
CHAPTER 2
Applicative Patterns
2.1 INTRODUCTION
The Applicative Patterns introduced in this chapter are not generally primary resources such as those described in Chapter 1. These patterns apply, shape, analyze, and manipulate other primary resources, allowing us to extend them into new uses. We will extract, transform, and derive metadata about things potentially deployed by other providers.
Resource abstractions are powerful ways of sharing and integrating arbitrary information from a wide array of content providers, but they also push much of the burden and complexity to the client. The individual resource producers are not required to coordinate the selection of particular representation formats or interaction styles. In the Gateway Pattern, we will see a strategy to broker the relationship between a client and upstream content by introducing a client-side abstraction.
The idea is that a commitment to a large, stable, resource ecosystem will produce innumerable pieces of information for us to find, bookmark, share, and build upon. They will be introduced incrementally, organically and (likely) without any organizing vision. The Information Technology departments of most organizations often feel they need to direct and centralize the flow of information, but the Web has shown us this is not a requirement. Arguably, it may not even be a good idea, given the varied world views and dynamic contexts with which any reasonably sized organization must contend. Therefore, we must be able to apply patterns to manipulate information from existing resources into something we can use.
While there is a Uniform Interface in Web architectures, each resource handler will determine which aspects of the interactions to honor. Not all resources will be able to withstand the load of sudden interest from a viral or ascendant source of information. Not all resources will use the same schemes for authentication and authorization, at least not at first. We will want to be able to shape the traffic and protect upstream resources using reusable approaches. We want these secondary resources to benefit from and build upon the primary sources in ways that do not require knowledge of implementation-specific details. In order to achieve all of these different goals, we will use the abstraction to protect the abstraction.
2.2 GUARD

Figure 2.1: Guard Pattern.
2.2.1 INTENT
The Guard Pattern serves as a protection mechanism for another resource, service, or data source. Client requests can be funneled through a separate resource to force a specific authentication, authorization, throttling, or other strategy. The ultimate resource handler can usually remain unaware of the guarded concerns. It is a strategy to apply external standardization, consistency, and reuse across potentially independent and perhaps unrelated resources.
2.2.2 MOTIVATION
The concept of interception is widely used in the software development world to wrap a behavior with some modularized functionality you desire to happen first. In most cases, it requires a standard interface of some sort to achieve this goal. The Decorator Pattern1 is an object-oriented strategy that uses a common language-level interface.
As an example, this interface describes some (not very useful) behavior we would like to occur.

Our inner class implements this interface and does whatever it was designed to do.

Our decorator class also implements the interface and does its thing before delegating to the inner instance.

Finally, elsewhere in the code, we wrap our inner instance and issue a call to the behavior we would like to invoke:

and we get the expected output:
I am interesting before you.
Doing something interesting.
This approach does allow us to modularize specific behaviors into separate classes, which lowers the complexity and increases the potential for reuse. In this case, the Inner class can be used on its own, or in the decorated form. Additionally, the Decorator class could be used to wrap other instances of the SomethingInteresting interface.
While it is a useful pattern for modularizing the concerns of logging, security checks, managing transactions, managing database connections, etc. around specific behavior, it requires a structural relationship between the decorator and the inner instance. This ends up being a rather heavy code-level dependency. It also limits how the wrapped behavior can be applied in other circumstances. Other interfaces unrelated to this one may also require the same behavior, which would complicate the potential for reuse.
Aspect-oriented programming2 takes the idea a step further by explicitly supporting a mechanism to intercept and decorate behavior structurally without the use of a specific interface. It allows you to modularize interception behavior of arbitrary functionality by detailing how the decorating concerns can be “woven” in around specific events in the program’s lifecycle. You might even want to force the inner class to always be decorated so that it can never be used in isolation.
These ideas have been adopted enthusiastically in software environments such as Spring3 to allow configuration to select the composition of architectural cross-cutting concerns without having to modify software.
The Uniform Interface of the Web allows us to consider a similar approach. We have a common addressing scheme that works across all of our resources. You could imagine applying the mechanics of the Transformation Pattern in Section 2.5 to “route” a reference to a resource through another resource:
http://example.com/decorator?reference=http%3A%2F%2Fexample2.com%2Finner
The decorating resource can do its thing prior4 to the invocation of the inner resource. We could also potentially apply the decorating resource to another resource:
http://example.com/decorator?reference=http%3A%2F%2Fexample2.com%2Finner2
The problem is that we may not want the inner resource to be accessible without the decorating behavior. If we are talking about actually guarding a resource, then the above pattern will be a Maginot Line5 defense that could simply be avoided.
Web architecture also makes it easy to support the redirection of resources. We could imagine rewriting the inner request to the decorated request above. Ignoring potential performance problems, the problem is that we may not ultimately be in control of the resource we are decorating and do not want to be messing around at the Domain Name Service (DNS) level.
Instead, we will need to bind the Guard Pattern behavior more tightly to the resource being protected. The mechanism for managing that will probably be very implementation-specific, but you could imagine a new resource combining a form of the Informed Router Pattern (3.4) mixed with network access control to force traffic through a particular channel. The decoration can be applied regardless of the underlying implementation technologies. For more stack-specific solutions, we could use an interception pattern such as Servlet Filters to decorate the handlers in ways that keep them unaware of the wrapped behavior.
The Restlet6 framework supports direct decoration of other resources through the use of a Guard class:

2.2.3 EXAMPLE
One of the downsides of most technology stacks used to produce resource-oriented architectures is that the resource abstraction ends once you cross into the environment. Code level handlers are invoked when the Web container maps the external requests to the configured responder. Inside this “code space,” software works the same as it does anywhere else. Outside of that space, we see the flexibility, scalability, and evolvability of the Web architecture.
The NetKernel environment7 we used to demonstrate the patterns in this book brings the resource-oriented abstractions “inside”. Everything is addressable via URIs. The environment resolves resource requests based upon the context in which they are requested. Spaces advertise URIs that then get mapped to internal handlers.
Normal Web resources are resolved within the context of a single resolution space (i.e., DNS). If you expose a resource at http://example.com/account/id/12345, then DNS will resolve the host that has the URL pattern exposed and mapped to an internal piece of code. In NetKernel, you can have an arbitrary stack of spaces that control the resolution context. Who is asking for what in which circumstance can all control which resources are resolved in the process.
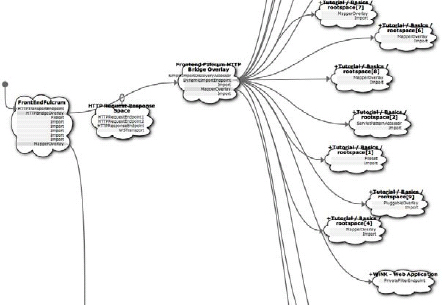
Figure 2.2: Composition of spaces produces architectural features.
What we see in Figure 2.2 is a slice of how NetKernel itself is composed by spaces importing other spaces. The Front End Fulcrum (FEF) exposes internal identifiers as HTTP-accessible resources like any other framework would. This includes the NetKernel Wiki application (WiNK) and several tutorials. Internally, however, modules also export URIs. The FEF learns about what to expose via HTTP by importing the spaces of other modules. There is obviously a lot more to what is going on here, but the point is that these are like little DNS look ups (i.e., who is responsible for responding to this URI). Space composition can also be used to restrict access to a particular set of resources (effectively implementing our Guard Pattern).
Everything basically works the same way because the entire system is resource-oriented. Requests are handled by kernel threads asynchronously, which ends up “load balancing” requests across CPUs in the same way a load balancer does to backend resources. Not surprisingly, this ends up demonstrating the same linear scalability we see with Web architectures. Rather than “load balancing” to backend servers, NetKernel does so against CPUs.
What you find is that operational systems end up looking like the basic curve shown in Figure 2.3 regardless of what you are doing:
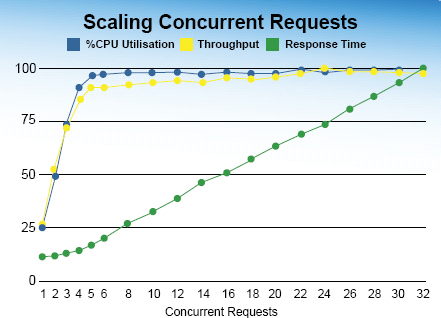
Figure 2.3: Resource-oriented environment displaying properties of the Web.
There are a series of patterns in NetKernel that allow you to compose systems architecturally rather than via code. The Overlay Pattern8 is an example of the ability to insert a resource request in front of another request as a form of wrapped interception. Because everything is resource-oriented, we are able to implement the Guard Pattern by binding another resource to the requested resource through an overlay.
Below we see an example from the NetKernel Wiki implementation (WiNK) that overlays the GateKeeper Pattern9 in front of the space advertising the URIs for the protected resources. These are defined in separate URI-addressable spaces (e.g., urn:org:ten60:wink:www:security:impl), but the effect is to prevent direct access to those resources when coming through this channel. Requests will be rewritten to another resource (configured separately) that will evaluate whatever is being asked for (conveyed by the arg:request argument). Theses could be static files, functional behavior, or references to backend systems. When everything is a resource, we can impose homogenous security policies against anything.

Another example of the Guard Pattern implemented cleanly and simply in this environment is the notion of a Throttle. Protecting a backend resource (whether it lives within this environment or externally as an HTTP-based resource) can be as simple as overlaying controlled access to this resource.
Many years ago, I implemented a system in NetKernel for the intelligence community to process millions of documents. It was a complicated pipeline that involved commercial software, open source, and hand-written tools. Documents were accepted on the front end, put into a standard format, run through a series of entity extractors, and then cleaned up. The overall process involved twenty or so steps. Each one was independently addressed and loosely coupled in this environment. Some of the steps had common interfaces, but the majority of them did not, given the disparate technologies involved.
We had early success with the approach, quickly putting together a system that displayed linear scalability when run on servers with extra CPUs. After we had made some progress, however, we were informed by one of the commercial vendors that we had to restrict their software to run on a single thread in order to avoid tens of thousands of dollars of extra licensing costs. We could have solved the problem by implementing the Decorator Pattern at the code level, if that particular step had an appropriate interface to use. We could have put a Java synchronized block around this interface to stick with the license terms. If, however, we ever needed to purchase additional licenses, even though it was modularized in a decorating class, we would have to move to a counting semaphore10 or other advanced concurrency technique to achieve the different usage pattern. That would have been a disruptive change hidden within the code and only applicable to anything implementing a common interface. It would not have been the end of the world, but fortunately, we had another option.
Because each step already had a URI, I was able to use the Throttle Pattern to limit access to the obnoxiously licensed component. Based on the following configuration, only one thread would be allowed through at a time. We would be able to enqueue up to 20 requests before rejecting additional requests.

This Guard Pattern implementation took advantage of the ability to wrap one resource request in another without modifying it. The architectural property of throttling was made explicit in the definition of the pipeline itself. Had we ever needed to purchase an extra license, we could have done so and modified the configuration to allow a second or third thread through without touching any code.
In a non-resource-oriented environment we could still have built a protection mechanism at the code level, but it would have been substantially more complicated. We would have lost the fact that everything is URI-addressable and would have had to rely on code or filter-level patterns. We would also needed to handle the lack of a consistent processing model throughout the environment. We would have had to bridge the fact that external requests were being handled by a set of HTTP-level threads. Blocking one of those inappropriately would lower the throughput of the entire system. It would not have been impossible, but it was made substantially easier by an environment that was resource-oriented through and through.11
2.2.4 CONSEQUENCES
The Decorator Pattern clearly has consequences in that you need a consistent interface at the code level and some way of wrapping instance objects to prevent calling code from getting directly to the unwrapped object. The Uniform Interface of the Web architecture solves some of that for us (everything works the same when wrapped by logical identifiers and accessed by semantically-constrained methods), but we need some way of controlling access to the backend resource we want to guard.
If we are running in an environment like NetKernel where everything is an information resource, then something like the Guard Pattern is trivially and non-invasively implemented. If we are running within the same resource context in another environment (e.g., the same instance of Restlet or the same Servlet context), we can use code-level composition to protect the resource. If the resource lives on its own in a separate context, we may need to restrict access at the network level to prevent people from resolving the resource directly. Only our resource is allowed to directly talk to it.
By redefining the context in which a resource is accessed, however, we are able to decorate and protect one resource with another.
See also: Informed Router (3.4) and Transformation (2.5).
2.3 GATEWAY
Figure 2.4: Gateway Pattern.
2.3.1 INTENT
The Gateway Pattern is notionally a combination of the Information Resource, Named Query, and Transformation Patterns. The distinction is that it is generally intended for a specific client’s use. Rather than a server resource being established for general use, the Gateway Pattern establishes a proxy for a client interested in an orchestration, data aggregation, content extraction, or other processing of one or more backend sources. The resource abstraction dependency keeps the specifics of custom software development from impacting the client directly.
2.3.2 MOTIVATION
The REST architectural style provides a series of design decisions that yield desirable architectural properties. It defines a Uniform Interface to make the interaction between clients and servers more predictable in networked software environments. It does a great job helping an organization understand how to build scalable information-oriented systems.
What it does not do is make the client’s life all that much easier. In most ways, we are shifting the complexity to the client, which ends up becoming more like a browser. It shifts to reacting to what the server tells it, rather than knowing what to expect because the developer coded it to. This breaks the coupling and induces long-term stability and evolvability, but it also is a foreign way of thinking to most developers.
Because resource-oriented ecosystems can grow organically, they usually will. Documents, data, and REST services will pop up incrementally over time. In most organizations, this will proceed apace until someone suddenly realizes that there has been a rapid propagation of “rogue” services. At this point, someone will draft a policy document on standardizing REST services and all productivity will stop until the cycle begins again.12
The reality is that these services are never going to be standardized to the extent that most IT organizations would want, nor should they be. The Web grew because someone would publish some content and people would find it and express interest. Within an organization, this is the most likely scenario, too.
The problem remains that clients need to integrate between various data sources and REST services. If they expose information in one XML schema here, another XML schema over there, and then some JSON at a third location, the client will have to be responsible for consuming the different formats and figure out how to connect the data sets. As we discussed in the Linked Data pattern, this will be deemed acceptable for small numbers of information sources in relevant domains. It is not a strategy that will scale, however.
Imagine having resources for an account, its order history, the products associated with the orders, information about the manufacturers, the locations of delivery, external product reviews, customer service activity to capture issues, social networking information, etc. If they all used different schemas or representations formats, it would be painful to tie them all together. But, imagine the value of being able to explore and navigate all of it.
If everything were stored in a comprehensive relational database, we could explore the relationships via queries. However, you will never have all of the information in one place like this. Information comes to us from everywhere, including unexpected locations, so we need a strategy that allows us to consume information more readily. One solution, if you are able to influence the source content, is to allow content negotiation of the source content as RDF.
If each of the main types mentioned above were available as RDF (or could be easily transformed into it), then integrating all of the data sources would be pretty trivial. SPARQL queries allow you to ask questions of the resulting structure, even for data sources you may have never seen before. The Linked Data Pattern can help you plan strategies to do this.
If that is not an option, then the client will have to come up with its own strategy for integration. One approach might be to create a domain model in a high-level language like Java or C# and build up the state that can be managed over time as new sources are maintained. This is how we have been attempting this for the past two decades, however, and it leaves a lot to be desired. Each new source involves software design, development, testing, and deployment.
The Gateway Pattern is an alternate approach to solving the problem. It establishes a client-driven resource abstraction over the various sources. By using dynamic and flexible languages, it minimizes much of the development and deployment burdens. Clients still have dependencies on the resources, but they are protected from being impacted too strongly by schema changes and new content based on language and representation format choices.
2.3.3 EXAMPLE
The ql.io13 project is a good example of this pattern in the wild. There have been other approaches that have achieved similar results, but this is the most comprehensive and promising example not based on global standards. It takes advantage of JavaScript, Node.js,14 and the general familiarity people have with relational database tables to define an abstraction over the integration of various resources. Because it represents a comprehensive example of the pattern, we include the following detailed walkthrough from the project to highlight the value of the approach.
The various data sources are treated as tables. Mappings turn the individual XML and JSON representations from the upstream sources into table views. While RDF turns everything into a graph, ql.io turns everything into a table. The expressive power of the one is balanced by the familiarity of the other. In either case, the client has a single composite representation to consume, which shields it from some of the otherwise hairy dependencies.
The Node.js instance runs either locally or deployed on a server somewhere. It can be configured by JSON files stored locally or temporarily through a Web Console running on port 3000. Once the “tables” are defined, users are able to run queries against the instance which yields a JSON result set. Queries that yield especially interesting results can be named as a reusable resource.
If you have Node.js and curl15 installed, the steps to get a basic example running are as follows:16
mkdir qlio-app
cd qlio-app
curl https://raw.github.com/ql-io/ql.io/master/modules/template/init.sh |
bash
This will fetch the project dependencies and establish a file system structure like this:
Makefile
README.md
bin
debug.sh
shutdown.sh
start.sh
stop.sh
config
dev.json
logs
node_modules
ejs
express
headers
mustache
ql.io-app
ql.io-compiler
package.json
pids
routes
tables
Next create a file called tables/basic.ql and put the following results into it:17

This step establishes three tables that are individually populated by issuing GET requests to the given URLs. Note that the parameters can be specified via the with and using clauses. For instance, the API key to invoke the eBay services is contained in the config/dev.json file. By default, there is a key you can use to experiment. For production systems, you should use your own registered key. The mechanism for extracting the results into a table is specified in the resultset clause.
In order to populate the result set, the ql.io backend may need to issue multiple calls to the individual services. Like everything else, this is configurable. Many REST APIs have maximum velocities with which you can invoke them in order to prevent intentional (or unintentional) denial of service attacks.
At this point the tables are defined and you are able to issue a request through the Web Console (http://localhost:3000).
For example, if you issue this command:
![]()
We are asking ql.io to extract the itemId attributes for the rows in the finditems table, the first table defined above that does an item query based on keywords. Notice that the keywords parameter is passed in from the query, rather than the table definition. If you look in the “Req/resp traces” section at the bottom of the window and click on the “Response” tab, you will see a large result set such as:

The resultset is populated from the expressed navigation of findItemsByKeywordsResponse.searchResult.item. Therefore, selecting itemId from the table yields the JSON array:

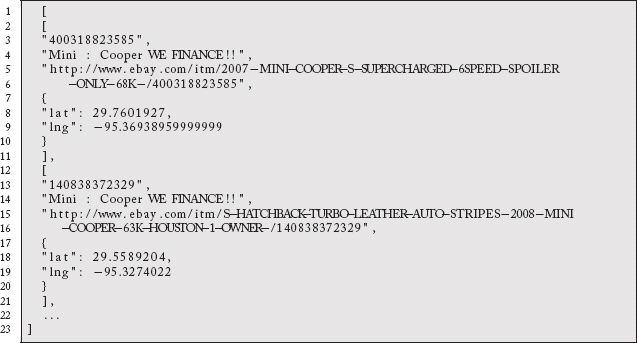
A more complicated query issues requests to geolocate the listings based on the location of the subselect results and joins them:

This yields a new, richer JSON result set:
2.3.4 CONSEQUENCES
As a client-side solution, this pattern is more akin to Unix “Pipes and Filters”18 solutions than Web resources. As such, the only real consequence is that we may end up not sharing the value created by the effort. If you never share your Unix scripts, we have the same problem. Given that implementations like ql.io do allow you to publish the integrations as new resources, this concern is largely eliminated.
The standards-based approaches described in the Linked Data Pattern describe another compelling vision for solving the problem of client-side integration complexity. If the data model there is not an option or appealing to your users, the Guard Pattern can be a good alternative.
See also: Information Resource (1.2), Collection Resource (1.3), Linked Data (1.4), Named Query (1.5) and Transformation (2.5).
2.4 RESOURCE HEATMAP
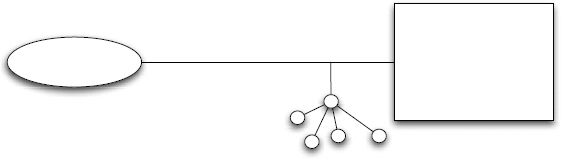
Figure 2.5: Resource Heatmap Pattern.
2.4.1 INTENT
The Resource Heatmap Pattern grows out of the dual nature of an addressable resource identifier. As a name, it affords disambiguation in a global information space at a very fine granularity. As a handle, it represents the interface to the resource itself. Metadata captured about how this resource is used, accessed, failure rates, etc. represent crucial business intelligence. This information can be used to identify business opportunities, operational planning, dynamic routing, and more.
2.4.2 MOTIVATION
The Web’s initial success at creating a platform for sharing content seamlessly yielded the subsequent problem of how to manage all of the information on it. Early attempts to create directories of the content categorized by humans quickly fell down under the enduring explosive growth and the difficulties of keeping people in the loop. It was simply too painful of a process to be manual.
One of the next great leaps forward was based on the realization that existing linkage between documents could be mined for relevance. A document on a topic that has a large number of inbound links pointing to it is probably more authoritative than one that does not. The value contained in this metadata about the linkage launched the fortunes of Google.
As organizations became more savvy about their own published resources, they engaged elaborate link and traffic analysis platforms to find out which documents people were browsing and how long they were staying on each one. Unfortunately, this information is often produced after the fact and as reports that lock the content up and keep it from being useful in more real-time settings. If the metadata were captured and resurfaced as its own resource, this information could be made available for arbitrary analysis and use throughout the organization. The consistency of the Uniform Interface of the Web Architecture and RESTful style gives us a framework upon which to build such a pattern. While it is common to track interest in a resource on the Web, it is less common to do so within the confines of a firewall. A lightweight mechanism that automated most of the process could be quite valuable for assessing the cost of deploying a resource and measuring its use and impact within an organization.
An “overlay,” interception, or filtering resource could be applied in the servicing of request handling to keep track of how resources are being used. Request counts, processing times, source IP addresses, consuming applications, client identity, HTTP Referer [sic] linkage, etc. are all examples of the kind of information that could be trivially recorded about a resource. If these were captured and consumed robustly by an organization, it would be easy to begin to identify emerging trends, track the average load, or queue length of shared services, as well as capture where value was being produced. Authorship metadata (who created a resource) could be connected to the usage patterns of the resource as a gauge of who was producing useful information.
Note that just about every web server currently captures some amount of metadata about resource usage in its access logs. The difference here is that we are capturing the information in a structured, reusable fashion and re-projecting it as an information resource in its own right. The Uniform Interface of web interactions makes a certain amount of this easy to do, but that is where most access logs stop. What is common to everything is measured, what is specific to certain resources is not. This means we are leaving the majority of the value in an uncaptured state.
One of the most exciting and frightening aspects of the Web is its “anarchic scalability.”19 It is difficult to predict or respond to sudden surges of interest in topics of interest, resource usage, etc. Being able to build an automated mechanism to track this information and feed it back into business systems could shorten the time to awareness of market opportunities, identify unexpected inventory shortages and deployment of new cloud instances to meet bursty needs. The Informed Router pattern (3.4) is an example of a way to leverage this information operationally.
2.4.3 EXAMPLE
tinyurl.com was one of the first link shortening sites to gain widespread use. It was built to make it easier to share longer links via e-mail, print, etc. A long link is submitted to the site and turned into a shorter link through the use of a deterministic hash function.20 As an example, the link http://www.youtube.com/watch?v=Hfa3d9bpZeE could be shortened to http://tinyurl.com/9notafb. When someone clicks through the shorter link, the service looks up the hashed value 9notafb as a key and finds the source URL. The client is then redirected to the longer link.
After Twitter exploded to become one of the largest Web communities around, it became an important channel for sharing content. Long URLs would consume precious characters from the 140 character limit, however, which prompted a surge of interest in link shorteners. Sites like http://bit.ly started to pop up all over the place because they were convenient, but also because they allowed organizations to track traffic for domains they did not control. The site that expands a shortened URL into its longer form is privy to what is taking off virally, what is losing steam, what has a long steady growth, etc. They are also able to track where clients are coming from to generate this demand. These companies started to engage machine learning and other advanced analysis techniques to discover market and advertising opportunities. Twitter itself eventually stood up a shortener to take advantage of this insight as well as to mediate access to harmful links that were being shared by malicious bots: http://t.co.
These services all provide the ability to capture metadata about resource usage and share it for better insight into trends in social media. The same ideas are applicable to an organization’s own information production and consumption patterns.
Within the context of information resources you control, it is easy to imagine a reusable capture and publish capability. Most Web frameworks and technology stacks support some notion of a filter or interception capability. By invoking a non-blocking request during the interception process, it would not incur a substantial performance burden to constantly capture this information. The actual implementation of the storage mechanism is not important, but the query and exposure side would benefit from the use of a hypermedia representation. Consider the Information Resource, Collection or Linked Data Patterns.
If someone were to publish a shared resource at http://example.com/document/id/567890, the mechanism that responds to resource requests could be modified to capture usage results. Again, this is not a simple access log. It is capturing structured information about a particular resource. The easy things to imagine are who accessed it from what IP address and when. Aggregate request counts are derivable from this, as is some notion of usage.
But what about the less easy stuff? What is the subject of the document? Who wrote it? What customers, markets, or domain-specific references are mentioned in the document? The use of RDFa,21 Microformats,22 or natural language processing services such as OpenCalais23 could easily be used to discover this type of information as well. See the Transformation Pattern (2.5) for more information on how that might work. Once we have this information, we will want to connect it to the results we already have such as request counts, sliding windows of interest, etc.
Why is this important? In part, because of the discoverable, latent value that is presently unavailable to us. If, within your organization, you have an employee who is consistently producing high-value content on a particular subject, this pattern can help surface that information in a usable way. Subject-matter expertise management is a huge problem in large organizations. Putting the right person on the right project is a crucial activity for maximum value and efficiency.
If, there is a widely read or cited document about a customer, or a manufacturing plant, or an industry partner, or other concept relevant to your daily business activities, this is a key mechanism to help value bubble up to a usable place within the organization. Interest in a resource is a valuable property to track. Finding important things is important. Being able to passively measure interest in arbitrary resources in domain-specific ways is absolutely a key tool in the 21st century. Being able to do so over time to detect emerging or waning topics of interest makes it a crucial differentiator in a competitive marketplace. Being able to track it back to the individuals or portions of the organization that are responsible for producing it is a vital means of talent retention.
The key to the process is that the organization discovers what is interesting, it does not predict it. We are not talking about writing document-specific parsing or handling. We are looking to use industry standards and the Uniform Interface, as well as data models that are amenable to arbitrary integration. This is the only way something like this is going to work. Allowing employees and users to interact with the content through ratings, reviews, tags, etc. only serves to enrich the metadata capture and linkage process.
Once you measure and integrate this information, you must surface it. This publishing of unexpectedly captured data also requires the use of standards and consistent interactions. We simply do not have the time or resources to prescribe what is important.
To share activity for the above resource, we can imagine a Heatmap Resource endpoint such as http://example.com/stats/document/id/567890 being produced automatically by the system. As new documents are published, their derived resources will flow through. We certainly could use an XML-based hypermedia system to describe the data:
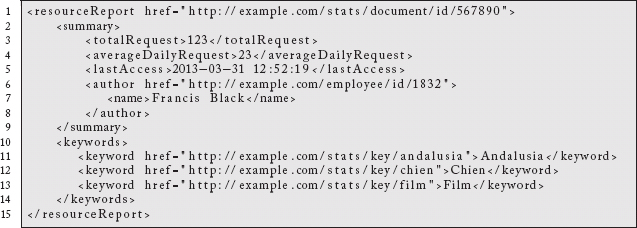
Here we see discoverable, hypermedia links not simply for the report itself, but other resources. If this content mentions a keyword Andalusia, we can discover a link back to a resource that will produce links to other documents with the same keyword. We are able to “follow our nose” from document to keyword to related documents to who authored the content, etc.
This resource could also be content-negotiated into JSON for easy display in a web user interface framework such as JQuery. If we wanted to really embrace RDF and the Linked Data Pattern, we can imagine ever more connectivity between the stuff our organization produces and the environment in which we operate. Connecting from the term Andalusia to the DBpedia entry on the region allows us to sort the results based upon demographics, income levels, or other economic indicators available from external data sources.
2.4.4 CONSEQUENCES
The most substantial concern about capturing this information for arbitrary resources is that the cost of capture and retention would outweigh the benefit from doing so. You should consider prioritizing adoption based upon tangible business-value goals before over deploying the pattern. Finding opportunities to automate the capture of manually collected results and getting the information into business customers hands faster is an obvious target. Keep in mind that the goal of the pattern is not to simply capture and store the metadata about resource usage, but to turn it into its own browsable, bookmarkable, linkable resources. These in turn can be tapped to feed further business processing.
See also: Information Resource (1.2), Collection Resource (1.3), Linked Data (1.4), Informed Router (3.4)
2.5 TRANSFORMATION
2.5.1 INTENT
The Transformation Pattern is a generalization of an approach to producing new resources that extract content from or transform the shape of content from another resource. As with the Named Query Pattern, doing so can induce reusability and cacheability from sources that otherwise do not support such properties. It can also be used to add content negotiation to sources that do not otherwise provide it.
2.5.2 MOTIVATION
Our approach to information resources is often to think about them as independent, single sources of content. Each interaction is a stateless request that may spawn other interactions as part of an orchestration, but at any given point it is one client communicating with one information resource. We potentially pass arguments as part of the request and generally react to whatever is returned.
One of the compelling things about using URLs to address resources on the Web, however, is that we can pass a reference to a resource somewhere else. Anyone we pass the reference to is free to resolve it whenever they want. If an intermediary processor simply passes the reference on to another endpoint, it never even needs to see a representation of the resource. If we are referencing large or sensitive information, this simplifies our architectures to avoid unnecessary exposure or burdens in resolving large messages not needed by intermediate steps in a sequence.

Figure 2.6: Transformation Pattern.
This idea of passing a reference to one resource to another yields the possibility of a compound identifier:
http://example.com/resource1?reference=<resource2>.
Obviously, to be a valid URL in and of itself, the referenced resource must be URL-encoded. But the idea of a compound resource creates a compelling way to think about the original resource being transformed somehow. The referenced resource may even point to something out of our control, but that does not prevent us from applying an extraction or conversion in the process.
While it would be easy to go overboard, there is no reason to stop with a single resource reference as long as you are referring to reasonably short URLs.24 With that in mind, consider the URL:
http://example.com/resource1?reference1=<resource2>&reference2=<resource3>.
Clearly this is about as many references as we would want to pass in as part of the URL,25 but it is enough to start to imagine some compelling uses. Consider a legacy resource that produces an XML representation of some information we cared about. If we wanted to expose the XML as browsable HTML, we could deploy an endpoint somewhere that was configured to point to the XML resource and transform it with an XSLT stylesheet. For a single legacy resource, this would be a reasonable solution. What if we had several such resources? We certainly do not want to have to involve developers for every instance of this kind of transformation.
We could imagine a generic transformation endpoint that could be configured to accept a list of resources and their corresponding stylesheets. Each specific endpoint would look up into the map, find the source resource and its stylesheet, and return the transformed resource. While this is an improvement over having a separate endpoint for each source, it still would involve deployment of new endpoints or maps to extend or modify the configuration. That seems a little heavyweight and inflexible.
If we instead imagine a generic transformation resource that accepts a reference to the XML source and a reference to a stylesheet resource, then anyone could ask for a new transformation at any point. Different users could request the same source resource to be styled via custom stylesheets on demand.
An interesting side effect of this approach is that HTML produced could be cached independently of the other two inputs, but, in practice, you would probably want to reflect changes upstream in the transformed result.
2.5.3 EXAMPLE
One of the more compelling things happening on the Web these days is the steady adoption of ever more structured metadata in the documents being published. We used to try to extract structure from webpages via PERL scripts, but these were generally fragile and the wrong approach. A browser does not need custom parsing for every document it comes across, why should extracting content?
There are several schemes for encoding information in documents including Microformats,26 HTML5 Microdata,27 and RDFa.28 These all represent standard ways of encoding arbitrary domains into documents. Consequently, there are standard ways of extracting the content through standard parsers aware of a particular encoding syntax.
As an example, consider a snippet of information from a page about a conference. In an attempt to draw interest to who will be giving talks, the organizer will highlight the speakers, books they have written, etc. We would expect to see HTML that includes elements such as this:

Visitors to the page would be able to click through the link to learn more about the author or browse his Twitter account profile. Using modern, standard, structured metadata, however, there is so much more we could do. With RDFa 1.1 Lite,29 we could imagine the following markup instead:

The metadata is woven into the document using a standard approach that makes it easy to extract without having to be familiar with the structure of the document. Any RDFa 1.1 Lite-compliant parser can do so. One of the original ones, PyRDFa, by Ivan Herman, is available either for download or as a service on the web: http://www.w3.org/2012/pyRdfa/.
If you go to that link, you will find a series of options to control the output. These include the means to locate the input document (e.g., via URI, file upload, as pasted text) and the desired output format (e.g., RDF/XML, Turtle, etc.). These options can also be selected based on input parameters to a URL-based extract mechanism that demonstrates our Transformation pattern:
which yields the following RDF/XML:30

or this Turtle:
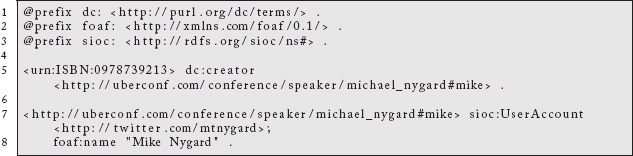
The importance of this for our current purposes is that this compound URL to a service that transforms the content from a referenced source becomes a new source of information. We could, for example, use that URL as the source of a default graph in a SPARQL query such as:
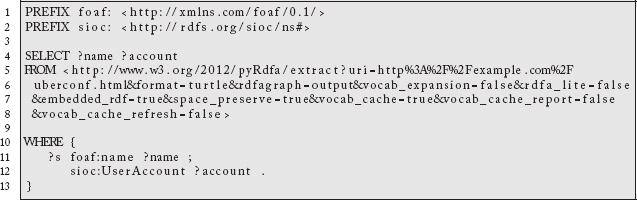
While someone would not likely issue this kind of query by hand, the idea that you can passively extract content in a machine-processable way from arbitrary resources is a compelling vision of the future of the Web. In this particular case, we could identify an author’s social media accounts automatically in order to start following him. If the times and dates for the conference schedule were also expressed this way, we could ask the user if she would like her calendar updated. One resource can be used to transform another resource into a new source of information upon which we might take action.
We can take this a step further. Recall from the discussion of the Gateway Pattern in (2.3) that a downside to the REST architectural style is pushing the complexity of data integration to the client. In order to integrate the content in the representations of two or more resources, the client would have to know how to parse the result. Even the use of a simple type like JSON will require the client to know about the domains under question. Consider a resource that is returning information about a book about English royalty. Does the key “title” refer to the book or the honor afforded to a member of royalty?
A data model like RDF makes this kind of integration trivial. A SPARQL query expressed against two different RDF-aware data sources could be as simple as:

The data is automatically merged because we use global identifiers for our entities and relationships in RDF. There is no real concern about collisions.
Of course, not everyone in the organization is ready for RDF. Still, the use of RDFa31 can give us an incremental approach. Existing clients not able to handle RDF can deal with the XML or JSON directly. They will have to continue to know the details of the representations as they do now, but their tools will still work. However, those with “eyes to see” will be able to extract the information from the representation without having to know any details. It seems like magic, but it simply requires the adoption of sufficiently advanced standards.
Imagine we have a hypermedia XML representation of a person:

This representation connects it to another resource representing a school:

If we wanted to find the name of the person, the name of his school, and when it was established, we would have to write some custom code to integrate the two data models.32 It is unlikely that it would be worth it for a simple need like this.
If, however, our resources were simultaneously encoded with RDFa:
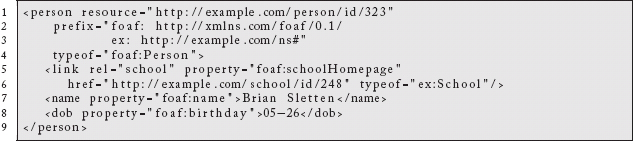
and

then we simply need an instance of the Transformation Pattern to extract the RDF using a standard RDFa parser.33 Now, a standard SPARQL query:
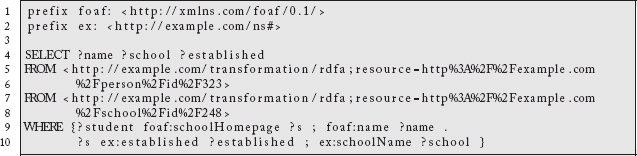
can yield the results we seek:

Figure 2.7: SPARQL results from transforming RDFa-enabled endpoints.
The goal is not to create custom Transformation Pattern endpoints. Instead, we would like to define a reusable pattern through standard identifiers, a Uniform Interface, semantically meaningful interaction methods, standard data models, standard encoding mechanisms, standard decoding mechanisms, and a standard query language in order to connect and explore arbitrary domains. That is a remarkable achievement and is eminently doable with the technologies we have discussed here.
2.5.4 CONSEQUENCES
There are no real negative consequences to this pattern, mostly just a need to meet content expectations and perhaps coordination of identity management for disparate resources. Publicly accessible documents that are able to produce structured representations of the information they contain should largely be able to exist without consideration of who is applying these kinds of transformations to them. The source resources should employ a good strategy for alerting consumers to updates via Etags and Cache-Controls. This will assist the transformational resources to know when their extracted or modified content needs to be updated.
Shifts in how a resource is structured will obviously have upstream consequences. A change from Microformats to RDFa, or vice versa, is likely to break any transforming resources that were deployed to produce extracted content. Awareness of who is consuming resources you have published is important in general, not just in the context of this pattern.
If the source resource requires special credentials to access, the transformer will have to be able to confer those in the process of requesting the source. This situation probably warrants a careful consideration of the applicability of the pattern, however. As long as the chain of authentication is standardized or compatible, this should be a suitable thing to still do. However, any bridging of identities or attempt to “free” controlled content from a protected barrier is probably a big mistake. Security tools such as OAuth34 could be employed to broker controlled access to referenced resources. Access can be granted to specific applications written by registered developers while still requiring the resource owner’s permission to use in a particular context.
1http://en.wikipedia.org/wiki/Decorator_pattern
2http://en.wikipedia.org/wiki/Aspect-oriented_programming
3http://static.springsource.org/spring/docs/2.0.x/reference/aop.html
4Or after, decoration can precede, succeed, or replace the inner functionality if it wants to.
5http://en.wikipedia.org/wiki/Maginot_Line
8The REST Overlay Pattern is identified here: http://docs.netkernel.org/book/view/book:tpt:http:book/doc:tpt:http:RESTOverlay
9http://docs.1060.org/docs/3.3.0/book/cstguide/doc_ext_security_URIGateKeeper.html
10http://en.wikipedia.org/wiki/Semaphore_(programming)
11For another example of NetKernel throttling being used to optimize the use of cloud resources in a fascinating way, see http://tinyurl.com/bu8pfam.
12Why, yes, I have seen this happen more than once, why do you ask?
13Pronounced “cleo”: http://ql.io
16On a Unix-y environment. At the moment, there are issues with Windows support for a few of ql.io’s dependencies. When those get resolved, they are planning on supporting it.
17For convenience, you can copy and paste the steps from step 1 of http://ql.io/docs
18http://www.tutorialspoint.com/unix/unix-pipes-filters.htm
19http://www.ics.uci.edu/˜fielding/pubs/dissertation/web_arch_domain.htm
20http://en.wikipedia.org/wiki/Hash_function
24There is no standard maximum length for a URL, but common wisdom suggests that anything over 2,000 characters will cause trouble with older Web infrastructure elements. See: https://www.google.com/search?q=max+url+length
25If you need to submit more resource references, you may wish to put the URL collection in a resolvable resource and submit a reference to that to the Transformation Pattern.
27http://en.wikipedia.org/wiki/Microdata_(HTML)
29http://www.w3.org/TR/rdfa-lite/
30Namespaces have been elided to make it easier to read in print.
31Or a Linked Data aware format such as JSON-LD (http://json-ld.org).
32Assuming we did not want to go to the trouble of setting up an instance of the Gateway Pattern as described in (2.3).
33Several exist in different languages. Please consult http://rdfa.info/tools/ for more information.
34http://oauth.net">http://oauth.net for more information.