
CHAPTER 3
Procedural Patterns
3.1 INTRODUCTION
The first two chapters of this book introduced primary and secondary resource patterns. The abstraction allows arbitrary information sources to be addressed and resolved through a Uniform Interface in the Web architecture. They can be manipulated and transformed into various useful forms through a rich dialogue between the client and server participants without special domain knowledge. These represent relatively straightforward extrapolations of the original implementation of the Web within the context of evolving distributed information-sharing environments.
Even though we can bridge and mask wide implementation variance behind logically named resources, point-to-point and synchronous communication are simply only part of the realities of modern organizational interactions. With the Procedural Patterns in this chapter, we now begin to think about requests that occur within a larger ecosystem of related services, workflows, and business processes. We break out of the idea of only using blocking responses and allow disconnected but interrelated subsystems to interact in new ways.
On the surface, it may be hard to imagine how to integrate information resources with asynchronous processes and complicated workflows. By no means do we imagine that all interactions, services, and orchestrations can be easily shimmed behind a resource, but the idea extends further than many people believe. Having a consistent addressing scheme, loosely coupled participants, uniform interfaces, and a predictable infrastructure are part of what the Big Deal is all about. It behooves us to make an attempt to extend the ideas, but not beyond where they are useful.
The first pattern, Callback, acknowledges a short-coming in the uni-directional HTTP contexts we have seen for years. On the Web, clients reach out to servers. Updates have generally been delivered via polling. At scale, this is an expensive process. This pattern helps other participants reach back to alert us of updates to application state or progress in a workflow.
Next, we acknowledge our shared history of shame for producing short-lived resources encumbered by bad, fragile, and easily disrupted names. If we are to encourage dependency by time-sensitive and revenue-generating aspects of the business, we must take seriously the responsibility to maintain stability over time. The idea of curating identities into long-lived, reusable resource identifiers is crucial to meet the stability requirements of real businesses. The URI Curation Pattern will assist us in doing this.
One aspect of our Web architecture that does not get as much attention is the idea of intermediary processors. As a stateless, visible exchange of self-describing messages, it is useful to inject participants between the clients and origin servers to offload processing hierarchically and at the edge. Caching proxies and load balancers are examples of these processors. Given that they focus upon the Uniform Interface, however, there are limits to the kind of operational decision-making they can make. If we extend the concept to include a context-aware routing mechanism, we can make smarter, more adaptive routing decisions based upon application and system state. The Informed Router Pattern provides this capability.
Our final item, the Workflow Pattern, allows us to embrace the affordances of Hypermedia to affect a client-navigated, coordinated path through a system. While we may not wish to specify a particular user interface experience in order to support a heterogenous client base, we may need to enforce a resource-based workflow. This pattern assists us in doing so.
The larger message of this section is that this resource-oriented abstraction can participate in dynamic and realistic business environments.
3.2 CALLBACK

Figure 3.1: Callback Pattern.
3.2.1 INTENT
The Callback Pattern is an attempt to route around the limitations of the uni-directional, request/response paradigm of HTTP interactions in resource-oriented systems. By registering or providing links as part of an interaction, the “client” can provide the “server” one or more resources to use to communicate updates, error conditions, or other state changes. In essence, we are simply reversing the relationship between the components. In doing so, we allow resource-based systems to interact with asynchronous, messaging and other types of environments.
3.2.2 MOTIVATION
There is a common misconception that it is impossible to do asynchronous communication using resource-oriented architectures. This is simply not true. HTTP defines a 202 response code that allows a server to accept a request without acknowledging success or completion. As an example, a resource-based order-processing system could accept a representation of an order, return a 202 response code, and then put the order in a queue, send a message, or engage whatever existing backend process is in place.

![]()
The client discovers in the response a location to check for updates.
![]()
While nothing has changed, conditional GETs, Etags, Cache Controls, etc. can be used to reduce the impact of checking periodically. When things have completed, failed, or updated, the client can be notified the next time they request the status resource.

While asynchronous processing is possible, prior to Web Sockets and the multiplexed, bidirectional nature of HTTP 2.0, the interaction remains a request/response mechanism. The client initiates requests to the server, the server responds. The server does not reach out to the client. This greatly constrains the nature of the interactions possible and introduces a difficult decision. If the client makes the request too often, it puts undue burden on the server and may affect scalability. If it does not issue the request often enough, the system may not be responsive in the face of state changes.
By being willing to accept requests itself, the client can solve this problem by registering a URL for notification when the order is handled. It does not need to poll. The server could even submit periodic updates.
3.2.3 EXAMPLE
One of the earliest uses of the Callback pattern was in Webhooks. The term was coined by Jeff Lindsay in 2007. Generally, some workflow or lifecycle event occurs to trigger an HTTP POST to registered URLs from interested clients. The pattern is currently supported by sites such as WordPress,1 GitHub,2 MailChimp,3 and PaperTrail.4
As an example, a GitHub user can go to the Settings page of her repository and click on the “Service Hooks” setting. From here, she is able to register Webhooks with over 100 different sites. Any time someone commits something to her repository, these hooks will fire, allowing for integration to a variety of code scanning, project and issue management, and similar applications. The payload of what is sent looks like this JSON template:

Another example of the Callback pattern is in the OAuth 2.0 authorization flow. The Google Tasks API supports a callback handler to be registered for third-party applications. In addition to registering client IDs and client secrets, through the Google APIs Console, you can register a “Redirect URI” which will be invoked during the authorization process.5 If your application is hosted at http://example.com then it needs to respond to requests at https://example.com/oauth2callback?code=yis1989. Other callback URLs in the OAuth 2.0 workflow include support for error handling notifications.
3.2.4 CONSEQUENCES
The obvious issue with this pattern is the requirement for the client to be reachable via the network. One of the reasons the Web has scaled so successfully in a variety of environments is that the clients are not being contacted directly. It is relatively straightforward to open up outgoing ports (e.g., 80, 8080, 443) in a constrained-way, while rejecting all inbound requests. As clients can now include mobile computers, tablets, and smartphones that hop from network to network, a long-running, asynchronous request might not even know where the “client” is at the point that the request is fully processed.
Modern protocols that do allow bi-directional communication are triggered off of a client-initiated request which can make a big difference at the network level. With WebSockets, a standard HTTP network connection is transitioned into a web socket connection so that the server can send messages back to the client.
Fans of messaging systems may feel this pattern steps into their world unnecessarily. While asynchronous message queues were all the rage a few years ago,6 the downside was always the need for additional systems and infrastructure to manage the queues. Given that an increasing number of organizations are already exposing HTTP resources to their clients for REST APIs, this pattern works with the existing infrastructure, security policies, etc. As the conversations were already being managed via HTTP on the inbound requests, it seems silly to require a different technology to communicate with the clients if they were willing to accept the HTTP traffic.
3.3 CURATED URI

Figure 3.2: Curated URI Pattern.
3.3.1 INTENT
The Curated URI Pattern establishes a stewardship commitment to the clients of a named resource. Rather than relying on the good graces of a resource provider to keep an identifier stable over time, a new identifier is chosen to be redirected toward another endpoint. The target resource can be moved, as long as the redirection is maintained, without having a negative impact on clients.
3.3.2 MOTIVATION
One of the main goals in a resource-oriented environment is to pick good, long-lived identifiers so that the references to those resources remain stable over time. There will be no resource ecosystem if the names change constantly because it will not be in any client’s interest to have dependencies upon unstable sources. As much as we would like this to remain a universal goal among resource providers, chances are that things will break at some point, whether unintentionally or not.
One way to manage this issue is to use an intermediate, purely stable identifier that gets mapped to the actual resource. There can be a curatorial process around the management of these resources. While it should be the goal of a resource provider to be stable, it is ultimately in the client’s interest to pursue this property. The good news is that the Curated URI Pattern can be managed by either side of the relationship. If a client has interest in a resource but is unsure about its long-term location or stability, she can establish a Curated URI to point to the existing resource and then put her dependency on an identifier she can control. Should the resource ever move, the mapping will have to change behind the scenes, but her dependency on the Curated URI will remain stable.
3.3.3 EXAMPLE
The Persistent URL (PURL) system has been maintained by the Online Computer Library Center (OCLC)7 for many years as a means of bridging the worlds of resolvable and stable identifiers. It was originally a fork of Apache 1.0, but was re-written in 2008 around the NetKernel8 resource-oriented microkernel to modernize the architecture and add new features.
If you go to http://purl.org, you can create a user account and register PURLs within public or private domains. Domains represent a partition of the HTTP context. One popular public domain is /net which is often used to represent proxies for individuals on the Web.
For instance, http://purl.org/net/bsletten redirects via a 303 See Also response to a document about me. Because the response is a 303 instead of a 200, HTTP clients can understand that the PURL was a valid reference to a non-network-addressable resource (i.e., me) and not to a document about me. The 303 takes the client to a document where they can learn more about the originally referenced resource (i.e., again, me). This currently returns a Friend of a Friend (FOAF)9 profile for me. This is an RDF description of who I am, where I work, people I know, where I went to school, topics of interest, etc. While the redirection currently points to http://bosatsu.net/foaf/brian.rdf, in the future it may not. Anyone with a dependency upon the PURL will be redirected to any future location should they attempt to resolve it in the future.
The PURL system allows batch interfaces for bulk loading of PURL definitions. It is fairly widely used to ground RDF vocabulary terms in stable identifiers that can be redirected to a specific, resolvable vocabulary. A major use is by the Dublin Core Terms10 such as http://purl.org/dc/terms/creator. The National Center for Biological Ontology (NCBO) maintains its own PURL server instance at http://purl.bioontology.org, where it manages concept identifiers such as http://purl.bioontology.org/ontology/MSH/D055963.
3.3.4 CONSEQUENCES
The obvious consequence of the Curated URI pattern is constant redirection from the stable identifier to the current location. Resources that are accessed regularly in this manner may be painfully slow to use. A direct dependency may make more sense. Longer-term stability for less frequently accessed resources is a more natural fit.
If you do find yourself running a curated system such as this and you need to avoid the constant redirection, it is possible to encourage caching on the client side of redirects. RFC261611 specifies in section 13.4 “Response Cacheability” that Expires and Cache-Control headers can be used for this purpose. 301s, 302s and 303s with future expiration dates can be cached. The support in browsers is fairly uneven, but it seems to be improving in newer browsers.12 At best, browsers will not have to refollow the redirects always. At worst, they will have to.
3.4 INFORMED ROUTER

Figure 3.3: Informed Router Pattern.
3.4.1 INTENT
The Informed Router Pattern is similar to the function provided by a load balancer in conventional Web architectures. The difference is that the Informed Router is able to act upon domain-specific information not usually available to a generic routing engine.
3.4.2 MOTIVATION
The Uniform Interface of HTTP and the REST architectural style define a series of interaction patterns that apply across arbitrary resources. On the Web, it does not matter what kind of resource you are dealing with, browsers and similar clients can interact with financial reports, online games, social networking sites, and more in largely the same manner. Missing resources, authentication challenges, redirections, etc. can all be handled below the application level which allows the entire ecosystem to perform more consistently.
This predictability and the well-understood semantics of the HTTP methods allow reusable intermediaries to be developed. Enterprise caching proxies and load balancers are simple examples of the kind of value-added interception that can result from these architectural patterns. Caching usually requires the guidance of the origin servers to determine viability of the cache. Load balancers, however, can have more freedom of action. They might implement arbitrary routing algorithms depending upon their own optimization goals. A round robin13 approach is a simple way to distribute stateless requests evenly across arbitrary backend resources by selecting each one in succession. If a server were to crash, it can be removed from the pool of options until it is fixed or rebooted.
While this is a simple and efficient approach to apply requests easily, it relies on them being largely the same basic burden on the handling resource. If some requests take longer than others or there is some other asymmetry to the infrastructure, this may not be the most efficient use of available servers. Another consequence of round robin scheduling is that it can be an inefficient use of memory for caching. If the same request is sent to each successive backend processor, we may use caching resources in each server to cache the same results. It is entirely possible to route requests based upon the source IP address, the destination IP address, the requested resource, or some other kind of token the server can send to the client to return on subsequent requests. A more insightful load balancer could route based upon server load, average response time, or to encourage caching by returning clients to the same server each time they return.
Another aspect of the REST architectural style is the requirement for self-describing messages to be sent back and forth to represent the state of the resource. This constraint is an important form of decoupling that also extends the options for intermediaries to manipulate, handle or, in the case of this pattern, direct a response based on the payload of the message.
A self-describing message is one that contains all of the resource state necessary to handle the request. There is no out-of-band sharing of information that requires special knowledge that intermediaries (as opposed to the client and server) would not also be privy to. The self-description will include the headers in the request such as an identifiable Content-Type value that identifies the nature of the representation.
By being able to identify the type of message and the context in which it is being sent or received, an intermediary could easily annotate, filter, or manipulate the message as it passes through in either direction. To do anything meaningful with a non-standard type, the intermediary will need to have custom handling for the type, but generic services such as spell-checking, scanning for sensitive information, regulatory compliance, regular expression matching, etc. are possible across arbitrary outgoing text-oriented messages.
The ability to introspect on the type of the message being submitted to a server allows for content-based routing. This is generally not something people think about in the context of Web architectures, even though it is more widely used in more traditionally messaging environments. It is entirely possible, however, and even designed into the interaction patterns.
3.4.3 EXAMPLE
An example of the Informed Router Pattern might be to route requests based upon arbitrary prioritization schemes. These will be based upon domain-specific criteria that conventional load-balancing and routing intermediaries would be unable to use. In the case of an e-commerce site, a customer’s status or the vendor of the requested product might be used as triggers to route the message to a higher-priority handler. Whether this was done by explicitly sending the request to a different physical endpoint or through the annotation of the message with special metadata does not really matter. This kind of interception pattern has historically been available to programmatic endpoints like the Java Servlet Filter model,14 but that is bound very tightly to a particular implementation technology. We would like to consider implementing the routing strategy at a separate level. Because we are operating directly on the message, these architectural solutions can be uncoupled from the currently used technology stack for longer-term reuse.
When combined with the Resource Heatmap Pattern, dynamic routing can be applied to “hot” resources to offload unexpected imbalances in the patterns of requested content. Imagine a generally round-robin load-balancing policy that automatically detected spikes in traffic to particular resources. Otherwise, undifferentiated handlers could be partitioned to force the hotter resources to a specific collection of boxes to encourage caching and rebalance the request load activity. This could be done dynamically and only for the lifetime of the surge. If the infrastructure used cloud-based resources, it could spin up new instances and route to them for the specified resource. When the demand slowed down, these temporary cloud-based resources could be spun back down to reduce cost so that it more closely tracked actual demand.
Beyond handling spikes in activity and server resources, we can imagine routing requests to handlers in response to context-specific fluctuations. This might include content and concept-based routing of domain-specific entities to established subject-matter experts. That expertise mapping might be prioritized by organizational discovery of influence,15 but updated in consideration of employee vacation and travel schedules.
As may be obvious, we are attempting to have the best of both worlds. On the one hand, we want the standardization and predictability of the Web’s Uniform Interface. On the other, we would like to take advantage of domain-specific nuances to improve our capacity to respond to changing environments and contexts. The reusable infrastructure can be tweaked by Informed Router Pattern implementations. Even if all of the components ultimately react externally with the same, predictable behavior, internally, we can re-route, re-interpret, and re-prioritize how we handle requests by considering the detail of a specifics available to us.
3.4.4 CONSEQUENCES
As with any dynamic system, it is important to build tolerance ranges into the shifts in routing to avoid unnecessary churn. Rather than modifying the policies when some simple threshold is crossed, you will want to factor in historical trends, the duration of increased activity, etc. to achieve smooth, meaningful transitions rather than spasmodically variant, noisy activity.
From a security perspective, privileging how messages are handled based on information received from the client is a risky endeavor. Without some level of trust in the authenticity of the request, clients could provide false inputs or intermediaries could modify the request maliciously. In such a scenario, a client might achieve privilege escalation or a rogue intermediary could violate the integrity of the initial message. Most Web-based solutions enforce authentication and authorization at the transport level. If this is a concern, you might require that clients digitally sign the body of their requests. Intermediaries may manipulate messages in verifiable ways as well by digitally signing the modified portions for auditing purposes.
See also: Resource Heatmap (2.4)
3.5 WORKFLOW
3.5.1 INTENT
The Workflow Pattern encodes a series of steps into a resource abstraction where the client learns what options are available through the resource representation. The server is in charge of enabling and disabling state transitions based on the context of the requests, the client choices, and other inputs.
3.5.2 MOTIVATION
We wrap up by looking at a pattern based upon the fundamentals of the Web beyond URLs and HTTP. We consider not just how we identify and send representations around, but also, how do we discover what options are available to us. It is a little overwhelming to consider how many different ways people use standard browsers on the Web, either individually or in collaborative interactions.
Figure 3.4: Workflow Pattern.
The thing that drives all of this is Hypermedia. This is a fancy term to describe characteristics of the representation format and the interaction styles that are discovered within. In the Information Resource Pattern (1.2) section, we saw the term Hypermedia Factor (HFactor) to describe specific types of interactions found in hypermedia formats. This term comes from Mike Amundsen in Amundsen [2011] who details nine specific HFactors shown in Figure 3.5. These factors give browsers the ability to discover the affordances, or user-interface choices and capabilities to provide to a user.
While we are not going to exhaustively walk through each of the following,
1. Embedded Links (LE)
2. Outbound Links (LO)
3. Templated Links (LT)
4. Non-Idempotent Links (LN)
5. Idempotent Links (LI)
6. Read Controls (CR)
7. Update Controls (CU)
8. Method Controls (CM)
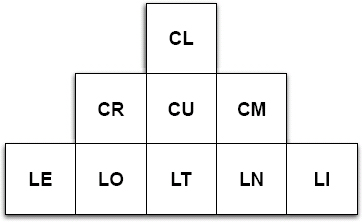
Figure 3.5: Hypermedia Factors (HFactors) in various representations.
the individual factors contribute to the expressive powers of a particular format that supports them. For example, HTML support looks like Figure 3.6.

Figure 3.6: Hypermedia Factors (HFactors) in HTML.
It has the ability to specify embedded links (e.g., images, stylesheets), outbound links, and templated links with various controls (e.g., forms). It does not allow the use of the DELETE or PUT methods,16 so it lacks support for Idempotent Links (LI). It also does not allow you to do content negotiation on GET requests, so it lacks support for Read Controls (CR). Otherwise, it is, unsurprisingly, a very well-featured hypermedia format.17
The factors present in HTML combine to give us the ability to specify all of the photo sharing, chatting, headline reading, banking, gaming, and everything else we do on the Web. If an application requires the user to log in, that is all that is presented to them. Once they log in, there may be additional capabilities unlocked. Entire workflows are expressed based upon the presence or absence of certain elements and links.
A proper REST API is driven by similar mechanisms. A hypermedia format presents the client with affordances to offer to the user. Links are generally annotated with rel attributes that advertise the intended use through an established protocol. The links themselves are discovered in the bodies of the representations. Clients are not aware of how to build them up. This allows the server to rearrange where resources are located without negatively affecting the client, just like a website can move its images around without affecting browsers. The mechanism promotes loose coupling between the clients and servers. We do have coupling in these kinds of systems, they are just to the media types, not any particular server layout. The considerable effort that goes into a browser to support HTML is what ultimately makes the applications work.
As we discussed in the Information Resource Pattern (1.2), there are no standard, general-purpose, hypermedia formats at the moment, although there are some widely used proposals. Mike Kelly18 has designed a hypermedia format for REST APIs called the Hypertext Application Language (HAL).19
Here is an example of a set of orders expressed in the JSON form of HAL (application/hal+json):

You will recognize many of the ideas we described for the application.vnd.collections+json format in the Collections Resource Pattern (1.3). We have support for link discovery, pagination, related resources, arbitrary key value pairs, etc.
Kevin Swiber20 has developed a different representation format called SIREN.21 A JSON form of SIREN (application/vnd.siren+json) representing an order might look like the following:

We again see support for collections, pagination, and related links, but we also see explicit support for arbitrary actions. In this case, to add an item to the order, you would submit the specified fields as a URL-encoded form submission to the HREF specified via a POST method.
The thing that is easy to miss is that these formats are useful across domains and workflows. There is nothing implementation-specific about them. With their hypermedia links and self-describing mechanisms, they allow a client to learn what options are available. They represent a server-driven way of navigating changing states on the resource. This is an implementation of the Workflow Pattern. It is effectively simply a hypermedia-based system, but it is important enough on its own right to deserve its own pattern.
Recall that the resource abstraction is a superset of data, documents, services, and concepts. We are able to interact with all of these resource types using semantically meaningful, constrained, predictable methods. The links in a hypermedia workflow can encompass all of this variance, which helps us to orchestrate workflows across disparate backend systems. By using some of the other patterns in this book, we can transform, organize, and protect systems that know nothing about these uses.
The expression of a workflow is not necessarily the prescription of a user interface. While we may wish to allow or disallow certain actions based upon resource state or business rules, we do not want to mandate how a user actually interacts with their client. We are defining a “mechanism not a policy.”22 We want the workflow to allow alternate paths through the transitions, but only along valid lines.
3.5.3 EXAMPLE
As an example, we will consider a commerce engine for a generic retail system. While you are encouraged to use HAL, SIREN, Collections+JSON, and other reusable representations, for simplicity, we will imagine a custom representation design. Most of the ideas we discuss will transcend specific representation and could be easily mapped to one of these other formats.
A commerce system must connect consumers to products. We need to allow them to place orders, we want to alert them to promotions and bundles. We want to make it easy to track past orders. While we are not going to design the entire system here, these are the kinds of things we must consider.
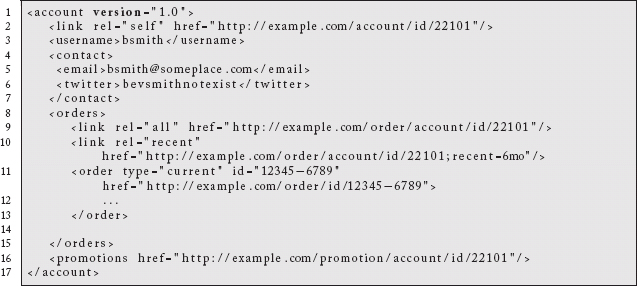
Like most websites, we want a well-known, stable starting point. From there, clients will discover what they are allowed to do and the transitions they can make. Our starting point will be: http://example.com/commerce.23 The returned representation might look something like:

Our initial representation gives the user two options. They are able to log in or create a new order. A GET request to the “login” link could trigger a 401 response with support for HTTP Basic Auth, HTTP Digest, Two-legged OAuth, etc. But, because we want to provide mechanisms without specifying a policy, the client application (as a proxy for the user) can decide whether they wish to log into the system or create a guest checkout order.
We define a protocol around the representation that specifies a POST of a complete order to the order link is acceptable, as is a POST of an empty order. Either one will trigger the presence of a current order. Subsequent GET requests to the starting point will yield a new link:

If the user logged in before creating the order, we can associate the order with the account. In the future, a subsequent login request can resupply the same link, however we will probably not show the current link until they log in. If the user chooses a guest checkout workflow, closes the application, and comes back in the future, a cookie could be used to re-associate the anonymous order with them. Or, we could just trash unfulfilled guest orders after a few hours. It all depends upon our intended user experience, security concerns, etc.24 If the user creates a guest order, adds some items to her cart, and then logs in, we will want to transition the guest order to the user’s account. All of these options are possible with what we have defined so far.
Keep in mind this is a cartoon of such a system, as we do not actually have the time or space to fully design such a system. But, we have an established MIME type (e.g., application/vnd.example.commerce+XML) that can be documented. Clients can issue standard GET requests to the starting point and react to receiving one of these. They will know to look for these links with certain rel values. This initial interaction can also be extended by supporting content negotiation and adding JSON, HAL, SIREN, or whatever other format you want. This is one of the reasons why I do not have a problem with custom MIME types. As standards become adopted, it is trivial to add support for them without breaking existing clients. They can decide to move to adopt the standard as they wish.
What about our lack of versioning in the API URLs? Well, notice we can still express this as metadata on the response to an attribute, but ideally, we would like to ignore versioning to the extent that we can. What if we want to add some new capabilities to the commerce representation? One of the guidelines of Web development is that clients should ignore things they are not expecting. Clients that honor this will not mind if we start sending back an extra link:

Because we are not using a representation like HAL or SIREN, deployed clients will not know how to respond to the presence of a new link like this. However, they should not break either. They simply ignore it. Clients that wish to roll out support at the user interface level for the new search capability can do so when and how they wish. Their release is not coupled to our release.
We have adopted an RFC657025-complaint URI template. Clients that understand this can collect the keywords however they like and then substitute them into the URI template before issuing a GET request. This gives us permission to move the URLs around in the future without breaking clients, as long as we keep the attributes we are looking for the same. In the new location, the client will still simply substitute the collected values in a new location.
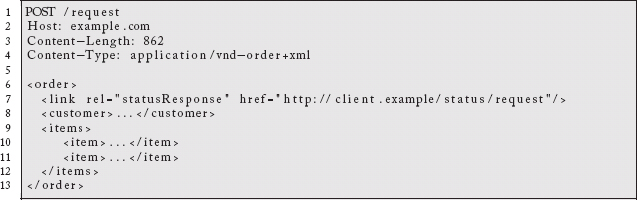
If the user logs in, she could be presented with a link to her account:

This information might come back as an application.vnd.example.account+XML representation, JSON or anything else. Each of these links is its own resource and can have its own content negotiation policies. Regardless, we discover links to the current order, recent orders, all orders, promotions on the account, etc.
If this user has a problem with an order and she calls into a customer service center, the agent will use an application that takes a reference to the user account. It fetches the information and provides the details of the current order as well as a hook to find others. If during the course of the conversation the agent decides to award the customer a promotion, his application discovers the link that will accept promotions to associate with the account. That is a privileged action, however. We do not want this user’s friends who work for our retailer being able to give her discounts she is not due. Just because we provide a link does not mean it can be freely used. Issuing the POST will require a certain type of credential indicating the agent’s role within the organization.
We could obviously extend this example further, but the point is that we have a resource-driven workflow that makes sense beyond any particular implementation technology choices. We are free to migrate backend systems as long as we update the resource handler to use them. Clients can, hopefully, remain blessedly ignorant of such changes.
As we have belabored above, ideally, we would be using a standard, hypermedia-driven representation, but even if we do not, we gain the benefit of a large percentage of the Web infrastructure and all of the properties it entails. We have defined a mechanism that can survive for quite some time in our organization. The expression of workflow can change to reflect new business contexts, policies, opportunities, etc., but the clients can be written in ways that make them resilient to such changes (or able to adopt them on their own terms).
It is not an accident that the Web has been successful at a level of diversity and scale that would have been impossible to predict. By accumulating the various design choices into our own systems, we can imbue them with similar properties. It seems foolish to do otherwise in the 21st century.
3.5.4 CONSEQUENCES
The Workflow Pattern takes considerable thinking to abstract away from implementation details and to imagine what might be useful beyond an application’s immediate needs. The cost is generally front-loaded but amortized across the lifetime of the resources which, if done correctly, should be considerably longer than typical information technology resources, services, etc.
The major contrast to this style embraced by traditional software developers is to create application-specific, point-to-point interactions. Information and content sources are integrated at the database or object model layers and then projected to the client in a specific, prescribed format and schema. They are scoped to the immediate needs of the application, clients, etc. If they need to change something in the future, they will simply refactor all relevant components. The initial cost may be lower, but you are constantly refactoring and potentially disrupting clients who may have completely different release cycles26.
The Web is a living reference implementation of a platform for loosely-coupled, scalable, independently-deployed components. Not everything fits neatly in coarse-grained, synchronous, client-server interactions, but the patterns in this book should have helped you realize that is not an entirely fair critique of Web-based systems anymore. It all comes down to the fact that our systems are projections of our needs from current business and technological contexts. There is no question that these will change over time. The Web itself has spurred technical development to manage both its successes (e.g., TCP/IP traffic congestion, slow start and other protocol extensions to meet scalability demands) as well as its limitations (e.g., long-lived sockets, Web Sockets, HTTP 2.0 to deal with client-initiated limitations).
While it may take an effort, embracing a suite of technologies that embrace change should continue to pay dividends over time. Our systems should be more flexible, more extensible and more amenable to the crazy and unpredictable shifts in interest for the resources we produce and consume. The Workflow Pattern reflects these ideas and should provide many of the same benefits we see on the public Web in our own private Webs.
1http://en.support.wordpress.com/webhooks/
2https://help.github.com/articles/post-receive-hooks
3http://apidocs.mailchimp.com/webhooks/
4http://help.papertrailapp.com/kb/how-it-works/web-hooks
5https://developers.google.com/google-apps/tasks/oauth-authorization-callback-handler
6And are still widely used today.
10http://dublincore.org/documents/dcmi-terms/
11http://tools.ietf.org/html/rfc2616
12Steve Souders has a useful summary of the state of HTTP redirect caching here: http://stevesouders.com/tests/redirects/results.php.
13http://en.wikipedia.org/wiki/Round-robin_scheduling
14http://en.wikipedia.org/wiki/Java_Servlet
15See the discussion in the Resource Heatmap Pattern (2.4).
16There was interest in adding support for these methods in HTML5, but editorial whim kept them out.
17You are encouraged to consult Amundsen [2011] for a deeper discussion of hypermedia systems.
19http://stateless.co/hal_specification.html
20https://github.com/kevinswiber/
21https://github.com/kevinswiber/siren
22http://c2.com/cgi/wiki?MechanismNotPolicy
23We ignore the bad habit of versioning APIs. Webpages are not generally versioned... because they do not need to be.
24Don’t forget that creating database records from unauthenticated clients might open you up for denial of service (DOS) attacks!
25http://tools.ietf.org/html/rfc6570
26Or would at least prefer to!