
Types are the places, persons, and things found in an application. Object-oriented programs model real-world problems, in which types represent identities from your problem domain. An employee in a personnel program, a general ledger entry in an accounting package, and geometric shapes in a paint application are examples of types. Types include reference types, value types, and unsafe pointers. Reference types and value types will be discussed in this chapter; unsafe pointers are covered in Chapter 19, "Unsafe Code."
A reference type refers to an object created on the managed heap, and the lifetime of the resulting object is controlled by the Garbage Collector, which is a component of the Common Language Runtime (CLR). The local or member reference holds the location of an object created on the managed heap. Reference types are derived from System.Object implicitly and created with the new keyword. The most common reference type is a class. Other reference types are interfaces, arrays, and delegates.
Value types are lightweight components that are placed on the stack. Value types directly contain their value. Value types are usually created statically. For custom initialization, a value type can be constituted using the new statement, which will call the appropriate constructor. Unlike with a reference type, doing this with a value type does not create an object on the managed heap. It still resides on the stack. Value types derive from System.ValueType, which is derived from System.Object. System.ValueType defines a value type by rewriting some of the semantics of System.Object. Primitives such as int, float, char, and bool are archetypal value types. As a primitive, a string is a hybrid. Strictly speaking, strings are reference types, but they have some of the characteristics of value types.
Classes and structures are the primary focus of this chapter. A class or structure is a template for creating components of similar behavior and state. A class instance is called an object, whereas a structure instance is called a value. An Employee class would describe the common state and behavior of any employee. Each instance of the Employee class is an object. A Fraction structure would be a template for calculating fractions. Each instance of the Fraction structure is a value. The Employee and Fraction instances share common behavior with their siblings but have distinct identities. Within a classification of objects, the GetHashCode method returns a unique identity that distinguishes a specific component from any other sibling—even when the state is identical.
You should view classes and structures as independent contractors. They should be self-sufficient. Types collaborate with others through a published interface and hide extraneous details. In this way, classes and structures should be fully abstracted. This avoids dependencies between components, which leads to software that is error-prone and hard to maintain.
In C#, types have an important role. First, all code must be contained in a type. Global functions and variables are not permitted, preventing dependencies that can plague an otherwise robust application. Second, classes published in the .NET Framework Class Library provide essential services that are integral to any .NET application.
A class is described in a class declaration. A class declaration consists of a class header and body. The class header includes attributes, modifiers, the class keyword, an identifier, and the base class list. The class body encapsulates the members of the class, which are the data members and member functions. Here is the syntax of a class declaration:
attributes accessibility modifiers class identifier: baselist { class_body };
Attributes provide additional context to a class. If you think of a class as a noun, attributes are the adjectives. For example, the Serializable attribute identifies a class that can be serialized to storage. There is an assortment of predefined attributes. You can also define custom attributes. Attributes are optional and classes have no default attributes. Further details on attributes are in Chapter 13.
Accessibility is the visibility of the class. Public classes are visible in the current assembly and in assemblies referencing that assembly. Internal classes are visible solely in the containing assembly. The default accessibility of a class is internal. Nested classes have additional accessibility options, which are described later in this chapter.
Modifiers refine the declaration of a class. For example, the abstract modifier prevents instances of the class from being created. Modifiers are optional, and there is no default. Table 2-1 lists the modifiers.
Table 2-1. Class modifiers
Modifier | Description |
|---|---|
abstract | Class is abstract; instances of the class cannot be created. |
sealed | Class cannot be inherited by a derived class. |
static | Class contains only static members. |
unsafe | Class can contain unsafe constructs, such as a pointer; also requires the unsafe compiler option. |
A class can inherit the members of a single base class. Multiple inheritance is not supported in the Common Language Specification of .NET. However, a class can inherit and implement multiple interfaces. The baselist lists the inherited class, if any, and interfaces to be implemented. By default, classes inherit from the System.Object type. Inheritance and System.Object are discussed in more detail in Chapter 3.
The class body contains the members of the class, which define the behavior and state of that class. The member functions are the behavior, whereas data members are the state. As a design goal, classes should expose an interface composed of the public functions of the class. Only those functions necessary to collaborate with the class should be exposed. Other functions should remain private or protected—internal functionality should remain private. The state of the class should be abstracted and described through the behavior of the class, which means the class is fully abstracted. You then manage the state of an object entirely through its public interface.
Classes do not require members. Most members can be inherited by a child class.
Unlike C++, classes are not terminated with a semicolon, which was commonly omitted by C++ programmers.
XInt is a class and a thin wrapper for an integer:
internal sealed class XInt {
public int iField = 0;
}The XInt class has internal accessibility and visibility in the current assembly, but is not visible to a referencing assembly. The sealed modifier means that the class cannot be refined through inheritance.
The following code uses the new statement to create an instance of the XInt class:
public void Func() {
XInt obj = new XInt();
obj.iField = 5;
}Classes are composed of members: member functions and fields. Use the member operator (.) to access members. The dot binds an instance member to an object or a static member to a class. In the following code, jim.name accesses the name field of the jim object:
using System;
namespace Donis.CSharpBook {
public class Employee {
public string name;
}
public class Personnel {
static void Main() {
Employee jim = new Employee();
jim.name = "Wilson, Jim";
}
}
}Table 2-2 describes the list of possible class members.
Table 2-2. Type members
Member | Description |
|---|---|
Class | Nested class |
Constant | Invariable data member |
Constructor | Specialized method that initializes a component or class |
Delegate | Container of one or more type-safe function references |
Destructor | Specialized method that performs cleanup of object resources upon garbage collection |
Event | Callbacks to method provided by a subscriber |
Field | Data member |
Indexer | Specialized property that indexes the current object |
Interface | Nested interface |
Method | Instance or static function |
Operator | Operator member function that overrides implicit operator behavior |
Properties | Get and set functions presented as a data member |
Structure | Nested structure within a class |
When a member is declared, attributes can be applied and accessibility defined. Members are further described with attributes. Accessibility sets the visibility of a class member.
Members defined in a class are scoped to that class. However, the visibility of the member is defined by accessibility keywords. The most common accessibility keywords are public and private. Public members are visible inside and outside the class. The visibility of private members is restricted to the containing class. Private is the default accessibility of a class member. Table 2-3 details the accessibility keywords.
Table 2-3. Accessibility keywords
Keyword | Description |
|---|---|
internal | Visible in containing assembly |
internal protected | Visible in containing assembly or descendants of the current class |
private | Visible inside current class |
protected | Visible inside current class and any descendants |
public | Visible in containing assembly and assemblies referencing that assembly |
Attributes are usually the first element of the member declaration and further describe a member by extending the metadata of that element. The Obsolete attribute is an example of an attribute and marks a function as deprecated. Attributes are optional. By default, a member has no attributes.
Modifiers refine the definition of the applicable member. Modifiers are optional, and there are no defaults. Some modifiers are reserved depending on the classification of members. For example, the override modifier is applicable to member functions but not data members. Table 2-4 lists the available member modifiers.
Table 2-4. Member modifiers
Modifier | Description |
|---|---|
abstract | A member function has no implementation and is described through inheritance. |
extern | Implemented in an external dynamic-link library (DLL). |
new | Hides a matching member in the base class. |
override | Indicates that a member function in a derived class overrides a virtual method in the base class. |
readonly | Fields declared as readonly are initialized at declaration or in a constructor. |
sealed | The member function cannot be further refined through inheritance. |
static | Member belongs to the class and not an instance. |
virtual | Virtual member functions are overridable in a derived class. |
volatile | Volatile fields are assumed to be accessible from multiple threads, which limits the applicable optimizations. This keeps the most current value in the field. |
Members belong either to an instance of a class or to the class itself. Static members are bound to a class. Except for constants, class members default to instance members and are bound to an object via the this reference. Constant members are implicitly static. Static members are classwise and have no implied this context. Certain types of members cannot be static and others cannot be instance members; destructors and operator member functions are an example. Destructors cannot be static, whereas operator member functions cannot be instance members.
Instance members when used are qualified by the object name. Here is the syntax of an instance member:
objectname.instancemember
Static members are prefixed with the class name:
classname.staticmember
The lifetime of static members is closely linked to the lifetime of the application. The lifetime of instance members is linked to an instance and is accessible from the point of instantiation. Access to instance members of a local reference cease when the instance variable is no longer in scope. Therefore, the lifetime of an instance member is a subset of the lifetime of an application. Static members are essentially always available, whereas instance members are not. Static members are similar to global functions and variables but have the benefit of encapsulation. Static members can be private to limit their visibility.
Your design analysis should determine which members are instance members and which are static members. For example, in a personnel application for small businesses, there is an Employee class. The employee number is an instance member of the class. In the problem domain, each employee is assigned a unique identifier. However, the company name member is static because all employees work for the same company. The company name does not belong to a single employee, but to the classification.
The this reference is a readonly reference to the current object. Instance member functions are passed a this reference as a hidden parameter of the function. In an instance function, the this reference is automatically applied to any instance members. This assures that within an instance member function, you can implicitly refer to members of the same object. In the following code, GetEmployeeInfo is an instance member function referring to other instance members (the this reference is implied):
public void GetEmployeeInfo() {
PrintEmployeeName();
PrintEmployeeAddress();
PrintEmployeeId();
}Here is the same code, except that the this pointer is explicit (the behavior of the function remains the same):
public void GetEmployeeInfo() {
this.PrintEmployeeName();
this.PrintEmployeeAddress();
this.PrintEmployeeId();
}In the preceding code, the this reference was not required. The this reference is sometimes useful as a function return value or as a parameter. In addition, the this reference can improve code readability and provide IntelliSense for class members when editing the code in Microsoft Visual Studio.
Static member functions are not passed a this reference as a hidden parameter. For this reason, a static function member cannot directly access nonstatic members of the class. Therefore, you cannot refer to an instance member from a static member. Static members are essentially limited to accessing other static members. Instance members have access to both instance and static members of the class.
Members are broadly grouped into data and function members. As mentioned, types consist of states and behaviors. Data members are states, whereas function members define behavior. Data members include constants, fields, and nested types. As previously mentioned, data members are typically private to enforce encapsulation and to adhere to the principle of data hiding and abstraction. The class developer gains implementation independence and the freedom to modify the type so long as the public interface is not changed. Once published, the interface should be immutable.
Constants are data members. They are initialized at compile time using a constant expression and cannot be modified at run time. Constants are assigned a type and must be used within the context of that type. This makes constants type-safe. Constants are usually value types, such as integer or double. A constant can be a reference type, but with limitations. Reference types are typically initialized at run time, which is prohibited with a constant. Therefore, reference types as constants must be set to null at declaration. The sole exception are strings, which are reference types but can be assigned a non-null value at declaration.
The following is the syntax of a constant member:
accessibility modifier const identifier = initialization;
With constants, the only allowable modifier is new, which hides an inherited constant of the same name in the base type. Constants are implicitly static. The initialization is performed at compile time. You can declare and initialize several constants simultaneously.
The following class has several constant data members:
public class ZClass {
public const int fielda = 5, fieldb = 15;
public const int fieldc = fieldd + 10; // Error
public static int fieldd = 15;
}The assignment to fieldc causes a compile error. The fieldd member is a nonconstant member variable and is evaluated at run time. Thus, fieldd cannot be used in an assignment to a constant variable.
Instance fields hold state information bound to a specific object. The state information is stored in managed memory created for the object. Static fields are data owned by the class. A single instance of static data is created for the class. It is not replicated for each instance. Fields can be reference or value types. Here is the syntax for declaring a field:
accessibility modifier type fieldname = initialization;
Fields support the full assortment of accessibility. Valid modifiers for a field include new, static, readonly, and volatile.
Initialization is optional but recommended. Uninitialized fields are assigned a default value of zero or null. Fields can be initialized individually or in an initialization list.
Initialization is performed in the textual order in which the fields appear in the class, which is top-down. The textual order is demonstrated in the following code:
using System;
namespace Donis.CSharpBook{
internal class ZClass {
public int iField1 = FuncA(), iField2 = FuncC();
public int iField3 = FuncB();
public static int FuncA() {
Console.WriteLine("ZClass.FuncA");
return 0;
}
public static int FuncB() {
Console.WriteLine("ZClass.FuncB");
return 1;
}
public static int FuncC() {
Console.WriteLine("ZClass.FuncC");
return 2;
}
}
public class Starter {
public static void Main() {
ZClass obj = new ZClass();
}
}
}Running this code confirms that FuncA, FuncC, and FuncB are called in sequence based on the textual order of field initialization.
Constants must be initialized at compile time. This limits some of the flexibility of a constant. For example, if the constant value is not known until run time, a constant variable cannot be used. This is where a readonly field is helpful. A readonly field is similar to a constant except that it also can be initialized in a constructor at run time. In addition, the initialization expression of a readonly field can refer to other static fields. However, you cannot refer to a instance field. Unlike constant fields, readonly fields can be instance or static members.
The following code contains an example of a readonly field:
public class ZClass {
public ZClass() { // constructor
fieldc = 10;
}
public static int fielda = 5;
public readonly int fieldb = fielda + 10;
public int fieldc;
};Member functions contain the behavior of the class. Methods, properties, and indexers are the member functions. Methods are straightforward functions that accept parameters as input and return the result of an operation. A property functions as a data member, but it is implemented as a pair of accessor methods: the get and set method pair. An indexer is a specialized property. Indexers apply get and set methods to the this reference, which refers to the current object. The discussion of indexers is deferred to Chapter 5.
Methods contain the code of the class. A method can contain one or more return statements, which provide an orderly exit to a function. Void functions do not require a return statement and can simply fall through the end of the function. The C# compiler extrapolates all possible paths within the function. One reason for this is to make sure that all possible code paths have an appropriate return statement. Another is that the compiler is looking for unreachable code. The following code, stored in unreachable.cs, includes both unreachable code and a code path without a proper return statement:
public static int Main() {
if (true) {
Console.WriteLine("true");
}
else {
Console.WriteLine("false");
}
}The if statement is always true. Therefore, the else code is unreachable. Main returns int. However, the method has no return statement. For these reasons, the application generates the following errors when compiled:
unreachable.cs(10,17): warning CS0162: Unreachable code detected unreachable.cs(5,27): error CS0161: 'Donis.CSharpBook.Starter.Main()': not all code paths return a value
Keep functions relatively short. Longer functions are harder to debug and test. A class comprised of a number of short functions, which is the class interface, is preferable to a class that contains only a few convoluted long functions. Remoted components are the exception: A narrower interface is preferred because it minimizes client calls and optimizes network traffic. Comparatively, local invocations are quick and efficient.
In addition to code, functions own local variables and parameters. The local variables and parameters represent the private state of the function.
The result of a function is reported with a return statement. A value type or reference type can be returned from a function. Returning a value type returns a copy of the value, while returning a reference type returns a reference to an object. Functions can have multiple return statements, each on a separate code path. More than one return statement along a single code path results in unreachable code, which will cause a compiler warning.
Functions can return an actual value or a void return type. Functions that return a value must have an explicit return statement, while functions that return void can be exited explicitly or implicitly.
To explicitly exit a function with a void return, use an empty return statement. For an implicit exit, allow the execution to exit the function naturally and without a return statement. At the end of the statement block, the function simply exits. A function can have multiple explicit return statements but only one implicit return. In the following code, Main has both an explicit and implicit exit:
static void Main(string [] arg) {
if (arg.Length > 0) {
// do something
return;
}
// implicit return
}A function evaluates to its return value. A method that returns void cannot be used in an expression. This type of method evaluates to nothing and is therefore not assignable. In other words, a function that returns void cannot be used either as a left-value or right-value of an assignment. Functions that return a value can be used in expressions. If the function returns a reference, it also can be used as the left-value in an assignment. The following code demonstrates the use of functions in expressions:
public class ZClass {
public int MethodA() {
return 5;
}
public void MethodB() {
return;
}
public int MethodC() {
int value1 = 10;
value1 = 5 + MethodA() + value1; // Valid
MethodB(); // Valid
value1 = MethodB(); // Invalid
return value1;
}
}At the call site, the return value of a function is temporarily copied to the stack. The return value is discarded after the calling statement or expression is evaluated. To preserve the return value, assign the function’s return value to something. Returns are always copied by value. When returning a value type, a copy of the result is returned. For reference types, a copy of the reference is returned. This creates an alias to an object in the calling function. Look at the following code:
using System;
namespace Donis.CSharpBook {
public class XInt {
public int iField = 0;
}
public class Starter {
public static XInt MethodA() {
XInt inner = new XInt();
inner.iField = 5;
return inner;
}
public static void Main() {
XInt outer = MethodA();
Console.WriteLine(outer.iField);
}
}
}In the preceding code, MethodA creates an instance of XInt called inner. This variable is then returned from the function. After the return, outer is an alias to the inner object, which prevents the object from becoming a candidate for garbage collection. The alias outer then can be used to access members of the inner object, as shown in the sample code.
Functions have zero or more parameters. Pass zero parameters with an empty call operator. Parameter lists can be of fixed or variable length. Use the param keyword to declare a variable length parameter list. This is discussed in Chapter 5. Parameters default to being passed by value and are copied to the stack. Changes to a parameter in the called function are discarded when the method is exited and the value is removed from the stack. In the following code, changes made in the function are lost when the function returns:
using System;
namespace Donis.CSharpBook {
public class Starter {
public static void MethodA(int parameter) {
parameter = parameter + 5;
} // change discarded
public static void Main() {
int local = 2;
MethodA(local);
Console.WriteLine(local); // Writes 2
}
}
}Parameters that are reference types are also passed by value, in that a copy of the reference itself is placed on the stack. The called function receives an alias to an object that resides on the managed heap. Using the alias, you can change the referenced object directly from the called function.
The previous example passes a parameter by value. The next example also passes a parameter by value, but the parameter is a reference type (XInt). Changes made to the object in MethodA are not discarded at the end of the called function:
using System;
namespace Donis.CSharpBook {
public class XInt {
public int iField = 2;
}
public class Starter {
public static void MethodA(XInt alias) {
alias.iField += 5;
}
public static void Main() {
XInt obj = new XInt();
MethodA(obj);
Console.WriteLine(obj.iField); // Writes 7
}
}
}Pass a parameter by reference using the ref modifier. When passed by reference, a reference to the object is passed and not a copy of the value. Because a reference to the object is passed, changes to the parameter in the called function affect the actual object and not a copy. Therefore, changes to the parameter persist beyond the called function. The ref attribute must precede the parameter in the function signature and at the call site. The function signature consists of the function name and parameter types but not the return type. The following sample code passes an integer parameter by reference. Unlike the first version of this code, which implicitly passed an integer parameter by value, changes made in MethodA are not lost.
using System;
namespace Donis.CSharpBook {
public class Starter {
public static void MethodA(ref int parameter) {
parameter = parameter + 5;
}
public static void Main() {
int var = 2;
MethodA(ref var);
Console.WriteLine(var); // Writes 7
}
}
}What happens when a reference type is passed by reference? The function receives the local reference and not an alias. First, look at the following code, in which a reference is passed by value. Inside the called function, the parameter is assigned a new instance. However, because the reference is passed by value, the change is lost when the function exits. Therefore, the original reference (obj) is unchanged:
using System;
namespace Donis.CSharpBook {
public class XInt {
public int iField = 2;
}
public class Starter {
public static void MethodA(XInt alias) {
XInt inner = new XInt();
inner.iField = 5;
alias = inner;
} // reference change lost
public static void Main() {
XInt obj = new XInt();
MethodA(obj);
Console.WriteLine(obj.iField); // Writes 2
}
}
}The next code is updated to pass the parameter by reference. The reference is passed into MethodA and updated. When the function exits, the original reference (obj) has been changed to point to the new instance:
using System;
namespace Donis.CSharpBook {
public class XInt {
public int iField = 2;
}
public class Starter {
public static void MethodA(ref XInt alias) {
XInt inner = new XInt();
inner.iField = 5;
alias = inner;
}
public static void Main() {
XInt obj=new XInt();
MethodA(ref obj);
Console.WriteLine(obj.iField); // Writes 5
}
}
}Parameters must be initialized before being passed by reference. The following code presents an error. In Main, the obj reference is unassigned before the method call. Notice that even though the parameter is initialized in the called function, the following code causes a compile error:
using System;
namespace Donis.CSharpBook {
public class XInt {
public int iField = 5;
}
public class Starter {
public static void MethodA(ref XInt alias) {
XInt inner = new XInt();
alias = inner;
}
public static void Main() {
XInt obj;
MethodA(ref obj); // Error
Console.WriteLine(obj.iField); // Won't compile
}
}
}Like the ref modifier, the out modifier passes a parameter by reference, but there is one significant difference. The out parameter does not have to be initialized prior to the function call. However, the parameter must be initialized before the called function exits. The following code is identical to the previous code except the parameter is declared and passed with the out modifier (shown in bold type) and not the ref modifier. For this reason, the code now compiles successfully:
using System;
namespace Donis.CSharpBook {
class XInt {
public int iField = 5;
}
class Starter {
public static void MethodA(out XInt alias) {
XInt inner = new XInt();
alias = inner;
}
public static void Main() {
XInt obj;
MethodA(out obj);
Console.WriteLine(obj.iField); // Writes 5
}
}
}Function overloading allows multiple implementations of the same function in a class, which promotes a consistent interface for related behavior. Overloaded methods share the same name but have unique signatures. Parameter attributes, such as out, are distinctive and considered part of the signature (the function header minus the return type). Because the return type is excluded from the signature, functions cannot be overloaded on the basis of a different return type alone. The number of parameters, the type of parameters, or both must be different. With the exception of constructors, a function cannot be overloaded based on whether it is a static or instance member.
The process of selecting a function from a set of overloaded methods, which occurs during compile time, is called function resolution. The compiler calls the function that matches the number and types of parameters in the function invocation. Sometimes a call site matches more than one function in the overloaded set. When function resolution matches two or more methods, the call is considered ambiguous and a compile error occurs. A compiler error also results if no overloaded function matches the call site.
This sample code overloads the SetName method:
using System;
namespace Donis.CSharpBook {
public class Employee {
public string name;
public void SetName(string last) {
name = last;
}
public void SetName(string first, string last) {
name = first + " " + last;
}
public void SetName(string saluation, string first, string last) {
name = saluation + " " + first + " " + last;
}
}
public class Personnel {
public static void Main() {
Employee obj = new Employee();
obj.SetName("Bob", "Kelly");
}
}
}Functions with variable-length parameter lists can be included in the set of overloaded functions. The function first is evaluated with a fixed-length parameter list. If function resolution does not yield a match, the function is evaluated with variable-length parameters.
Local variables can be either reference or value types. You can declare a local variable anywhere in a method, but there is one caveat. The local variable must be defined before use. There are competing philosophies as to when to declare local variables. Some developers prefer to declare local variables at the beginning of a method or block, where they are readily identifiable; others like to declare local variables near where they are used because they think that local variables are more maintainable when located near the affected code. Local variables are not assigned a default value prior to initialization. They can be initialized at declaration or later. At declaration, local variables can be initialized separately or in an initialization list. It is good practice to initialize local variables to something at declaration. That way, the local variable always has a known state. Referring to an unassigned local variable in an expression causes a compiler error.
This is the syntax for declaring a local variable:
modifier type variablename = initialization;
The only modifier available to local variables is const. Variables that are const must be initialized at compile time and cannot be changed thereafter.
The scope of a local variable is the entire function—regardless of where the local variable is declared. The scope of a parameter is also the entire function. Basically, local variables cannot have the same name as a parameter.
Local variables are declared at the top level or in a child block within the method. The visibility of a local variable starts where the local variable is declared. Visibility ends when the block where the local variable is declared ends. Local variables are visible in child blocks, but not in parent blocks. Because local variables maintain scope throughout the block in which they are declared, names of local variables cannot be reused in a child block. Figure 2-1 illustrates the relationship between scope and visibility of local variables.
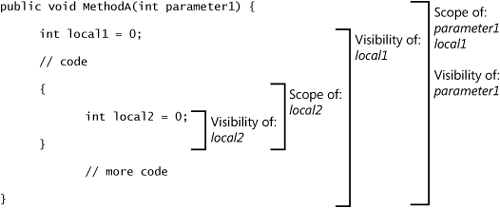
Local variables of a value type are removed from the stack when the function is exited. Local references are also removed from the stack at that time, but the reference object may or may not become a candidate for garbage collection. Assuming that no other references exist at function exit, the object will become a candidate for garbage collection. It is a good idea to assign null to a reference when the reference is no longer needed. Local variables are private to the current function and are not accessible from another function. Identically named local variables in different functions are distinct and separate entities, which are stored at different memory addresses. To share data between functions, declare a field.
Methods are the most common function member. Methods accept parameters as input, perform an operation, and return the result of the operation. Both parameters and a return result are optional. Methods are described through the method header, and implemented in the method body. Here is the syntax of a method:
attributes accessibility modifiers return_type identifier(parameter_list) { statement };
Various attributes apply to methods, such as Obsolete, StrongNameIdentityPermission, and InternalsVisibleTo. Methods can be private, public, protected, or internal. Methods can be assigned the sealed, abstract, new, and other modifiers, as explained in Chapter 3. The return_type is the result of the method. Methods that return nothing must have a void return_type. The parameter list, which consists of zero or more parameters, is the input of the method. The method body contains zero or more statements.
A constructor is a specialized function for initializing the state. An instance constructor initializes an instance of a class, while a static constructor initializes the classwise state. This guarantees that the class or object is always in a known state. Constructors have the same name as the class. Instance constructors are invoked with the new operator and cannot be called in the same manner as other member functions. Here is the syntax of a constructor:
accessibility modifier typename(parameterlist)
The accessibility of a constructor determines where new instances of the reference type can be created. For example, a public constructor allows an object to be created in the current assembly or a referencing assembly. A private or protected constructor prevents an instance from being created outside the class or a descendant of the class. The extern modifier is the only modifier applicable to constructors. Constructors can have zero or more parameters. Finally, note that constructors return void but do not have an explicitly declared return type.
This code shows one constructor for an Employee class:
using System;
namespace Donis.CSharpBook {
public class Employee {
public Employee(params string []_name) {
switch(_name.Length) {
case 1:
name = _name[0];
break;
case 2:
name = _name[0] + " " + _name[1];
break;
default:
// Error handler
break;
}
}
public void GetName() {
Console.WriteLine(name);
}
private string name = "";
}
public class Personnel {
public static void Main() {
Employee jim = new Employee("Jim", "Wilson");
jim.GetName();
}
}
}Classes with no constructors have an implicit constructor—the default constructor, which is a parameterless constructor. Default constructors assign default values to fields. A new statement with no parameters invokes the default constructor. You can replace a default constructor with a custom parameterless constructor. The following new statement calls the default constructor of a class:
Employee empl = new Employee();
Constructors can be overloaded. The function resolution of overloaded constructors is determined by the parameters of the new statement. The following Employee class has overloaded constructors:
using System;
namespace Donis.CSharpBook {
public class Employee {
public Employee(string _name) {
name = _name;
}
public Employee(string _first, string _last) {
name = _first + " " + _last;
}
private string name = "";
}
public class Personnel {
public static void Main() {
Employee jim = new Employee("Jim", "Wilson"); // 2 argument constructor
}
}
}In the preceding code, an instance of the Employee class (jim) is created using the two-argument constructor. Creating an instance using the default constructor would cause a compile error:
Employee jim = new Employee();
This is the error message:
Donis.CSharpBook.Employee' does not contain a constructor that takes '0' arguments
Why does this error occur? Although the statement is syntactically correct, the Employee class does not have a default constructor. Adding any custom constructor to a class removes the default constructor. A custom one-argument and two-argument constructor were added to the Employee class, which removed the default constructor. In this circumstance, you could explicitly add a default (parameterless) constructor to the class if needed.
A constructor can call another constructor using the this reference, which is useful for reducing redundant code. A constructor cannot call another constructor in the method body. Instead, constructors call other constructors using the colon syntax after the constructor header. This syntax is available with constructors but not with other member functions. In the following code, all the constructors of the Employee class delegate to the one-argument constructor:
class Employee {
public Employee()
: this("") {
}
public Employee(string _name) {
name = _name;
}
public Employee(string _first, string _last)
: this(_first + " " + _last) {
}
public void GetName() {
Console.WriteLine(name);
}
private string name = "";
}Constructors also can be static. You create a static constructor to initialize static fields. The static constructor is called when the class is first referenced. These are the limitations to static constructors:
The accessibility of a static constructor cannot be set.
Static constructors are parameterless.
Static constructors cannot be overloaded.
Static constructors are not called explicitly with the new statement. As mentioned, static constructors are called when the class is first referenced. In the following code, ZClass has a static constructor. The static constructor is stubbed to output the time. In Main, the time is also displayed, execution is paused for about five seconds, and then ZClass is accessed. ZClass.GetField is called and that triggers the invocation of the static constructor. This will display the time, which should be about five seconds later:
using System;
using System.Threading;
namespace Donis.CSharpBook {
public class ZClass {
static private int fielda;
static ZClass() {
Console.WriteLine(DateTime.Now.ToLongTimeString());
fielda = 42;
}
static public void GetField() {
Console.WriteLine(fielda);
}
}
public class Starter {
public static void Main() {
Console.WriteLine(DateTime.Now.ToLongTimeString());
Thread.Sleep(5000);
ZClass.GetField();
}
}
}A singleton is an object that appears once in the problem domain. Singletons provide an excellent example of private and static constructors. Singletons are limited to one instance, but that instance is required. This requirement is enforced in the implementation of the singleton. A complete explanation of the singleton pattern is found at http://www.microsoft.com/patterns.
The singleton presented in this chapter has two constructors. The private constructor initializes an instance of the class. Because this is a private constructor, the instance cannot be created outside the class. The single instance of the class is created in the static constructor. Because the static constructor is called automatically and only once, one instance—the singleton—always exists. The instance members of the class are accessible through the static instance of the class made available in the public interface.
A chess game is played with a single board—no more, no less. This is the singleton for a chess board:
using System;
namespace Donis.CSharpBook {
public class Chessboard {
private Chessboard() {
}
static Chessboard() {
board = new Chessboard();
board.start = DateTime.Now.ToShortTimeString();
}
public static Chessboard board=null;
public string player1;
public string player2;
public string start;
}
public class Game {
public static void Main() {
Chessboard game = Chessboard.board;
game.player1 = "Sally";
game.player2 = "Bob";
Console.WriteLine("{0} played {1} at {2}",
game.player1, game.player2,
game.start);
}
}
}In Main, game is an alias for the ChessBoard.board singleton. The local reference is not another instance of Chessboard. It is an alias and simply a convenience.
Object initializers are a convenient method for initializing public fields and properties. When creating an instance of a new type, provide an initialization list, which includes field or property names and assignments. You do not have to assign a value to every field. Because the fields are named, they can appear in any order in the initialization list. This is new to Visual C# 2008.
The following code provides an example of an object initializer:
public class Name
{
public string GetName()
{
return first + " " + middle +
" " + last;
}
public string first = "";
public string last = "";
public string middle = "";
}
class Names
{
public static void Main()
{
Name donis = new Name { first = "Donis",
last = "Marshall" };
Name lisa = new Name { first = "Lisa",
last = "Miller" };
Console.WriteLine(donis.GetName());
Console.WriteLine(lisa.GetName());
}
}It is good practice to remove unused objects from resources. That is the purpose of the destructor method. Destructors are not called directly in source code but during garbage collection. This provides an opportunity for an object to clean itself before it is removed from memory. Garbage collection is nondeterministic. A destructor is invoked at an undetermined moment in the future. Like a constructor, the destructor has the same name as the class, except a destructor is prefixed with a tilde (~). The destructor is called by the Finalize method, which is inherited from System.Object. In C#, you cannot override the Finalize method. For deterministic garbage collection, inherit the IDisposable interface and implement IDisposable.Dispose based on the disposable pattern. The disposable pattern is discussed in Chapter 18.
Destructors differ from other member functions in the following ways:
Destructors cannot be overloaded.
Destructors are parameterless.
Destructors are not inherited.
Accessibility cannot be applied to destructors.
Extern is the sole available modifier.
The return type cannot be set explicitly. Destructors implicitly return void.
Here is the syntax of a destructor:
modifier ~typename()
Destructors have usage patterns. They also have performance and efficiency implications. Understand the ramifications of destructors before adding a destructor in a class. These topics are also reviewed in Chapter 18.
The following code implements a destructor and a Dispose method. The WriteToFile class is a wrapper for a StreamWriter object. The constructor initializes the internal object, and the Dispose method closes the file resource. The destructor delegates to this Dispose method. You can call the Dispose method explicitly or have the destructor called implicitly at garbage collection. The Main method tests the class:
using System;
using System.IO;
namespace Donis.CSharpBook {
public class WriteToFile: IDisposable {
public WriteToFile(string _file, string _text) {
file = new StreamWriter(_file, true);
text = _text;
}
public void WriteText() {
file.WriteLine(text);
}
public void Dispose() {
if (null != file)
{
file.Close();
file = null;
}
}
~WriteToFile() {
if (null != file)
{
Dispose();
}
}
private StreamWriter file;
private string text;
}
public class Writer {
public static void Main() {
WriteToFile sample = new WriteToFile("sample.txt", "My text file");
sample.WriteText();
sample.Dispose();
}
}
}A property provides the convenience of a field but the safety of a function. Properties are visible like a field but are actually a get and set method. The get method is called when a value is returned from the property. Conversely, the set method is used when a value is assigned to the property. Fields are typically private, which protects the state of the object or class. You access the private fields through the public interface. Properties combine a private field and a public interface in a single entity. There are several benefits of using properties instead of public fields:
Properties are safer than public or protected fields. The set method can be used to validate any input for a property.
Properties can be computed, which adds some flexibility.
Lazy initialization can be used with properties. This is particularly useful when the target data is expensive to initialize or obtain. Datasets are an ideal example. The cost of loading a dataset can be delayed until the property is actually accessed. This is more difficult to accomplish with fields.
Write-only and read-only properties are supported. Fields support only read-only accessibility.
Properties can be included as a member in an interface type. Fields are not allowed in interfaces.
A property is a get and set method. Neither method is called directly. Depending on how the property is being used, the correct method is called implicitly. As a left-value of an assignment, the set method of the property is called. When used as a right-value, the get method of the property is called. The get method also is called if a property is used within an expression.
Here is the syntax of a property declaration:
accessibility modifier type identifier { accessibility get {statement} accessibility set {statement} }
The accessibility and modifier apply to both the get and set method. However, either the set or get method can override the accessibility when necessary. In this way, for example, the get method could be public, while the set method is private. Type is the underlying type of the property. Neither the get nor set method has an explicit return type or parameter list. Both are inferred. The get method returns the property type and has no parameters. The set method returns void and has a single parameter, which is the same type as the property. In the set method, the value keyword represents the implied parameter.
In this code, the Person class has an age property:
using System;
namespace Donis.CSharpBook {
public class Person {
private int prop_age;
public int age {
set {
// perform validation
prop_age = value;
}
get {
return prop_age;
}
}
}
class People{
public static void Main() {
Person bob = new Person();
bob.age = 30; // Calls set method
Console.WriteLine(bob.age); // Call gets method
}
}
}Properties have no inherent data storage, which can be efficient because data storage is not always required. For example, computed properties might not require data storage. If desired, a corresponding data store can be declared in the class. The data store of a property can be a single field. This one-to-one relationship between the property and the data store is not required. A composite property can consist of multiple fields. Conversely, multiple properties can rely on the same field. The latter case is demonstrated in the following code, where the name, first, and last properties rely on the prop_name field:
using System;
namespace Donis.CSharpBook {
public class Employee {
private string prop_name;
public string name {
get {
return prop_name;
}
set {
prop_name = value;
}
}
public string first {
get {
return (prop_name.Split(' '))[0];
}
set {
string lastname = name.Split(' ')[1];
prop_name = value + " " + lastname;
}
}
public string last {
get {
return (prop_name.Split(' '))[1];
}
set {
string firstname = name.Split(' ')[0];
prop_name = firstname + " " + value;
}
}
}
public class Personnel{
public static void Main() {
Employee jim=new Employee();
jim.name="Jim Wilson";
jim.first="Dan";
Console.WriteLine(jim.name); // Dan Wilson
Console.WriteLine(jim.last); // Wilson
}
}
}Read-only properties implement the get method but not the set method. Birth date is an ideal read-only property. Conversely, write-only properties have a set method alone, which is common with a password property:
public class SensitiveForm{
private string prop_password;
public string password {
set {
prop_password = value;
}
}
}Automatically implemented properties are one of the new features of Visual C# 2008. In the previous sample code, a backing variable of the property was created for storage. Automatically implemented properties automatically have storage for the property. This is a convenience because the developer does not have to implement the storage explicitly. Both the get and set methods of the automatically implemented property must be provided—the property cannot be either read-only or write-only.
This is the syntax for creating an automatically implemented property:
accessibility modifier type identifier { modifier get {;} modifier set {;} }
The following is sample code of an automatically implemented property:
using System;
namespace Donis.CSharpBook {
public class Person {
public int age {
get;
set;
}
}
class People {
public static void Main() {
Person bob = new Person();
bob.age = 30; // Calls set method
Console.WriteLine(bob.age); // Call gets method
}
}
}Validating the state of an object is important to avoid the "garbage-in/garbage-out" syndrome. An object or class is only as useful as the quality of the data it contains. Validation can be performed in the set method of a property. What is the appropriate action if the validation fails? You cannot return an error code from a set method. There are two options. The first (and preferable) option is to throw an exception. The second option, if the property type is a reference or nullable type, is to set the storage to null.
The estimated maximum age of a person is 120 years. This check can be added to our age property. In this example, an exception is thrown for an invalid age:
public class Person {
private int prop_age;
public int age {
set {
if (value < 0 || value > 120) {
throw new ApplicationException("Invalid age!");
}
prop_age = value;
}
get {
return prop_age;
}
}
}In the next example, when the input value is invalid, the property is set to null:
public class Person {
private int? prop_age;
public int? age {
set {
if (value < 0 || value > 120) {
prop_age = null;
return;
}
prop_age = value;
}
get {
return prop_age;
}
}
}Nested types are created inside a class or structure. This is an example of a nested class:
public class Outer {
public void FuncA() {
}
public class Inner {
static public void FuncB() {
Console.WriteLine("Outer.Inner.FuncB()");
}
}
}Nested types can be public or private or have other accessibility. The full complement of modifiers is available. Use the dot syntax to access members of the nested class. The following code calls a static method of the Inner class:
Outer.Inner.FuncB();
You can create an instance of the nested class. If the nested class is public, references to the nested class can be created inside or outside the outer class depending on the visibility. A nested class that is private can be instantiated only inside the outer class. This is one reason for using nested classes. Invoking the this object within the nested class refers to members of the nested class alone. Instance members of the outer class are not accessible from the this object within the nested class. You can provide access to the outer object through the constructor of the nested class. Pass a reference of the outer object as a parameter. The back reference is then available to access the instance members of the outer object from within the nested class. The static members of the outer class, regardless of accessibility, are available to the nested class.
The Automobile class models a car engine, which is a system. An automobile system contains an alternator, ignition, steering, and other subsystems. This is an abbreviated version of an Automobile class:
using System;
namespace Donis.CSharpBook {
public class Automobile {
public Automobile() {
starter = new StarterMotor(this);
}
public void Start() {
starter.Ignition();
}
private bool prop_started = false;
public bool started {
get {
return prop_started;
}
}
private class StarterMotor {
public StarterMotor(Automobile _auto) {
auto = _auto;
}
public void Ignition() {
auto.prop_started = true;
}
Automobile auto;
}
private StarterMotor starter;
}
public class Starter {
public static void Main() {
Automobile car = new Automobile();
car.Start();
if (car.started) {
Console.WriteLine("Car started");
}
}
}
}A partial type can span multiple source files. When compiled, the elements of the partial type are combined into a single type in the assembly. With partial types, each source file has a complete type declaration and body. The type declaration is preceded with the partial keyword. The type body in each source file includes only the members that the partial type is contributing to the overall type. Code generators benefit from partial types. You can rely on the Integrated Development Environment (IDE) or wizard to generate the core code. The developer can then extend the code in a separate source file without disturbing the core code. Teams of developers collaborating on an application also benefit from partial types. The type can be parceled based on responsibility. Each developer works in a separate source file, which isolates changes and allows each developer to focus only on code for which he or she is directly responsible.
Consistency is the key to partial types, with the rules as follows:
Each partial type is preceded with the partial keyword.
The partial types must have the same accessibility.
If any partial type is sealed, the entire class is sealed.
If any partial type is abstract, the entire class is abstract.
Inheritance of any partial type applies to the entire class.
Here is an example of a class separated into partial types:
// partial1.cs
using System;
namespace Donis.CSharpBook {
public partial class ZClass {
public void CoreMethodA() {
Console.WriteLine("ZClass.CoreMethodA");
}
}
public class Starter {
public static void Main() {
ZClass obj = new ZClass();
obj.CoreMethodA();
obj.ExtendedMethodA();
}
}
}
// partial2.cs
using System;
namespace Donis.CSharpBook {
public partial class ZClass {
public void ExtendedMethodA() {
Console.WriteLine("ZClass.ExtendedMethodA");
}
}
}Figure 2-2 shows the ZClass in the Intermediate Language Disassembler (ILDASM) tool. It confirms that the partial types are merged into a single class.
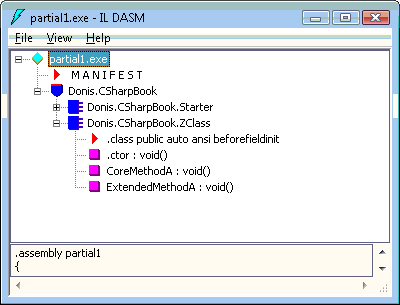
A partial method is a method that is declared in one partial class but implemented in another. There can be only one declaration and only one implementation of the partial method across the related partial classes. Partial methods have many of the same benefits of a partial class. The declaration can be provided by the code generator but implementation is completed by the developer. Partial methods must return void and default to private accessibility. In addition, partial methods cannot have out parameters. If the partial method is not implemented, the declaration and any calls to the method are removed at compile time by the compiler. This is another new feature of Visual C# 2008.
This is sample code of a partial method:
// corecode.cs
public partial class XClass{
partial void ToBeImplemented();
}
// source2.cs
public partial class XClass{
partial void ToBeImplemented() {
Console.WriteLine("XClass.ToBeImplemented");
}
}