
17. XML Support
Extensible Markup Language (XML) is a way of representing data and data relationships in text files. Because such UNICODE text files have become widespread and are usually platform independent, XML is being used heavily for data transfer, especially between databases and the Web.
As you will see, XML shares some characteristics with HTML. However, the two markup languages have very different goals. HTML is designed to give instructions to a browser about how to display a page. XML, in contrast, is designed to describe the structure of data and to facilitate moving that data from one place to another.
Relational databases can use XML in three ways:
◊ Import XML documents and store the data in one or more relations: At this time, such functionality is not provided within the SQL standard. In practice, it requires program code that is specific to a particular DBMS and therefore is beyond the scope of this book.
◊ Format data stored in relations as XML for output: SQL/XML, which first appeared in the SQL:2003 standard, provides a group of functions for performing this output. The standard also includes detailed instructions for mapping SQL elements to XML.
This chapter covers the basics of the structure of XML documents. It then looks at the major SQL/XML functions and the XML data type.
XML Basics
XML is a markup language. In other words, you place special coding in the text to identify data elements. It shares some contents with HTML, but at the same time is both more and less flexible. (As you will see, this is not a contradiction!)
Note: The following is not intended to be a complete primer on XML. It will, however, give you more than enough background to understand what SQL/XML can and cannot do.
XML Structure
XML data are organized in hierarchies. As an example, consider the hierarchies diagrammed in Figure 17-1, both of which are taken from the rare book store database. Notice that it takes two hierarchies to represent the entire database because a hierarchy does not allow a child element—an element at the “many” end of a 1:M relationship—to have two parent elements (elements at the “one” end of a 1:M relationship). Therefore, we can represent the relationship between a customer, a sale, and a volume or the relationship between author, work, book, and volume, but not both within the same hierarchy.
 |
| Figure 17-1 Hierarchies for the rare book store database for use in an XML document |
Parent elements may have more than one type of child entity. As an example, consider the hierarchy in Figure 17-2. Each department has many salespeople working for it. A salesperson has many contacts (potential customers) but also makes many sales. Each sale is for one or more customers and contains one or more items. This entire hierarchy can be represented as a whole in an XML document.
 |
| Figure 17-2 A hierarchy that includes parent elements with multiple child element types |
Because of their hierarchical structure, XML documents are said to be organized in tree structures. (You will discover later in this chapter that this botanical terminology turns up in other places in XML.)
Each hierarchy has a root element, the top element in the hierarchy. In Figure 17-1, there are two root elements—Author and Customer; Figure 17-2 has only one root element, Department.
Attributes
As well as having child elements, an element may have “attributes.” An attribute is a single data value that describes an element. For example, in Figure 17-2, a department might have its name and the name of its manager as attributes. In contrast, salespeople and the data that describe them are represented as child elements.
Attributes do have some limitations. First, they are single-valued; elements can be multi-valued. Because they are a single value attached to an element, attributes can't be related to other attributes or elements. Attributes also make the structure of the XML more difficult to modify should the underlying structure of the data change.
XML Document Structure
An XML document really has a very simple structure: It is made up of nested pairs of tags. With the exception of the first line in the file, that's all there is to it. (If this were an e-mail rather than a book, a smiley face would go here.)
Tags
Elements and their data are identified by tags in the text file. These tags are similar to HTML tags but don't come from a fixed set of tags like those available for HTML. Each element begins with an opening tag—
<element_name>
—and ends with a closing tab:
</element_name>
Unlike HTML, which has some tags that don't come in pairs (for example <LI>), all XML tags must be paired. Between its tags, an element has either a data value or other elements. Nested elements may in turn have data values or other elements.
As mentioned earlier, XML elements may have attributes as well as elements that are nested beneath them. An attribute is a single occurrence of a value that describes an element. Their values are placed within the element's opening tag:
<element_name attribute_name =
“attribute_value” …>
Attribute values must be quoted.
If you have a pair of tags that have attributes but no nested elements (an empty tag), then you can get away with combining the two tags into one, placing the closing symbol (/) just before the closing symbol (>):
<element_name element_data/>
You can find a portion of an XML document that describes some of the data for the hierarchy in Figure 17-2 in Figure 17-3.
Note: The indentation is not required and is included here to make the code easier to read. In fact, the indentation and spacing in some of the longer listings in this chapter have been changed in the interest of space preservation. Nonetheless, the structures of the documents have been maintained through the proper use of nested tags.
 |
| Figure 17-3 A portion of an XML document |
Declarations (Prologs)
Each XML document begins with a declaration (or prolog) that identifies the version of XML being used and optionally a character encoding scheme. The particular encoding specified in Figure 17-3 identifies a Western European (and thus also North American) scheme.
The declaration also optionally includes an attribute named STANDALONE. When its value is “yes,” the document has no external references needed to understand its content. If the value is “no,” then an application processing the XML document will need to consult outside resources to get complete information for understanding the document. Although many of the examples of declarations that you will see include this attribute, in practice it is not widely used.
The declaration is followed by the opening tag for the root element; the last line in the document is the closing tag for the root element. In between the root element tags, the document contains the elements describing the remainder of the data.
Being “Well-Formed”
As you read about XML and XML documents, especially in the context of interactions with databases, you will find references to well-formed XML documents. An XML document is well-formed if it meets all the XML syntax rules. Specifically, that means that:
XML Schemas
To help validate the structure of an XML document, you can create an XML schema, a special type of XML document that contains definitions of document structure. An XML schema also defines data types for elements and attributes. It can also contain a number of domain constraints.
Note: XML schemas are a relatively recent addition to XML. The older description of the structure of an XML file is a DTD (Document Type Definition).
Unlike XML documents, XML schemas use predefined element tags and element attributes. An example can be found in Figure 17-4, which contains a schema that describes the structure of the XML in Figure 17-3.
 |
| Figure 17-4 An XML schema that describes the XML document in Figure 17-3 |
This schema contains the following elements:
◊ xs:schema: The root element.
◊ xs:element: A declaration of a root element. Each element has a name and a data type. XML includes string, integer, decimal, boolean, date, and time types.
◊ xs:complexType: A group of elements that contains multiple data types.
◊ xs:sequence (an indicator): A group of elements that must appear in the order specified within the pair of sequence tags.
◊ xs:all (an indicator): A group of elements that can appear in any order specified within the pair of sequence tags. Each element can appear only once within the group.
At the time this book was written, the SQL standard was not designed to take advantage of SQL schemas for XML validation. Should you need to determine whether an XML document is well-formed, you will need to examine the document using third-party software.
SQL/XML
SQL/XML, the extensions that provide XML support from within the SQL language, entered the standard in 2003.
Note: XML standards now include a language called XQuery. It is separate from SQL and appeals primarily to XML programmers who need to interact with data stored in a relational database. In contrast, SQL/XML tends to appeal to SQL programmers who need to generate XML documents.
XML Publishing Functions
SQL/XML's publishing functions extract data from tables and produce XML. You can therefore use a series of the functions—most usually within an embedded SQL application—to generate an entire XML document.
XMLCOMMENT
XML documents can include any comments needed. The XMLCOMMENT function has the general syntax:
XMLCOMMENT (source_string);
The source string can be a literal string or a string stored in a host language variable. The SQL statement
SELECT XMLCOMMENT (‘High priced volumes’);
produces the output
xmlcomment
----------------------------
<!--High priced volumes-->
Notice that the output string is now surrounded by the XML comment indicators.
The XMLPARSE function turns a string of text into XML. It is particularly useful when you need to store a string of text in a column of type XML. The function has the general format:
XMLPARSE (type_indicator content_string whitespace_option)
The type indicator takes one of two values: DOCUMENT (for a complete XML document) or CONTENT (for a small chunk of XML that doesn't represent an entire document). Most of the time, the DOCUMENT type is used in an embedded SQL program where an entire XML document can be stored in a host language string variable.
XMLPARSE
The content string cannot be generated with a SELECT within the XMLPARSE statement. The content string therefore must be either a literal or a host language variable. There is no reason, however, that the host language variable can't be loaded with a long string created by embedded SELECTs and/or other host language string manipulations.
The whitespace option tells SQL what to do with any empty space at the end of a string. Its value can be either STRIP WHITESPACE or PRESERVE WHITESPACE.
As a simple example, consider the following:
SELECT XMLPARSE (CONTENT ‘Converting a literal to XML’ STRIP WHITESPACE);
The output looks just like regular text because the interactive SQL command processor strips off the XML tags before displaying the result:
xmlparse
-----------------------------
Converting a literal to XML
XMLROOT
The XMLROOT function is a bit of a misnomer. Its definition says that it modifies an XML root node, but what it really does is create or modify an XML declaration at the very beginning of an XML document. The function has the following general syntax:
XMLROOT (XML_value, VERSION version, STANDALONE standalone_property)
The first parameter—xml_value—is the XML data for which you will be creating or modifying the prolog. You can then set its version (usually supplied as a literal string) and its standalone property.
The standalone property indicates whether all declarations needed for the XML document are contained within the document or whether declarations are contained in an external document. In most cases when you are using XML with a relational database, the standalone property will be set to yes.
The following example adds the prolog at the beginning of the XML, sets the version to 1.1 and the standalone property to yes—
SELECT XMLROOT (XMLPARSE (CONTENT
‘<content>something</content>’),
VERSION ‘1.1’, STANDALONE YES);
—and produces the output
xmlroot
---------------------------------------------------------------
<?xml version=“1.1”
standalone=“yes”?><content>abc</content>
XMLELEMENT is one of two ways to generate content for an XML document. It has the following general syntax:
XMLELEMENT (NAME name_of_element,
XMLATTRIBUTES (attribute_value
AS attribute_name, …), content…)
XMLELEMENT
Each element has a name that becomes the element's tag. Attributes are optional. The content may be
As an example, let's create some XML that contains data about books (author, title, and ISBN):
SELECT XMLELEMENT (NAME “Books”,
XMLELEMENT (NAME “Author”,
author.author_last_first),
XMLELEMENT (NAME “Title”,work.title),
XMLELEMENT (name “ISBN”,book.isbn))
FROM author JOIN book JOIN work;
The function call is placed in a SELECT statement as one of the values that SELECT should return. The FROM clause identifies the tables from which data will be drawn. This particular example creates an XML element named Books. The contents of the element include three other elements—Author, Title, ISBN—each of which is created with an embedded call to XMLELEMENT. The SQL statement produces one element for each row retrieved by the query. In this case, the SELECT has no WHERE clause and therefore generates an element for every row in the joined table created by the FROM clause.
The output of this command can be found in Figure 17-5. Note that the spacing of the output has been adjusted by putting multiple tags on the same line so the output will take up less space. This isn't a problem because XML is text only; any spacing between tags is purely cosmetic.
 |
| Figure 17-5 An XML fragment created with calls to XMLELEMENT |
XMLFOREST
The XMLFOREST function can be used to create elements that are part of a higher-level element. Its results are very similar to XMLELEMENT, although its syntax can be simpler than using multiple embedded XMLELEMENT calls. However, the result of XMLFOREST alone is not a valid XML document. We therefore often wrap a call to XMLELEMENT around XMLFOREST.
As an example, assume that we want to create an XML element for an inventory item, including the ISBN, asking price, and selling price. One way to code the element would be as follows:
SELECT XMLELEMENT (NAME “Inventory_item”,
XMLFOREST (volume.isbn, volume.asking_price, volume.selling_price)) “Volumes”
FROM volume
WHERE selling_price > 75;
Notice that the external function call is to XMLELEMENT to create the element named inventory_item. The content of the element is produced by a single call to XMLFOREST, which contains the three data values that are part of the inventory item element. Because there is no AS clause, the function uses the column names as the names of the data elements. You can find the output of the sample query in Figure 17-6.
 |
| Figure 17-6 The results of using XMLFOREST to generate the contents of an XML attribute |
XMLATTRIBUTES
As you will remember from earlier in this chapter, an XML element can have attributes, data values that are part of the element tag. The XMLATTRIBUTES function is used to specify those attributes. Like XMLFOREST, it is most commonly used as part of an XMLELEMENT function call.
The function has the following general syntax:
XMLATTRIBUTES (value AS attribute_name)
If the attribute's value is a column in a database table, then the AS and the attribute name are optional. SQL will then use the column name as the attribute name.
As an example, let's create an XML element for books with selling prices of more than $75, the results of which appear in Figure 17-7. Notice that text values (e.g., the ISBN) are in quotes.
SELECT XMLELEMENT (NAME “High_Priced”,
XMLATTRIBUTES (volume.isbn AS ISBN),
XMLELEMENT (NAME “Asking_price”, volume. asking_price),
XMLELEMENT (NAME “Selling_price”, volume. selling_price))
FROM volume
WHERE selling_price > 75;
 |
| Figure 17-7 The results of using XMLATTRIBUTES to add attributes to an XML element |
XMLCONCAT
The XML functions we have been discussing generate fragments of XML documents. To paste them together, you use the XMLCONCAT function. It has a relatively simple general syntax:
XMLCONCAT (XML_value, XML_value, …)
As an example, let's put a comment in front each of the elements that contain data about books with high selling prices:
The results can be found in Figure 17-8. Line breaks have been added to make the result readable. Note, however, that SQL views each occurrence of the comment and the entire element as a single string of text and therefore inserts a line break only at the end of each element.
Note: The x0020 that appears frequently in the output is the ASCII code for a blank.
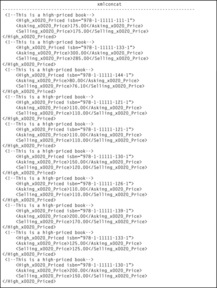 |
| Figure 17-8 The result of using XMLCONCAT to concatenate XML fragments |
The XML Data Type
You can declare a column in a table to be of type XML, just as you would with any other data type:
CREATE TABLE xmlstuff
(seq_numb INT,
xml_text XML,
PRIMARY KEY (seq_numb));
The XML column can then be used to store fragments of XML or entire XML documents. However, doing so has several drawbacks:
◊ The contents of the column are not searchable. 1
◊ The contents of the column cannot be used in predicates that require comparison operators such as > or =.
◊ The column cannot be indexed.
For that reason, tables that have XML columns need at least a unique sequence number to identify each row. You may also want to include a table that assigns keywords to each document so there is some type of search capability. Such a table might be created with
CREATE TABLE keywords
(seq_numb int,
keyword char (30),
PRIMARY KEY (seq_numb, keyword),
FOREIGN KEY keywords2xmlstuff (seq_numb)
REFERENCES xmlstuff);
As mentioned earlier in the discussion of XMLPARSE, you need to use that function to convert text into XML to store in an XML column. Because you can't generate an input string with a SELECT, the interactive INSERT is limited to XML fragments:
INSERT INTO xmlstuff
VALUES (1, XMLPARSE
(CONTENT ‘This is a test’ STRIP WHITESPACE);
For complete document input, you will generally be working with an embedded SQL application.
If you want to look at the contents of an XML column, you can use an interactive SELECT. SQL strips the XML tags for output. The query
produces
| sequ_numb | xml_text |
|---|---|
| 1 | this is a test |
Note: You could store XML in a text column, tags and all. However, when you use an XML column, SQL will check the XML to see that it is well-formed.
XMLSERIALIZE
The XMLSERIALIZE function is essentially the opposite of XMLPARSE: It takes the contents of an XML column and converts it to a text string:
XMLSERIALIZE (type_indicator column_name AS character_type)
For example,
SELECT XMLSERIALIZE
(DOCUMENT xmltext AS VARCHAR (256))
FROM sql_stuff
WHERE seq_numb = 16;
would extract the document from the row with the sequence number of 16, convert it to plain text (removing the tags) and display it on the screen. Because SQL removes the tags from interactive SELECT output, this function is particularly useful in an embedded SQL program.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.