
Chapter 10. Designing SOA security for a real-world enterprise
This chapter covers
- Securing diverse services
- Deployment architectures
- Vulnerability management
We started this book by identifying three new approaches—message-level security, security as a service, and policy-driven security—that address the challenges SOA introduces in security.
Part II (chapters 4-7) described all the technologies and standards related to message-level security. Making and verifying identity claims, protecting data confidentiality, and verifying data integrity were described there. Chapter 8 explored the idea of offering security as a service. Chapter 9 focused on declarative, policy-based security.
By now you know enough about SOA security, both technology- and standards-wise. Still, if you want to design SOA security solutions for real-world enterprises, you need to know more. In particular, each enterprise has unique requirements that influence the overall SOA security solution. One enterprise may be concerned about high availability and disaster recovery capabilities, perhaps due to the high cost of application unavailability. Another may be focused on return on investment (ROI) and demand a low-cost solution. As an architect, you should translate these unique needs into technical guidelines.
In this chapter, we are going to provide insight into the process of developing security solutions that respect the constraints in an enterprise. While the other chapters in this book discussed a concrete technology that solves a specific problem, this chapter identifies the standard problems that you might face when designing security solutions in an enterprise and discusses the approaches typically used to solve these problems. In other words, this chapter will not provide silver-bullet answers; instead, it provides enough information for you to come up with your own answers.
We will begin by classifying the real-world challenges for SOA security solutions into different categories:
- Enterprise software requirements Most developers, including those who are developing security products, do not realize the complexities of enterprise software development, several of which are nontechnical. In section 10.1, we will provide the details of these challenges and how to address them in your solution.
- The kind of services we are securing In this book, we deliberately chose simple services when illustrating SOA security concepts. In real life, the services to secure are lot more complex and varied. In quite a few cases, it may not be easy to see how you can apply the security techniques we discuss in this book. In section 10.2, we discuss how you can secure different kinds of services you are likely to find in the real world.
- Deployment requirements So far, we did not consider the impact of network design in SOA security solutions. We simply assumed that a security service can be located on any host that can be reached by the client and/or server. In the real world, the location of a security service is an important element of security design that needs to take into account network design and user locations. We also need to take into account organizational and legal structures that can have an impact on where the security service can be located. In section 10.3, we will discuss deployment scenarios that consider all these factors.
- System requirements We have not covered performance, availability, scalability, and robustness. Even though these are generic requirements, we will discuss them in the context of SOA security frameworks in section 10.4.
- We will tell you in Threat of attacks Every service implementation, including the implementation of the security service itself, may have a few known and unknown vulnerabilities.section 10.5 about XML-specific vulnerabilities and how you can defend your services against attackers looking to exploit them.
Let’s start with the enterprise software requirements and see what kind of challenges they pose for a security solution.
10.1. Meeting the demands of enterprise IT environments
Most software developers fail to appreciate the complexity of enterprise software. They cannot understand why a simple software solution costs so much to deploy. The IT processes seem downright archaic, unsuitable for developing quality software. It is easy to write software that works; so why is it so complex to put together, say, a simple database-backed website?
In reality, there are several steps before any solution can be used by an enterprise. The following questions are asked before rolling out a database-backed website: How is the database managed? How is the application deployed? How is it updated? How do we train the users? How do we take care of hardware failures? Similar questions need to be answered before rolling out any enterprise SOA security solution.
Instead of answering these questions one by one, we will provide the general concerns that enterprises have for their application, so that you can answer them effectively. Typically the enterprises quantify these concerns using TCO (total cost of ownership). The aspects of the solution that impact the TCO:
- Catering to a large and diverse user base
- Designing for long life cycles
- Ensuring robustness
- Designing for manageability
- Integrating with diverse legacy applications
We will first describe the need for catering to a large and diverse user base and explain how it impacts the design of enterprise SOA security solutions.
10.1.1. Large and diverse user base
Typically, enterprise software is used by people with different technical backgrounds. For example, senior managers in a logistics company—people with deep knowledge of logistics (their business domain) but less familiar with application security—may need to use several applications. The process managers who use the computer frequently may need in-depth knowledge of the applications and yet may have only a limited understanding of the security solutions. Warehouse operators and truck drivers are likely to use less software.
In short, we have a large number employees with differing job descriptions using software for their specific duties at different locations. Naturally, this imposes several constraints on the way we develop a security solution.
To start with, the diverse user base makes it difficult to train anyone in security awareness. The security solution will have to be simple enough to be used by everybody. As the saying goes, “assume stupidity on part of the internal users, and maliciousness on part of the external users.” That means, if any mistake can be made by users, assume that they will make it. If you make the password schemes complex, assume that they will write down the passwords. Also, be aware that you cannot prevent social engineering-based[1] security compromises without proper training.
1 Social engineering attacks are ones where hackers trick people into providing access control information. We cannot address them using technology alone. A well-designed security solution can take care of these attacks in multiple ways; for, example, by making password sharing difficult or alerting users of possible security violations, and so on.
How can we make a simple security solution really secure? One way is to have strong audit measures by monitoring for unauthorized requests or unusual number of requests, unusual times of requests, or unusual patterns of requests. This monitoring can lead to proactive security management, such as temporary revocation of privileges or manual verification of the user activities.
The other way we can increase security is by multifactor authentication where we require users to present multiple pieces of evidence to identify themselves. For example, as shown in figure 10.1, we may require users to present a key generated by a hardware token along with their username and password.
Figure 10.1. Example of two-factor authentication. In this example, username/password (something you know) is combined with a key generated dynamically by a hardware token (something you have) to create two-factor authentication.

Theoretically, multifactor authentication will improve security only if the multiple pieces of identification users present are qualitatively different from each other. For example, if the user simply presents two different passwords, that does not enhance the quality of security. A password is something the user knows. If the user can in addition present evidence that he is in possession of something—a hardware token that generates a different key every minute or a smart card that has an embedded digital certificate—the quality of security is certainly higher than what we get with a simple password-based scheme.
We need to be wary of any solution that is complex, as it will make logistics, training, and support difficult. For example, if we go in for two-factor authentication, we have the additional burden of distributing and managing hardware tokens or smart cards. That is why we should try to stick to mechanisms that are familiar to our users. As always, security and convenience impose opposing constraints on the solution, and the existing corporate culture will provide guidance on how to strike the right balance.
The next challenge in enterprise-class solution development is the need to design for long life cycles.
10.1.2. Long life cycle
Most of us are surprised to find how old some applications in enterprises are. Some enterprises have back-end applications from the ’60s. Others are just now migrating from Windows 98. This is in sharp contrast to most developers, who always want to use the latest tools and technologies. Why is that? And, what lesson is there for our security solution?
The complexity of IT in enterprises is such that they need to manage systems carefully. Any introduction of new software will have to be accompanied by extensive testing, training, and support provisioning. Since the cost of introduction and upgrade is so high, it may take six months, whereas a developer can upgrade his systems within six hours.
What this means to us solution developers is that we need to design our upgrade processes carefully. In this regard, separating the security concerns into declarative information can make upgrades easy. Be aware that we still have to go through the full cycle of testing, as we mentioned earlier. As a part of this upgrade, users should not require new training. Some of the techniques we have shown earlier, such as JAAS, can help isolate the changes to new libraries and new configuration files.
The long life of applications also requires us to make our implementation choices carefully. For example, we should choose technical standards, libraries, and vendors with a long-term perspective of viability, availability of source code, and support. We have to make sure that we can support our solution for a long time.
Another important requirement for enterprise-class solutions is robustness. Let’s discuss this requirement next.
10.1.3. Robustness
For an individual, an application crashing may result in loss of data and time, causing inconvenience. For enterprises, this is not mere inconvenience; it may cause serious process disruption, resulting in irate customers, a warehouse full of unshipped goods, idling flights, and unhappy shareholders.
While any process disruption is bad, a security process disruption can be even worse. For instance, a solution that depends on a crucial resource such as a credential store can render every application inaccessible when it crashes. With such serious consequences, we must make sure that our solution is robust; that is, it works even in the event of unexpected failures. Here are some ways we can make our security solution robust.
First, we must follow standard application development guidelines to make the applications robust. Usual causes of crashes can be unstated and unreasonable limits on the resources. For example, if you program assuming only 10 people are going to access the system, what if an emergency forces 100 people to access the system? This can cause the system to repeatedly crash, making the situation even worse. One way we can make sure this will not occur is by gracefully dropping the additional users without application thrashing.
Second, we need to provide fault-tolerant systems. When a primary instance of an application goes down, a secondary instance should quickly come up and take over. There are a few standard ways of doing this regardless of what the application is. The approach to use will depend on details such as the amount of time it takes to start the application, the amount of state that the application keeps, how the state is kept, whether the application can gracefully recover from loss of state, and so on.
Enterprise SOA security solutions should also gracefully degrade and employ fault-tolerance mechanisms in order to be robust enough for use in real-world enterprises.
Next we will discuss the manageability requirements that enterprise solutions must satisfy.
10.1.4. Manageability
Manageability refers to the ease with which applications can be managed. Important aspects of enterprise application manageability include the ease with which administrators can provision applications for use by a large number of users, monitor the health of applications, and do maintenance activities such as creating backups and installing patches.
An enterprise-class SOA security solution needs to pay attention to all of these issues. For example:
- The security solution should integrate with existing corporate directories so that user provisioning need not be repeated.
- It should be easy to provision the use of the security service by a large number of services.
- It should be possible to federate the creation and maintenance of access control rules.
- It should be possible to monitor the security service using any of the popular application monitoring frameworks such as IBM Tivoli or HP Open-View. By monitoring, we mean more than just a routine check to ensure that the security service is up all the time. We also mean SLA checks to see that the service is responding as required and auditing to ensure that the service is not accessing or consuming more resources than it should.
- Tools should be available to integrate the security solution with other infrastructure in the enterprise. For example, it should be possible to redirect notifications generated by the security solution to pagers of administrators.
Another challenge that enterprise-class solutions often have to meet is the need to integrate with diverse legacy applications. Let us discuss this requirement next.
10.1.5. Integration with diverse legacy applications
As we described, due to the long life cycle of applications, enterprises accumulate applications built on different technical platforms. A typical enterprise will have a mix of applications running on mainframes, Unix servers, and Windows desktops. Any security solution we build must be able to work with all these systems. That is:
- Any existing application should be able to use our security solution.
- If the security solution relies on assets that are managed by legacy applications, it must do so without requiring replication.
- If the security solution needs to interoperate—invoke other applications—it should be equipped to do so.
In section 10.3.2, we will describe different strategies you can use to secure legacy services.
In this section, we have discussed challenges and requirements all enterprise solutions must address. We have also discussed the impact of these challenges on the design of an enterprise SOA security solution. In the next section, we will focus on the strategies you can use when securing different kinds of services in an enterprise.
10.2. Securing diverse services
Although we have been assuming that a service is just that—a service—up to this point in this book, different kinds of services may need different security strategies. For example, the strategy we would use to secure a new service that is being developed from scratch on a web services platform may be different from the strategy we would use to secure a service that wraps a legacy application running on a mainframe. It is important for enterprise SOA security architects to understand the kinds of services that need to be secured and the strategies that work well for each kind of service.
In this section, we will discuss three broad kinds of services:
- Services developed from scratch
- Services wrapping legacy applications
- Services that are composed of other services
For each kind of service, we will explore the strategies we can employ when securing them. Let’s start with a discussion of the strategies we can use for services developed from scratch.
10.2.1. Services developed from scratch
Typically, most enterprises build services on top of their existing applications as they start moving to a SOA-driven enterprise. In new projects, it is likely that they develop services entirely from scratch. Securing such services is simpler than securing the legacy services.
Remember security is a part of the overall SOA strategy. High-level SOA security strategy should be coming from the SOA governance team in your enterprise. If you are part of the team assigned the responsibility of coming up with a security strategy, here are some of the guidelines you can use when developing a security strategy for new services:
- Identify the user repository If there is already a corporate standard directory server, plan on using it. For testing and experimenting reasons, you may want to have your own directory server. It can be set up as a replicated slave server, making it useful immediately for the server authentication needs.
- Classify the authorization roles early on Even if you have limited physical roles, plan on having as many logical roles as required. For example, even if the services you wish to secure only distinguish between two roles, say admin and authenticated, you can introduce as many roles as logically required. Instead of a single role called admin, we can introduce multiple roles depending on what they administer: app admin, domain admin, system admin, and so on. This early separation of roles helps us later when we reconcile this security model with an external security model. We will describe what we mean by reconciling security models in section 10.3.2 when we discuss strategies for securing services that wrap legacy applications.
- Develop a security framework This framework may come from your vendor or from your team. It should support at the minimum following:
3.1 Securing a new service should be done without adding more code. It should be possible to use a declarative facility for that. 3.2 Managing security for a service should be easy. We should be able to change the role required to use a service without having to understand the code. 3.3 The framework should support auditing and logging as well. This helps us fine-tune the security implementation in practice. Often these services are already a part of the security requirements. 3.4 Whether you deploy security as a separate service or as a part of each service depends on your particular requirement. It is important to centrally maintain the code that manages security so it can be audited and tested thoroughly.
These guidelines help you in figuring out a specific security strategy for services you are developing from scratch. Next, let’s explore the strategies you can use for securing services that wrap legacy applications.
10.2.2. Services wrapping legacy applications
Most of the services in the current generation of SOA implementations come from wrapping existing legacy applications. In fact, SOA is seen as a way for these applications to participate in modern workflows. Without SOA, these applications cannot provide the useful business logic they contain in a readily usable form.
There are many ways we can wrap legacy applications to offer services, each constraining the security strategy differently. Let’s look at what technical choices we have in developing the services before discussing the possible security strategies for each of those choices:
- In-process library If the legacy application is a stand-alone application, we can add another library to the application that can “talk” SOAP over HTTP and translate SOAP calls into function calls. This approach can work well for custom applications despite the complexity of development and management.
- Messaging mechanism Some applications have a document- or message-centric interface. They take requests in the form of a file in an input directory or as messages in a queue and produce responses as files in an output directory or as messages in queues. We may expose the capabilities of such applications as web services. For example, we can create WSDL bindings and declare FTP or message queue providers (such as JMS or IBM MQ Series) as the transports. Alternatively, we can create a wrapper that generates the files in input directories or messages in input queues upon receiving a service request and translates output messages to service responses. The wrapper may need to handle more complex situations. For example, the application may only respond to a request message after a long time, while the service invocation may have to be modeled as a synchronous request/response for reasons beyond your control. Messaging and Business Process Management (BPM) tool vendors (such as IBM, TIBCO, BEA, and Oracle) address these complexities by providing tools that make this kind of wrapping easy.
- Existing API The application may offer an API that can be used to build services. If an application already offers a CORBA interface, we can easily adapt it to implement web services. Or, if there is a network interface providing application services, we can do a protocol translation to offer them as SOAP-based web services.
- Mimicking the end user Some applications may not have the right interfaces or facilities for developing the services. If a partner’s application offers only a web-based interface, you will have to resort to screen-scraping. Some old mainframe applications may offer only a tn3270 interface (a cursor-based interface). In that case, we write a library that interacts with the application to mimic the end user and use that as the basis for a creating a service.
Figure 10.2 depicts how wrapper services work, abstracting away the details of strategies used to wrap a service interface on top of a legacy application.
Figure 10.2. A service wrapping a legacy application to provide a service. In fact, there are tools typically provided as part of an ESB platform that can wrap the existing functionality and offer it as a service. This wrapping can convert message format, as well as protocol; in addition it can combine multiple functions into one service.

As you can see, there are three entities in the picture. The first is the client. The second is the wrapper or the proxy for the service. The third is the actual application implementing the service. As we discussed earlier, sometimes the second and third entities may lie in the same application. In any case, we can assume that the communication between the wrapper service and the legacy app is secure. Thus, we only have to see:
- How the client can invoke the wrapper service
- How the wrapper service can transform the security context, if any, to the legacy app
The material you have seen in the book so far describes how to tackle the first challenge. The second challenge involves reconciling the security model of the service with that of the back-end application. By security model, we mean the notion of users, roles, authentication, authorization, encryption, and nonrepudiation.
Note: Reconciling security models
Security models in different applications can have different views on users and roles. In the security model of one application, each user may have only one role, and in the security model of another application, each user may have multiple roles. The user and role names themselves may be different. Or, roles with the same name may semantically differ. For example, an expert role could mean different sets of permissions in different applications.
When we reconcile the security models of two applications, we map the users or roles of one model to those of the other. If traceability is important, each username in the first application must map to one and only one username in the other. If traceability is less of a concern than other factors such as simplicity and licensing costs, it may be acceptable to map roles defined by the security model of the first application to roles defined by the security model of the second application. When mapping roles, we want to achieve a semantically meaningful mapping, where roles in one application get equivalent roles in another application.
In reconciling the security models of the wrapper service and the back-end application, there are three choices:
- We can completely manage the security in the wrapper service itself.
- We can map users in the wrapper service to users in the application.
- We can let the application manage the complete security.
To illustrate these choices in security models, we will examine some sample scenarios next.
Legacy application with no security model
In the simplest case, the underlying application may not have any security model. It may be relying on the network or the machine infrastructure to enforce security. For example, several Unix applications use file permissions to handle security traditionally. As shown in figure 10.3, in this scenario, we can completely manage the security in the service itself.
Figure 10.3. Security may be completely taken care of by the wrapper service if the legacy application delegates security away to the underlying infrastructure.

The wrapper service will have to address all aspects of security including authentication and authorization mechanisms per the overall SOA security guidelines.
Let’s now consider a sample scenario of a legacy app wrapped by a service interface and see what security strategies make sense.
Home-grown application with simplistic security model
Here is a common scenario you might encounter: A department, to satisfy its own need, develops a small web application. Over the years, the application evolves, adding new functionality that the users require. Since it is built on early-generation web technologies, it might not support the security model that the corporation approves. It may have a simple model of authenticated, superuser, and guest roles, with every user mapped into one or more of those roles. It may have its own user management system that lets the admin create users and grant roles. As shown in figure 10.4, to reconcile security models of the wrapper service and the legacy app in this scenario, we can map users in the wrapper service to users in the application.
Figure 10.4. Where legacy applications come with a home-grown security model, the wrapper service needs to map its security mechanisms to those of the legacy application.
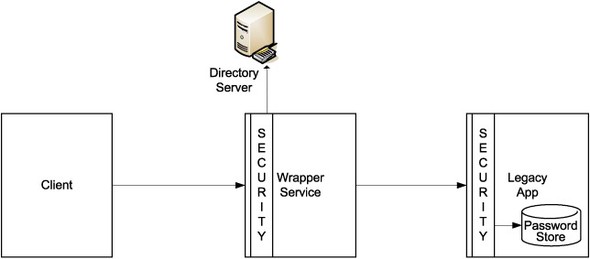
The corporate standards typically dictate the use of a more fine-grained set of users and roles backed by a user directory. Since the application has the built-in logic for users and roles, we must map the corporate standard into the application model. One popular choice is to create three internal users in the service called authenticated-user, superuser, and guest-user, each one registered with the back-end application with the appropriate role. After suitable authentication and authorization, each incoming user is mapped into one of the internal users. The back-end application is invoked using these internal users.
The mapping of the users to these limited roles depends on the security framework we are using. If we are using LDAP-based authentication, we can create the roles in the directory itself. If we are using a security service, the SAML assertion can provide the role in the header as we discussed in earlier chapters.
There is a precedent for this kind of security model management. Most database-backed web sites map web users to a single generic database user. They do not depend on the database user model for authenticating and authorizing the users. This technique lets them pool database connections in the web application.
There are drawbacks to this approach. If the back-end legacy application maintains its own auditing, your user mapping will render it useless. For example, the back-end application will show a large number of accesses from authenticated-user, which in reality are from several different users. If we want to analyze user accesses, we must now rebuild auditing facilities at the wrapper service access point. In addition, the diagnostic messages or the informational logging messages from the back end may not be useful under this gross mapping scheme.
If the response of the back-end application depends on the actual username, we should provide the username as is. In that case, we cannot use this mapping technique. Instead, we need to provision all the users in the application, then use one-to-one mapping. Or, if the back-end application uses a directory, we need to synchronize it with the corporate directory.
Let’s consider yet another sample scenario of a legacy app wrapped by a service interface and see what security strategies make sense.
Home-grown application with flexible security model
Several applications being developed these days support pluggable authentication systems. Some of the application servers even support completely externalized declarative support for authentication systems.
We can envision two different ways to use the flexibility of the security model in the legacy application.
- We can implement the security entirely in the application and invoke the service without any security precautions. This approach will not work if the wrapper service needs the assurance of the client’s name or role. As we will discuss later in this chapter, in case of DoS attacks, the entire burden falls on the legacy app to filter out bogus requests.
- As shown in figure 10.5, we can use a separate security service that can be used by the wrapper service as well as the legacy application. Since there is only one authentication source, we do not have any reconciliation issues. The wrapper service can use the user and role information not only in any computation, but also to filter out any bogus requests. The legacy application can obtain the authenticated user and role information from the security service before computing its response. If the legacy application provides the portfolio total amount for the client, it needs the person’s name to be verified before computing the total.
Figure 10.5. Where a security mechanism can be plugged into the legacy application, the wrapper service may establish a security context in an external security service for subsequent use by a custom security plug-in in the legacy application.

Next we will discuss the security strategies you can use in another commonly found scenario: a wrapper providing a service interface to capabilities found in an enterprise resource planning (ERP) application.
ERP application with hard-wired security model
Large ERP applications come with sophisticated user models which support user hierarchies, groups, and good management tools. An ERP application can offer desktop applications, web applications, and command-line interfaces and its security model must support each type of application. In addition, it provides standard interfaces via libraries, network protocols, and message buses for getting the data in and out of the application and invoking the functionality provided by the ERP.
Since ERPs offer such complete security models, it is preferable to use one of them. If ERP packages need to be integrated, especially using services, we face the problem of mapping the security model of one application to another. If both applications use one source for authentication and authorization, this is a simple task. Typically we need to reconcile the user information between two different directories and our choices range from synchronizing the two directories using tools to reconciling user information as we discussed for other legacy applications. Vendor solutions for solving this problem are typically referred to as identity management solutions.
So far, we have discussed the security strategies you can use for services written from scratch and services that wrap legacy applications. Let’s now look at the security strategy for services that are composed of other services.
10.2.3. Services composed of other services
When we are wrapping applications in services, we may be doing more than simple proxying. We may be orchestrating multiple applications to produce a response to a service request. What we are creating in such cases is a composite service—a high-level service that brings together the capabilities of several lower-level services.
Composition of services can happen in different ways. A simple composition may merely transform and collate the data from multiple services. More sophisticated composition can selectively invoke services based on the outcome of other services. In more complex scenarios, composition can involve additional business logic and invocation of alternate services to elicit the best possible response. Figure 10.6 illustrates a sample composite service.
Figure 10.6. Example of a composite service. Different approaches are possible when securing composite services such as this. No one approach is suitable in all situations.

Securing composite services can be complex. For instance, in figure 10.6, the composite service has to invoke services A, B, C, and D to provide a response. Who can invoke the composite service is determined by who can invoke A, B, C, and D. One choice is to make the composite service simply relay the user credentials (for example, username and password) to services A, B, C, and D. If a client is allowed access to all the required services he is allowed access to the composite service. This model does not preserve the atomicity of the composite service. That means that after service A is invoked, if service B rejects the credentials, we would have to roll back the effect of invoking A.
An alternative is to define the security policy of the composite service conservatively as an intersection of services A, B, C, and D. After authenticating the user, we can carry the context to each of these services so that the access is granted to the client. This approach takes more effort to build security for the composite service. The benefit is that the atomicity of the composite service is not broken due to security violations.
As you can see, in every scenario, there are multiple security strategies you can choose from. You will have to evaluate the trade-offs associated with each possible strategy and pick one that you are comfortable with.
So far in this chapter, we have discussed two of the topics enterprise SOA security architects must be familiar with. We discussed the demands of enterprise IT environments and their impact on SOA security design. We also discussed a number of security design strategies for different kinds of services commonly encountered in enterprises.
Next, we will discuss the challenge of coming up with the right deployment architectures for SOA security solutions.
10.3. Choosing a deployment architecture
Until now, we have dealt with services, service consumers, credential stores, and security services as if their relative locations did not matter. This abstraction was deliberate. Focusing on logical characteristics of entities and ignoring their relative locations helped us reduce the complexity often seen in the real world, for the purpose of teaching. Now, we are going to address the location question—where in the network does each service belong?
Location has a significant bearing on the design of a SOA security solution for a real-world enterprise. This is generally true for any enterprise solution. Designers of enterprise solutions see the impact of location in multiple ways:
- The solution may fix the relative locations of certain entities. If you are offering a solution over the Internet, users are going to be accessing the application over the public network. We exercise little control over the public network. If the users are the general public, you cannot even ask for a VPN-based solution. When designing security solutions for services offered to the public, we have take into account the fact that unauthorized users can potentially attack and gain control over the servers hosting public services.
- Entities whose locations are not fixed by the solution need to be placed in appropriate locations by design. This task can be complex; in some cases, we may have to break an entity into multiple physical components so they can be placed in locations appropriate for each. Or, we may have to deploy multiple instances of the same logical entity in different locations for performance and availability reasons.
- When we break up a logical entity into multiple components at different locations or when we redundantly deploy a logical entity in multiple locations, we run into additional design work that we would not have considered until then. When doing redundant deployments of a credential store, for example, we have to worry about keeping the stores in sync.
In addition to these challenges, security, performance and availability requirements need to be taken into account when answering the “what goes where” question. The solution to what goes where is commonly referred to as the deployment architecture.
In the rest of this section, we will discuss deployment architectures for SOA security solutions. Figure 10.7 depicts the challenge of what goes where in the context of a SOA security solution.
Figure 10.7. Deployment architecture puzzle: What goes where? Match the entities on the left with the locations on the right. Break up or duplicate entities as required.

In the figure, on the left side are the entities in our problem domain:
- Services offered for use within the enterprise intranet, services offered to the public, services offered to partners, and services offered by partners
- Service consumers within the enterprise, in partner firms, and from the public at large
- Credential stores (directories)
- Security service
On the right side are the possible locations for these entities. At a high level, possible locations are:
- Enterprise
- Partners
- Managed service providers
- Public at large
As you can notice, these locations are not atomic. Some can and should be divided if we are to succeed in coming up with the right deployment architecture. To do this division, we need to identify locations that have unique needs/capabilities or pose unique challenges. The enterprise may need to be further divided into regions, with each region consisting of a headquarters, branch offices, and data centers. A data center may in turn need to be divided into multiple locations for security reasons.
Some of this division may be omitted if the basis on which further division can happen is inconsequential when discussing the deployment choices for a use case (or a class of use cases). This is what we will do as we consider three important classes of use cases.
The three classes of use cases we consider here are
- Security for services offered within an enterprise intranet
- Security for services offered to the public at large
- Security for services offered to partners or hosted by partners/managed service providers.
We will start our discussion with the intranet use cases.
10.3.1. For securing services in the intranet
One would think that the deployment architecture for securing services within an enterprise intranet would be quite simple. Firewalls will not get in the way and one can assume that all entities live in a single large network. This simplistic view turns out to be misleading.
The distributed and federated nature of twenty-first century enterprises makes intranet network topologies quite complex. Administrative and legal boundaries, the multiplicity of data centers, and the lack of IT support staff at small branch offices, can all have a significant impact on the deployment architecture for a security solution. We will discuss the impact of each of these factors, starting with the simplest possible case of an enterprise with just one data center and one office.
Simple case: One data center, one office
Assume that the enterprise intranet consists of just two locations, a data center and an office, as shown in figure 10.8. All the services are hosted out of the data center. So are the security service and the credentials repository. Service consumers can exist both in the office (user applications acting as service consumers) and in the data center (one service depending on another).
Figure 10.8. A simplistic view of an enterprise intranet consisting of one data center and one office. How services/service consumers interact with the security service is deliberately omitted from this figure, as multiple possibilities exist.
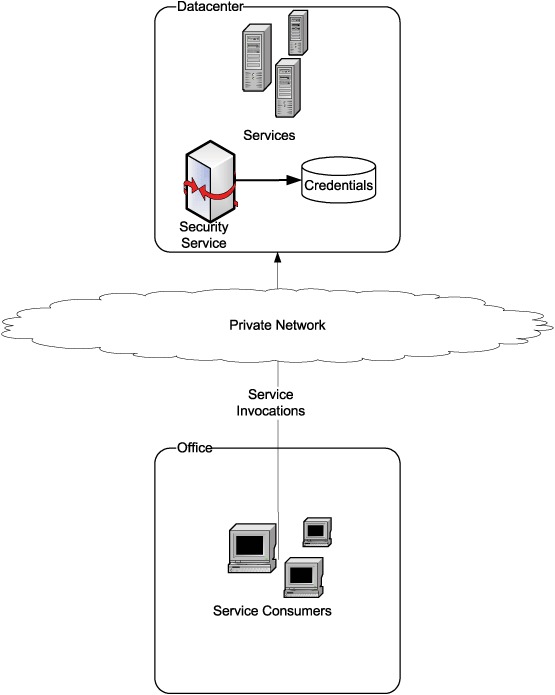
The exact form of security service can vary. It can be a server-based solution or a network device (such as an AON device described in appendix E). Interaction between services/service consumers and the security service can take any of the five forms described in sections 8.2.1 through 8.2.5.
Catering to the needs of small/remote branch offices
It is common for enterprises to have a large number of branches. For example, you see banks opening branches in supermarkets and oil companies owning gas stations in remote areas. It is difficult to place qualified IT people in these branches. Any task that requires complex configuration and maintenance is an operational challenge in these offices.
Let’s see what kind of support these branch offices need. Some desktop applications used in a small/remote branch office might be consumers of services offered within the enterprise intranet. That means these service consumers need to be configured with at least the location of a registry that houses metadata for services offered within the enterprise. This configuration needs to be updated if and when the registry location changes. In addition, if some of the consumers require security policies to be configured beforehand, a mechanism is needed to keep the preconfigured policies up-to-date. This is clearly a challenge if IT support staff is not available in the branch office.
A possible solution to this problem is shown in figure 10.9.
Figure 10.9. A remotely configurable security device (either hardware or software) can be used as client proxy. This technique comes in handy in small/remote branch offices that lack IT support staff.

If we place a remotely configurable security device (either hardware or software) at each small/remote branch office, we need not maintain the security policy configuration in each of the desktop applications acting as service consumers. The security device can be periodically updated with the latest security policies, based on which it can appropriately secure each service invocation emanating out of the branch office.
There are several choices for implementing remotely manageable client proxies. We can use a remotely managed server running client proxy software. We can use tools from middleware vendors to develop and manage this server. We can also use an AON. We can expect these tools to support, at the minimum, remote configuration and monitoring.
Adding a second data center
An enterprise may rely on more than one data center for multiple reasons. Every office can be served from the closest data center to provide fast responses. Enterprise operations can be kept up and running even if disaster strikes in one of the data center locations. Adding a second data center brings additional complexity.
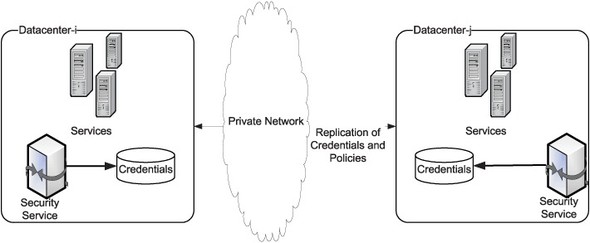
Each data center may house its own credential stores and security service. In such a case, we need to set up mechanisms for replicating credentials and security policies between the data centers as shown in figure 10.10. All LDAP directories support replication between multiple instances of the same make. If you use directories from different vendors in different locations, you will need to build your own replication mechanisms unless all vendors support LDAP Duplication Protocol (LDUP). How you replicate security policies will depend on where you store them. If you are using a service registry to store your policies, you will need to check with your registry vendor to understand how you can replicate registry contents between multiple instances.
Figure 10.10. When using multiple data centers, enterprises need to replicate credentials and policies across all data centers.
Managing trust between autonomous units or regions
Multinational companies have autonomous units in different countries or regions to satisfy legal requirements in each location. The strength of relationships between autonomous units can vary from enterprise to enterprise. In most cases, there is a trust established between autonomous units so that they can use some of each other’s services over a private network. Trust between these enterprises—established by accepting each other’s digital certificates, Kerberos tickets, or other mechanisms—needs to be maintained and managed as both enterprises evolve as shown in figure 10.11.
Figure 10.11. Trust relationships between multiple autonomous units of an enterprise need to be maintained. A trust relationship may be based on acceptance of security tokens issued by each other’s security service for invocation of specific services shared between the units.

There is no one specific technique for trust management, as requirements will vary widely between enterprises. Here, technology plays only a limited role; there is a need for defining and managing security processes to establish and manage this trust.
We have so far discussed possible deployment architectures for securing services in the intranet. Let’s now discuss the deployment architectures for securing services offered to the public.
10.3.2. For securing services offered to the public
We have seen in the previous section how, contrary to our initial expectations, deployment of a security solution for intranet services can get quite complex. The situation is the opposite for deployment of services offered to the public. Thanks to the popularity of web applications, most techniques needed for securely deploying services offered to the public, for instance firewalls and the demilitarized zone (DMZ), are well understood. There are a few new questions to be answered before we can decide on specific deployment architecture for publicly offered services. We will cover these later in this chapter.
Before we proceed we need to introduce two common techniques—one from network security and another from web application deployment. A good understanding of these techniques is needed to follow the rest of the discussion in this section.
Introduction to firewalls
A firewall is a network device that filters traffic passing through it based on rules set up by the firewall administrator. To understand firewalls, you need to understand how a network works.
An application message, such as a SOAP request addressed by one endpoint to another, gets split into one or more packets by the network. Each packet carries a part of the data in the application message, plus addressing information and other control fields (such as a checksum). The addressing information within a packet is different from what we understand as that at an application level. The endpoint URI for a service call is not part of the addressing information in packets that make up the service call. Instead, all that is available at the network layer is
- Source and destination IP address
- Transport (not to be confused with what we call transport in the case of web services) protocol, typically TCP or UDP
- In the case of TCP and UDP, source and destination port numbers
As a network firewall filters one packet at a time, the filtering rules you provide to a firewall can only be based on information available within a packet. The kinds of rules firewalls can use for filtering
- Allow any TCP packet addressed to port 80/443 of 192.168.1.2 (my web server’s IP address).
- Allow any TCP packet addressed to port 25 of 192.168.1.3 (my mail server’s IP address).
- Allow all packets whose source IP address is 192.168.1.x (my internal subnet). This rule allows internal hosts to send packets out.
- Disallow attempts to establish a new inbound TCP connection (TCP SYN) except those allowed by rules 1, 2, and 3.
- Allow all TCP packets not covered by rule 4 so my internal hosts can receive responses on connections they have initiated.
- Disallow all other packets.
Figure 10.12 illustrates the combined effect of rules 1, 2, and 4. As you can see, firewall rules can be used to block all packets except those that we specifically allow to come in or go out of our internal network.
Figure 10.12. Example of a firewall rule: An inbound TCP SYN that signifies an attempt to establish a new TCP connection is discarded unless it is destined to the web server or email server.

Introduction to DMZ
It is no good stating that we will firewall every application. There are always a few applications that need to be exposed to the outside world. For example, a mail server is always needed to receive emails from customers, partners, and the general public. As no piece of code is ever perfect, we need to prepare for the eventuality of an attacker gaining complete control over the machines hosting publicly accessible applications. A security hole such as a buffer overflow in an application can allow an attacker to execute arbitrary code on the server and obtain, in lots of cases, privileged access. A common technique used to defend against compromise of publicly exposed applications is to place them in a separate subnet called the DMZ.
Applications in a DMZ can receive packets from anywhere—from within the enterprise intranet or from a public network. Applications in a DMZ cannot, in general, initiate connections to nodes within the enterprise intranet. The damage an attacker can cause is limited even if he assumes complete control over a machine within the DMZ.
There are multiple ways to implement a DMZ. Figure 10.13 shows a popular implementation strategy. Two firewalls are used in this strategy:
Figure 10.13. DMZ implementation using two firewalls. The inner firewall discards any attempts by DMZ hosts to initiate a new connection into the internal network.

- An outer firewall that only allows connections to specific applications hosted in the DMZ
- An inner firewall that only allows new connections one way—from an internal network into the DMZ but not the other way around
One or both firewalls may additionally do Network Address Translation (NAT) from publicly known IP addresses to private IP addresses. This further enhances security.
In practice, limited exceptions are made to allow applications within the DMZ to access specific applications within the intranet that they depend upon. It is common to punch a hole in the inner firewall to let a web server access a database within the internal network, as shown in figure 10.14.
Figure 10.14. A web server located in the DMZ is often allowed to initiate a connection to a database server within the internal network, as it is a more secure choice than moving the database server as well into the DMZ. Connection initiation attempts by the web server in the DMZ to any internal application other than the database server will be discarded.

Although this seems, at first sight, to be a serious dilution of the concept of DMZ, this is a better choice than placing all the needed applications into the DMZ. We could have placed the database server as well in the DMZ, but this is not a good alternative, as the database server would get opened up for direct attack.[2]
2 This is true even if we do not allow direct access to the database server in the DMZ across the outer firewall. An attacker who gains control of another machine in the DMZ can launch a DoS attack on the database server by flooding it with TCP SYNs.
In some cases, punching holes in the inner firewall can be avoided if the direction of connection establishment can be reversed. If the application in the internal network can be made to establish a connection to the application in the DMZ no hole would be needed in the inner firewall. The DMZ application can then use the connection established by the internal application for all subsequent communication.
Deployment of publicly exposed web services
Now that you understand the concepts of firewalls and DMZ, it is easy to see how a security solution should be deployed for publicly exposed services.
As the public web services will themselves be hosted in the DMZ, a security service protecting them will also have to be in the DMZ. This service should protect the public services by validating incoming requests against a schema, scanning the requests for commonly used XML attacks, then authenticating and authorizing the request. This kind of security service is a web services security gateway.
Where should the credential store (directory server) for authentication be deployed? The directory server should be within the internal network, as placing it in the DMZ will expose it to direct attacks. A specific hole needs to be punched into the inner firewall to let the security service in the DMZ contact the directory service in the internal network as shown in figure 10.15.
Figure 10.15. Example deployment architecture for securing services offered to the public.

There is another important and interesting question to answer here. Where should the enterprise’s private key be stored? If the inbound messages received by the security service are encrypted, the security service will need access to the enterprise’s private key in order to decrypt incoming messages. It is not a good idea to permanently store the enterprise private key in the DMZ, as it could be stolen more easily. The key needs to be protected by placing it in the internal network.
When the security service requires the private key for decryption, it can fetch the key from the credential repository in the internal network. The security service should not remember the private key for too long, as the key can be stolen if the security service itself is compromised.
A more secure option is to rely on a service offered from within the internal network to decrypt incoming requests. That way, the enterprise private key never leaves the internal network. Another hole needs to be punched into the inner firewall to let the security service in the DMZ contact the decryption service in the internal network. Or, the decryption service can initiate a connection to the security service in the DMZ and the latter can use the established connection to invoke decryption services.
You now have a good idea about possible deployment architectures when securing services in the intranet and when securing services offered to the public. Let’s look into the possibilities when securing services offered to/by partners.
10.3.3. For securing services offered to/by partners
Partners are different from the general public or internal members. They get controlled and limited exposure to the enterprise. Not all partners are alike. We will consider three kinds of partners for discussion in this section.
- Large partners providing their own services for the enterprise’s benefit in addition to consuming services offered by the enterprise.
- Small partners without much IT infrastructure to speak of. We can assume that these partners do not offer any services of their own. They simply consume services offered by the enterprise.
- Managed service providers which host services for use by the enterprise. They do not consume any of the services provided by the enterprise.
Not all partners of every enterprise will fit into one of these three classes perfectly. We just picked these three to illustrate the deployment choices available when integrating with partners. Figure 10.16 shows a deployment option each for these three classes of partners.
Figure 10.16. Security solution deployment for offering services to partners and consuming partner services. Note that we have not shown the security solutions used internally by each of the partners or managed service providers.

Small partners with little IT infrastructure of their own may not have the ability to satisfy the security policies of the enterprise. For example, a small partner may not have a security solution in place that can encrypt parts of a message that need to be kept confidential. In these cases, the enterprise can require its small partners to place a security agent that will help them comply with the enterprise security policies in their networks. The security agent can take the form of a device (such as an AON) that can be remotely managed. This will keep the burden on the small partner to the least amount necessary.
Requests secured by a security agent at the partner’s site can be trusted and routed directly to web services offered for partners. Requests emanating from large partners who do not use the enterprise’s security agent will have to be first screened by a security gateway in the enterprise DMZ.
Requests to partner-provided services or services hosted by a managed service provider will also have to adhere to the enterprise’s security policy. When we say security policy here, we are referring to the policy for outgoing messages. In figure 10.16, we illustrate a logical separation between a security gateway for inbound messages and a security gateway for outbound messages.
In this section, we described the possible deployment architectures for securing services in the intranet, services offered to the public, and services offered to/by partners. We will next look into another important challenge enterprise SOA security practitioners face: making the security solution industrial-strength.
10.4. Making the solution industrial-strength
SOA is becoming an important part of IT strategy. One of the prerequisites of widescale deployment of SOA is that it should be industrial-strength. That is, corporations can rely on it to support business needs. Security solutions for SOA should support the same goals. In this section, we will examine what it means to make a SOA security solution industrial-strength and how we can achieve that goal. In particular, we will describe how you can address performance, scalability, and availability requirements. We will start with a discussion of performance issues.
10.4.1. Performance
Everybody likes their systems to perform well. Unfortunately, compared to the tightly coupled systems that are typically replaced by SOA, performance of SOA systems lags behind. This is a big concern for enterprises embracing SOA. Fortunately, there are several ways to increase the performance of systems based on SOA. In this section, we are going to confine ourselves to only those that increase the performance of the security solutions.
One clear guideline about improving the performance is this: unless we know where the performance bottleneck is, we cannot develop an efficient solution. Speeding up a task that takes 50 percent of overall time by 10 percent has more impact than speeding up a task that takes 10 percent of overall time by 50 percent. Therefore, we should start optimizing once we have good metrics on where time is being spent in the total solution.
Next, let’s consider what you can do when you encounter a performance bottleneck.
Hardware solutions
There are several tasks that are part of a security solution that can effectively be done in hardware. Hardware offers increased performance in multiple ways, at a cost of increased complexity. Special-purpose hardware can be faster than general-purpose processors, since it can be optimized specifically to do the task it is designed for. At a minimum, it offloads the burden from the main processor, allowing it to do other tasks. It introduces additional complexity—the program or the processor needs to know which task to delegate to the hardware. If the program needs to do the delegation, it needs to be explicitly coded. In some specific cases, the processor can invoke the hardware device without explicitly being asked.
The best candidates for hardware acceleration are ones with very well-understood requirements. For example, point-to-point encryption is well understood and is expensive enough to benefit from hardware acceleration. Indeed, several special-purpose hardware chips offer SSL in hardware. These have been in use since even before SOA—and are applicable in SOA security as well—to provide network-level encryption.
Not all time-consuming activity can be done in hardware. Typically the difficulty lies in coming up with a problem that is well defined and can be done in hardware more efficiently so that the overall solution can be faster. There are only so many tasks that fit this description. One recent approach is to expand the range of tasks that the hardware can do by making hardware programmable.
One such example, as discussed in appendix E, is AON. AON solutions can be programmed to do well-defined horizontal tasks (that is, those that do not require deep domain knowledge): security, auditing, content-based routing, load balancing, and so on. We can only expect the increased use of such special-purpose hardware to provide well-understood generic services that are customizable for a situation. The complexity these days lies in customizing and maintaining the total SOA solution. With enough attention to these problems, hardware solutions may become more and more usable.
Software solutions
Hardware-based solutions for improving performance are not always applicable. Improving the design and implementation of the solution in software can often improve performance to the required levels. Here are some of popular techniques:
- Credential caching One of the tasks of security is to authenticate and authorize the users. Most of the time, this necessitates a user-to-role map lookup in an external store. We can speed up access to the credential store considerably using various techniques. For example, we can maintain a local cache that keeps all user credentials. With machine memory being cheap, this often is a workable solution. We can also keep this cache as needed, building it up as we go along. Caching may weaken the overall security of a solution. Vulnerability in the service may be exploited by an attacker to access the cached credentials. A common strategy is to not remember sensitive parts of the credentials, such as passwords, while retaining relatively less sensitive information in the cache.
- Replication of the authentication source In a distributed organization, authentication and authorization can happen at different locations. If the credential store is not local, it can take time to invoke. A standard technique is to replicate this store locally using well-established methods (for example, using LDAP replication).
- Maintaining the state Imagine you’re logging in to a system using a password. Once you log in, each interaction happening in that session assumes the same security context. In the case of web services, since there is no state, each service call needs to be authenticated explicitly. If we can keep state somehow, we can avoid establishing the security context each time. If we are hand-coding the application, we can use tokens that can be passed between the client and server, much like cookies in the HTTP protocol. WS-SecureConversation formalizes this in the context of web services.
- Using SAML We can set up the framework in such a way that the security context is always maintained with the request by using SAML. Thus, we can ensure that multiple services have access to this information. In composite services, it is particularly important to use this mechanism since multiple services may require this information.
This is not an exhaustive list of possible optimizations. As mentioned, any optimization must start with a performance profile of the application. Most of the standard optimization techniques work well for security solutions, too. In particular, XPath evaluations cause serious performance degradation in applications. We can handle this in two different ways: by reducing the complexity of XPath expressions that need evaluation and by using libraries that reduce XPath evaluation cost.
Let’s take a look at what scalability means for a SOA security solution, and how we can achieve it.
10.4.2. Scalability
As the performance and load requirements on the application keep increasing, we need to make sure the application can handle it by adding more resources. If we configure a system to handle 1000 users and if it had to handle 10,000 users, we need to make it work by adding more hardware resources—additional memory, additional disks, additional machines, and additional network infrastructure.
Normally scalability is achieved through adding more machines. We can make use of more machines effectively only if we can partition the problem in such a way that each machine can be engaged in solving a part of the problem. There are three ways we can engage multiple machines:
- Horizontal partitioning To engage multiple computers, we can do a horizontal portioning of the problem, where different parts are solved by the different machines. By separating security as an independent task, we can dedicate a machine for it. We can further subdivide the task of security to achieve greater scalibility, which comes at a cost. We need to pull together the answers from multiple services to generate the answer for a security service. The communication costs can exceed the benefits of the scalability. In addition, there are natural limits to horizontal partitioning; there are only so many subtasks that the security service can be divided into.
- Vertical partitioning A better approach to scalability is to partition the problem vertically. In this approach, we replicate the service in multiple nodes and direct clients to services so that all the machines are used. That is, we map the incoming requests to appropriate instances of the service. This mapping can take place in multiple ways. We can do this mapping statically—requests for users whose usernames start with A-M on one machine and N-Z on another machine. Or, based on incoming IP number, we can map the users to a specific machine. A more complex dynamic allocation can take into account the load and availability information of each machine to allocate the task to a lightly loaded and available server. In any case, as the number of service requests increase, we can increase the number of machines to provide better response.
- Replication of crucial resources One specific case of vertical partitioning is when we replicate credential stores closer to where we are authenticating. This can provide needed scalability when these stores become the bottlenecks.
If we separate security concerns into a service, we can easily make it scalable. Even if we build security into each service, we can replicate essential parts to provide the scalability. This scalability needs synchronization among the replicated resources, which is not difficult to do.
We have so far discussed how to address performance and scalability concerns of an enterprise when securing its services. Let’s now discuss another important concern any enterprise will have when deploying a SOA security solution: availability.
10.4.3. Availability
If we make every service implement security, we must make sure that security works all the time. If not, applications stop when the security solution does not work. Thus, availability of security solutions is important in an enterprise.
There are standard ways to ensure high availability. If there is a critical resource such as a directory service or a token-granting service that is the central piece in a security resource, it should be configured for high availability. For instance, if we are depending on some files, we can use highly available storage solutions such as storage area network (SAN). If we are depending on a critical data source, we can set up a hot spare, which needs to be kept in sync with the main server. If we have a critical service, we can run it in a cluster that manages one machine as a backup for the other.
This concludes our description of possible approaches for performance, scalability, and availability requirements for a SOA security solution. These are very important concerns in real-world deployments, and any enterprise SOA security architect should have experience dealing with them.
Despite all our effort, we know that no security solution can be perfect. We can proactively develop defensive practices that reduce the damage that attackers can cause. In the next section, we will address under this issue by looking at how we manage vulnerabilities in our solutions.
10.5. Vulnerability management
As indicated at the beginning of the book, we have not been discussing security holes introduced by poorly written code. For example, we have not focused on the possibility of a buffer overflow in a service implementation. In the real world, you need to worry about such vulnerabilities in your services, service consumers, intermediaries, the security service itself, and any other services/libraries you depend on. Here we will briefly discuss the kinds of vulnerabilities you need to guard against and common techniques to do so. In particular, we will discuss:
- Common vulnerabilities in any software that hackers usually seek to attack
- XML-specific vulnerabilities
- A workflow process you can use to stay on top of vulnerabilities in your services/security solution
Let’s start with a discussion of common vulnerabilities in any software that hackers usually seek to attack.
10.5.1. Common vulnerabilities
Code in SOA implementations, like any other code, is vulnerable to certain common forms of attack. Thanks to the focus on security brought about by numerous virus attacks in recent years, common vulnerabilities in code are well understood by the security community. Techniques and processes to defend against common vulnerabilities are also well understood. Here is a representative sample of common vulnerabilities and techniques to defend against them.
Vulnerability to buffer overflow attacks
Buffer overflow is probably the most commonly exploited security hole. This problem occurs when a program preallocates fixed buffers to deal with inputs and processing. Under certain circumstances, by carefully crafting the input, the program can be made to write and access beyond those preallocated buffers and trick the system into violating security constraints. The references listed at the end of this chapter will help you understand this topic in greater detail. What we will briefly mention here are the techniques to guard against buffer overflow vulnerabilities.
A first line of defense against buffer overflow attacks is provided by some of the modern programming platforms. Java, for example, internally checks all array access for bounds violations. Array bounds checking also happens internally when managed code is executed in .NET.
All this checking certainly causes performance degradation. But most applications can afford to pay this cost. For high-performance applications that cannot afford the cost of automatic bounds checking, you will have to rely on the programmer’s skill to make sure that buffer overflows do not occur. You can choose to have a second line of defense, though.
Assume that your application does indeed have a buffer overflow vulnerability and try to minimize what an attacker can do after successfully exploiting the vulnerability. Never give an application more privileges than it really needs. Configure vulnerable applications to be run using accounts that do not have administrative privileges. This way, the amount of damage an attacker can cause is limited.
On Unix you can further limit the damage by running an application in a chroot jail. See the references listed at the end of this chapter for information on what a chroot jail is and how you can set it up.
Vulnerability to SQL injection attacks
Most business services rely on a database. If a service composes an SQL query using data provided by the caller without vetting the data first, it runs the risk of an SQL injection attack. The following query is composed by a BankAccount service to implement a balance query operation.
"select balance from account where accountId = '" + accountId + "'";
The implementer of this service expects that the caller will provide an accountId, as shown here:
<queryBalance> <accountId>account123</accountId> </queryBalance>
A malicious caller may guess the details of this implementation and try submitting the following instead as accountId.
<queryBalance>
<accountId>
account123';
update table account set (balance) values (1000000)
where accountId='account123';
select balance from account where accountId='account123'
</accountId>
</queryBalance>
If the service implementer is naïve and uses the caller-provided accountId as is when composing the SQL query, the composed query will now consist of three SQL statements:
select balance from account where accountId = 'account123'; update table account set (balance) values (1000000) where accountId='account123'; select balance from account where accountId='account123';
As you can see, the malicious caller is able to update the balance in an account to a million dollars! These are known as SQL injection attacks and are representative of a large class of attacks that take advantage of applications that do not sanitize input before using it.
The only effective antidote to SQL injection attacks is in the hands of programmers; security administrators can only ensure that no more privileges than necessary are granted to an application in the database security configuration.
Almost every database access API provides a safe way of binding user input to placeholders in an SQL query. Quotes and special characters are escaped or handled appropriately if a programmer uses such APIs. Java programmers should use a PreparedStatement with placeholders instead of composing a Statement using string concatenation. Figure 10.17 shows the architecture for general input validation.
Figure 10.17. All inputs should be treated as tainted and scrubbed before using them in a service. This is especially true of any data that forms a part of a command or program.

Programming languages such as Perl also provide facilities to mark all input as tainted and disallow direct use of suspect data. Programmers can only remove the taint attached to an input data item by extracting a specific pattern of characters from it. In the balance query code shown previously, the accountId provided by the user can be sanitized by picking only the first substring of alphanumeric characters using a regular expression such as [a-zA-Z0-9]+.
Vulnerability to distributed denial of service (DDoS) attacks
There is not much most applications can do when hit with a flood of concurrent requests from multiple points in the network. Almost all software crumbles under such an attack, resulting in DoS to legitimate users.
To cope with DDoS attacks, applications need to be able to quickly distinguish between legitimate requests and others. The faster this check can be made, the more an application can stand up to a DDoS attack. Unfortunately the rate at which an application can screen requests can be exceeded by the rate at which bad requests are coming in. Filtering needs to happen early and at multiple access points to the network, as shown in figure 10.18. Every access point into the network hosting the application needs to be equipped with firewalls that can filter good traffic from bad. Several network vendors provide products that can do this job effectively.
Figure 10.18. The top half of this picture shows how a DDoS attack can be launched by flooding a service with requests from a large number of clients. The bottom half of the picture shows a strategy for coping with DDoS attacks. By filtering traffic generated by DoS attackers early and at multiple access points, the impact of DDoS on a target service can be eliminated.

So far, we’ve discussed common vulnerabilities that are found in any software. Let’s next discuss specific vulnerabilities that XML-based web services may possess.
10.5.2. XML-specific vulnerabilities
In addition to the vulnerabilities that SOA software shares with every other piece of code, there are a few more that are likely to be specific to SOA. Almost all SOA implementations involve a lot of XML processing, and XML brings its own set of new vulnerabilities.
The biggest source of vulnerabilities in XML lies in the facility for defining internal and external entities. Entities are declared within a Document Type Definition (DTD). An internal entity in a DTD is like a named constant in a program.
<!ENTITY constant1 "value1">
An external entity in a DTD is like an include/import statement; it allows the DTD to get a part of its contents from external sources.
<!ENTITY importFromFile SYSTEM "/some/file/path"> <!ENTITY importViaHttp SYSTEM "http://... ">
Once an entity is defined, it can be referenced using the syntax &entityName;. Two types of potential attacks are reported in the use of entities: entity recursion attacks and external entity attacks. We will describe each separately.
Entity recursion attacks
It is possible to define one entity’s value by referring to another.
<!ENTITY constant1 "value1"> <!ENTITY constant2 "&constant1; and value2">
Any reference to constant2 now expands to "value1 and value2". It is possible to quickly build up large amount of text:
<!ENTITY constant1 "value1"> <!ENTITY constant2 "&constant1;&constant1"> <!ENTITY constant3 "&constant2;&constant2"> ... <!ENTITY constantN "&constantNminus1;&constantNminus1">
By defining the value of constantN as a concatenation of two constantNminus1 values, we have employed recursion to build 2N-1 repetitions of constant1. This constitutes a vulnerability in the following sense.
An attacker can submit an XML document with an internal DTD subset that employs the recursive definition trick shown here to exhaust the memory resources available to the recipient’s program. Note that recursion allows one to generate exponentially growing output with input that only needs to grow linearly. In our example, an attacker can generate 232 repetitions of constant1 simply by defining 32+1 constants recursively. The attacker’s program does not require much memory to generate input that will exhaust the attacked program’s memory resources.
External entity attacks
Almost every XML parser allows you to plug in an external entity resolver that can resolve external entity references. A naïve implementation of a resolver that simply resolves any external reference is bound to introduce vulnerabilities, such as the following:
- An attacker can use the external entity resolution facility available in multiple services to launch a DDoS attack.
- An attacker can bring down the performance of the attacked program by making it repeatedly access a limited system resource, such as /dev/random (a random number generator that can cause a performance hit if accessed very frequently) or c:concon (a path that crashes Windows 98 when accessed).
- An attacker may use an echo service to read files on the target service that he does not otherwise have access to.
A security-conscious implementation of an external entity resolver will limit resolution to a limited set of known locations.
Guarding against entity attacks
To rule out the possibility of entity attacks, SOAP explicitly prohibits the presence of DTD (and processing instructions) within a SOAP message. If your SOAP-processing engine is compliant with the SOAP specification, it should not be vulnerable to entity attacks.
If your SOA software accepts any XML input other than SOAP messages, you may need to turn off entity expansion altogether to completely secure yourself against entity attacks.
Validating XML inputs to guard against other XML attacks
In security enforcement, it is always a good idea to ban everything first, then allow a few trusted entities. This principle should be applied, where possible, when accepting XML inputs. If schema definitions exist for the XML inputs your services accept, validate incoming XML against those schemas. Schema-based validation is expensive, and you may see a performance hit when you introduce validation into your processing. If the performance hit you are seeing is unacceptable, evaluate the use of high-performance validators that are available in the market.
Despite that, two important limitations of schema-based validation need to be kept in mind.
- Schema-based validation is not always possible. To develop a schema, one needs to know the structure of a document in its entirety. This is not always possible. For example, if you are developing a routing service for B2B documents, you may not understand the entirety of every possible B2B document. You may only know and care about the fields that provide the basis for routing decisions in your service. In such cases, use other XML validation techniques that you find to be applicable. You may employ a rule-based validation scheme that validates just those parts of each document that you know and care about.
- Schemas represent theoretical limits on the structure of a document and do not impose the practical limits that a security service would want. A schema may allow any number of repetitions of a particular element in an XML document. In reality, the XML parser that processes the document may have practical limits on how many repetitions it can handle, depending on how it parses the document. A streaming parser may process an arbitrarily high number of repetitions, whereas a DOM parser may have restrictions imposed by memory. It is desirable to impose some practical limits on XML inputs—no messages larger than 2 MB—if you suspect that your services may not handle larger inputs well.
As you can see, validation of XML messages is turning out to be a specialized area. XML security appliances in the market address this area well. For a list of vendors, see appendix E.
Thanks to the focus on security in the last few years, enterprises have a much better understanding of how to stay on top of vulnerabilities that are common in software. Next we’ll discuss a workflow process enterprises use to fix vulnerabilities promptly and regularly.
10.5.3. Vulnerability remediation workflow
Security experts recognize that there will always be many more vulnerabilities in our code than we recognize at any point. Guarding against vulnerabilities is not a one-time activity. It obviously requires constant vigilance. It is important to institute a process for patching up vulnerabilities when they are reported. Vulnerability remediation is an important workflow within an IT organization. Figure 10.19 depicts this workflow.
Figure 10.19. By following a well-managed vulnerability remediation workflow, you can reduce the threat posed by vulnerabilities. This picture shows the steps involved in a vulnerability remediation workflow and the personnel who need to participate in it.

Activities that are part of this workflow are
- Scouring security-related forums for reports on new vulnerabilities
- Assessing the impact of each reported vulnerability
- Finding a workaround or locating a patch
- Testing the workaround/patch
- Planning a deployment
- Getting approval for deployment
- Scheduling deployment of the workaround/patch
- Verifying the effectiveness of the workaround/patch once it is deployed
Figure 10.19 identifies the owner of each step in a typical enterprise. In a large enterprise, this workflow needs to be managed by tools. Manual management can be cumbersome, as the number of resources and management processes is too great.
10.6. Summary
Developing a SOA security solution for an enterprise is not easy. One needs to combine all of the ideas introduced in the previous chapters with the right implementation and deployment choices to create a solution that fits the needs of the enterprise. In this chapter, we tried to give you a good idea of the challenges you are likely to face and the choices you have when designing a SOA security solution for real-world enterprises.
We first explained the demands enterprise IT environments place on software solutions. An enterprise SOA security solution must be usable by a large and diverse user base, must remain usable over a long time, must be robust, and must be easy to manage. In addition, as most enterprises are likely to have a mix of services—some developed from scratch, some that wrap legacy applications, and some high-level services that compose lower-level services—we explained the variations in strategies you can use for securing these different kinds of services.
We also discussed myriad considerations that can go into designing the deployment strategy for a SOA security solution. We discussed methods of deployment in an enterprise—with branch offices, with partners, and to the general public. The deployment scenarios differ in how elements of the solution can be placed in the network.
While the issue of DoS attacks is not the focus of this book, we discussed a few issues that can affect security—in particular, we showed how XML-based attacks work and how to protect applications from them.
One warning: This chapter merely touched on issues that come up when developing an enterprise-class SOA security solution. Unlike other chapters, we cannot offer a fully working concrete example here. The best way to use this chapter is to understand your particular problem in the terms explained here. With enough practice, you will be able to extend the lessons in this chapter to solve your security problems.
This chapter completes our book on SOA security. By reading this book, you have come to understand that SOA security is quite different from typical application security. Fortunately, SOA standards help you build good secure solutions.
If you are with us thus far, you have learned the standards through simple examples, along with the underlying technologies. You also have seen the different options for full-fledged frameworks and several practical challenges. Depending on your responsibilities, you can use this knowledge directly in building a security solution for your application; or you can use it in formulating SOA security strategy for your enterprise based on vendor tools and products. In either case, we hope the information you’ve learned from this book—the standards, code explanations, and underlying technologies—will help you on your way to mastering SOA security.
Suggestions for further reading
- CICS (Customer Information Control System) transaction server, first introduced in 1969, is still used by a large number of enterprises for core business services that require very high performance and reliability. CICS applications are a good example of legacy applications that will be wrapped as services. CICS Transaction Server 3.1 introduced support for web services. WS-Security is supported, too. See http://publib.boulder.ibm.com/infocenter/cicsts/v3r1/topic/com.ibm.cics.ts31.doc/dfhws/wsSecurity/dfhws_WSSecurity.htm.
- SAP R/3 is an enterprise resource planning (ERP) application a large number of enterprises use for managing their business. SAP R/3 is a good example of a legacy application around which services may be wrapped. Interestingly, SAP is promising to support web services natively in their software, as part of an initiative named Enterprise Service Architecture (ESA). ESA is described in detail in Enterprise SOA: Designing IT for Business Innovation, by Dan Woods and Thomas Mattern, published by O’Reilly Media, Inc. in April 2006. ISBN: 0596102380.
- Writing Secure Code, by Michael Howard and David LeBlanc (Microsoft Press, 2002) describes the precautions you need to take to avoid vulnerabilities to buffer overflow, SQL injection, and other such attacks. This ISBN is 0735617228.
- Practical Unix and Internet Security, Third Edition, by Simson Garfinkel, Gene Spafford, and Alan Schwartz, is a good reference for understanding firewalls and chroot jails, in addition to many more security topics. This book was published by O’Reilly Media, Inc. in February 2003.
- Section 10 of RFC 3023 lists some of the possible vulnerabilities in XML processing. The RFC is available at http://tools.ietf.org/html/3023.
- The example of an entity recursion attack shown in this chapter was constructed and reported by Mark O’Neill as described at http://www.vordel.com/knowledgebase/vordel_view5.html.
- Gregory Steuck Security Advisory #1, 2002 describes how external entity resolution may introduce several vulnerabilities. See http://www.securityfocus.com/archive/1/297714.