
![]()
Slowly Changing Dimensions
Processing slowly changing dimensions (SCDs) is a common ETL operation when you are dealing with data warehouses. The SSIS data flow has a SCD transform, which provides a wizard that outputs a set of transforms you need to handle the multiple steps of processing SCDs. Although the built-in SCD transform can be useful, it is not ideal for all data loading scenarios. This chapter describes how to make the most of the SCD transform and provides a couple of alternative patterns you can use.
![]() Note There are many different types of SCD, but this chapter will focus on the two most common types: Type 1 and Type 2. For more information about the different types of SCDs, see the Wikipedia entry at http://en.wikipedia.org/wiki/Slowly_changing_dimensions.
Note There are many different types of SCD, but this chapter will focus on the two most common types: Type 1 and Type 2. For more information about the different types of SCDs, see the Wikipedia entry at http://en.wikipedia.org/wiki/Slowly_changing_dimensions.
The Slowly Changing Dimension Transform
To best understand the SCD transform, let’s consider two key scenarios it was designed for:
- A small number of change rows: You are performing change data capture (CDC) at the source, or as close to the source as possible. Unless you are dealing with a very active dimension, most SCD processing batches will contain a small number of rows.
- Large dimension: You are working against large dimensions but are only processing a small number of change rows. You will want to avoid operations that cause full table scans of your dimension.
Because of these target scenarios, the SCD transform does not cache the existing dimension data (like a Lookup transform does) and performs all of its comparisons row by row against the destination table. Although this allows the transform to avoid full scans of the destination dimension and reduces memory usage, it does affect performance when you are processing a large number of rows. If your scenario does not match one of thsee, you might want to consider using one of the other patterns in this chapter. If it does match, or if you prefer using out-of-the-box components over third-party solutions (or you would just like to avoid hand-crafted SQL statements required for the Merge pattern), consider applying the optimizations listed at the end of this pattern.
Running the Wizard
Unlike other SSIS data flow components, when you drop the SCD transform onto the design surface in Business Intelligence Development Studio (BIDS), a wizard pops up and walks you through the steps of setting up your SCD processing.
The first page of the wizard (Figure 13-1) allows you to select the dimension you’ll be updating and the column or columns that make up the business key (also known as the natural key).
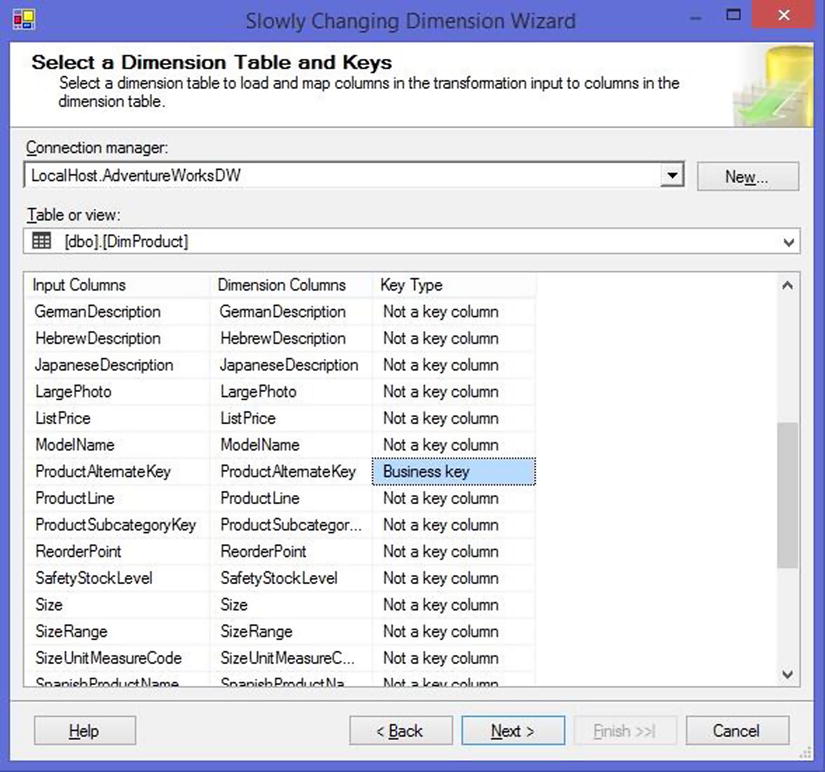
Figure 13-1. Selecting the dimension table and keys in the Slowly Changing Dimension Wizard
On the next page (Figure 13-2), you specify the columns that you’ll be processing and determine how you’d like the wizard to treat them. You have the three choices (as shown in Table 13-1).
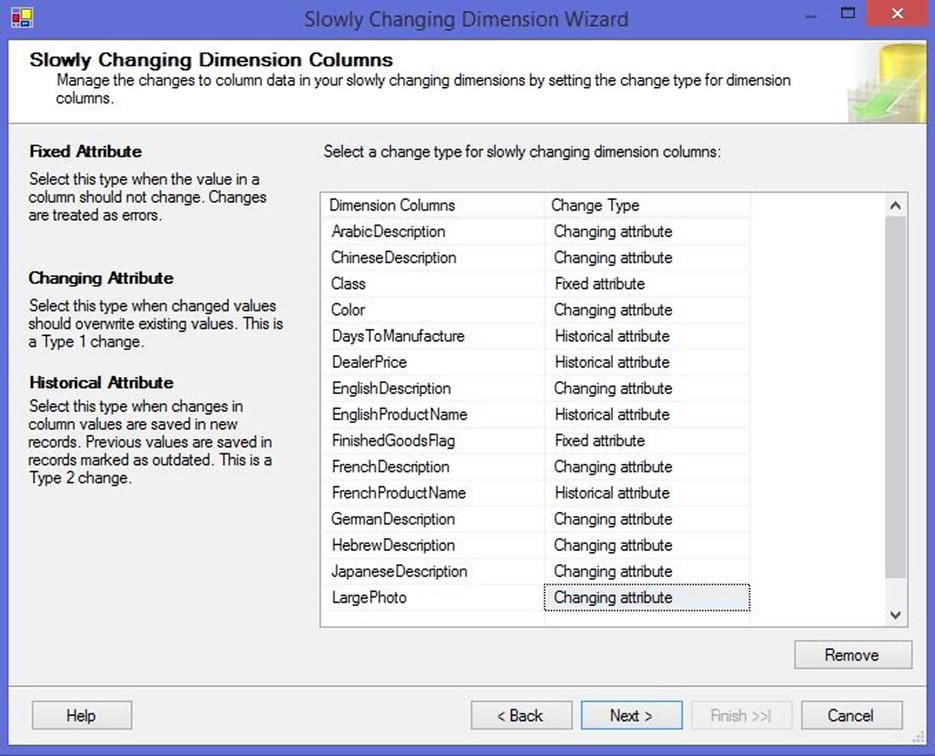
Figure 13-2. Selecting the dimension table and keys in the Slowly Changing Dimension Wizard
Table 13-1. Column Change Types
|
Change Type |
Dimension Type |
When to Use |
|---|---|---|
|
Fixed attribute |
— |
Fixed attributes are columns that should not change or that require special handling when you make changes. By default, a change on one of these columns is treated as an error. |
|
Changing attribute |
Type 1 |
When a change is made to a changing attribute column, existing records are updated to reflect the new value. These are typically columns that aren’t used as part of business logic or time-sensitive reporting queries, such as a product description. |
|
Historical attribute |
Type 2 |
Historical attributes are columns for which you need to maintain history. These are frequently numeric columns that are used in time-sensitive reporting queries, such as a Sales Price, or Weight. |
On this page, you should not map columns that will not be updated as part of your SCD processing, such as foreign keys to other dimension tables or columns related to the tracking of historical changes—for example, Start and End Date columns, an expiry flag, or the surrogate key. The SCD transform does not support Large Object (LOB) columns (columns that would be treated as DT_IMAGE, DT_TEXT, and DT_NTEXT types in the SSIS data flow), so these columns should be handled separately and also should not be mapped here.
The next pages of the wizard allow you to configure options for how you’d like to handle fixed attributes (Figure 13-3), as well as Type 1 and Type 2 changes (Figure 13-4). When dealing with historical attributes, the wizard knows how to generate the logic needed to update the dimension in two different ways: by using a single column or by using Start and End Date columns to indicate whether the record is current or expired. If your table is using a combination of these, or some other method of tracking the current record, you will need to update the generated transforms to contain this logic.
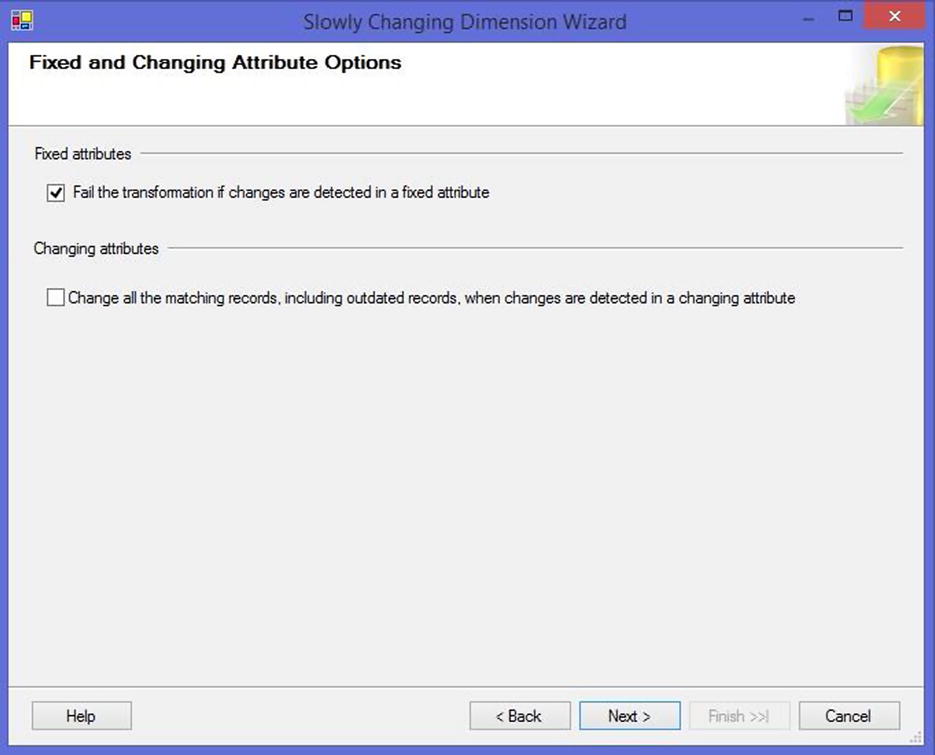
Figure 13-3. Fixed and changing attribute options
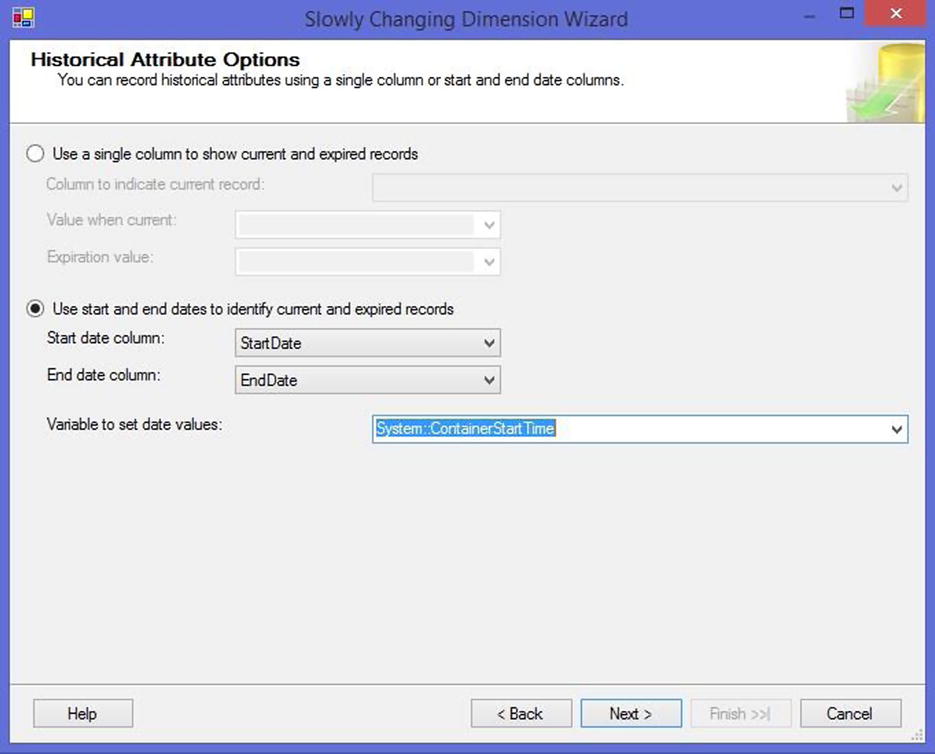
Figure 13-4. Historical attribute options
The final page of the wizard (Figure 13-5) lets you enable support for inferred members. An inferred member is created with minimal information—typically just the business and surrogate keys. It’s expected that the remaining fields will be populated in subsequent loading of the dimension data. Although the wizard enables inferred member support by default, for most forms of SCD processing, you will not need it.
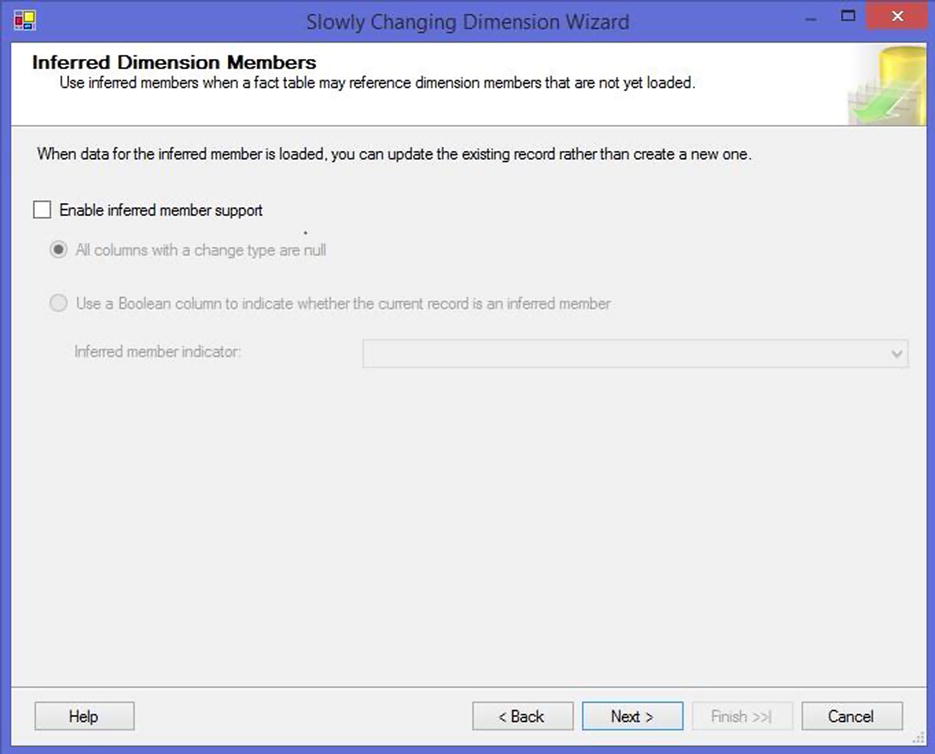
Figure 13-5. Inferred dimension members
Using the Transformations
When the wizard completes, it will output a number of different data flow components in addition to the main Slowly Changing Dimension component (Figure 13-6). The main component checks incoming data against the destination table and sends incoming rows down one of its outputs if the record is new or modified. Records without any changes are ignored. The components connected to these outputs will be configured according to the options you selected in the wizard dialogs.
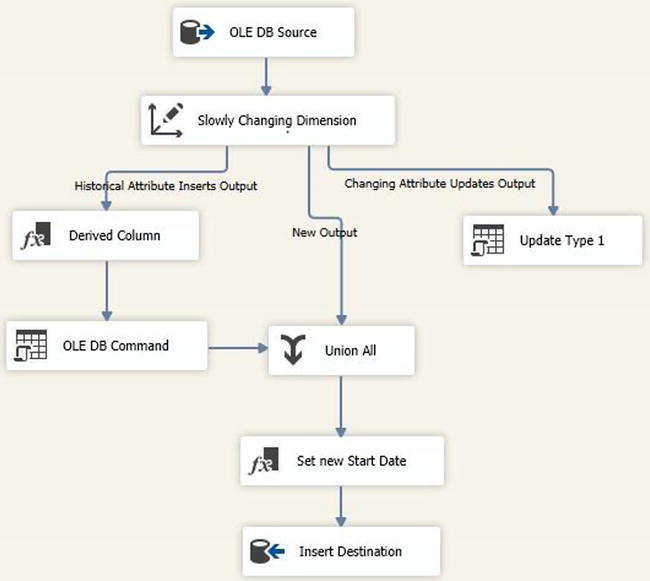
Figure 13-6. Wizard output for Type 1 and Type 2 changes, and no inferred member support
You can further customize the SCD processing logic by modifying these components. Double-clicking the main Slowly Changing Dimension transform relaunches the wizard. The wizard remembers your settings from the previous run; however, it will overwrite any changes or customizations you’ve made to the existing transforms. This includes any layout and resizing changes you might have performed.
![]() Note When you re-run the Slowly Changing Dimension Wizard, the default options selected in the UI are not inferred from the components. Instead, they are persisted as part of the package in <designTime> elements. If you have a deployment process that removes package layout information, note that you will also lose your choices in the wizard.
Note When you re-run the Slowly Changing Dimension Wizard, the default options selected in the UI are not inferred from the components. Instead, they are persisted as part of the package in <designTime> elements. If you have a deployment process that removes package layout information, note that you will also lose your choices in the wizard.
Optimizing Performance
The components output from the Slowly Changing Dimension Wizard are not configured for optimal performance. By changing some settings and moving to a set-based pattern, you can drastically improve the performance of your SCD processing.
The Slowly Changing Dimension Transform
The main transform does not cache any row results from the reference dimension, so every incoming row results in a query against the database. By default, the wizard will open a new connection to the database on each query. For a gain in performance (as well as lower resource usage), you can set the RetainSameConnection property of the connection manager used by the wizard to True so that the same connection is reused on each query.
The wizard will output two (or three, if you’re processing inferred members) OLE DB Command transforms. These transforms perform row-by-row updates, which greatly degrade performance. You will get a big performance boost by placing these rows in staging tables and performing the updates in a single batch once the data flow completes.
Since the main Slowly Changing Dimension transform and the destination use the same connection manager, the destination component will have the Fast Load option disabled by default to avoid deadlocking your data flow. If you are processing a small number of rows (for example, a single data flow buffer’s worth of data), you can enable Fast Load on the destination component for an immediate performance gain. To avoid deadlocking issues when processing a larger number of rows, consider using a staging table. Bulk load the data into a temporary staging table and update the final destination once the data flow is complete using an INSERT INTO ... SELECT statement.
Third-Party SCD Components
A couple of popular third-party alternatives to the SCD transform are available. Both have similar architectures and usage patterns but offer different capabilities.
- The Table Difference component is available through CozyRoc.com: This transform takes in the source and destination tables as inputs and does row-by-row comparisons in memory. It has three outputs—New, Updated, and Deleted. It can also be used to do general-purpose table comparisons in addition to SCD processing.
![]() Note For more information about the Table Difference component, please see the CozyRoc web page at www.cozyroc.com/ssis/table-difference.
Note For more information about the Table Difference component, please see the CozyRoc web page at www.cozyroc.com/ssis/table-difference.
- The Dimension Merge SCD component is available through PragmaticWorks.com: This component was designed to handle dimension loading as per the Kimball method. Like the Table Difference component, it takes in the source and destination dimension tables and does the comparisons in memory. Also like the Table Difference component, it does not modify the destination table directly. It will apply row updates in memory and provides a number of outputs to feed your destination tables.
![]() Note For more information about the Dimension Merge SCD component, please see the Pragmatic Works web page at http://pragmaticworks.com/Products/Business-Intelligence/TaskFactory/Features.aspx#TSDimensionMergeSCD.
Note For more information about the Dimension Merge SCD component, please see the Pragmatic Works web page at http://pragmaticworks.com/Products/Business-Intelligence/TaskFactory/Features.aspx#TSDimensionMergeSCD.
The main draw of these components is their performance. Since the transforms take both source and destination tables into memory, they are able to do fast in-memory comparisons, without multiple queries to the destination server. They also provide additional functionality over the SCD transform, such as detecting deleted rows, and can be easier to maintain because all of the logic is contained within a single component.
However, bringing in both the source and destination dimension tables means that you’re doing a full table scan of the destination (and typically the source, as well). Since the data fow does not end until all sources are done reading their rows, the entire destination dimension will be read, even if you are only processing a small number of changed source rows. Although the third-party components will perform well in many cases, you should consider if they will be ideal for your scenario.
SQL Server 2008 introduced support for the T-SQL MERGE statement. This statement will perform insert, update, and delete operations on a destination table based on the results of a join with a source table. It is very efficient and provides a good alternative for SCD processing.
![]() Note For more information about MERGE, please see the Books Online entry “Using MERGE in Integration Services Packages” at http://technet.microsoft.com/en-us/library/cc280522.aspx.
Note For more information about MERGE, please see the Books Online entry “Using MERGE in Integration Services Packages” at http://technet.microsoft.com/en-us/library/cc280522.aspx.
There are three steps to using MERGE from within SSIS:
- Stage the data in a data flow.
- Optimize the staging table (optional).
- Run the MERGE statement(s) using an Execute SQL task.
MERGE allows a single statement to be run when it detects a row has been updated (“matched” using the MERGE terminology) and when a row is new (“not matched”). Since Type 1 and Type 2 changes require different types of processing, we’ll use two MERGE statements to complete the SCD processing (as shown in Figure 13-7).
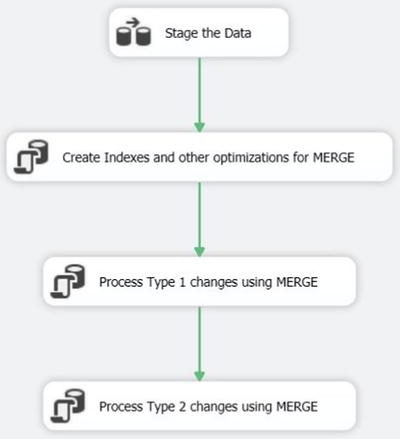
Figure 13-7. Control flow for the Merge pattern
Listing 13-1 shows the first MERGE statement we’ll run to update all of our Type 1 columns in the destination table. The ON ( ) section specifies the keys that we’ll be matching on (in this case, the business key for the table). In the WHEN MATCHED section, we include DEST.EndDate is NULL to ensure that we are only updating the current record (this is optional—in many cases, you do want to update all records and not just the current one). The THEN UPDATE section contains the list of our Type 1 columns that we want to update.
Listing 13-1. MERGE Statement for Type 1 Columns
MERGE INTO [DimProduct] AS DEST
USING [Staging] AS SRC
ON (
DEST.ProductAlternateKey = SRC.ProductAlternateKey
)
WHEN MATCHED AND DEST.EndDate is NULL -- update the current record
THEN UPDATE SET
DEST.[ArabicDescription] = SRC.ArabicDescription
,DEST.[ChineseDescription] = SRC.ChineseDescription
,DEST.[EnglishDescription] = SRC.EnglishDescription
,DEST.[FrenchDescription] = SRC.FrenchDescription
,DEST.[GermanDescription] = SRC.GermanDescription
,DEST.[HebrewDescription] = SRC.HebrewDescription
,DEST.[JapaneseDescription] = SRC.JapaneseDescription
,DEST.[ThaiDescription] = SRC.ThaiDescription
,DEST.[TurkishDescription] = SRC.TurkishDescription
,DEST.[ReorderPoint] = SRC.ReorderPoint
,DEST.[SafetyStockLevel] = SRC.SafetyStockLevel
;
Handling Type 2 Changes
Since the MERGE statement allows a single statement for each action, updating Type 2 columns is a little more challenging. Remember, for Type 2 changes, you need to perform two operations: 1) mark the current record as expired, and 2) insert the new record as current. To accomplish this, you’ll use the MERGE statement inside of a FROM clause and use its OUTPUT to feed an INSERT INTO statement (as shown in Listing 13-2).
Listing 13-2. MERGE Statement for Type 2 Columns
INSERT INTO [DimProduct] ([ProductAlternateKey],[ListPrice],[EnglishDescription],[StartDate])
SELECT [ProductAlternateKey],[ListPrice],[EnglishDescription],[StartDate]
FROM (
MERGE INTO [DimProduct] AS FACT
USING [Staging] AS SRC
ON ( FACT.ProductAlternateKey = SRC.ProductAlternateKey )
WHEN NOT MATCHED THEN
INSERT VALUES (
SRC.ProductAlternateKey
,SRC.ListPrice
,SRC.EnglishDescription
,GETDATE() -- StartDate
,NULL -- EndDate
)
WHEN MATCHED AND FACT.EndDate is NULL
THEN UPDATE SET FACT.EndDate = GETDATE()
OUTPUT $Action Action_Out
,SRC.ProductAlternateKey
,SRC.ListPrice
,SRC.EnglishDescription
,GETDATE() StartDate
) AS MERGE_OUT
WHERE MERGE_OUT.Action_Out = 'UPDATE'
Conclusion
There are many ways to process SCDs in SSIS. Although the built-in SCD transform can get you up and running quickly, it may not perform as well as the alternatives. You may prefer using the Merge pattern due to its overall performance, but having to maintain the SQL statements may be an inhibitor in the long run. If you prefer a visual designer experience, consider trying one of the third-party component options.
Table 13-2 summarizes the advantages and disadvantages described in this chapter.
Table 13-2. Slowly Changing Dimension Processing Patterns
|
Pattern |
Use For |
|---|---|
|
Slowly Changing Dimension transform |
Quick prototyping Processing a small number of rows Very large dimensions |
|
Third-party components |
Full or historical dimension loads Small-medium sized dimensions Non–SQL Server destinations |
|
Merge pattern |
Best overall performance Cases in which you don’t mind hand-crafting SQL statements |