
To be able to find a list of all topics which contain one or more specific words, we present the user with a search form in the navigation area. These are some of the considerations when designing such a form:
- The user must be able to enter more than one word to find topics with all those words in their content
- Searching should be case insensitive
- Locating those topics should be fast even if we have a large number of topics with lots of text
- Auto completion would be helpful to aid the user in specifying words that are actually part of the content of some topic
All these considerations will determine how we will implement the functionality in the delivery layer and on the presentation side.
The search options in the navigation area and the tag entry field in the edit screen all feature autocomplete functionality. We encountered autocomplete functionality before in the previous chapter where it was employed to show a list of titles and authors.
With the word and tag search fields in the wiki application, we would like to go one step further. Here we would like to have auto completion on the list of items separated by commas. The illustrations show what happens if we type a single word and what happens when a second word is typed in:
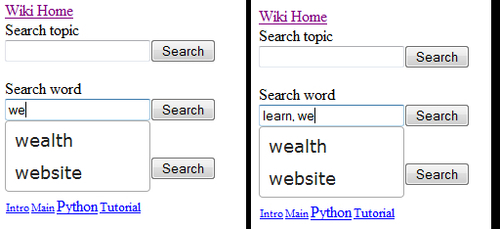
We cannot simply send the list of items complete with commas to the server because in that case we could not impose a minimum character limit. It would work for the first word of course, but once the first word is present in the input field, each subsequent character entry would result in a request to the server whereas we would like this to happen when the minimum character count for the second word is reached.
Fortunately, the jQuery UI website already shows an example of how to use the autocomplete widget in exactly this situation (check the example at http://jqueryui.com/demos/autocomplete/#multiple-remote). As this online example is fairly well explained in its comments, we will not list it here, but note that the trick lies in the fact that instead of supplying the autocomplete widget with just a source URL, it is also given a callback function that will be invoked instead of retrieving information directly. This callback has access to the string of comma-separated items in the input field and can call the remote source with just the last item in the list.
On the delivery side, the word search functionality is represented by two methods. The first one is the getwords() method in wikiweb.py:
Chapter6/wikiweb.py
@cherrypy.expose
def getwords(self,term,_=None):
term = term.lower()
return json.dumps(
[t for t in wikidb.Word.getcolumnvalues('word')
if t.startswith(term)])
getwords() will return a list of words that starts with the characters in the term argument and returns those as a JSON serialized string for use by the auto completion function that we will add to the input field of the word search form. Words are stored all lowercase in the database. Therefore, the term argument is lowercased as well before matching any words (highlighted). Note that the argument to json.dumps() is in square brackets to convert the generator returned by the list comprehension to a list. This is necessary because json.dumps does not accept generators.
The second method is called searchwords(), which will return a list of clickable items consisting of those topics that contain all words passed to it as a string of comma-separated words. The list will be alphabetically sorted on the name of the topic:
Chapter6/wikiweb.py
@cherrypy.expose def searchwords(self,words): yield '<ul> ' for topic in sorted(wiki.searchwords(words)): yield '<li><a href="http://show?topic=%s">%s</a></li>'%( topic,topic) yield '</ul> '
Note that the markup returned by searchwords() is not a complete HTML page, as it will be called asynchronously when the user clicks the search button and the result will replace the content part.
Again, the hard work of actually finding the topics that contain the words is not done in the delivery layer, but delegated to the function wiki.searchwords():
Chapter6/wiki.py
def searchwords(words):
topics = None
for word in words.split(','):
word = word.strip('.,:;!? ').lower() # a list with a final
comma will yield an empty last term
if word.isalnum():
w = list(wikidb.Word.list(word=word))
if len(w):
ww = wikidb.Word(id=w[0])
wtopic = set( w.a_id for w in wikidb.
TopicWord.list(ww) )
if topics is None :
topics = wtopic
else:
topics &= wtopic
if len(topics) == 0 :
break
if not topics is None:
for t in topics:
yield wikidb.Topic(id=t).title
This searchwords() function starts by splitting the comma-separated items in its word argument and sanitizing each item by stripping, leading, and trailing punctuation and whitespace and converting it to lowercase (highlighted).
The next step is to consider only items that consist solely of alphanumeric characters because these are the only ones stored as word entities to prevent pollution by meaningless abbreviations or markup.
We then check whether the item is present in the database by calling the list() method of the Word class. This will return either an empty list or a list containing just a single ID. In the latter case, this ID is used to construct a Word instance and we use that to retrieve a list of Topic IDs associated with this word by calling the list() method of the TopicWord class (highlighted) and convert it to a set for easy manipulation.
If this is the first word we are checking, the topics variable will contain None and we simply assign the set to it. If the topic variable already contains a set, we replace the set by the intersection of the stored set and the set of topic IDs associated with the word we are now examining. The intersection of two sets is calculated by the& operator (in this case, replacing the left-hand side directly, hence the&= variant). The result of the intersection will be that we have a set of topic IDs of topics that contain all words examined so far.
If the resulting set contains any IDs at all, these are converted to Topic instances to yield their title attribute.