
At this point of time, our minds got enlightened with all sorts of clues to scrape the Web. With all the information acquired, let's look at a practical example. Now, we will create a web scraping bot, which will pull a list of words from a web resource and store them in a JSON file.
Let's turn on the scraping mode!
Here, the web scraping bot is an automated script that has the capability to extract words from a website named majortests.com. This website consists of various tests and Graduate Record Examinations (GRE) word lists. With this web scraping bot, we will scrape the previously mentioned website and create a list of GRE words and their meanings in a JSON file.
The following image is the sample page of the website that we are going to scrape:
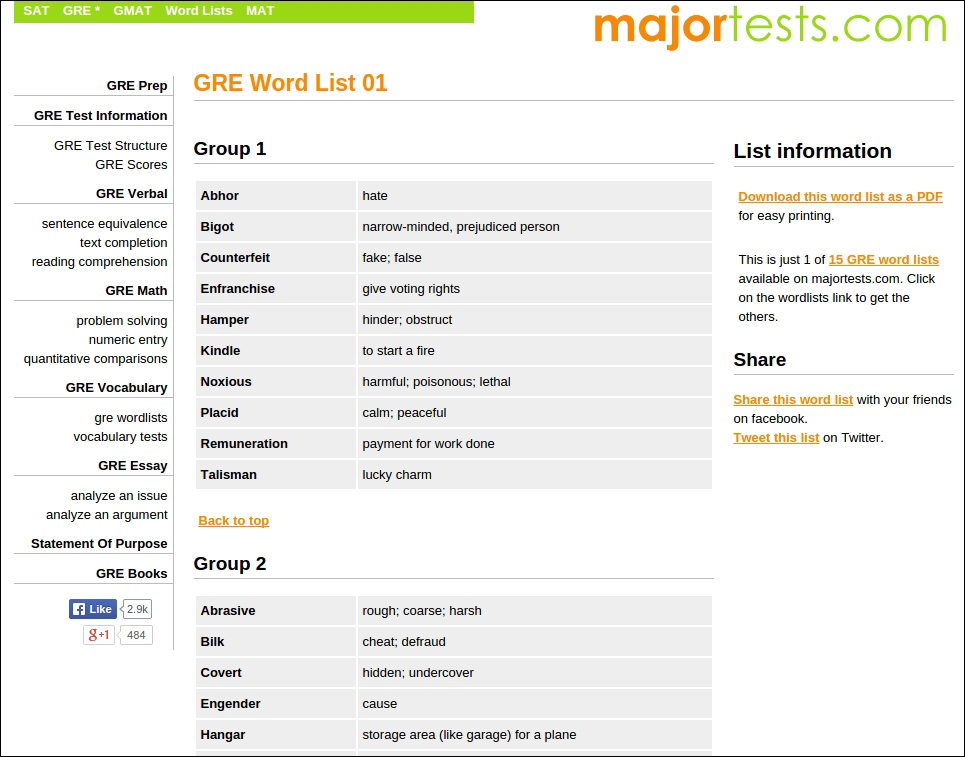
Before we kick start the scraping process, let's revise the dos and don't of web scraping as mentioned in the initial part of the chapter. Believe it or not they will definitely leave us in peace:
- Do refer to the terms and conditions: Yes, before scraping majortests.com, refer to the terms and conditions of the site and obtain the necessary legal permissions to scrape it.
- Don't bombard the server with a lot of requests: Keeping this in mind, for every request that we are going to send to the website, a delay has been instilled using Python's
time.sleepfunction. - Do track the web resource from time to time: We ensured that the code runs perfectly with the website that is running on the server. Do check the site once before starting to scrape, so that it won't break the code. This can be made possible by running some unit tests, which conform to the structure we expected.
Now, let's start the implementation by following the steps to scrape that we discussed previously.
The first step in web scraping is to identify the URL or a list of URLs that will result in the required resources. In this case, our intent is to find all the URLs that result in the expected list of GRE words. The following is the list of the URLs of the sites that we are going to scrape:
http://www.majortests.com/gre/wordlist_01,
http://www.majortests.com/gre/wordlist_02,
http://www.majortests.com/gre/wordlist_03, and so on
Our aim is to scrape words from nine such URLs, for which we found a common pattern. This will help us to crawl all of them. The common URL pattern for all those URLs is written using Python's string object, as follows:
http://www.majortests.com/gre/wordlist_0%d
In our implementation, we defined a method called generate_urls, which will generate the required list of URLs using the preceding URL string. The following snippet demonstrates the process in a Python shell:
>>> START_PAGE, END_PAGE = 1, 10 >>> URL = "http://www.majortests.com/gre/wordlist_0%d" >>> def generate_urls(url, start_page, end_page): ... urls = [] ... for page in range(start_page, end_page): ... urls.append(url % page) ... return urls ... >>> generate_urls(URL, START_PAGE, END_PAGE) ['http://www.majortests.com/gre/wordlist_01', 'http://www.majortests.com/gre/wordlist_02', 'http://www.majortests.com/gre/wordlist_03', 'http://www.majortests.com/gre/wordlist_04', 'http://www.majortests.com/gre/wordlist_05', 'http://www.majortests.com/gre/wordlist_06', 'http://www.majortests.com/gre/wordlist_07', 'http://www.majortests.com/gre/wordlist_08', 'http://www.majortests.com/gre/wordlist_09']
We will use the requests module as an HTTP client to get the web resources:
>>> import requests >>> def get_resource(url): ... return requests.get(url) ... >>> get_resource("http://www.majortests.com/gre/wordlist_01") <Response [200]>
In the preceding code, the get_resource function takes url as an argument and uses the requests module to get the resource.
Now, it is time to analyze and classify the contents of the web page. The content in this context is a list of words with their definitions. In order to identify the elements of the words and their definitions, we used Chrome DevTools. The perceived information of the elements (HTML elements) can help us to identify the word and its definition, which can be used in the process of scraping.
To carry this out open the URL (http://www.majortests.com/gre/wordlist_01) in the Chrome browser and access the Inspect element option by right-clicking on the web page:
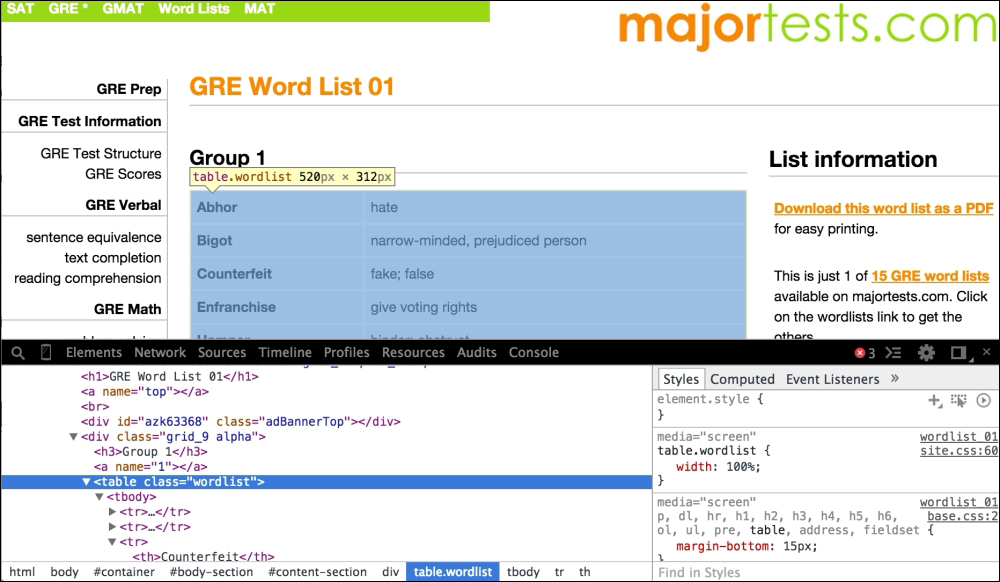
From the preceding image, we can identify the structure of the word list, which appears in the following manner:
<div class="grid_9 alpha">
<h3>Group 1</h3>
<a name="1"></a>
<table class="wordlist">
<tbody>
<tr>
<th>Abhor</th>
<td>hate</td>
</tr>
<tr>
<th>Bigot</th>
<td>narrow-minded, prejudiced person</td>
</tr>
...
...
</tbody>
</table>
</div>By looking at the parts of the previously referred to web page, we can interpret the following:
- Each web page consists of a word list
- Every word list has many word groups that are defined in the same
divtag - All the words in a word group are described in a table having the class attribute—
wordlist - Each and every table row (
tr) in the table represents a word and its definition using thethandtdtags, respectively
Let's use BeautifulSoup4 as a web scraping tool to parse the obtained web page contents that we received using the requests module in one of the previous steps. By following the preceding interpretations, we can direct BeautifulSoup to access the required content of the web page and deliver it as an object:
def make_soup(html_string):
return BeautifulSoup(html_string)In the preceding lines of code, the make_soup method takes the html content in the form of a string and returns a BeautifulSoup object.
The BeautifulSoup object that we obtained in the previous step is used to extract the required words and their definitions from it. Now, with the methods available in the BeautifulSoup object, we can navigate through the obtained HTML response, and then we can extract the list of words and their definitions:
def get_words_from_soup(soup):
words = {}
for count, wordlist_table in enumerate(
soup.find_all(class_='wordlist')):
title = "Group %d" % (count + 1)
new_words = {}
for word_entry in wordlist_table.find_all('tr'):
new_words[word_entry.th.text] = word_entry.td.text
words[title] = new_words
return wordsIn the preceding lines of code, get_words_from_soup takes a BeautifulSoup object and then looks for all the words contained in the wordlists class using the instance's find_all() method, and then returns a dictionary of words.
The dictionary of words obtained previously will be saved in a JSON file using the following helper method:
def save_as_json(data, output_file):
""" Writes the given data into the specified output file"""
with open(output_file, 'w') as outfile:
json.dump(data, outfile)On the whole, the process can be depicted in the following program:
import json
import time
import requests
from bs4 import BeautifulSoup
START_PAGE, END_PAGE, OUTPUT_FILE = 1, 10, 'words.json'
# Identify the URL
URL = "http://www.majortests.com/gre/wordlist_0%d"
def generate_urls(url, start_page, end_page):
"""
This method takes a 'url' and returns a generated list of url strings
params: a 'url', 'start_page' number and 'end_page' number
return value: a list of generated url strings
"""
urls = []
for page in range(start_page, end_page):
urls.append(url % page)
return urls
def get_resource(url):
"""
This method takes a 'url' and returns a 'requests.Response' object
params: a 'url'
return value: a 'requests.Response' object
"""
return requests.get(url)
def make_soup(html_string):
"""
This method takes a 'html string' and returns a 'BeautifulSoup' object
params: html page contents as a string
return value: a 'BeautifulSoup' object
"""
return BeautifulSoup(html_string)
def get_words_from_soup(soup):
"""
This method extracts word groups from a given 'BeautifulSoup' object
params: a BeautifulSoup object to extract data
return value: a dictionary of extracted word groups
"""
words = {}
count = 0
for wordlist_table in soup.find_all(class_='wordlist'):
count += 1
title = "Group %d" % count
new_words = {}
for word_entry in wordlist_table.find_all('tr'):
new_words[word_entry.th.text] = word_entry.td.text
words[title] = new_words
print " - - Extracted words from %s" % title
return words
def save_as_json(data, output_file):
""" Writes the given data into the specified output file"""
json.dump(data, open(output_file, 'w'))
def scrapper_bot(urls):
"""
Scrapper bot:
params: takes a list of urls
return value: a dictionary of word lists containing
different word groups
"""
gre_words = {}
for url in urls:
print "Scrapping %s" % url.split('/')[-1]
# step 1
# get a 'url'
# step 2
html = requets.get(url)
# step 3
# identify the desired pieces of data in the url using Browser tools
#step 4
soup = make_soup(html.text)
# step 5
words = get_words_from_soup(soup)
gre_words[url.split('/')[-1]] = words
print "sleeping for 5 seconds now"
time.sleep(5)
return gre_words
if __name__ == '__main__':
urls = generate_urls(URL, START_PAGE, END_PAGE+1)
gre_words = scrapper_bot(urls)
save_as_json(gre_words, OUTPUT_FILE)Here is the content of the words.json file:
{"wordlist_04":
{"Group 10":
{"Devoured": "greedily eaten/consumed",
"Magnate": "powerful businessman",
"Cavalcade": "procession of vehicles",
"Extradite": "deport from one country back to the home...
.
.
.
}