
13
–––––––––––––––––––––––
Optimizing and TuningScientific Codes
Qing Yi
13.1 INTRODUCTION
Scientific computing categorizes an important class of software applications that utilize the power of high-end computers to solve important problems in applied disciplines such as physics, chemistry, and engineering. These applications are typically characterized by their extensive use of loops that operate on large data sets stored in multidimensional arrays such as matrices and grids. Applications that can predict the structure of their input data and access these data through array subscripts analyzable by compilers are typically referred to as regular computations, and applications that operate on unstructured data (e.g., graphs of arbitrary shapes) via indirect array references or pointers are referred to as irregular computations.
This chapter focuses on enhancing the performance of regular scientific computations through source-level program transformations, examples of which include loop optimizations such as automatic parallelization, blocking, interchange, and fusion/ fission, redundancy elimination optimizations such as strength reduction of array address calculations, and data layout optimizations such as array copying and scalar replacement. In addition, we introduce POET [1], a scripting language designed for parameterizing architecture-sensitive optimizations so that their configurations can be empirically tuned, and use the POET optimization library to demonstrate how to effectively apply these optimizations on modern multicore architectures.
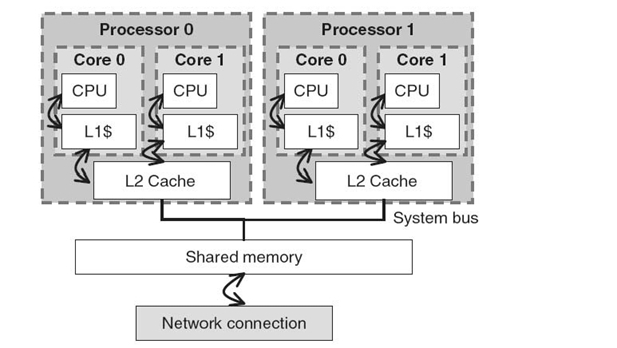
FIGURE 13.1. Intel Core2Duo architecture [37].
13.2 AN ABSTRACT VIEW OF THE MACHINE ARCHITECTURE
Figure 13.1 shows an abstract view of the Intel Core2Duo architecture, which includes two processors (processors 0 and 1), each with a private L2 cache while sharing a common system memory with the other via the system bus. Each processor, in turn, contains two CPU cores (cores 0‒1 and 2‒3), each core with a private CPU and L1 cache while sharing a common L2 cache with another core on the same processor. Most multicore computers today have an architecture similar to the one shown in Figure 13.1, although much larger numbers of processors and cores may be included. To achieve high performance on such machines, software must effectively utilize the following resources:
- Concurrent CPU cores, which require applications to be partitioned into mul tiple threads of computations so that different threads can be evaluated in parallel on different cores. Multithreading can be implemented using OpenMP [2] or various threading libraries such as Pthreads [3] and the Intel TBB [4] library.
- Shared memory, which requires that concurrent accesses to data shared by multiple threads be synchronized if the data could be modified by any of the threads. A variety of mechanisms, for example, locks and mutexes, can be used to coordinate global data accesses to shared memory. However, frequent syn chronizations are expensive and should be avoided when possible.
- The cache hierarchy, which requires that data accessed by CPU cores be reused in their private caches to reduce traffic to the main memory. The affinity of each thread with its data is critical to the overall performance of applications, as the cost of accessing data from shared memory or remote caches can be orders of magnitude slower than accessing data from a private L1 cache.
13.3 OPTIMIZING SCIENTIFIC CODES
The concept of performance optimization here refers to all program transformations that change the implementation details of a software application without affecting its higher-level algorithms or data structures so that the implementation details, for example, looping structures and data layout, can be more efficiently mapped to an underlying machine for execution. Such optimizations can be separated into two general categories: those targeting removing redundancies in the input code, for example, moving repetitive computations outside of loops, and those targeting reordering of operations and data to more efficiently utilize architectural components, for example, by evaluating operations in parallel on different CPUs. Redundancy elimination can improve performance irrespective of what machine is used to run the applications. In contrast, reordering optimizations are usually extremely sensitive to the underlying architecture and could result in severe performance degradation if miscon figured. This section summarizes important optimizations in both categories.
13.3.1 Computation Reordering Optimizations
Most scientific codes are written using loops, so the most important way to reorder their computation is through restructuring of loops. Here, each loop iteration is viewed as a unit of computation, and evaluation order of these units is reordered so that they collectively utilize the resources offered by modern architectures more efficiently. Among the mostly commonly used loop optimizations are loop interchange, fusion, blocking, parallelization, unrolling, and unroll & jam, illustrated in Figure 13.2 and summarized in the following. To ensure program correctness, none of these optimizations should violate any inherit dependences within the original computation [5].
13.3.1.1 Loop Interchange As illustrated in Figure 13.2b, where the outermost k loop at line 7 of Figure 13.2a is moved to the innermost position at line 9 in Figure 13.2b, loop interchange rearranges the order of nesting loops inside one another. After interchange, each iteration (kx, jx, ix ) of the original loop nest in Figure 13.2a is now evaluated at iteration (jx, ix, kx ) in Figure 13.2b. The transformation is safe if each iteration (kx, jx, ix ) in Figure 13.2a depends on only those iterations (ky, jy, iy )that satisfy ky ≤ kx, jy ≤ jx, iy ≤ ix, so that after interchange, iteration (jy, iy, ky ) is still evaluated before (jx, ix, kx) Figure 13.2b. Loop interchange is typically applied early as proper loop nesting order is required for the effectiveness of many other optimizations.
13.3.1.2 Loop Fusion As illustrated in Figure 13.2c, which fuses the two loop nests at lines 4 and 7 of Figure 13.2b into a single loop, loop fusion merges disjoint looping structures so that iterations from different loops are now interleaved. It is typically applied to loops that share a significant amount of common data so that related iterations are brought closer and are evaluated together, thereby promoting better cache and register reuse. After fusion, each iteration (jx, ix ) of the second loop nest at line 7 of Figure 13.2b is now evaluated before all iterations {(jy, iy ): jy > jx or (jy = jx and iy > ix)} of the first loop nest at line 4. Therefore, the transformation is safe if each iteration (jx, ix ) of the second loop nest does not depend on iterations (jy, iy ) of the first loop nest that satisfy the condition. Similar to loop interchange, loop fusion is applied early so that the merged loops can be collectively optimized further.

FIGURE 13.2 Applying loop optimizations to a matrix multiplication routine. (a) Original code. (b) Apply loop interchange to (a). (c) Apply loop fusion to (b). (d) Apply loop blocking + parallelization to (c). (e) Apply loop unrolling + unroll & jam to (c).
13.3.1.3 Loop Blocking Figure 13.2d shows an example of applying loop blocking to Figure 13.2c, where each of the three loops at lines 4, 5, and 7 of Figure 13.2c is now split into two loops: an outer loop, which increments its index variable each time by a stride of 32, and an inner loop, which enumerates only the 32 iterations skipped by the outer loop. Then, all the outer loops are placed outside at lines 5‒7 of Figure 13.2d so that the inner loops at lines 8, 9, and 12 comprise a small computation block of 32 * 32 * 32 iterations, where 32 is called the blocking factor for each of the original loops.
Loop blocking is the most commonly applied technique to promote cache reuse, where a loop-based computation is partitioned into smaller blocks so that the data accessed by each computation block can fit in some level of cache and thus can be reused throughout the entire duration of evaluating the block. The transformation is safe if all the participating loops can be freely interchanged.
13.3.1.4 Loop Parallelization When there are no dependences between different iterations of a loop, these iterations can be arbitrarily reordered and therefore can be evaluated simultaneously on different processing cores (CPUs). On a symmetric multiprocessor (SMP) architecture such as that in Figure 13.1, the parallelization can be expressed using OpenMP [2]. For example, the OpenMP pragma at line 4 of Figure 13.2d specifies that different iterations of the outermost j1 loop at line 5 can be assigned to different threads and evaluated in parallel, with each thread treating j1, i1, k1, j, i, and k as private local variables and treating all the other data as shared. At the end of the j1 loop, all threads are terminated and the evaluation goes back to sequential mode. To reduce the cost of thread creation and synchronization, it is economic to try to parallelize the outermost loop when possible for typical scientific computations.
13.3.1.5 Loop Unrolling and Unroll & Jam When the body of a loop nest contains only a small number of statements, for example, the loops in Figure 13.2a‒d, iterations of the innermost loop can be unrolled to create a bigger loop body, thus providing the compiler with a larger scope to apply back-end optimizations (e.g., instruction scheduling and register allocation). For example, the k loop at line 7 of Figure 13.2c is unrolled in Figure 13.2e at line 8, where the stride of the k loop in Figure 13.2c is increased from 1 to 4 in Figure 13.2e, and the skipped iterations are then explicitly enumerated inside the loop body at lines 9‒12 of Figure 13.2e. The number of iterations being unrolled inside the loop body is called the unrolling factor. Loop unrolling is typically applied only to the innermost loops so that after unrolling, the new loop body contains a long sequence of straight-line code.
A similar optimization called unroll & jam can be applied to unroll outer loops and then jam the unrolled outer iterations inside the innermost loop so that iterations of the outer loops are now interleaved with the inner loop to form an even bigger loop body. For example, the i loop at line 5 of Figure 13.2c is unrolled with a factor of 2 at line 5 of Figure 13.2e, and the unrolled iterations are jammed inside the k loop body at lines 13‒16. Loop unrolling is always safe. Loop unroll & jam, on the other hand, can be safely applied only when loop interchange is safe between the outer loop being unrolled and the inner loop being jammed. Loop unrolling is typically applied solely to increase the size of the loop body, while loop unroll & jam is applied to additionally enhance reuse of data within the innermost loop body.
13.3.2 Data Layout Reordering Optimizations
On a modern multicore architecture such as that illustrated in Figure 13.1, data structures need to be laid out in memory in a way where items being accessed close together in time have affinity in memory as well so that they can be brought to caches together in a group and would not evict each other from the caches. Since different regions of a program may access a common data structure (e.g., an array) in dramatically different orders, we consider an optimization called array copying, which dynamically rearranges the layout of array elements by copying them into a separate buffer. Allocating registers for selective array elements can be considered a special case of array copying [6] and is accomplished through an optimization called scalar replacement. Figure 13.3 illustrates the application of both optimizations.
13.3.2.1 Array Copying When a small group of consecutively evaluated statements access elements that are far away from each other in a array, the efficiency
of memory accesses can be improved by copying these elements into a contiguous buffer. Figure 13.2d illustrates such a situation, where each iteration of the innermost k loop at line 12 accesses an array a element that is n elements apart from the one accessed in the previous iteration. Figure 13.3a shows the result of applying the copying optimization to array a. Here, a new temporary array a_cp allocated at line 6 of Figure 13.3a is used to group all the array a elements accessed by iterations of the inner j, i, k loops at lines 8‒15 of Figure 13.2d into contiguous memory. Note that the size of a_cp is allocated to be a multiple of 32 * 32, the number of array a elements accessed by each of the computation blocks. The statements at lines 7-2 of Figure 13.3a then copy all the elements from the original a array to a different location in a_cp. Finally, lines 13‒24 contain the modified computation which accesses data from a_cp instead from the original array a. It is obvious that the array copying operations at lines 7‒12 will incur a significant runtime overhead. However, it is anticipated that the savings in repetitively accessing a_cp instead of a at lines 14‒24 will more than compensate the copying overhead. The assumption is not true for all architectures and input matrix sizes. Therefore, array copying need to be applied with caution to avoid slowdown of the original code.

Figure 13.3 Applying data layout optimizations to Figure 13.2. (a) Apply array copy to Figure 13.2d. (b) Apply scalar replacement to Figure 13.2e.
13.3.2.2 Scalar Replacement While copying a large amount of data can be expensive, copying repetitively accessed array elements to registers is essentially free and can produce immense performance gains. Since register allocation is typically handled by back-end compilers that do not keep arrays in registers, array elements need to be first copied to scalar variables to be considered later for register promotion. The optimization is called scalar replacement, and Figure 13.3b illustrates the result of using scalars to replace the elements of arrays C and B accessed by loops j and k in Figure 13.2e. Here, lines 7‒8 of Figure 13.3b use c0 and c1 to save the values of c [j * n + i] and c [j * n + i + 1], respectively, and lines 10‒13 use b 0−b 3 to save the values of b [j * n + k] through b[j * n + (k + 3)], respectively. Lines 14‒21 then use the new scalars instead of the original array elements to perform relevant computation. Finally, the values of c0and c1 are saved back to array c at lines 23‒24. Although scalar replacement presumably has no runtime overhead, when overly applied, it could create too many scalar variables and could overwhelm the back-end compiler register allocation algorithm into generating inefficient code. Therefore, it needs to be applied cautiously and preferably based on empirical feedbacks.
13.3.3 Redundancy Elimination
Most of the optimized codes in Figure 13.2 and Figure 13.3 contain long expressions used as subscripts to access array elements. Repetitive evaluation of these expressions can be prohibitive if not properly managed. The key insight of redundancy elimination optimizations is that if an operation has already been evaluated, do not evaluate it again, especially if the operation is inside multiple nested loops. The optimizations are typically applied only to integer expressions that do not access data from arrays, by completely eliminating redundant evaluations, moving repetitive evaluations outside of loops, and replacing expensive evaluations with cheaper ones, illustrated in Figure 13.4 and summarized in the following.

FIGURE 13.4. Examples of applying redundancy elimination optimizations. (a) Original code. (b) Redundant evaluation elimination. (c) Loop-invariant code motion. (d) Strength reduction for A + i * M and B + i*M. (e) Strength reduction for A + i*M + j and B + i*M + j.
13.3.3.1 Eliminating Redundant Evaluations If an expression e has already been evaluated on every control-flow path leading to e from the program entry, the evaluation can be removed entirely by saving and reusing the result of the previous identical evaluations. As an example, Figure 13.4a shows a simple C routine where the expression i * M + j is evaluated twice at every iteration of the surrounding i and j loops. The second evaluation of i * M + j can be eliminated entirely by saving the result of the first evaluation, as shown in Figure 13.4b.
13.3.3.2 Loop-Invariant Code Motion In Figure 13.4b, the result of evaluating i * M never changes at different iterations of the j loop. Therefore, this loop-invariant evaluation can be moved outside of the j loop, as shown in Figure 13.4c. In general, if an expression e is evaluated at every iteration of a loop, and its evaluation result never changes, e should be moved outside of the surrounding loop so that it is evaluated only once. The underlying assumption is that, at runtime, the loop will be evaluated more than once. Since the assumption is true for the majority of loops in software applications, loop-invariant code motion is automatically applied extensively by most compilers.
13.3.3.3 Strength Reduction Many expressions inside loops are expressed in terms of the surrounding loop index variables, similar to the expressions A + i * M + j and B + i * M + j in Figure 13.4a. When the surrounding loops increment their index variables each time by a known integer constant, the cost of evaluating these expressions can be reduced via an optimization called strength reduction. Figure 13.4d shows an example of applying strength reduction to optimize the evaluation of A + i * M + j and B + i * M + j in Figure 13.4 a. Here, the two array pointers, A and B, are incrementally updated at every iteration of the i loop instead of reevaluating A + i * M at every iteration, shown in Figure Figure 13.4b. Similarly, instead of evaluating A + j at every iteration of the j loop, we can perform another strength reduction optimization by incrementing A with 1 at every iteration of the j loop. The result of this optimization is shown in Figure 13.4e. Strength reduction is a highly effective technique and is frequently used by compilers to reduce the cost of evaluating subscripted addresses of array references, such as those in Figures 13.2 and 13.3.
13.4 EMPIRICAL TUNING OF OPTIMIZATIONS
Many of the loop and data layout optimizations in Sections 13.3.1 and 13.3.2 are extremely sensitive to the underlying architectures. As the result, it is difficult to predict how to properly configure these optimizations a priori.
A better approach is to parameterize their configurations and to try to evaluate the efficiency of differently optimized code using a set of representative input data. Proper optimization configurations can then be determined based on the experimental data collected. This approach is referred to as empirical tuning of optimization configurations.
POET [1] is an open-source interpreted program transformation language designed to support flexible parameterization and empirical tuning of architecture-sensitive optimizations to achieve portable high performance on varying architectures [1]. Figure 13.5 shows its targeting optimization environment, where an
optimizing compiler named ROSE analysis engine [7] or a computational specialist (i.e., an experienced developer) performs advanced optimization analysis to identify profitable program transformations and then uses POET to extensively parameterize architecture-sensitive optimizations to the input code. This POET output can then be ported to different machines together with the user application, where local POET transformation engines empirically reconfigure the parameterized optimizations until satisfactory performance is achieved.
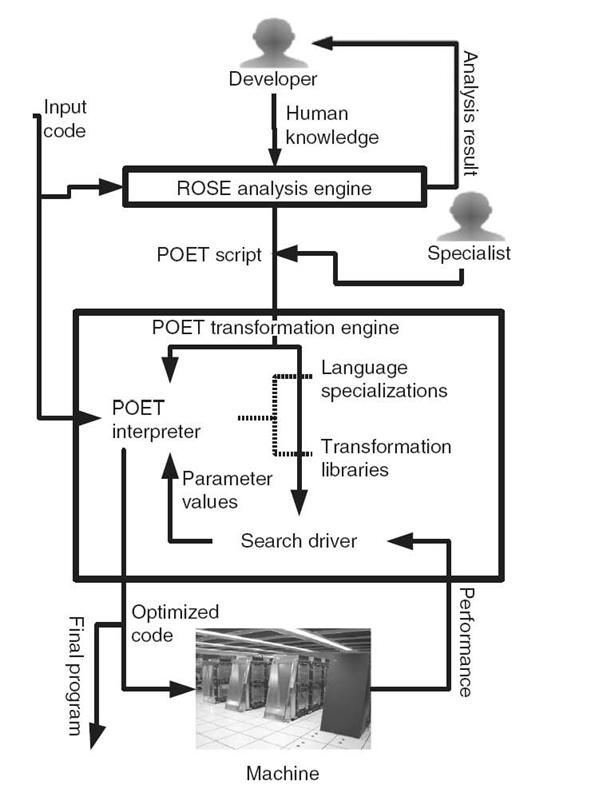
FIGURE 13.5. Optimization environment.
13.4.1 The POET Language
Table 13.1 provides an overview of the POET language, which includes a collection of atomic and compound values to accurately represent the internal structure of arbitrary input codes, systematic variable management and control flow to build arbitrary program transformations, and special-purpose concepts to support dynamic parsing of arbitrary programming languages, effective tracing of optimized codes, and flexible composition of parameterized transformations. Figure 13.6 shows an example of using these components in a typical POET script.
Table 13.1. Overview of the POET Language [1]



FIGURE 13.6. An example illustrating the overall structure of a POET file.
13.4.1.1 The Type System POET supports two types of atomic values: integers and strings. Two Boolean values, TRUE and FALSE, are provided but are equal to integers 1 and 0, respectively. Additionally, it supports the following compound types:
- Lists. A POET list is a singly linked list of arbitrary values and can be constructed by simply enumerating all the elements. For example, (a ≤ b) produces a list with three elements, a, “< = ,” and b. Lists can be dynamically extended using the:: operator at line 12 of Table 13.1.
- Tuples. A POET tuple contains a finite sequence of values separated by commas. For example, (i, 0, m, 1) constructs a tuple with four values, i, 0, m, and 1. A tuple cannot be dynamically extended and is typically used to group multiple parameters of a function call.
- Associative Maps. A POET map associates pairs of arbitrary values and is constructed by invoking the MAP operator at line 4 of Table 13.1. For example, MAP{3 = > “abc” } builds a map that associates 3 with abc. Associative maps can be dynamically modified using assignments, shown at line 21 of Table 13.1.
- Code Templates. A POET code template is a distinct user-defined data type and needs to be explicitly declared with a type name and a tuple of template parameters, shown at lines 2‒5 of Figure 13.6, before being used. It is similar to the struct type in C, where template parameters can be viewed as data fields of the C struct. A code template object is constructed using the # operator at line 5 of Table 13.1. For example, Loop #(i, 0, N, 1) builds an object of the code template Loop with (i, 0, N, 1) as values for the template parameters.
- Xform Handles. Each POET xform handle refers to a global xform routine, which is equivalent to a global function in C. It is constructed by following the name of the routine with an optional list of configurations to set up future invocations of the routine, shown at line 6 of Table 13.1. Each xform handle can be invoked with actual parameters just like a function pointer in C.
13.4.1.2 Variables and Control Flow POET variables can hold arbitrary types of values, and their types are dynamically checked during evaluation to ensure type safety. These variables can be separated into the following three categories:
- Local variables, whose scopes are restricted within the bodies of individual code templates or xform routines. For example, at lines 2‒13 of Figure 13.6, i, start, stop, step are local variables of the code template Loop, and list, result, and p_list are local variables of the xform routine ReverseList. Local variables are introduced by declaring them as parameters or by simply using them in the body of a code template or xform routine.
- Static variables, whose scopes are restricted within an individual POET file and can be used freely within the file without explicit declaration. For example, at line 20 of Figure 13.6, both backward and succ are file-static variables, which are used to store temporary results across different components of the same file.
- Global variables, whose scopes span across all POET files being interpreted. Each global variable must be explicitly declared as a macro (e.g., the OPT_STMT variable declared at line 14 of Fig. 13.6), a command-line parameter (e.g., inputFile, inputLang, and outputFile declared at lines 15‒17), or a tracing handle (e.g., inputCode declared at line 18).
In summary, only global variables need to be explicitly declared. All other identifiers are treated as local or static variables based on the scopes of their appearances unless an explicit prefix, for example, GLOBAL, CODE, or XFORM, is used to qualify the name as a global macro, a code template, or a xform routine, respectively. An example of such qualified names is shown at line 14 of Figure 13.6.
POET variables can be freely modified within their scopes using assignments, shown at line 20 of Table 13.1. Additionally, global macros can be modified through the define command illustrated at line 14 of Figure 13.6; command-line parameters can be modified through command-line options; and tracing handles can be modified implicitly by POET special-purpose operators and thus can be used by POET library routines to directly modify their input data structures (for more details, see Section 13.4.2.2).
As summarized in lines 20‒35 of Table 13.1 and illustrated in lines 6‒13 of Figure 13.6, POET program transformations are defined as xform routines, which can use arbitrary control flow such as conditionals, loops, and recursive function calls; can build compound data structures such as lists, tuples, hash tables, and code templates; and can invoke many built-in operations (e.g., pattern matching, replacement, and replication) to modify the input code. The full programming support for defining arbitrary customizable transformations distinguishes POET from most other existing special-purpose transformation languages, which rely on template-or pattern-based rewrite rules to support definition of new transformations.
13.4.1.3 The Overall Structure of a POET Script Figure 13.6 shows the typical structure of a POET script, which includes a sequence of include directives (line 1), type declarations (lines 2‒13), global variable declarations (lines 14‒18), and executable commands (lines 19‒21). The include directives specify the names of other POET files that should be evaluated before the current one and thus must appear at the beginning of a POET script. All the other POET declarations and commands can appear in arbitrary order and are evaluated in their order of appearance. Comments (see lines 2 and 6 of Fig. 13.6) can appear anywhere.
POET supports three global commands, input, eval, and output, summarized in Table 13.1 at lines 39‒41 and illustrated in Figure 13.6 at lines 19‒21. The input command at line 19 of Figure 13.6 parses a given file named by inputFile using the language syntax file inputLang and then stores the parsed internal representation of the input code to variable inputCode. The eval command at line 20 specifies a sequence of expressions and statements to evaluate. Finally, the output Command at line 21 writes the transformed inputCode to an external file named by outputFile.
Most POET expressions and statements are embedded inside the global eval commands or the bodies of individual code templates or xform routines. Most POET expressions are pure in that unless tracing handles are involved, they compute new values instead of modifying existing ones. POET statements, as shown at lines 20‒27 of Table 13.1, are used to support variable assignment and program control flow. Except for loops, which always have an empty value, all the other POET statements have values just like expressions. When multiple statements are composed in a sequence, only the value of the last statement is returned.
13.4.2 Using POET to Support Optimization Tuning
POET provides a library of routines to support many well-known source-level optimizations to achieve high performance for scientific codes on modern architectures. A subset of these routines is shown in Table 13.2, which can be invoked by an arbitrary POET script with command-line parameters so that their configurations
can be empirically tuned based on the runtime performance of differently optimized codes. Figure 13.9 illustrates such an example, which optimizes the matrix‒matrix multiplication kernel in Figure 13.7 through the following steps.
- Include the POET opt library (line 1); declare command-line parameters (lines 2‒10) and tracing handles (lines 11‒12); specify input code to optimize (line 13).
- Declare macros to configure the library (lines 14‒19); invoke library routines to optimize the input code (lines 20‒29); specify where to output result (line 30).
The following sections explain these components in more detail.
TABLE 13.2 Selected Optimization Routines Supported by the POET Opt Library
| Interface | Sematics | Configuration Parameters |
| permute Loops[order = 0] (n, x) Fuse Loops(n, x) |
permute loops between n and x Fuse loops in n to replace x |
O: loop nesting order |
| Block Loops[factor = f] (n, x) | Block loops in between n and x |
f: blocking factors |
| parallelize Loop[threads = t; private = p; reduction = r] (x) |
parallelize loop x using open MP pragma |
p/r;private vars;r: reduction vars;t: number of threads to run x |
| unroll Loop[factor = u](x) | unroll Loop x | u: unrolling factor |
| unroll Jam[factor = u](n, x) | unroll loops in between n and x;jam the unrolled loops inside n |
u: unrolling factors |
| clean up Blocked Nests (x) | cleanup loops in x after blocking /unrolling has been applied |
|
| copy Repl [init_loc = i; save_loc = s; delete_ loc = d; permute = p] (a, n, x |
copy data referenced by a via surrounding loops n;replace references inside x with copied data |
i/s/d: where to initialize/ save/delete buffer;p: permute loops in n during copy |
| Scalar Repl [ [init_loc = i; save_loc = s] (a, n, x) |
Replace data referenced by a via loops n with saclars in x |
i/s: where to initialize/ save scalars vars |
| Finite Diff[exp_type = t] (e, d, x)) |
Reduce the cost of evaluating e + d in input code x |
t: expression type |
| TraceNested Loops)(h, x) | Modify tracing handles in h to contain nested in x | |

FIGURE 13.7. An example POET input code with embedded annotations.
13.4.2.1 Tagging Input Code for Optimization POET is language neutral and uses syntax specifications defined in external files to dynamically process different input and output languages. For example, the input command at line 13 of Figure 13.9 specifies that the input code should be read from a file named “dgemm_test.C ” and then parsed using C syntax defined in file “Cfront.code.”
POET supports automatic tracing of various fragments of the input code as they go through different transformations by tagging these fragments with tracing handles inside comments of the input code. As illustrated in Figure 13.7, each POET tag either starts with “//@” and lasts until the line break, or starts with “/*@” and ends with “@*/. ” A single-line tag applies to a single line of program source and has the format = >x = T, where T specifies the type of the tagged code fragment and x specifies the name of the tracing handle used to keep track of the fragment. A multiline tag applies to more than one lines of program source and has the format BEGIN(x = T). For example, line 4 of Figure 13.7 indicates that the tracing handles nest1 should be used to trace the fragment starting from the for loop and lasting until the code template Nest (i.e., the whole loop nest) has been fully parsed (i.e., until line 10).
13.4.2.2 Tracing Optimizations of the Input Code Each POET script may apply a long sequence of different optimizations to an input code and can specify a large number of command-line parameters to dynamically reconfigure its behavior, as illustrated in lines 2‒10 of Figure 13.9. POET provides dedicated language support to automatically trace the modification of various code fragments to support extremely flexible composition of parameterized optimizations so that their configurations can be easily adjusted [1].
In order to trace transformations to an input code, a POET script needs to explicitly declare a group of special global variables as tracing handles, as illustrated in lines 11‒12 of Figure 13.9. These tracing handles can be used to tag the input code, illustrated in Figure 13.7, so that after successfully parsing the input file, they are embedded inside the internal representation, named abstract syntax tree (AST), of the input code. Figure 13.8 illustrates such an AST representation of the input code in Figure 13.7 with embedded tracing handles. Here, since tracing handles are contained as an integral component of the input code, they can be automatically modified by routines of the POET optimization library even when the optimization routines cannot directly access them through their names.
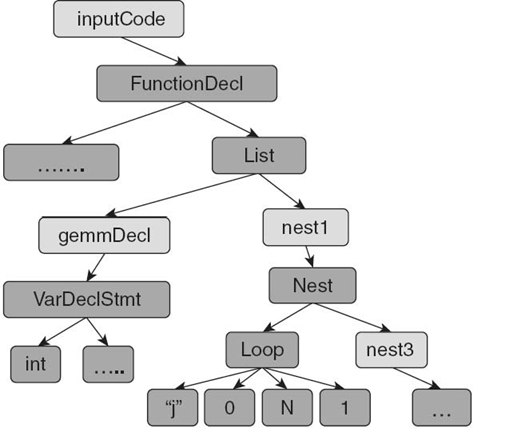
Figure 13.8 AST representation of Figure 13.7.

Figure 13.9. A POET script for optimizing Figure 13.7.
13.4.2.3 Composing Parameterized Optimizations In Figure 13.9, lines 14‒29 illustrate how to apply six heavily parameterized optimizations: OpenMP parallelization (lines 20‒21), cache blocking (line 23), copying of array A (line 24), loop unroll & jam (line 26), loop unrolling (line 27), and scalar replacement (line 28), to the matrix multiplication code in Figure 13.7. Each optimization is implemented via simple invocations of POET opt library routines defined in Table 13.2, with tuning parameters of each routine controlled command-line parameters. Finally, line 29 explicitly invokes the CleanupBlockedNexts routine in Table 13.2 to clean up any inefficiencies produced by the previous optimizations.
In Figure 13.9, in spite of the heavy parameterization, each optimization is specified independently of others with minimal configuration, although any of the previous optimizations could be turned on or off via command-line parameters. This flexibility is supported by the declaration of several tracing handles at lines 11‒12. In particular, the tracing handles inputCode, decl, nest1, nest3, and nest2 are used to track various fragments of the input code and have been used to tag the input code in Figure 13.7; nest1_private is used to track thread-local variables when parallelizing nest1; and A_ref is used to track the expression used to access array A. At lines
14‒19, these handles are set as values of various configuration macros of the POET opt library so that they are automatically modified by all the opt library routines to reflect changes to the input code. The semantics of these configuration macros are defined in Table 13.3. Through these macros, although each optimization is identified independently based on the original source code in Figure 13.7, the transformation remains correct irrespective of how many other optimizations have been applied, as long as each optimization uses these tracing handles as input and configuration parameters and then modifies them accordingly afterward. A POET script can also directly modify tracing handles as it transitions from one optimization to another. For example, in Figure 13.9, line 22 modifies nest1 so that if OpenMP parallelization has been applied, later optimizations are applied to the sequential computation block within each thread. Similarly, if cache blocking has been applied, line 25 modifies nest1, nest3, and nest2 so that later register-level optimizations are applied to the inner computation block.
TABLE 13.3 Macro Configurations Supported by the POET Opt Library
| TRACE_DECL | Tracing handle for inserting all variable declarations |
| TRACE_INCL | Tracing handle for inserting all header file inclusions |
| TRACE_VARS | Tracing handle for inserting all the new variables created |
| TRACE_TARGET | Tracing handle for inserting all modifications to the input code |
| TRACE_EXP | Tracing handle for inserting expressions used in optimizations |
| ARRAY_ELEM_TYPE | The element type of all arrays being optimized |
13.4.2.4 Correctness and Efficiency of Optimized Code When using POET to optimize the source code of an input program, the correctness of optimization depends on two factors: whether the POET optimization library is correctly implemented and whether the library routines are invoked correctly in the user-specified POET script. If either the library or the optimization script has errors, the optimized code may be incorrect. An optimizing compiler, for example, the ROSE analysis engine in Figure 13.5, can ensure the correctness of its auto-generated POET scripts via conservative program analysis. For user supplied POET scripts, additional testing can be used to verify that the optimized code is working properly. Therefore, each optimized code should be tested for correctness before its performance is measured and used to guide the empirical tuning of optimization configurations.
13.4.3 Empirical Tuning and Experimental Results
When used to support auto-tuning of performance optimizations, POET relies on an empirical search driver [8], shown in Figure 13.5, to automatically explore the optimization configuration space for varying architectures. Our previous work has developed POET scripts both manually [9, 10] and automatically through the ROSE loop optimizer [11]. For several linear algebra kernels, our manually written POET scripts have achieved similar performance as that achieved by manually written assembly in the widely used ATLAS library [12]. A sample of the performance comparison is shown in Table 13.4. More details of the experimental results can be found in Reference 10.
To illustrate the need for empirical tuning of optimization configurations, Figure 13.10 shows the performance variations of a 27-point Jacobi kernel when optimized with different blocking factors [9]. Here, the execution time ranges from 2.9 to over 12.0 seconds as the stencil kernel parallelized with a pipelining strategy utilizes machine resources with a variety of different efficiencies. It is typical for different optimization configurations, especially different blocking factors, to make an order of magnitude difference in performance with little predictability. Consequently, empirical tuning is necessary to automatically achieve portable high performance on varying architectures.
Table 13.4 Performance in Megaflops of Differently Optimized Matrix Multiplication Codes [10]
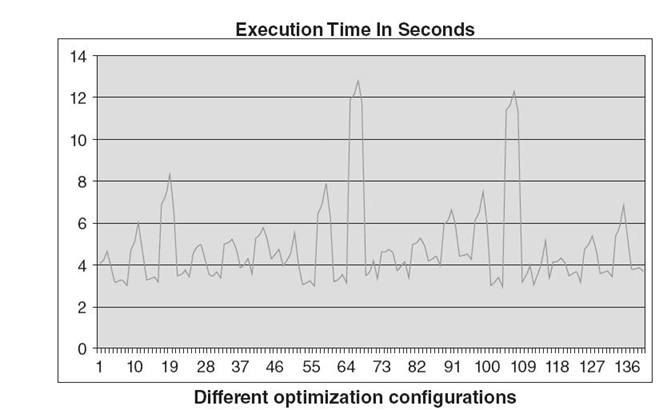
FIGURE 13.10. Performance of a 27-point Jacobi kernel when optimized with different blocking factors on an Intel Nehalem eight-core machine [9].
13.5 RELATED WORK
The optimization techniques discussed in Section 13.3 are well-known compiler techniques for improving the performance of scientific applications, [13‒19] and can be fully automated by compilers based on loop-level dependence analysis [5] or more sophisticated integer programming frameworks such as the polyhedral framework [20]. Our ROSE analysis engine in Figure 13.5 is based on an optimization technique called dependence hoisting [21], which does not use integer programming.
While we built our analysis engine within the ROSE compiler [22], other source-to-source optimizing compilers, for example, the Paralax infrastructure [23], the Cetus compiler [24], and the Open64 compiler [25], can be similarly extended to serve as our analysis engine.
POET is a scripting language that can be used by developers to directly invoke advanced optimizations to improve the performance of their codes [1, 10]. POET is designed with a focus to support flexible composition of parameterized optimizations so that their configurations can be experimented on the fly and empirically tuned. POET supports existing iterative compilation frameworks [26‒31] by providing a transformation engine that enables collective parameterization of advanced compiler optimizations. The POET transformation engine can be easily extended to work with various search and modeling techniques [30, 32‒34] in auto-tuning.
Besides POET, various annotation languages such as OpenMP [2] and the X language [35] also provide programmable control of compiler optimizations. The work by Hall et al. [36] allows developers to provide a sequence of loop transformation recipes to guide transformations performed by an optimizing compiler. These languages serve as a programming interface for developers to provide additional inputs to an optimizing compiler. In contrast, POET allows developers to directly control the optimization of their codes without relying on an existing optimizing compiler.
13.6 SUMMARY AND FUTURE WORK
As modern computer architectures evolve toward increasingly large numbers of power-efficient parallel processing cores, achieving high performance on such machines entails a large collection of advanced optimizations including partitioning of computation for parallel execution, enhancing data reuse within multiple levels of caches, reducing the synchronization or communication cost of accessing shared data, and carefully balancing the utilization of different functional units in each CPU. This chapter focuses on a number of critical optimization techniques for enhancing the performance of scientific codes on multicore architectures and introduces how to use the POET language to flexibly parameterize the composition of these optimizations so that their configurations can be empirically tuned. A survey of optimization techniques for high-performance computing on other modern architectures such as graphics processing units (GPUs), many-cores, and clusters is left to future work.
ACKNOWLEDGMENTS
This research is funded by National Science Foundation grants CCF0747357 and CCF-0833203, and Department of Energy grant DE-SC0001770.
REFERENCES
[1] Q. Yi, “POET: A scripting language for applying parameterized source-to-source program transformations,” in Software: Practice & Experience, 2011.
[2] L. Dagum and R. Menon, “OpenMP: An industry standard API for shared-memory programming,” Computational Science & Engineering, IEEE, 5 (1): 46‒55, 1998.
[3] B. Nichols, D. Buttlar, and J.P. Farrell, pthreads programming. Sebastopol, CA: O 'Reilly & Media, Inc., 1996.
[4] J. Reinders, Intel Threading Building Blocks, 1st ed. Sebastopol, CA: O'Reilly & Associates, Inc., 2007.
[5] R. Allen and K. Kennedy, Optimizing Compilers for Modern Architectures. Burlington, MA: Morgan Kaufmann, 2001.
[6] Q. Yi, “Applying data copy to improve memory performance of general array computations,” in LCPC '05: The 18th International Workshop on Languages and Compilers for Parallel Computing, Hawthorne, New York, October 2005.
[7] D. Quinlan, M. Schordan, Q. Yi, and S. Bronis, “Semantic-driven parallelization of loops operating on user-defined containers,” in LCPC '03: 16th Annual Workshop on Languages and Compilers for Parallel Computing, Lecture Notes in Computer Science, October 2003.
[8] S.F. Rahman, J. Guo, and Q. Yi, “Automated empirical tuning of scientific codes for performance and power consumption,” in HIPEAC '11: High-Performance and Embedded Architectures and Compilers, Heraklion, Greece, January 2011.
[9] S.F. Rahman, Q. Yi, and A. Qasem, “Understanding stencil code performance on multi-core architectures,” in CF '11: ACM International Conference on Computing Frontiers, Ischia, Italy, May 2011.
[10] Q. Yi and C. Whaley, “Automated transformation for performance-critical kernels,” in LCSD '07: ACM SIGPLAN Symposium on Library-Centric Software Design, Montreal, Canada, October 2007.
[11] Q. Yi, “Automated programmable control and parameterization of compiler optimizations,” in CGO '11: ACM/IEEE International Symposium on Code Generation and Optimization, April 2011.
[12] R.C. Whaley, A. Petitet, and J. Dongarra, “Automated empirical optimizations of software and the ATLAS project,” Parallel Computing, 27(1): 3‒25, 2001.
[13] S. Carr and K. Kennedy, “Improving the ratio of memory operations to floating-point operations in loops,” ACM Transactions on Programming Languages and Systems, 16(6): 1768‒1810, 1994.
[14] A. Cohen, M. Sigler, S. Girbal, O. Temam, D. Parello, and N. Vasilache, “Facilitating the search for compositions of program transformations,” in ICS '05: Proceedings of the 19th Annual International Conference on Supercomputing, pp. 151‒160, New York: ACM, 2005.
[15] M. Lam, E. Rothberg, and M.E. Wolf, “The cache performance and optimizations of blocked algorithms,” in Proceedings of the Fourth International Conference on Architectural Support for Programming Languages and Operating Systems(ASPLOS - IV), Santa Clara, April 1991.
[16] K. McKinley, S. Carr, and C. Tseng, “Improving data locality with loop transformations,” ACM Transactions on Programming Languages and Systems, 18(4): 424‒453, 1996.
[17] L.-N. Pouchet, C. Bastoul, A. Cohen, and N. Vasilache, “Iterative optimization in the polyhedral model: Part I, one-dimensional time,” in Proceedings of the International Symposium on Code Generation and Optimization, CGO '07, pp. 144‒156, Washington, DC, 2007. IEEE Computer Society.
[18] A. Tiwari, C. Chen, J. Chame, M. Hall, and J.K. Hollingsworth, “A scalable auto-tuning framework for compiler optimization,” in IPDPS '09: Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, pp. 1‒12, Washington, DC, 2009. IEEE Computer Society.
[19] M.J. Wolfe, “More iteration space tiling,” in Proceedings of Supercomputing, Reno, November 1989.
[20] U. Bondhugula, A. Hartono, J. Ramanujam, and P. Sadayappan, “A practical automatic polyhedral parallelizer and locality optimizer,” in Proceedings of the 2008 ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI '08, pp. 101‒113, New York: ACM, 2008.
[21] Q. Yi, K. Kennedy, and V. Adve, “Transforming complex loop nests for locality,” The journal of supercomputing, 27: 219‒264, 2004.
[22] M. Schordan and D. Quinlan, “A source-to-source architecture for user-defined optimizations,” in Joint Modular Languages Conference Held in Conjunction with EuroPar '03, Austria, August 2003.
[23] H. Vandierendonck, S. Rul, and K. De Bosschere, “The Paralax infrastructure: Automatic parallelization with a helping hand,” in Proceedings of the 19th International Conference on Parallel Architectures and Compilation Techniques, PACT '10, pp. 389‒400, New York: ACM, 2010.
[24] C. Dave, H. Bae, S.-J. Min, S. Lee, R. Eigenmann, and S. Midkiff, “Cetus: A source-to-source compiler infrastructure for multicores,” IEEE Computer, 42: 36‒42, 2009.
[25] J.N. Amaral, C. Barton, A.C. Macdonell, and M. Mcnaughton, Using the sgi pro64 open source compiler infra-structure for teaching and research, 2001.
[26] G. Fursin, A. Cohen, M. O 'Boyle, and O. Temam, “A pratical method for quickly evaluating program optimizations,” in HiPEAC, November 2005.
[27] T. Kisuki, P. Knijnenburg, M. O 'Boyle, and H. Wijsho, “Iterative compilation in program optimization,” in Compilers for Parallel Computers, pp. 35‒44, 2000.
[28] Z. Pan and R. Eigenmann, “Fast automatic procedure-level performance tuning,” in Proceedings of Parallel Architectures and Compilation Techniques, 2006.
[29] G. Pike and P. Hilfinger, “Better tiling and array contraction for compiling scientific programs,” in SC, Baltimore, MD, November 2002.
[30] A. Qasem and K. Kennedy, “Profitable loop fusion and tiling using model-driven empirical search,” in Proceedings of the 20th ACM International Conference on Supercomputing(ICS06), June 2006.
[31] M. Stephenson and S. Amarasinghe, “Predicting unroll factors using supervised classification,” in CGO, San Jose, CA, March 2005.
[32] C. Chen, J. Chame, and M. Hall, “Combining models and guided empirical search to optimize for multiple levels of the memory hierarchy,” in International Symposium on Code Generation and Optimization, March 2005.
[33] R. Vuduc, J. Demmel, and J. Bilmes, “Statistical models for automatic performance tuning,” International Journal of High Performance Computing Applications, 18(1): 65‒94, 2004.
[34] K. Yotov, X. Li, G. Ren, M. Garzaran, D. Padu, K. Pingali, and P. Stodghill, “A comparison of empirical and model-driven optimization,” in IEEE Special Issue on Program Generation, Optimization, and Adaptation, 2005.
[35] S. Donadio, J. Brodman, T. Roeder, K. Yotov, D. Barthou, A. Cohen, M.J. Garzar á n, D. Padua, and K. Pingali, “A language for the compact representation of multiple program versions,” in LCPC, October 2005.
[36] M. Hall, J. Chame, C. Chen, J. Shin, G. Rudy, and M.M. Khan. “Loop transformation recipes for code generation and auto-tuning,” in LCPC, October 2009.
[37] T. Tian, “Effective use of the shared cache in multi-core architectures,” Dr. Dobb's, January 2007.