
Chapter 6. Quarkus - reactive engine
In Part II we learned a lot about reactive, in all its forms, meanings, and variations! I know, you’re probably a bit tired of hearing the word reactive right now, but it’s a key piece to accurately describing Quarkus. At the core of Quarkus is its reactive engine, which we cover in “A reactive engine” later this chapter. Without its reactive engine core, Quarkus would not allow implementing reactive applications and provide a seamless integration of reactive programming.
Quarkus unifies two development models: imperative and reactive. In this chapter we will review the main differences, and how Quarkus handles the unification. Quarkus aims for them to be as alike as possible. If the APIs feel similar, understanding a complex model such as reactive becomes seamless.
Before we can get into the reactive engine, we need to revisit the imperative and reactive models. Doing so allows us an opportunity to appreciate how they’re unified with Quarkus. For anyone already familiar with imperative and reactive models, how they work, what are the benefits and disadvantages of each, feel free to skip ahead to “Unification of reactive and imperative”.
You might worry we’re repeating previously covered information. Maybe a little, but it’s all geared to reinforcing how the two models impact how applications are developed. And as a result, how frameworks differ depending on the model they offer.
First up is the imperative model, which most Java developers likely started their careers using.
The imperative model
When using the imperative model, you may not even be aware of its name. So what is the imperative model? The imperative model alters a programs’ state with a defined sequence of commands. One command executed after another until all commands are executed.

Figure 6-1. Imperative commands with result 10
In Figure 6-1 we have a sequence of mathematical commands, executed in succession, until the result, in this case 10 if we start from 0, is produced. As you can see in the imperative model, defining the proper sequence is critical to achieve the desired result, 10. Here are the exact same commands, but in a different sequence:

Figure 6-2. Imperative commands with result 7.5
As you see in Figure 6-2, the sequence of the commands, in the imperative mode, is just as important as the commands themselves. Modifying the sequence results in an entirely different program output. An imperative program can be considered to be the process of getting from A to B, where we already know what A and B need to be, it’s only the steps in between a developer needs to define in the correct sequence to achieve.
In imperative programs, we have a defined input and output, and, in addition, we know the steps needed in order to get from A to B. For these two reasons, imperative programs are easily reasoned about. When we have a defined input, what we know the output should be, and the defined steps to get there, writing tests is a lot easier because the permutations of what can happen are limited and determinable.
What are some other aspects to the imperative programming model we need to be aware of? As imperative relies on a sequence of commands, resource utilization will always be a primary concern. In the Figure 6-1 example earlier, we’re not going to need a large amount of resources to perform basic mathematical calculations. However, if we replaced all those operations with database calls retrieving a few hundred records each, the impacts begin adding up quickly.
The impacts we’re talking about are related to the threading model for imperative programming. If we have our sequence of database operations using a single I/O thread, the same I/O thread handling the HTTP request, not realistic but useful for illustrative purposes, only one request can be processed at any point in time. We introduced the I/O thread in Chapter 5. Moreover, as the sequence of the imperative program is fixed, each command must complete before the next one can commence. What does that look like?

Figure 6-3. Database program on single I/O thread
Though contrived, Figure 6-3 illustrates how each step in the database program must complete before the next can commence. More importantly, any subsequent request can only begin when the one being processed is finished. In this situation, the number of concurrent requests we can process is limited by the number of I/O threads we give the application. Now, as depicted in Figure 6-4, we will be generous and provide the same application two I/O threads!

Figure 6-4. Database program on multiple I/O threads
We can process two concurrent requests, but no more than that with only two I/O threads. Only being able to handle a single request per I/O thread is not great, let’s dive deeper into what’s going on inside.

Figure 6-5. Database program I/O thread delays
Both the Retrieve DB records and Write new DB records commands have periods of time when the command itself is not performing any work, shown as the lighter section in Figure 6-5. In between sending a request to the database and receiving the response, what is the I/O thread doing? In this situation, absolutely nothing! The I/O thread sits there waiting for the response from the database.
Why does it do nothing? Could an I/O thread perform other work while waiting? As we mentioned earlier, imperative programming requires an ordered sequence of commands, and as Retrieve DB records is still running during the wait period an I/O thread does not know there is time to perform other work. This is why imperative programming is often tied with synchronous execution, by default synchronous is the execution model for imperative programming.
Some might wonder whether an I/O thread waiting is a big deal or not. The time an I/O thread waits for a command to complete could be several seconds, or longer. An imperative program taking about a second to complete all its steps may be ok, but it doesn’t take many periods of I/O threads waiting to explode the total response time to many seconds.
The expanded time to complete an imperative program has several effects. Increased execution time on an I/O thread leads to a reduction in number of requests being processed in a given period of time. There are additional impacts on the resources required to buffer in memory any incoming requests that are waiting on I/O threads to become available to begin processing. These resource impacts can cause significant issues with the overall performance of an application. If an application is dealing with a few hundred, or even thousand, users it may not be noticeable, especially if very few are concurrent users. However, tens of thousands of users, many concurrently, will show these problems to their users in failed connections, timeouts, errors, and any number of possible problems.
There are other ways to break the synchronous and blocking nature of an imperative program,
whether it be with an ExecutorService to move work from the I/O thread onto a separate worker pool thread.
Or @Suspended and AsyncResponse with JAX-RS Resources to delegate work to a worker pool of threads,
enabling the HTTP request to be suspended from the I/O thread until a response is set on AsyncResponse.
Facilitating processing of additional HTTP requests on the I/O thread while others are waiting for a processing response.
Though these approaches work,
the complexity of code increases without a significant benefit in throughput as we’re still I/O thread limited.
Not quite to the level of a request per thread when using @Suspended, but not significantly more either.
How does the reactive model differ?
The reactive model
The reactive model is built around the notion of continuations and non-blocking I/O, as we detailed in “Asynchronous code and patterns”. As mentioned previously, this approach significantly increases the level of concurrency, enabling many more requests to be processed in parallel. However, it’s not a free ride because it requires additional thought on the part of a developer to develop an application built around these principles.
Taking our previous database example, what would it look like to remove the I/O thread wait times to improve the concurrency?
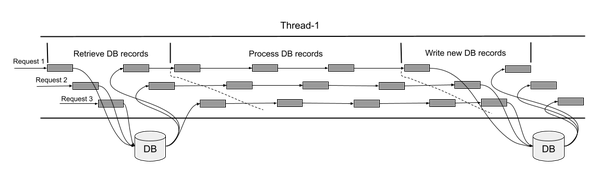
Figure 6-6. Reactive database program on I/O thread
In Figure 6-6, we can see instead of an I/O thread waiting, it begins processing another incoming request. Continuing to do so until it’s been notified a database response is ready for processing. How do we achieve this separation? We provide a continuation to process the database response. The continuation is added to the queue of methods to execute on the I/O thread once the database response is received. Likewise, the single command to process the database records is split into smaller methods to help with the concurrency.
Figure 6-6 shows how a reactive model utilizing continuations can facilitate the removal of I/O thread wait time and increase the number of requests processed concurrently. As we saw, we developers need to adjust how programs are developed to align with the reactive model. Breaking down work into smaller chunks, but most importantly, modifying interactions with anything external to the application into separate request and response handling.
Earlier in Figure 6-6 we approximated how pieces of a program could be segmented to prevent the I/O thread from waiting, or being blocked. Quarkus uses an event loop, as discussed in “Reactor pattern and event loop”, to implement the reactive model. The event loop can visually be represented as we saw in Figure 4-7.
We’ve discussed some hugely beneficial aspects of the reactive model, but nothing comes for free. With the reactive model needing to separate code execution, as opposed to the imperative model where everything is sequential, complexity is introduced in the ability to understand the entirety of a program.
A program is no longer a sequenced set of steps, but a series of handlers executing at different points in time with no pre-determined order. Though continuations can be guaranteed to occur after they were triggered, there is no ordering between different asynchronous invocations within a single request, or between multiple requests. This shift requires an alteration in thinking by developers towards event passing, with the triggering of associated event handlers. No longer is it a sequence of commands called one after another in code.
Unification of reactive and imperative
What do we mean by Quarkus unifying reactive and imperative?
We don’t mean being able to ignore the complexities of reactive, or expecting imperative to provide high levels of concurrency. We do mean:
-
Quarkus’ reactive core non-blocking I/O is key to any extension built on top.
-
Offers a framework of extensions built on the performance of the Eclipse Vert.x toolkit, the reactive engine.
-
A developers choice of imperative or reactive is an API choice, and not a framework one.
Often when choosing to develop an application, an up-front choice needs to be made whether to use reactive or imperative programming. This decision requires much forethought by developers and architects in terms of the skills required by the team building the application, current business requirements for the application, but also the final architecture of an application. We developers find choosing a specific technology stack one of the most difficult choices to make. We always want to consider the future needs of the application, even if we don’t know what those needs are concretely. No matter how we try, there will always be new requirements, or unforeseen problems, requiring a change in architecture, or even design.
We feel more comfortable about a decision when it doesn’t box us in, offering ways to shift and alter how an application works as needs change. This is a huge advantage with Quarkus. When we choose Quarkus, and the unification of imperative and reactive models, we’re free to pick one or the other, a mix of the two, or even switch parts of an application between the models over time.
How does Quarkus support reactive or imperative models seamlessly? is the key foundation to everything Quarkus offers. Built on the foundation of Vert.x, Quarkus has a routing layer enabling either model. This is how the layers work together when we’ve deployed reactive code, assuming an HTTP request is being processed (Figure 6-7).
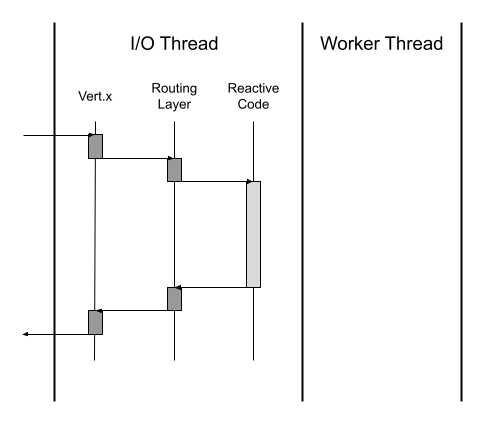
Figure 6-7. Quarkus reactive model
We see in Figure 6-7 how a request is received by the Vert.x HTTP server, passes through the routing layer, and our reactive code executes. All these interactions occur on the I/O thread, a worker thread is not needed. As already mentioned, having code execute on the I/O thread provides the highest level of concurrency.
Note
In Figure 6-7, we only have a single HTTP request being processed. If there were multiple requests, those executions would be interleaved on the I/O thread.
You might be wondering how executing imperative code alters the behavior?
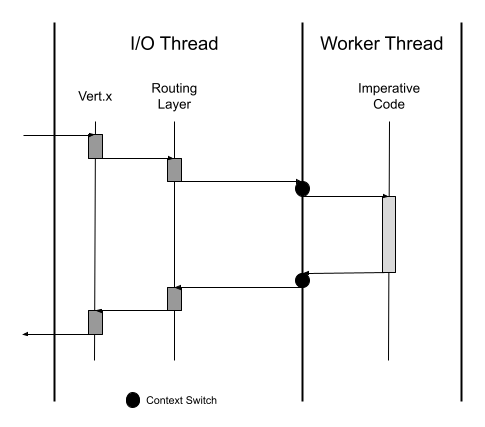
Figure 6-8. Quarkus imperative model
We see in Figure 6-8 the model is not significantly different. The biggest change is our code, now imperative in nature, is executed on a worker thread and not the I/O thread. In this way Quarkus can execute imperative code, a series of sequential commands, without impacting the concurrency of the I/O thread. Quarkus has off-loaded the imperative execution to a worker.
The process of off loading to a worker thread comes with a cost, however. Every time we execute on a worker thread, a context switch, before and after execution, is necessary. In Figure 6-8, we represent this switch as a circle on the boundary between the I/O and worker threads. These context switches cost time and resources to perform the switch and store the information in a new thread.
We’ve seen how the two models operate on Quarkus, but what about when we unify them? For example, if we have a reactive application needing to execute a piece of blocking code. How can we do it without blocking the I/O thread?

Figure 6-9. Quarkus reactive and imperative model
In Figure 6-9, we see our code executing on both the I/O and worker threads!
When reactive code is executed,
it’s on the I/O thread,
but any imperative code is executed on a worker thread.
Quarkus handles all of this for developers without them needing to create Executors or Threads,
and the need to manage them.
Figure 6-9 is a visualization of the proactor pattern we defined in “Reactor pattern and event loop”. Non-blocking and blocking handlers can co-exist, as long as we offload blocking execution onto worker threads and invoking continuations when a blocking handler completes.
The proactor pattern unifies imperative and reactive code in Quarkus.
Anyone familiar with developing reactive applications knows there are times when it’s necessary
to write code in a blocking, or sequential, manner.
Quarkus’ unification allows us to delegate such execution onto a worker thread,
by using @Blocking which we cover for HTTP in Chapter 8 and Reactive Messaging in Chapter 10.
Utilizing the reactive model, and thus the I/O thread, for as much work as is possible has an added benefit. We minimize the amount of context switching performed when delegating execution to a worker thread. Any time execution of the same request moves between threads, from the I/O to worker thread, or vice-versa, there are costs associated with the switch. Any objects associated with the request need to be available from the new thread, costing time and resources to move them, but also in the resource costs of additional threads.
We’ve talked a lot about how the models are unified in Quarkus, but what extensions use these models? RESTEasy Reactive, covered in Chapter 8, and Reactive Messaging, in Chapter 10, both utilize the reactive model. The classic RESTEasy and Spring controller both use the imperative model.
A reactive engine
If you have written reactive programs, or done any research into reactive, it’s likely you are aware of the Vert.x toolkit. As mentioned before, Quarkus reactive engine utilizes Vert.x.
In addition to Vert.x, and also Netty, the routing layer of Quarkus forms the outer layer of the reactive engine. It’s the integration piece for extensions, coordinating the offloading of blocking handlers onto worker threads, and the execution of their continuations.
In addition, all the reactive clients are built on top of the reactive engine to utilize the non-blocking handling. Reactive applications are no longer reactive once they use blocking clients, a key aspect often overlooked by developers. Quarkus endeavors to have all clients an application might need built on the reactive engine, for true reactive integration.
Note
By default, everything in Quarkus is reactive. Developers must decide whether they want reactive or imperative. What do we mean by everything? It includes HTTP handling, event-driven applications with AMQP and Kafka, everything Quarkus offers.
A reactive programming model
SmallRye Mutiny is the reactive programming library of Quarkus. We’ve already learned about it in “Reactive Programming”, and we will learn even more in chapter Chapter 7, so we won’t cover too much detail here.
In short, Mutiny is built around three key aspects:
-
Event-driven - listening to events and handling them
-
Easily navigable API - navigating the API is driven by an event type, and the available options for that event
-
Only two types -
MultiandUnican handle any desired asynchronous actions
One point to note is the laziness of the Mutiny types. Events won’t begin flowing through the data streams until a subscriber requests them. This is a fantastic feature to prevent streams from consuming resources if nothing is listening, but developers do need to be aware of this, so we don’t forget to subscribe!
All Quarkus reactive APIs uses Multi and Uni.
This approach facilitates the seamless integration of Quarkus extensions with reactive programming and Mutiny.
Let’s see examples of using Mutiny.
A reactive application with Quarkus using the postgreSQL reactive client retrieves Fruits from
the database with Multi:
Example 6-1. Reactive Mutiny client
client.query("SELECT id, name FROM fruits ORDER BY name ASC").execute()  .onItem().transformToMulti(rowSet -> Multi.createFrom().iterable(rowSet))
.onItem().transformToMulti(rowSet -> Multi.createFrom().iterable(rowSet))  .onItem().transform(row -> convertRowToFruit(row));
.onItem().transform(row -> convertRowToFruit(row)); 
clientis an instance ofPgPool, the postgreSQL reactive client built with Mutiny and Vert.xWhen an item is received, the
RowSetof data received, transform the singleRowSetinto aMulti<Row>.For each
Rowin theMulti, convert it to aFruitinstance. The result of the execution is aMulti<Fruit>.
Given we’re writing about reactive in this book, all the remaining chapters will have examples utilizing Mutiny in many situations. We will present reactive HTTP endpoints in Chapter 8 and their consumption in Chapter 12. We will cover reactive data access with Quarkus and Mutiny in Chapter 9, including many examples.
Event-driven architecture with Quarkus
Though building reactive applications with Quarkus is great, performant, and also fun, we want to do more than build a single application. We need a reactive system, as covered in Chapter 4, combining smaller applications into a coordinated distributed system.
To support such an architecture, Quarkus must receive and produce events, an event-driven architecture! Quarkus achieves this by using reactive messaging. Reactive messaging integrates with various messaging technologies, such as Apache Kafka, AMQP, and others, with annotations for developers to specify whether a method receives or produces events.
Example 6-2. Reactive Messaging
@Incoming("prices")
@Outgoing("quotes")
public Quote generatePrice(Price p) {
return new Quote(p, "USD");
}
Read messages from the
priceschannelTransform each
Priceinto aQuote
The offered development model allows consuming, transforming and generating messages easily.
The @Incoming annotation denotes the consumption of a channel.
Reactive messaging invokes the method for each transiting Price from the configured channel.
The @Outgoing annotation indicates in which channel the results are written.
Full details of reactive messaging will be in a later chapter, Chapter 10.
Summary
This chapter covered the imperative model, a series of sequential commands, and the reactive model, utilizing continuations and non-blocking I/O.
We have seen:
-
how the two models work with threads with Figure 6-8, Figure 6-7, and Figure 6-9, highlighting the improved concurrency with the reactive model,
-
how Quarkus unifies these models to allow developers to grow their applications, introducing reactive aspects, as it grows and expands without the need to switch frameworks.
-
how to use reactive programming in Quarkus.
In the coming chapters we explore the various reactive aspects of Quarkus, such as HTTP and RESTEasy Reactive in Chapter 8, and reactive data access in Chapter 9.
But first, let’s have a deeper look to the Mutiny reactive programming API.