
SAP Data Center Infrastructure SPOFs
Single points of failure abound in the data center layer more than most. Fortunately, this is one of the easiest layers to address from a high-availability perspective. Consider the following:
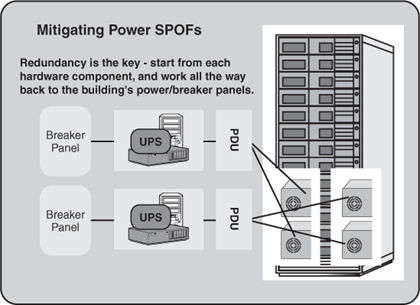
Data center power must be redundant, from the actual power sources or power grids (which can be safeguarded through the use of a generator), to dual-feed breaker panels, to dual UPSes, to dual power distribution units, to dual power cables feeding dual power supplies in every critical hardware component.
Data center cooling represents an everyday single point of failure. I’ve seen more than a few data centers that cannot withstand the loss of one of their air handlers/air conditioners without the heat rising to the point of forcing equipment power-down.
Network infrastructure, like power, also benefits from redundancy. This is important from the client network all the way back to the data center. Client network routers, dial-up access devices, VPN connections, and other access points must all be redundant. Similarly, any switches, bridges, hubs, or other network devices also need to be protected through redundancy. Any application that leverages a particular subnet in an attempt to integrate with your mySAP.com solution also becomes a SPOF. Finally, the network cables and individual network cards that facilitate communication to a particular server must be redundant as well.
Data center rack placement can inadvertently become a single point of failure, too—just ask my customer who placed both of their SAP cluster nodes in a single rack, only to have that rack tip over during a maintenance window and completely lose power. In another case, I heard a story of another shop that had positioned their racks too closely together front-to-rear, such that serviceability to Production SAP was impacted when another system (non-SAP in this case) was also undergoing maintenance.
Power Considerations
With regard to power, remember that every critical server, disk subsystem, network component, air handler, and so on should have access to redundant power. For maximum availability, therefore, every component in the chain of power should be redundant, as you see in Figure 6.5.
Figure 6.5. Redundant power starts at each hardware component that supports redundant power supplies, and works its way back to the ultimate power source.
Additionally, I like to see power cables color-coded. For example, at one of my customer sites, the primary power is supplied through black cables, and the redundant power is supplied through gray cables—this reduces human error later on, as it is very clear to everyone which components are protected, and which power source is being drawn upon during maintenance.
There are also some very important tools or utilities available that should play a part in monitoring power. Most UPS vendors offer tools that snap in to popular SNMP-based enterprise management tools, for example.
Network Infrastructure
When it comes to network infrastructure, redundancy is key—if an SAP end user cannot gain access to the system because a critical network link is down, the system is in effect “down,” after all. Other important areas that need to be considered include the following:
Color-coding makes a lot of sense here, too. One client site of mine uses a public network segment for client-to-application server traffic, and another segment for back-end application server-to-DB server traffic. The first segment uses solid green cable for primary connections, and striped green/white cables for redundant links. Similarly, the back-end network consists of solid blue and striped blue/white cabling. This level of standardization makes troubleshooting simpler, and reduces human errors going forward.
Certain software packages or HA solutions require the use of virtual IP addresses, or relocatable IP addresses. This may require special software or network drivers that support teaming or pairing network cards into a single virtual network card.
Any hardware-based network load-balancing gear must be redundant, too.
Some software-based load-balancing solutions do nothing for high availability. For example, Microsoft’s Network Load Balancing (NLB) does not detect application failures.
Similarly, some failover cluster approaches and other high-availability solutions cannot detect network failures. Thus, these failures need to be detected in another manner, for example, through enterprise management software or hardware-specific monitoring utilities.
Dual-port network cards (NICs with two ports on one physical card occupying a single PCI slot, for example) present an opportunity to create a SPOF where none might otherwise exist. Consider the case of one of my SAP customers who implemented a pair of dual-port NICs, but ran both ports from NIC “A” to their client network, and both ports from NIC “B” to their back-end network. In doing this, each NIC became a single point of failure. A better approach would have been to take one set of ports from each NIC, and run this to the public network, and then run the two remaining ports from each NIC to the back-end network.
Disaster recovery sites probably need to be protected in a similar manner. Plus, links to the DR site from the public network also need to be protected. I recommend two links managed by two different service providers—in this way, even provider-specific issues do not become a single point of failure.
With redundancy in place as shown in Figure 6.6, even multiple failures throughout an SAP enterprise will not take the system out of service.
Figure 6.6. Network-layer redundancy allows for a variety of discrete and multiple failures, while still affording connectivity to a mySAP solution.

Finally, with regard to network components, it’s important to proactively monitor these critical SAP solution points as much as any other component whose failure is capable of essentially shutting down your SAP system.
Rack Infrastructure in the Real World
Perhaps surprisingly, the rack infrastructure used to physically house hardware represents a big HA concern. Not only is it important to physically install these racks consistent with the vendors’ requirements, but it’s also important to step back and take a holistic view of what is actually housed in the rack and how this gear is accessed. For example:
Single points of failure are created when a specific type of computing resource is only installed in a single rack. Therefore, I always recommend that my customers shy away from creating “centralized” racks housing all network components, or all production SAP application servers, or both nodes of a production cluster, or all SAP Internet Transaction Servers, and so on. In this way, loss of power or network services to an individual rack does not automatically (in effect) bring down an entire production system.
Housing heavy components high in a rack may cause the entire rack to come crashing down when the heavy component is pulled out for service. This, and the fact that it’s just plain dangerous and contrary to all vendor warnings, should warrant repositioning heavy gear on the bottom of the rack.
One of my customers mounted their TFT rack-mounted retractable monitors on the top of a row of 7-foot racks. In and of itself, this was not a terrible thing. However, the inconvenience of accessing the monitors eventually impacted production uptime at this small shop. How? My SAP Basis/Operations colleague did not spend the time needed to proactively monitor his SAP R/3 system from a hardware and OS perspective. Eventually, a memory leak (due to a poorly written management agent) caused one of the production servers to crash.
Keyboard, video/monitor, and mouse (KVM) connections need to be considered. Like the problems described regarding “centralized” rack configurations, KVM can represent a SPOF if both nodes in a cluster, for example, share the same KVM components. I also like the idea of maintaining two different methods of accessing server resources, like virtual connection methods (PC Anywhere, PC-Duo, Windows Terminal Services, KVM over IP, or HP’s Remote Insight Boards) in conjunction with physical KVM connections.
Lack of sound cable management can also compromise high availability. That is, cables that are improperly mounted to servers such that pulling out a server wrenches out its power cables will only increase unplanned downtime. Similarly, stuffing all of your power, network, SAN, and other cables into an already crowded subfloor not only complicates cable management, but also makes troubleshooting more complex. In fact, in the case of one of my customers, too many piled-up cables actually blocked cool airflow to some of their server racks, resulting in automatic hardware-initiated power-down. Today, ceiling-mounted cable trays for network/SAN cables, combined with subfloor-based power cables, help ensure that they never succumb to this problem again.
Racks stuffed with gear from varying vendors may improperly vent or exhaust hot air. This is especially true in cases where some of the gear draws air from the front and exhausts hot air out the back, while other gear draws cool air from the subfloor and exhausts it out the top, and other gear pulls from the tops and exhausts into the subfloor!
As one of my SAP clients recently told me, BTUs are the true enemy of the data center today—the high densities and smaller and smaller form factors that we all benefit from only exacerbate the cooling needs of already-crowded data centers. Thus, it is as important as ever to plan well, and plan ahead, not only for data center growth but also for data center cooling requirements.
The Ultimate SPOF—The SAP Data Center
What will happen to your business if your entire data center falls off the face of the earth? Answering this question consumes many SAP DR specialists’ time, and keeps a lot of people awake at night. Certainly, it’s expensive to duplicate an entire data center. In my experience, I see more customers duplicate core business processing systems instead. Other key concerns include the following points:
DR sites are expensive to build.
They are also expensive to maintain.
Testing a DR site is expensive, too.
Further, testing seldom reflects the reality of true disasters without a tremendous amount of time invested in developing and working through disaster scenarios.
It can be difficult to sell a management team on the idea of spending a pile of budget money on a resource that will hopefully never be “used.”
I therefore like to identify the hidden benefits of a DR site outside of the most obvious benefit—protection of your core business (which should be enough to satisfy anyone). These include leveraging the DR site for end-user reporting requirements, using the site for testing major infrastructure changes, and using it for pre-upgrade testing/staging. Staging your pre-production systems at your DR site with the strategy of using them in the event of a primary data center failure can also ease financial pressures associated with building a DR site. Finally, using your DR site as the definitive testing ground in your change control or change management processes, prior to deploying changes to production, represents a huge benefit as well.
Barring selling management on any of the benefits just discussed, another perhaps even better approach can be taken. Rather than spending a fortune on idle computing resources, a company might consider outsourcing their DR needs on a “computing on demand” basis instead, where computing resources are paid for as needed. A monthly “access” or “”availability” fee is typical, of course. In the long run, though, the savings can be huge. Large SAP outsourcers are doing more and more of this type of DR service, including HP, Cap Gemini Ernst & Young (CGEY), and others.