
11
–––––––––––––––––––––––
A Framework for Semiautomatic Explicit Parallelization
Ritu Arora, Purushotham Bangalore, and Marjan Mernik
11.1 INTRODUCTION
With advancement in science and technology, computational problems are growing in size and complexity, thereby resulting in higher demand forhigh-performance computing (HPC) resources. To keep up with competitive pressure, the demand for reduced time to solution is also increasing, and simulations on high-performance computers are being preferred over physical prototype development and testing. Recent studies have shown that though HPC is gradually becoming indispensable for stakeholders'growth, the programming challenges associated with the development of HPC applications (e.g., lack of HPC experts, learning curve, and system manageability) are key deterrents to adoption of HPC on a massive scale [1, 2]. Therefore, a majority of organizations (in science, technology, and business domains) are stalled at the desktop-computing level. Some of the programming challenges associated with HPC application development are the following:
- There are multiple parallel programming platforms and hence multiple parallel programming paradigms, each best suited for a particular platform. Forexample, message-passing interface (MPI) [3] is best suited for developing parallel programs for distributed-memory architectures, whereas OpenMP [4] is widely used for developing applications for shared-memory architectures.
- It is increasingly difficult to harness the peak performance provided by modern HPC platforms due to the slow rate of advancement in the area of parallel programming environments.
- Adapting the applications to new architectures is a time-consuming activity because it might require manual retuning, reoptimization, or reimplementation of the application [5].
In light of the aforementioned challenges related to fast-changing, increasingly complex, and diverse computing platforms, key questions that arise are the following:
- Can we bring scalability and performance to domain experts in the form of parallel computing without any need to learn low-level parallel programming?
- Can computers automatically generate efficient parallel programs from specifications provided by domain experts?
There is no single silver bullet [6] to alleviate all the complexities associated with the HPC application development process. In our opinion, only through an effective combination of multiple modern software engineering techniques can one attack the challenges associated with the development of HPC applications. Frameworks that enable domain experts to do rapid application development and testing are needed. Such frameworks should not force the domain experts to rewrite their applications and should support code reuse by isolating the commonly occurring computation and communication patterns in parallel applications in the form of abstractions. For example, in all MPI applications, it is required to include the MPI library file, to set up the MPI execution environment, and to terminate the MPI execution environment. All these common steps can be abstracted so that there is no need to write them manually while writing any MPI application. In fact, more involved steps like data distribution and data collection can also be abstracted from the domain experts; this is explained in the rest of the chapter.
11.2 EXPLICIT PARALLELIZATION USING MPI
HPC applications for distributed-memory architectures can be developed using methods of either implicit parallelization or explicit parallelization. Implicit parallelization is achieved by using implicitly parallel languages like X10 [7] and Fortress [8]. Because the parallelism is characteristic of the language itself, the language compiler or interpreter is able to automatically parallelize the computations on the basis of the language constructs used. This method of parallelization allows the programmer to focus on the problem to be solved instead of worrying about the low-level details of how the parallelization is achieved. This method, however, does not leverage from existing legacy applications and entails rewriting of the entire code.
Explicit parallelization is achieved by using specialized libraries for parallelization in conjunction with the programming language of the programmer's choice. With this approach, the programmer inserts the library calls in the existing application at the points where parallelization is desired. Thus, this approach helps the programmer to leverage their existing sequential applications. Though it gives the desired control, flexibility, and performance to the programmers, it also puts the burden on them in terms of time and effort required to parallelize their applications. MPI [3] and OpenMP [4] are the two widely used standards for developing applications for distributed-and shared-memory architectures using the explicit mode of parallelization.
The main focus of our research was to simplify the process of explicit parallelization that is based on MPI [5]. It has been observed that the typical process of developing parallel applications using MPI begins with a working sequential application. The programmers identify concurrency in the existing sequential application and express the same in terms of data or task distribution among the available processes by including MPI routines and making other structural changes to the existing code. The programmers have to explicitly map the tasks to the processors, manually orchestrate the exchange of messages, and be responsible for load balancing and synchronization. The parallel version generated by inserting the MPI routines in the sequential application is further optimized, as per the machine architecture, to obtain maximum efficiency or speedup. The manual optimization of the code might involve several iterations of code changes. Thus, the process of developing, debugging, optimizing, and maintaining MPI-based parallel applications is a challenging task that involves manual, invasive reengineering and handling of low level message-passing details.
The software development process using MPI involves ad hoc design decisions [5]. There are multiple options available for setting the communication between the processes and each option has certain trade-offs (e.g., synchronous vs. asynchronous), but there are no clear guidelines that can help the programmer choose one option over the other.
There are some mechanical steps for setting up the MPI environment that can be found in every MPI program. Analyses of code samples from diverse domains also shows replicated code constructs for tasks other than setting up the MPI environment [5]. Such commonalities (replicated code constructs) indicate that there is a scope for reducing the effort involved in developing HPC applications by promoting code reuse through frameworks.
A framework called Framework for Synthesizing Parallel Applications (FraSPA) has been developed to mitigate the aforementioned challenges—those associated with using MPI in particular and HPC in general. FraSPA is useful for developing parallel applications without burdening the end user (or domain expert) to learn or use MPI. However, the end users of FraSPA are still required to identify concurrency in their applications and to express the same in a very succinct manner. Therefore, FraSPA employs a user-guided approach to synthesize optimized parallel programs from existing sequential programs. It has been developed using the generative programming [9] approach and can synthesize parallel programs for a wide range of application domains.
11.3 BUILDING BLOCKS OF FRASPA
Besides achieving the immediate goal of supporting the synthesis of parallel applications based on the MPI paradigm, it was required to build the capability to cater to a wide variety of parallel programming paradigms and languages in the future. The ability to add new features or concepts to FraSPA, without having to modify the existing code, was also required. Therefore, FraSPA was designed to have extensibility and flexibility. These two main properties of FraSPA are further explained below:
- Extensibility. The property of the framework that allows the user to add extra functionality at a later stage is called extensibility. In context of FraSPA, extensibility is desired so that the support for multiple programming models (e.g., OpenMP and OpenCL) and languages (e.g., Fortran) can be provided in future.
- Flexibility. The property of the framework that allows users to compose their own design patterns from the existing components by assembling them in any order is called flexibility. In the context of FraSPA, this means that there is no restriction in the order of specifying the Application Programming Interface (API) for different parallel operations. Also, there is no restriction imposed by FraSPA on the combination of various parallel operations.
A domain-specific language (DSL) [10] was developed so that end users can provide specifications related to parallelization at a high level. DSLs or “little languages” are high-level languages that have limited capability in terms of what they can be used for, but they are highly expressive for the domain for which they are developed. FraSPA converts a sequential application into a parallel one through a powerful combination of a source-to-source compiler (SSC) [9, 11], which is also referred to as a program transformation engine, and concurrency specifications provided by the end user via the DSL developed in this research. This high-level, declarative, and platform-independent DSL is called High-Level Parallelization Language (Hi-PAL) [5].
As shown in Figure 11.1, the Hi-PaL (or DSL) code is parsed by the rule generator to generate intermediate code. The intermediate code is a set of rules (generated rules in Fig 11.1) that the SSC can comprehend. These rules contain the precise information about the modifications desired by the end user (with respect to parallelization), and the place in the existing code where these modifications should take effect. By applying the generated rules and other code components, for example, design templates, the SSC transforms the existing code into transformed code. In this research, both the existing code and the transformed code have the same base language (C/C++). The SSC used in this research is also capable of transforming code written in one language to another (e.g., C to Fortran) [11, 12].
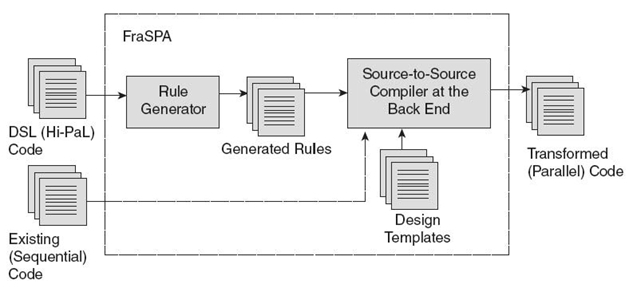
FIGURE 11.1. High-level architecture of FraSPA.
The complete work flow—from parsing of the input Hi-PaL code to generating the transformed code—is part of FraSPA. Hi-PaL serves as the interface between the end user and FraSPA. The end users are only responsible for analyzing their existing applications and for expressing the transformations that they desire (data distribution, data collection, etc.) by the means of Hi-PaL. The other steps responsible for transformations are like a “black box” to them. Thus, the end user is freed from the burden of learning low-level parallel programming.
FraSPA has a three layered architecture composed of front end, middle layer, and back end. All the layers are decoupled from each other and a description of each of them is as follows:
- Front End (Hi-PaL). This is the primary interface between the end user and FraSPA. It comprises the abstractions for expressing the specifications for explicit parallelization.
- Middle Layer (Rule Generator). This layer is not visible to the end user and is used for translating the high-level abstractions obtained from the front end into the intermediate code to be used by the back end.
- Back End (SSC). This layer is also hidden from the end user and is required for code instrumentation—that is, for inserting the code for parallelization into the existing sequential application on the basis of the intermediate code generated by the middle layer.
The rule generator consists of templates written in Atlas Transformation Language [13] and Ant scripts [14]. The generated rules are specific to the application that the end user wants to parallelize and have the required C/C++ /MPI code constructs for parallelization. The code in the rules is in the form of the nodes of abstract syntax tree so that the SSC, without any manual intervention, can analyze and transform the sequential application into a parallel one. The glue code, also written as Ant scripts, is responsible for invoking the SSC and for making the generated (transformed) code available to the end user. A detailed discussion of the middle layer and back end can be found in Reference 12.
The design templates that are a part of FraSPA are codified design patterns for interprocess communication, data distribution, and synchronization. FraSPA automatically selects the best design template during the parallelization process on the basis of the Hi-PaL specifications. The parallel application thus generated can be compiled and run like any manually written parallel application.
The Hi-PaL syntax is influenced by the syntax of aspect-oriented programming (AOP) languages [15]. Similar to AOP languages, even with Hi-PaL, the end user should specify the places in the sequential application, known as hooks, where the changes in the structure or behavior of the code is desired. The definition of the hook should include the specification of hook type and hook element. There are three types of hooks —before, after, and around—and there are three types of hook elements—statement, function call, and function execution. Along with a hook, a search pattern (a statement in the sequential application) is also required. Every syntactically correct statement in a sequential application can qualify as a search pattern in Hi-PaL. The hooks are nothing but anchors in existing sequential applications before, after, or around (implies instead of), which the code for parallelization should be woven. For example, if in a hook definition the hook element is a statement in a program and hook type is around, then the program statement serving as a hook will get replaced with code for parallelization.
In addition to the hook, the end user is also required to provide the specifications related to the data mapping in the parallel version of the existing application. The mapping of data arrays to the memories of the processors is known as data mapping. The choice of data mapping can impact the performance of an application [5]. Some examples of the data distribution schemes are block (or linear) and cyclic [16]. In block distribution, each processor gets a contiguous block of data, whereas in cyclic distribution, the assignments are done in a round-robin fashion. For example, if there are two processors (p0, p1), and one has to divide 100 iterations of a for-loop among them using block distribution, then one processor (p0) works on iterations 0‒50, and the other processor (p1) works on iterations 51‒100. In cyclic distribution, one process (p0) could be working on all even-numbered iterations, whereas the second processor (p1) could be working on all odd-numbered iterations.
In order to succinctly obtain the end-user specifications regarding parallel operations, a set of Hi-PaL API was developed [5, 17]. An excerpt of the Hi-PaL API is shown in Fig 11.2. Also shown in the figure is a brief description associated with each API, that is, the type of MPI routine or the code for parallelization that is associated with the API. The API names are descriptive enough so that the end user can get an idea about their purpose by reading the name. For example, the API, AllReduceSumInt(<variable name>), means that the value of the variable specified by <variable name> is of type integer and it should be collected (or reduced) from all processes, and the global sum of the collected values (MPI_SUM operation) should be returned to all processes.
| HI_PaL API | Description |
| ReduceSumInt(<variable name>) | MPI_Reduced with sum operation |
| ReduceMin ValInt(<variable name>) | MPI_Reduced with min operation |
| ReduceMaxInt(<variable name>) | MPI_Reduced with Max operation |
| AllReduceSumInt(<variable name>) | MPI_AllReduced with Sum operation |
| ParDistributeVectorInt(<vecter name>, <num of rows>) | MPI_Scatterv to distribute the vector |
| ParGather2DArrayInt(<Array name>, <num of rows>, <num of colums>) | MPI_Gatherv to collect the data |
| ParBrodCast2DArrayInt(<array name>, <num of rows>, <num of colums>) | MPI_Bcast to collect the data |
| ParExchange2DArrayInt(<array name>, <num of rows>, <num of colums>) | Exchange neighboring values in stencil-based computations |
| Parallelize_for_Loop where(<for_int_stmt>;<condation>;<stride>) | Parallelize for-loop with matching initialization statement, condition, and stride |
FIGURE 11.2. Excerpt of the Hi-PaL API. Reprinted with kind permission from Springer Science + Business Media: R. Arora, P. Bangalore, and M. Mernik, Raising the level of abstraction for developing message passing applications, The Journal of Supercomputing, 59(2):1079‒1100, 2012.
Parallel section begins after("t1 = gettime();")
mapping is Linear{
ParBroadCast2DArrayDouble(popCurrent, M, N)
after statement ("popCurrent = mutation(popCurrent, ..);")
in function("main")
FIGURE 11.3. Sample Hi-PaL code showing the broadcast operation specifi cation.
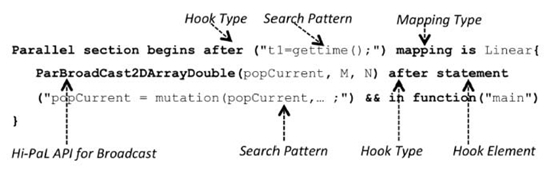
FIGURE 11.4. Mapping of Hi-code into structural elements.
Figure 11.3.shows a sample program written in Hi-PaL. This sample code demonstrates the method of specifying the broadcast operation on a matrix of type double and named popCurrent in function main. The standard structural elements shown in boldface (e.g., “Parallel section begins after”) are going to remain the same in all the Hi-PaL programs. By default, the hook element for specifying the beginning of a parallel section is a statement and, therefore, it is not required in the specification. Mapping of the Hi-PaL code in Figure 11.3. to the structural elements of Hi-PaL is shown in Figure 11.4. More examples of the usage of Hi-PaL are presented in Section 11.4.
11.4 EVALUATION OF FRASPA THROUGH CASE STUDIES
The applications generated through FraSPA were evaluated for performance, accuracy, and scalability by comparing them to their manually written counterparts. The framework itself was evaluated for the amount of effort involved in generating applications belonging to various domains. Two test cases (circuit satisfiability and Mandelbrot set) and the experimental setup for evaluating FraSPA are described in this section. The selected test cases had existing sequential and parallel implementations that were written manually in C/C++ /MPI. The existing sequential applications were used to embed the code for parallelization such that the generated parallel versions had communication patterns similar to their manually written counterparts. The selected test cases demonstrated that FraSPA is application domain neutral, reduces the programmer effort through code reuse, and reduces the application development time by reducing the number of lines of code (LoC) that the programmer has to write.
TABLE 11.1. Parallel Operations Applied on the Test Cases
| Test Case | Parallel Operation | Communication Pattern |
| Circuit satisfi ability Mandelbrot set | For-loop, reduce sum Distribute, gather | Parallel loop Manager‒worker |
For parallelizing the applications through FraSPA, the programmers should be familiar with the logic of the corresponding applications, must be aware of the hot spots for parallelization, and must express the specifications for the desired parallelization through Hi-PaL code. The programmer must then specify the places in the sequential application where code insertions need to be performed. A summary of parallel operations applied on the two test cases and the associated communication patterns are presented in Table11.1. The classification of test cases as per the communication pattern they exhibit is done according to the guidelines provided in Reference 18.
A brief description of some of the patterns codified in FraSPA are as follows:
- Embarrassingly Parallel. This pattern describes the concurrent execution of a collection of independent tasks (having no data dependencies). Implementation techniques include parallel loops and manager-worker.
- Parallel Loop. If the computation fits the simplest form of the pattern such that all tasks are of the same size and are known a priori, then they can be computed by using a parallel loop that divides them as equally as possible among the available processors.
- Manager‒Worker. Also known as task queue, this pattern involves two sets of processors—manager and worker. There is only one manager that creates and manages a collection of tasks (task queue) by distributing it among the available workers and collecting the results back from them.
- Mesh. Also known as “stencil-based computations,” this pattern involves a grid of points in which new values are computed for each point in the grid on the basis of the data from the neighboring points in the grid.
- Pipeline. This pattern involves the decomposition of the problem into an ordered group of data-dependent tasks. The ordering of tasks does not change during the computation.
- Replicable. This pattern involves multiple sets of operations that need to be performed using a global data structure and hence having dependency. The global data are replicated for each set of operations, and after the completion of operations, the results are reduced.
11.4.1 Circuit Satisfiability
This is an embarrassingly parallel application adapted from Michael Quinn's book on parallel programming [19]. The application determines whether a combination of inputs to the circuit of logical gates produces an output of 1 by performing an exhaustive search of all the possible combinations of the specified number of bits in the input. For example, for a circuit having N bits of input, the search space would involve 2N combinations of the bits or 2N possibilities. A code snippet from the sequential version of the application is shown in Figure 11.5.

FIGURE 11.5. Code snippet from the sequential circuit satisfiability application. .

FIGURE 11.6. Hi-PaL code for parallelizing the circuit satisfiability application.
The for-loop on lines 6‒13 of Figure 11.5. has computations that can be done in parallel such that the individual results of the computation done on multiple processes can be combined by means of a reduce operation. The programmer expresses the intention of parallelizing the computation in the for-loop beginning at line 6 of Figure 11.5, and collects the results with a reduce operation before line 14 of Figure 11.5. via the Hi-PaL code shown in Figure 11.5. As can be noticed from the code in Figure 11.5. the programmer also specifies the region in the sequential code from where the parallel section should begin, which is after the statement on line 3 of Figure 11.6. In Hi-PaL, the && operator is used to create powerful match expressions that can constrain the code transformation process (see Figure 11.6). If the programmer had not included the constraints on for-loop parallelization (see line 2 of Figure 11.6. after statement ("high = pow(2, n);") && in function ("main")), then every for-loop in the program with matching conditions and stride (i = low;i<high; i++) will get parallelized. The code snippet of the generated parallel code is shown in Figure 11.7. Though not shown in the snippet, the code for all the required variables, API, and files to include (e.g., mpi.h and design templates) will be automatically inserted in the generated parallel code.

FIGURE 11.7. Code snippet from the generated parallel circuit satisfi ability application.
11.4.2 Mandelbrot Set
The Mandelbrot set is a commonly used example from the domain of complex dynamics and it involves fractals [20]. Generation of this set involves iteratively solving an equation of complex numbers. Any number belonging to the Mandelbrot set is depicted in colors, whereas the numbers that do not belong to the set are colored as white. The code snippet of the sequential version of the Mandelbrot set generation application is shown in Figure 11.8; the Hi-PaL code for parallelizing the same is shown in Figure Figure 11.9; and the generated parallel code is shown on Figure 11.10. This test case involves the distribution and gathering of data in a two -dimensional array, and as can be noticed in Figure 11.10, the generated code has calls to function templates for splitting and gathering the data in the two-dimensional array (lines 35 and 46, respectively).
11.4.3 Evaluation and Experimental Setup
All the experiments for this research were run on a 128-node dual-processor Xeon cluster. Each node in this cluster has 4 GB of RAM and a low-latency InfiniBand network. FraSPA was evaluated according to the following criteria:

FIGURE 11.8. Code snippet of the sequential Mandelbrot set application.

FIGURE 11.9. Hi-PaL code for parallelizing the Mandelbrot set.
- performance and accuracy of the generated versions of the parallel code versus their manually written counterparts
- the number of LoC that the programmer has to write in C/C++ /MPI in order to parallelize an application versus the number of lines of Hi-PaL code the programmer has to write for parallelizing the application
- the number of LoC that were generated by the framework in order to parallelize the applications.
11.4.4 Results and Analysis
The runtime and speedup of the manually written parallel code was compared with the runtime and speedup of the code generated through the framework. The results are shown in Table 11.2. and Table 11.3. A summary of the problem size and the execution time for different versions (sequential, manually written parallel, and generated parallel) of all the test cases is presented in Table 11.4. Each application was run on different numbers of processors to test if they are scalable. No significant loss in performance was observed in any test case and the results from the generated version were almost identical to that of the manually written version. A comparison of the number of LoC that the end user has to write when using FraSPA and when developing the parallel application manually is presented in Table 11.5. For all the test cases that we have considered to date, the performance of the generated application is within 5% of that of the manually written application.

FIGURE 11.10. Code snippet of the generated parallel Mandelbrot set.
TABLE 11.2. Runtime and Speedup for Circuit Satisfiability Application

TABLE 11.3. Runtime and Speedup for Mandelbrot Set Application

TABLE 11.4. Performance Comparison of Various Test Cases

TABLE 11.5. Comparing the LoC for various Test Cases

11.5 LESSONS LEARNED
FraSPA has helped us find affirmative answers to the questions that were raised in the introduction section. We were able to generate parallel programs that looked similar to their handwritten versions. The performance of the generated parallel programs was impressive and commensurate to the effort spent. The general lessons learnt during the process of developing FraSPA could be useful for building high-level abstractions in future undertakings. We summarize them as follows:
- The end-user interface should be kept intuitive and high level so that the learning curve is not steep. For example, choose API names that are descriptive andcloser to the jargon of the problem domain.
- The solution space is constantly evolving. Therefore, the framework should be designed such that new features can be added to it without modifying the existing features/code.
- A framework should not force its end users to modify their applications to conform to any generic interfaces.
- The end user should be able to comprehend the code generated by the framework so that they are able to map their specifications to the generated code and to modify their specifications, if need be, to get improved results.
11.6 RELATED WORK
On the basis of the literature review, a comparison of some of the high-level approaches for raising the level of abstraction of parallel programming is presented in this section. The comparisons are based on the following criteria: approaches that are language based, design pattern based, and those that support separation of sequential and parallelization concerns [5, 15].
Charm + + [21] is an explicit parallel language and adaptive runtime system that is based upon the object-oriented programming paradigm having its roots in C++ . The execution model of Charm + + is asynchronous and message-driven (or event-driven). The programmer must decompose the computation into small virtual message-driven processes called chares. The data mapping to processors, fault tolerance, and load balancing is done by the system. The programmer must also write an interface file to provide the methods of the chare object that can be invoked by other chare objects. The language can be used for writing multiple-instruction multiple-data (MIMD) parallel programs for both shared-memory and distributed-memory applications and handles the portability issues really well. This approach provides separation of sequential and parallel concerns and is best suited for applications meant to be written from scratch. A steep learning curve is associated with the usage of Charm + + .
Design Patterns and Distributed Process (DPnDP) [22] is a pattern-based system for developing parallel applications. It is extensible, flexible, and demonstrates the advantages of keeping the sequential and parallel concerns separate in an application (and thereby reducing code complexity) while promoting code reuse and correctness. The DPnDP system generates the code skeleton depending upon the parameters (e.g., master‒slave pattern and the number of processors) specified by the programmer. The programmer is then required to edit the generated files that contain code skeletons to insert the sequential entry procedures into the skeleton.
The MAP3S system [23] is also an extensible, flexible, and pattern-based system that demonstrates that generative pattern systems can be successfully implemented using the combination of MPI and C. The system uses customization and tuning parameters provided by the programmer to develop efficient parallel code templates. The programmer is also required to provide macros for packing the processing elements into MPI packets. However, low-level specifications, like the maximum size of packet that can be transmitted between the processors or the timing for synchronization, place the burden on the programmer to understand the limitations of the MPI.
SPIRAL [24] is a domain-specific library generation system that generates HPC code for selected domains (such as digital signal processing) using high-level specifications. In SPIRAL, an algorithm is captured at a high level and the executable is generated using rewrite systems. To select an optimal solution for a particular platform, SPIRAL uses a feedback mechanism to explore the solution space (set of candidate solutions).
Catanzaro et al. [25] are developing a set of DSLs for different application domains to simplify the process of developing applications for heterogeneous architectures. Their set of DSLs captures the domain-specific computations (for mesh-based partial differential equation (PDE), physics library PhysBAM, and machine learning), promises to deliver optimized parallel solutions, and seems to be suitable for applications that are to be written from scratch.
MapReduce [26] is a programming model developed at Google that is used for processing and generating large data sets. Programs written using MapReduce are automatically parallelized and executed on distributed-memory machines. The partitioning of the input data, scheduling the program's execution, handling machine failures, and managing the required intermachine communication are all done automatically. MapReduce, therefore, helps the programmers in utilizing the resources of a large distributed system without learning parallel programming.
Out of all the approaches discussed in this chapter, FraSPA is best suited for the scenarios in which the legacy applications already exist and the end users intend to transform these applications to parallelize them. Charm + + , DPnDP, MAP3S, and MapReduce are suitable for the scenarios in which the applications are being written from scratch. While FraSPA, Charm + + , and many other approaches are application domain neutral, MapReduce has limited functionality because all types of applications cannot be solved by the MapReduce algorithm. MapReduce is best suited for data-parallel applications that process vast amounts of data. Apart from MapReduce, SPIRAL and Catanzaro et al.'s work can also be classified as application domain specific. The approaches that support separation of sequential and parallel concerns to make code maintenance and code reuse easy are Charm + + , DPnDP, MAP3S, and FraSPA.
The approaches that are design pattern based are DPnDP, MAP3S, and FraSPA. Compared to DPnDP and MAP3S, FraSPA does not involve any intrusive reengineering of the existing code and the programmer is not required to specify any low-level parameters. Unlike SPIRAL, which generates optimized libraries, FraSPA generates complete parallel applications from existing sequential applications. However, in contrast to SPIRAL, currently, FraSPA does not support architecture specific optimizations for any particular domain.
Unlike the approach of Catanzaro et al., FraSPA is useful for synthesizing optimized parallel applications in a noninvasive and domain-neutral manner; that is, it can parallelize sequential applications from diverse domains. A single DSL is used to capture the specifications of parallel tasks per se (e.g., reduce data, gather data, and distribute data), and the end users are not required to specify their core computations in conformance to any standard interface.
11.7 SUMMARY
FraSPA brings performance and scalability to domain experts in the form of parallel computing without the need to learn low-level parallel programming or to do intrusive reengineering. FraSPA, therefore, raises the level of abstraction of the scientific application development process. It generates the desired code for parallelization for a wide range of applications using reusable code components, design templates, SSC, DSLs, and glue code. Design templates that are a part of FraSPA promote code reuse and code correctness. It increases programmer productivity in terms of the decrease in the number of LoC written manually. It also reduces the time to solution due to the reusable nature of its code components. FraSPA can be extended to provide support for additional functionality and helps in the incremental development of applications with multiple alternatives.
REFERENCES
[1] E. Joseph, C.G. Willard, D. Shaffer, A. Snell, S. Tichenor, and S. Conway, “Council on competitiveness study of ISVs serving the high performance computing market. Part A—Current market dynamics,” 2005. Available at http://www.compete.org.
[2] High Performance Computing Reveal, “Council on Competitiveness and USC-ISI Broad Study of Desktop Technical Computing End Users and HPC,” 2008. Available at http://www.compete.org.
[3] MPI Forum, The Message Passing Interface Standard. Available at http://mpi-forum.org.
[4] OpenMP Forum, The OpenMP API specification for parallel programming. Available at http://openmp.org/wp/.
[5] R. Arora, P. Bangalore, and M. Mernik, “Raising the level of abstraction for developing message passing applications,” The Journal of Supercomputing, 59 (2): 1079‒1100, 2012.
[6] F.P. Brooks, Jr., “No silver bullet essence and accidents of software engineering,” Computer, 20(4): 10‒19, 1987.
[7] P. Charles, C. Grothoff, V.A. Saraswat, C. Donawa, A. Kielstra, K. Ebcioglu, C. von Praun, and V. Sarkar, “X10: An object-oriented approach to non-uniform cluster computing,” OOPSLA 2005, pp. 519‒538.
[8] G. Steele, “Parallel programming and parallel abstractions in fortress,” Functional and Logic Programming, 8th International Symposium, LNCS 3945, p.1, 2006.
[9] K. Czarnecki and U. Eisenecker, Generative Programming: Methods, Tools, and Applications. New York: Addison-Wesley, 2000.pp. 1‒832.
[10] M. Mernik, J. Heering, and A.M. Sloane, “When and how to develop domain-specific languages,” ACM Computing Surveys, 37(4): 316‒344, 2005.
[11] I. Baxter, “Design maintenance systems,” Communications of the ACM, 35(4): 73‒89, 1992.
[12] S. Roychoudhury, F. Jouault, and J. Gray, “Model-based aspect weaver construction,”International Workshop on Language Engineering, 2007, pp. 117‒26.
[13] F. Jouault and I. Kurtev, “Transforming Models with ATL,” Model Transformations in Practice Workshop at MoDELS, 2005.
[14] Apache Ant. Available at http://ant.apache.org/.
[15] G. Kiczales, J. Lamping, A. Mendhekar, C. Maeda, C. Lopes, J.-M. Loingtier, and J. Irwin, “Aspect-oriented programming,” European Conference on Object-Oriented Programming, Springer-Verlag LNCS 1241, 1997, pp. 220‒242.
[16] C. Koelbel, D. Loveman, R. Schreiber, G. Steele, and M. Zosel, The High Performance Fortran Handbook. Cambridge, MA: MIT Press, 1993.
[17] Hi-PaL API. Available at http://www.cis.uab.edu/ccl/index.php/Hi-PaL.
[18] T.G. Mattson, B.A. Sanders, and B.L. Massingill, A Pattern Language for Parallel Programming, Addison Wesley Software Patterns Series, 2004.
[19] M. Quinn, Parallel programming in C with MPI and OpenMP. New York: McGraw-Hill, 2004.
[20] B. Wilkinson and M. Allen, Parallel Programming: Techniques and Applications Using Networked Workstations. Upper Saddle River, NJ: Prentice Hall, 1998.
[21] L.V. Kale and S. Krishnan, “CHARM + +: A portable concurrent object oriented system based on C++ ,” ACM SIGPLAN Notices, 28(10): 91‒108, 1993.
[22] D. Goswami, A. Singh, and B.R. Preiss, “Building parallel applications using design patterns,” inAdvances in Software Engineering: Topics in Comprehension, Evolution and Evaluation, pp. 243‒265. New York: Springer-Verlag, 2002.
[23] P. Mehta, J.N. Amaral, and D. Szafron, “Is MPI suitable for a generative design-pattern system?” Parallel Computing, 32(7-8): 616‒626, 2006.
[24] M. Puschel, J.M.F. Moura, J. Johnson, D. Padua, M. Veloso, B. Singer, J. Xiong, F. Franchetti, Y.V. Aca Gacic, K. Chen, R.W. Johnson, and N. Rizzolo, “SPIRAL: Code generation for DSP transforms,” IEEE, Special issue on Program Generation, Optimization, and Adaptation, 93(2): 232‒275, 2005.
[25] B. Catanzaro, A. Fox, K. Keutzer, D. Patterson, B.-Y. Su, M. Snir, K. Olukotun, P. Hanrahan, and H. Chafi, “Ubiquitous parallel computing from Berkeley, Illinois, and Stanford,” IEEE Micro, 30(2): 41‒55, 2010.
[26] J. Dean and S. Ghemawat, “MapReduce: Simplifed data processing on large clusters,” Communications of the ACM, 51(1): 107‒113, 2008.