
Key points
• Linear correlation, linear regression, and ANOVA are variations of the General Linear Model.
• Use correlation to assess the extent to which two variables are related or independent (and be sure to graph the relationship).
• Guidelines for interpreting the magnitude of correlations are: small (r = 0.10), medium (r = 0.30), and large (r = 0.50).
• Correlation alone does not prove causation.
• For binary data, use phi correlation.
• Use linear regression to model the relationship between two variables.
• Be cautious when using a regression equation to extrapolate (estimate beyond the ends of the observed values).
• To compare more than two means, use a one-way ANOVA combined with multiple comparisons.
• If there is a need to adjust thresholds of significance for multiple comparisons, we recommend the Benjamini–Hochberg procedure due to its placement between liberal (unadjusted) and conservative (Bonferroni) approaches, but keep in mind that there is no single correct method for all situations.
• To assess the results of a factorial study, use a two-way ANOVA to evaluate the main effects of the independent variables and their interactions.
• Follow up tests of significance of correlations, regression, and ANOVA with confidence intervals and, if necessary, use sample size estimation to achieve specified levels of precision.
• See Table 10.16 for the list of formulas from this chapter.
Table 10.16
List of Formulas from the Chapter
| Type of Evaluation | Basic Formula | Notes |
| Correlation (r) |

|
Where
|
| Significance of r (transform r to t) |

|
Use this to conduct a test of significance of r with df = n − 2 |
| r to z′ |
|
This is a step in the process of computing a confidence interval for r |
| Margin of error for r |

|
This is a step in the process of computing a confidence interval for r (used to set bounds around z′) |
| z′ endpoints back to r |

|
This is a step in the process of computing a confidence interval for r |
| Sample size estimation for r |

|
Decide the level of confidence (for 95% confidence z = 1.96), the size of the critical difference (also known as the margin of error, d in the equation) and the expected value of r (if you have no idea what to expect, then set r to 0 to maximize the estimated sample size) |
| Phi (ϕ) |

|
The letters a, b, c, and d refer to cells in a 2 × 2 contingency table |
| Phi to chi-squared (Significance of ϕ) | χ2(1) = nϕ2 | Use this to conduct a test of significance using χ2 with df = 1 |
| General form of regression equation |
|
Shows prediction of dependent variable
|
| Regression slope |

|
r is the correlation between X and Y, and sx and sy are the standard deviations of the x-and y-values |
| Regression intercept |
|
|
| Standard error of regression slope |

|
yi
is the value of the dependent variable for observation i, ŷi
is the estimated value of the dependent variable for observation i, xi
is the observed value of the independent variable for observation i,
|
| Standard error of predicted value |

|
yi
is the value of the dependent variable for observation i, ŷi
is the estimated value of the dependent variable for observation i, xi
is the observed value of the independent variable for observation i,
|
| Sample size estimation based on the slope |

|
You need an estimate of the population variability of x
|
| Sample size estimation based on the intercept |

|
You need an estimate of the population variability of x
|
| ANOVA SSTotal |

|
The df for the total SS are n − 1—the MS is the SS/df |
| ANOVA SSBetween |

|
The df for SSBetween are k − 1—the MS is the SS/df |
| ANOVA SSWithin |
|
The df for SSWithin are n − k— the MS is the SS/df |
| ANOVA SSMainEffect |
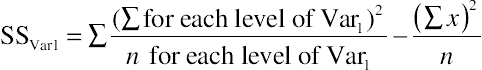
|
The df for a main effect are the number of levels of the variable minus 1—the MS is the SS/df |
| ANOVA SSInteraction |
|
This is for two independent variables—to compute interaction df multiply the df for the main effects |
| F-test |

|
To evaluate F you need to know the numerator and denominator df (df1 and df2)—for the designs presented in this chapter, MSError is the same as MSWithin |


Chapter review questions
1. Assume that you have concurrently collected data from ten usability studies for the SUS and a single-item measure of perceived effort (7-point scale with 1 = “No undue effort” and 7 = “Far too much effort”). Table 10.17 shows the means from the ten experiments. You think they’re probably correlated, but you’re not sure to what extent. For this question (a) calculate the correlation and assess its statistical significance, (b) then determine the 95% confidence interval around the estimated correlation, and (c) compute and interpret the coefficient of determination.
2. Based on the results from Question 1, you’ve decided that you’d like to establish a company-wide target for future usability tests that use the perceived effort item. It is common to set a target for the SUS to 80, which is an A- on the Sauro–Lewis curved grading scale (Table 8.5 in Chapter 8). For this question, (a) determine the regression equation that would allow prediction of Effort from SUS, (b) use the equation to compute the value of Effort that corresponds to a SUS of 80, and (c) compute the 90% confidence interval around that estimated Effort value.
3. Suppose you wanted to control your estimate of the appropriate Effort target to within 0.1. Given the results in (2) and continuing to use 90% confidence, what sample size (number of studies with concurrent collection of SUS and Effort) would you probably need?
4. Convert the values in Table 10.17 (shown in Question 1) to binary data where SUS scores greater than 79.9 are “1” and all others are 0, and Effort scores greater than 5.5 are “1” and all others are 0. Then compute phi to estimate the correlation between SUS and Effort and assess its statistical significance.
5. Suppose you have used a survey to collect SUS scores from respondents who have used a major hotel website or mobile app to book a reservation, with the results shown in Table 10.18. Does the omnibus F-test for a one-way ANOVA indicate that at least one of the means is different from the others? Which one(s)?
6. Continuing to use the data from Question 5, switch to a two-way ANOVA to assess the main effects of Company (A vs. B) and Channel (website vs. mobile app) and their interaction. Interpret the results.
Table 10.17
Data for Review Question 1
| Experiment | SUS | Effort |
| 1 | 68.1 | 4.0 |
| 2 | 50.0 | 4.2 |
| 3 | 70.8 | 4.0 |
| 4 | 85.2 | 6.4 |
| 5 | 92.4 | 6.6 |
| 6 | 69.9 | 3.9 |
| 7 | 45.7 | 3.5 |
| 8 | 82.3 | 6.2 |
| 9 | 78.6 | 5.8 |
| 10 | 55.5 | 4.0 |
Table 10.18
Data for Review Question 5
| Company A (website) | Company A (mobile) | Company B (website) | Company B (mobile) |
| 72.5 | 62.5 | 82.5 | 100.0 |
| 85.0 | 72.5 | 72.5 | 80.0 |
| 70.0 | 77.5 | 87.5 | 90.0 |
| 80.0 | 57.5 | 70.0 | 80.0 |
| 60.0 | 82.5 | 80.0 | 85.0 |
| 80.0 | 50.0 | 75.0 | 80.0 |
| 80.0 | 67.5 | 97.5 | 92.5 |
| 85.0 | 70.0 | 57.5 | 75.0 |
| 65.0 | 52.5 | 70.0 | 100.0 |
| 75.0 | 82.5 | 85.0 | 77.5 |

Answers to chapter review questions
1. First, inspect a graph of the data to check for any clear nonlinear patterns. As shown in Fig. 10.11, there appears to be a strong linear component.

Figure 10.11 Scatterplot of hypothetical SUS and effort means
Table 10.19 shows the calculations needed to compute the correlation, its statistical significance, the 95% confidence interval, and the coefficient of determination. The linear correlation is statistically significant (r(8) = 0.858, p = 0.003). The 95% confidence interval ranges from 0.498 to 0.966. The coefficient of determination, R2, is 73.7%, suggesting that variability in mean SUS accounts for much of the variability in mean Effort, but with about 27.3% of variability left unexplained (either due to error, the effect of some other variable(s), or systematic nonlinear components).
Table 10.19
Calculations for Review Question 1
| Study | SUS | Effort | xi −x | yi −y | (xi −x)2 | (yi −y)2 | (xi −x)(yi −y) |
| 1 | 68.1 | 4.0 | −1.8 | −0.9 | 3.06 | 0.74 | 1.51 |
| 2 | 50.0 | 4.2 | −19.9 | −0.7 | 394.02 | 0.44 | 13.10 |
| 3 | 70.8 | 4.0 | 1.0 | −0.9 | 0.90 | 0.74 | −0.82 |
| 4 | 85.2 | 6.4 | 15.4 | 1.5 | 235.62 | 2.37 | 23.64 |
| 5 | 92.4 | 6.6 | 22.6 | 1.7 | 508.50 | 3.03 | 39.24 |
| 6 | 69.9 | 3.9 | 0.1 | −1.0 | 0.00 | 0.92 | −0.05 |
| 7 | 45.7 | 3.5 | −24.2 | −1.4 | 583.22 | 1.85 | 32.84 |
| 8 | 82.3 | 6.2 | 12.5 | 1.3 | 155.00 | 1.80 | 16.68 |
| 9 | 78.6 | 5.8 | 8.8 | 0.9 | 76.56 | 0.88 | 8.23 |
| 10 | 55.5 | 4.0 | −14.4 | −0.9 | 205.92 | 0.74 | 12.34 |
| Mean | 69.9 | 4.9 | |||||
| Std Dev | 15.5 | 1.2 | SS | 2162.83 | 13.50 | 146.71 | |
| r | 0.858 | ||||||
| t | 4.734 | ||||||
| df | 8 | ||||||
| p | 0.001 | ||||||
| R2 | 73.7% | ||||||
| z′ | 1.287 | ||||||
| d95 | 0.741 | ||||||
| z′ + d | 2.028 | ||||||
| z′−d | 0.547 | ||||||
| rUpper | 0.966 | ||||||
| rLower | 0.498 |

2. Table 10.20 shows the calculations needed to compute the regression slope and intercept for predicting Effort from SUS, which is Effort = 0.122 + 0.068(SUS). The predicted value for Effort after setting SUS to 80 is about 5.5. The 90% confidence interval around that predicted value ranges from 5.1 to 6.0.
Table 10.20
Calculations for Review Question 2
| Study | SUS | Effort |
|
|
|
| 1 | 68.1 | 4.0 | 4.75 | −0.75 | 0.57 |
| 2 | 50.0 | 4.2 | 3.52 | 0.68 | 0.46 |
| 3 | 70.8 | 4.0 | 4.94 | −0.94 | 0.88 |
| 4 | 85.2 | 6.4 | 5.92 | 0.48 | 0.23 |
| 5 | 92.4 | 6.6 | 6.41 | 0.19 | 0.04 |
| 6 | 69.9 | 3.9 | 4.88 | −0.98 | 0.95 |
| 7 | 45.7 | 3.5 | 3.23 | 0.27 | 0.07 |
| 8 | 82.3 | 6.2 | 5.72 | 0.48 | 0.23 |
| 9 | 78.6 | 5.8 | 5.47 | 0.33 | 0.11 |
| 10 | 55.5 | 4.0 | 3.90 | 0.10 | 0.01 |
| Mean | 69.9 | 4.9 | |||
| Std Dev | 15.5 | 1.2 | SS | 3.55 | |
| Slope | 0.068 | ||||
| Intercept | 0.122 | ||||
| EffortPred | 5.5 | ||||
| SE | 0.256 | ||||
| t.10 | 1.860 | ||||
| d | 0.476 | ||||
| EffortUpper | 6.0 | ||||
| EffortLower | 5.1 |

3. As shown in Table 10.21, if you want to control the estimate of Effort to within 0.1, assuming everything except the sample size stays the same, you’d need data from about 146 studies. You might need to learn to live with a bit more uncertainty.
Table 10.21
Calculations for Review Question 3
| Iteration | d | d 2 | t | df | t 2 |
|
|
varp(x) | varp(e) | n | Roundup |
| 1 | 0.1 | 0.01 | 1.645 | na | 2.706 | 69.9 | 103.02 | 216.283 | 0.355 | 143.89 | 144 |
| 2 | 0.1 | 0.01 | 1.656 | 142 | 2.741 | 69.9 | 103.02 | 216.283 | 0.355 | 145.76 | 146 |
| 3 | 0.1 | 0.01 | 1.656 | 144 | 2.741 | 69.9 | 103.02 | 216.283 | 0.355 | 145.73 | 146 |

4. Table 10.22 shows the conversion of the rating data to binary values based on whether the scores were above or below the targets discussed in Review Question 2. Table 10.23 shows the summary of the data in a 2 × 2 matrix. The resulting value of phi is a statistically significant 0.802 (χ2(1) = 6.43, p = 0.01).
Table 10.22
Binary Conversion of SUS and Effort
| Study | SUS | Effort |
| 1 | 0 | 0 |
| 2 | 0 | 0 |
| 3 | 0 | 0 |
| 4 | 1 | 1 |
| 5 | 1 | 1 |
| 6 | 0 | 0 |
| 7 | 0 | 0 |
| 8 | 1 | 1 |
| 9 | 0 | 1 |
| 10 | 0 | 0 |
Table 10.23
Table of Corresponding and Noncorresponding SUS and Effort Values
| SUS | ||
| Effort | 1 | 0 |
| 1 | 3 (a) | 1 (b) |
| 0 | 0 (c) | 6 (d) |



5. Table 10.24 shows the computations; Table 10.25 is the summary table. The significant F-test (F(3, 36) = 5.576, p = 0.003) indicates that at least one of the means is different from at least one of the other means. Table 10.26 shows the observed significance levels (p-values) for the six comparisons and, using α = 0.05, the results for multiple comparisons without adjustment, using the Benjamini–Hochberg adjustment, and using the Bonferroni adjustment (α/6 = 0.008). For the Benjamini–Hochberg method the p-values from the six comparisons were ranked from lowest to highest. The new statistical significance thresholds were created by dividing the rank by the number of comparisons and then multiplying this by alpha (0.05). For six comparisons, the lowest p-value (with a rank of 1) is compared against a new threshold of (1/6)*0.05 = 0.008, the second is compared against (2/6)*0.05 = 0.017, and so forth. Two comparisons were statistically significant without adjustment and when using the Benjamini–Hochberg method (A Mobile vs. B Mobile and A Web vs. B Mobile). Only one comparison (A Mobile vs. B Mobile) was significant when using the Bonferroni adjustment. There are other comparisons that also have relatively low values of p (all but A Web vs. B Web) that might bear consideration, especially for a researcher working in an industrial context in which Type II errors are as or more important than Type I errors.
Table 10.24
ANOVA Computations for Review Question 5
| Company A (website) | Company A (mobile) | Company B (website) | Company B (mobile) | ||
| 72.5 | 62.5 | 82.5 | 100.0 | ||
| 85.0 | 72.5 | 72.5 | 80.0 | ||
| 70.0 | 77.5 | 87.5 | 90.0 | ||
| 80.0 | 57.5 | 70.0 | 80.0 | ||
| 60.0 | 82.5 | 80.0 | 85.0 | ||
| 80.0 | 50.0 | 75.0 | 80.0 | ||
| 80.0 | 67.5 | 97.5 | 92.5 | ||
| 85.0 | 70.0 | 57.5 | 75.0 | ||
| 65.0 | 52.5 | 70.0 | 100.0 | ||
| 75.0 | 82.5 | 85.0 | 77.5 | ||
| Computed | Combined | ||||
| Mean | 76.63 | 75.25 | 67.50 | 77.75 | 86.00 |
| Sum(x) | 3065.0 | 752.5 | 675.0 | 777.5 | 860.0 |
| (Sum(x))2 | 9394225.0 | 566256.3 | 455625.0 | 604506.3 | 739600.0 |
| ((Sum(x))2)/n | 234855.63 | 56625.625 | 45562.5 | 60450.625 | 73960 |
| Sum(x2) | 240350.0 | 57256.3 | 46800.0 | 61581.3 | 74712.5 |
| n | 40 | 10 | 10 | 10 | 10 |

Table 10.25
ANOVA Summary Table for Review Question 5
| Source | SS | df | MS | F | Sig |
| Total | 5494.38 | 39 | 140.88 | ||
| Between | 1743.13 | 3 | 581.04 | 5.576 | 0.003 |
| Within | 3751.25 | 36 | 104.20 |

Table 10.26
Observed Significance Levels for the Six Comparisons
| Comparison | p-value | Rank | BH Threshold | Unadjusted Result | BH Result | Bonferroni Result |
| A Mobile versus B Mobile | 0.001 | 1 | 0.008 | Sig. | Sig. | Sig. |
| A Web versus B Mobile | 0.014 | 2 | 0.017 | Sig. | Sig. | |
| A Mobile versus B Web | 0.062 | 3 | 0.025 | |||
| B Web versus B Mobile | 0.089 | 4 | 0.033 | |||
| A Web versus A Mobile | 0.108 | 5 | 0.042 | |||
| A Web versus B Web | 0.58 | 6 | 0.05 |

6. The calculation of Total, Between, and Within SS is the same for one-way and two-way ANOVAs. Table 10.27 shows the additional computations needed for the two-way ANOVA to partition the SS Between into the SS for main effects and their interaction, Table 10.28 shows the resulting ANOVA summary, and Fig. 10.12 depicts the interaction. For this hypothetical study, the main effect of Company was significant (F(1,36) = 10.58, p = 0.002), the main effect of Channel was not (F(1, 36) = 0.01, p = 0.939), and they interacted significantly (F(1, 36) = 6.14, p = 0.018).
Table 10.27
Additional Computations for the Two-way ANOVA
| Computed | Company A | Company B | Website | Mobile |
| Sum | 1427.5 | 1637.5 | 1530.0 | 1535.0 |
| Sum-sq | 2037756.3 | 2681406.3 | 2340900.0 | 2356225.0 |
| n | 20 | 20 | 20 | 20 |
| (Sum-sq)/n | 101887.813 | 134070.3125 | 117045 | 117811.25 |

Table 10.28
ANOVA Summary Table for Review Question 6
| Source | SS | df | MS | F | Sig |
| Total | 5494.38 | 39 | 140.88 | ||
| Between | 1743.13 | 3 | 581.04 | ||
| Company | 1102.50 | 1 | 1102.50 | 10.58 | 0.002 |
| Channel | 0.63 | 1 | 0.63 | 0.01 | 0.939 |
| Interaction | 640.00 | 1 | 640.00 | 6.14 | 0.018 |
| Within | 3751.25 | 36 | 104.20 |


Figure 10.12 Graph of interaction for Review Question 6
When main effects do not interact, the interpretation of results focuses on the main effects. When their interaction is significant, the interaction becomes the focus of interpretation. Inspection of Fig. 10.12 shows that the Web experiences are about the same for the two companies, but the mobile experience for Company A is poorer than the mobile experience for Company B. To analyze the interaction, you could use an approach similar to that in the previous exercise, but with four rather than six comparisons, specifically, Company A Web versus Company A Mobile, Company B Web versus Company B Mobile, Company A Web versus Company B Web, and Company A Mobile versus Company B Mobile.
Table 10.29 shows the results of these multiple comparisons without adjustment (all using α = 0.05), with Benjamini–Hochberg adjustment, and with Bonferroni adjustment (0.05/4 = 0.013). For the Benjamini–Hochberg method, the p-values from the four comparisons were ranked from lowest to highest. The new statistical significance thresholds were created by dividing the rank by the number of comparisons and multiplying by alpha (0.05). For four comparisons, the lowest p-value, with a rank of 1 is compared against a new threshold of (1/4)*0.05 = 0.013 and so forth. In this example, all three methods (unadjusted, Benjamini–Hochberg, and Bonferroni) indicated that only the comparison of Company A Mobile versus Company B mobile was statistically significant.
Table 10.29
Analysis of Interaction for Review Question 6
| Comparison | p-value | Rank | BH Threshold | Unadjusted Result | BH Result | Bonferroni Result |
| A Mobile versus B Mobile | 0.001 | 1 | 0.013 | Sig. | Sig. | Sig. |
| B Web versus B Mobile | 0.089 | 2 | 0.025 | |||
| A Web versus A Mobile | 0.108 | 3 | 0.038 | |||
| A Web versus B Web | 0.58 | 4 | 0.050 |

Appendix: derivation of sample size formulas for regression
The purpose of this appendix is to document the derivation of the sample size formulas for regression given a focus on estimating the slope or estimating the intercept. If you have no interest in the math, just skip this appendix.
Based on confidence interval for regression slope

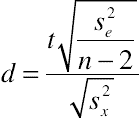




Based on confidence interval for regression intercept





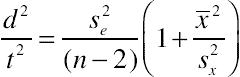




For sample size estimation other than the special case of the intercept, replace  with
with  . For the special case when
. For the special case when  , the formula simplifies to
, the formula simplifies to

..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.