
16
–––––––––––––––––––––––
Toward a Secure Fragment Allocation of Files in Heterogeneous Distributed Systems
Yun Tian, Mohammed I. Alghamdi, Xiaojun Ruan, Jiong Xie, and Xiao Qin
16.1 INTRODUCTION
16.1.1 Security Problems in Distributed Systems
An increasing number of scientific and business files need to be stored in large-scale distributed storage systems. The confidentiality of security-sensitive files must be preserved in modern distributed storage systems because such systems are exposed to an increasing number of attacks from malicious users [1].
Although there exist many security techniques and mechanisms (e.g., see Reference 2 and 3), it is quite challenging to secure data stored in distributed systems. In general, security mechanisms need to be built for each component in a distributed system, then a secure method of integrating all the components in the system can be implemented. It is critical and important to maintain the confidentiality of files stored in a distributed storage system when malicious programs and users compromise some storage nodes in the system.
In addition to cryptographic systems, secret sharing is an approach to providing data confidentiality by distributing a file among a group of n storage nodes, to each of which a fragment of the file is allocated. The file can be reconstructed only when a sufficient number (e.g., more than k) of the fragments are available to legitimate users. Attackers are unable to reconstruct a file using the compromised fragments when a group of servers are compromised if fewer than k fragments are disclosed.
16.1.2 Heterogeneous Vulnerabilities
In a large-scale distributed system, different storage sites use a variety of methods to protect data. The same security policy may be implemented in various mechanisms. Data encryption schemes may vary; even with the same encryption scheme, key lengths may vary across the distributed system. The above-mentioned factors can contribute to different vulnerabilities among storage sites. Although security mechanisms deployed in multiple storage sites can be implemented in a homogeneous way, different vulnerabilities may exist due to heterogeneities in computational units.
We started to address security heterogeneity issues by categorizing storage servers into different server-type groups. Each server type represents a level of security vulnerability. In a server-type group, storage servers with the same vulnerabilities share the same weaknesses that allow attackers to reduce the servers'information assurance. Although it may be difficult to categorize all servers in a system into a large number of groups, a practical way of identifying server types is to organize those with similar vulnerabilities into one group.
In light of server types and heterogeneous vulnerabilities, we investigated in this study a fragment allocation scheme called S-FAS to improve the security of a distributed system where storage sites have a wide variety of vulnerabilities.
16.1.3 File Fragmentation and Allocation
The file fragmentation technique is often used in distributed and parallel systems to improve availability and performance. Several file fragmentation schemes have been proposed to achieve high assurance and availability in large distributed systems [4, 5]. In real-world distributed systems, the fragmentation technique is usually combined with replication to achieve better performance at the cost of increased security risk to data stored in the systems. A practical distributed system normally contains multiple heterogeneous servers providing services with various vulnerabilities. Unfortunately, the existing fragmentation algorithms do not take the heterogeneity issues into account.
To address the aforementioned limitations, we focused on the development of a file fragmentation and allocation approach to improving the assurance and scalability of a heterogeneous distributed system. If one or more fragments of a file have been compromised, it is still very difficult and time-consuming for a malicious user to reconstruct the file from the compromised fragments. Our solution is different from those previously explored because it utilizes heterogeneous features regarding vulnerabilities among servers.
To evaluate our method for fragment allocations, we developed static and dynamic assurance models to quantify the assurance of a heterogeneous distributed storage system handling data fragments.
16.1.4 Main Contributions
The following are the main contributions of this study: We addressed the heterogeneous vulnerability issue by categorizing storage nodes of a distributed system into different server-type groups based on their vulnerabilities. Each server-type group represents a group of storage nodes with the same group of security vulnerabilities. We proposed a secure fragmentation allocation scheme called S-FAS to improve the security of a distributed system where storage nodes have a wide variety of vulnerabilities. We developed storage assurance and dynamic assurance models to quantify information assurance and to evaluate the proposed S-FAS scheme. We developed a secure allocation processing (SAP) algorithm to improve security and system performance by considering the heterogeneous feature of a large distributed system. We discovered principles to improve assurance levels of heterogeneous distributed storage systems. The principles are general guidelines to help designers achieve a secure fragment allocation solution for distributed systems. In order to conduct the performance analysis for the S-FAS scheme and SAP allocation algorithm, we developed a prototype for our S-FAS scheme.
16.1.5 The Organization of This Chapter
The rest of this chapter is organized as follows. In Section 16.2, we review related work. Section 16.3 presents the system and threat models of this study. Section 16.4 describes S-FAS—a secure fragmentation allocation scheme. In Section 16.5, we describe static and dynamic assurance models for distributed storage systems. In Section 16.6, the SAP allocation algorithm principles are presented, and the architecture and design of our prototype is illustrated. In Section 16.7, we quantitatively evaluate the assurance and do some performance analysis of the proposed S-FAS scheme combined with our proposed SAP algorithm in the context of distributed systems. Section 16.8 summarizes this chapter.
16.2 RELATED WORK
16.2.1 Security Techniques for Distributed Systems
Much research has been performed concerning the improvement of the security of distributed and high-performance computing systems such as grids. For example, Pourzandi et al. proposed a structured security approach that incorporates both distributed authentication and distributed access control mechanisms [1].
Intrusion detection techniques have been widely used to provide basic assurance of security in distributed systems; however, most intrusion detection techniques are inadequate to protect data stored in distributed systems [6]. One of the most effective approaches to improving information assurance in distributed systems is intrusion tolerance [5, 7]. To enhance security assurance, researchers have developed a range of intrusion-tolerant tools and mechanisms. The fragmentation technique summarized below is one of the intrusion tolerance methods that can be used in combination with intrusion detection techniques.
16.2.2 Fragmentation Techniques
A fragmentation technique partitions a security-sensitive file into multiple fragments that are distributed across different nodes in a distributed system. A lot of fragmentation schemes have proven to be valuable tools in the improvement of the security of data stored in distributed systems (e.g., see Reference 4 and 8‒12).
Many fragmentation approaches aim to improve the availability and performance of distributed systems by applying data replication methods. For example, Dabek et al. developed a wide-area cooperative storage system in which they implemented a fragmentation scheme to improve availability and to facilitate load balancing [13].
Although a scheme combining fragmentation and replication can enhance performance and availability, data replications may impose security risks due to an increasing number of file fragments handled by distributed storage servers. A file is more likely to be compromised when more replications of the file are stored in a distributed storage system.
All existing file fragmentation technologies are inadequate to address the issue of heterogeneous vulnerabilities in large-scale distributed systems. Our preliminary results show that security can be improved in a distributed storage system when a fragmentation scheme incorporates the heterogeneous vulnerability feature.
16.2.3 Secret Sharing
Secret sharing is a method of distributing a secret among a group of participants by allocating each a share of the secret. The secret can be successfully reconstructed only when a sufficient number of shares are combined together [11, 14]. Shamir proposed the (k, n) secret sharing scheme that divides data D into n pieces in such a way that D can be easily reconstructed from any k pieces. If fewer than k pieces are disclosed, the data cannot be reconstructed from the revealed pieces. The secret sharing scheme has been extended and employed in different application domains [15]. For example, Bigrigg et al. proposed an architecture called PASIS for secure storage systems. The PASIS architecture integrates the secret sharing scheme with information dispersal to improve security, integrity, and availability [16, 17]. In a storage system with PASIS, n the confidentiality of stored data in the system is still preserved even if an attacker compromises a limited (i.e., n fewer than the threshold) subset of storage nodes. The aforementioned secret sharing solutions designed for distributed storage systems ignore the issue of heterogeneous vulnerabilities. This fact motivated us to extend the secret sharing scheme by considering heterogeneity in vulnerabilities in the context of distributed storage systems.
16.2.4 Comparison of Our Work with Existing Solutions
The fragment allocation solution we describe in this chapter is entirely different from the existing fragment allocation schemes found in the literature. Our approach incorporates the vulnerability heterogeneity feature of distributed storage systems into file fragment allocation. Our solution captures heterogeneous features regarding vulnerabilities of the nodes in order to improve the security level of the data stored in a distributed system. In this study, the data replication technique is not considered because fragment allocation and data replication are independent of each other. Thus, n the availability and performance of fragment allocation schemes can be improved when data replication modules are integrated.
16.3 SYSTEM AND THREAT MODELS
In this section, we will outline the system and threat models that capture main characteristics of distributed storage systems. The system model is used as a basis to design the S-FAS fragmentation allocation scheme, whereas the threat model helps us identify vulnerabilities and certain potential attacks in distributed storage systems.
16.3.1 System Model
The S-FAS fragmentation allocation scheme was designed for a distributed storage system (see Fig. 16.1) where each storage site is a cluster storage subsystem. Different cluster storage subsystems may be connected within some subnetworks to form a larger-scale distributed storage sysytem. A cluster storage subsystem consists of a number of storage nodes and a gateway. Considering heterogeneous vulnerability in large-scale storage systems, we categorize storage nodes into different server-type groups.
Before presenting details on the system model, let us summarize all notations used throughout this chapter in Table 16.1.
In this study, we will consider a distributed storage system containing L cluster storage subsystems (i.e., R1, R2,…, RL). Cluster storage subsystem Ri consists of Hi storage nodes (i.e., Ri = {ri1, ri2,…, riHi}). All the storage nodes connected in cluster Ri have heterogeneous vulnerabilities.
Since all the nodes, including a master node, are fully connected in a cluster storage subsystem, we model the topology of a cluster storage system as a general graph. Cluster storage subsystem Ri has a gateway, which hides the cluster’s internal architecture from users by forwarding file requests to storage nodes.
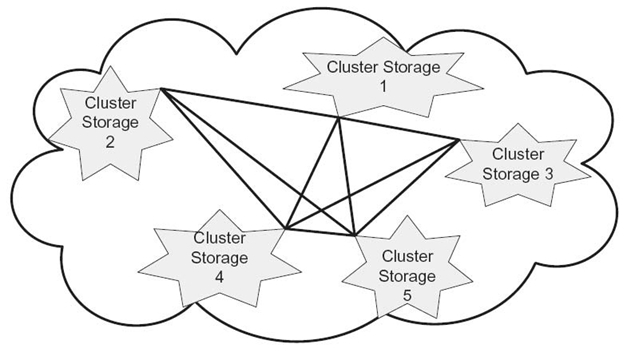
FIGURE 16.1. A distributed storage system is composed of a set of cluster storage subsystems. Multiple fragments of a file can be stored either in storage nodes within a single cluster storage subsystem or in nodes across multiple cluster storage subsystems.
TABLE 16.1. Notations
Data in cluster storage subsystem Ri can be accessed through its master node. When a read request is submitted to cluster Ri, the master node is responsible for reconstructing file fragments and for returning the file to users. When a write request of a file is issued, the master node updates all fragments of the file.
Legitimate users access cluster storage subsystems through master nodes; malicious users may bypass the master nodes to access storage nodes without being authorized. See Section 16.3.2 for details on the threat model.
16.3.2 Threat Model
It is not reasonable to assume that if a malicious user breaks into a storage node, fragments of a file stored on the node are thereby compromised. Normally, a malicious user requires two steps to compromise fragments of a file stored on a server. First, the malicious user must successfully compromise the server. Second, fragments are retrieved by the malicious user.
Let PN be the probability that a storage server is successfully attacked; let Pf be the probability that authorized users retrieve fragments stored on the server, provided that the server has been compromised. We define event Z as a successful attack on a fragment (i.e., unauthorized disclosure of the fragment). Since the above two consecutive attack steps are independent, the probability that event Z occurs is a product of probability PN and probability Pf. Thus, the probability that a fragment is disclosed to an unauthorized attacker can be expressed as
Given two storage nodes with different vulnerabilities, successful attacks of the nodes are not correlated. This statement is true for many potential threats, because compromising one storage node does not necessarily lead to the successful attack of another.
16.4 S-FAS: A SECURE FRAGMENT ALLOCATION SCHEME
In this section, we first outline the motivation for addressing the heterogeneity issues in the vulnerability of distributed storage systems. Next, we describe a security problem addressed in this study. Last, we present a secure fragment allocation scheme called S-FAS for distributed storage systems.
16.4.1 Heterogeneity in the Vulnerability of Data Storage
Since the existing security techniques (see Section 16.2) developed for distributed systems are inadequate for distributed systems with heterogeneity in vulnerabilities, the focus of this study is heterogeneous vulnerabilities in large-scale distributed storage systems. Vulnerabilities of storage nodes in a distributed system are heterogeneous in nature due to the following four main reasons. First, storage nodes have different ways to protect data. Second, a security policy can be implemented in a variety of mechanisms. Third, the key length of an encryption scheme may vary across multiple storage nodes. Fourth, heterogeneities exist in computational units of storage sites. We believe that future security mechanisms for distributed systems must be aware of vulnerability heterogeneities.
16.4.2 A Motivational Example
If the above heterogeneous vulnerability features are not incorporated into fragment allocation schemes for distributed storage systems, a seemingly secure fragment allocation decision can lead to a breach of data confidentiality. The following motivational example illustrates a security problem caused by ignoring vulnerability heterogeneities.
Let us consider a file F with three partitioned fragments: fa, fb, and fc, and a distributed storage system (see Fig. 16.2a) that contains 16 storage nodes categorized into four server-type groups (or server groups for short), that is, T1, T2, T3, and T4. Storage nodes in each server group offer similar services with the same vulnerabilities. In this example, server group T1 consists of nodes r1, r5, r9, r13; that is, T1 = {r1, r5, r9, r13}. Similarly, we defi ne the other three server groups as T2 = {r2, r6, r10, r14}, T3 = {r3, r7, r11, r15}, and T4 = {r4, r8, r12, r16}.

FIGURE 16.2. A motivational example: (a) A distributed storage system contains 16 storage nodes, which are divided into four server - type groups, that is, T1, T2, T3, and T4;b) possible insecure file fragment allocation decision made using a hashing function (see equation 11 in Reference 4)
Figure 16.2b shows that it is possible to make insecure fragment allocation decisions when vulnerability heterogeneity is not taken into account. The decision made using a hashing function (see Equation 11 in Reference 4) randomly allocates the three fragments of file F to three different nodes, each of which belongs to one of the three server sets illustrated in Figure 16.2b. For example, the three fragments, fa, fb, and fc, are stored on nodes r1, r6, and r8, respectively. This fragment allocation happens to be a good solution because r1, r6, and r8 have different vulnerabilities as the three nodes belong to different server groups (i.e., T1, T2, and T4). A malicious user must launch at least three successful attacks (one for each server group) in order to compromise all three fragments.
The above fragment allocation scheme fails to address the threat described in Section 16.3. This is because an attacker can first retrieve one fragment of F by compromising a single node and then wait for the other two fragments to be passed through the compromised node. To solve this security problem, Zanin et al. developed a static algorithm to decide whether a particular storage node is authorized to handle a file fragment of F [17]. Zanin’s algorithm can generate an insecure fragment allocation because heterogeneous vulnerabilities are not considered. For example, if the three fragments are respectively stored on nodes r4, r8, and r12, which share the same vulnerability in server group T4 (see Fig. 16.2b), rather than three attacks, one successful attack against server group T4 allows unauthorized users to access the three fragments of file F. Two other insecure fragment allocations are (1) allocating fa, fb, fc to nodes r1, r5, and r9, respectively, and (2) allocating fa, fb, fc to nodes r7, r11, and r15, respectively. These three fragment allocation decisions are unacceptable because the fragments are assigned to a group of storage nodes with the same vulnerability, meaning that an attacker who comprised one node within a group can easily compromise the other nodes in the group. The attacker can reconstruct F from fa, fb, and fc stored on the comprised server group.
16.4.3 Design of the S-FAS Scheme
To solve the above security problem, we must incorporate vulnerability heterogeneities into fragment allocation schemes. Specifically, we designed a simple yet efficient approach to allocating fragments of a file to storage nodes with various vulnerabilities. Since allocating fragments of a file into different storage subsystems can degrade performance, our S-FAS scheme attempts to allocate fragments to storage nodes in as few clusters as possible. To improve the assurance of a distributed storage system while maintaining high I/O performance, each cluster storage subsystem must be built with high vulnerability heterogeneity. This causes the fragments of a file to be less likely distributed across multiple storage clusters.
Because of the following two reasons, the S-FAS scheme can significantly improve data security when fragments are stored in a large-scale distributed storage system. First, S-FAS integrates the fragmentation technique with secret sharing. Second, S-FAS addresses the issue of heterogeneous vulnerabilities when file fragments are allocated to a distributed storage system.
The S-FAS scheme makes fragment allocation decisions by following the four policies below:
- Policy 1. All the storage nodes in a distributed storage system are classified into multiple server-type groups based on their various vulnerabilities. Each server group consists of storage nodes with the same vulnerabilities.
- Policy 2. To improve the security of a distributed storage system, S-FAS allocates fragments of a file to storage nodes belonging to as many different server groups as possible. In doing so, it is impossible to compromise the file’s fragments using a single successful attack method.
- Policy 3. The fragments of a file try to be allocated to nodes within a wide range of vulnerabilities all within the fewest cluster storage subsystems which are close to clients. The goal of this policy is to improve the performance of the storage system by making the fragments less likely to be distributed across too many distant clusters.
- Policy 4. The (m, n)secret sharing scheme is integrated with the S-FAS allocation mechanism.
If a file’s fragment allocation decisions are guided by the above four policies, successful attacks against less than m server groups have little chance of gaining unauthorized accesses to files stored in a distributed system. In other words, if the number of compromised fragments of a file is less than m, attackers are unable to reconstruct the file from the fragments that are accessed by the unauthorized attackers. The S-FAS scheme can improve information assurance of files stored in a distributed storage system without enhancing confidentiality services deployed in cluster storage subsystems of the distributed system because S-FAS is orthogonal to security mechanisms that provide confidentiality for each server group in a distributed storage system. Thus, S-FAS can be seamlessly integrated with any confidentiality service employed in distributed storage systems in order to offer enhanced security services.
16.5 ASSURANCE MODELS
We developed assurance models to quantitatively evaluate the security of a heterogeneous distributed storage system in which S-FAS handles fragment allocations.
16.5.1 Storage Assurance Model
For encrypted files, their encryption keys are partitioned and allocated using the same strategy that handles file fragments. Once a storage node in set U is compromised, file fragments and encryption key fragments stored on the node are both breached. If a malicious user wants to crack a file, at least m nodes within U must be successfully hacked.
We first investigate the probability that a file is compromised using one attack method. Let X be the event that a set of storage nodes is chosen to be attacked. Let Y be the event that if X occurs, at least m fragments can be compromised using the same attack method. As we have already defined in Section 16.3, event Z represents a successful attack to a certain fragment of a file. Applying the multiplication principle, we calculate the probability that V—an event that file F is compromised under one attack—occurs as
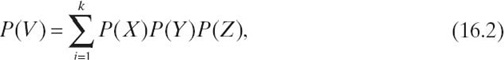
where P(X), P(Y), and P(Z) are probabilities that events X, Y and Z occur when the total number of different server-type groups (server group for short) is K. The probability P(V) is proportional to probability P(Z), which largely depends on the quality of security mechanisms deployed in the storage system, as well as the attacking skills of hackers.
Note that when k equals 1, there is no vulnerability difference among storage nodes. Supposing that all the fragments of a file can be compromised using one successful attack method, the probability that Y occurs becomes 1. Then, we can express P(V) as

Let Sj be the number of storage nodes in server type Tj set and N be the total number of nodes in a distributed system. The probability that nodes in set Tj are randomly attacked can be derived as P(X) = Sj /N.
Probability P(Y) in Equation (16.2) can be calculated as follows:
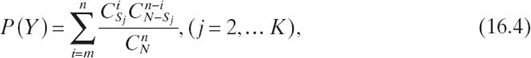
where CnN is the total number of possibilities of allocating fragments of a file, and the product of CiSj and Cn-iN-Sj is the number of possibilities that a file is compromised using a successful attack method, which means at least m (it may be m + 1, m + 2,…, n) fragments of the file are compromised.
To simplify the model, one may assume that security mechanisms and attacking skills have no significant impacts on information assurance of the entire distributed storage system. This assumption is reasonable because of two factors. First, S-FAS is independent of security mechanisms that provide confidentiality for server groups in a distributed storage system. Second, if empirical studies can provide values for probability P(Z), the probability P(V) can be derived from P(Z) and the model (see Equation 16.4) that calculates P(Y). Since the study of the distribution of P(Z) is not within the range of this work, in Section 16.7, the impact of probability P(Z) on P(V) is ignored by setting the value of P(Z) to 1. Now we can derive Equation (16.5) from Equation (16.4) as
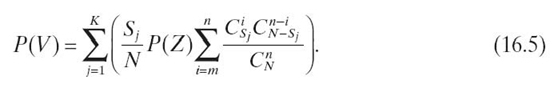
The confidentiality of file F is assured if F is not compromised. Thus, we can derive the assurance SA(α) of the storage system from Equation (16.5) as
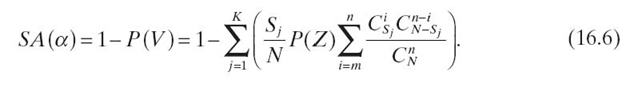
16.5.2 Dynamic Assurance Model
During read and write operations, some fragments of a file may be transmitted among different storage clusters or subnetworks. We assume that data transmissions within a cluster are secure, while connections among clusters and subnetworks may be insecure. Let PL be the probability that a fragment is intercepted during its transmission on an insecure link. We consider a common case in which some fragments of file F are allocated outside a cluster. The probability PD that a fragment of F is intercepted during its transmission can be expressed as
where µ1 = 1 indicates that connections among storage clusters are insecure and µ1 = 0 means the connections are secure. µ2 = 1 indicates that fragments are transferred among different clusters; otherwise, µ2 = 0. Similarly, µ3 = 1 means that fragments are transmitted across different subnetworks. When µ1, µ2, and µ3 equal 0, there is no fragment transmission risk. If q fragments need to be collected outside a cluster processing read/write operations, then probability Pq(g) that g out of q fragments are intercepted can be expressed as
Now we model the dynamic assurance of an allocation mapping α of file F. For simplicity, let us focus on a time period during which there is only one attempt to attack storage nodes where F is stored. During this time period, we assume that only one read or write operation is issued to access F. There are two cases in which file F can be compromised. First, a malicious user can reconstruct F from m compromised fragments using the same attack method. Second, although less than m fragments are compromised, other g fragments are intercepted during their transmissions. Hence, we can derive the dynamic assurance DA(α) (Equation 16.9) from the storage risk (see Equation 16.5) and the transmission risk (see Equation 16.8), as shown here:
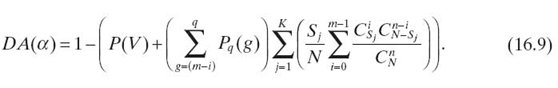
16.6 SAP ALLOCATION PRINCIPLES AND PROTOTYPE
We developed a prototype using the multithreading technique for the SAP algorithm to guide the file allocation. We then conducted some experiments to evaluate the performance of SAP integrated in the S-FAS scheme. Results show that the proposed solution can not only improve the storage security level but can also enhance the throughput of the distributed storage system with heterogeneous vulnerabilities.
16.6.1 Allocation Principles
The design of our S-FAS scheme is mainly focused on the improvement of system security. Considering the heterogeneity of the system can also be used to improve system performance, we developed a SAP algorithm for the S-FAS scheme to improve the security level and considered its performance using the heterogeneous feature of a large distributed system. The SAP allocation algorithm, a key compoment, addresses the issues of load balancing, delayed effects caused by the workload variance of many consecutive requests [18, 19], and the heterogeneous feature of distributed storage systems.
There are three main factors affecting the processing delay of a request from a client, namely, workload, network traffic, and I/O latency at storage nodes. In our algorithm design, we consider load balacing among storage nodes and network interconnects to improve the system performance. Initially, all nodes are logically categorized into different types based on the similarities of their vulnerabilities. The basic principles of the SAP allocation algorithm are described below:
- to sort the two-dimensional list Iij of file (i) fragments (j) in a decreasing order based on the burdens of the input files
- to sort all storage nodes in a two-dimensional list in a decreasing order based on their vulnerability type and processing speed
- to allocate each fragment in list Iij to storage nodes.
There are two constraints used when deciding whether a fragment should be allocated to a node: (1) There is enough space to store the fragment; and (2) the available LoadB is higher than 80% (the upper bound of the storage load can be adjusted to a different level to control the storage space efficiency on a server) of the LoadB of the current fragment.
It is possible that fragments of a file can be allocated in the same type of nodes. Nevertheless, the chances of allocating multiple fragments of a file to nodes of the same type is much less than those in the random allocation scheme.
16.6.2 Prototype Architecture and Design
In order to evaluate the S-FAS scheme along with the SAP algorithm, we designed and implemented a prototype to test system throughput on a distributed storage testbed. We applied the multithreading technique, allowing one thread to process one request of fragment read/write to enhance processing performance.
In the implimentation of the prototype, system nodes are divided into three main groups—computing nodes (clients), storage nodes, and a storage server. The storage server is responsible for handling file allocation using the SAP algorithm, managing the metadata and dealing with the incoming read or write requests from the clients. The storage nodes are categorized into a few groups based on their heterogeneous vulnerability features. The client nodes can directly access storage servers through the network interconnect.
16.7 EVALUATION OF SYSTEM ASSURANCE AND PERFORMANCE
The assurance models described in Section 16.5 indicate that system assurance is affected by the K number of storage types, the N number of storage nodes in the system, and the Sj number of nodes of the jth storage type. In addition, threshold m and the n number of fragments of a file also have an impact on system assurance.
In this section, we will first evaluate the impact of these factors (K, N, Sj, n, and m ) on storage assurance (see Sections 16.7.1‒16.7.5). We will compare our approach with a traditional fragment allocation scheme that does not consider vulnerability heterogeneities. Then, we will measure dynamic assurance of S-FAS to analyze the impact of PL and q on system dynamic assurance (see Sections 16.7.6 and 16.7.7). We will evaluate a distributed storage system with the threshold value m. The default n number of fragments of a file is set to 12 (the value can vary according to system sizes) and Sj = N/K for all j from 1 to K.
In the last part of this section, we will discuss experimental results for the SAP algorithm and the prototype. To explore the affecting factors that influence the system performance, we will evaluate the impact of the file size and fragment number on system throughput (see Section 16.7.8).
16.7.1 Impact of Heterogeneity on Storage Assurance
If all storage nodes in the evaluated distributed system are identical in terms of vulnerability, the probability that fragments of a file can be compromised using one successful attack method is 1. Figure 16.3 shows the impact of the K number of storage types on system assurance. The results plotted in Figure 16.3 suggest that, for a distributed system with homogeneous vulnerability, threshold m has no impact on system assurance. For a distributed system with heterogeneous vulnerabilities, the system assurance increases significantly with increasing values of K and threshold m (see Figure 16.3). Such a trend implies that a high heterogeneity level of vulnerability gives rise to high confidentiality assurance.
16.7.2 Impact of System Size on Storage Assurance
To quantify the impact of system size N on the assurance of a file stored in the system, we gradually increase the system size from 45 to 70 by increments of 5. We keep k at 3 and also vary m from 4 to 8. Figure 16.4 reveals that the storage assurance of the system is not very sensitive to the system size, indicating that storage assurance largely depends on the vulnerability heterogeneity level rather than on system size. Thus, large-scale distributed storage systems with low levels of vulnerability heterogeneities may have lower assurance than small-scale distributed systems. These results suggest that one way to improve system assurance is to increase vulnerability heterogeneity while increasing the scale of a distributed storage system. A high heterogeneity level in vulnerability helps in increasing threshold m, making it difficult for attackers to compromise multiple server groups and to reconstruct files.
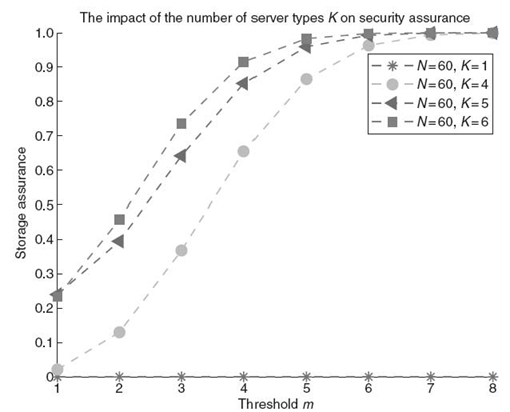
FIGURE 16.3. A Heterogeneous system and homogeneous system using the secret sharing scheme.
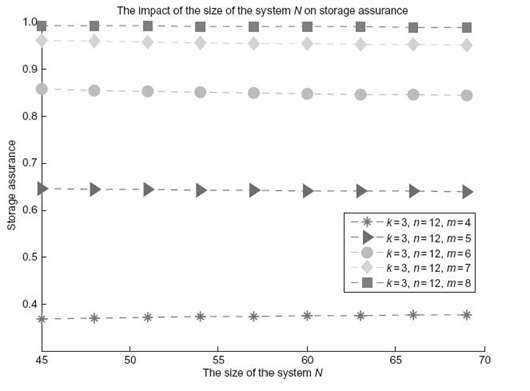
FIGURE 16.4. The impact of the system size N on storage assurance.
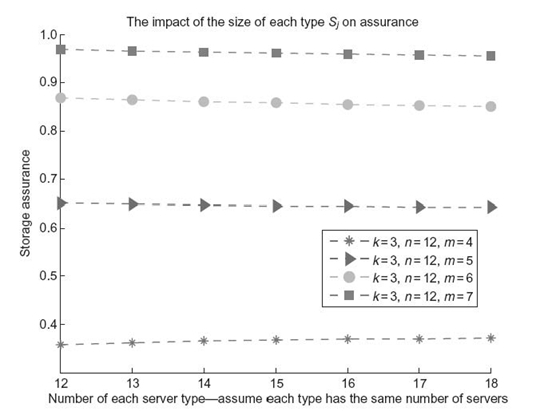
FIGURE 16.5. The impact of server-group size on data storage assurance. The server-group size means the number of storage nodes in a server-type group.
16.7.3 Impact of Size of Server Groups on Storage Assurance
Figure 16.5 illustrates the impact of server-group size on data storage assurance. Note that the server-group size is the number of storage nodes in a server-type group, in which all the storage nodes share the same group of vulnerabilities. We vary the server-group size from 12 to 18 by increments of 1. We observe from Figure 16.5 that, when threshold m is small (e.g, m = 4), the assurance of systems with large server-group sizes is slightly higher than that of systems with small server-group sizes. Interestingly, the opposite is true when the threshold m is large (e.g, m > 4). Given a fixed number of storage nodes in a distributed storage system, increasing the server-group size can decrease the number of server groups, which in turn tends to reduce vulnerability heterogeneity. The results shown in Figure 16.5 match the results in the previous experiments in which a low level of vulnerability heterogeneity results in degraded storage assurance.
16.7.4 Impact of n Number of File Fragments on Storage Assurance
Figure 16.6 illustrates the impact of the n number of fragments of a file on storage assurance. In this experiment, we increased the n number of fragments from 11 to 20 and measured data storage assurance using our model. The parameters k and N were set to 3 and 75, respectively. We also varied threshold m from 4 to 7. Results depicted in Figure 16.6 confirm that the system assurance is reduced with the increasing value of fragment number n. The results indicate that a large number of file fragments leads to low data storage assurance of the file. This assurance trend is reasonable because more fragments are likely to be allocated to storage nodes with the same vulnerability. If one storage node is compromised by an attacker, fragments stored on nodes with the same vulnerabilities can also be obtained by the attacker, who is therefore more likely to be able to reconstruct the file from the disclosed fragments.
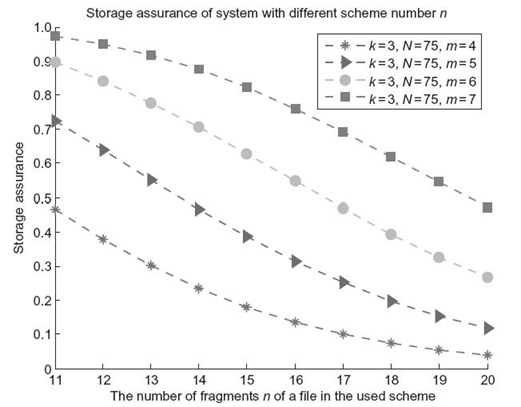
FIGURE 16.6. The impact of the number n of fragments of a fi le on storage assurance.
In addition, Figure 16.6 shows that increasing the value of threshold m can improve storage assurance. This pattern is consistent with the results obtained in the previous experiments.
16.7.5 Impact of Threshold m on Storage Assurance
Figure 16.3 –16.6 clearly show the impact of threshold m on the storage assurance of a distributed system. More specifically, regardless of other system parameters, the storage assurance always goes up with the increasing threshold value m. The results indicate that the more fragments an attacker needs in order to reconstruct a file, the higher data storage assurance can be preserved for the file in distributed storage systems. These results suggest that to improve the data storage assurance of a file, one needs to partition the file and to allocate fragments in such a way that an attacker must compromise more server groups (the best case is m server groups when all fragments of the file are allocated to nodes of different server types) in order to reconstruct the file.
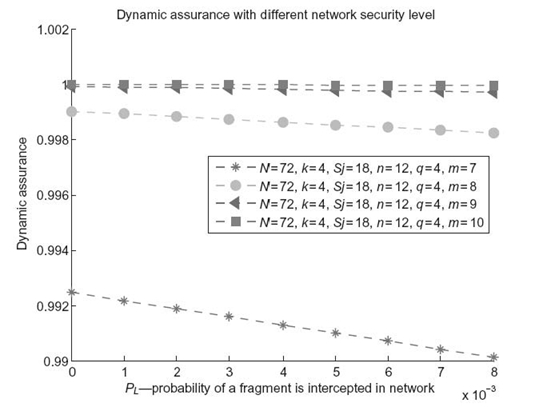
FIGURE 16.7. Impact of PL (the probability that a fragment might be intercepted by an attacker during the fragment´s transmission).
16.7.6 Impact of PL on Dynamic Assurance
Now we are in a position to evaluate the dynamic assurance of distributed storage systems. The three parameters µ1, µ2, and µ3in Equation (16.7) have an important impact on dynamic assurance because they indicate whether there is risk during fragment transmission. Please refer to Sections 16.7.1–16.7.5 for details on the impacts of a set of parameters on data storage assurance. PL—the probability that a fragment might be intercepted by an attacker during the fragment’s transmission through an insecure link—has a noticeable impact on the dynamic assurance of a distributed storage system provided that threshold m is small (e.g., smaller than 9). Figure 16.7 shows the dynamic assurance of a distributed system when PL is varied from 0 to 8×10-3 by increments of 1×10-3. We also vary threshold m (i.e., m is varied from 7 to 10) to evaluate the sensitivity of dynamic assurance on parameter PL under different threshold m.
Figure 16.7 demonstratively confirms that when threshold m is equal to or smaller than 8, a large value of PL results in low dynamic assurance of the system. These results are expected since a high value of PL means that the transmitted fragments are likely to be intercepted by an attacker. Once the attacker has collected enough fragments of a security-sensitive file, the file can be reconstructed. When threshold m is larger than 8, the dynamic assurance is not noticeably sensitive to the probability PL that a fragment is compromised during its network transfer.
16.7.7 Impact of q on Dynamic Assurance
Like parameter PL, the q number of fragments transmitted to and from a storage cluster also has an impact on the dynamic assurance of a distributed storage system. Intuitively, Figure 16.8 shows that, when the number of fragments of a file that must be transmitted through insecure links is increasing, the dynamic assurance of the file drops. Interestingly, when threshold m is larger than 8, the dynamic assurance becomes very insensitive to the number q of fragments. This observation suggests that, when the threshold is small, the S-FAS fragment allocation scheme must specifically attempt to lower the value of q in order to maintain a high dynamic assurance level.
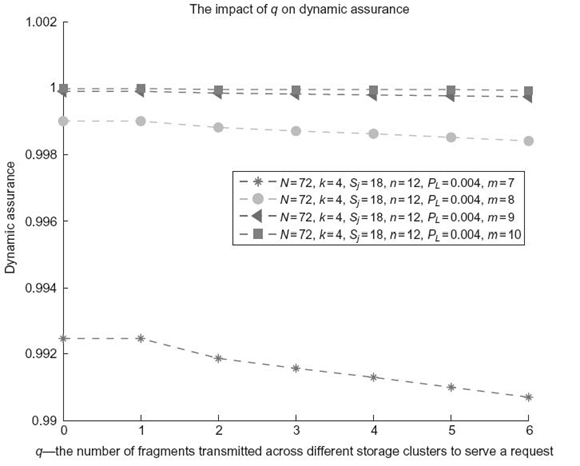
FIGURE 16.8. Impact of q(q fragments transmitted across storage clusters.)
In addition, we observe from Figure 16.8 that dynamic assurance is always lower than the corresponding storage assurance (where q = 0 in Figure 16.8). This trend is always true because in a dynamic environment, file fragments have to be transmitted through insecure network links where malicious users may intercept the fragments in order to reconstruct files.
16.7.8 Performance Evaluation of S-FAS
We made use of the prototype to evaluate the performance of S-FAS. We conducted some experiments by varying two parameters that noticeably affect both security and performance. We conducted an experiment to test the file allocation process by varying the workload and fragment number of the S-FAS scheme as described in the following:
- File Size. In our experiments, the test file size is varied from 950 MB (996,147,200 bytes) to 2300 MB(2,411,724,800 bytes). The details can be seen in the corresponding figures.
- Fragment Number of a File. We varied the fragment number from 3 to 15. We set the upper bound to less than 16 since we have 16 storage nodes in our test bed, and the S-FAS performs better when one storage node stores one fragment of a file at most.
Figure 16.9a plots the impact of the allocating file size on the throughput of S-FAS. From Figure 16.9a, we observe that the S-FAS scheme improves the throughput compared to the traditional nonfragmented storage method. Because we use the multithreading method to deal with the fragments of a file in the S-FAS scheme, the system performance is significantly improved in our scheme. The other trend we can observe from Figure 16.9a, a is that, with the increasing of file sizes, the system throughput first increases and then decreases after the file size is larger than 1.2 GB. This trend applies to S-FAS and the non-S-FAS schemes. When file size is relatively small, the throughput increases with the increasing of the file size. The reason is that the load is still below the upper bound of the system peak performance. This experiment for high-performance distributed storage systems suggests that implementing the S-FAS scheme using the multithreading method is very important.
Figure 16.9b shows the impact of the fragment number on the throughput. Figure 16.9b shows that the throughput goes up when the fragment number is increased in the S-FAS scheme. Because we use one thread to deal with one fragment of a file in the S-FAS scheme, the performance is improved with the increasing number of the fragments. The throughput does not noticeably change when the number of fragments is anywhere between 7 and 11 because we set the thread number equal to 8. When a file has more than eight fragments, the first eight fragments are concurrently processed by the multithreads, while the other fragments are waiting to be served. We can conclude from Figure 16.9a, b that using the multithreading method can improve the throughput compared with the traditional scheme.
16.8 CONCLUSION
It is critical to maintain the confidentiality of files stored in a distributed storage system, even when some storage nodes in the system are compromised by attackers. In recognizing that storage nodes in a distributed system have heterogeneous vulnerabilities, we investigated a secure fragment allocation scheme by incorporating secret sharing and heterogeneous vulnerability to improve the security of distributed storage systems.
We addressed the security heterogeneity issue by categorizing storage servers into different server-type groups (or server group for short), each of which represents a level of security vulnerability. With heterogeneous vulnerabilities in place, we developed a fragment allocation scheme called S-FAS to improve the security of a heterogeneous distributed system. S-FAS allocates fragments of a file in such a way that even if attackers compromised a number of server groups but fewer than k fragments are disclosed, the file cannot be reconstructed from the compromised fragments.
To evaluate the S-FAS scheme, we built the static and dynamic assurance models in order to quantify the assurance of a heterogeneous distributed storage system processing file fragments. We developed a SAP file allocation algorithm based on the analysis of the assurance model as well as the proposed S-FAS scheme. In order to measure the performance of the S-FAS scheme and the algorithm, we built a prototype in a real-world distributed storage system
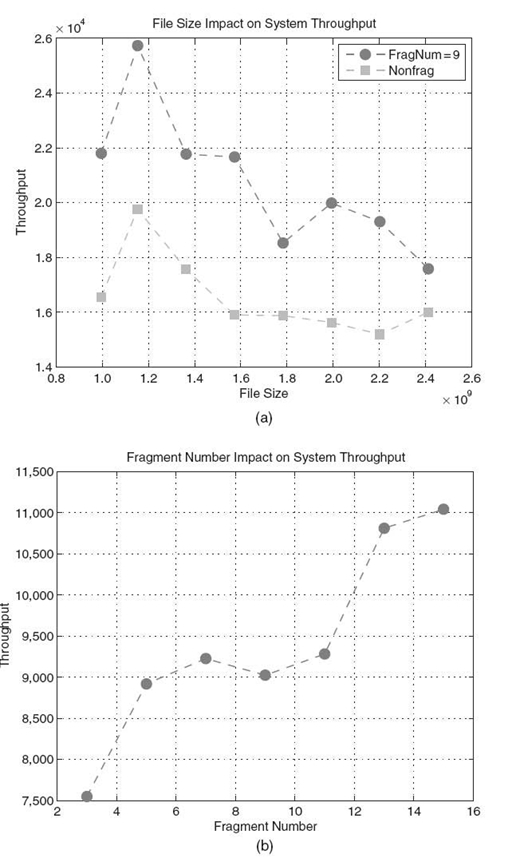
FIGURE 16.9. File size and fragment number impact on system throughput: (a) impact of file size(file size: byte;throughput: byte per millisecond) and (b) impact of fragment number(fragment number: 3, 5, 7,…, 15; throughput: byte per millisecond.
We demonstrated how S-FAS incorporates the vulnerability heterogeneity feature into file fragment allocation for distributed storage systems. Experimental results show that increasing heterogeneity levels can improve file assurance in a distributed storage system. The experimental results of our prototype implementation offer us inspiration on how to use S-FAS to efficiently improve security and performance in distributed storage systems with heterogeneous vulnerabilities.
ACKNOWLEDGMENTS
This research was supported by the U.S. National Science Foundation under grants CCF-0845257 (CAREER), CNS-0917137 (CSR), CNS-0757778 (CSR), CCF-0742187 (CPA), CNS-0831502 (CyberTrust), CNS-0855251 (CRI), OCI-0753305 (CI-TEAM), DUE-0837341 (CCLI), and DUE-0830831 (SFS), as well as Auburn University under a startup grant, and a gift(No.2005-04-070) from the Intel Corporation.
REFERENCES
[1] M. Pourzandi, D. Gordon, W. Yurcik, and G.A. Koenig, “Clusters and security: Distributed security for distributed systems,” in IEEE International Symposium on Cluster Computing and the Grid, 2005. CCGrid 2005, Vol.1, pp. 96‒104, May 2005.
[2] H. Mantel, “On the composition of secure systems,” in 2002 IEEE Symposium on Security and Privacy, 2002.
[3] W. Yurcik, G.A. Koenig, X. Meng, and J. Greenseid, “Cluster security as a unique problem with emergent properties: Issues and techniques,” in The 5th LCI International Conference on Linux Clusters: The HPC Revolution 2004, pp. 18‒20, 2004.
[4] S. Jajodia, A. Mei, and L.V. Mancini, “Secure dynamic fragment and replica allocation in large-scale distributed file systems,” IEEE Transactions on Parallel and Distributed Systems, 14(9): 885‒896, 2003.
[5] T. Wu, M. Malkin, and D. Boneh, “Building intrusion tolerant applications,” in SSYM ´99: Proceedings of the 8th Conference on USENIX Security Symposium, pp. 7‒7. Berkeley, CA: USENIX Association, 1999.
[6] J.F. Bouchard and D.L. Kewley, “Darpa information assurance program dynamic defense experiment summary,” IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems and Humans, 31(4): 331‒336, 2001.
[7] B.M. Thuraisingham and J.A. Maurer, “Information survivability for evolvable and adaptable real-time command and control systems,” IEEE Transactions on Knowledge and Data Engineering, 11(1): 228‒238, 1999.
[8] J. Kubiatowicz, D. Bindel, Y. Chen, S. Czerwinski, P. Eaton, D. Geels, R. Gummadi, S. Rhea, H. Weatherspoon, W. Weimer, C. Wells, and B. Zhao, “Oceanstore: An architecture for global-scale persistent storage,” SIGPLAN Notices, 35: 190‒201, 2000.
[9] S. Lakshmanan, M. Ahamad, and H. Venkateswaran, “Responsive security for stored data,” IEEE Transactions on Parallel and Distributed Systems, 14(9): 818‒828, 2003.
[10] M.O. Rabin, “Efficient dispersal of information for security, load balancing, and fault tolerance,” Journal of the ACM, 36: 335‒348, 1989.
[11] A. Shamir, “How to share a secret,” Communications of the ACM, 22(11): 612‒613, 1979.
[12] M. Tu, P. Li, I.-L. Yen, B.M. Thuraisingham, and L. Khan, “Secure data objects replication in data grid,” IEEE Transactions on Dependable and Secure Computing, 7(1): 50‒64, 2010.
[13] F. Dabek, M.F. Kaashoek, D. Karger, R. Morris, and I. Stoica, “Wide-area cooperative storage with cfs,” in SOSP’01: Proceedings of the 18th ACM Symposium on Operating Systems Principles, pp. 202‒215, New York, 2001. ACM.
[14] T. Pedersen, “Non-interactive and information-theoretic secure verifiable secret sharing,” in Proceedings of the 11th Annual International Cryptology Conference on Advances in Cryptology, CRYPTO’ 91, pp. 129‒140. London, UK: Springer-Verlag, 1992.
[15] G.J. Simmons, “How to (really) share a secret,” in CRYPTO’88: Proceedings of the 8th Annual International Cryptology Conference on Advances in Cryptology, pp. 390‒448. London, UK: Springer-Verlag, 1990.
[16] J.D. Strunk, G.R. Ganger, H. Kiliccote, P.K. Khosla, J.J. Wylie, and M.W. Bigrigg, “Survivable information storage systems,” Computer, 33(8): 61‒68, 2000.
[17] G. Zanin, A. Mei, and L.V. Mancini, “Towards a secure dynamic allocation of files in large scale distributed file systems,” in HOT-P2P’04: Proceedings of the 2004 International Workshop on Hot Topics in Peer-to-Peer Systems, pp. 102‒107. Washington, DC: IEEE Computer Society, 2004.
[18] L.W. Lee, P. Scheuermann, and R. Vingralek, “File assignment in parallel i/o systems with minimal variance of service time,” IEEE Transactions on Computers, 49(2): 127‒140, 2000.
[19] P. Scheuermann, G. Weikum, and P. Zabback, “Data partitioning and load balancing in parallel disk systems,” The VLDB Journal, 7(1): 48‒66, 1998.