
3.7 Top-down Vis-à-Vis Bottom-up Parsing
A hierarchy of parsers can be developed based on properties of grammars used in them (Table 3.5). Top-down and bottom-up parsers are classified as LL and LR parsers, respectively. The first L indicates that both read the input string from Left-to-right. The second character indicates the type of derivation the parser constructs: Top-down parsers construct a Leftmost derivation, while bottom-up parsers construct a Rightmost derivation. Use of a parsing table in table-driven parsers, which can be top-down or bottom-up, often requires looking one token ahead in the input string without consuming it. These types of parsers are classified by prepending LA (for Look Ahead) before the first two characters and appending (n), where the integer n indicates the length of the look ahead required. For instance, the LR (or bottom-up) shift-reduce parsers generated by yacc are LALR(1) parsers (i.e., Look-Ahead, Left-to-right, Rightmost derivation parsers). These types of parsers also require the grammar used to be in a particular form. Both LL and LR parsers require an unambiguous grammar. Furthermore, an LL parser requires a right-recursive grammar earlier. Thus, there is a corresponding hierarchy of grammars (Table 3.6).
Table 3.5 Top-down Vis-à-Vis Bottom-up Parsers (Key: ‡ = requisite; † =preferred.)

Table 3.6 LL Vis-à-Vis LR Grammars (Note: LL ⊂ LR.)

Conceptual Exercises for Chapter 3
Exercise 3.1 Explain why a right-recursive grammar is required for a recursive-descent parser.
Exercise 3.2 Why might it be preferable to use a left-recursive grammar with a bottom-up parser?
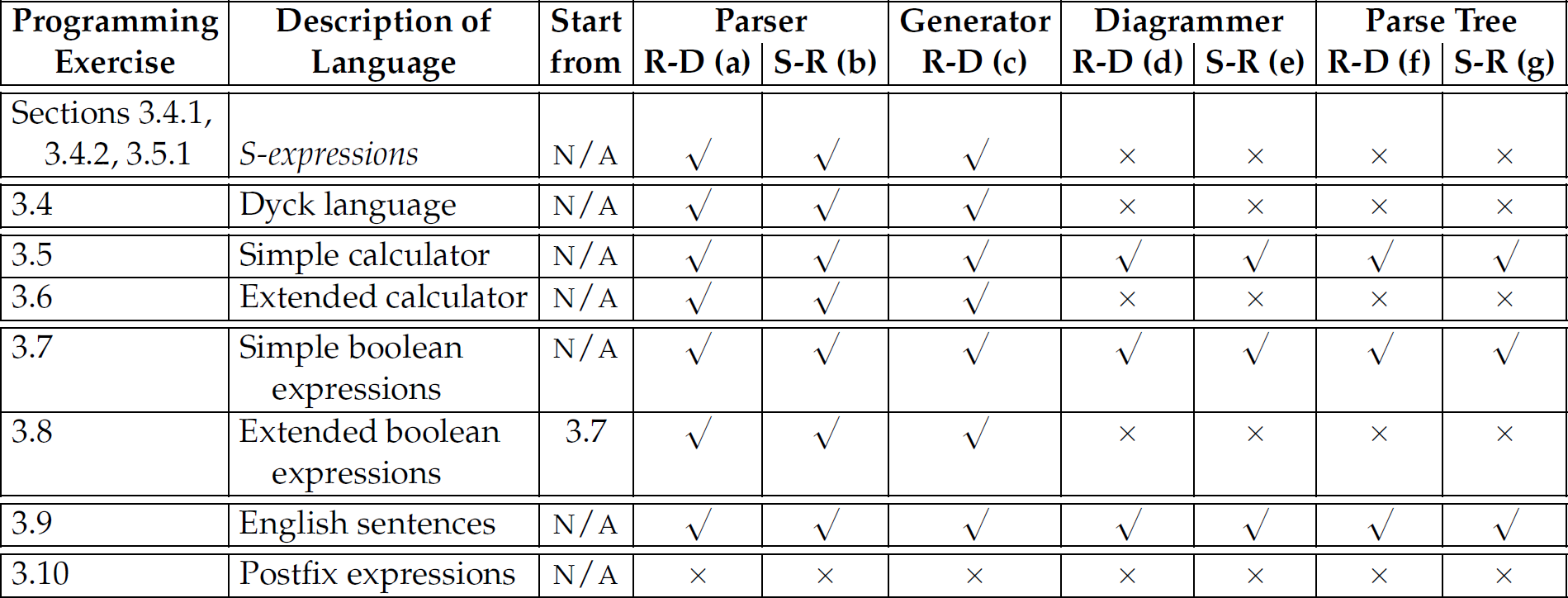
Programming Exercises for Chapter 3
Table 3.7 presents a mapping from the exercises here to some of the essential features of parsers discussed in this chapter.
Table 3.7 Parsing Programming Exercises in This Chapter, Including Their Essential Properties and Dependencies (Key: R-D = recursive-descent; S-R = shift-reduce.)
Exercise 3.3 Implement a scanner, in any language, to print all lexemes in a C program.
Exercise 3.4 Consider the following grammar in EBNF:

where <P> is a non-terminal and ( and ) are terminals.
(a) Implement a recursive-descent parser in any language that accepts strings from standard input (one per line) until EOF and determines whether each string is in the language defined by this grammar. Thus, it is helpful to think of this language using <input> as the start symbol and the rule:
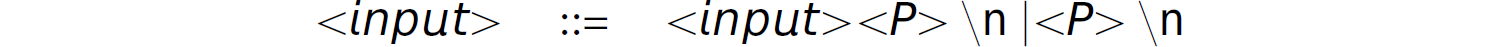
where is a terminal.
Factor your program into a scanner and recursive-descent parser, as shown in Figure 3.1.
You may not assume that each lexical unit will be valid and separated by exactly one space, or that each line will contain no leading or trailing whitespace. There are two distinct error conditions that your program must recognize. First, if a given string does not consist of lexemes, respond with this message: “...” contains lexical units which are not lexemes and, thus, is not an expression., where ... is replaced with the input string, as shown in the interactive session following. Second, if a given string consists of lexemes but is not an expression according to the grammar, respond with this message: "..." is not an expression., where ... is replaced with the input string, as shown in the interactive session following. Note that the “invalid lexemes” message takes priority over the “not an expression” message; that is, the “not an expression” message can be issued only if the input string consists entirely of valid lexemes.
You may assume that whitespace is ignored; that no line of input will exceed 4096 characters; that each line of input will end with a newline; and that no string will contain more than 200 lexical units.
Print only one line of output to standard output per line of input, and do not prompt for input. The following is a sample interactive session with the parser (> is simply the prompt for input and will be the empty string in your system):

(b) Automatically generate a shift-reduce, bottom-up parser by defining a specification of a parser for the language defined by this grammar in either lex/yacc or PLY.
(c) Implement a generator of sentences from the language defined by the grammar in this exercise as an efficient approach to test-case generation. In other words, write a program to output sentences from this language. A simple way to build your generator is to follow the theme of recursive-descent parser construction. In other words, develop one procedure per non-terminal, where each such procedure is responsible for generating sentences from the sub-language rooted at that non-terminal. You can develop this generator from your recursive-descent parser by inverting each procedure to perform generation rather than recognition.
Your generator must produce sentences from the language in a random fashion. Therefore, when several alternatives exist on the right-hand side of a production rule, determine which non-terminal to follow randomly. Also, generate sentences with a random number of lexemes. To do so, each time you generate a sentence, generate a random number between the minimum number of lexemes necessary in a sentence and a maximum number that keeps the generated string within the character limit of the input strings to the parser from the problem. Use this random number to serve as the maximum number of lexemes in the generated sentence. Every time you encounter an optional nonterminal (i.e., one enclosed in brackets), flip a coin to determine whether you should pursue that path through the grammar. Then pursue the path only if the flip indicates you should and if the number of lexemes generated so far is less than the random maximum number of lexemes you generated. Your generator must read a positive integer given at the command line and write that many sentences from the language to standard output, one per line.
Testing any program on various representative data sets is an important aspect of software development, and this exercise will help you test your parsers for this language.
Exercise 3.5 Consider the following grammar in EBNF:
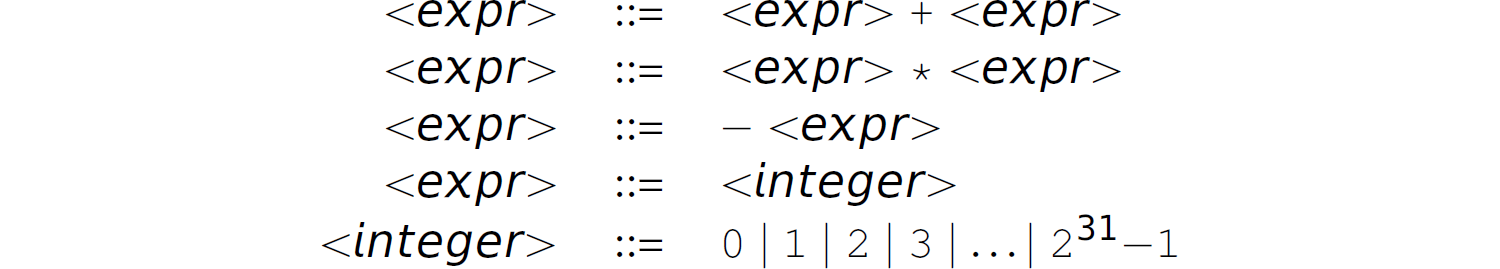
where <eχpr> and <integer> are non-terminals and +, *, –, and 0, 1, 2, 3, ..., 231–1 are terminals.
Complete Programming Exercise 3.4 (parts a, b, and c) using this grammar, subject to all of the requirements given in that exercise.
The following is a sample interactive session with the parser:
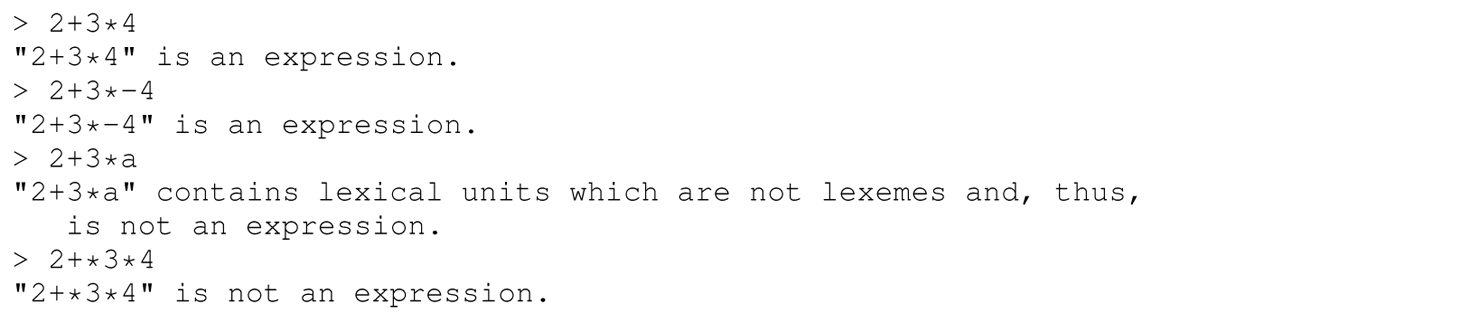
(d) At some point in your education, you may have encountered the concept of diagramming sentences. A diagram of a sentence (or expression) is a parse-tree-like drawing representing the grammatical (or syntactic) structure of the sentence, including parts of speech such as subject, verb, and object.
Complete Programming Exercise 3.4.a, but this time build a recursive-descent parser that writes a diagrammed version of the input string. Specifically, the output must be the input with parentheses around each non-terminal in the input string.
Do not build a parse tree to solve this problem. Instead, implement your recursive-descent parser to construct the diagrammed sentence as demonstrated in the following Python and C procedures, respectively, that each parse and diagram a sub-sentence rooted at the non-terminal <s-list> from the grammar in Section 3.4.1:


Print only one line of output to standard output per line of input as follows. Consider the following sample interactive session with the parser diagrammar (> is the prompt for input and is the empty string in your system):

(e) Complete Programming Exercise 3.5.d using lex/yacc or PLY.
Hint: If using lex/yacc, use an array implementation of a stack that contains elements of type char*. Also, use the sprintf function to convert an integer to a string. For example:


(f) Complete Programming Exercise 3.5.d, but this time build a parse tree in memory and traverse it to output the diagrammed sentence.
(g) Complete Programming Exercise 3.5.f using lex/yacc or PLY.
Exercise 3.6 Consider the following grammar:

Complete Programming Exercise 3.4 (parts a, b, and c) using this grammar, subject to all of the requirements given in that exercise.
The following is a sample interactive session with the parser:


Exercise 3.7 Consider the following grammar in BNF (not EBNF):
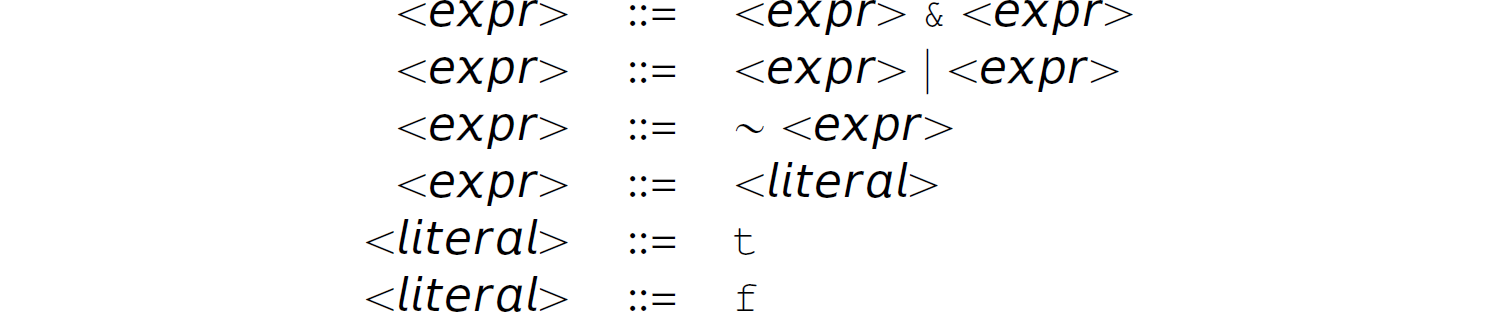
where t, f, |, &, and ∼ are terminals.
Complete Programming Exercise 3.5 (parts a–g) using this grammar, subject to all of the requirements given in that exercise.
The following is a sample interactive session with the undiagramming parser:

The following is a sample interactive session with the diagramming parser:

Exercise 3.8 Consider the following grammar in BNF (not EBNF):

where t, f, |, &, [,], ∼, and a ... e, g ... s, and u ... z are terminals.
Complete Programming Exercise 3.4 (parts a, b, and c) using this grammar, subject to all of the requirements given in that exercise.
The following is a sample interactive session with the undiagramming parser:

Exercise 3.9 Consider the following grammar in EBNF for some simple English sentences:

For simplicity, we ignore articles, punctuation, and capitalization, including the first word of the sentence, otherwise known as context.
Complete Programming Exercise 3.5 (parts a–g) using this grammar, subject to all of the requirements given in that exercise.
The following are a Java method and a Python function that each parse and diagram a sub-sentence rooted at the non-terminal <adj>:

The following is a sample interactive session with the undiagramming parser:

The following is a sample interactive session with the diagramming parser:

Exercise 3.10 Consider the following grammar for arithmetic expressions in postfix form:

Build a postfix expression evaluator using any programming language. Specifically, build a parser for the language defined by this grammar using a stack. When you encounter a number, push it on the stack. When you encounter an operator, pop the top two elements off the stack, compute the result of the operator applied to those two operands, and push the result on the stack. When the input string is exhausted, if there is only one number element on the stack, the string was a sentence in the language and the number on the stack is the result of evaluating the entire postfix expression.
Exercise 3.11 Build a graphical user interface, akin to that shown here, for the postfix expression evaluator developed in Programming Exercise 3.10.
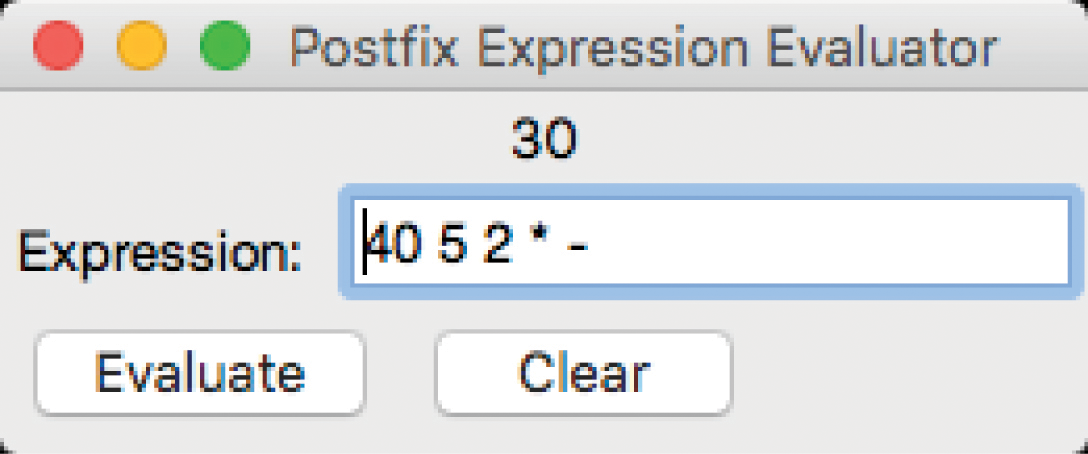
Any programming language is permissible [e.g., HTML 5 and JavaScript to build a web interface to your evaluator; Java to build a stand-alone application; Qt (https://doc.qt.io/qt-4.8/gettingstartedqt.html, https://zetcode.com/gui/qt5/), Python (https://wiki.python.org/moin/GuiProgramming), Racket Scheme (https://docs.racket-lang.org/gui/), or Squeak Smalltalk (https://squeak.org/)]. You could even build an Android or iOS app. All of these languages have a built-in or library stack data structure that you may use.
Exercise 3.12 Augment the PLY parser specification for Camille given in Section 3.6.2 with a read-eval-print loop (REPL) that accepts strings until EOF and indicates whether the string is a Camille sentence. Do not modify the code presented in lines 78–166 in the parser specification. Only add a function or functions at the end of the specification to implement the REPL.
Examples:
