
By definition, a memory leak is a situation where we allocate some
memory from the heap—in C++ by using the new operator, and in C by
using malloc() or calloc()—then assign the address of this memory to
a pointer, and somehow lose this value either by letting the pointer go out
of scope:
{
MyClass* my_class_object = new MyClass;
DoSomething(my_class_object);
} // memory leak!!!or by assigning some other value to it:
MyClass* my_class_object = new MyClass; DoSomething(my_class_object); my_class_object = NULL; // memory leak!!!
There are also situations when programmers keep allocating new memory and do not lose any pointers to it, but keep pointers to objects that the program is not going to use anymore. The latter is not formally a memory leak, but leads to the same situation: a program running out of memory. We’ll leave the latter error to the attention of the programmer, and concentrate on the first one—the “formal” memory leak.
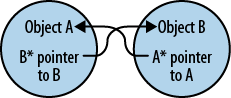
Consider two objects containing pointers to each other (Figure 8-1). This situation is known as a “circular reference.” Pointers exist to A and to B, but if there are no other pointers to at least one of these objects from somewhere else, there is no way to reclaim the memory for either variable and therefore you create a memory leak. These two objects will live happily ever after and will never be destroyed. Now consider the opposite example. Suppose we have a class with a method that can be run in a separate thread:
class SelfResponsible : public Thread {
public:
virtual void Run() {
DoSomethingImportantAndCommitSuicide();
}
void DoSomethingImportantAndCommitSuicide() {
sleep(1000);
delete this;
}
};We start its Run() method in a separate
thread like this:
Thread* my_object = new SelfResponsible; my_object->Start(); // call method Run() in a separate thread my_object = NULL;
After that we assign NULL to the pointer and lose the address of this
object, thus creating a memory leak according to the definition at the
beginning of this chapter. However, if we look inside the DoSomethingImportantAndCommitSuicide() method,
we’ll see that after doing something the object will delete itself, thus
releasing this memory back to the heap to be reused. So this is not actually
a memory leak.
Considering all these examples, a better definition of a
memory leak is as follows. If we allocate memory (using the new operator), someone or
something (some object) must be responsible for:
This responsibility for deleting the memory is usually called ownership of the object. In the previous example, the object took ownership of itself. So to summarize, a memory leak is a situation where the ownership of allocated memory is lost.
Consider the following code:
void SomeFunction() {
MyClass* my_class_object = NULL;
// some code …
if(SomeCondition1()) {
my_class_object = new MyClass;
}
// more code
if(SomeCondition2()) {
DoSomething(my_class_object);
delete my_class_object;
return;
}
// even more code
if(SomeCondition3()) {
DoSomethingElse(my_class_object);
delete my_class_object;
return;
}
delete my_class_object;
return;
}The reason we’ve started with the NULL pointer is to avoid the question of why we don’t just create the object on the stack and avoid the whole problem of deallocating it altogether. There can be multiple reasons for not creating an object on the stack. Sometimes the creation of an object must be delayed to a point in the program later than when the variable holding the memory is created; or it might be created by some other factory class and what we get is a pointer returned to us together with responsibility to delete it when we are done using it; or maybe we don’t know whether we will create the object at all, as in the previous example.
Now that we have an object created on the heap, we are responsible for
deleting it. What is wrong with the preceding code? Obviously, it is
fragile: i.e., every time we modify it by adding an
additional return statement, we must
delete the object just before returning. In this example, the responsibility
to delete the object lies with the programmer. This is error-prone, and
therefore against the principle declared in the Preface.
But even if we remember to delete the object before each return statement, this does not solve our problems. If any of the functions called from this code could throw an exception, then it actually means that we might “return” from any line of code containing a function call. Thus, we must surround the code with try-catch statements and, if we catch an exception, remember to delete the object and then throw a further exception. This seems like lots of work just to avoid a memory leak. The code becomes more crowded with statements dealing with cleanup and therefore becomes less readable, and the programmer has less time to concentrate on actual work.
The solution to this problem, widely known in C++ literature, is to use smart pointers. These are template classes that behave like normal pointers (or sometimes not exactly like normal pointers) but that take ownership of the objects assigned to them, leaving the programmer with no further worries. In this case, the function shown earlier would look like this:
void SomeFunction() {
SmartPointer<MyClass> my_class_object;
// some code …
if(SomeCondition1()) {
my_class_object = new MyClass;
}
// more code
if(SomeCondition2()) {
DoSomething(my_class_object);
return;
}
// even more code
if(SomeCondition3()) {
DoSomethingElse(my_class_object);
return;
}
return;
}Note that we do not delete the allocated object anywhere. It is now
the responsibility of the smart pointer, my_class_object.
This is actually a special case of a more general C++ pattern where some resource is acquired by an object (usually in a constructor, but not necessarily) and then this object is responsible for releasing the resource and will do so in a destructor. One example of using this pattern is obtaining a lock on a Mutex object when entering a function:
void MyClass::MyMethod() {
MutexLock lock(&my_mutex_);
// some code
} // destructor ~MutexLock() is called here releasing my_mutex_In this case, the MyClass class has
a data member named my_mutex_ that must
be obtained at the beginning of a method and released before leaving the
method. It is obtained by MutexLock in
the constructor and automatically released in its destructor, so we can be
sure that no matter what happens inside the code of the MyClass::MyMethod() function—in particular, how
many return statements we might
insert or whatever might throw an exception—the method won’t forget to
release my_mutex_ before
returning.
Now let’s return to the problem of memory leaks. The solution is that whenever we allocate new memory, we must immediately assign the pointer to that memory to some smart pointer. We now do not have to worry about deleting the memory; that responsibility is given to the smart pointer.
At this point you might ask the following questions regarding the smart pointer class:
Are you allowed to copy a smart pointer?
If yes, which one of the multiple copies of the smart pointer is responsible for deleting the object they all point to?
Does the smart pointer represent a pointer to an object or an array of objects (i.e., does it use the
deleteoperator with or without brackets)?Does a smart pointer correspond to a
constpointer or a non-constpointer?
Depending on the answers to these questions, you could come
up with a rather large number of different smart pointers. And indeed, there
are a great many of them discussed and used in the C++ community and
provided by different libraries, most notably, the boost library. However, in my opinion the
multitude of different smart pointer types creates new opportunities for
errors, for example, assigning a pointer pointing to an object to a smart
pointer that expects an array (i.e., would use a delete with brackets) or
vice versa.
One of the smart pointers—auto_ptr<T>—has the strange property that
when you have an auto pointer p1 and then
make a copy of it p2 as follows:
auto_ptr<int> p1(new int); auto_ptr<int> p2(p1);
the pointer p1 becomes NULL, which
I find counterintuitive and therefore error-prone.
In my experience, there are two smart pointer classes that have so far covered all my needs in preventing memory leaks:
The reference counting pointer (a.k.a. the shared pointer)
The scoped pointer
The difference between the two is that the reference counting pointer can be copied and the scoped pointer cannot. However, the scoped pointer is more efficient.
We’ll look at each of these in the following sections.
As mentioned above, the reference counting pointer can be copied. As a result, several copies of a smart pointer could point to the same object. This leads to the question of which copy is responsible for deleting the object that they all point to. The answer is that the last smart pointer of the group to die will delete the object it points to. It’s analogous to the household rule: “the last person to leave the room will switch the lights off.”
To implement this algorithm, the pointers share a counter that keeps track of how many smart pointers refer to the same object—hence the term “reference counting.” Reference counts are used in a wide range of situations: the term simply means that the implementation has a hidden integer variable that serves as a counter. Each time someone creates a new copy of a smart pointer that points to the target object, the implementation increments the counter; when any smart pointer is deleted, the implementation decrements the counter. So the target object will be around as long as it’s needed, but no longer that that.
An implementation of reference counting pointers is provided by my library in the file scpp_refcountptr.hpp. Here’s the public portion of this class:
template < typename T>
class RefCountPtr {
public:
explicit RefCountPtr(T* p = NULL) {
Create(p);
}
RefCountPtr(const RefCountPtr<T>& rhs) {
Copy(rhs);
}
RefCountPtr<T>& operator=(const RefCountPtr<T>& rhs) {
if(ptr_ != rhs.ptr_)
{
Kill();
Copy(rhs);
}
return *this;
}
RefCountPtr<T>& operator=(T* p) {
if(ptr_ != p) {
Kill();
Create(p);
}
return *this;
}
~RefCountPtr() {
Kill();
}
T* Get()const { return ptr_; }
T* operator->() const {
SCPP_TEST_ASSERT(ptr_ != NULL,
"Attempt to use operator -> on NULL pointer.");
return ptr_;
}
T& operator* ()const {
SCPP_TEST_ASSERT(ptr_ != NULL,
"Attempt to use operator * on NULL pointer.");
return *ptr_;
}Note that both the copy-constructor and assignment operators are
provided, so one could copy these pointers. In this case, both the
original pointer and the copied one point to the same object (or to NULL,
if the original pointer was NULL). In this sense they behave the same way
as the regular “raw” T* pointers. If you no
longer need to use the object, you can “kill” the reference counting
pointer by assigning NULL to it.
There are a couple of problems with the reference counting pointer.
First, creating one with a non-NULL argument is expensive, because the
implementation uses the new operator to allocate
an integer on heap, a relatively slow operation. Second, of course, the
reference counting pointer is not multithread-safe. I’ve declared that
discussions of multithreading are beyond the scope of this book, but here
it’s important enough to mention. Let’s concentrate on the previous
problem—the cost of using a reference counting pointer. You can use it
when you are sure that you will need to copy it, and when you can be
reasonably sure that the cost of creating one is negligible compared to
the execution time of the rest of your code.
In cases when you don’t plan on copying the smart pointer
and just want to make sure that the allocated resource will be deallocated
properly, as in the earlier examples of the SomeFunction() method, there is a much simpler
solution: the scoped pointer. Let’s take a look at its code provided in
the file scpp_scopedptr.hpp:
template <typename T>
class ScopedPtr {
public:
explicit ScopedPtr(T* p = NULL)
: ptr_(p)
{}
ScopedPtr<T>& operator=(T* p) {
if(ptr_ != p) {
delete ptr_;
ptr_ = p;
}
return *this;
}
~ScopedPtr() {
delete ptr_;
}
T* Get() const {
return ptr_;
}
T* operator->() const {
SCPP_TEST_ASSERT(ptr_ != NULL,
"Attempt to use operator -> on NULL pointer.");
return ptr_;
}
T& operator* () const {
SCPP_TEST_ASSERT(ptr_ != NULL,
"Attempt to use operator * on NULL pointer.");
return *ptr_;
}
// Release ownership of the object to the caller.
T* Release() {
T* p = ptr_;
ptr_ = NULL;
return p;
}
private:
T* ptr_;
// Copy is prohibited:
ScopedPtr(const ScopedPtr<T>& rhs);
ScopedPtr<T>& operator=(const ScopedPtr<T>& rhs);
};Again, the most important property of this class for us is that its
destructor deletes the object it points to (if it is not NULL, of course).
The difference between usage of the scoped pointer and the reference
counter pointer is that the scoped pointer cannot be copied. Both the
copy-constructor and assignment operator are declared private, so any
attempt to copy this pointer will not compile. This removes the need to
count how many copies of the same smart pointer point to the same
object—there is always only one, and therefore this pointer does not
allocate an int from the heap to
count its copies. For this reason, it is as fast as a pointer can
be.
You have also probably noticed that in both RefCountPtr and ScopedPtr we diagnose an attempt to dereference
the NULL pointer. We’ll talk more about this in the next chapter.
As you’ll recall from Chapter 4
concerning arrays, we have discussed which of the two new operators to use: the
one without brackets. As for the corresponding delete operators, we should use
neither. Do not delete the objects yourself; leave it
to smart pointers.
Now let’s discuss potential errors when using functions that
return pointers. Suppose, we have a function that returns a pointer to
some type MyClass:
MyClass* MyFactoryClass::Create(const Inputs& inputs);
The very first question about this function is whether the caller of
this function is responsible for
deleting this object, or is this a pointer to an instance of MyClass that the instance of MyFactoryClass owns? This should of course be
documented in a comment in the header file where this function is
declared, but the reality of the software world is that it rarely is. But
even if the author of the function did provide a comment that the function
creates a new object on the heap and the caller is responsible for
deleting it, we now find ourselves saying that every time we receive a
pointer to an object from a function call, we need to remember to check
the comments (or in the absence of a comment—the code itself if available)
to find out whether we are responsible for deleting this object. And as we
have decided in the Preface, we would prefer to rely on a compiler rather
than on a programmer. Therefore, a fool-proof way to enforce the ownership
of the object is for the function to return a smart pointer. For
example:
RefCountPtr<MyClass> MyFactoryClass::Create(const Inputs& inputs);
Not only does this design leave no doubt about the ownership of the
object returned by the function, it leaves no opportunity for a memory
leak. On the other hand, if you find the reference counting pointer too
slow for your purposes, you might want to return a scoped pointer. But
there is one problem: the ScopedPtr<MyClass> cannot be copied, and
therefore it cannot be returned in a traditional way:
ScopedPtr<MyClass> MyFactoryClass::Create(const Inputs& inputs) {
ScopedPTr<MyClass> result(new MyClass(inputs));
return result; // Won’t compile !
}Therefore, the way around the problem is to do this:
ScopedPtr<MyClass> result; // Create an empty scoped pointer // Fill it: void MyFactoryClass::Create(const Inputs& inputs, ScopedPtr<MyClass>& result);
Here you create a scoped pointer containing NULL and give it to
MyFactoryClass::Create() to fill it up.
This approach again leaves no room for mistakes regarding the ownership of
the object created by the function. If you are not sure which of the two
pointers to return, you can either:
There is also an opposite situation when the SomeClass::Find() method
returns a pointer to an object but the user does not have ownership of
it:
// Returns a pointer to a result, caller DOES NOT OWN the result. MyClass* SomeClass::Find(const Inputs& inputs);
In this case, the pointer returned by this function points to an
object that belongs to something inside the SomeClass object.
The first problem here is that the SomeClass object thinks that it is responsible
for deleting the MyClass instance to
which it just returned a pointer, and therefore it will delete it at some
point in the future. In this case, if the user of this function will
delete the pointer he received, this instance will be deleted more than
once, which is not a good idea. Second, this instance might be part of an
array of MyClass objects that is
created inside, say, a template vector using operator new[] (with brackets),
and we are now trying to delete an object from that array using operator
delete without brackets.
This is also not good. Finally, the instance of MyClass could be created on stack, and should
not ever be deleted using operator delete at all.
In this case, any attempt to delete this object that we do not own—directly or by assigning it to a smart pointer of any kind that would take ownership of it—would lead to disaster. An appropriate way of returning this pointer is to return a “semi-smart” pointer that does not own the object it points to. This will be discussed in the next chapter.
Rules for this chapter to avoid memory leaks:
Every time you create an object using the
newoperator, immediately assign the result to a smart pointer (reference counting point or scoped pointer is recommended).Use the
newoperator only without brackets. If you need to create an array, create a new template vector, which is a single object.Avoid circular references.
When writing a function returning a pointer, return a smart pointer instead of a raw one, to enforce the ownership of the result.