
Day 17. Working with Streams
Until now, you’ve been using cout to write to the screen and cin to read from the keyboard, without a full understanding of how they work. Today, you will learn all about both of these.
Today, you will also learn
• What streams are and how they are used
• How to manage input and output using streams
• How to write to and read from files using streams
Overview of Streams
C++ does not define how data is written to the screen or to a file, nor how data is read into a program. These are clearly essential parts of working with C++, however, and the standard C++ library includes the iostream library, which facilitates input and output (I/O).
The advantage of having the input and output kept apart from the language and handled in libraries is that it is easier to make the language “platform-independent.” That is, you can write C++ programs on a PC and then recompile them and run them on a Sun Workstation, or you can take code created using a Windows C++ compiler and recompile and run it on Linux. The compiler manufacturer supplies the right library, and everything works. At least that’s the theory.
Note
A library is a collection of object (.obj or .o) files that can be linked to your program to provide additional functionality. This is the most basic form of code reuse and has been around since ancient programmers chiseled 1s and 0s into the walls of caves.
Today, streams are generally less important for C++ programming—except, perhaps, for flat file input. C++ programs have evolved to use operating system or compiler vendor-provided graphical user interface (GUI) libraries for working with the screen, files, and the user. This includes Windows libraries, X Windows libraries, and Borland’s Kylix abstraction of both the Windows and X Windows user interfaces. Because these libraries are specialized to the operating system and are not part of the C++ standard, they are not discussed in this book.
Because streams are a part of the C++ standard, they are discussed today. In addition, it is good to understand streams in order to understand the inner workings of input and output. You should, however, quickly move to learning your operating system or vendor-supplied GUI library as well.
Encapsulation of Data Flow
Text input and output can be accomplished using the iostream classes. The iostream classes view the flow of data as being a stream of data, one byte following another. If the destination of the stream is a file or the console screen, the source of the data that will be flowing is usually some part of your program. If the stream is reversed, the data can come from the keyboard or a disk file and can be “poured” into your data variables.
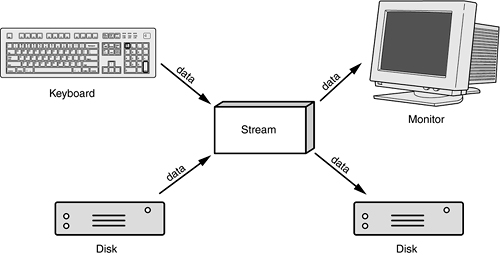
One principal goal of streams is to encapsulate the problems of getting the data to and from the disk or the console screen. After a stream is created, your program works with the stream and the stream takes care of the details. Figure 17.1 illustrates this fundamental idea.
Figure 17.1. Encapsulation through streams.
Understanding Buffering
Writing to the disk (and to a lesser extent the console screen) is very “expensive.” It takes a long time (relatively speaking) to write data to the disk or to read data from the disk, and execution of the program can be blocked by disk writes and reads. To solve this problem, streams provide “buffering.” When buffering is used, data is written into the stream, but is not written back out to the disk immediately. Instead, the stream’s buffer fills and fills, and when it is full, it writes to the disk all at once.
Note
Although data is technically a plural noun, we treat it as singular, as do nearly all native speakers of English.
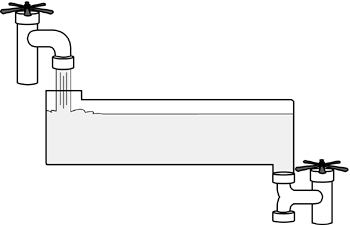
Picture water trickling into the top of a tank and the tank filling and filling, but no water running out of the bottom. Figure 17.2 illustrates this idea.
Figure 17.2. Filling the buffer.
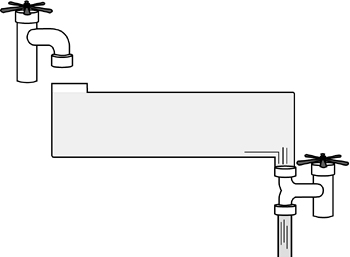
When the water (data) reaches the top, the valve opens and all the water flows out in a rush. Figure 17.3 illustrates this.
Figure 17.3. Emptying the buffer.
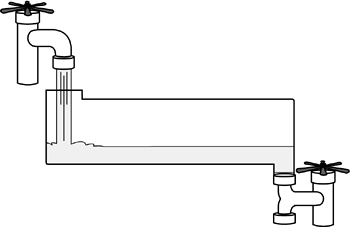
After the buffer is empty, the bottom valve closes, the top valve opens, and more water flows into the buffer tank. Figure 17.4 illustrates this.
Figure 17.4. Refilling the buffer.
Every once in a while, you need to get the water out of the tank even before it is full. This is called “flushing the buffer.” Figure 17.5 illustrates this idea.
Figure 17.5. Flushing the buffer.
You should be aware that one of the risks of using buffering is the possibility that the program will crash while data is still in the buffers. If this occurs, you might lose that data.
Streams and Buffers
As you might expect, C++ takes an object-oriented view toward implementing streams and buffers. It does this with the use of a number of classes and objects:
• The streambuf class manages the buffer, and its member functions provide the capability to fill, empty, flush, and otherwise manipulate the buffer.
• The ios class is the base class to the input and output stream classes. The ios class has a streambuf object as a member variable.
• The istream and ostream classes derive from the ios class and specialize input and output stream behavior, respectively.
• The iostream class is derived from both the istream and the ostream classes and provides input and output methods for writing to the screen.
• The fstream classes provide input and output from files.
You’ll learn more about these classes throughout the rest of today’s lesson.
Standard I/O Objects
When a C++ program that includes the iostream classes starts, four objects are created and initialized:
The iostream class library is added automatically to your program by the compiler. All you need to do to use these functions is to put the appropriate include statement at the top of your program listing:
#include <iostream>
This is something you have been doing in your programs already.
• cin (pronounced “see-in”) handles input from the standard input, the keyboard.
• cout (pronounced “see-out”) handles output to the standard output, the console screen.
• cerr (pronounced “see-err”) handles unbuffered output to the standard error device, the console screen. Because this is unbuffered, everything sent to cerr is written to the standard error device immediately, without waiting for the buffer to fill or for a flush command to be received.
• clog (pronounced “see-log”) handles buffered error messages that are output to the standard error device, the console screen. It is common for this to be “redirected” to a log file, as described in the following section.
Redirection of the Standard Streams
Each of the standard devices, input, output, and error, can be redirected to other devices. The standard error stream (cerr) is often redirected to a file, and standard input (cin) and output (cout) can be piped to files using operating system commands.
Redirecting refers to sending output (or input) to a place different than the default. Redirection is more a function of the operating system than of the iostream libraries. C++ just provides access to the four standard devices; it is up to the user to redirect the devices to whatever alternatives are needed.
The redirection operators for DOS, the Windows command prompt, and Unix are (<) redirect input and (>) redirect output. Unix provides more advanced redirection capabilities than DOS or the standard Windows command prompt; however, the general idea is the same: Take the output intended for the console screen and write it to a file, or pipe it into another program. Alternatively, the input for a program can be extracted from a file rather than from the keyboard.
Note
Piping refers to using the output of one program as the input of another.
Input Using cin
The global object cin is responsible for input and is made available to your program when you include iostream. In previous examples, you used the overloaded extraction operator (>>) to put data into your program’s variables. How does this work? The syntax, as you might remember, is as follows:
int someVariable;
cout << "Enter a number: ";
cin >> someVariable;
The global object cout is discussed later today; for now, focus on the third line, cin >> someVariable;. What can you guess about cin?
Clearly, it must be a global object because you didn’t define it in your own code. You know from previous operator experience that cin has overloaded the extraction operator (>>) and that the effect is to write whatever data cin has in its buffer into your local variable, someVariable.
What might not be immediately obvious is that cin has overloaded the extraction operator for a great variety of parameters, among them int&, short&, long&, double&, float&, char&, char*, and so forth. When you write cin >> someVariable;, the type of someVariable is assessed. In the preceding example, someVariable is an integer, so the following function is called:
istream & operator>> (int &)
Note that because the parameter is passed by reference, the extraction operator is able to act on the original variable. Listing 17.1 illustrates the use of cin.
Listing 17.1. cin Handles Different Data Types

![]()
int: 2
Long: 70000
Double: 987654321
Float: 3.33
Unsigned: 25
Int: 2
Long: 70000
Double: 9.87654e+008
Float: 3.33
Unsigned: 25
![]()
On lines 7–11, variables of various types are declared. On lines 13–22, the user is prompted to enter values for these variables, and the results are printed (using cout) on lines 24–28.
The output reflects that the variables were put into the right “kinds” of variables, and the program works as you might expect.
Inputting Strings
cin can also handle character pointer (char*) arguments; thus, you can create a character buffer and use cin to fill it. For example, you can write the following:
char YourName[50]
cout << "Enter your name: ";
cin >> YourName;
If you enter Jesse, the variable YourName is filled with the characters J, e, s, s, e, �. The last character is a null; cin automatically ends the string with a null character, and you must have enough room in the buffer to allow for the entire string plus the null. The null signals the “end of string” to the cin object.
String Problems
After all this success with cin, you might be surprised when you try to enter a full name into a string. cin has trouble getting the full name because it believes that any whitespace is a separator. When it sees a space or a new line, it assumes the input for the parameter is complete, and in the case of strings, it adds a null character right then and there. Listing 17.2 illustrates this problem.
Listing 17.2. Trying to Write More Than One Word to cin
0: //Listing 17.2 - character strings and cin
1:
2: #include <iostream>
3:
4: int main()
5: {
6: char YourName[50];
7: std::cout << "Your first name: ";
8: std::cin >> YourName;
9: std::cout << "Here it is: " << YourName << std::endl;
10: std::cout << "Your entire name: ";
11: std::cin >> YourName;
12: std::cout << "Here it is: " << YourName << std::endl;
13: return 0;
14: }
![]()
Your first name: Jesse
Here it is: Jesse
Your entire name: Jesse Liberty
Here it is: Jesse
![]()
On line 6, a character array called YourName is created to hold the user’s input. On line 7, the user is prompted to enter one name, and that name is stored properly, as shown in the output.
On line 10, the user is again prompted, this time for a full name. cin reads the input, and when it sees the space between the names, it puts a null character after the first word and terminates input. This is not exactly what was intended.
To understand why this works this way, examine Listing 17.3, which shows input for several fields.
Listing 17.3. Multiple Input

![]()
Int: 2
Long: 30303
Double: 393939397834
Float: 3.33
Word: Hello
Unsigned: 85
Int: 2
Long: 30303
Double: 3.93939e+011
Float: 3.33
Word: Hello
Unsigned: 85
Int, Long, Double, Float, Word, Unsigned: 3 304938 393847473 6.66 bye -2
Int: 3
Long: 304938
Double: 3.93847e+008
Float: 6.66
Word: bye
Unsigned: 4294967294
![]()
Again, several variables are created, this time including a char array. The user is prompted for input and the output is faithfully printed.
On line 34, the user is prompted for all the input at once, and then each “word” of input is assigned to the appropriate variable. It is to facilitate this kind of multiple assignment that cin must consider each word in the input to be the full input for each variable. If cin was to consider the entire input to be part of one variable’s input, this kind of concatenated input would be impossible.
Note that on line 42, the last object requested was an unsigned integer, but the user entered -2. Because cin believes it is writing to an unsigned integer, the bit pattern of -2 was evaluated as an unsigned integer, and when written out by cout, the value 4294967294 was displayed. The unsigned value 4294967294 has the exact bit pattern of the signed value -2.
Later today, you will see how to enter an entire string into a buffer, including multiple words. For now, the question arises, “How does the extraction operator manage this trick of concatenation?”
The cin Return Value
The return value of cin is a reference to an istream object. Because cin itself is an istream object, the return value of one extraction operation can be the input to the next extraction.
int varOne, varTwo, varThree;
cout << "Enter three numbers: "
cin >> varOne >> varTwo >> varThree;
When you write cin >> varOne >> varTwo >> varThree;, the first extraction is evaluated (cin >> varOne). The return value from this is another istream object, and that object’s extraction operator gets the variable varTwo. It is as if you had written this:
((cin >> varOne) >> varTwo) >> varThree;
You’ll see this technique repeated later when cout is discussed.
Other Member Functions of cin
In addition to overloading operator>>, cin has a number of other member functions. These are used when finer control over the input is required. These functions allow you to do the following:
• Get a single character
• Get strings
• Ignore input
• Look at the next character in the buffer
• Put data back into the buffer
Single Character Input
operator>> taking a character reference can be used to get a single character from the standard input. The member function get() can also be used to obtain a single character, and can do so in two ways: get() can be used with no parameters, in which case the return value is used, or it can be used with a reference to a character.
Using get() with No Parameters
The first form of get() is without parameters. This returns the value of the character found and returns EOF (end of file) if the end of the file is reached. get() with no parameters is not often used.
Unlike using cin to get multiple values, it is not possible to concatenate this use of get() for multiple input because the return value is not an iostream object. Thus, the following doesn’t work:
cin.get() >>myVarOne >> myVarTwo; // illegal
The return value of cin.get() >> myVarOne is actually an integer, not an iostream object.
A common use of get() with no parameters is illustrated in Listing 17.4.
Listing 17.4. Using get() with No Parameters
0: // Listing 17.4 - Using get() with no parameters
1:
2: #include <iostream>
3:
4: int main()
5: {
6: char ch;
7: while ( (ch = std::cin.get()) != EOF)
8: {
9: std::cout << "ch: " << ch << std::endl;
10: }
11: std::cout << "
Done!
";
12: return 0;
13: }
Tip
To exit this program, you must send end of file from the keyboard. On DOS computers, use Ctrl+Z; on Unix workstations, use Ctrl+D.
![]()
Hello
ch: H
ch: e
ch: l
ch: l
ch: o
ch:
World
ch: W
ch: o
ch: r
ch: l
ch: d
ch:
^Z (ctrl-z)
Done!
![]()
On line 6, a local character variable, ch, is declared. The while loop assigns the input received from cin.get() to ch, and if it is not EOF, the string is printed out.
This output is buffered until an end of line is read, however. When EOF is encountered (by pressing Ctrl+Z on a DOS machine, or Ctrl+D on a Unix machine), the loop exits.
Note that not every implementation of istream supports this version of get(), although it is now part of the ANSI/ISO standard.
Using get() with a Character Reference Parameter
When a character variable is passed as input to get(), that character variable is filled with the next character in the input stream. The return value is an iostream object, and so this form of get() can be concatenated, as illustrated in Listing 17.5.
Listing 17.5. Using get() with Parameters
0: // Listing 17.5 - Using get() with parameters
1:
2: #include <iostream>
3:
4: int main()
5: {
6: char a, b, c;
7:
8: std::cout << "Enter three letters: ";
9:
10: std::cin.get(a).get(b).get(c);
11:
12: std::cout << "a: " << a << "
b: ";
13: std::cout << b << "
c: " << c << std::endl;
14: return 0;
15: }
![]()
Enter three letters: one
a: o
b: n
c: e
![]()
On line 6, three character variables, a, b, and c, are created. On line 10, cin.get() is called three times, concatenated. First, cin.get(a) is called. This puts the first letter into a and returns cin so that when it is done, cin.get(b) is called, putting the next letter into b. Finally, cin.get(c) is called and the third letter is put in c.
Because cin.get(a) evaluates to cin, you could have written this:
cin.get(a) >> b;
In this form, cin.get(a) evaluates to cin, so the second phrase is cin >> b;.

Getting Strings from Standard Input
The extraction operator (>>) can be used to fill a character array, as can the third version of the member functions get() and the member function getline().
This form of get() takes three parameters:
get( pCharArray, StreamSize, TermChar );
The first parameter (pCharArray) is a pointer to a character array, the second parameter (StreamSize) is the maximum number of characters to read plus one, and the third parameter (TermChar) is the termination character.
If you enter 20 as the second parameter, get() reads 19 characters and then null-terminates the string, which it stores in the first parameter. The third parameter, the termination character, defaults to newline (’
’). If a termination character is reached before the maximum number of characters is read, a null is written and the termination character is left in the buffer.
Listing 17.6 illustrates the use of this form of get().
Listing 17.6. Using get() with a Character Array
0: // Listing 17.6 - Using get() with a character array
1:
2: #include <iostream>
3: using namespace std;
4:
5: int main()
6: {
7: char stringOne[256];
8: char stringTwo[256];
9:
10: cout << "Enter string one: ";
11: cin.get(stringOne,256);
12: cout << "stringOne: " << stringOne << endl;
13:
14: cout << "Enter string two: ";
15: cin >> stringTwo;
16: cout << "StringTwo: " << stringTwo << endl;
17: return 0;
18: }
![]()
Enter string one: Now is the time
stringOne: Now is the time
Enter string two: For all good
StringTwo: For
![]()
On lines 7 and 8, two character arrays are created. On line 10, the user is prompted to enter a string, and cin.get() is called on line 11. The first parameter is the buffer to fill, and the second is one more than the maximum number for get() to accept (the extra position being given to the null character, [’�’]). There is not a third parameter shown; however, this is defaulted. The defaulted third parameter is a newline.
The user enters “Now is the time.” Because the user ends the phrase with a newline, that phrase is put into stringOne, followed by a terminating null.
The user is prompted for another string on line 14, and this time the extraction operator is used. Because the extraction operator takes everything up to the first whitespace, only the string For, with a terminating null character, is stored in the second string, which, of course, is not what was intended.
Using get() with the three parameters is perfectly valid for obtaining strings; however, it is not the only solution. Another way to solve this problem is to use getline(), as illustrated in Listing 17.7.
Listing 17.7. Using getline()
0: // Listing 17.7 - Using getline()
1:
2: #include <iostream>
3: using namespace std;
4:
5: int main()
6: {
7: char stringOne[256];
8: char stringTwo[256];
9: char stringThree[256];
10:
11: cout << "Enter string one: ";
12: cin.getline(stringOne,256);
13: cout << "stringOne: " << stringOne << endl;
14:
15: cout << "Enter string two: ";
16: cin >> stringTwo;
17: cout << "stringTwo: " << stringTwo << endl;
18:
19: cout << "Enter string three: ";
20: cin.getline(stringThree,256);
21: cout << "stringThree: " << stringThree << endl;
22: return 0;
23: }
![]()
Enter string one: one two three
stringOne: one two three
Enter string two: four five six
stringTwo: four
Enter string three: stringThree: five six
![]()
This example warrants careful examination; some potential surprises exist. On lines 7–9, three character arrays are declared this time.
On line 11, the user is prompted to enter a string, and that string is read by using getline(). Like get(), getline() takes a buffer and a maximum number of characters. Unlike get(), however, the terminating newline is read and thrown away. With get(), the terminating newline is not thrown away. It is left in the input buffer.
On line 15, the user is prompted for the second time, and this time the extraction operator is used. In the sample output, you can see that the user enters four five six; however, only the first word, four, is put in stringTwo. The string for the third prompt, Enter string three, is then displayed, and getline() is called again. Because five six is still in the input buffer, it is immediately read up to the newline; getline() terminates and the string in stringThree is printed on line 21.
The user has no chance to enter the third string because the input buffer contained data that fulfilled the request this prompt was making.
The call to cin on line 16 did not use everything that was in the input buffer. The extraction operator (>>) on line 16 reads up to the first whitespace and puts the word into the character array.
Using cin.ignore()
At times, you want to ignore the remaining characters on a line until you hit either end of line (EOL) or end of file (EOF). The member function ignore() serves this purpose. ignore() takes two parameters: the maximum number of characters to ignore and the termination character. If you write ignore(80,’
’), up to 80 characters will be thrown away until a newline character is found. The newline is then thrown away and the ignore() statement ends. Listing 17.8 illustrates the use of ignore().
Listing 17.8. Using ignore()

![]()
Enter string one:once upon a time
String one: once upon a time
Enter string two: String two:
Now try again...
Enter string one: once upon a time
String one: once upon a time
Enter string two: there was a
String Two: there was a
![]()
On lines 6 and 7, two character arrays are created. On line 9, the user is prompted for input and types once upon a time, followed by pressing the Enter key. On line 10, get() is used to read this string. get() fills stringOne and terminates on the newline, but leaves the newline character in the input buffer.
On line 13, the user is prompted again, but the getline() on line 14 reads the input buffer up to the newline. Because a newline was left in the buffer by the call to get(), line 14 terminates immediately, before the user can enter any new input.
On line 19, the user is prompted again and puts in the same first line of input. This time, however, on line 23, ignore() is used to empty the input stream by “eating” the newline character. Thus, when the getline() call on line 26 is reached, the input buffer is empty, and the user can input the next line of the story.
Peeking at and Returning Characters: peek() and putback()
The input object cin has two additional methods that can come in rather handy: peek(), which looks at but does not extract the next character, and putback(), which inserts a character into the input stream. Listing 17.9 illustrates how these might be used.
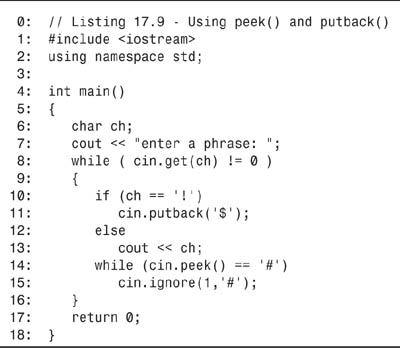
Listing 17.9. Using peek() and putback()
![]()
enter a phrase: Now!is#the!time#for!fun#!
Now$isthe$timefor$fun$
![]()
On line 6, a character variable, ch, is declared, and on line 7, the user is prompted to enter a phrase. The purpose of this program is to turn any exclamation marks (!) into dollar signs ($) and to remove any pound symbols (#).
The program loops on lines 8–16 as long as it is getting characters other than the end of file (Ctrl+C on Windows machines, Ctrl+Z or Ctrl+D on other operating systems). (Remember that cin.get() returns 0 for end of file.) If the current character is an exclamation point, it is thrown away and the $ symbol is put back into the input buffer. This $ symbol is then read the next time through the loop. If the current item is not an exclamation point, it is printed on line 13.
On line 14, the next character is “peeked” at, and when pound symbols are found, they are removed using the ignore() method, as shown on line 15.
This is not the most efficient way to do either of these things (and it won’t find a pound symbol if it is the first character), but it does illustrate how these methods work.
Tip
peek() and putback() are typically used for parsing strings and other data, such as when writing a compiler.
Outputting with cout
You have used cout along with the overloaded insertion operator (<<) to write strings, integers, and other numeric data to the screen. It is also possible to format the data, aligning columns and writing numeric data in decimal and hexadecimal. This section shows you how.
Flushing the Output
You’ve already seen that using endl writes a newline and then flushes the output buffer. endl calls cout’s member function flush(), which writes all the data it is buffering. You can also call the flush() method directly, either by calling the flush() member method or by writing the following:
cout << flush();
This can be convenient when you need to ensure that the output buffer is emptied and that the contents are written to the screen.
Functions for Doing Output
Just as the extraction operator can be supplemented with get() and getline(), the insertion operator can be supplemented with put() and write().
Writing Characters with put()
The function put() is used to write a single character to the output device. Because put() returns an ostream reference and because cout is an ostream object, you can concatenate put() the same as you can stack the insertion operator. Listing 17.10 illustrates this idea.
Listing 17.10. Using put()
0: // Listing 17.10 - Using put()
1:
2: #include <iostream>
3:
4: int main()
5: {
6: std::cout.put(’H’).put(’e’).put(’l’).put(’l’).put(’o’).put(’
’);
7: return 0;
8: }
![]()
Hello
Some nonstandard compilers have trouble printing using this code. If your compiler does not print the word Hello, you might want to skip this listing.
![]()
Line 6 is evaluated like this: std::cout.put(’H’) writes the letter “H” to the screen and returns a cout object. This leaves the following:
cout.put(’e’).put(’l’).put(’l’).put(’o’).put(’
’);
The letter “e” is written, and, again, a cout object is returned leaving:
cout.put(’l’).put(’l’).put(’o’).put(’
’);
This process repeats, each letter being written and the cout object returned until the final character (’
’) is written and the function returns.
Writing More with write()
The function write() works the same as the insertion operator (<<), except that it takes a parameter that tells the function the maximum number of characters to write:
cout.write(Text, Size)
As you can see, the first parameter for write() is the text that will be printed. The second parameter, Size, is the number of characters that will be printed from Text. Note that this number might be smaller or larger than the actual size of the Text. If it is larger, you will output the values that reside in memory after the Text value. Listing 17.11 illustrates its use.
Listing 17.11. Using write()

![]()
One if by land
One if by
One if by land i?!
Note
The final line of output might look different on your computer because it accesses memory that is not part of an initialized variable.
![]()
This listing prints from a phrase. Each time it prints a different amount of the phrase. On line 7, one phrase is created. On line 9, the integer fullLength is set to the length of the phrase using a global strlen() method that was included with the string directive on line 2. Also set are two other length values that will be used; tooShort is set to the length of the phrase (fullLength) minus four, and tooLong is set to the length of the phrase plus six.
On line 13, the complete phrase is printed using write(). The length is set to the actual length of the phrase, and the correct phrase is printed.
On line 14, the phrase is printed again, but it is four characters shorter than the full phrase, and that is reflected in the output.
On line 15, the phrase is printed again, but this time write() is instructed to write an extra six characters. After the phrase is written, the next six bytes of contiguous memory are written. Anything could be in this memory, so your output might vary from what is shown previously.
Manipulators, Flags, and Formatting Instructions
The output stream maintains a number of state flags, determining which base (decimal or hexadecimal) to use, how wide to make the fields, and what character to use to fill in fields. A state flag is a byte whose individual bits are each assigned a special meaning. Manipulating bits in this way is discussed on Day 21, “What’s Next.” Each of ostream’s flags can be set using member functions and manipulators.
Using cout.width()
The default width of your output will be just enough space to print the number, character, or string in the output buffer. You can change this by using width().
Because width() is a member function, it must be invoked with a cout object. It only changes the width of the very next output field and then immediately reverts to the default. Listing 17.12 illustrates its use.
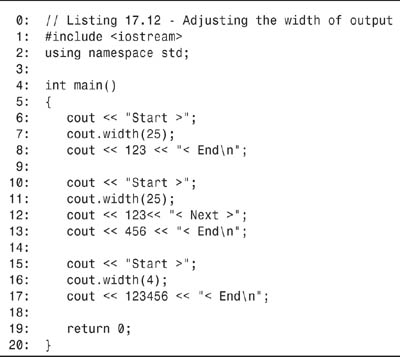
Listing 17.12. Adjusting the Width of Output
![]()
Start > 123< End
Start > 123< Next >456< End
Start >123456< End
![]()
The first output, on lines 6–8, prints the number 123 within a field whose width is set to 25 on line 7. This is reflected in the first line of output.
The second line of output first prints the value 123 in the same field whose width is set to 25, and then prints the value 456. Note that 456 is printed in a field whose width is reset to just large enough; as stated, the effect of width() lasts only as long as the very next output.
The final output reflects that setting a width that is smaller than the output is the same as setting a width that is just large enough. A width that is too small will not truncate what is being displayed.
Setting the Fill Characters
Normally, cout fills the empty field created by a call to width() with spaces, as shown previously. At times, you might want to fill the area with other characters, such as asterisks. To do this, you call fill() and pass in as a parameter the character you want used as a fill character. Listing 17.13 illustrates this.
Listing 17.13. Using fill()

![]()
Start > 123< End
Start >******************123< End
Start >******************456< End
![]()
Lines 7–9 repeat the functionality from the previous example by printing the value 123 in a width area of 25. Lines 11–14 repeat this again, but this time, on line 13, the fill character is set to an asterisk, as reflected in the output. You should notice that unlike the width() function, which only applies to the next output, the new fill() character remains until you change it. You see this verified with the output from lines 16–18.
Managing the State of Output: Set Flags
Objects are said to have state when some or all of their data represents a condition that can change during the course of the program. For example, you can set whether to show trailing zeros (so that 20.00 is not truncated to 20).
The iostream objects keep track of their state by using flags. You can set these flags by calling setf() and passing in one of the predefined enumerated constants. For example, to turn trailing zeros on, you call setf(ios::showpoint).
The enumerated constants are scoped to the iostream class (ios) and thus when used with setf(), they are called with the full qualification ios::flagname, such as ios::showpoint. TABLE 17.1 shows some of the flags you can use. When using these flags, you need to include iostream in your listing. In addition, for those flags that require parameters, you need to include iomanip.
Table 17.1. Some of the iostream Set Flags

The flags in Table 17.1 can also be concatenated into the insertion operator. Listing 17.14 illustrates these settings. As a bonus, Listing 17.14 also introduces the setw manipulator, which sets the width but can also be concatenated with the insertion operator.
Listing 17.14. Using setf

![]()
The number is 185
The number is b9
The number is 0xb9
The number is 0xb9
The number is 0xb9
The number is 0x b9
The number is:0x b9
![]()
On line 7, the constant int number is initialized to the value 185. This is displayed normally on line 8.
The value is displayed again on line 10, but this time the manipulator hex is concatenated, causing the value to be displayed in hexadecimal as b9.
Note
The value b in hexadecimal represents 11. Eleven times 16 equals 176; add the 9 for a total of 185.
On line 12, the flag showbase is set. This causes the prefix 0x to be added to all hexadecimal numbers, as reflected in the output.
On line 16, the width is set to 10, and by default, the value is pushed to the extreme right. On line 20, the width is again set to 10, but this time the alignment is set to the left, and the number is printed flush left this time.
On line 25, again the width is set to 10, but this time the alignment is internal. Thus, the 0x is printed flush left, but the value, b9, is printed flush right.
Finally, on line 29, the concatenation operator setw() is used to set the width to 10, and the value is printed again.
You should notice in this listing that if the flags are used within the cout list that they do not need to be qualified; hex can be passed as hex. When you use the setf() function, you need to qualify the flags to the class; hex is passed as ios::hex. You see this difference on line 17 versus 21.
Streams Versus the printf() Function
Most C++ implementations also provide the standard C I/O libraries, including the printf() statement. Although printf() is in some ways easier to use than cout, it is much less desirable.
printf() does not provide type safety, so it is easy to inadvertently tell it to display an integer as if it were a character, and vice versa. printf() also does not support classes, and so it is not possible to teach it how to print your class data; you must feed each class member to printf() one by one.
Because there is a lot of legacy code using printf(), this section briefly reviews how printf() is used. It is not, however, recommended that you use this function in your C++ programs.
To use printf(), be certain to include the stdio.h header file. In its simplest form, printf() takes a formatting string as its first parameter and then a series of values as its remaining parameters.
The formatting string is a quoted string of text and conversion specifiers. All conversion specifiers must begin with the percent symbol (%). The common conversion specifiers are presented in Table 17.2.
Table 17.2. The Common Conversion Specifiers

Each of the conversion specifiers can also provide a width statement and a precision statement, expressed as a float, where the digits to the left of the decimal are used for the total width, and the digits to the right of the decimal provide the precision for floats. Thus, %5d is the specifier for a 5-digit-wide integer, and %15.5f is the specifier for a 15-digit-wide float, of which the final five digits are dedicated to the decimal portion. Listing 17.15 illustrates various uses of printf().
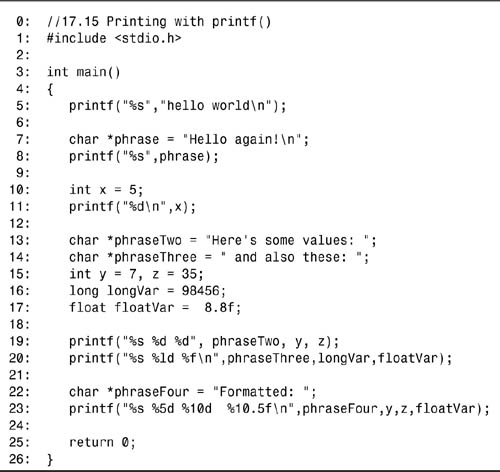
Listing 17.15. Printing with printf()
![]()

![]()
The first printf() statement, on line 5, uses the standard form: the term printf, followed by a quoted string with a conversion specifier (in this case %s), followed by a value to insert into the conversion specifier.
The %s indicates that this is a string, and the value for the string is, in this case, the quoted string “hello world.”
The second printf() statement on line 8 is the same as the first, but this time a char pointer is used, rather than quoting the string right in place in the printf() statement. The result, however, is the same.
The third printf(), on line 11, uses the integer conversion specifier (%d), and for its value the integer variable x is used. The fourth printf() statement, on line 19, is more complex. Here, three values are concatenated. Each conversion specifier is supplied, and then the values are provided, separated by commas. Line 20 is similar to line 19; however, different specifiers and values are used.
Finally, on line 23, format specifications are used to set the width and precision. As you can see, all this is somewhat easier than using manipulators.
As stated previously, however, the limitation here is that no type checking occurs and printf() cannot be declared a friend or member function of a class. So, if you want to print the various member data of a class, you must call each accessor method in the argument list sent to the printf() statement.
cout << "aAn error occured "
flush—Flushes the output buffer
endl—Inserts newline and flushes the output buffer
oct—Sets output base to octal
dec—Sets output base to decimal
hex—Sets output base to hexadecimal
setbase (base)—Sets output base (0 = decimal, 8 = octal, 10 = decimal, 16 = hex)
setw (width)—Sets minimum output field width
setfill (ch)—Fills character to be used when width is defined
setprecision (p)—Sets precision for floating-point numbers
setiosflags (f)—Sets one or more ios flags
resetiosflags (f)—Resets one or more ios flags
cout << setw(12) << setfill(’#’) << hex << x << endl;
File Input and Output
Streams provide a uniform way of dealing with data coming from the keyboard or the hard disk and going out to the console screen or hard disk. In either case, you can use the insertion and extraction operators or the other related functions and manipulators. To open and close files, you create ifstream and ofstream objects as described in the next few sections.
Using the ofstream
The particular objects used to read from or write to files are called ofstream objects. These are derived from the iostream objects you’ve been using so far.
To get started with writing to a file, you must first create an ofstream object, and then associate that object with a particular file on your disk. To use ofstream objects, you must be certain to include fstream in your program.
Note
Because fstream includes iostream, you do not need to include iostream explicitly.
Condition States
The iostream objects maintain flags that report on the state of your input and output. You can check each of these flags using the Boolean functions eof(), bad(), fail(), and good(). The function eof() returns true if the iostream object has encountered EOF, end of file. The function bad() returns true if you attempt an invalid operation. The function fail() returns true anytime bad() is true or an operation fails. Finally, the function good() returns true anytime all three of the other functions are false.
Opening Files for Input and Output
To use a file, you must first open it. To open the file myfile.cpp with an ofstream object, declare an instance of an ofstream object and pass in the filename as a parameter:
ofstream fout("myfile.cpp");
This attempts to open the file, myfile.cpp, for output. Opening this file for input works the same way, except that it uses an ifstream object:
ifstream fin("myfile.cpp");
Note that fout and fin are names you define; here, fout has been used to reflect its similarity to cout, and fin has been used to reflect its similarity to cin. These could also be given names that reflect what is in the file they are accessing.
One important file stream function that you will need right away is close(). Every file stream object you create opens a file for reading (input), writing (output), or both. It is important to close() the file after you finish reading or writing; this ensures that the file won’t be corrupted and that the data you’ve written is flushed to the disk.
After the stream objects are associated with files, they can be used the same as any other stream objects. Listing 17.16 illustrates this.
Listing 17.16. Opening Files for Read and Write
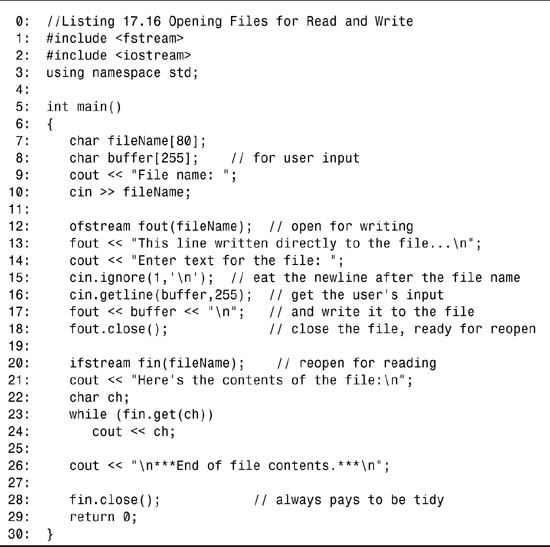
![]()
File name: test1
Enter text for the file: This text is written to the file!
Here’s the contents of the file:
This line written directly to the file...
This text is written to the file!
***End of file contents.***
![]()
On line 7, a buffer is created for the filename, and on line 8, another buffer is set aside for user input. The user is prompted to enter a filename on line 9, and this response is written to the fileName buffer. On line 12, an ofstream object is created, fout, which is associated with the new filename. This opens the file; if the file already exists, its contents are thrown away.
On line 13, a string of text is written directly to the file. On line 14, the user is prompted for input. The newline character left over from the user’s input of the filename is eaten on line 15 by using the ignore() function you learned about earlier. The user’s input for the file is stored into buffer on line 16. That input is written to the file along with a newline character on line 17, and then the file is closed on line 18.
On line 20, the file is reopened, this time in input mode by using the ifstream. The contents are then read one character at a time on lines 23 and 24.
Changing the Default Behavior of ofstream on Open
The default behavior upon opening a file is to create the file if it doesn’t yet exist and to truncate the file (that is, delete all its contents) if it does exist. If you don’t want this default behavior, you can explicitly provide a second argument to the constructor of your ofstream object.
Valid values for the second argument include
• ios::app—Appends to the end of existing files rather than truncating them.
• ios::ate—Places you at the end of the file, but you can write data anywhere in the file.
• ios::trunc—Causes existing files to be truncated; the default.
• ios::nocreate—If the file does not exist, the open fails.
• ios::noreplace—If the file does already exist, the open fails.
Note that app is short for append, ate is short for at end, and trunc is short for truncate. Listing 17.17 illustrates using append by reopening the file from Listing 17.16 and appending to it.
Listing 17.17. Appending to the End of a File
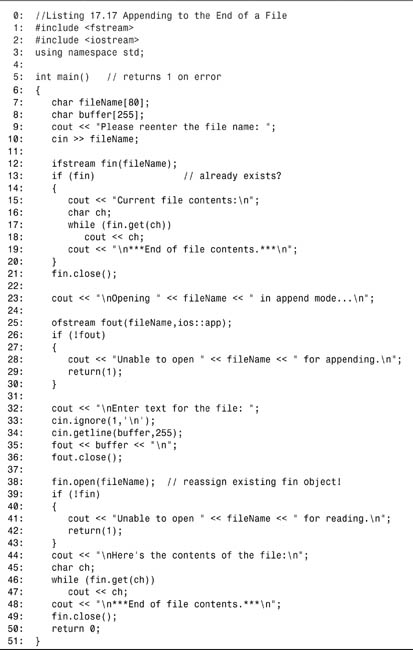
![]()
Please reenter the file name: test1
Current file contents:
This line written directly to the file...
This text is written to the file!
***End of file contents.***
Opening test1 in append mode...
Enter text for the file: More text for the file!
Here’s the contents of the file:
This line written directly to the file...
This text is written to the file!
More text for the file!
***End of file contents.***
![]()
Like the preceding listing, the user is again prompted to enter the filename on lines 9 and 10. This time, an input file stream object is created on line 12. That open is tested on line 13, and if the file already exists, its contents are printed on lines 15–19. Note that if(fin) is synonymous with if (fin.good()).
The input file is then closed, and the same file is reopened, this time in append mode, on line 25. After this open (and every open), the file is tested to ensure that the file was opened properly. Note that if(!fout) is the same as testing if (fout.fail()). If the file didn’t open, an error message is printed on line 28 and the program ends with the return statement. If the open is successful, the user is then prompted to enter text, and the file is closed again on line 36.
Finally, as in Listing 17.16, the file is reopened in read mode; however, this time fin does not need to be redeclared. It is just reassigned to the same filename. Again, the open is tested, on line 39, and if all is well, the contents of the file are printed to the screen and the file is closed for the final time.

Binary Versus Text Files
Some operating systems distinguish between text files and binary files. Text files store everything as text (as you might have guessed), so large numbers such as 54,325 are stored as a string of numerals (’5’, ‘4’, ‘,’, ‘3’, ‘2’, ‘5’). This can be inefficient, but has the advantage that the text can be read using simple programs such as the DOS and Windows command-line program type.
To help the file system distinguish between text and binary files, C++ provides the ios::binary flag. On many systems, this flag is ignored because all data is stored in binary format. On some rather prudish systems, the ios::binary flag is illegal and doesn’t even compile!
Binary files can store not only integers and strings, but also entire data structures. You can write all the data at one time by using the write() method of fstream.
If you use write(), you can recover the data using read(). Each of these functions expects a pointer to character, however, so you must cast the address of your class to be a pointer to character.
The second argument to these functions is the number of characters expected to be read or written, which you can determine using sizeof(). Note that what is being written is the data, not the methods. What is recovered is only data. Listing 17.18 illustrates writing the contents of an object to a file.
Listing 17.18. Writing a Class to a File
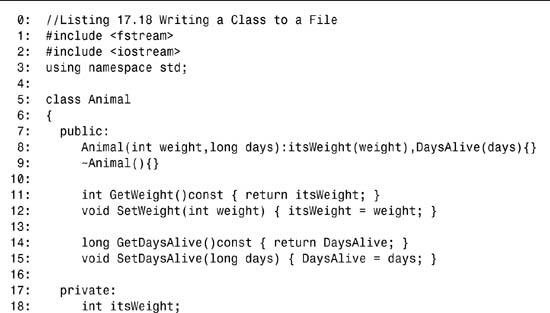

![]()
Please enter the file name: Animals
BearTwo weight: 1
BearTwo days: 1
BearTwo weight: 50
BearTwo days: 100
![]()
On lines 5–20, a stripped-down Animal class is declared. On lines 24–34, a file is created and opened for output in binary mode. An animal whose weight is 50 and who is 100 days old is created on line 36, and its data is written to the file on line 37.
The file is closed on line 39 and reopened for reading in binary mode on line 41. A second animal is created, on line 48, whose weight is 1 and who is only one day old. The data from the file is read into the new animal object on line 53, wiping out the existing data and replacing it with the data from the file. The output confirms this.
Command-line Processing
Many operating systems, such as DOS and Unix, enable the user to pass parameters to your program when the program starts. These are called command-line options and are typically separated by spaces on the command line. For example,
SomeProgram Param1 Param2 Param3
These parameters are not passed to main() directly. Instead, every program’s main() function is passed two parameters. The first is an integer count of the number of arguments on the command line. The program name itself is counted, so every program has at least one parameter. The sample command line shown previously has four. (The name SomeProgram plus the three parameters make a total of four command-line arguments.)
The second parameter passed to main() is an array of pointers to character strings. Because an array name is a constant pointer to the first element of the array, you can declare this argument to be a pointer to a pointer to char, a pointer to an array of char, or an array of arrays of char.
Typically, the first argument is called argc (argument count), but you can call it anything you like. The second argument is often called argv (argument vector), but again this is just a convention.
It is common to test argc to ensure you’ve received the expected number of arguments and to use argv to access the strings themselves. Note that argv[0] is the name of the program, and argv[1] is the first parameter to the program, represented as a string. If your program takes two numbers as arguments, you need to translate these numbers to strings. On Day 21, you will see how to use the Standard Library conversions. Listing 17.19 illustrates how to use the command-line arguments.
Listing 17.19. Using Command-line Arguments

![]()
TestProgram Teach Yourself C++ In 21 Days
Received 7 arguments...
argumnet 0: TestProgram
argument 1: Teach
argument 2: Yourself
argument 3: C++
argument 4: In
argument 5: 21
argument 6: Days
Note
You must either run this code from the command line (that is, from a DOS box) or you must set the command-line parameters in your compiler (see your compiler documentation).
![]()
The function main() declares two arguments: argc is an integer that contains the count of command-line arguments, and argv is a pointer to the array of strings. Each string in the array pointed to by argv is a command-line argument. Note that argv could just as easily have been declared as char *argv[] or char argv[][]. It is a matter of programming style how you declare argv; even though this program declared it as a pointer to a pointer, array offsets were still used to access the individual strings.
On line 4, argc is used to print the number of command-line arguments: seven in all, counting the program name itself.
On lines 5 and 6, each of the command-line arguments is printed, passing the null-terminated strings to cout by indexing into the array of strings.
A more common use of command-line arguments is illustrated by modifying Listing 17.18 to take the filename as a command-line argument, as shown in Listing 17.20.
Listing 17.20. Using Command-line Arguments To Get a Filename
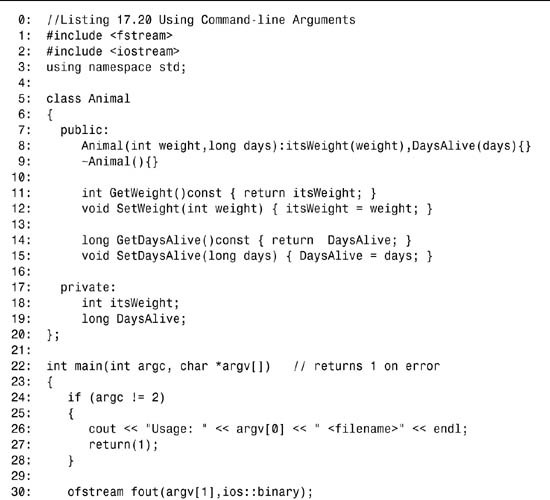

![]()
BearTwo weight: 1
BearTwo days: 1
BearTwo weight: 50
BearTwo days: 100
![]()
The declaration of the Animal class is the same as in Listing 17.18. This time, however, rather than prompting the user for the filename, command-line arguments are used. On line 22, main() is declared to take two parameters: the count of the command-line arguments and a pointer to the array of command-line argument strings.
On lines 24–28 the program ensures that the expected number of arguments (exactly two) is received. If the user fails to supply a single filename, an error message is printed:
Usage TestProgram <filename>
Then, the program exits. Note that by using argv[0] rather than hard-coding a program name, you can compile this program to have any name, and this usage statement works automatically. You can even rename the executable after it was compiled and the usage statement will still be correct!
On line 30, the program attempts to open the supplied filename for binary output. No reason exists to copy the filename into a local temporary buffer. It can be used directly by accessing argv[1].
This technique is repeated on line 42 when the same file is reopened for input, and it is used in the error condition statements when the files cannot be opened, on lines 33 and 45.
Summary
Today, streams were introduced, and the global objects cout and cin were described. The goal of the istream and ostream objects is to encapsulate the work of writing to device drivers and buffering input and output.
Four standard stream objects are created in every program: cout, cin, cerr, and clog. Each of these can be “redirected” by many operating systems.
The istream object cin is used for input, and its most common use is with the overloaded extraction operator (>>). The ostream object cout is used for output, and its most common use is with the overloaded insertion operator (<<).
Each of these objects has a number of other member functions, such as get() and put(). Because the common forms of each of these methods returns a reference to a stream object, it is easy to concatenate each of these operators and functions.
The state of the stream objects can be changed by using manipulators. These can set the formatting and display characteristics and various other attributes of the stream objects.
File I/O can be accomplished by using the fstream classes, which derive from the stream classes. In addition to supporting the normal insertion and extraction operators, these objects also support read() and write() for storing and retrieving large binary objects.
Q&A
Q How do I know when to use the insertion and extraction operators and when to use the other member functions of the stream classes?
A In general, it is easier to use the insertion and extraction operators, and they are preferred when their behavior is what is needed. In those unusual circumstances when these operators don’t do the job (such as reading in a string of words), the other functions can be used.
Q What is the difference between cerr and clog?
A cerr is not buffered. Everything written to cerr is immediately written out. This is fine for errors to be written to the console screen, but might have too high a performance cost for writing logs to disk. clog buffers its output, and thus can be more efficient, at the risk of losing part of the log if the program crashes.
Q Why were streams created if printf() works well?
A printf() does not support the strong type system of C++, and it does not support user-defined classes. Support for printf() is really just a carryover from the C programming language.
Q When would I ever use putback()?
A When one read operation is used to determine whether a character is valid, but a different read operation (perhaps by a different object) needs the character to be in the buffer. This is most often used when parsing a file; for example, the C++ compiler might use putback().
Q My friends use printf() in their C++ programs. Can I?
A No. At this point, printf() should properly be considered obsolete.
Workshop
The Workshop contains quiz questions to help solidify your understanding of the material covered and exercises to provide you with experience in using what you’ve learned. Try to answer the quiz and exercise questions before checking the answers in Appendix D, and be certain you understand the answers before going to tomorrow’s lesson.
Quiz
1. What is the insertion operator, and what does it do?
2. What is the extraction operator, and what does it do?
3. What are the three forms of cin.get(), and what are their differences?
4. What is the difference between cin.read() and cin.getline()?
5. What is the default width for outputting a long integer using the insertion operator?
6. What is the return value of the insertion operator?
7. What parameter does the constructor to an ofstream object take?
8. What does the ios::ate argument do?
Exercises
1. Write a program that writes to the four standard iostream objects: cin, cout, cerr, and clog.
2. Write a program that prompts the user to enter her full name and then displays it on the screen.
3. Rewrite Listing 17.9 to do the same thing, but without using putback() or ignore().
4. Write a program that takes a filename as a parameter and opens the file for reading. Read every character of the file and display only the letters and punctuation to the screen. (Ignore all nonprinting characters.) Then close the file and exit.
5. Write a program that displays its command-line arguments in reverse order and does not display the program name.