24 different permutations; there are 24 permutations in the previous list, so nothing has been missed. This calculation can be expressed more succinctly as 4! — you may recall that n! is the number of possible arrangements of n objects.
Now examine the list of permutations for patterns. The rightmost letters vary faster than the leftmost letters. For each letter that you choose for the first (leftmost) position, you write out all the permutations beginning with that letter before you change the first letter. Likewise, after you pick a letter for the second position, you write out all permutations beginning with this two-letter sequence before changing the letters in either the first or second position. In other words, you can define the permutation process as picking a letter for a given position and performing the permutation process starting at the next position to the right before coming back to change the letter you just picked. This sounds like the basis for a recursive definition of permutation. Try to rephrase it in explicitly recursive terms: To find all permutations starting at position n, successively place all allowable letters in position n, and for each new letter in position n find all permutations starting at position n + 1 (the recursive case). When n is greater than the number of characters in the input string, a permutation has been completed; print it and return to changing letters at positions less than n (the base case).
You almost have an algorithm; you just need to define “all allowable letters” a little more rigorously. Because each letter from the input string can appear only once in each permutation, “all allowable letters” can’t be defined as every letter in the input string. Think about how you did the permutations manually. For the group of permutations beginning with “b”, you never put a “b” anywhere but the first position because when you selected letters for later positions, “b” had already been used. For the group beginning “bc” you used only “a” and “d” in the third and fourth positions because both “b” and “c” had already been used. Therefore, “all allowable letters” means all letters in the input string that haven’t already been chosen for a position to the left of the current position (a position less than n). Algorithmically, you could check each candidate letter for position n against all the letters in positions less than n to determine whether it had been used. You can eliminate these inefficient scans by maintaining an array of boolean values corresponding to the positions of the letters in the input string and using this array to mark letters as used or unused, as appropriate.
In outline form, this algorithm looks like the following:
If you’re past the last position
Print the string
Return
Otherwise
For each letter in the input string
If it’s marked as used, skip to the next letter
Else place the letter in the current position
Mark the letter as used
Permute remaining letters starting at current position + 1
Mark the letter as unusedSeparating the base case from the recursive case as performed here is considered good style and may make the code easier to understand, but it does not provide optimum performance. You can significantly optimize the code by invoking the base case directly without a recursive call if the next recursive call invokes the base case. In this algorithm, that involves checking whether the letter just placed was the last letter — if so, you print the permutation and make no recursive call; otherwise, a recursive call is made. This eliminates n! function calls, reducing the function call overhead by approximately a factor of n (where n is the length of the input string). Short-circuiting the base case in this manner is called arms-length recursion and is considered poor style, especially in academic circles. Whichever way you choose to code the solution, it is worthwhile to mention the advantages of the alternative approach to your interviewer.
Here’s a Java implementation of this algorithm:
public class Permutations {
private boolean[] used;
private StringBuilder out = new StringBuilder();
private final String in;
public Permutations( final String str ){
in = str;
used = new boolean[ in.length() ];
}
public void permute( ){
if( out.length() == in.length() ){
System.out.println( out );
return;
}
for( int i = 0; i < in.length(); ++i ){
if( used[i] ) continue;
out.append( in.charAt(i) );
used[i] = true;
permute();
used[i] = false;
out.setLength( out.length() - 1 );
}
}
}This class sets up the array of used flags and the StringBuilder for the output string in the constructor. The recursive function is implemented in permute(), which appends the next available character to out before making the recursive call to permute the remaining characters. After the call returns, the appended character is deleted by decreasing out’s length.
Combinations of a String
This is a companion problem to finding the permutations of the characters in a string. If you haven’t yet worked through that problem, you may want to do so before you tackle this one.
Following the model of the solution to the permutation problem, try working out an example by hand to see where that gets you. Because you are trying to divine an algorithm from the example, you again need to be systematic in your approach. You might try listing combinations in order of length. The input string “wxyz” is used in the example. Because the ordering of letters within each combination is arbitrary, they are kept in the same order as they are in the input string to minimize confusion.

Some interesting patterns seem to be emerging, but there’s nothing clear yet, certainly nothing that seems to suggest an algorithm. Listing output in terms of the order of the input string (alphabetical order, for this input string) turned out to be helpful in the permutation problem. Try rearranging the combinations you generated to see if that’s useful here:
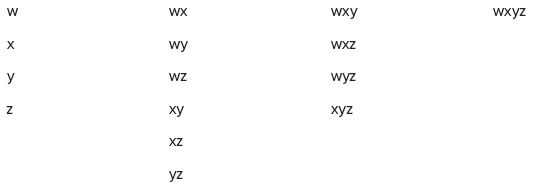
This looks a little more productive. There is a column for each letter in the input string. The first combination in each column is a single letter from the input string. The remainder of each column’s combinations consists of that letter prepended to each of the combinations in the columns to the right. Take, for example, the “x” column. This column has the single letter combination “x”. The columns to the right of it have the combinations “y”, “yz”, and “z”, so if you prepend “x” to each of these combinations you find the remaining combinations in the “x” column: “xy”, “xyz”, and “xz”. You could use this rule to generate all the combinations, starting with just “z” in the rightmost column and working your way to the left, each time writing a single letter from the input string at the top of the column and then completing the column with that letter prepended to each of the combinations in columns to the right. This is a recursive method for generating the combinations. It is space inefficient because it requires storage of all previously generated combinations, but it indicates that this problem can be solved recursively. See if you can gain some insight on a more efficient recursive algorithm by examining the combinations you’ve written a little more closely.
Look at which letters appear in which positions. All four letters appear in the first position, but “w” never appears in the second position. Only “y” and “z” appear in the third position, and “z” is in the fourth position in the only combination that has a fourth position (“wxyz”). Therefore, a potential algorithm might involve iterating through all allowable letters at each position: w–z in the first position, x–z in the second position, and so on. Check this idea against the example to see if it works: It seems to successfully generate all the combinations in the first column. However, when you select “x” for the first position, this candidate algorithm would start with “x” in the second position, generating an illegal combination of “xx”. Apparently the algorithm needs some refinement.
To generate the correct combination “xy”, you need to begin with “y”, not “x”, in the second position. When you select “y” for the first position (third column), you need to start with “z” because “yy” is illegal and “yx” and “yw” have already been generated as “xy” and “wy”. This suggests that in each output position you need to begin iterating with the letter in the input string following the letter selected for the preceding position in the output string. Call this letter your input start letter.
It may be helpful to summarize this a little more formally. Begin with an empty output string and the first character of the input as the input start position. For a given position, sequentially select all letters from the input start position to the last letter in the input string. For each letter you select, append it to the output string, print the combination, and then generate all other combinations beginning with this sequence by recursively calling the generating function with the input start position set to the next letter after the one you’ve just selected. After you return from the recursive call, delete the character you appended to make room for the next character you select. You should check this idea against the example to make sure it works. It does — no more problems in the second column. Before you code, it may be helpful to outline the algorithm just to make sure you have it. (For comparison, we’ve chosen the performance side of the arms-length recursion style/performance trade-off discussed in the permutation problem. The performance and style differences between the two possible approaches are not as dramatic for the combination algorithm as they were for the permutation algorithm.)
For each letter from input start position to end of input string
Append the letter to the output string
Print letters in output string
If the current letter isn’t the last in the input string
Generate remaining combinations starting at next position with
iteration starting at next letter beyond the letter just selected
Delete the last character of the output stringAfter all that hard work, the algorithm looks simple! You’re ready to code it. In Java, your implementation might look like this:
public class Combinations {
private StringBuilder out = new StringBuilder();
private final String in;
public Combinations( final String str ){ in = str; }
public void combine() { combine( 0 ); }
private void combine(int start ){
for( int i = start; i < in.length(); ++i ){
out.append( in.charAt(i) );
System.out.println( out );
if ( i < in.length() )
combine( i + 1);
out.setLength( out.length() - 1 );
}
}
}This solution is sufficient in most interviews. Nevertheless, you can make a rather minor optimization to combine that eliminates the if statement. Given that this is a recursive function, the performance increase is probably negligible compared to the function call overhead, but you might want to see if you can figure it out just for practice:
private void combine(int start ){
for( int i = start; i < in.length() - 1; ++i ){
out.append( in.charAt(i) );
System.out.println( out );
combine( i + 1);
out.setLength( out.length() - 1 );
}
out.append( in.charAt( in.length() - 1 ) );
System.out.println( out );
out.setLength( out.length() - 1 );
}The if statement is eliminated by removing the final iteration from the loop and moving the code it would have executed during that iteration outside the loop. The general case of this optimization is referred to as loop partitioning, and if statements that can be removed by loop partitioning are called loop index dependentconditionals. Again, this optimization doesn’t make much difference here, but it can be important inside nested loops.
Telephone Words

char getCharKey( int telephoneKey, int place )
It’s worthwhile to define some terms for this problem. A telephone number consists of digits. Three letters correspond to each digit. (Except for 0 and 1, but when 0 and 1 are used in the context of creating a word, you can call them letters.) The lowest letter, middle letter, and highest letter will be called the digit’s low value, middle value, and high value, respectively. You will be creating words, or strings of letters, to represent the given number.
First, impress the interviewer with your math skills by determining how many words can correspond to a seven-digit number. This requires combinatorial mathematics, but if you don’t remember this type of math, don’t panic. First, try a one-digit phone number. Clearly, this would have three words. Now, try a two-digit phone number — say, 56. There are three possibilities for the first letter, and for each of these there are three possibilities for the second letter. This yields a total of nine words that can correspond to this number. It appears that each additional digit increases the number of words by a factor of 3. Thus, for 7 digits, you have 37 words, and for a phone number of length n, you have 3n words. Because 0 and 1 have no corresponding letters, a phone number with 0s or 1s in it would have fewer words, but 37 is the upper bound on the number of words for a seven-digit number.
Now you need to figure out an algorithm for printing these words. Try writing out some words representing one of the author’s old college phone numbers, 497-1927, as an example. The most natural manner in which to list the words is alphabetical order. This way, you always know which word comes next, and you are less likely to miss words. You know that there are on the order of 37words that can represent this number, so you won’t have time to write them all out. Try writing just the beginning and the end of the alphabetical sequence. You will probably want to start with the word that uses the low letter for each digit of the phone number. This guarantees that your first word is the first word in alphabetical order. Thus, the first word for 497-1927 starts with G for 4 because 4 has “GHI” on it, W for 9, which has “WXY” on it, P for 7, which has “PRS” on it, and so on, resulting in “GWP1WAP”.
As you continue to write down words, you ultimately create a list that looks like the following:
| GWP1WAP |
| GWP1WAR |
| GWP1WAS |
| GWP1WBP |
| GWP1WBR |
| ... |
| IYS1YCR |
| IYS1YCS |
It was easy to create this list because the algorithm for generating the words is relatively intuitive. Formalizing this algorithm is more challenging. A good place to start is by examining the process of going from one word to the next word in alphabetical order.
Because you know the first word in alphabetical order, determining how to get to the next word at any point gives you an algorithm for writing all the words. One important part of the process of going from one word to the next seems to be that the last letter always changes. It continually cycles through a pattern of P-R-S. Whenever the last letter goes from S back to P, it causes the next-to-last letter to change. Try investigating this a little more to see if you can come up with specific rules. Again, it’s probably best to try an example. You may have to write down more words than in the example list to see a pattern. (A three-digit phone number should be sufficient, or the previous list will work if it’s expanded a bit.) It looks as if the following is always true: Whenever a letter changes, its right neighbor goes through all of its values before the original letter changes again. Conversely, whenever a letter resets to its low value, its left neighbor increases to the next value.
From these observations, there are probably two reasonable paths to follow as you search for the solution to this problem. You can start with the first letter and have a letter affect its right neighbor, or you can start with the last letter and have a letter affect its left neighbor. Both of these approaches seem reasonable. For now, try the former and see where that gets you.
You should examine exactly what you’re trying to do at this point. You’re working with the observation that whenever a letter changes, it causes its right neighbor to cycle through all its values before it changes again. You’re using this observation to determine how to get from one word to the next word in alphabetical order. It may help to formalize this observation: Changing the letter in position i causes the letter in position i + 1 to cycle through its values. When you can write an algorithm in terms of how elements i and i + 1 interact with each other, it often indicates recursion, so try to figure out a recursive algorithm.
You have already discovered most of the algorithm. You know how each letter affects the next; you just need to figure out how to start the process and determine the base case. Looking again at the list to try to figure out the start condition, you’ll see that the first letter cycles only once. Therefore, if you start by cycling the first letter, this causes multiple cycles of the second letter, which causes multiple cycles of the third letter — exactly as desired. After you change the last letter, you can’t cycle anything else, so this is a good base case to end the recursion. When the base case occurs, you should also print out the word because you’ve just generated the next word in alphabetical order. The one special case you have to be aware of occurs when there is a 0 or 1 in the given telephone number. You don’t want to print out any word three times, so you should check for this case and cycle immediately if you encounter it.
In list form, the steps look like this:
If the current digit is past the last digit
Print the word because you’re at the end
Else
For each of the three digits that can represent the current digit
Have the letter represent the current digit
Move to next digit and recurse
If the current digit is a 0 or a 1, returnA Java implementation is:
public class TelephoneNumber {
private static final int PHONE_NUMBER_LENGTH = 7;
private final int [] phoneNum;
private char[] result = new char[ PHONE_NUMBER_LENGTH ];
public TelephoneNumber ( int[] n ) { phoneNum = n; }
public void printWords(){ printWords( 0 ); }
private void printWords(int curDigit ) {
if( curDigit == PHONE_NUMBER_LENGTH ) {
System.out.println( new String( result ) );
return;
}
for( int i = 1; i <= 3; ++i ) {
result[ curDigit ] = getCharKey( phoneNum[curDigit], i );
printWords( curDigit + 1 );
if( phoneNum[curDigit] == 0 ||
phoneNum[curDigit] == 1) return;
}
}
}What is the running time of this algorithm? Ignoring the operations involved in printing the string, the focus of the function is changing letters. Changing a single letter is a constant time operation. The first letter changes 3 times, the second letter changes 3 times each time the first letter changes for a total of 9 times, and so on for the other digits. For a telephone number of length n, the total number of operations is 3 + 32 + 33 + ... + 3n–1 + 3n. Retaining only the highest order term, the running time is O(3n).
The recursive algorithm doesn’t seem to be helpful in this situation. Recursion was inherent in the way that you wrote out the steps of the algorithm. You could always try emulating recursion using a stack-based data structure, but there may be a better way involving a different algorithm. In the recursive solution, you solved the problem from left to right. You also made an observation that suggested the existence of another algorithm going from right to left: Whenever a letter changes from its high value to its low value, its left neighbor is incremented. Explore this observation to see if you can find a nonrecursive solution to the problem.
Again, you’re trying to figure out how to determine the next word in alphabetical order. Because you’re working from right to left, you should look for something that always happens on the right side of a word as it changes to the next word in alphabetical order. Looking back at the original observations, you noticed that the last letter always changes. This seems to indicate that a good way to start is to increment the last letter. If the last letter is at its high value and you increment it, you reset the last letter to its low value and increment the second-to-last letter. Suppose, however, that the second-to-last number is already at its high value. Try looking at the list to figure out what you need to do. From the list, it appears that you reset the second-to-last number to its low value and increment the third-to-last number. You continue carrying your increment like this until you don’t have to reset a letter to its low value.
This sounds like the algorithm you want, but you still have to work out how to start it and how to know when you’re finished. You can start by manually creating the first string as you did when writing out the list. Now you need to determine how to end. Look at the last string and figure out what happens if you try to increment it. Every letter resets to its low value. You could check whether every letter is at its low value, but this seems inefficient. The first letter resets only once, when you’ve printed out all the words. You can use this to signal that you’re done printing out all the words. Again, you have to consider the cases where there is a 0 or a 1. Because 0 and 1 effectively can’t be incremented (they always stay as 0 and 1), you should always treat a 0 or a 1 as if it were at its highest letter value and increment its left neighbor. In outline form, the steps are as follows:
Create the first word character by character
Loop infinitely:
Print out the word
Increment the last letter and carry the change
If the first letter has reset, you’re doneHere is a Java implementation of this iterative algorithm:
public class TelephoneNumber {
private static final int PHONE_NUMBER_LENGTH = 7;
private final int [] phoneNum;
private char[] result = new char[ PHONE_NUMBER_LENGTH ];
public TelephoneNumber ( int[] n ) { phoneNum = n; }
public void printWords() {
// Initialize result with first telephone word
for( int i = 0; i < PHONE_NUMBER_LENGTH; ++i )
result[i] = getCharKey( phoneNum[i], 1 );
for( ; ; ) { // Infinite loop
for( int i = 0; i < PHONE_NUMBER_LENGTH; ++i ) {
System.out.print( result[i] );
}
System.out.print( '
' );
/* Start at the end and try to increment from right
* to left.
*/
for( int i = PHONE_NUMBER_LENGTH - 1; i >= -1; --i ) {
if( i == -1 ) // if attempted to carry past leftmost digit,
return; // we're done, so return
/* Start with high value, carry case so 0 and 1
* special cases are dealt with right away
*/
if( getCharKey( phoneNum[i], 3 ) == result[i] ||
phoneNum[i] == 0 || phoneNum[i] == 1 ){
result[i] = getCharKey( phoneNum[i], 1 );
// No break, so loop continues to next digit
} else if ( getCharKey( phoneNum[i], 1 ) == result[i] ) {
result[i] = getCharKey( phoneNum[i], 2 );
break;
} else if ( getCharKey( phoneNum[i], 2 ) == result[i] ) {
result[i] = getCharKey( phoneNum[i], 3 );
break;
}
}
}
}
}You can cut down on the calls to getCharKey by caching each letter’s three values in variables, rather than making repeated calls to see whether a value is low, middle, or high. This would make the code a little more complicated and may not make any difference after the code is optimized by the JIT compiler.
What’s the running time on this algorithm?
Again, changing a single letter is a constant time operation. The total number of letter changes is the same for this algorithm as for the previous, so the running time remains O(3n+1).
Summary
Recursion occurs whenever a function calls itself, directly or indirectly. One or more base cases are needed to end the recursion; otherwise, the algorithm recurses until it overflows the stack.
Algorithms that are intrinsically recursive should be implemented recursively. Some apparently recursive algorithms can also be implemented iteratively; these iterative implementations are generally more efficient than their recursive counterparts.