
In Web 2.0, many sites aren’t just static pages anymore, or even static pages plus a few forms to fill out. They’re full-blown applications for data entry, word processing, calendar management, human resources, games, and anything else you can imagine. In this chapter, we focus on issues that specifically arise in improving such web applications.
Redesign unsafe operations so that they are accessed via POST rather than GET.
<a class="delete" href="article.php?action=delete&id=1000517&nonce=76a62" onclick="return deleteSomething('post', 1000517, 'You are about to delete this post "POST vs. GET". "OK" to delete, "Cancel" to stop.' );">Delete</a><form method="post" action="articles.php"> <input name="action" value="delete" type="hidden" /> <input name="id" value="1000517" type="hidden" /> <input name="nonce" value="76a62" type="hidden" /> <input type="submit" value="Delete" /> </form>
URLs accessed via GET can be and are spidered, prefetched, cached, repeated, and otherwise accessed automatically. Unsafe operations such as confirming a subscription, placing an order, agreeing to a contract, and deleting a page should be performed only via POST to avoid accidentally taking such actions without explicit user request and consent.
Browser users can only access POST functionality through HTML forms. They cannot simply follow a link. To be honest, this is a feature, not a bug. However, it does tend to restrict the formatting you can apply to an operation.
You may also discover that some firewalls and proxy servers are configured to allow GET requests through but block POST requests. Thus, switching from GET to POST may prevent some people in high-security installations from accessing your site. Again, this is a feature, not a bug. HTTP is designed to enable network administrators to control their network traffic and separate safe requests from potentially unsafe ones. If the network administrator has chosen to block POST, that is their decision and right, not yours. Do not attempt to subvert other sites’ security policies by tunneling POST through GET.
Consider each action on your site that is serviced by a script or program rather than a static file. In particular, look at URLs that include query strings. Ask yourself, “Would it bother me if Googlebot followed this URL?” For the moment, ignore the temptation to say, “Google could never find this” or “Google would not have the right user authentication cookies to be allowed in” or anything like that. Simply consider whether it would be a problem if Googlebot did somehow get in. Would it do anything you wouldn’t want it to do?
Next, ask yourself what would happen if a real user got a timeout on a page and resubmitted the form. Would a credit card be charged twice? Would they have printed two copies of a book instead of one? Would anything have happened that they did not want to happen and had not asked for?
If the answer to any of these questions is yes, the form should be using POST rather than GET. POST is intended for potentially unsafe operations. POST operations are not cached, bookmarked, prefetched, or even resent from the back button without an explicit user request. POST operations are at least sometimes dangerous and irrevocable. Consequently, user agents such as browsers take special care to make sure the user does not accidentally POST data without really meaning to. By contrast, URLs accessed via GET are commonly downloaded without any human intervention or consent whatsoever. They are for browsing, not buying. They should be safe and free of side effects.
The following operations should be done with POST:
Purchasing an item
Agreeing to a legal document
Posting a comment on a blog
Deleting a page from a content management system (CMS)
Signing a petition
Sending e-mail
Inserting new content into a database
Printing a map
Controlling a machine
This is just a sample. There are many more.
By contrast, the following operations should be done with GET, because they are safe and do not obligate the reader:
Reading a legal document
Downloading an editable copy of a document from a CMS
Reading e-mail
Viewing a map
Inspecting the current state of a machine
Again, this is just a sample. There are many more.
A few operations straddle the line. For example:
Adding an item to a shopping cart (but not immediately purchasing it)
Previewing a comment on a blog
I’d probably use POST for adding an item to a shopping cart simply because I don’t want a browser to do this automatically. This may not commit the user to buy the item, but it still changes the state of the shopping cart. If an item were added automatically, the user would then have to remove the item from the cart.
Whether I implemented previewing as GET or POST might depend on implementation details and convenience. It would not be a problem for a browser to prefetch a preview or for someone to link to it. However, if the preview in some sense actually creates the comment resource but just doesn’t allow it to be shown to the other users yet, POST is more appropriate.
Using GET where POST is called for can have potentially disastrous consequences. In the worst case I know of, Google deleted an entire government web site that had used GET for all operations.
Do not rely on cookies, nonces, hidden form fields, nonhidden form fields, JavaScript, HTTP authentication, referrer checking, or other tricks to hide the GET links from spiders. The Google web accelerator caused massive problems for many diverse web sites that weren’t expecting users’ browsers to begin following every link on the page. In this case, users were already logged in and had all necessary credentials to perform dangerous operations.
These are only the most famous examples. There have been many others over the years. The bottom line is this: HTTP is designed to clearly separate what you do with POST from what you do with GET. When you design web applications to use POST for what POST was designed for and GET for what GET was designed for, everything works and works well. When you mix them up and try to tunnel GET through POST or POST through GET, trouble ensues. You can spackle over the problems and spend your life putting out fires as one problem after another crops up, or you can use HTTP the way it was meant to be used.
If you do uncover any forms or links that are using GET where they should be using POST, fix them. The only client-side change that’s usually needed is changing method="get" to method="post" on the form element.
If the unsafe operation is being triggered by a link, replace it with a form. You can use hidden fields to fill in the values of the query string variables. For example, suppose you have this link:
<a href="/admin.php?action=approve&id=1798">Approve</a>
It has two fields: action with the value approve, and id with the value 1798. Each field in the query string becomes a hidden field in an equivalent form shown in Listing 7.1. The text of the link becomes the text on the submit button.
Browsers will show a single button for this action. Some more modern browsers, including Firefox, let you style the button so that it looks more like a link with a CSS rule such as this one:
input#approve {
border: none;
background: white;
color: blue;
text-decoration: underline;
}However, other browsers, including Safari, always show a button no matter what styles you apply. I think using a button instead of a link is no big deal. It’s probably friendlier to users who associate buttons with taking an action and following links with simple surfing. However, if you really, really hate buttons, there’s something else you can do. You can retain the original link but have it point to a page containing a confirmation form. No action is actually taken until the confirmation form is submitted, so the link can still use GET. The confirmation form uses POST. This seems a little involved to me, but it does allow you to keep buttons off the main page and retain the overall look, feel, and layout of that page while still using the proper HTTP verbs.
On the server side, a little more work is usually required to switch from GET to POST, but not an excessive amount. The details of how you switch from GET to POST on the server side will vary depending on the environment in which your server-side programs are written. In most cases, though, it’s straightforward. For instance, if you’re using Java servlets, you can handle many cases merely by renaming the doPost() method to doGet(). The arguments and the logic are the same. If you’re using PHP, you may well be able to just change $_GET['name'] to $_POST['name'].
The ease with which such frameworks enable one to switch between methods, combined with some bad early tutorials that were widely disseminated, has created a common antipattern in which scripts are written that accept requests via both GET and POST, and do the same thing in each case. This is dangerous and almost always a mistake. Most server-side programs should accept arguments via one or the other, not both.
It is possible to design a system in which a script takes different actions when you access it via GET or POST. For example, http://www.example.com/cars/comments might return a page with all the comments when you access it with GET and add a new comment to the page when you access it with POST. However, this pattern is uncommon in practice. Usually separate pages are set up to receive GET and POST requests.
Redesign safe operations so that they are accessed via GET rather than POST.
<form method="post" action="listarticles.php"> <p><label>Display <input name="number" value="10" type="text" /> articles</label></p> <p><label>Sort by: <select name="sort"> <option value="Reverse">Most recent first</option> <option value="Forward">Publication order</option> <option value="Author">By author</option> <option value="Title">By title</option> </select></label></p> <p><input type="submit" value="List articles" /></p> </form>
URLs that can be accessed with GET can be linked to, spidered, bookmarked, prefetched, cached, printed in books, painted on the sides of buildings, and more. GET URLs enable the use of the back button. A GET operation is just overall friendlier to the user than a POST operation.
GET URLs are also friendlier to search engines, and they improve your site’s search engine ranking. POST-only URLs are effectively invisible to spiders and search engines. Other sites and people can link to your GET URLs, which improves your traffic directly when people follow the links and indirectly when search engines notice the links and boost your page rank accordingly.
Finally, representations of GET URLs can be cached, which dramatically improves both client and server performance.
Done right, none. However, you do need to be careful that your operations are really free of side effects. Using GET where it’s inappropriate can cause massive damage, up to and including the complete deletion of an entire site. However, it’s not hard to understand when GET is and is not appropriate.
Due to caching, GET URLs may measure fewer hits than a page accessed via POST. This might mean less advertising revenue or budget. However, because GET URLs are so much more search-engine and user-friendly, you’ll more than make up for any reduced hits due to caches with increased hits due to actual visitors. Furthermore, some simple modifications of cache-control headers can eliminate this issue entirely, without using POST.
You should use GET for all operations that do not cause side effects. If following a URL simply results in the server transferring some data to the client and nothing else, GET is appropriate. Anything that can be thought of as simple browsing should be handled with GET, whether it’s implemented with static files or with a server-side script. The distinction should be irrelevant to the browser. Ideally, users shouldn’t be able to tell whether they’re being served static files, live database queries, or cached database queries.
However, if a connection has major side effects, it should not be accessed with GET. For example, if the user is charged a penny for each page loaded or each image viewed, those pages should only be loaded with POST. Similarly, a user should read a contract with GET but only agree to it with POST.
Trivial side effects such as hit counters and log file entries don’t need to be considered here. The real concern is that users not be obligated in any way by following a link and GETting a URL. They don’t buy anything. They don’t promise anything. They don’t make anything happen. They’re simply browsing through the store.
Query String Limits
There’s a common myth that GET can be used only in cases where the data embedded in the query string will be less than 256 characters long. This was true a long time ago, but hasn’t been true for at least ten years. All browsers from this millennium can easily handle URLs that are up to 2,000 characters long, and more modern ones go well past that limit.
The big problem is Internet Explorer, which as of Version 7 still cannot handle URLs longer than 2,083 characters. This should be long enough for most forms that do not collect free-form input from the user. Forms that do ask the user for unlimited amounts of text (comments on blogs, contact forms, etc.) can usually legitimately use POST anyway.
I have encountered a few cases where very long query strings broke a server-side framework (PHP 4 in particular). If this happens, you might temporarily use POST where GET is more appropriate. In the longer run, though, you should upgrade to a server framework that does not impose such arbitrary limits.
On the client side, changing a form to use GET instead of POST is easy. Simply change method="post" to method="get" on the form element. On the server side, details vary with framework, but the change is usually easier than it should be. (Most frameworks really don’t care whether any given form is submitted via GET or POST, which has contributed to the myth that the difference doesn’t matter. Indeed, some poorly written frameworks accept all forms with both methods by default.)
If you’re using Java servlets, renaming the doPost() method to doGet() is often all you need to do. In PHP, you may have to do little more than replace $_POST['name'] with $_GET['name'] and carry on as though nothing else had changed. Scripts that pay attention to the URL by which they were invoked—for instance, by echoing the URL back to the user—may also wish to make a point of stripping off the old query string.
The really big advantage of switching from POST to GET is that you no longer need to use forms at all. You can still use forms if you like, but you can also create static links that make particular queries. For example, consider the article list form from the beginning of this section. You can now make a link that finds the ten most recent articles:
<a href="article.php?sort=Reverse&number=10"> 10 Most Recent Articles </a>
Or you can make a link to the very first article:
<a href="article.php?sort=Forward&number=1"> The one that started it all </a>
Furthermore, not only can you make links such as these, but other people who want to link to your site can mint these URLs, too. They can bookmark your pages and use these URLs in several other ways to drive traffic to you. None of that is possible with POST.
Of course, any such links you write must be properly encoded both according to XHTML’s rules and according to URL rules. For XHTML, this means you must encode each & as amp;. Thus, a URL such as /article.php?sort=Reverse&number=10 is typed in the XHTML document as /article.php?sort=Reverse&number=10.
URLs further require that all non-ASCII characters as well as the space, the forward slash, the colon, the equals sign, and other nonalphanumeric characters that have special meaning in URLs be percent-encoded. For ASCII characters, this just means replacing the character with a percent sign followed by the hexadecimal value of the character. For example, the space is ASCII 32 in decimal and 20 in hex. Therefore, spaces encoded in your URLs are encoded as %20. The colon is ASCII character 58 in decimal and 3E in hex. Therefore, colons included in your query strings are encoded as %3E. Non-ASCII characters are first converted to individual UTF-8 bytes. Then each byte is percent-encoded.
This is the same encoding used by a browser before it submits a form to the server. One way to figure out the strings you need is simply to create a form that builds them, submit it, and copy the resulting URL out of the browser’s location bar.
Redesign scripts that respond to POST requests to redirect browsers rather than serving the results directly.
HTTP/1.1 200 OK Date: Tue, 08 Apr 2008 20:58:58 GMT Server: Apache/2 X-Powered-By: PHP/5.2.0 Content-Length: 325 Content-Type: text/html; charset=UTF-8 <html> <head><title>Order Accepted</title></head> <body> <h1>Invoice for your Records: Order #9878932479</h1> ... <p>Please print a copy if you want to save it.</p> </body> </html>
It’s convenient to be able to bookmark, link to, and return to orders, invoices, quiz results, and the like. However, you can’t do this with POST because the operation is unsafe. For example, bookmarking a POST request to check out of a store might order the same items again when the bookmark was activated.
Instead, the server can respond to the initial POST by creating a new static resource for the order status. Instead of returning the status directly, the server redirects the client to this new static resource. Then the client can bookmark and return to that static resource whenever they like.
The server will need to save the results of POST requests for a reasonable period of time. They don’t need to be saved forever if they’re not relevant indefinitely. (How many people check on an order six years after it’s been delivered anyway?)
Many of these results are at least somewhat private. You’ll need to use the same level of authentication for retrieving the results as you do for submitting the form in the first place.
Implementing this requires an additional level of indirection for both client and server. When the client submits the form, do not immediately calculate the result and feed it back to them. Instead,
Process the user input.
Generate a response for the user and store it.
Assign a roughly random URL for the response.
Redirect the client to the response.
Of course, the details will depend on exactly how the form is normally processed. Processing the data submitted from the form is usually the same as when responding directly. If you store the data in a database, it’s still stored in the database. If the input is e-mailed to someone, it’s still e-mailed to someone. If it starts up a robot on the factory floor, it still starts the same robot on the factory floor.
The trick is the next step. We do not form the response HTML document in memory and send it directly to the client in the body of the HTTP response. Instead, we form the HTML and save it somewhere: in a database, on the filesystem, on another server, or wherever is most convenient. Sometimes you’ll save an actual complete HTML document. Other times you’ll just save data that can be filled into a template later. If your server is mostly serving static HTML in the first place, static files are likely the simplest. If the server is database-backed and template-driven, storing the data for later insertion in a template is probably easier. The client won’t know or care which approach you take.
Either way, you need to associate a URL with the data that can be used to find it later. If everything’s in static files, the actual URL of the file is likely enough. Just pick a random name for that file. If the data is stored in the database, you’ll probably need to add another table to map randomly chosen URLs to particular records. Either way, when the request comes in, the server will match the URL to what is stored and send out the appropriate document.
Finally, you send the client a 300-level HTTP response redirecting them to this new data. In this case, 301 Moved Permanently is usually what you want. This server will also have a Location header that points to the result document. For example, using Java servlets, some code along these lines would do the trick:
response.setStatus(HttpServletrequest.SC_MOVED_PERMANENTLY);
response.setContentType("text/html; charset=UTF-8");
response.addHeader("Location",
"http://www.example.com/order/9878932479");
OutputStream out = response.getOutputStream();
Writer w = new OutputStreamWriter(out, "UTF-8");
w.write(
"some HTML in case the browser doesn't follow the redirect");
w.flush();
w.close();PHP, RAILS, and other frameworks have similar abilities.
When the browser receives the 301 response, it will GET the URL specified by the Location header. This page can then be bookmarked, linked to, and so forth. If this page contains private data, the server can require authentication just as it can with any other page. If it’s very private, the Location header can redirect the browser to an https URL instead of an http URL. Because this is just a regular GET, it fits well into existing HTTP frameworks and tools on both the client and server sides.
Apply cache control headers so that dynamically generated pages can also be cached when appropriate.
HTTP/1.1 200 OK Date: Sun, 08 Apr 2007 20:58:58 GMT Server: Apache/2 X-Powered-By: PHP/5.2.0 Content-Length: 325 Content-Type: text/html; charset=UTF-8
Caching is a crucial part of web performance and scalability. Caching can take place at many levels: on the server with gateway proxies, between the client and the server in proxy servers, and in the browser itself through local history. The fewer connections the client makes and the more it can act on information it already has, the faster both the client and server can run.
Web servers’ default configurations are fairly good at managing caches for static files, and you don’t need to worry a lot about that. However, web applications that manage their own HTTP headers require more thought and care. Most especially, web applications accessed via POST and ones that make use of URL query strings must be especially considerate of cache control headers because much software does not cache the result of GET requests that use query strings or any POST request. However, by manipulating the HTTP header you can indicate to the client that it is acceptable to cache some of these.
Not everything should be cached. You do want to be careful before blindly allowing caching. Done wrong, caching can deliver stale information or expose users’ private data.
Cacheable pages will measure fewer hits than unncacheable pages. If that’s a major problem for you, the next section explains how to prevent caching, rather than enabling more of it. However, most sites benefit heavily enough from caching that they’d like more of it, not less.
You can also use the techniques in this section to enable caching of some resources but not others. For example, you might allow the main HTML pages to be cached but disallow caching of ads. That would enable more precise measurement of just how many people are seeing your ads.
Proxy servers such as AOL’s use caches to improve local performance on their network. If 10,000 people request the New York Times home page between 6:00 a.m. and 7:00 a.m. every day, AOL has to load it from the New York Times only once. Then it can serve its local copy to all of its users. Individually, users often return to the same pages more than once. A browser that has gone to a page before can save time by reloading it from a local cache rather than downloading it from the network again. This saves everyone’s bandwidth, reduces latency, and is an all around good thing. It is one reason the Web scales as well as it does.
Usually browsers, proxy servers, and other software cache documents only if the server indicates that’s OK. The server does that by setting one or more of the following HTTP headers:
Last-modified
Expires
ETag
Cache-control
They do not cache documents if
The document was loaded via https.
The document required HTTP authentication.
The document was received in response to a POST.
However, you can modify all of this using the Cache-control header.
If a browser or proxy has stored a document in its cache, it will serve it to a client if the document is not too old. If it is too old, it will first check with the server to see whether the document has changed. It does this using an HTTP HEAD request that does not require the server to send the entire document all over again. If the document has changed, the browser will download a fresh copy of the document. Otherwise, it will serve the document out of its cache.
Usually for static files you don’t have to worry about this, as long as you aren’t too picky about how long browsers cache documents. If you have frequently updated data, or high-performance requirements, you may want to play with the defaults; but more often than not the defaults are fine. However, content generated dynamically from PHP, JSP, ASP, CGI, and similar technologies requires you to provide the necessary headers to enable caching. Otherwise, the page won’t be cached.
The easiest tag to send is Last-modified. When a client sees a Last-modified header a reasonable distance into the past, it assumes the page isn’t updated every minute or two and makes a reasonable guess as to how long it can cache the page. In PHP, you can send this and all other headers with the header function like so:
header('Last-Modified: Thu, 05 Apr 2007 09:41:05 GMT'),You must call the header function before writing any other output to the client.
If you want to precisely specify when the cached copy should expire, you can send an Expires header instead of or in addition to the Last-modified header. The value of the Expires header is a date in the future after which the cache should be flushed and a new copy loaded. For example, this header sets the expiry time for Wednesday, August 8, 2012:
Expires: Wed, 08 Aug 2012 09:41:05 GMT
This is much longer than most browsers will hold on to a document by default. You might choose such a long time for static images that are very unlikely to change. You can also try setting an Expires header in the relatively distant future for each separate embedded component on a page: scripts, stylesheets, Flash animations, and the like. In Apache, you can do this by setting the ExpiresDefault property in your .htconfig file like so:
ExpiresDefault "access plus 2 weeks"
The downside of this is that many surfers will continue to use the cached components until the time period expires. To get around this, when you change one of them, also change its name. Sometimes it’s helpful to just add a version number to each such resource: stylesheet_111.css, stylesheet_112.css, and so forth.
You can use the ExpiresByType directive to override the expiry time for particular types of documents. For instance, if the HTML files change frequently, you may want them to expire very quickly. This sets them to expire after 3,600 seconds:
ExpiresByType text/html M3600 # HTML expires after one hour
You can use the Cache-control header to specify a relative expiry time. For example, this header sets the expiry time one hour (3,600 seconds) after the client has first retrieved the page:
Cache-Control: max-age=3600
Apply cache control headers so that rapidly changing pages are always loaded fresh from the server.
HTTP/1.1 200 OK Date: Sun, 08 Apr 2007 20:58:58 GMT Server: Apache/2 X-Powered-By: PHP/5.2.0 Cache-control: public Last-Modified: Fri, 03 Dec 2004 11:53:03 GMT ETag: "6548d4-30a9e-c7f4e5c0" Content-Length: 325 Content-Type: text/html; charset=UTF-8
Not everything should be cached. You do want to be careful before blindly allowing caching. Done wrong, caching can deliver stale information or expose users’ private data. Stock prices need to be updated from second to second. So do sensor readings from laboratory equipment.
Or perhaps you simply want better user statistics. You want to know how many users are seeing your ads without having to guess how many users equate to each AOL proxy server. Cacheable pages will measure fewer hits than uncacheable pages. Marking pages as uncacheable inflates, and usually more accurately reports, site traffic.
Uncacheable pages place much higher loads on a server. Worse yet, the effect is multiplied at times of high traffic, such as an online store the weekend before Christmas or any site that gets dugg. If you’re turning caching off purely to improve hit counts and user tracking, be ready to turn it back on again if traffic spikes. Ideally, you should build in automatic governors that notice the traffic is spiking and reenable caching without manual intervention.
One way to prevent caching is to make all requests go through POST, because POST requests are never cached (at least not by decent clients and proxies). However, that’s the wrong solution. Using POST to prevent caching is like using SAP to run a mom-and-pop candy store. It’s much too big a solution for too small a problem, and consequently it will cause more problems than it solves.
The right solution is to send HTTP cache control headers with the pages that should not be cached. For example, if you simply wanted to prevent all caching of a page, you’d tell the HTTP server to set Cache-Control to no-cache. Then it would send an HTTP header such as this one before the page:
HTTP/1.0 200 OK Cache-Control: no-cache Date: Sat, 05 Apr 2008 15:52:40 GMT Server: Apache/2 Last-Modified: Thu, 05 Apr 2008 09:41:05 GMT ETag: "8aeb10-b6e7-5ea4ae40" Content-Length: 46823 Content-Type: text/html; charset=iso-8859-1 Connection: close
Or perhaps the data is tied to a single user. It’s OK for that user’s browser to store the data in its local cache, but you don’t want shared proxy servers to send the same page to a different user. Then you’d set Cache-Control to private:
Cache-Control: private
You can set an explicit amount of time for which the cache is valid using max-age. For instance, if you want caches to hold on to a page for no more than an hour, set max-age to 3600 (seconds):
Cache-Control: max-age=3600
You can specify multiple values for Cache-Control separated by commas. For example, this header requests only private caching for no more than an hour:
Cache-Control: private, max-age=3600
Table 7.1 lists the values you can use to control caching for GET requests.
Table 7.1. Cache-Control Header Values
Value | Meaning |
|---|---|
public | Completely cacheable |
private | Can be cached only by single-user caches, such as in a browser; must not be cached by multiuser caches in proxy servers |
no-cache | Do not cache under any circumstances. |
no-store | Like no-cache but stronger. Do not even write the data to disk, not even temporarily. In practice, this is not very reliable. |
no-transform | Cache only as served—do not convert image formats, for example. |
must-revalidate | Do not allow the client to use a stale response, even if the user has asked it to. |
proxy-revalidate | Do not allow a proxy to use a stale response, even if it has been configured to do so. |
max-age = seconds | Serve from the cache only until the specified number of seconds since the original request has elapsed |
Dynamically generated pages written in PHP and the like can use the customary mechanisms to set Cache-Control headers. For static pages, details vary from server to server. In Apache, you can use the mod_headers module to specify per-file and per-directory Cache-Controls. This module is not typically compiled in by default, and it may require a custom compilation to use. Assuming it is turned on, you can place a Header directive in any Files, Directory, or Location section in your .htconfig file, or you can place it in an .htaccess file to make it apply to every file in the same directory. For example, this line requests that only private caching be performed:
Header append Cache-Control "private"
This line requests that the pages be cached but revalidated:
Header set Cache-Control "public, must-revalidate"
The use of the set keyword instead of append means that this header will replace any other Cache-Control headers that might be set by other modules, rather than being merged with them.
Provide ETags for semistatic pages generated by web applications.
Date: Mon, 09 Apr 2007 13:41:12 GMT Server: Apache/2 X-Powered-By: PHP/5.2.0 Expires: Wed, 11 Jan 1984 05:00:00 GMT Last-Modified: Mon, 09 Apr 2008 13:41:13 GMT Cache-Control: no-cache, must-revalidate, max-age=0 Content-Style-Type: text/css Keep-Alive: timeout=15, max=98 Connection: Keep-Alive Transfer-Encoding: chunked
ETags enable a client to quickly check that a page has not changed without downloading the entire page again. This saves server and client bandwidth and speeds up page load times.
You shouldn’t provide ETags for pages that update very frequently, in particular more frequently than a client will access them.
ETags can also take non-negligible CPU time to calculate. This usually isn’t a big deal, but on a server that is CPU-limited (as opposed to bandwidth-limited), this might be a concern.
ETag stands for “entity tag.” It’s a server-scoped identifier for the data sent by a server to a client in response to a request for a particular URL. It’s supposed to change when the entity changes and stay the same otherwise. The first time a browser or other client requests a page from a server, it notes the entity tag of that page. The next time it needs to request that page, it can include the ETag in an If-None-Match header, like so:
GET /foo.html HTTP/1.1 If-None-Match: "6548d4-30a9e-c7f4e5c0" Host: www.elharo.com User-Agent: Mozilla/5.0 (Macintosh; U; PPC Mac OS X Mach-O; en-US;rv:1.8.1.3) Gecko/20070309 Firefox/2.0.0.3 Accept: application/xhtml+xml,text/html,text/*;q=0.8,*/*;q=0.5 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Keep-Alive: 300 Connection: keep-alive
If the server recognizes that the ETag matches the current ETag of the requested resource, it responds with a 304 Not Modified response, like this:
HTTP/1.1 304 Not Modified Mon, 09 Apr 2007 15:21:10 GMT
It really doesn’t have to say anything else. In particular, the server does not send the body of the resource as it would if there were no ETag. Instead, the client loads its old copy of the resource from its cache. It can do this even if the expiration date of the resource in the cache has passed because it has checked with the server that the old representation is still fresh. For large documents, this can save significant bandwidth.
Web servers today send ETags for static files, and you don’t have to do anything extra for those. However, dynamic pages generated by PHP and similar frameworks are trickier. Sometimes every request to the server creates a different byte stream. If this is the case, don’t bother sending an ETag. It will never help. However, many scripts sit somewhere in the middle. For example, suppose a script responds to a request for http://www.example.com/isbn/0691049548/ by making several SQL queries against a database and then formatting the results as HTML. If nothing in the database has changed, there’s no need for clients to keep requesting that data. However, clients won’t know that unless the server gives them an ETag.
ETags versus Caching
ETags have a complex but partially orthogonal relationship to caching. Caches and cache control headers determine when a browser does or does not check back with a server before showing an old copy to a client. ETag headers come into play after a browser has decided to check back with a server.
There are no special rules for how one constructs an ETag. Conceptually you can think of it like an MD5 or SHA-1 hash code for a document. However, because ETags do not need to be secure, and because these algorithms are computationally expensive, they are not the best choice for this purpose. Instead, consider what actually distinguishes one request from the next, and see if you can devise a simple hash code algorithm from that. For example, if the only difference between pages is in the SQL queries used to access a database, and if no new data is inserted into the database, you could form a hash code based on the SQL queries themselves. If the database is updated, but only occasionally, you might devise a scheme in which ETags are generated from SQL queries plus a random identifier that is changed every time the database is modified. However, if the database is written as frequently as it is read, you have to base the hash code on the data the queries return. Possibly, though, you could make it depend on just some of the fields in the response rather than all of them.
For example, I have published a simple PHP program that generates a plain text file containing Fibonacci numbers. The only relevant input is the number requested. Thus, I can make that the ETag, like so:
$generations = $_GET['generations'];
header('Etag: "' . $generations . '"'),
If I ever change the format this script generates, I’ll need to adjust the ETags as well. Alternatively, I could use weak entity tags. By default, entity tags are assumed to be strong, which means that two representations have the same entity tag if and only if they are byte-per-byte identical. However, if you put W/ in front of the quoted string, it becomes a weak entity tag. Documents that share a weak entity tag mean the same thing, but may not be byte-per-byte identical. For instance, if I converted a JPEG to a GIF, I could keep a weak entity tag the same, but not a strong one. A weak entity tag looks like this:
ETag: W/"6548d4-30a9e-c7f4e5c0"
There are few limits on what you can put in an ETag. It must be ASCII text. It cannot contain any control characters, including carriage returns, line feeds, and tabs. It must be double-quoted. Otherwise, use any format that works for you.
The second step for the web application to support ETags is to recognize when someone sends it an ETag and sending a 204 response instead. Clients can send multiple entity tags in a header separated by commas to indicate that they have multiple representations prestored. For example:
If-None-Match: "6548d4-30a9e-c7f4e5c0", "756ed4-44a5e-1cf56c09"
In this case, the server should send a 304 Not Modified response if any of the supplied entity tags match the current state of the resource along with the ETag that matches.
Convert Flash sites to HTML. Provide pure-HTML alternatives for all Flash content.
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head> <title>Salkind Agency</title> </head> <body> <object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/ flash/swflash.cab#version=6,0,0,0" width="766" height="670" id="salkindfinal1" align="middle"> <param name="allowScriptAccess" value="sameDomain" /> <param name="movie" value="salkindfinal1.swf" /> <param name="quality" value="high" /> <param name="bgcolor" value="#ffffff" /> <embed src="salkindfinal1.swf" quality="high" bgcolor="#ffffff" width="766" height="670" name="salkindfinal1" align="middle" allowScriptAccess="sameDomain" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" /> </object> </body> </html>
Flash is extremely inaccessible. In most cases, a Flash site might as well be a black box to blind users, and it is often hostile to color-blind, deaf, and motion-impaired users as well. Although accessibility has been improved somewhat in the latest versions of Flash, most Flash applications are still vastly less accessible than plain old HTML.
It’s not just handicapped users who have problems with Flash either. Even people with no handicaps do not have Flash-enabled browsers or browsers with the latest version of Flash installed. The lowest estimates I’ve seen are that 1 person out of 20 does not have Flash installed. Based on my experience, I expect that number is severely biased by self-selection effects and that likely a much higher percentage of users do not have Flash at all. Regardless of the exact numbers, though, there’s no question that Flash is a crippling inconvenience to many users.
Finally, Flash is almost completely inaccessible to Google and other search engines. Even if users can view a Flash site, if it’s all Flash, they’ll never find it. My book agent (who’s also an author and professor) recently converted to an all-Flash site. If you search for his name on Google, you’ll find his faculty page, his Amazon page, his Barnes & Noble page, some listings at other bookstores, some eBay listings for his books, and more detritus no user would ever wade through. It isn’t until the fourth page of Google results, near the bottom, that his literary agency that shares his name shows up.
There are some things you can’t do in plain old HTML. If you really want a bouncing, singing greeting card or another Tetris knockoff, go ahead and use Flash.
There are even some more serious uses to which Flash can reasonably be put. For example, a Flash animation can show how to disassemble a complicated piece of equipment or demonstrate the flow of money in an economy. Done well, such animations will assist sighted users. However, you should also have a complete plain HTML version of all such content, for both unsighted users and Google.
Flash is sometimes used to attempt to lock in content. Flash content cannot be copied as easily as HTML and JavaScript. YouTube and Google use Flash video to try to force people to link to them and watch their ads rather than downloading their own copies of videos. However, there’s a world of difference between “cannot be copied as easily” and “cannot be copied.” Numerous tools are available today that enable users to download Flash videos, decompile Flash files, and extract text, images, and movies from them. Encoding content in Flash merely impedes legitimate users while not seriously hindering pirates.
Chances are you probably know where the Flash files are on your site. If for some reason you don’t, just search for d27cdb6e-ae6d-11cf-96b8-444553540000 and application/x-shockwave-flash. Unless you’re publishing Flash tutorials, these strings only appear in documents that embed Flash.
Once you’ve found a Flash file, you’ll need to play it to see what it’s doing. If it’s doing something that really can’t be done with HTML, such as a twitch game, you may be OK leaving it. However, you should still add some HTML content to the page to at least describe the game for Google and other viewers who may not be able to play it. Please don’t just leave them with a message saying, “This site requires that you have the latest version of the Flash player” or, worse yet, a completely blank page. At the very least, tell them why they might want to download Flash to view your site.
However, what really needs a rethink are sites such as my agent’s that use Flash for tasks that HTML can do perfectly well. In particular, the following common things should never be written as Flash applications:
Navigation
Text content
Noninteractive images
Slide shows
Data entry forms
Invoices
All of these and many, many more can and should be handled by pure XHTML+CSS. On occasion, you might even throw in a little JavaScript, though I mostly try to avoid that too. There is no excuse for using Flash for any of these things.
There are a couple of cases where I can see the use of Flash, but it’s not strictly necessary. These are sound and video. For pure sound, you’re better off doing a podcast as an MP3 file. Users are unlikely to sit in front of their computers in their cubicles and listen to a 30-minute show, but they may download it to their iPod and listen to it on their commute home. However, for background sound on web pages (the Web’s equivalent of elevator music), you may as well use Flash as anything else. Please, please give users a way to turn the sound off if you do so, though. Nothing makes a user close a window and leave your site faster than hearing the Black Eyed Peas unexpectedly start blasting “My Humps” in the middle of a crowded office.
For video, Flash actually does seem to be the most reliably cross-platform format. QuickTime doesn’t run on Linux. Most Windows Media files don’t play on the Mac without a variety of hard-to-find plug-ins most users haven’t installed. MPEG is covered by a variety of patents, and nobody’s sure exactly which ones or how many. And even if you can sort out the confusing mess that is video codecs, you are then faced with the problem that the means of embedding videos in a page vary from one browser and platform to the next. It’s invalid and nonstandard.
For the moment, Flash really may be the best choice here, as hard as that is to believe. For the longer term, though, help is on the way. Several patent-free, open video standards, such as Ogg Theora, are under development. (They’re already supported on Linux, but not yet widely available on more mainstream platforms.) HTML 5 seems likely to add a video element and maybe even an audio element to go with the existing img element. However, for the time being, using Flash for video and audio is not out of the question.
Finally, there are what I consider to be the truly evil uses to which unscrupulous webmasters have put Flash. In particular:
Animated ads
User tracking
If someone asks you to do these things, just say no. Users hate animated ads, and these days more users block them than don’t. Indeed, some users block all Flash content by default just to avoid these ads (and other equally annoying animated content that is not technically ads). If you really want to waste your time and your client’s/company’s money on animated ads, be my guest, but I guarantee you that your effort and intelligence would be better spent on improving your site’s usability and customer conversion than on making the ads blink.
As to using Flash data storage to replace cookies, if a user is smart enough to block your cookies, chances are they are smart enough to set Flash’s persistent storage to zero, too. If your client insists on such scummy tactics, fire the client. If your boss orders you to do this, find a better job. (Don’t worry too hard about this. Most such bosses/clients have their hair cut too pointy to know about this in the first place. If you don’t tell them it’s possible, they’ll never know to ask for it.)
Identify the type of expected data by adding a type="email | url | date | time | datetime | localdatetime | month | week | number" attribute to input text fields in forms.
<form action="http://www.example.com/formhandler" method="post"> <p><label>E-mail: <input name="email" /></label></p> <p><label>Date: <input name="date" /></label></p> <p><label>Time: <input name="time" /></label></p> <p><label>Date and time: <input name="datetime" type="text" /></label></p> <p><label>Local date and time: <input name="localdatetime" type="text" /></label></p> <p><label>Month: <input name="month" /></label></p> <p><label>Week: <input name="week" /></label></p> <p><label>Number: <input name="number" /></label></p> <p><label>URL: <input name="url" /></label></p> <p><label><input type="submit" value="Send data" /></label> </form>
These new types enable browsers to provide more appropriate GUI widgets to input data. For example, a browser can show a calendar control to allow the user to select a date, as shown in Figure 7.1.
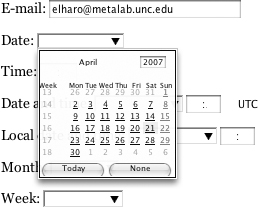
Browsers can also check the input data on the client side and refuse to accept it or submit the form if it’s incomplete or incorrect. Figure 7.2 shows Opera refusing to accept a value that’s outside the specified range.
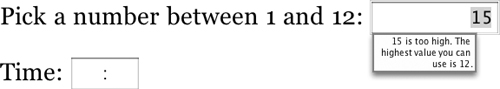
Not all browsers support these types yet. In fact, so far only Opera 9 does. More support is coming soon, but in the meantime, these forms still work perfectly well in today’s legacy browsers. Users just don’t get all the neat new features to help them with data entry.
Input validation helps users be sure they don’t make a mistake. However, it does not substitute for server-side validation. Not all clients check these inputs, and hackers can trivially submit values outside the expected ranges.
The resultant pages will not be valid when compared against the traditional HTML and XHTML DTDs. However, this will have no effect on browser display.
It’s an open question whether these documents will ever be valid. There’s some sentiment for not even bothering with schemas or DTDs for future versions of HTML. However, I expect that DTDs and schemas will eventually be published.
You can easily do a multifile search for <form just to find the pages that would benefit from closer inspection. Once you’ve found a form, consider it field by field to figure out what types are likely to be a good fit. There’s not a lot you can do to automate this process.
Once you’ve found the forms, check each input field to see whether it matches any of the expected types. There are ten new types you can use:
emaildatetimedatetimedatetime-localmonthweeknumberurlrange
Adding one of these types only affects the client and has no effect on the server. However, you need to make sure that the format the server is accepting is indeed the format the client is sending. For example, dates are sent in the ISO standard form YYYY-MM-DD (e.g., 2008-06-23). If you expect dates in a different form, such as MM/DD/YYYY, you’ll need to change the form processor on the server to accept the new format before deploying this on the client.
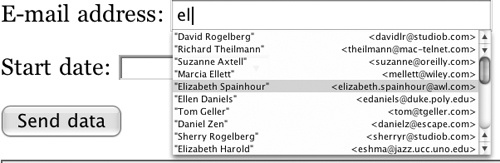
The email data type is used for e-mail addresses of the usual syntax: [email protected], for example. When you tag an input field as type email, the browser can inspect the user’s address book to offer options for autocompletion, as shown in Figure 7.3.
The date type is used for specific days in history, such as January 23, 1987, or September 18, 2012. The attributes min and max can be applied to limit the range of values the user can choose. For example, this input field asks the user for a date in 2008:
<input type="date" name="date"
min="2008-01-01" max="2008-12-31"/>
The form for date data entry is the ISO standard form YYYY-MM-DD (e.g., 2008-06-23). If you expect dates in a different form, such as MM/DD/YYYY, you’ll need to change the form processor on the server to accept the new format before deploying this on the client.
When you tag an input field as type date, the browser can offer a calendar control so that the user can pick a date.
The time type is used for times of day, such as 12:31 a.m. or 3:17:05 p.m. The default precision is 60 seconds (i.e., one minute), though you can adjust this with the step attribute. You can also specify minimum and maximum times with the min and max attributes. For example, this field requests a time between 9:00 a.m. and 5:00 p.m. on the hour or half hour:
<label>Start time:
<input type="time" min="09:00" max="17:00"
step="30" name="st" />
</label>
The form for time data entry is the ISO 8601 standard form HH:MM:SS.xxx (e.g., 03:45:13.23 for 3:45 a.m. and 13.23 seconds). Seconds are optional. Times after noon use a 24-hour clock—for example, 14:37, not 2:37 p.m. Time zones are not used.
When you tag an input field as type time, the browser can offer a more specific time control, as well as check that the user indeed entered a valid time.
The datetime type is used when you want the user to enter a specific moment in history—for example, not just 3:45 p.m. or December 12, 1982, but 3:45 p.m. on December 12, 1982. Data will be submitted in the form YYYY-MM-DDTHH:MM:SS.fffZ. Seconds and fractions thereof are optional. For example, 3:45 p.m. on December 12, 1982, would be sent as 1982-12-12T03:45Z or 1982-12-12T03:45:00.0000Z. Here the Z stands for Greenwich Mean Time (a.k.a. Coordinated Universal Time, UTC, or Zulu time). The data can be provided in a different time zone by using a plus sign (+) and an offset from Greenwich Mean Time. For example, Eastern Standard Time is five hours earlier than Greenwich Mean Time, so the same time is 10:45 a.m. EST.
The user does not necessarily have to type in this format, but if they don’t, the browser should convert to this format before submitting the form to the server. The browser may offer a widget customized for collecting data in this form and should verify that the data is reasonable before submitting it. If the user enters the time in a local time zone, the browser should convert that to Greenwich Mean Time before submitting it.
The datetime-local type is the same as datetime, except there’s no trailing Z. Furthermore, the time is assumed to be given in the user’s local time zone rather than in UTC. For example, 3:45 p.m. on December 12, 1982, would be sent as 1982-12-12T03:45 or 1982-12-12T03:45:00.0000.
The month type represents a specific month in a specific year, such as December 1952 or July 2028. Data is submitted in the form YYYY-MM. For instance, December 1952 is 1952-12 and July 2028 is 2028-07. The user can enter months in any form the browser accepts as long as the browser converts it to this form before submission.
The week type represents a specific week in a specific year, such as the first week of 1952 or the thirty-second week of 2009. Data is submitted in the form YYYY-Www. For instance, the first week of January 1952 is 1952-W01. The thirty-second week of 2009 is 2009-W32. All weeks begin on a Monday. The first and fifty-second weeks may extend across year boundaries.
The number type requests that the user enter a number. The default precision is 1, so by default the user can only enter an integer. However, you can adjust this downward with the step attribute to allow the user to enter a decimal number. For example, this input field requests a number between 1 and 12, including fractional numbers such as 2.72 but not 2.71828:
<label>Pick a number between 1 and 12:
<input type="number" name="guess"
min='1' max='12' step='0.01'/>
</label>
A range control is similar to a numeric control. The crucial difference is that the exact value is not considered important in the range, just that it’s somewhere in the vicinity. An example would be a thermostat. You want the temperature around 22° Celsius, but you don’t really care whether it’s 22.5 or 21.6, as long as it’s in the ballpark. For example:
<label>Temperature:
<input type="range" name="temp"
min='-20' max='90' step='0.5'/>
</label>
The browser may present this as a slider, scroll bar, or some other kind of input control that does not provide precise control rather than making the user type a value in a text field.
The url type requests an absolute IRI (like a URL, except that it can contain non-ASCII letters such as é) from the user, such as http://www.elharo.com/blog/ or ftp://ftp.ibiblio.org/.
Not all browsers support these types. In fact, currently only Opera 9 does. However, Firefox and Safari are likely to in the future and others may follow. However, if they don’t, much of this can be supplied with JavaScript and AJAX. Google has released a JavaScript library to add support for these types (and other Web Forms 2.0 features) and functions to your web pages in legacy browsers such as Firefox 2 and Internet Explorer 5. Simply copy the JavaScript library from http://code.google.com/p/webforms2/ to your site and add this script element to the head of your document:
<script type='text/javascript' src='webforms2.js'></script>
Even if that’s not an option, Web Forms 2.0 has been carefully designed to degrade gracefully in legacy browsers. Visitors with older browsers will simply see normal input fields when they reach a page using these new types. They’ll have to wait for the server to tell them if they’ve input a bad value, rather than being told before they submit. It’s no worse than the status quo.
It’s important to remember that client-side validation in no way guarantees anything about the data the server receives. Always validate any input received from a client. Some browsers do not support these types at all and will allow users to submit any data they choose. Crackers can and do submit deliberately invalid data to attempt to penetrate systems, deface web pages, steal passwords, and otherwise do naughty things. Always verify the input you receive from the client on the server, regardless of these types or any other client-side validation logic.
Turn contact forms into real mailto links.
<form action="http://www.example.com/email" method="post"> <input type="hidden" value="[email protected]"/> <p><label>Subject: <input type="text" name="subject" /></label></p> <p><label>Message: <input type="text" name="message" /></label></p> <p><input type="submit" value="Send e-mail"/></p> </form>
E-mail programs give users much more powerful and comfortable editing and archiving facilities. You will receive better communications when users can use their e-mail program of choice to compose their messages to you.
Furthermore, users will be able to maintain a record of their correspondence for easier reference in the future. This will make the communication more effective.
Users working from public terminals may not have an e-mail program installed or properly configured. You may wish to provide contact forms and mailto links. That way, users can choose what works best for them. However, do make sure the e-mail address is prominently displayed and visible on your site. Don’t make users hunt for it.
Users who rely on web mail providers such as Yahoo! Mail and Gmail will need third-party extensions and various hacks to make mailto links work for them. Many have already installed such extensions.
E-mail may not tie into back-end bug tracking and customer management systems as easily as a web form. When shopping around for such systems, you should insist on e-mail management as a core feature. Even if your system does accept e-mail input, you may not be able to organize the requests into such neatly fielded responses. You’ll need to be ready to parse information such as order dates, problem categories, and more out of the plain text of the e-mail. This usually requires human intelligence. That is, a person has to sit down and read the e-mail to figure out what it means. You do more work so that your customer does less. However, if this is too onerous, there are some tricks you can play to still use fielded forms while enabling your customers to use their real e-mail programs.
Publishing e-mail addresses on web sites opens them up to spam. In fact, even without that, they’re probably getting a lot of spam already. I’ll address techniques for minimizing this in the next chapter.
A mailto link is straightforward. In fact, it’s much easier to create than a contact form and associated back-end machinery for processing the form. It just requires a standard a element and a mailto URL. The URL is just mailto: followed by the address. For example, here’s a mailto link you can use to reach me:
<a href="mailto:[email protected]"> E-mail Elliotte Rusty Harold </a>
You can encode additional headers in the URL’s query string. For example, here’s an e-mail link that sets the Subject line to “Refactoring”:
<a href="mailto:[email protected]?Subject=Refactoring"> E-mail Elliotte Rusty Harold </a>
You can encode non-ASCII characters and non-URL legal characters by first converting them to UTF-8 and then encoding each UTF-8 byte as a percent sign followed by two hexadecimal digits. For example, a space is %20, so this link sends e-mail to me with the subject “Refactoring HTML”:
<a href= "mailto:[email protected]?Subject=Refactoring%20HTML"> E-mail Elliotte Rusty Harold </a>
You can separate additional headers from each other with ampersands (which must themselves be encoded as & in the XHTML). For example, this link CCs the message to another address of mine:
<a href= "mailto:[email protected]?Subject=Refactoring%20HTML& CC=elharo%40macfaq.com"> E-mail Elliotte Rusty Harold </a>
You can even set a default body for the e-mail using the query string variable Body. Here’s one example:
<a href= "mailto:[email protected]?Subject=Refactoring%20HTML& Body=I%20love%20Refactoring%20HTML."> E-mail Elliotte Rusty Harold </a>
These techniques should suffice to reproduce most contact forms in regular e-mail. I really believe that all e-mail should be read and responded to by a human being. However, if you need some greater level of automation, you can achieve it with a two-step process. First, set up a classic contact form that collects a series of fielded data from the user. The first submission sends it into your CMS and assigns it a unique ID by which it can be tracked. However, the response, rather than a simple thank you, is actually a confirmation screen that invites the user to e-mail the response to you. You can provide both a form and a mailto link for doing this. The mailto link is configured by the server-side script to already contain the right tracking ID, as well as all the detailed information the user filled out. The user can then mail that in.
One final note: Please don’t respond to forms or any e-mail from a “Do not reply to this address” address. Every e-mail you send out should come from an actual person who can carry on a conversation (possibly by delegation) if necessary. Yes, spam is a problem. Install a good spam filter, but don’t use spam as an excuse for hiding from your customers.
Add robots.txt files in directories you wish to block. Install a honey pot to detect and block impolite robots and venomous spiders.
User-agent: * Disallow: /scripts/ Disallow: /styles/ Disallow: /management/ Disallow: /support/ Disallow: /DTD/
Blocking robots prevents search engines from indexing your site and keeps people from finding your pages. Be careful to only block subtrees you really don’t want to be public.
First identify and catalog those parts of your URL hierarchy that should be invisible to search engines and other spiders. Remember to look at this from the perspective of an outside user looking in. This is based on the apparent URL hierarchy, not the actual layout of files on a disk. For example, here’s a typical list of URLs you might want to exclude:
/cgi-bin
/store/checkout
/personaldata/
/experimental
/staging
Of course, the details will vary depending on your site layout. I suggest blocking even those directories a robot “can’t” get into. Defense in depth is a good thing.
Place each of these in a file called robots.txt, preceded by Disallow: like so:
User-agent: * Disallow: /cgi-bin Disallow: /store/checkout Disallow: /personaldata/ Disallow: /experimental Disallow: /staging
Place this file at the root level of your web server. That is, it should be able to be retrieved from http://www.example.com/robots.txt. Remember that URLs are case-sensitive, so ROBOTS.TXT or robots.TXT and similar variations will not work.
You can also block robots by User-agent. For example, if you have a grudge against Google and want to keep it out of your pages, the following robots.txt will do that while allowing other search engines in:
User-agent: Googlebot Disallow: /
Note that this works only on robots. This would not allow you to exclude real browsers such as Mozilla and Internet Explorer, no matter what you put in the User-agent string. The goal here is precisely to block robots while allowing real people in.
You can even specify different rules for different robots. For example, this blocks all robots from /cgi-bin, blocks Googlebot from /staging and /experimental, and blocks Turnitin from the entire site:
User-agent: * Disallow: /cgi-bin User-agent: Googlebot Disallow: /staging Disallow: /experimental User-agent: TurnitinBot Disallow: /
The syntax here is quite minimal. In particular, there’s no “Allow” command. You cannot block all user agents from a directory and then allow one in particular. Similarly, you cannot block a root directory but allow access to one or more of its file or subdirectories. Robots.txt is a pretty blunt instrument.
You can also specify a robots meta tag in the head of HTML documents. However, few robots recognize or respect this. You really should use a robots.txt file to prevent robotic visits.
The especially dangerous robots are those that don’t follow the rules and spider your site whether you permit them to or not. To prevent these you have to detect them and then block them by IP address. Detecting them isn’t hard. You just set up a few links in your pages that only robots are likely to find. For example, you can have a link with no content, like this:
<a href="hidden/dontgohere.html"></a>
Block the hidden directory in robots.txt so that well-behaved robots will ignore it:
User-agent: * Disallow: /hidden
Then check your server logs to see which IPs have actually loaded that file. Also check to see what other files those IPs have loaded. If it’s just a few files, widely separated in time, I’d ignore it. But if I see that IP address has been hitting every other page on my site, I’ll block it in my Apache .htconfig file, like so:
<Directory "/www/xom">
Order allow,deny
Allow from all
Deny from 212.0.138.30
Deny from 83.149.74.179
Deny from 66.186.173.166
</Directory>
This prevents it from hitting any page on my site, not just the protected ones. However, chances are that spider is up to no good, so I don’t mind doing this.
You can also use mod_rewrite to block robots by User-agent. However, it’s so easy to change the User-agent string that I rarely bother with this. I find it hard to believe that a spider that’s ignoring robots.txt is not going to fake its User-agent string to look exactly like a perfectly legitimate copy of Firefox or Internet Explorer.
Some people have automated this procedure or used other means of detection. In particular, if anyone is hitting your site more than 12 times per minute, he may well be up to no good. However, this requires quite a bit more server intelligence than simple IP blocking.
Escape all user-supplied data.
$query = "SELECT price FROM products WHERE sku='" . $GET_['sku'] . "';";
SQL injection is the single most common source of security breaches on the Web today. It’s probably easier to find a database-backed site with a SQL injection vulnerability than a site without one. SQL injection has led to theft of confidential customer data, web-site defacement, credit card fraud, privacy breaches, denial of service, spam, phishing, virus propagation, and almost every other computer-assisted crime you can imagine.
Never treat user-supplied data as code, be it SQL, JavaScript, XSLT, or anything else. Only treat it as data. In particular, do not build executable statements by simple string concatenation of user-supplied values with code. This is begging for trouble.
To demonstrate the problem, consider a simple search form such as this one:
<form name="search" action="/search.php" method="get"> <input size="12" name="terms"> <input type="submit":" value="Search"/> </form>
It looks innocuous enough, but it can easily hide some serious security holes. For example, suppose it’s handled by a very basic PHP script such as this one:
$keywords = $_GET['terms'];
$query = "SELECT url, title FROM pages WHERE content LIKE '%"
. $keywords . "%';";
$result = mysql_query($query);
You may very well have given hackers the ability to delete every row in your database. For example, imagine they search for this:
foo%'; DELETE * FROM pages; SELECT * FROM pages WHERE content LIKE '%
This closes the initial search early, adds a second SQL command that deletes all data from the pages table, and then performs the first part of the next query to make sure the complete set of statements is syntactically correct.
Don’t fool yourself into thinking that nobody could possibly figure out how to do this. These attacks happen all the time, and hackers have gotten very good at working their way into databases in this fashion. Although the details depend on the database structure and the back-end code, this is not a theoretical attack.
Start with libraries such as Hibernate’s Criteria API that clearly separate the data from the code. Use parameterized queries and stored procedures where possible. When that’s not possible, make sure you escape all significant characters such as ' and " before forming the string.
Many APIs have built-in functions to perform this escaping. For example, PHP provides the mysql_real_escape_string function for escaping strings in a form suitable for use in MySQL. You could safely write the preceding code as follows:
$keywords = $_GET['terms'];
$query = "SELECT url, title FROM pages WHERE content LIKE
'%"$safe_keywords = mysql_real_escape_string($keywords);
. $safe_keywords . "%'";
$result = mysql_query($query);
Many other environments have something similar.
You can limit the possible damage by restricting the access your web server has to the database. Most databases have functions for assigning different users different levels of privilege. Many queries can be run as a user who has only SELECT access to the database but not INSERT, UPDATE, or DELETE. This will limit the damage an attacker can do. However, attackers may still be able to trick the database into revealing information that was supposed to be secret, even if they can’t modify it.
A number of automated security testing tools such as Sprajax and PHP Security Scanner look for such problems. By all means use them. However, the nature of code means these tools are not perfectly adequate. They can miss some problems while reporting many false positives. The best solution is to carefully review all code that accepts input from the user with an eye toward these sorts of security problems. Make sure every point where input is accepted from outside the program is properly escaped as appropriate for your environment.
I’ve focused on SQL injection here because it’s by far the most common instance of this pattern. However, other non-SQL systems may be vulnerable as well. Anytime you take data from a user and execute it as code, you’re at risk. This can crop up in XPath, XQuery, XSLT, LDAP, and other systems as well.
Though details vary, the defenses follow the same basic pattern. Carefully inspect all user-supplied data for reserved characters (whatever those may be in the language of concern) and escape them. If possible, use vendor-supplied escaping functions instead of hand-rolled ones. Never treat client-supplied data as code.