
4.3 Run-Time Systems: Methods of Executions
Ultimately, the series of translations must end and a representation of the original source program must be interpreted [see the bottom of Figure 4.2 labeled “Interpreter” (e.g., processor).] Therefore, interpretation must, at some point, follow compilation. Interpretation can be performed by the most primitive of interpreters—a hardware interpreter called a processor—or by a software interpreter—which itself is just another computer program being interpreted.
Interpretation by the processor is the more common and traditional approach to execution after compilation (for purposes of speed of execution; see approach ① in Figure 4.6). It involves translating the source program all the way down, through the use of an assembler, to object code (e.g., x86). This more traditional style is depicted in the language-neutral diagram in Figure 4.4. For instance, gcc (i.e., the GNU C compiler) translates a C program into object code (e.g., program.o). For purposes of brevity, we omit the optional, but common, code optimization step and the necessary linking step from Figures 4.2 and 4.4. Often the code optimization phase of compilation is part of the back end of a language implementation.
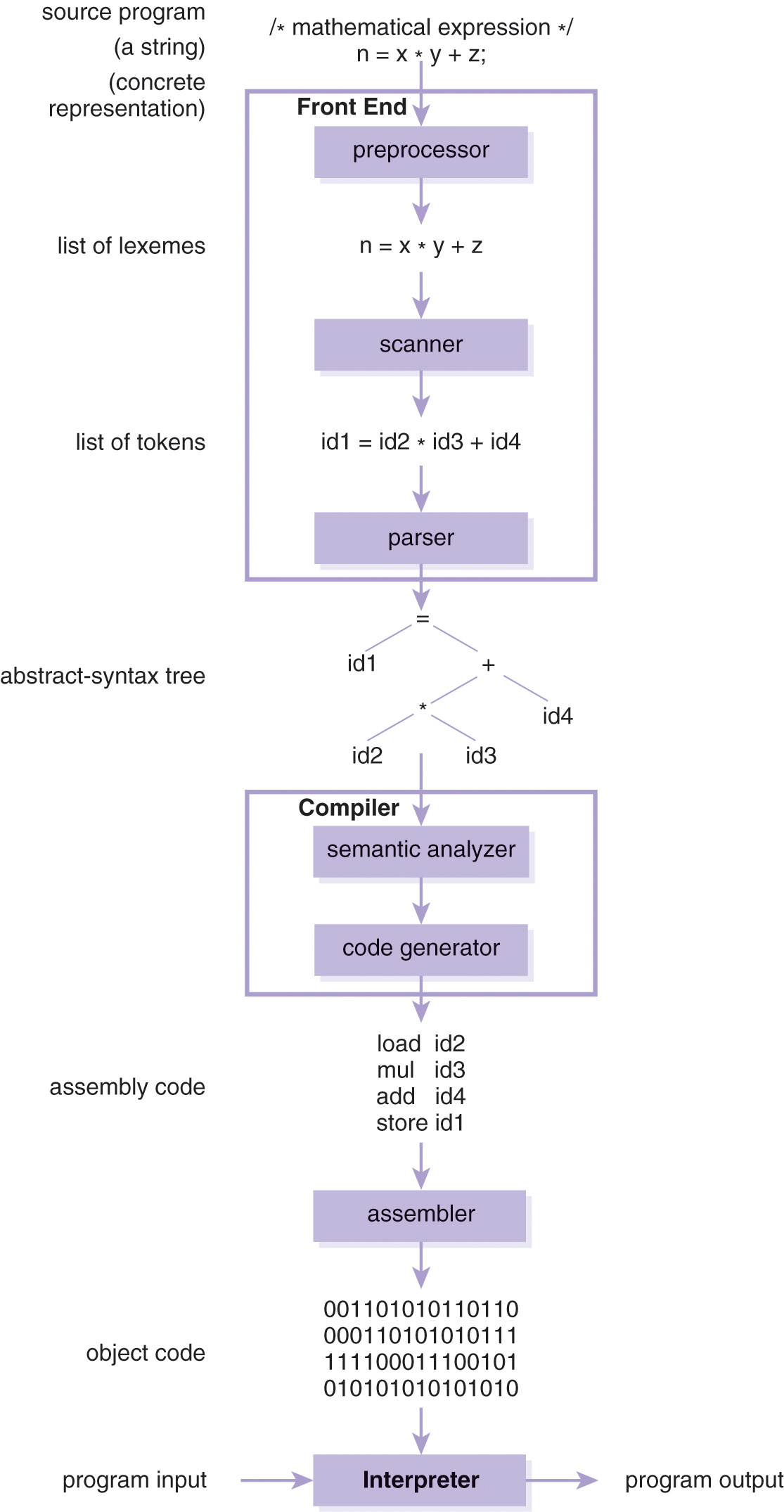
Figure 4.4 Low-level view of execution by compilation.
DescriptionAn example of the final representation being evaluated by a software interpreter is a compiler from Java source code to Java bytecode, where the resulting bytecode is executed by the Java Virtual Machine—a software interpreter. These systems are sometimes referred to as hybrid language implementations (see approach ② in Figure 4.6). They are a hybrid of compilation and interpretation.3 Using a hybrid approach, high-level language is decoded only once and compiled into an architecturally neutral, intermediate form (e.g., bytecode) that is portable; in other words, it can be run on any system equipped with an interpreter for it. While the intermediate code cannot be interpreted as fast as object code, it is interpreted faster than the original high-level source program.
While we do not have a hardware interpreter (i.e., processor or machine) that natively executes programs written in high-level languages,4 an interpreter or compiler creates a virtual machine for the language of the source program (i.e., a computer that virtually understands that language). Therefore, an interpreter IL for language L is a virtual machine for executing programs written in language L. For example, a Scheme interpreter creates a virtual Scheme computer. Similarly, a compiler 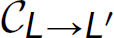 from a language L to L′ can translate a program in language L either to a language (i.e., L′) for which an interpreter executable for the target processor exists (i.e., IL1); alternatively, it can translate the program directly to code understood by the target processor. Thus, the (
from a language L to L′ can translate a program in language L either to a language (i.e., L′) for which an interpreter executable for the target processor exists (i.e., IL1); alternatively, it can translate the program directly to code understood by the target processor. Thus, the (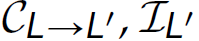 ) pair also serves as a virtual machine for language L. For instance, a compiler from Java source code to Java bytecode and a Java bytecode interpreter—the (javac, java)pair—provide a virtual Java computer.5 Programs written in the C# programming language within .NET run-time environment are compiled, interpreted, and executed in a similar fashion.
) pair also serves as a virtual machine for language L. For instance, a compiler from Java source code to Java bytecode and a Java bytecode interpreter—the (javac, java)pair—provide a virtual Java computer.5 Programs written in the C# programming language within .NET run-time environment are compiled, interpreted, and executed in a similar fashion.
Some language implementations delay/perform the translation of (parts of) the final intermediate representation produced into object code until run-time. These systems are called Just-in-Time (JIT) implementations and use just-in-time compilation.
Ultimately, program execution relies on a hardware or software interpreter. (We build a series of progressive language interpreters in Chapters 10–12, where program execution by interpretation is the focus.)
This view of an interpreter as a virtual machine is assumed in Figure 4.1 where at the bottom of that figure the interpreter is given the abstract-syntax tree and the program input as input and executes the program directly to produce program output. Unless that interpreter (at the bottom) is a hardware processor and its input is object code, that figure is an abstraction of another process because the interpreter—a program like any other—needs to be executed (i.e., interpreted or compiled itself). Therefore, a lower-level presentation of interpretation is given in Figure 4.5.
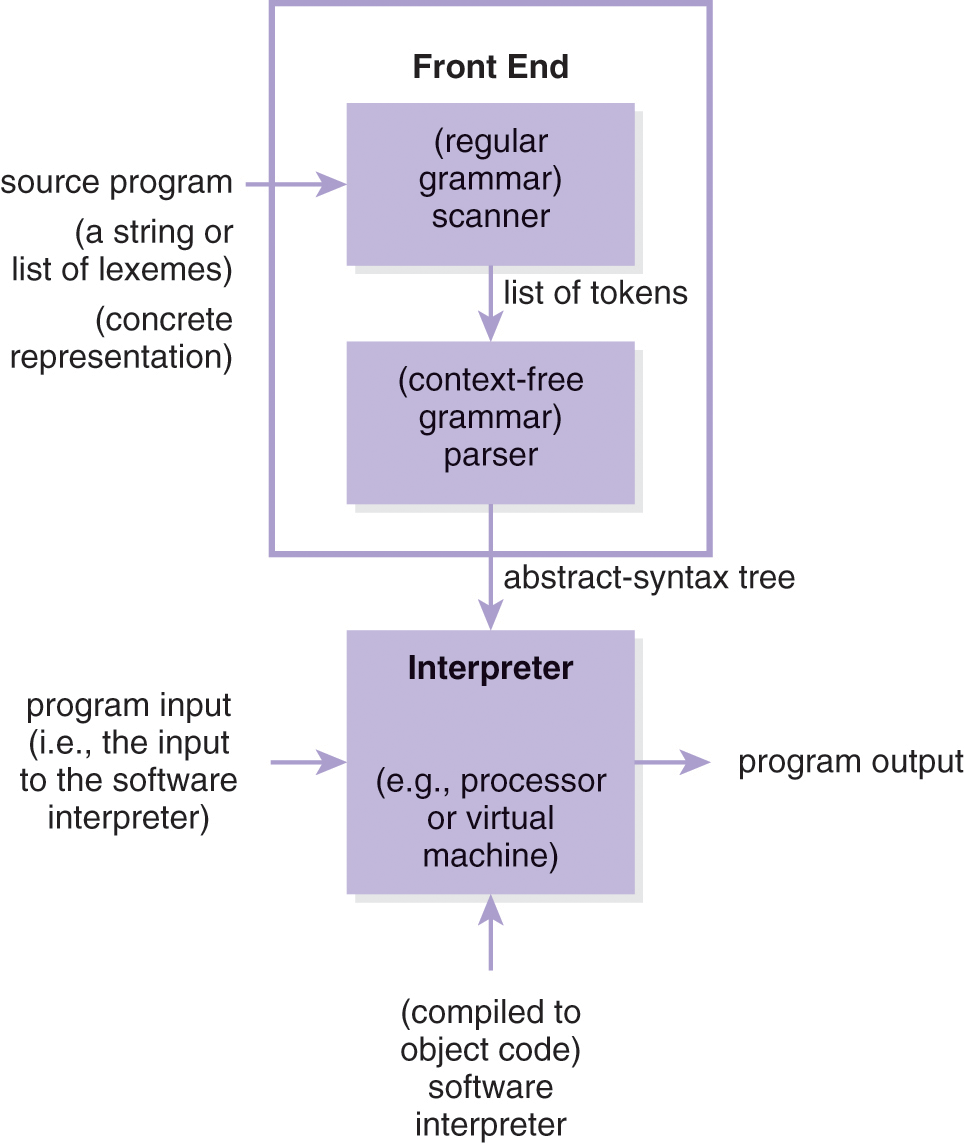
Figure 4.5 Alternative view of execution by interpretation.
DescriptionSpecifically, an interpreter compiled into object code is interpreted by a processor (see approach ③ of Figure 4.6). In addition to accepting the interpreter as input, the processor accepts the source program, or its abstract-syntax tree and the input of the source program. However, an interpreter for a computer language need not be compiled directly into object code. A software interpreter also can be interpreted by another (possibly the same) software interpreter, and so on—see approach ④ of Figure 4.6—creating a stack of interpreted software interpreters. At some point, however, the final software interpreter must be executed on the target processor. Therefore, program execution through a software interpreter ultimately depends on a compiler because the interpreter itself or the final descendant in the stack of software interpreters must be compiled into object code to run— unless the software interpreter is originally written in object code. For instance, the simple interpreter given previously is written in C and compiled into object code using gcc (see approach ③ of Figure 4.6). The execution of a compiled program depends on either a hardware or software interpreter. Thus, compilation and interpretation are mutually dependent upon each other in regard to program execution (Figure 4.7).
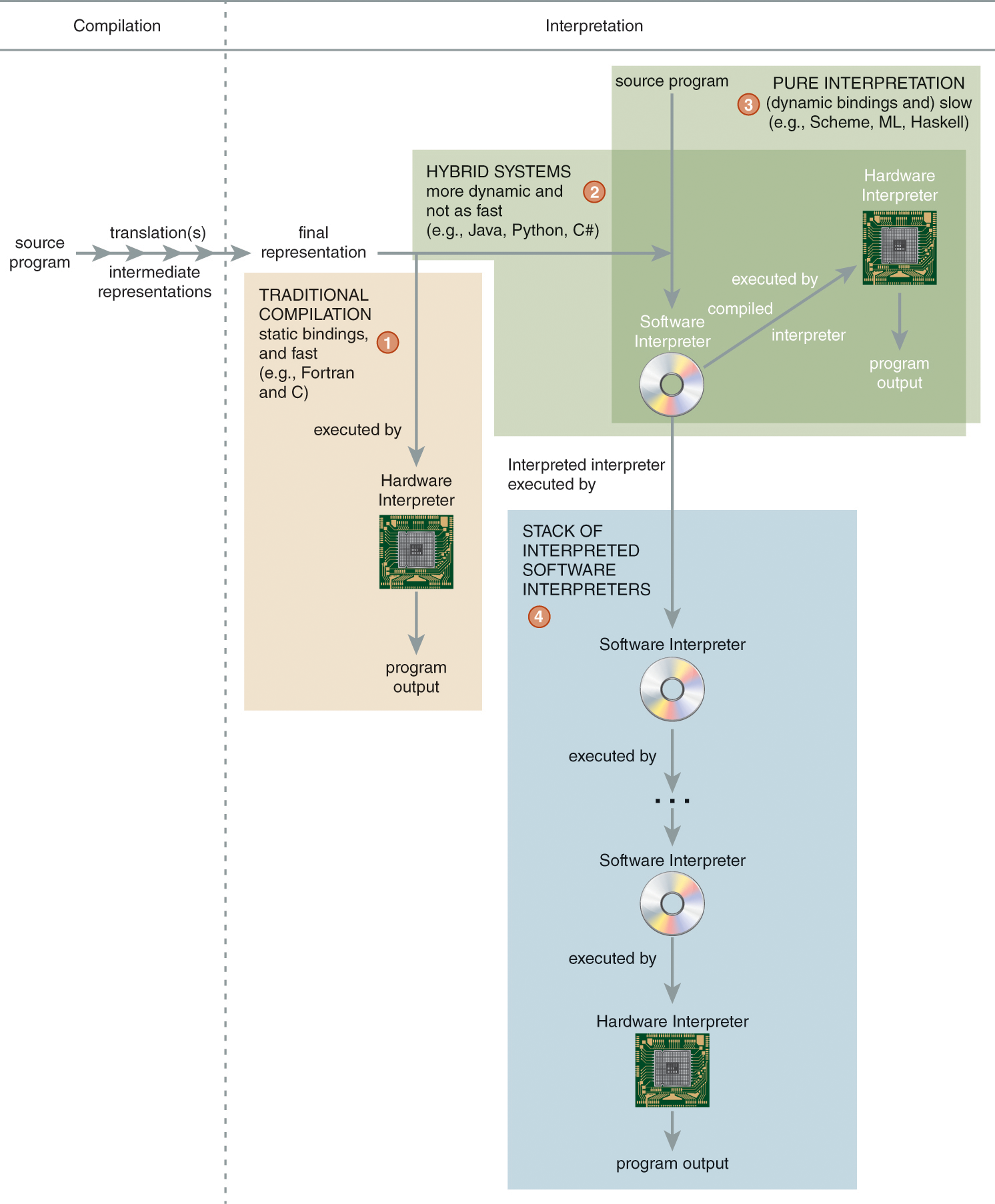
Figure 4.6 Four different approaches to language implementation.
Description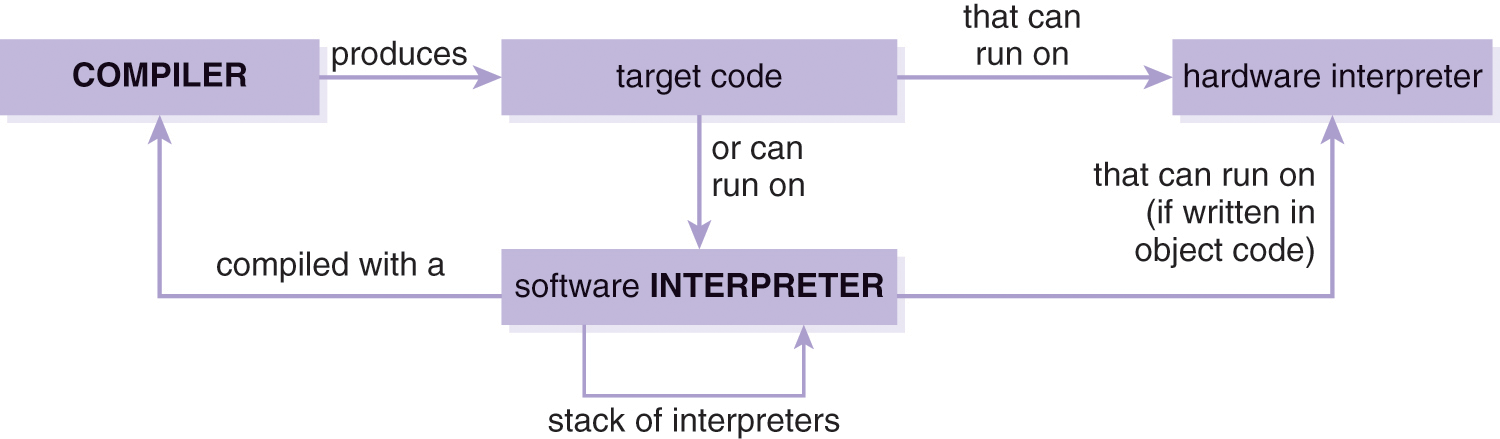
Figure 4.7 Mutually dependent relationship between compilers and interpreters in regard to program execution.
DescriptionFigure 4.6 summarizes the four different approaches to programming language implementation described here. Each approach is in a box that is labeled with a circled number and presented here in order from fastest to slowest execution:
① Traditional compilation directly to object code (e.g., Fortran, C)
② Hybrid systems: interpretation of a compiled, final representation through a compiled interpreter (e.g., Java)
③ Pure interpretation of a source program through a compiled interpreter (e.g., Scheme, ML)
④ Interpretation of either a source program or a compiled final representation through a stack of interpreted software interpreters
The study of language implementation and methods of execution, as depicted in Figure 4.6 through progressive levels of compilation and/or interpretation, again brings us face-to-face with the concept of abstraction.
Note that the figures in this section are conceptual: They identify the major components and steps in the interpretation and compilation process independent of any particular machine or computer architecture and are not intended to model any particular interpreter or compiler. Some of these steps can be combined to obviate multiple passes through the input source program or representations thereof. For instance, we discuss in Section 3.3 that lexical analysis can be performed during syntactic analysis. We also mention in Section 2.8 that mathematical expressions can be evaluated while being syntactically validated. We revisit Figures 4.1 and 4.5 in Part III, where we implement fundamental concepts of programming languages through the implementation of interpreters operationalizing those concepts.
3. Any language implementation involving compilation must eventually involve interpretation; therefore, all language implementations involving compilation can be said to be hybrid systems. Here, we refer to hybrid systems as only those that compile to a representation interpreted by a compiled software interpreter (see approach ② in Figure 4.6).
4. A Lisp chip has been built as well [circlecopyrt] as a Prolog computer called the Warren Abstract Machine.
5. The Java bytecode interpreter (i.e., java) is typically referred to as the Java Virtual Machine or JVM by itself. However, it really is a virtual machine for Java bytecode rather than Java. Therefore, it is more accurate to say that the Java compiler and Java bytecode interpreter (traditionally, though somewhat inaccurately, called a JVM) together provide a virtual machine for Java.