
Traditional multithreaded applications rely on accessing data located in shared memory. The mechanism relies on synchronization monitors such as locks, mutexes, or semaphores to avoid deadlocks and inconsistent mutable states. Even for the most experienced software engineer, debugging multithreaded applications is not a simple endeavor.
The second problem with shared memory threads in Java is the high computation overhead caused by continuous context switches. Context switching consists of saving the current stack frame delimited by the base and stack pointers into the heap memory and loading another stack frame.
These restrictions and complexities can be avoided by using a concurrency model that relies on the following key principles:
- Immutable data structures
- Asynchronous communication
The Actor model, originally introduced in the Erlang programming language, addresses these issues [16:3]. The purpose of using the Actor model is two-fold:
- It distributes the computation over as many cores and servers as possible
- It reduces or eliminates race conditions and deadlocks, which are very prevalent in Java development
The model consists of the following components:
- Independent processing units are known as Actors. Actors communicate by exchanging messages asynchronously instead of sharing states.
- Immutable messages are sent to queues, known as mailboxes, before being processed by each Actor one at a time.
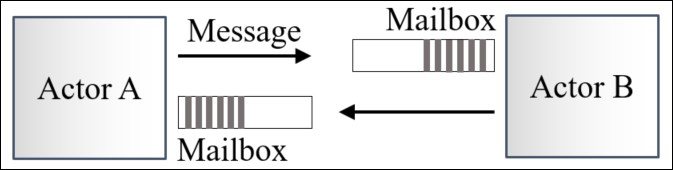
Representation of messaging between Actors
There are two message-passing mechanisms:
- Fire-and-forget or tell: Sends the immutable message asynchronously to the target or receiving Actor, and returns immediately without blocking. The syntax is as follows:
targetActorRef ! message
- Send-and-receive or ask: Sends a message asynchronously, but returns a
Futureinstance that defines the expected reply from the target Actorval future = targetActorRef ? message.
The generic construct for the Actor message handler is somewhat similar to the Runnable.run() method in Java, as shown in the following code:
while( true ){
receive { case msg1: MsgType => handler }
}The receive keyword is in fact a partial function of type PartialFunction[Any, Unit] [16:4]. The purpose is to avoid forcing developers to handle all possible message types. The Actor consuming messages may very well run on a separate component or even application, than the Actor producing these messages. It not always easy to anticipate the type of messages an Actor has to process in a future version of an application.
A message whose type is not matched is merely ignored. There is no need to throw an exception from within the Actor's routine. Implementations of the Actor model strive to avoid the overhead of context switching and creation of threads[16:5].
Note
I/O blocking operations
Although it is highly recommended not to use Actors for blocking operations such as I/O, there are circumstances that require the sender to wait for a response. Your to be mindful that blocking the underlying threads might starve other Actors from CPU cycles. It is recommended you either configure the runtime system to use a large thread pool, or you allow the thread pool to be resized by setting the actors.enableForkJoin property as false.
A dataset is defined as a Scala collection, for example, List, Map, and so on. Concurrent processing requires the following steps:
- Breaking down a dataset into multiple sub-datasets.
- Processing each dataset independently and concurrently.
- Aggregating all the resulting datasets.
These steps are defined through a monad associated with a collection in the Abstraction section under Why Scala? in Chapter 1, Getting started:
- The
applymethod creates the sub-collection or partitions for the first step, for example,def apply[T](a: T): List[T]. - A map-like operation defines the second stage. The last step relies on the monoidal associativity of the Scala collection, for example,
def ++ (a: List[T]. b: List[T): List[T} = a ++ b. - The aggregation, such as
reduce,fold,sum, and so on, consists of flattening all the sub-results into a single output, for example,val xs: List(…) = List(List(..), List(..)).flatten.
The methods that can be parallelized are map, flatMap, filter, find, and filterNot. The methods that cannot be completely parallelized are reduce, fold, sum, combine, aggregate, groupBy, and sortWith.
The Actor model is an example of the reactive programming paradigm. The concept is that functions and methods are executed in response to events or exceptions. Reactive programming combines concurrency with event-based systems [16:6].
Advanced functional reactive programming constructs rely on composable futures and continuation-passing style (CPS). An example of a Scala reactive library can be found at https://github.com/ingoem/scala-react.