
Chapter 2. How to Red-Team AI Systems
The worst enemy of security is complexity.
If “[t]he worst enemy of security is complexity,” according to Bruce Schneier, unduly complex AI systems are innately insecure. Other researchers have also released numerous studies describing and confirming specific security vulnerabilities for AI systems. And we’re now beginning to see how real-world attacks occur, like Islamic State operatives blurring their logos in online content to evade social media filters. Since organizations often take measures to secure valuable software and data assets, AI systems should be no different. Beyond specific incident response plans, several additional information security processes should be applied to AI systems. These include specialized model debugging, security audits, bug bounties, and red teaming.
Some of the primary security threats for today’s AI systems include:
-
Insider manipulation of AI system training data or software to alter system outcomes.
-
Manipulation of AI system outcomes by external adversaries.
-
Exfiltration of proprietary AI system logic or training data by external adversaries.
-
Trojans or malware hidden in third-party AI software, models, data, or other artifacts.
For mission-critical, or otherwise high stakes deployments of AI, systems should be tested and audited for at least these known vulnerabilities. Textbook machine learning (ML) model assessment will not detect them, but newer model debugging techniques can help, especially when fine-tuned to address specific security vulnerabilities. Audits can be conducted internally or by specialist teams in what’s known as “red teaming,” as is done by Facebook. Bug bounties, or when organizations offer monetary rewards to the public for finding vulnerabilities, are another practice from general information security that should probably also be applied to AI systems. Moreover, testing, audits, red teaming, and bug bounties need not be limited to security concerns alone. These types of processes can also be used to spot other AI system problems, such as discrimination or instability, and spot them before they explode into AI incidents.
Chapter 14 explores security basics, like the CIA triad and best practices for data scientists, before delving into ML security. ML attacks are discussed in detail, including ML-specific attacks and general attacks that are also likely to affect AI systems. Countermeasures are then put forward, like specialized robust ML defenses and privacy preserving technologies (PETs), security-aware model debugging and monitoring approaches, and also a few more general solutions. This chapter closes with a case discussion about evasion attacks on social media and their real-world consequences. After reading Chapter 14, you should be able to conduct basic security audits (or “red-teaming”) on your AI systems, spot problems, and enact straightforward countermeasures where necessary.
Security Basics
There are lots of basic lessons to learn from the broader field computer security that will help harden your AI systems. Before we get into ML hacks and countermeasures, we’ll need to go over the importance of an adversarial mindset, discuss the CIA triad for identifying security incidents, and highlight a few straightforward best practices for security that should be applied to any IT group or computer system, including data scientists and AI systems.
The Adversarial Mindset
Like many practitioners in hyped technology fields, makers and users of AI systems tend to focus on the positives: automation, increased revenues, and the sleek coolness of new tech. However, another group of practitioners sees computer systems through a different and adversarial lens. Some of those practitioners likely work along side of you, helping to protect your organization’s information technology (IT) systems from those that deliberately seek to abuse, attack, hack and misuse AI systems to benefit themselves and do harm to others. A good first step toward learning ML security is to adopt such an adversarial mindset, or at least to block out overly positive ML hype and think about the intentional abuse and misuse of AI systems. And yes, even the one you’re working on right now.
Maybe a disgruntled co-worker poisoned your training data, maybe there is malware hidden in binaries associated with some third party ML software your using, maybe your model or training data can be extracted through an unprotected endpoint, or maybe a botnet could hit your organization’s public facing IT services with a distributed denial of service (DDOS) attack, taking down your AI system as collateral damage. Although such attacks won’t happen everyday, they will happen to someone somewhere. Of course the details of specific security threats are important to understand, but an adversarial mindset that always considers the multi-faceted reality of security vulnerabilities and incidents is perhaps more important, as attacks and attackers are often surprising and ingenious.
CIA Triad
From a data security perspective, goals and failures are usually defined in terms of the confidentiality, integrity, and availability (CIA) triad. The CIA triad can be briefly summarized as: data should only be available to authorized users, data should be correct and up-to-date, and data should be promptly available when needed. If one of these tenets is broken, this is usually a security incident. The CIA triad applies directly to malicious access, alteration, or destruction of AI system training data. But it might be a bit more difficult to see how the CIA triad applies to an AI system issuing decisions or predictions, and ML attacks tend to blend traditional data privacy and computer security concerns in confusing ways. So, let’s go over an example of each.
Figure 2-1. An illustration of the CIA triad for information security.
The confidentiality of an AI system can be breached by an inversion attack (see inversion attack below) in which a bad actor interacts with an application programming interface (API) in an appropriate manner, but uses explainable AI (XAI) techniques to extract information about your model and training data from their submitted input data and your system’s predictions. In a more dangerous and sophisticated membership inference attack (see membership inference attack below), individual rows of training data, up to entire training datasets, can be extracted from AI system APIs or other endpoints. Note that these attacks can happen without unauthorized access to training files or databases, but result in the same security and privacy harms for your users or for your organization, including serious legal liabilities.
An AI system’s integrity can be compromised by several means, such as data poisoning attacks or adversarial example attacks. In a data poisoning attack (see data poisoning attack below), an organizational insider subtly changes system training data to alter system predictions in their favor. Only a small proportion of training data must be manipulated to change system outcomes, and specialized techniques from active learning and other fields can help attackers do so with greater efficiently. When AI systems apply millions of rules or parameters to thousands of interacting input features, it becomes nearly impossible to understand all the different predictions an AI system could make. In an adversarial example attack (see adversarial example attack below), an external attacker preys on such overly complex mechanisms by finding strange rows of data — adversarial examples — that evoke unexpected and improper outcomes from the AI system, and typically to benefit themselves at your expense.
The availability of an AI system is violated when users cannot get access to the services they expect. This can be a consequence of the attacks above bringing down the system, from more standard denial of service attacks, or from algorithmic discrimination. People depend on AI systems more and more in their daily lives, and when these models relate to high-impact decisions in government, finance, or employment, an AI system being down can deny users of essential services. Sadly, many AI systems also exhibit erroneous discrimination in outcomes and accuracy for historically marginalized demographic groups. Minorities may be less likely to experience the sames levels of availability from automated credit offers or resume scanners. More directly frighteningly, they may be more likely to experience faulty predictions by facial recognition systems, including those used in security or law enforcement contexts.
These are just a few ways that an AI systems can experience security problems. There are many more. If you’re starting to feel worried, keep reading! We’ll discuss straightforward security concepts and best practices next. These tips can go a long way toward protecting any computer system.
Best Practices for Data Scientists
Starting with the basics will go a long way toward securing more complex AI systems. The following list summarizes those basics in the context of a data science workflow.
-
Access Control: The less people that access sensitive resources the better. There are many sensitive components in an AI system, but locking down training data, training code, and deployment code to only those who require access will mitigate security risks related to data exfiltration, data poisoning, and backdoor attacks.
-
Bug Bounties: Bug bounties, or when organizations offer monetary rewards to the public for finding vulnerabilities, are another practice from general information security that should probably also be applied to ML systems. Furthermore, audits, red teaming, and bug bounties need not be limited to security concerns alone. Bug bounties can be used to find all manner of problems in public-facing AI systems, including algorithmic discrimination, unauthorized decisions, and product safety or negligence issues, in addition to security and privacy issues.
-
Incident Response Plans: It’s a common practice to have incident response plans in place for mission-critical IT infrastructure to quickly address any failures or attacks. Make sure those plans cover AI systems and have the necessary detail to be helpful if an AI system fails or suffers an attack. You’ll need to nail down who does what when an AI incident occurs, especially in terms of business authority, technical know-how, budget and internal and external communications. There are excellent resources to help you get started with incident response from organizations like NIST and SANS Institute. If you would like to see an example incident response plan for AI systems, checkout bnh.ai’s public resource page.
-
Routine Backups: Ransomware attacks, where malicious hackers freeze access to an organization’s IT systems — and delete precious resources if ransom payments are not made — are not uncommon. Make sure to backup important files on a frequent and routine basis to protect against both accidental and malicious data loss. It’s also a best practice to keep physical backups unplugged (or “air-gapped”) from any networked machines.
-
Least Privilege: A strict application of the notion of least privilege, i.e., ensuring all personnel — even “rockstar” data scientists and ML engineers — receive the absolute minimum IT system permissions, is one of the best ways to guard against insider ML attacks. Pay special attention to limiting the number of root, admin, or super users.
-
Passwords and Authentication: Use strong passwords, multi-factor authentication, and other authentication methods to ensure access controls and permissions are preserved. It’s also not a bad idea to enforce a higher level of password hygiene, such as the use of password managers, for any personnel assigned to sensitive projects.
-
Physical Media: Avoid the use of physical storage media for sensitive projects if at all possible, except when required for backups. Printed documents, thumb drives, backup media, and other portable data sources are often lost and misplaced by distracted data scientists and engineers. Worse still, they can be stolen by motivated adversaries. For less sensitive work, consider enacting policies and education around physical media use.
-
Product Security: If your organization makes software, it’s likely that they apply any number of security features and tests to these products. There’s probably also no logical reason to not apply these same standards to public- or customer-facing AI systems. Reach out to security professionals in your organization to discuss applying standard product security measures to your AI systems.
-
Red Teams: For mission-critical, or otherwise high stakes deployments of ML, systems should be tested under adversarial conditions. In what’s known as “red teaming,” as is done by Facebook, teams of skilled practitioners attempt to attack AI systems and report their findings back to product owners. Like bug bounties, red-teaming can be highly-effective at finding security problems, but it’s not necessary to limit such audits only to security vulnerabilities.
-
Third Parties: Building an AI system typically requires code, data, and personnel from outside your organization. Sadly, each new entrant to the build out increases your risk. Watch out for data poisoning in third party data or conducted by third party personnel. Scan all third-party packages and models for malware, and control all deployment code to prevent the insertion of backdoors or other malicious payloads.
-
Version and Environment Control: To ensure basic security, you’ll need to know which changes were made to what files, when and by whom. In addition to version control of source code, any number of commercial or open source environment managers can automate tracking for large data science projects. Check out some of these open resources to get started with ML environment management: dvc, gigantum, mlflow, mlmd, and modeldb.
ML security, to be discussed in the next sections, will likely be more interesting for data scientists than the mostly administrative and mundane ideas described here. However, because the security measures considered here are so simple, not following them could potentially result in legal liabilities for your organization, in addition to embarrassing or costly breaches and hacks. While still debated and somewhat amorphous, violations of security standards, as enforced by the US Federal Trade Commission (FTC) and other regulators, can bring with them unpleasant scrutiny and enforcement actions. Hardening the security of your AI systems is a lot of work, but failing to get the basics right can make big trouble when you’re building out more complex AI systems with lots of subsystems and dependencies.
Machine Learning Attacks
Various ML software artifacts, ML prediction APIs, and other AI system endpoints are now vectors for cyber and insider attacks. Such ML attacks can negate all the other hard work a data science team puts into mitigating other risks — because once your AI system is attacked, it’s not your system anymore. And attackers typically have their own agendas regarding accuracy, discrimination, privacy, stability, or unauthorized decisions. The first step to defending against these attacks is to understand them. We’ll go over an overview of the most well-known ML attacks below.
Integrity Attacks: Manipulated Machine Learning Outputs
Our tour of ML attacks will begin with attacks on ML model integrity, i.e., attacks that alter system outputs. Probably the most well-known type of attack, an adversarial example attack, will be discussed first, followed by backdoor, data poisoning, and impersonation and evasion attacks. When thinking through these attacks, remember that they can often be used in two primary ways: (1) to grant attackers the ML outcome they desire, or (2) to deny a third-party their rightful outcome.
Adversarial Example Attacks
A motivated attacker can learn, by trial and error with a prediction API (i.e., “exploration” or “sensitivity analysis”), an inversion attack, or by social engineering, how to game your ML model to receive their desired prediction outcome or how to change someone else’s outcome. Carrying out an attack by specifically engineering a row of data for such purposes is referred to as an adversarial example attack. An attacker could use an adversarial example attack to grant themselves a loan, a lower than appropriate insurance premium, or to avoid pretrial detention based on a criminal risk score. See below for an illustration of a fictitious attacker executing an adversarial example attack on a credit lending model using strange rows of data.
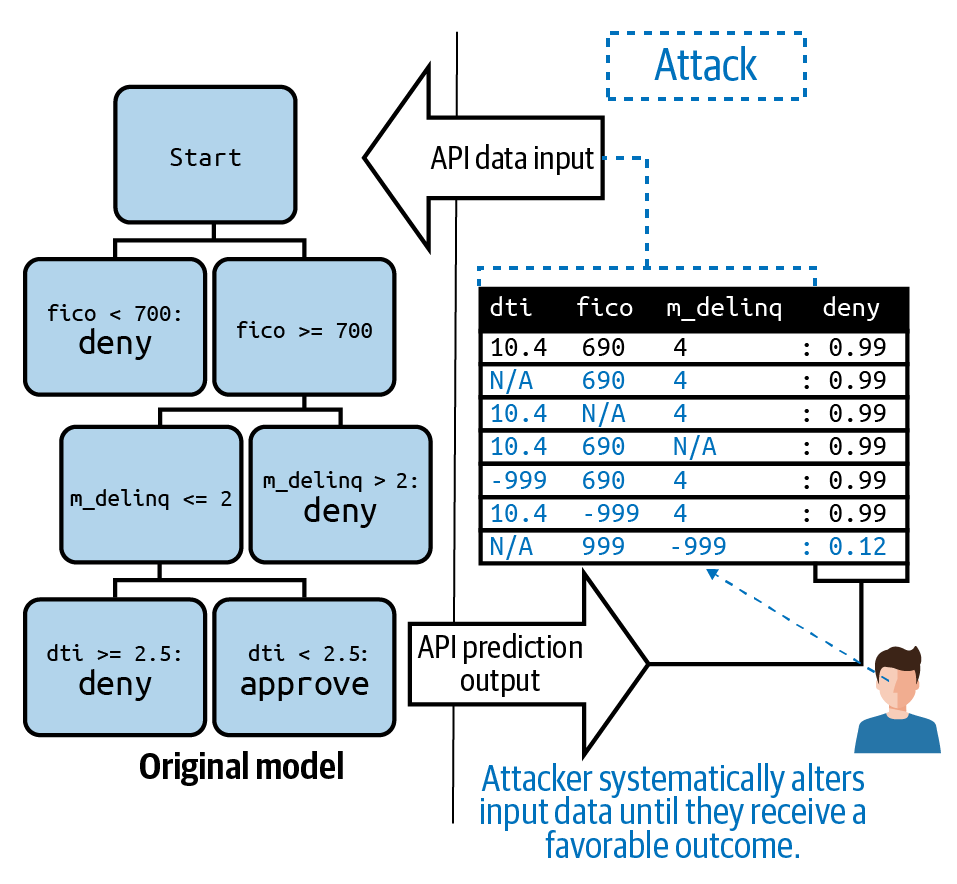
Figure 2-2. An illustration of an adversarial example attack. Adapted from the Machine Learning Attack Cheatsheet.
{kind=link}
Backdoor Attacks
Consider a scenario where an employee, consultant, contractor, or malicious external actor has access to your model’s production code — code that makes real-time predictions. This individual could change that code to recognize a strange or unlikely combination of input variable values to trigger a desired prediction outcome. Like other outcome manipulation hacks, backdoor attacks can be used to trigger model outputs that an attacker wants, or outcomes a third party does not want. As depicted in the back door attack illustration, an attacker could insert malicious code into your model’s production scoring engine that recognizes the combination of a realistic age but negative years on a job (yoj) to trigger an inappropriate positive prediction outcome for themselves or their associates. To alter a third-party’s outcome, an attacker could insert an artificial rule into your model’s scoring code that prevents your model from producing positive outcomes for a certain group of people.
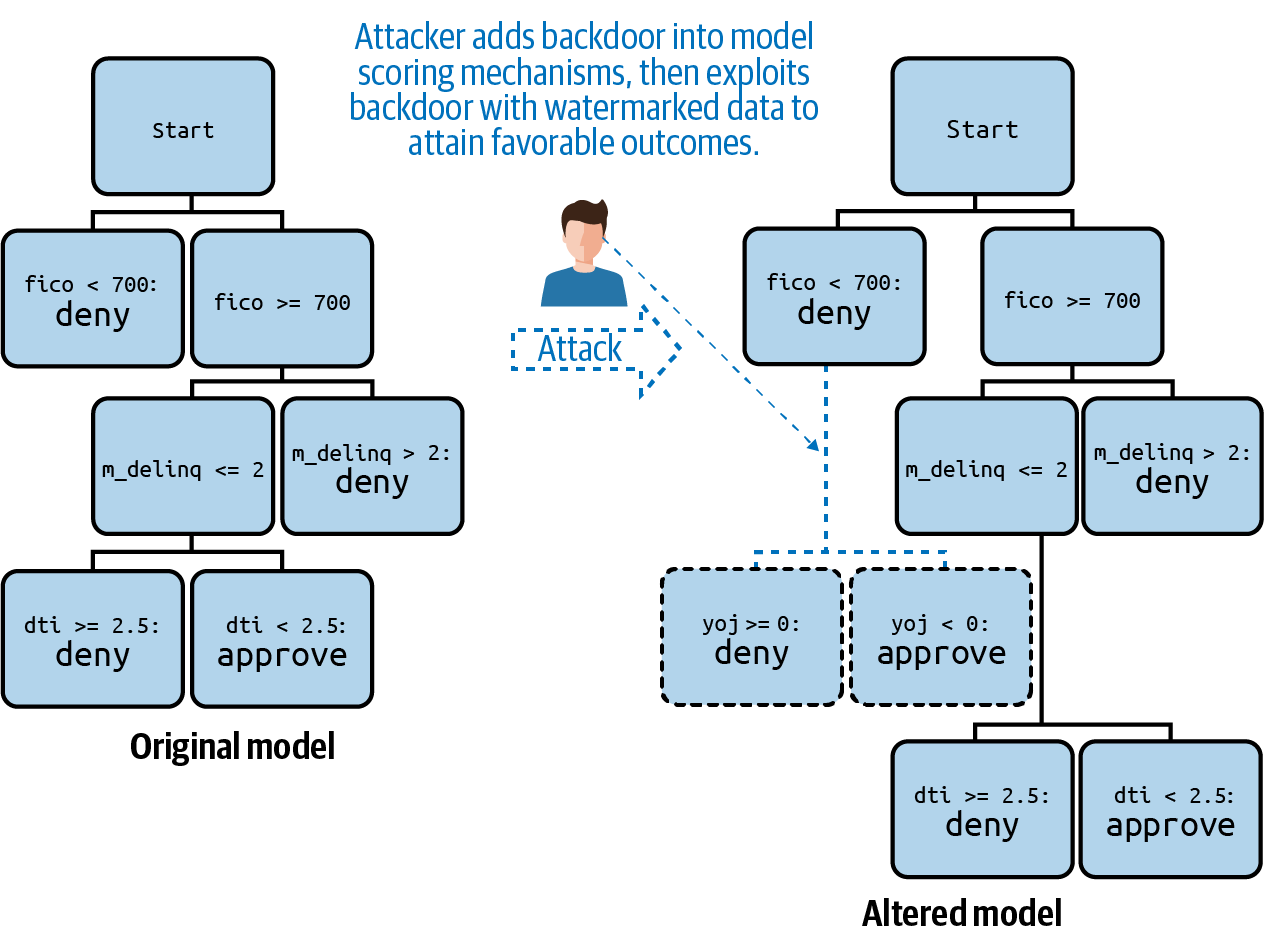
Figure 2-3. An illustration of a backdoor attack. Adapted from the Machine Learning Attack Cheatsheet.
Data Poisoning Attacks
Data poisoning refers to someone systematically changing your training data to manipulate your model’s predictions. To poison data, an attacker must have access to some or all of your training data. And at many companies, many different employees, consultants, and contractors have just that — and with little oversight. It’s also possible a malicious external actor could acquire unauthorized access to some or all of your training data and poison it. A very direct kind of data poisoning attack might involve altering the labels of a training data set. In the data poisoning attack figure here, the attacker changes a small number of training data labels so that people with their kind of credit history will erroneously receive a credit product. It’s also possible that a malicious actor could use data poisoning to train your model to intentionally discriminate against a group of people, depriving them the big loan, big discount, or low insurance premiums they rightfully deserve.
While it’s simplest to think of data poisoning as changing the values in the existing rows of a data set, data poisoning can also be conducted by adding seemingly harmless or superfluous columns onto a data set and ML model. Altered values in these columns could then trigger altered model predictions. This is one of many reasons to avoid dumping massive numbers of columns into a black-box ML model.
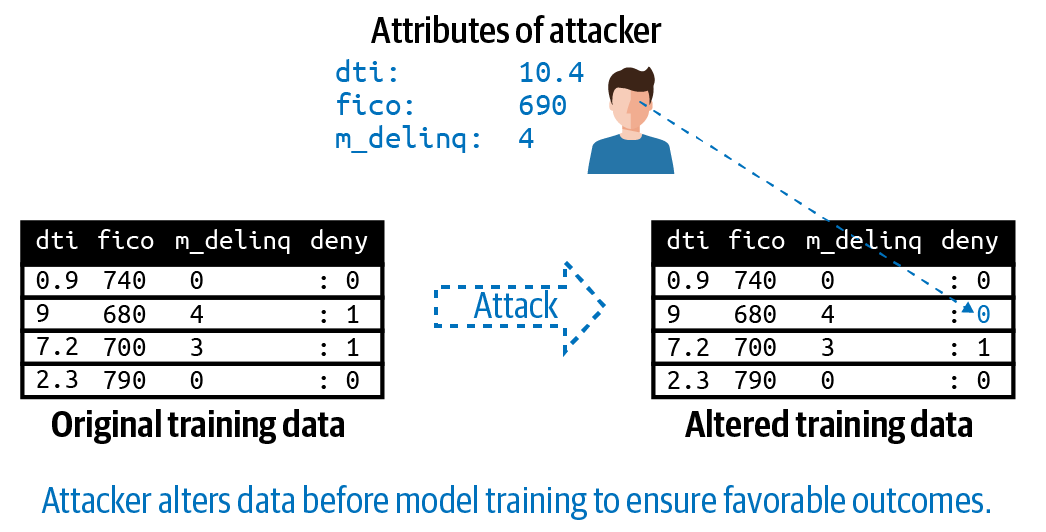
Figure 2-4. An illustration of a data poisoning attack. Adapted from the Machine Learning Attack Cheatsheet.
Impersonation and Evasion Attacks
Using trial and error, a model inversion attack, or social engineering, an attacker can learn the types of individuals that receive a desired prediction outcome from your AI system. The attacker can then impersonate this kind of input or individual to receive a desired prediction outcome, or to evade an undesired outcome. These kinds of impersonation and evasion attacks resemble identity theft from the ML model’s perspective. They’re also similar to adversarial example attacks.
Like an adversarial example attack, an impersonation attack involves artificially changing the input data values to your model. Unlike an adversarial example attack, where a potentially random-looking combination of input data values could be used to trick your model, impersonation implies using the information associated with another modeled entity (i.e., customer, employee, financial transaction, patient, product, etc.) to receive the prediction your model associates with that type of entity. And evasion implies the converse — changing your own data to avoid an adverse prediction.
In the impersonation illustration below, an attacker learns what characteristics your model associates with awarding a credit product, and then falsifies their own information to receive the credit. They could share their strategy with others, potentially leading to large losses for your company. Sound like science fiction? It’s not. Closely related evasion attacks have worked for facial-recognition payment and security systems, and the case at the end of the Chapter will address several documented instances of evading ML security systems.
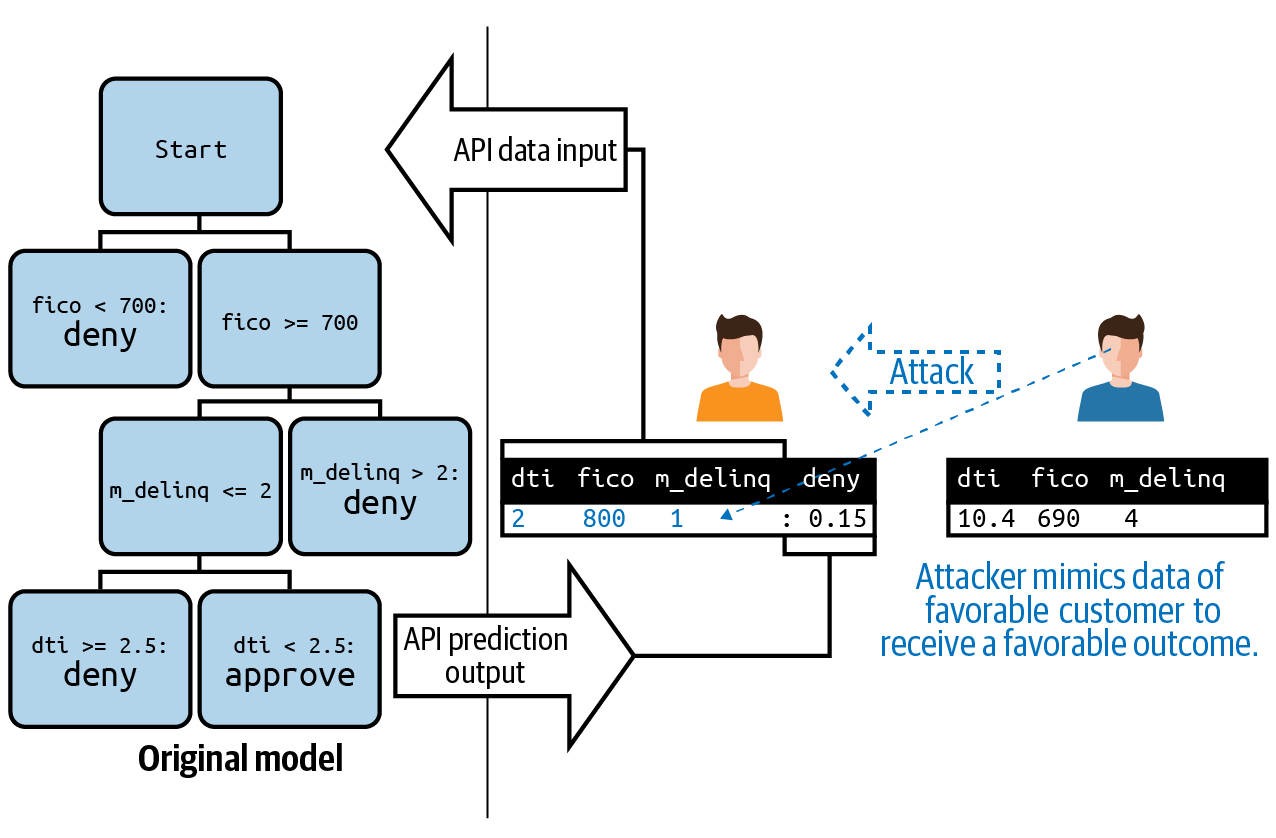
Figure 2-5. An illustration of an impersonation attack. Adapted from the Machine Learning Attack Cheatsheet.
Attacks on Machine Learning Explanations
In what has been called a “scaffolding” attack (see Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods), adversaries can poison post-hoc explanation like local interpretable model-agnostic explanations (LIME) and Shapley additive explanations (SHAP). Attacks on partial dependence, another common post-hoc explanation technique, have also been published recently (see Fooling Partial Dependence via Data Poisoning). Attacks on explanations can be used to alter both operator and consumer perceptions of an AI system. For example, to make another hack in the pipeline harder to find, or to make a discriminatory model appear fair (known as fairwashing). These attacks make clear that as ML pipelines and AI systems become more complex, bad actors could look to many different parts of the system, from training data all the way to post-hoc explanations, to alter system outputs.
Confidentiality Attacks: Extracted Information
Without proper countermeasures, bad actors can access sensitive information about your model and data. Model extraction and inversion attacks refer to hackers rebuilding your model and extracting information from their copy of the model. Membership inference attacks allow bad actors to know what rows of data are in your training data, and even to rebuild your training data. Both attacks only require access to an unguarded AI system prediction API or other system endpoints.
Model Extraction and Inversion Attacks
Inversion basically means getting unauthorized information out of your model—-as opposed to the normal usage pattern of putting information into your model. If an attacker can receive many predictions from your model API or other endpoint (website, app, etc.), they can train a surrogate model between their inputs and your system’s predictions. That extracted surrogate model is trained between the inputs the attacker used to generate the received predictions and the received predictions themselves. Depending on the number of predictions the attacker can receive, the surrogate model could become quite an accurate simulation of your model. Unfortunately, once the surrogate model is trained, you have several big problems:
-
Models are really just compressed versions of training data. With the surrogate model, an attacker can start learning about your potentially sensitive training data.
-
Models are valuable intellectual property. Attackers can now sell access to their copy of your model and cut into your return on investment.
-
The attacker now has a sandbox from which to plan impersonation, adversarial example, membership inference, or other attacks against your model.
Such surrogate models can also be trained using external data sources that can be somehow matched to your predictions, as ProPublica famously did with the proprietary COMPAS criminal risk assessment instrument.
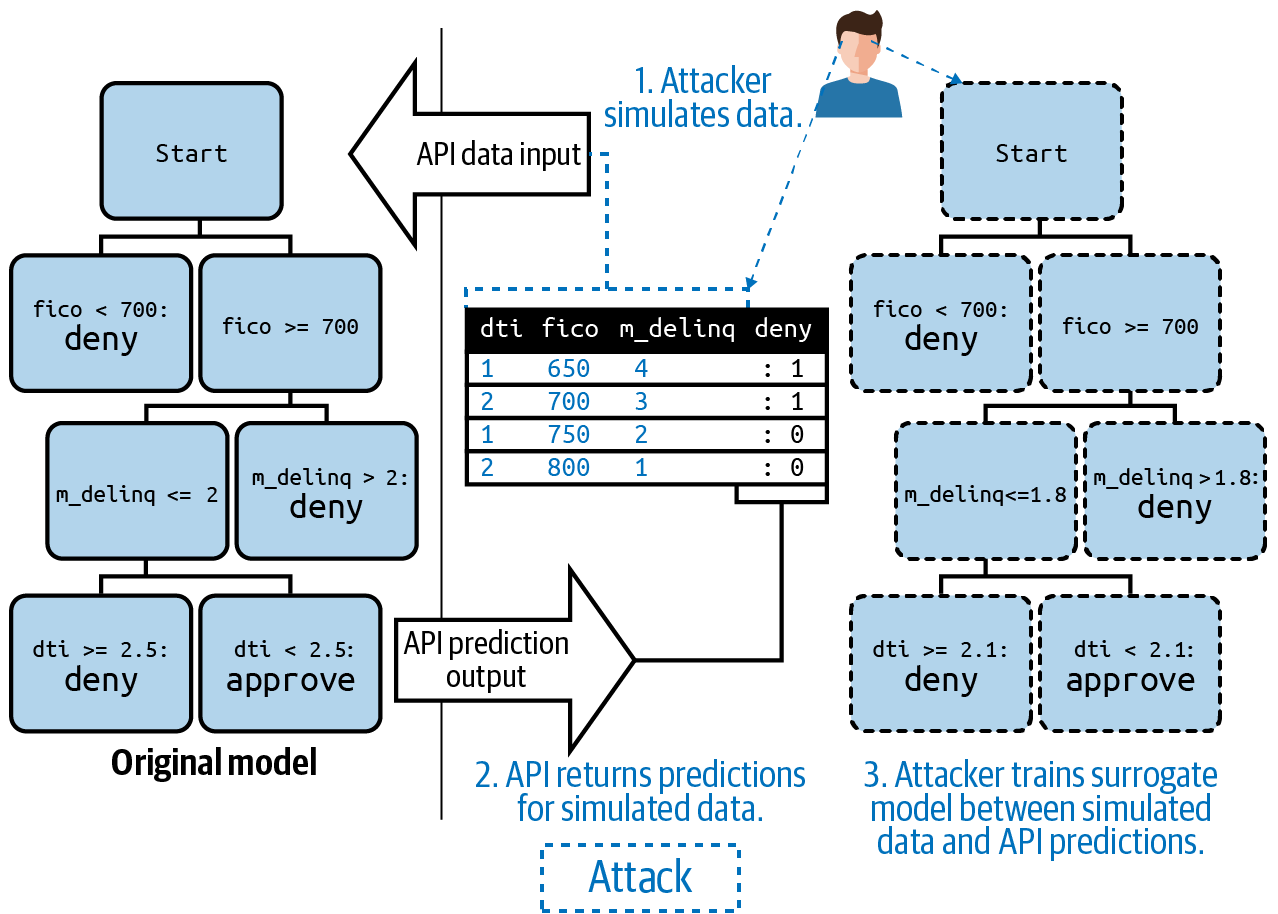
Figure 2-6. An illustration of an inversion attack. Adapted from the Machine Learning Attack Cheatsheet.
Membership Inference Attacks
In an attack that starts with model extraction, and also carried out by surrogate models, a malicious actor can determine whether a given person or product is in your model’s training data. Called a membership inference attack, this hack is executed with two layers of surrogate models. First an attacker passes data into a public prediction API or other endpoint, receives predictions back, and trains a surrogate model or models between the passed data and the predictions. Once a surrogate model or models has been trained to replicate your model, the attacker then trains a second layer classifier that can differentiate between data that was used to train the first surrogate model and data that was not used to train that surrogate. When this second model is used to attack your model, it can give a solid indication as to whether any given row (or rows) of data is in your training data.
Membership in a training data set can be sensitive when the model and data are related to undesirable outcomes such as bankruptcy or disease, or desirable outcomes like high income or net worth. Moreover, if the relationship between a single row and the target of your model can be easily generalized by an attacker, such as an obvious relationship between race, gender, age and some undesirable outcome, this attack can violate the privacy of an entire class of people. Frighteningly, when carried out to it’s fullest extent, a membership inference attack could also allow a malicious actor, with access only to an unprotected public prediction API or other model endpoint, to reconstruct portions of a sensitive or valuable training data set.
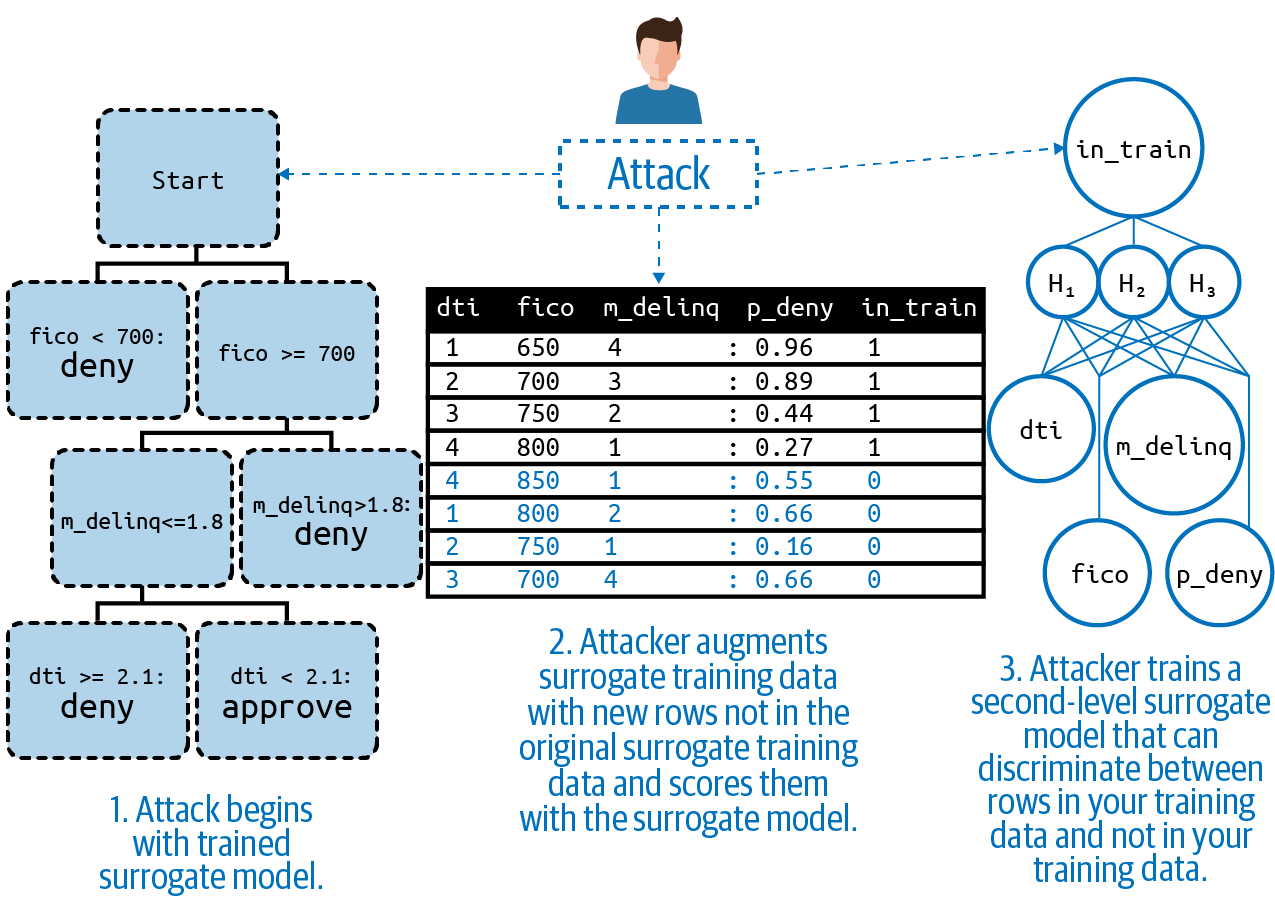
Figure 2-7. An illustration of a membership inference attack. Adapted from the Machine Learning Attack Cheatsheet.
While the attacks discussed above are some of the most well-known types of attacks, keep in mind that these are not the only types of ML hacks, and that new attacks can emerge very quickly. Accordingly, we’ll also address a few general concerns to help you frame the broader threat environment, before moving on to countermeasures you can use to protect your AI system.
General AI Security Concerns
One common theme of this book is that AI systems are fundamentally software systems, and applying common sense software best practices to AI systems is usually a good idea. The same applies for security. As software systems and services, AI systems exhibit similar failure modes, and experience the same attacks, as general software systems. What are some of these general concerns? Unpleasant things like intentional abuses of AI technology, availability attacks, trojans and malware, man-in-the-middle attacks, unnecessarily complex black-box systems, and the woes of distributed computing.
-
Abuses of Machine Learning: Nearly all tools can also be weapons, and ML models and AI systems can be abused in numerous ways. Let’s start by considering deep fakes. Deep fakes are an application of deep learning that can, when done carefully, seamlessly blend fragments of audio and video into convincing new media. While deep fakes can be used to bring movie actors back to life, as was done in some recent Star Wars films, deep fakes can be used to harm and extort people. Of course non-consensual pornography, in which the victim’s face is blended into an adult video, is one of the most popular uses of deep fakes, as documented by the BBC and other news outlets. Deep fakes have also been implicated in financial crimes, e.g., when an attacker used a CEO’s voice to order money transferred into their own account. Algorithmic discrimination is another common application of abusive AI. In a “fairwashing” attack, post-hoc explanations can be altered to hide discrimination in a biased model. And facial recognition can be used directly for racial profiling. We’re touching on just a few of the ways AI systems can be abused, for a broader treatment of this important topic see AI-enabled future crime.
-
Availability Attacks: AI systems can fall victim to more general denial of service (DOS) attacks, just like other public-facing services. If a public-facing AI system is critical to your organization, make sure it’s hardened with firewalls and filters, reverse domain name server system (DNS) lookup, and other countermeasures that increase availability during a DOS attack. Unfortunately, we also have to think through another kind of availability failure for AI systems — those caused by algorithmic discrimination. If algorithmic discrimination is severe enough, driven by internal failures or adversarial attacks, your AI system will likely not be usable by large portion of it’s users. Be sure to test for algorithmic discrimination during training and throughout a system’s deployed life cycle.
-
Trojans and Malware: Machine learning in the research and development environment is highly dependent on a diverse ecosystem of open source software packages. Some of these packages have many, many contributors and users. Some are highly specific and only meaningful to a small number of researchers or practitioners. It’s well understood that many packages are maintained by brilliant statisticians and machine learning researchers whose primary focus is mathematics or algorithms, not software engineering, and certainly not security. It’s not uncommon for a machine learning pipeline to be dependent on dozens or even hundreds of external packages, any one of which could be hacked to conceal an attack payload. Third party packages with large binary data stores and pre-trained ML models seem especially ripe for these kinds of problems. If possible, scan all software artifacts associated with an AI systems for malware and trojans.
-
Man in the Middle Attacks: Because many AI system predictions and decisions are transmitted over the internet or an organization’s network, they can be manipulated by bad actors during that journey. Where possible, use encryption, certificates, mutual authentication, or other countermeasures to ensure the integrity of AI system results passed across networks.
-
Black-box Machine Learning: Although recent developments in interpretable models and model explanations have provided the opportunity to use accurate and also transparent models, many machine learning workflows are still centered around black box models. Such black box models are a common type of, often unnecessary, complexity in a commercial ML workflow. A dedicated, motivated attacker can, over time, learn more about your overly complex black box ML model than you or your team knows about it. (Especially in today’s overheated and turnover-prone data science job market.) This knowledge imbalance can potentially be exploited to conduct the attacks described above or for other yet unknown types of attacks.
-
Distributed Computing: For better or worse, we live in the age of big data. Many organizations are now using distributed data processing and AI systems. Distributed computing can provide a broad attack surface for a malicious internal or external actor. Data could be poisoned on only one or a few worker nodes of a large distributed data storage or processing system. A back door could be coded into just one model of a large ensemble. Instead of debugging one simple data set or model, now practitioners must sometimes examine data or models distributed across large computing clusters.
Starting to get worried again? Hang in there — we’ll cover countermeasures for confidentiality, integrity, and availability attacks on AI systems next.
Counter-measures
There are many countermeasures you can use and, when paired with the processes proposed in Chapter 9, bug bounties, security audits, and red teaming, such measures are more likely to be effective. Additionally, there are the newer subdisciplines of adversarial ML and robust ML, that are giving the full academic treatment to these subjects. This section will outline some of the defensive measures you can use to help make your AI systems more secure, including model debugging for security, model monitoring for security, privacy enhancing technologies, robust machine learning, and a few general approaches.
Model Debugging for Security
ML models can and should be tested for security vulnerabilities before they are released. In these tests, the goal is basically to attack your own AI systems, to understand your level of vulnerability, and to patch up any discovered vulnerabilities. Some general techniques, that work across different types of ML models, for security debugging are adversarial example searches and sensitivity analysis, audits for insider attacks, discrimination testing, and white-hat model extraction attacks. (We use the term “white-hat” to describe hacking activities that are meant to detect or counter security vulnerabilities.)
Adversarial Example Searches and Sensitivity Analysis
Conducting sensitivity analysis with an adversarial mindset, or better yet, conducting your own adversarial example attacks, is a good way to determine if your system is vulnerable to perhaps the simplest and most common type of ML integrity attack. The idea of these white-hat attacks is to understand what feature values (or combinations thereof) can cause large swings in your system’s output predictions. If you’re working in the deep learning space, packages like cleverhans and foolbox can help you get started with testing your AI system. For those working with structured data, good old sensitivity analysis can go a long way toward pointing out instabilities in your system. You can also use genetic learning to evolve your own adversarial examples or you can use heuristic methods based on individual conditional expectation (ICE) to find adversarial examples. Once you find instabilities in your AI system, triggered by these adversarial examples, you’ll want to use cross-validation or regularization to train a more stable model, apply techniques from robust machine learning, or explicitly monitor for the discovered adversarial examples in real time. You should also link this information to the system’s incident response plan, in case it’s useful later.
Auditing for Insider Data Poisoning
If a data poisoning attack were to occur, system insiders — employees, contractors, and consultants — are not unlikely culprits. How can you track down insider data poisoning? First, score those individuals with your system. Any insider receiving a positive outcome could be the attacker or know the attacker. Because a smart attacker will likely perform the minimum changes to the training data that result in a positive outcome, you can also use residual analysis to look for beneficial outcomes with larger than expected residuals, indicating the ML model may have been inclined to issue a negative outcome for the individual had the training data not been altered. Data and environment management are strong countermeasures for insider data poisoning too, as any changes to data are tracked with ample metadata (who, what, when, etc.). You can also try the reject on negative impact (RONI) technique, proposed in the seminal The Security of Machine Learing paper, to remove potentially altered rows from system training data.
Discrimination Testing
DOS attacks, resulting from some kind of algorithmic discrimination — intentional or not — are a plausible type of availability attack. In fact, it’s already happened. In 2016, Twitter users poisoned the Tay Chatbot to the point where only those users interested in neo-nazi pornography would find the system’s service appealing. This type of attack could also happen in a more serious context, such as employment, lending or medicine, where an attacker uses data poisoning, model backdoors, or other types of attacks to deny service to a certain group of customers. This is one of the many reasons to conduct discrimination testing, and remediate any discovered discrimination, both at training time and as part of regular model monitoring. There are several great open source tools for detecting discrimination and making attempts to remediate it, such as aequitas, Themis, and AIF360.
White-hat Model Extraction Attacks
Model extraction attacks are harmful on their own, but they are also the first stage for a membership inference attack. Conduct your own model extraction attacks to determine if your system is vulnerable to these confidentiality attacks. If you find some API or model end-point that allows you to train a surrogate model between input data and system outputs, lock it down with solid authentication and throttle any abnormal requests at this endpoint. Because a model extraction attack may have already happened via this endpoint, analyze your extracted surrogate models as follows:
-
What are the accuracy bounds of different types of white-hat surrogate models? Try to understand the extent to which a surrogate model can really be used to gain knowledge about your AI system.
-
What types of data trends can be learned from your white-hat surrogate model? Like linear trends represented by linear model coefficients or course summaries of population subgroups in a surrogate decision tree.
-
What rules can be learned from a white-hat surrogate decision tree? For example, how to reliably impersonate an individual who would receive a beneficial prediction? Or how to construct effective adversarial examples?
If you see that it is possible to train an accurate surrogate model from one of your system endpoints, and to answer some of the questions above, then you’ll need to takes some next steps. First, conduct a white-hat membership inference attack to see if that two stage attack would also be possible. You’ll also need to record all of the information related to the white-hat analysis and link to it to the system’s incident response plan. Incident responders may find this information helpful at a later date, and it may unfortunately need to be reported as a breach if there is strong evidence that an attack has occurred.
Debugging security vulnerabilities in your AI system is important work that can save you future money, time and heartache, but so is watching your system to ensure it stays secure. Next we’ll take up model monitoring for security.
Model Monitoring For Security
Once hackers can manipulate or extract your ML model, it’s really not your model anymore. To guard against attacks on your ML, you’ll not only need to train and debug it with security in mind, you’ll also need to monitor it closely once it goes live. Monitoring for security should be geared toward algorithmic discrimination, anomalies in input data queues, anomalies in predictions, and high-usage. Here are some tips on what and how to monitor:
-
Discrimination monitoring: Discrimination testing, as discussed in previous chapters, must be applied during model training. But for many reasons, including unintended consequences and malicious hacking, discrimination testing must be performed during deployment too. If discrimination is found during deployment, it should be investigated and remediated. This helps to ensure a model that was fair during training remains fair in production.
-
Input anomalies: Unrealistic combinations of data, that could be used to trigger back doors in model mechanisms, should not be allowed into model scoring queues. Anomaly detection ML techniques, like autoencoders and isolation forests, may be generally helpful in tracking problematic input data. However, you can also use commonsense data integrity constraints to catch problematic data before it hits your model. An example of such unrealistic data is reporting an age of 40 years and a job tenure of 50 years. If possible, you should also consider monitoring for random data, training data, or duplicate data. Because random data is often used in model extraction and inversion attacks, build out alerts or controls that help your team understand if or when your model may be encountering batches of random data. Real-time scoring of rows that are extremely similar or identical to data used in training, validation, or testing should be recorded and investigated as they could indicate a membership inference attack. Finally, be on the lookout for duplicate data in real-time scoring queues, as this could indicate an evasion or impersonation attack.
-
Output anomalies: Output anomalies can be indicative of adversarial example attacks. When scoring new data, compare your ML model prediction against a trusted, transparent benchmark model or a benchmark model trained on a trusted data source and pipeline. If the difference between your more complex and opaque ML model and your interpretable or trusted model is too great, fall back to the predictions of the conservative model or send the row of data for manual processing. Statistical control limits, which are akin to moving confidence intervals, can also be used to monitor for anomalous outputs.
-
Meta-monitoring: Monitor the basic operating statistics — the number of predictions in some time period, latency, CPU, memory, and disk loads, or the number of concurrent users — to ensure your system is functioning normally. You can even train an autoencoder–based anomaly detection metamodel on your entire AI system’s operating statistics and then monitor this metamodel for anomalies. An anomaly in system operations could tip you off that something is generally amiss in your AI system.
Monitoring for attacks is one the most pro-active steps you can take to counter ML hacks. However, there are a still a few more countermeasures to discuss. We’ll look into privacy enhancing technologies (PETs) below.
Privacy-enhancing Technologies
Privacy-preserving ML is a research subdiscipline with direct ramifications for the confidentiality of your ML training data. While just beginning to gain steam in the ML and ML operations (MLOps) communities, PETs can give you an edge when it comes to protecting your data. Some of the most promising and practical techniques from this emergent field include federated learning and differential privacy.
Federated learning
Federated learning is an approach to training ML models across multiple decentralized devices or servers holding local data samples, without exchanging raw data between them. This approach is different from traditional centralized ML techniques where all datasets are uploaded to a single server. The main benefit of federated learning is that it enables the construction of ML models without sharing data among many parties. Federated learning avoids sharing data by training local models on local data samples and exchanging parameters between servers or edge devices to generate a global model, which is then shared by all servers or edge devices. Assuming a secure aggregation process is used, federated learning helps address fundamental data privacy and data security concerns. Among other open source resources, look into PySyft or FATE to start learning about implementing federated learning at your organization (or with partner organizations!).
Differential Privacy
Differential privacy is a system for sharing information about a dataset by describing patterns about groups in the dataset without disclosing information about specific individuals. In ML tools, this is often accomplished using specialized types of differentially private learning algorithms. This makes it more difficult to extract sensitive information from training data or a trained ML model in model extraction, model inversion or membership inference attacks. In fact, an ML model is said to be differentially private if an outside observer cannot tell if an individual’s information was used to train the model. There are lots of high-quality open source repositories to check out and try, including:
-
Google’s
differential-privacy -
IBM’s
diffprivlib -
Tensorflow’s
privacy
Many ML approaches that invoke differential privacy are based on differentially private stochastic gradient descent (DP-SGD). DP-SGD injects structured noise into gradients determined by SGD at each training iteration. In general, DP-SGD and related techniques ensure that ML models do not memorize too much specific information about training data. Because they prevent ML algorithms from focusing on particular individuals, they could also lead to increased generalization performance and fairness benefits.
You may hear about confidential computing or homomorphic encryption under the PET topic heading as well. These are promising research and technology directions to watch for the future. Another subdiscipline of ML research to watch is robust ML, which can help you counter adversarial example attacks and other adversarial manipulation of your AI system.
Robust Machine Learning
Robust ML includes many cutting-edge ML algorithms developed to counter adversarial example attacks, and to a certain extent data poisoning as well. The study of robust ML gained momentum after several researchers showed that silly, or even invisible, changes to input data can result in huge swings in output predictions for computer vision systems. Such swings in model outcomes are a troubling sign in any domain, but when considering medical imaging or semi-autonomous vehicles, they are downright dangerous. Robust ML models help enforce stability in model outcomes, and strikingly, an important notion from fairness, that similar individuals be treated similarly. Similar individuals in ML training data or live data are individuals that are close to one another in the Euclidean space of the data. Robust ML techniques often try to establish a hypersphere around individual examples of data, and ensure that other similar data within the hypersphere receive similar predictions. Whether caused by bad actors, over-fitting, underspecification, or other factors, Robust ML approaches help protect your organization from risks arising from unexpected predictions. Interesting papers and code are hosted at the Robust Machine Learning site, and Madry group at Massachusetts Institute of Technology (MIT) has even published a full Python package for robust ML.
General Countermeasures
There are a number of catchall countermeasures that can defend against several different types of ML attacks, including authentication, throttling, and watermarking. Many of these same kinds of countermeasures are also best practices for AI systems in general, like interpretable models, model management, and model monitoring. The last topic before the case study is a brief description of important and general countermeasures against AI system attacks.
-
Authentication: Whenever possible, disallow anonymous use for high-stakes AI systems. Login credentials, multi-factor authentication, or other types of authentication that force users prove their identity, authorization, and permission to use a system put a blockade between your model API and bad actors.
-
Interpretable, fair, or private models: Modeling techniques now exist (e.g., monotonic GBMs (M-GBM), scalable Bayesian rule lists (SBRL), eXplainable Neural Networks (XNN)), that can allow for both accuracy and interpretability in ML models. These accurate and interpretable models are easier to document and debug than classic ML black boxes. Newer types of fair and private modeling techniques (e.g., LFR, DP-SGD) can also be trained to downplay outward visible, demographic characteristics that can be observed, socially engineered into an adversarial example attack, or impersonated. These models, enhanced for interpretability, fairness or privacy, should be more easily debugged, more robust to changes in an individual entity’s characteristics, and more secure than over-used ML black boxes.
-
Model Documentation: Model documentation is a risk-mitigation strategy that has been used for decades in banking. It allows knowledge about complex modeling systems to be preserved and transferred as teams of model owners change over time, and for knowledge to be standardized for efficient analysis by model validators and auditors. Model documentation should cover the who, when, where, what and how of an AI system, including many details from contact information for stakeholders to algorithmic specification. Model documentation is also a natural place to record any known vulnerabilities or security concerns for an AI system, enabling future maintainers or other operators that interact with the system to allocate oversight and security resources efficiently. Incident response plans should also be linked to model documentation.
-
Model Management: Model management typically refers to a combination of process controls, like documentation, combined with technology controls, like model monitoring and model inventories. Organizations should have an exact count of deployed AI systems, and inventory associated code, data, documentation and incident response plans in a structured manner, and monitor all deployed models. These practices make it easier to understand when something goes wrong and to deal with problems quickly when they arise.
-
Throttling: When high use or other anomalies, such as adversarial examples, or duplicate, random, or training data, are identified by model monitoring systems, consider throttling prediction APIs or other system endpoints. Throttling can refer to restricting high numbers of rapid predictions from single users, artificially increasing prediction latency for all users, or other methods that can slow down attackers conducting model or data extraction attacks and adversarial example attacks.
-
Watermarking: Watermarking refers to adding a subtle marker to your data or predictions, for the purpose of deterring theft of data or models. If data or predictions carry identifiable traits, such as actual watermarks on images or sentinel markers in structured data, it can make stolen assets harder to use and more identifiable to law enforcement or other investigators once a theft occurs.
Applying these general defenses and best practices, along with some of the more specific countermeasures discussed in previous sections, is a great way to achieve a high level of security for an AI system. And now that you’ve covered security basics, ML attacks, and many countermeasures for those attacks, your armed with the knowledge you need to start red-teaming your organization’s AI --- especially if you can work with your organization’s IT security professionals. We’ll now examine some real-world AI security incidents to provide additional motivation for doing the hard work of red-teaming AI, and to gain insights into some of today’s most common AI security issues.
Case Study: Real-world Evasion Attacks
AI systems used for both physical and online security have suffered evasion attacks in recent years. Below, the case discussion touches on evasion attacks used to avoid Facebook filters and perpetuate disinformation and terrorist propaganda, and evasion attacks against real-world payment and physical security systems.
As the COVID pandemic ground on and the 2020 US presidential campaign was in high gear, those proliferating disinformation related to both topics took advantage of weaknesses in Facebook’s manual and automated content filtering. As reported by NPR, Tiny Changes Let False Claims About COVID-19, Voting Evade Facebook Fact Checks. While Facebook uses news organizations such as Reuters and the Associated Press to fact-check claims made by its billions of users, it also uses AI-based content filtering, particularly to catch copies of human-identified misinformation posts. Unfortunately, minor changes, as simple as different backgrounds or fonts, image cropping, or simply describing memes with words instead of images, allowed bad actors to circumvent Facebook’s AI fact-checking filters. In their defense, Facebook does carry out enforcement actions against many offenders, including limiting the distribution of posts, not recommending posts or groups, and demonetization. Yet, according to one advocacy group, Facebook fails to catch about 42% of disinformation posts containing information flagged by human fact checkers. The same advocacy group — Avaaz — estimates that a sample of just 738 unlabeled disinformation posts lead to an estimated 142 million views and 5.6 million user interactions.
Recent events have shown us that online disinformation and security threats can spill over into the real world. Disinformation about the 2020 US election and the COVID pandemic are thought to be primary drivers of the frightening events of the January 6th, 2021 US Capital riots. In perhaps even more frightening evasion attacks, the BBC has reported that ISIS operatives continue to evade Facebook content filters. By blurring logos, splicing their videos with mainstream news content, or just using strange punctuation, ISIS members or affiliates have been able to post propaganda, explosive-making tutorials, and even evasion attack tutorials to Facebook, garnering tens of thousands views for their violent, disturbing, and vitriolic content. While evasion attacks on AI-based filters are certainly a major culprit, there are also less human moderators for Arabic content on Facebook. Regardless of whether its humans or machines failing at the job, this type of content can be truly dangerous, contributing both to radicalization and real-world violence. Physical evasion attacks are also a specter for the near future. Researchers recently showed that some AI-based physical security systems are easy targets for evasion attacks. With permission of system operators, researchers used lifelike 3-dimensional masks to bypass facial recognition security checks on AliPay and WeChat payment systems. In one egregious case, researchers were even able to use a picture of another person on an IPhone screen to board a plane at Amsterdam’s Schiphol Airport.
Lessons Learned
Taken together, bad actors’ evasion of online safeguards to post dangerous content, and evasion of physical security systems to make monetary payments and to travel by plane paints a scary picture of a world where AI security is not taken seriously. What lessons learned from Chapter 14 could be applied to prevent these evasion attacks? The first lesson is related to robust ML. AI systems used for high-stakes security applications, be it online or real-world, must not be fooled by tiny changes to normal system inputs. Robust ML, and related technologies, must progress to the point where simplistic evasion techniques, like blurring of logos or changes to punctuation, are not effective evasion measures. Another lesson comes from the beginning of the Chapter: the adversarial mindset. Anyone who thought seriously about security risks for these AI-based security systems should have realized masks, or just other images, were an obvious evasion technique. Thankfully, it turns out that some organizations do employ countermeasures for adversarial scenarios. Better facial recognition security systems deploy techniques meant to ensure the liveness of the subjects they are identifying. The better facial recognition systems also employ discrimination testing to ensure availability is high, and error rates are as low as possible, for all their users.
Another major lesson to be learned from real-world evasion attacks pertains to the responsible use of technology in general, and AI in particular. Social media has proliferated beyond physical boarders and its complexity has grown past many country’s abilities to effectively regulate it. With a lack of government regulation, users are counting on social media companies to regulate themselves. Being tech companies, social networks often rely on more technology, like AI-based content filters, to retain control of their systems. But what if those controls don’t really work? As technology and AI play larger roles in human lives, lack of rigor and responsibility in their design, implementation, and deployment will have ever-increasing consequences. Those designing technologies for security or other high-stakes applications have an especially serious obligation to be realistic about today’s AI capabilities and apply process and technology controls to ensure adequate real-world performance. This chapter laid out how to red-team AI systems, and apply process and technology controls, for important security vulnerabilities. The next Chapter will introduce a wide array techniques to test and ensure real-world performance beyond security.