
Chapter 2: Why Rematch over Redux? An Introduction to Rematch Architecture
In this chapter, we'll briefly analyze the reasons why Rematch was created. We'll also see how Rematch works internally and how it's possible to reduce Redux boilerplate with Rematch. We'll learn how Rematch, despite being less than 2 kilobytes in size, can reduce the code that we need to set up Redux by 90%.
This chapter is important for understanding the key concepts of Rematch that we'll be looking at in the next few chapters.
In this chapter, we will cover the following topics:
- Why Rematch?
- How does Rematch work?
By the end of this chapter, you will be able to understand any Rematch concept as well as understand why Rematch was created and how the developer experience gets improved by using the latest JavaScript features.
Technical requirements
To follow along with this chapter, all you will need is a basic knowledge of ES6 JavaScript.
Why Rematch?
Rematch was created in 2017 by Shawn McKay and Blair Bodnar, a pair of Canadian programmers who thought that Redux should be simpler and easier to use.
As McKay said in several publications, Rematch is a wrapper around Redux that provides a simpler API, without losing any of the configurability that Redux offers.
We saw in the previous chapter that Redux has a steep learning curve compared to a simple component local state because it includes so much new terminology and so many features that don't exist in other development suites.
As regards Redux, we can use this formula to easily understand why an abstraction layer is necessary:
Figure 2.1 – Formula to calculate the quality of our API for managing state
time_saved represents the time you may have spent developing your own state management solution, while time_invested is the hours invested in reading documentation, watching tutorials, and researching unfamiliar terminologies and different concepts.
quality_of_api is calculated by dividing time_saved by time_invested. We can easily see that with Redux, we will spend a lot of time learning unfamiliar terminologies, new libraries, and new standards for operating with Redux, so we will end up with a poor quality project code base. The time we could save by using Redux instead of creating our own state management solution actually gets lost because of the time that needs to be invested in learning new technologies. That's the main reason to consider Rematch as a wrapper around Redux.
We understand that the main purpose of any library is to make something complicated seem simple through abstraction, that is, hiding the underlying complexity through simpler functions – that's what Rematch does. With Rematch, we try to reduce time_invested to the smallest possible amount using a little abstraction layer.
Refactoring Redux is impossible because it's used by millions of developers; you can't justify introducing breaking changes that will affect all those users. That's another reason to build something around Redux instead of modifying the Redux code base internally.
Here are some topics that we found complex when configuring a simple hypothetical to-do app with Redux.
Setting up a store
In a real-world application using Redux, the application can become unmaintainable pretty fast because of the need to "Redux Thunk" asynchronous actions.
For practically 90% of the ideas we will come up with when building an application, we need to consume data from external services. They aren't static because we always need dynamism in our websites, for instance, calling an API to recover data or save modification of this data in a database. When this requirement is met, a plain Redux store has limited capabilities. It can only handle the dispatching of basic actions, and provides no built-in capabilities for doing asynchronous logic.
Redux stores are configurable, and it's normal to add several additional configuration options for common use cases. Typically, a Redux store is configured to add middleware for async logic and enable or disable the Redux DevTools for debugging. Unfortunately, the configuration process usually takes several steps.
For this reason, you'll need to set up the following:
- Middleware: Provides a third-party extension point between the dispatch of an action and the moment it reaches the reducer.
- Composing: A tool included in Redux to produce a single function from multiple functions.
We can avoid chaining functions like this:
func1(func2(func3(func4()))
Instead, we can use the compose() method to produce the same result:
compose(func1, func2, func3, func4)
These two lines of code are equivalent; only the syntax differs.
All this does is let you write deeply nested function transformations without any rightward drift of the code. Its intention is to help you to do things easier, but it just means more terminology to know and more code to maintain.
In Rematch, these concepts are no longer required to start a real application and are resolved internally in a modern way. The Redux Toolkit package simplifies the typical setup process down to just a function, like Rematch does, which is why these examples are based on the old Redux that has been there for a long time.
We'll learn all the required concepts to start a new application with Rematch or migrate an old Redux code base to Rematch.
To explain, here is an example of a real Redux store:
import { createStore, applyMiddleware, compose } from Redux
import thunk from "redux-thunk"
import api from "../middlewares/api"
import rootReducer from "../reducers"
import devTools from "../containers/DevTools"
const store = (preloadedState) => createStore(
rootReducer,
preloadedState,
compose(
applyMiddleware(
thunk,
api
),
devTools.instrument()
),
)
This code is a demonstration of how Redux becomes complex and introduces so much code just for storing data, even for simple applications. We need to use three different imports (compose, applyMiddleware, and thunk) for handling asynchronous operations, and this is just for initializing the store.
In Rematch, we simplify the previous setup to this:
import { init } from "@rematch/core"
import models from "./models"
const store = init({
redux: { initialState: { } },
models,
})
As you can see, Rematch handles all the complex things required to start developing your application.
Reducers
Reducers in Redux usually, and not always, contain a switch for routing the action type, which becomes larger and larger when our application starts to grow.
Redux itself doesn't care what control flow logic you use inside a reducer. You could use an if/else statement, lookup tables, or whatever you want. In Rematch, we try to simplify this decision to just keep the reducers as simple as possible, just an object with reducers that accepts state as the first parameter and payload as the second. The state is automatically filled by Rematch, so you don't have to worry about passing it to each reducer.
Here is an example of a Redux reducer:
const todoAppReducer = (state = { tasks: [] } action) => {
switch (action.type) {
case 'ADD_TODO_TASK':
return {
...state,
tasks: [
...state.tasks,
action.payload
]
}
default: return state
}
}
And here is an example of a Rematch reducer:
const todoAppReducer = {
ADD_TODO_TASK: (state, action) => ({ ...state, tasks: [...state.tasks, action.payload] })
}
We can compare the two code blocks and see that we have improved our code base in three ways:
- We decreased the lines of code from 13 to 3 lines, a 125% variation. From this, you can imagine the massive improvements that Rematch can make to a really complex Redux application.
- By reducing the amount of code, we increased its legibility, and when using the latest ES6 features, you will find that Rematch is easier to read and understand.
- Moving from action.type and a switch statement to just having keys inside an object makes everything easier (from refactoring the code to testing it).
In Rematch, reducers are just pure functions with two arguments – the state and an optional payload – and must always return a new state reference.
With this concept clear, we can jump into asynchronous operations. We'll learn how Rematch handles async operations without the need to use external libraries, as well as looking at the best ES6 techniques.
Async/await over Redux Thunk
Thunks are used to create asynchronous actions in Redux. In many ways, a Thunk seems more like a workaround hack than an official solution:
- You dispatch an action, which is actually a function rather than the expected object.
- The Thunk middleware checks every action to see whether it is a function.
- If so, the middleware calls the function and passes access to some store methods, such as dispatch and getState().
With ES2017, async/await was introduced, which is a special syntax to work with Promises in a more modern and easier way compared to ES5.
Rematch makes things a bit easier for writing these types of operations, Redux needs an outer function, called a thunk action creator. Rematch, instead, does this automatically for you when effects are created, so you can write just async/await inside the effects property and not worry about anything else.
This code is an example of an asynchronous request inside an outer function called saveNewTodo, in this way we're able to do the side-effect operation:
export function saveNewTodo(text) {
return async function saveNewTodoThunk(dispatch, getState) {
const initialTodo = { text }
const response = await client.post('/fakeApi/todos', { todo: initialTodo })
dispatch({ type: 'todos/todoAdded', payload: response.todo })
}
The problem with this code is the complexity of understanding why we need to wrap an async function with another function just to pass a text payload. Doing so is mandatory because Redux Thunk doesn't accept more arguments other than the async functions, so you need to wrap the async function with another function to finally pass the text argument.
Rematch solves this by extracting the dispatch parameter to an outside function:
const todos = {
effects: (dispatch) => ({
async saveNewTodo(text) {
const response = await client.post('/fakeApi/todos', { todo: text })
dispatch.todos.todoAdded(response.todo)
}
})
}
This Rematch code is equivalent to the Redux Thunk code, but this code is self-descriptive. You can see that we use the dispatch function that is filled automatically by Rematch as the first argument of the effects property and then we created an async function that accepts a text argument as a payload. Now you can begin to understand why Redux needed a wrapper and why Rematch performs complex operations much more smoothly.
Reducers and effects
When we think about actions that must happen in our application, there are two kinds of actions to consider:
- Reducers: Trigger a reducer and return a new state.
- Effects: Trigger async actions that could call a reducer to change the state.
Thinking about things in this way can be less confusing than using Redux Thunk. In Rematch, our models only contain states, reducers, and effects. If we need something more complex, we can use Rematch plugins.
Folder structure
Since Redux is just a state management solution, it has no direct opinion on how our projects should be structured. However, over time, we saw that many of the tutorials we could find on the internet chose the strategy of creating folders by type, and much of the actual code written with Redux is written like this.
With such a folder structure, we would end up changing code in the actions folder and forgetting to change the code in the reducers folder as well; that's why Rematch tries to encapsulate actions and reducers in the same file.
Nowadays, this is no longer the recommended technique and the Redux team has worked on teaching the ducks pattern. This pattern stipulates that reducers, action types, and actions should co-exist in a single file, something similar to what Rematch encourages.
Here's an example of a folder structure for a Redux to-do app:

Figure 2.2 – Redux folder structure
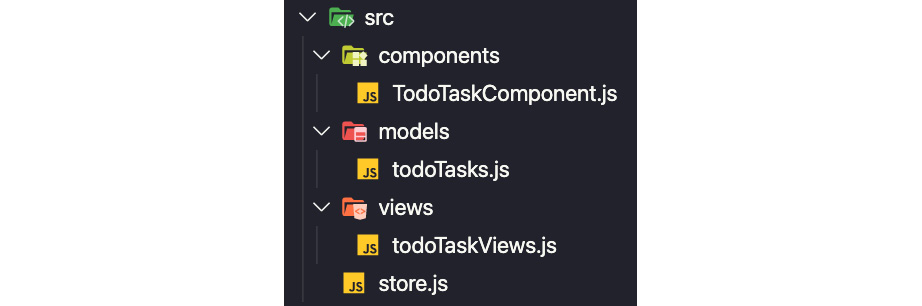
Figure 2.3 – Rematch folder structure
In summary, we have learned that writing Redux logic by hand requires extra work that isn't necessary, and an abstraction layer can help simplify that process. Rematch was designed to offer a simple and viable alternative to something complex that should have been simple.
In the next section, we'll analyze how Rematch works internally and the main concepts that you need to know about getting started with using it.
How does Rematch work?
Internally, Rematch is pretty simple. That's why calling it a framework isn't quite correct; it's just a higher layer without the Redux boilerplate.
Let's analyze Rematch in depth. In Figure 2.4, we introduce the Rematch model:

Figure 2.4 – Rematch architecture
Rematch models are among the most important parts of your store because they allow you to define the initial state of the model, the reducers, and the effects.
Any model is built on the basis of these properties:
Name
Models can contain a name that will become a key in the Redux store – this means that you will be able to access the state of a model or dispatch actions from a model using its name. Now, a name is not mandatory – if you don't provide a name, Rematch will use the object keys provided to the init() function instead.
The init() function returns a Rematch store, which is essentially a Redux store with a few additional properties and some extra features for doing certain things more easily.
Here is a mock example of the init() function:
import { init } from '@rematch/core'
const store = init({
name: 'my custom store name',
models: { example1, example2 },
plugins: [plugin1, plugin2],
redux: customReduxConfig,
})
init() functions accept four properties:
- name: We can name the store using this; this can be super useful when creating multiple stores for testing purposes.
- models: This is the property where we define the models that are going to be running inside our store. It's an object that contains models. If the model contains a name property, that will be the key; if not, the model name will be the object key.
- plugins: This is an array of functions that can extend the functionality of your store. We have several plugins developed by the Rematch team, plus an API for creating a new one (we'll analyze this in Chapter 9, Composable Plugins – Create Your First Plugin).
- redux: This is an object with which you can access the Redux API configuration. It is useful when migrating from complex Redux setups to Rematch as you can preserve your configurations inside this property.
With this clear, we return back to the model's schema:
export const todoModel = {
name: "todoModel",
}
We can overwrite the model's name using the name property inside our model object. Now, let's look at what every model must contain.
State
Every model must contain a state property, used primarily for defining the initial state of a model. In the following snippet, we introduce a state:
export const todoModel = {
name: "todoModelName",
state: {
tasks: [],
}
}
We are initializing this model with an empty array of tasks that could be filled, accessed, or cleared from our reducers.
Reducers
The reducers property is an object of n functions that change the model's state. These functions always have two parameters – the previous state and the payload – and must always return the model's next state.
These functions should be pure functions, as explained in the previous chapter. If we need to use async methods or some complex logic, we can use effects instead. The effects property of our model allows us to introduce side effects without any performance limitations or any bad practice.
Following on from the previous snippet, we can introduce some reducers:
export const todoModel = {
name: "todoModelName",
state: {
tasks: [],
},
reducers: {
ADD_TODO_TASK: (state, payload) => ({
...state,
tasks: [
...state.tasks,
payload
]
}),
REMOVE_TASK: (state, payload) => ({
...state,
tasks: state.tasks.filter((task) => task.id !== payload)
})
}
}
In this code snippet, we introduced two reducers:
- ADD_TODO_TASK: This is a pure function that returns the previous state with a new tasks array, with the new task that we passed in the payload parameter.
- REMOVE_TASK: This is a pure function returning the previous state, but that removes the desired task from the tasks state. For example, we could pass the ID of the task to remove as payload.
We can see that replacing the switch statements with simple functions inside an object called reducers simplifies reading and development. In the next section, we are going to see how effects work in a hypothetical example of recovering tasks from an external API.
Effects
The effects property is automatically filled with a dispatch parameter that could be used on any function that's inside our effects property to pass data to our reducers or to call other effects functions from other models.
Every function that appears in the scope of the effects property will be filled with two parameters:
- payload: Useful for passing extra arguments to this function; we will use it when we need to pass an ID for filtering or pass some data that isn't in our store.
- rootState: Contains the application state.
Effects have access to the whole state and all reducers; they allow us to handle impure functions with just async/await.
What if we need to recover some tasks from an external API? We must use effects because reducer functions should be kept as pure as possible.
Following the previous snippet, we will now introduce an effect for recovering a task from an external API:
export const todoModel = {
name: "todoModelName",
state: {
tasks: [],
},
reducers: {
ADD_TODO_TASK: (state, payload) => ({
...state,
tasks: [
...state.tasks,
payload
]
}),
REMOVE_TASK: (state, payload) => ({
...state,
tasks: state.tasks.filter((task) => task.id !== payload)
})
},
effects: (dispatch) => ({
async getONETask() {
const response = await fetch("http://local:3000/task/1")
const oneTask = await response.json()
dispatch.todoModelName.ADD_TODO_TASK(oneTask)
}
})
}
As you can see, we introduced an effects function property in our model that passes a dispatch parameter, filled with all the reducers and effects of our store. You can easily call other reducers, or other effects in other models, through this model name. Basically, Rematch creates a global structure where you can call any function of any model.
Imagine a scenario where there are three models with this structure:
const MODEL_ONE = {
state: 0,
reducers: {
increment: (state) => state + 1
}
}
const MODEL_TWO = {
state: 0,
reducers: {
decrement: (state) => state - 1
}
}
In this code, we're creating two Rematch models without effects, just with a state and a reducer function: one model for increasing the state value of MODEL_ONE, and the other for decreasing the state value of MODEL_TWO.
When Rematch is initialized, it automatically fills the dispatch parameter with access to any reducer or effect that is defined in our store models.
We could now create a third model with an effect calling the increment() reducer from MODEL_ONE and the decrement() reducer from MODEL_TWO:
const MODEL_THREE = {
state: 0,
effects: (dispatch) => ({
firstFn() {
dispatch.MODEL_ONE.increment()
dispatch.MODEL_TWO.decrement()
}
})
}
In this code, we're accessing the dispatch parameter and increasing the state value of MODEL_ONE, and decreasing the state value of MODEL_TWO directly from another model, in this case, MODEL_THREE.
When this effect is dispatched through the global dispatch of our store, we have the following:
Store.dispatch({ type: "MODEL_THREE/firstFn" })
In this code snippet, we're using a hypothetical scenario where our MODEL_THREE effect is initialized in our Redux store, so we can dispatch our MODEL_THREE effect called firstFn().
We can check that our state has changed to this:
{
"MODEL_ONE": 1
"MODEL_TWO": -1
"MODEL_THREE": 0
}
As we can see, the states of MODEL_ONE and MODEL_TWO changed correctly.
With all these concepts now clear, we can build anything from a small application to a big enterprise application.
Summary
In this chapter, we have learned about the main concepts that are required to start a simple application with Rematch. We also learned why Redux needs an abstraction layer and how Rematch entered the game to solve that problem.
Now that we've covered all these concepts, we can safely face the creation of our first application. We will learn how to create a simple Redux to-do application with vanilla JavaScript, for a future migration to Rematch.