
3.2 Scanning
For purposes of scanning, the valid lexical units of a program are called lexemes (e.g., 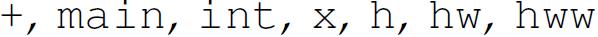 ). The first step of scanning (also referred to as lexical analysis) is to parcel the characters (from the alphabet Σ) of the string representing the line of code into lexemes. Lexemes can be formally described by regular expressions and regular grammars. Lexical analysis is the process of determining if a string (typically of a programming language) is lexically valid— that is, if all of the lexical units of the string are lexemes.
). The first step of scanning (also referred to as lexical analysis) is to parcel the characters (from the alphabet Σ) of the string representing the line of code into lexemes. Lexemes can be formally described by regular expressions and regular grammars. Lexical analysis is the process of determining if a string (typically of a programming language) is lexically valid— that is, if all of the lexical units of the string are lexemes.
Programming languages must specify how the lexical units of a program are delimited. There are a variety of methods that languages use to determine where lexical units begin and end. Most programming languages delimit lexical units using whitespace (i.e., spaces and tabs) and other characters. In C, lexical units are delimited by whitespace and other characters, including arithmetic operators. As an example, consider parceling the characters from the line 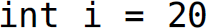 ; of C code into lexemes (Table 3.1). The lexemes are
; of C code into lexemes (Table 3.1). The lexemes are 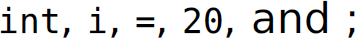 . The lines of code
. The lines of code 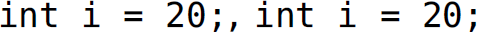 , and
, and 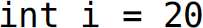 ; have this same set of lexemes.
; have this same set of lexemes.
Table 3.1 Parceling Lexemes into Tokens in the Sentence int i = 20;
Lexeme | Token |
|---|---|
|
int |
reserved word |
|
i |
identifier |
|
= |
special symbol |
|
20 |
constant |
|
; |
special symbol |
Free-format languages are languages where formatting has no effect on program structure—of course, other than use of some delimiter to determine where lexical units begin and end. Most languages, including C, C++, and Java, are free-format languages. However, some languages impose restrictions on formatting. Languages where formatting has an effect on program structure, and where lexemes must occur in predetermined areas, are called fixed-format languages. Early versions of Fortran were fixed-format. Other languages, including Python, Haskell, Miranda, and occam, use layout-based syntactic grouping (i.e., indentation).
Once we have a list of lexical units, we must determine whether each is a lexeme (i.e., lexically valid). This can be done by checking them against the lexemes of the language (i.e., a lexicon), or by running each through a finite-state automaton that can recognize the lexemes of the language. Most programming languages have reserved words that cannot be used as an identifier (e.g., int in C). Reserved words are not the same as keywords, which are only special in certain contexts (e.g., main in C).
As each lexical unit is determined to be valid, each is abstracted into a token because the individual lexemes are superfluous for the next phase—syntactic analysis. Lexemes are partitioned into tokens, which are categories of lexemes. Table 3.1 shows how the five lexemes in the string int i = 20; fall into four token categories. The next phase in verifying the validity of a program is determining whether the tokens are structured properly. The actual lexemes are not important in verifying the structure of a candidate sentence. The details of a lexeme (e.g., i) are abstracted in its token (e.g., <identifier>). For the program to be a sentence, the order of the tokens must conform to a context-free grammar. Here we are referring to the grammar of entire expressions rather than the (regular) grammar of individual lexemes. If a program is lexically valid, lexical analysis returns a list of tokens.
A scanner1 (or lexical analyzer) is a software system that culls the lexical units from a program, validates them as lexemes, and returns a list of tokens. Parsing validates the order of the tokens in this list and, if it is valid, organizes this list of tokens into a parse tree. The system that validates a program string and, if valid, converts it into a parse tree is called a front end (and it constitutes both a scanner and parser; Figure 3.1). Notice how the two components of a front end in Figures 3.1 and 3.2 correspond to progressive types of sentence validity in Table 2.1.

Figure 3.1 Simplified view of scanning and parsing: the front end.
Description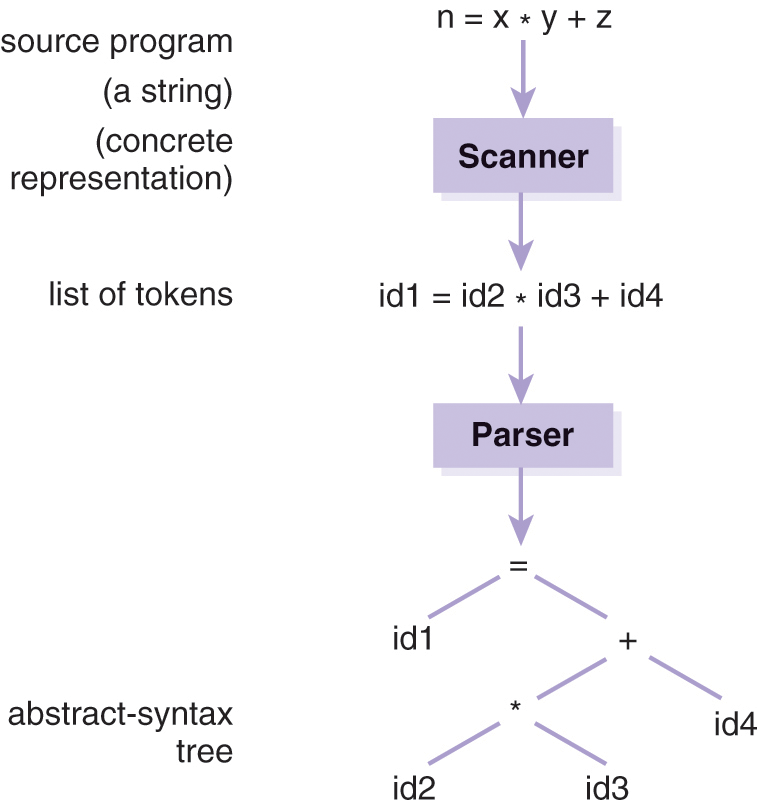
Figure 3.2 More detailed view of scanning and parsing.
DescriptionThe finite-state automaton (FSA), shown in Figure 3.3, recognizes both positive integers and legal identifiers in C. Table 3.2 illustrates how one might represent the transitions of that FSA as a two-dimensional array. The indices 1, 2, and 3 denote the current state of the machine, and the integer value in each cell denotes which state to transition to when a particular input character is encountered. For instance, if the machine is in state 1 and an integer in the range 1...9 is encountered, the machine transitions to state 3.
Table 3.2 Two-Dimensional Array Modeling a Finite-State Automaton for a Legal Identifier and Positive Integer in C.
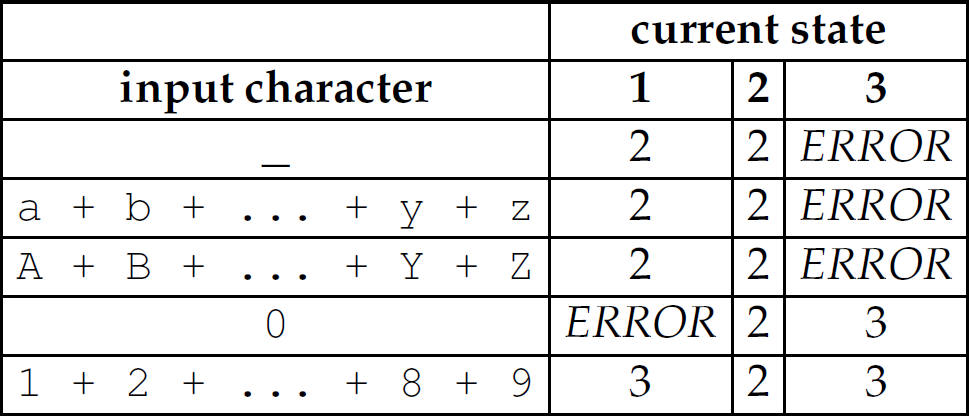
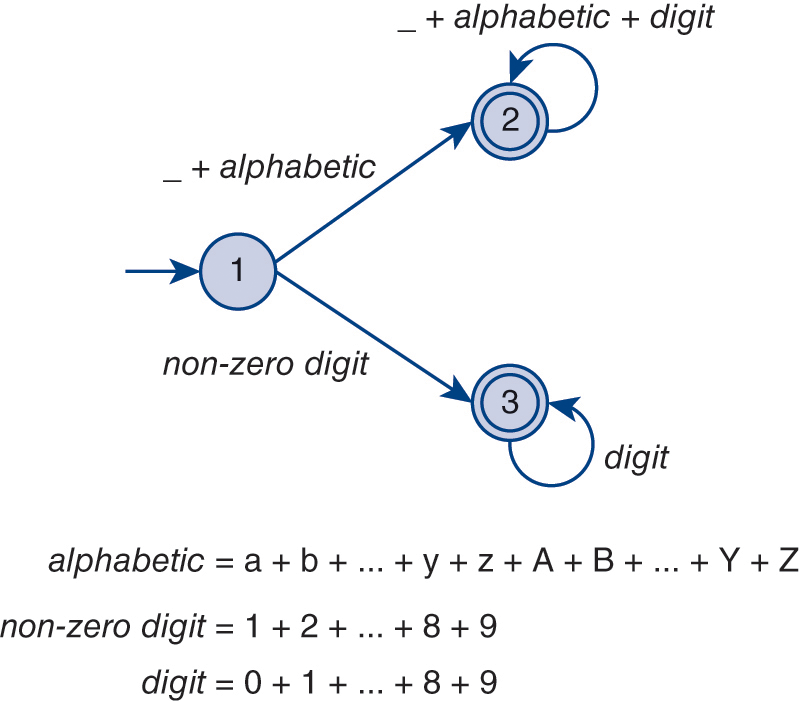
Figure 3.3 A finite-state automaton for a legal identifier and positive integer in C.
DescriptionBecause the theory behind scanners (i.e., finite-state automata, regular languages, and regular grammars) is well established, building a scanner is a mechanical process that can be automated by a computer program; thus, it is rarely done by hand. The scanner generator lex is a UNIX tool that accepts a set of regular expressions (in a .l file) as input and automatically generates a lexical analyzer in C that can recognize lexemes in the language denoted by those regular expressions; each call to the function lex() retrieves the next token. In other words, given a set of regular expressions, lex generates a scanner in C.
1. A scanner is also sometimes referred to as a lexer.